
Методика человек интерпретация: Сторінку не знайдено | Донецький обласний навчально-методичний центр психологічної служби системи освіти
Методика «Человек под дождём». Авторы А. Абрамс, А. Эмчин. Проективные (рисуночные) тесты.
Малораспространённой, но интересной и информативной является методика Человек под дождём. Эта проективная методика ориентирована на диагностику силы Эго человека, его способности преодолевать неблагоприятные ситуации, противостоять им. Она позволяет также осуществить диагностику личностных резервов и особенностей защитных механизмов. Тест позволяет определить, как человек реагирует на стрессовые, неблагоприятные ситуации, что он чувствует при затруднениях. Тест Человек под дождем подходит как для детей, так и для взрослых.
Инструкция к тесту Человек под дождем.
На чистом листе бумаги формата А4, который вертикально ориентирован, нарисуйте человека под дождём. Рисуйте свободно, в любой части листа, и столько времени, сколько вам потребуется. Вы можете рисовать подробно, с деталями, а можете ограничиться самым простым рисунком.
Ключ к тесту Человек под дождем.
В процессе тестирования важно наблюдать за ходом рисования и обращать внимание на все высказывания испытуемого. Для получения более достоверной информации необходимо провести дополнительное интервью.
Примеры дополнительных вопросов:
- Расскажите об этом человеке: как он себя ощущает, чувствует?
- Как он здесь оказался?
- Насколько комфортно чувствует себя человек в этой ситуации?
- Kакое у него настроение?
- Что ему больше всего хочется сделать?
- Дождь пошёл неожиданно или по прогнозу?
- Человек был готов к тому, что пойдёт дождь или для него это неожиданность?
- Любите ли Вы дождь? Почему?
- В какой момент времени мы его застали?
- Что с ним будет дальше?
- Если человеку под дождём плохо, то чем ему можно помочь?
- Что сам человек может сделать, чтобы себе помочь, чтобы справится с дождём?
- Что Вы чувствуете, когда смотрите на свой рисунок?
- Что для Вас значит каждая его деталь?
При интерпретации рисунков рекомендуется руководствоваться следующими положениями — когда рисунок готов, важно воспринять его целиком. Необходимо «войти» в рисунок и почувствовать, в каком настроении пребывает персонаж (радостном, ликующем, удручённом и т. д.), ощущает ли он себя беспомощным или, напротив, чувствует в себе внутренние ресурсы для борьбы с трудностями, а возможно, спокойно и адекватно воспринимает затруднения, считая их обычным жизненным явлением. Таким образом, важно отследить глобальное впечатление от рисунка. Это интуитивный процесс.
Необходимо «войти» в рисунок и почувствовать, в каком настроении пребывает персонаж (радостном, ликующем, удручённом и т. д.), ощущает ли он себя беспомощным или, напротив, чувствует в себе внутренние ресурсы для борьбы с трудностями, а возможно, спокойно и адекватно воспринимает затруднения, считая их обычным жизненным явлением. Таким образом, важно отследить глобальное впечатление от рисунка. Это интуитивный процесс.
Только после этого можно перейти к анализу всех специфических деталей с точки зрения логики, опираясь при этом на основные положения руководства по интерпретации.
Интерпретация к методике Человек под дождем.
Важно посмотреть, как представлена экспозиция. Так, например, если человек изображён уходящим, то это может быть связано с наличием тенденции к уходу от трудных жизненных ситуаций, избеганию неприятностей (особенно если фигура человека изображается как бы наблюдаемой с высоты птичьего полёта).
В случае смещения фигуры человека под дождём в верхнюю часть листа можно предположить склонность испытуемого к уходу от действительности, к потере опоры под ногами, а также наличие защитных механизмов по типу фантазирования, чрезмерного оптимизма, который часто не оправдан.
Положение фигуры в профиль или спиной указывает на стремление отрешиться от мира, к самозащите.
Изображение, помещённое внизу листа, может свидетельствовать о наличии депрессивных тенденций, чувстве незащищённости.
В остальном при интерпретации Человека можно опираться на методику «Дом, Дерево, Человек». Например, изображение, смещённое влево, возможно, связано с наличием импульсивности в поведении, ориентацией на прошлое, в ряде случаев с зависимостью от матери. Изображение, смещённое вправо, указывает на наличие ориентации на окружение и, возможно, зависимость от отца.Изображение фигуры: Чрезмерно увеличенное изображение фигуры иногда встречается у подростков, которых неприятности мобилизуют, делают более сильными и уверенными. Уменьшение фигуры имеет место тогда, когда испытуемый нуждается в защите и покровительстве, стремится перенести ответственность за собственную жизнь на других. Люди, которые рисуют маленькие фигурки, обычно стесняются проявлять свои чувства и имеют тенденцию к сдержанности и некоторой заторможенности при взаимодействии с людьми, а также может указывать на заниженную самооценку в проблемных ситуациях.
Если в рисунке «Человека под дождём» при изображении фигуры пропускаются какие-либо части тела (ноги, руки, уши, глаза), то это указывает на специфику защитных механизмов и особенности проявлений Эго-реакций (нет ног – нет возможности уйти от ситуации; рук – сделать что-то, преобразовать действительность; глаз – не хочу видеть; ушей – слышать и т.д., что впоследствии при длительном и сильном воздействии проблемной ситуации может привести к психосоматическим проявлениям в данной части тела – нежелание слышать происходящие может привести к понижению слуха).
Атрибуты дождя: дождь – помеха, нежелательное воздействие, побуждающее человека закрыться, спрятаться.
Необходимо определить, откуда дождь «приходит» (справа или слева от человека) и какая часть фигуры подвергается воздействию в большей степени. Интерпретация проводится в соответствии с приписываемыми значениями правой и левой стороны листа или фигуры человека.
Более полная расшифровка деталей основывается на символическом значении представленных образов. Например, молния может символизировать начало нового цикла в развитии и драматические изменения в жизни человека. Радуга, нередко возникающая после грозы, предвещает появление солнца, символизирует мечту о несбыточном стремлении к совершенству.
Зонт представляет собой символическое изображение психической защиты от неприятных внешних воздействий. С точки зрения трактовки образов зонт может рассматриваться как отображение связи с матерью и отцом, которые символически представлены в образе зонта: купол – материнское начало, а ручка – отцовское. Зонт может защищать или не защищать от непогоды, ограничивать поле зрения персонажа, а может и отсутствовать.
Зонт может защищать или не защищать от непогоды, ограничивать поле зрения персонажа, а может и отсутствовать.
Так, например, огромный зонт-гриб может свидетельствовать о сильной зависимости от матери, решающей все сложные ситуации за человека или сильнейшей потребности в ней. Размер и расположение зонта по отношению к фигуре человека указывают на интенсивность действия механизмов психической защиты.
Искажение и пропуск деталей: отсутствие существенных деталей может указывать на область конфликта и быть следствием вытеснения как защитного механизма психики. Так, например, отсутствие зонта в рисунке может свидетельствовать об отрицании поддержки со стороны родителей в трудной ситуации.
Все дополнительные детали (дома, деревья, скамейки, машины) или предметы, которые человек держит в руках (сумочка, цветы, книги), рассматриваются как отражение потребности в дополнительной внешней опоре, в поддержке, в стремлении уйти от решения проблем путем переключения и замещающей деятельности. Дополнительные предметы, изображенные на рисунке (фонарь, солнце и т.д.), могут символизировать значимых людей для автора рисунка. Животные и птицы – потребность в ласке и заботе.
Дополнительные предметы, изображенные на рисунке (фонарь, солнце и т.д.), могут символизировать значимых людей для автора рисунка. Животные и птицы – потребность в ласке и заботе.
Лужи, грязь символически отражают последствия тревожной ситуации, те переживания, которые остаются после «дождя». Следует обратить внимание на манеру изображения луж (форму, глубину, брызги). Важно отметить, как расположены лужи относительно фигуры человека (находятся ли они перед или за фигурой, окружают человека со всех сторон или он сам стоит в луже). Лужи — скажут нам о том, что человек уже давно пребывает в стрессовой ситуации, о том, что его стресс принял хроническую форму.
Если лужа находится слева, значит, человек видит проблемы в прошлом.
Если справа – предвидит их в будущем.
Если человек стоит в луже, это может означать неудовлетворенность, потерю ориентиров.
Тучи являются символом ожидания неприятностей. Важно обращать внимание на количество облаков, туч, их плотность, размер, расположение. В депрессивном состоянии изображаются тяжелые грозовые тучи, занимающие все небо. Косматые, темные и многочисленные тучи говорят о том, что человек склонен заранее ожидать неприятности. Также могут указывать на то, что человек хорошо знаком с основным источником своего стресса и постоянно о нём думает.
В депрессивном состоянии изображаются тяжелые грозовые тучи, занимающие все небо. Косматые, темные и многочисленные тучи говорят о том, что человек склонен заранее ожидать неприятности. Также могут указывать на то, что человек хорошо знаком с основным источником своего стресса и постоянно о нём думает.
Тенденции.
Признаки эмоциональной холодности — схематичная фигура; лицо частично или полностью не прорисовано
Признаки импульсивности — много движений у фигуры; взлохмаченные волосы; несогласованность направленности тела, рук и ног; недостаточность одежды
Признаки конфликта в семье — ограничение пространства для фигуры; явное несоответствие качества рисунка другим; на лице прорисованы явно положительные эмоции.
Признаки инфантильности — человек в сказочной или праздничной одежде; на лице выражение восторга; у фигуры отсутствует шея; рисунок переместился вверх по сравнению с другими; уменьшение возраста человека, по сравнению с другими рисунками.
Если в рисунке «Человека под дождем» при изображении фигуры пропускаются какие-либо части тела (ноги, руки, уши, глаза), то это указывает на специфику защитных механизмов и особенности проявлений Эго-реакций.
Чрезмерно детские, игровые рисунки говорят о потребности в одобрении. Рисунки-шаржи означают желание избежать оценочных суждений в свой адрес, переживание неполноценности, враждебности.
Поза, ракурс
Слева направо акцент смещается с себя на мир, с прошлого на будущее и с пассивности на активность.
Человек изображен спиной – проявление замкнутости, конфликтность, иногда негативизм.
Человек идет или бежит – творческая направленность, в некоторых случаях желание скрыться от кого-либо.
Человек на рисунке стоит неустойчиво – это может означать напряжение, отсутствие стержня, равновесия.
Человек лежит или сидит – пассивность.
Голова в профиль, тело анфас – тревожность, иногда потребность в общении.
Занимается какой-нибудь работой – высокая активность.
Фигура из палочек указывает на негативизм, сопротивление методике.
Иногда изображение фигуры в профиль или со спины можно трактовать как желание отрешиться от действительности (так проявляется самозащита). Соответственно, это говорит о том, что у испытуемого сложности с установлением контакта с другими людьми.
Интерпретация Человека.
Голова — сфера интеллекта и контроля.
Чем больше голова, тем больше значимость интеллекта
Отсутствие головы может говорить о гиперактивности, импульсивности и, иногда о психических расстройствах (как и отсутствие любой другой важной части тела).
Шея — связь разума с чувствами. Чрезмерно крупная шея говорит о том, что рисующий осознает свои телесные импульсы и старается их контролировать. Длинная, тонкая шея означает торможение в осознании своих телесных импульсов. Короткая толстая шея — потакание слабостям, желаниям. Шея перевязана платком — разрыв связи между разумом и чувствами.
Плечи — признак физической силы. Чем больше плечи, тем больше потребность во власти, признании. Плечи мелкие — ощущение собственной ничтожности. Покатые плечи — уныние, отчаяние, чувство вины.
Чем больше плечи, тем больше потребность во власти, признании. Плечи мелкие — ощущение собственной ничтожности. Покатые плечи — уныние, отчаяние, чувство вины.
Лицо показывает отношение к миру, важно обратить внимание на выраженность тех или иных черт. Лицо подчеркнуто — сильная озабоченность отношениями с другими, своим внешним видом. Лицо спрятано под полями шляпы или закрыто зонтом или не прорисовано — стремление избегать неприятных воздействий.
Глаза
Большие заштрихованные глаза говорят о наличии страхов, желании контролировать внешнюю среду.
Маленькие глаза-точки (палочки) – погруженность в себя, избегание визуальных стимулов.
Закрытые глаза – стремление избегать неприятных визуальных контактов.
Пустые глаза – астения, импульсивность, иногда страхи.
Подведенные глаза с ресницами – демонстративность.
Отсутствие глаз – свидетельство гиперактивности, высокой импульсивности.
Нос
Нос выдающийся с горбинкой – презрение, ирония.
Нос особенно большой – недовольство своей внешностью.
Хорошо прорисованные ноздри выражают агрессию.
Рот
Рот отсутствует или очень маленький – астения, негативизм. Также может означать невозможность открыто выражать свое мнение.
Впалый рот – пассивность.
Рот перекошен – негативизм, иногда отрицательное отношение к тестированию.
Очень большие губы, жирно обведенные – значимость сексуальной сферы.
Рот с хорошо прорисованными зубами – агрессия.
Уши
Чем больше уши, тем больше значения придается мнению со стороны и тем спокойнее человек воспринимает критику.
Волосы
Волосы сильно заштрихованы – тревожность.
Тщательно прорисованы как волосы, так и прическа – демонстративность.
Туловище
Чрезмерно крупное — наличие неудовлетворенных потребностей, желаний.
Тело квадратное — признак мужественности.
Тело очень маленькое — чувство унижения, обесценивания.
Очень полная фигура – в некоторых случаях недовольство своей внешностью.
Длинная, худощавая – астения.
Уродливая – негативизм, импульсивность.
Фигура обнажена или просвечивает через одежду – повышенный интерес к сексуальной сфере.
Фигура, согнувшаяся от ветра, – потребность в любви и заботе.
Фигура с ранами и шрамами – невротическое состояние.
Фигура с татуировкой – негативизм или демонстративность. Если изображена татуировка, присутствующая у человека, это также может просто указывать на её значимость (следует задать соответствующие вопросы).
Руки – символ межличностного взаимодействия и возможностей человека.
Отсутствие рук – импульсивность, нарушение общения.
Руки расположены близко к телу – напряжение.
За спиной, скрещены на груди, в карманах, уперты в бока – нежелание общения, в некоторых случаях враждебность.
Руки за спиной означают нежелание уступать, однако агрессия находится под контролем.
Руки расставлены в разные стороны – общительность.
Руки длинные и мускулистые – стремление к физической силе, храбрости. Руки слишком длинные — большие амбиции.
Руки очень короткие – отсутствие стремлений, чувство неадекватности.
Кисти рук отсутствуют или укорочены – недостаток в общении. Отсутствие рук — нежелание общаться, чувство собственной неадекватности.
Очень большие кисти – потребность в общении.
Кисти рук зачернены – конфликтность.
Большой кулак, острые ногти – агрессивность.
Широко раскрытые руки, ладонями вперед говорят об открытости, стремлению к действиям.
Если руки шире у запястий, чем у плеч, это говорит об импульсивности в действиях.
Если руки изображены отдельно от тела — импульсы тела для рисующего неподконтрольны.
Руки напряжены и прижаты к телу — ригидность, неповоротливость, напряжение.
Пальцы на рисунке олицетворяют чувства, чаще всего агрессию. Большие пальцы, нарисованные отдельно, выражают вытесненную агрессивность.
Связанные руки (или другая форма лишения движения) — невозможность изменить внешнюю ситуацию, отсутствие веры в свои силы или возможности их проявления.
Ноги
Ноги широко расставлены – потребность в общении.
Ступни ног отсутствуют – пассивность.
Ступни ног очень маленькие – неумелость в социальных отношениях.
Ступни ног большие – потребность в опоре.
Одежда
Функция одежды — «формирование защиты от стихии».
Обилие одежды указывает на потребность в дополнительной защите.
Отсутствие одежды связано с игнорированием определенных стереотипов поведения, импульсивностью реагирования.
Детально вырисованная одежда (карманы, шляпа, туфли, украшения, отделка и т. п.) – демонстративность.
Многочисленные пуговицы – ригидность, в некоторых случаях закрытость.
Другие особенности одежды трактуются на основе беседы.
Цвет в рисунке
Рисунки можно выполнять простым карандашом. Следует помнить, что точная интерпретация цветового решения не может быть сделана, если у испытуемого нет всего набора цветных карандашей.
Цвета могут символизировать определенные чувства, настроение и отношения человека. Они также могут отражать спектр различных реакций или областей конфликтов.
Хорошо адаптированный и эмоционально не обделенный ребенок (если тест проводится ребенку) обычно использует от двух до пяти цветов. Семь-восемь цветов свидетельствуют о высокой лабильности. Использование одного цвета говорит о возможной боязни эмоционального возбуждения.
Семь-восемь цветов свидетельствуют о высокой лабильности. Использование одного цвета говорит о возможной боязни эмоционального возбуждения.
Обедненная цветовая гамма (использование простого карандаша или одного-двух цветов) – пассивность, астения, депрессия.
Пониженная плотность цвета (слабый нажим, незакрашенный контур) – астения или отрицательное отношение к обследованию.
Преобладание холодных тонов – снижение настроения, субдепрессия.
Преобладание темных тонов (особенно сочетание черного с коричневым или синим) – депрессия, повышенная напряженность.
Много красного цвета указывает на тревогу, эмоциональное напряжение, иногда агрессивность.
Много красного цвета в сочетании с темными тонами – депрессия.
Источник: Журнал научных публикаций «Актуальные проблемы гуманитарных и естественных наук» СПб, №2 ;2009, стр. 279.
Методика «Человек под дождём». Авторы А. Абрамс, А. Эмчин. Проективные (рисуночные) тесты.
Оцените статью:
Другие тесты, которые могут быть вам интересны:
- Назад: Методика «Определение типа поведения в стрессовой ситуации».
 Типы А, В и АВ.
Типы А, В и АВ. - Вперед: Опросник Шкала депрессии В. Зунга (Цунга). Адаптация Т. И. Балашовой.
|
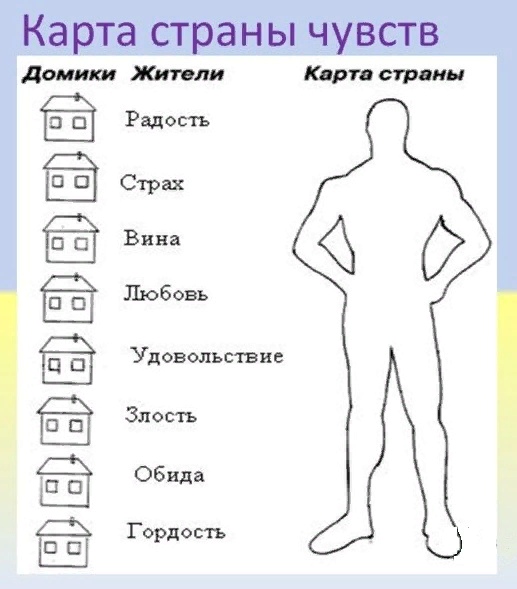
Цель: Исследование эмоционально-личностной сферы детей и подростков, умение их реагировать на стресс, способность преодолевать жизненные трудности. Процедура проведения. Лист бумаги формата А4, простой карандаш (желательно мягкий) и ластик. Нарисуйте на листе бумаги человека под дождем. Нарисовали? Читайте интерпретацию рисунка … Прежде чем приступить к интерпретации рисунка, постарайтесь «войти» в него, почувствовать, какое настроение у изображенного на нем героя. Интерпретация рисункаТяжелые грозовые тучи, вспышки молний, темное небо, плотная стена проливного дождя на рисунке могут свидетельствовать о том, что и в реальной жизни рисовавшего в данный момент наблюдается «ненастная погода». Возможно, он пребывает в подавленном состоянии или депрессии. Протокол анализа теста «Человек под дождём»Ф.И. _________________________ , класс ___________ , дата ______
|
||
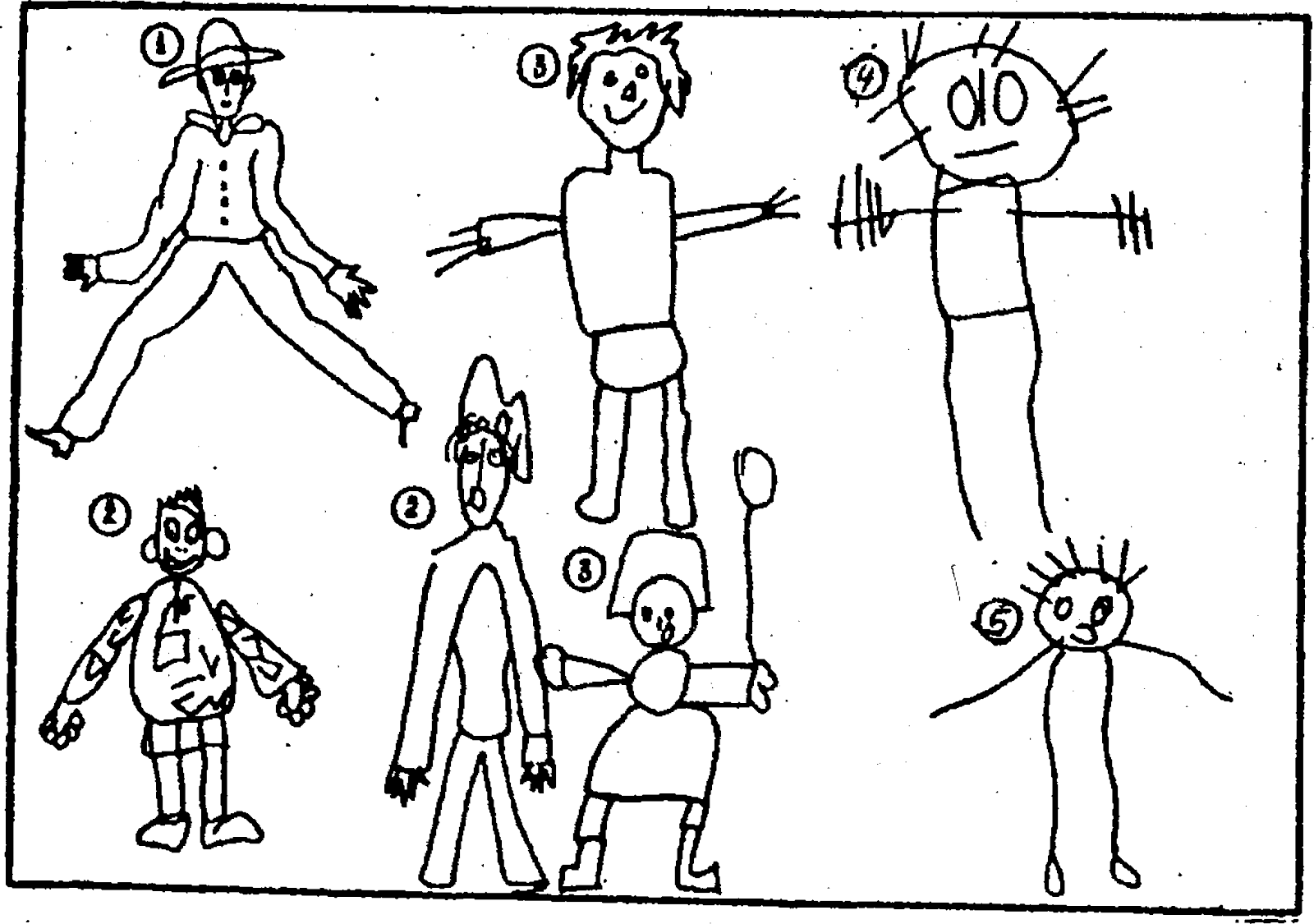 Какое впечатление производит увиденная вами картина? Какие эмоции она вызывает? Это важно понять, ведь перед нами не что иное, как автопортрет художника на фоне стрессовой ситуации. В качестве символического стресса в данном случае выступает дождь. Как поведет себя настигнутый стихией человечек на рисунке? Попытается спрятаться или убежать? Сумеет защититься от непогоды, облачившись в непромокаемый плащ? Раскроет зонт? Наденет резиновые сапоги? Или будет беспомощно стоять на месте, поливаемый струями дождя? Впрочем, может, он как раз любит дождик, и не имеет ничего против того, чтобы иногда побегать по лужам…
Какое впечатление производит увиденная вами картина? Какие эмоции она вызывает? Это важно понять, ведь перед нами не что иное, как автопортрет художника на фоне стрессовой ситуации. В качестве символического стресса в данном случае выступает дождь. Как поведет себя настигнутый стихией человечек на рисунке? Попытается спрятаться или убежать? Сумеет защититься от непогоды, облачившись в непромокаемый плащ? Раскроет зонт? Наденет резиновые сапоги? Или будет беспомощно стоять на месте, поливаемый струями дождя? Впрочем, может, он как раз любит дождик, и не имеет ничего против того, чтобы иногда побегать по лужам…
 В последнем случае можно говорить о том, что рисовавший имеет достаточное количество творческих ресурсов для противостояния житейским неурядицам.
В последнем случае можно говорить о том, что рисовавший имеет достаточное количество творческих ресурсов для противостояния житейским неурядицам.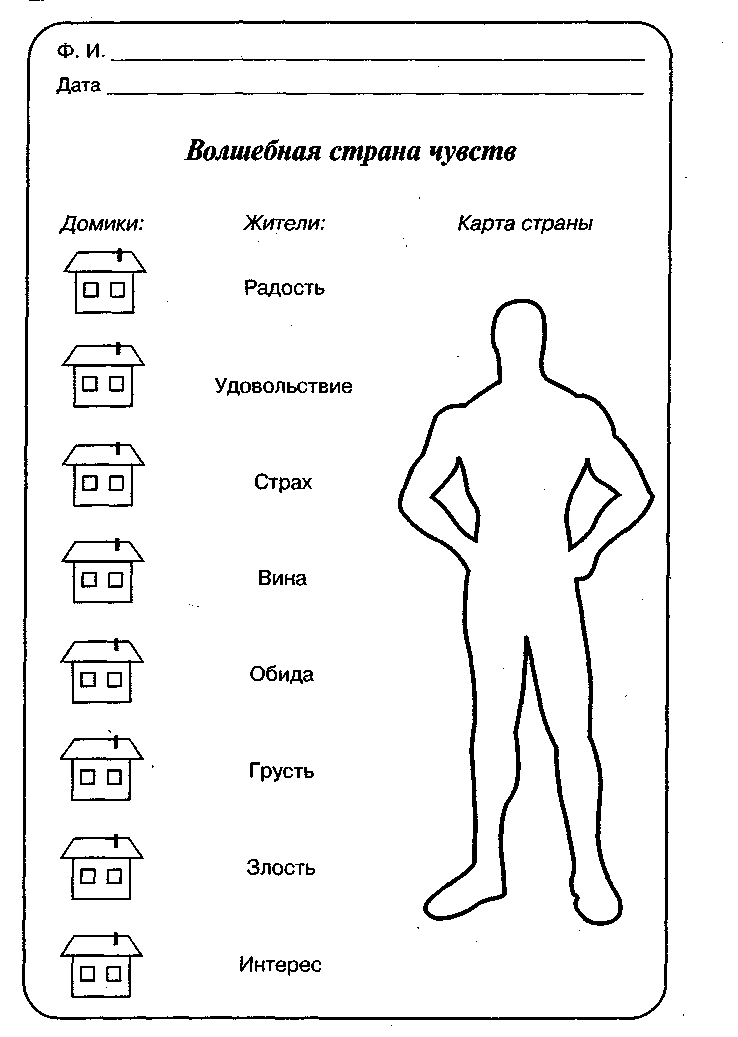 При этом если нарисованный ребенок выглядит покинутым, растерянным и беспомощным, – велика вероятность того, что и в случае реальных жизненных испытаний нарисовавший его может повести себя инфантильно, ожидая, что кто-то более сильный о нем позаботится: «возьмет под свое крыло» или «тучи разведет руками».
При этом если нарисованный ребенок выглядит покинутым, растерянным и беспомощным, – велика вероятность того, что и в случае реальных жизненных испытаний нарисовавший его может повести себя инфантильно, ожидая, что кто-то более сильный о нем позаботится: «возьмет под свое крыло» или «тучи разведет руками».

 Изображение человека помещено в угол листа
Изображение человека помещено в угол листа Мужская фигура
Мужская фигура При этом если нарисованный ребенок выглядит покинутым, растерянным и беспомощным
При этом если нарисованный ребенок выглядит покинутым, растерянным и беспомощным Отсутствие рук
Отсутствие рук Дополнительные образы и детали на рисунке: дома, деревья, автомобили, животные, а также сумочки, цветы, трости и прочие предметы, находящиеся в руках у нарисованного человека
Дополнительные образы и детали на рисунке: дома, деревья, автомобили, животные, а также сумочки, цветы, трости и прочие предметы, находящиеся в руках у нарисованного человекаПроективная методика «Дом.Дерево.Человек»: подробная интерпретация
В статье мы расскажем:
- Методика «Дом.Дерево.Человек»: характеристика
- Интерпретация рисунка дома
- Отношение рисунка к листу бумаги
- Заключение
Всем известна поговорка, часть которой построить дом, посадить дерево и родить сына. Не случайно, методика «Дом. Дерево. Человек» (ДДЧ) одна из самых востребованных у психологов, использующих проективные методики в своей работе. В статье мы расскажем, что представляет собой проективная методика «Дом.Дерево.Человек», как правильно расшифровывается рисунок.
Методика «Дом.Дерево.Человек»: характеристика
Сама методика предложена Дж.Буком в 1948 году. Она изначально предназначалась для определения уровня интеллектуального развития человека. Но затем разглядели возможность использовать рисунки для получения психологического портрета человека.
Разные модификации методики «Дом. Дерево.Человек» отличаются тем, что предлагается нарисовать их на одном листе одной сценой или на разных листах. Мы будем рассматривать по отдельности.
Напомним, что для рисунка необходимы:
-
бумага нелинованная, белая, выбранного стандарта
-
карандаш простой средней мягкости
Что надо сделать? Нарисовать дом, дерево и человека. Остановитесь и нарисуйте свой рисунок. А затем читайте интерпретацию.
Интерпретация рисунка дома
Возможно три варианта дома:
-
многоэтажное здание обязательно с антенной.
 Это самый редкий вариант, который человек рисует. Но этот вариант рисуют те, для которых семья имеет чисто номинальное значение. Антенна – обязательный атрибут такого рисунка – признак формальной связи. Интерпретируется наличие антенны, даже если она встречается в других вариантах изображения дома.
Это самый редкий вариант, который человек рисует. Но этот вариант рисуют те, для которых семья имеет чисто номинальное значение. Антенна – обязательный атрибут такого рисунка – признак формальной связи. Интерпретируется наличие антенны, даже если она встречается в других вариантах изображения дома.
-
Традиционный дом – это самый распространенный вариант. Его рисует 90% испытуемых;
-
«экзотика» – это все остальные варианты, которые не подпадают под первые два, например, шалаш, скворечник и тому подобное. Экзотичный вариант рисунка дома свидетельствует о романтизации отношения к семье и сформированности представления о том, что такое дом, что такое семья. Мир семьи важен настолько, что он противопоставляется всему остальному миру.
В качестве иллюстрации экзотичного варианта рисунка дома можно продемонстрировать работу современного польского художника Яцека Йерка.
Необходимые детали, которые должны быть нарисованы:
Надо обращать внимание, если одна из этих деталей отсутствует. Поскольку это тоже является диагностическим признаком.
Смешанные варианты домаПредставлены два варианта домов в смешанном стиле:
-
промежуточный вариант между традиционным и экзотичным домом
-
промежуточный вариант между домом-зданием и традиционным домом
И в том, и в другом случае отдельные признаки интерпретируется, как если бы дом был традиционным.
Обязательные элементы-
«Домик аутиста» – изображен дом только с одним окном и без двери. Аутичный он в том смысле, что свидетельствует о дефиците у автора рисунка социального взаимодействия и общения.
-
Манифестация «мой дом» – выражены признаки обитаемости: дым из трубы, занавески, цветочки на окне.
 Значит понятие «мой дом» очень важно и в реальном доме этот человек с трудом потерпит другого хозяина.
Значит понятие «мой дом» очень важно и в реальном доме этот человек с трудом потерпит другого хозяина.
-
Дом старый, разваливающиеся– разрушительное отношение к самому себе, аутоагрессия.
-
Дерево закрывает дом – потребность в зависимости и контроле от доминантных родителей или людей исполняющих эту роль.
-
Дом вытянут вверх – слабое чувство реальности.
-
Эффект прозрачной стены – когда она есть, но открыта для зрителей – демонстративное выставление собственной жизни всем на обозрение и потребность во внешнем влиянии на ситуацию в доме, для ее нормализации.
Замечание! Если диагностический признак находится только на одном рисунке, интерпретация ограничивается только темой этого рисунка. Если же тот или иной признак встречается в разных рисунках, неоднократно, то можно говорить о том, что он характеризует личность в целом.
Если же тот или иной признак встречается в разных рисунках, неоднократно, то можно говорить о том, что он характеризует личность в целом.
Другие предметы Признак: стена
Признак: крыша
Крыша совмещает себе две функции:
Все это касается самого дома, семьи, отношения с близкими людьми, но необязательно входящими в понятия «семья» для этого человека
| Характеристика | Интерпретация |
| Толстый контур края | Чрезмерная озабоченность контролем над фантазией, попытка ее обуздать |
| Крыша обведена черным контуром, который не свойственен всему другому и выбивается из контекста | Это свидетельствует о фиксации на фантазиях, как источнике удовольствие и обычно такие фантазии вызывают у человека тревогу |
| Крыша не совпадает по размеру с домом | Плохая структура организации личности |
| Тонкий контур края или его вообще нет | Это переживание ослабления контроля над собственными фантазиями |
| Сильно прочерчена поверхность крыши | Свидетельствует о повышенной тревожности |
| Наличие карниза его акцентирование ярким контуром или с выходом за контур | Это сильная защитная установка обычно сочетаемая с мнительностью |
Труба
| Характеристика | Интерпретация |
| Ее нет | Отсутствие психологической теплоты |
| Труба выделена | Подчёркивание «я мужик», а у женщин возможно нарушение сексуальной роли |
| Как бы перечеркнута, выглядит прозрачной | Повышенная озабоченность собственной сексуальностью |
| Труба «с дыркой» | Нарушение сексуальной жизни |
| Что-то другое на крыше кроме трубы, антенн | Повышенные защитные качества |
| С дымом | Теплые интимные отношения |
| Без дыма | Холод в интимных отношениях или их отсутствие |
| Дым выходит вправо | Пессимизм в оценке прошлых интимных отношений |
| Дым влево | Пессимизм в оценке будущего в интимных отношениях |
| Дым выходит в обе стороны | Патологический дефект чувства реальности |
| Тоненький дым | Дефицит теплоты в доме |
| Несоразмерно большое густой дым | Внутренняя напряженность в отношениях |
Окна
Они символизируют межличностные отношения характерные для автора рисунка. Количество окон указывает на количество метажильцов, то есть на число значимых членов семьи. Это число может отличаться от фактического количества членов семьи:
Количество окон указывает на количество метажильцов, то есть на число значимых членов семьи. Это число может отличаться от фактического количества членов семьи:
-
На рисунке окон меньше – значит, на самом деле кто-то из семьи для обследуемого не имеет большого значения;
-
Если больше – то у исследуемого есть человек, которого он хочет видеть в своей семье, но не получается, из-за каких-либо причин.
| Характеристика | Интерпретация |
| Пропорции окна нарушены | Есть какие-то осложнения с метажильцами |
| Окно распахнуто | Прямолинейность, эмоциональные разряды |
Двери
Двери – признак социальных контактов, открытости.
| Характеристика | Интерпретация |
| Нет двери | Ощущение проблемы раскрытия перед окружающими |
| Несоразмерно маленькие двери | Социальная неадекватность, нежелание впускать других в свое «я», неадекватность и нерешительность |
| Двери боковые | Отчужденность |
| Несоразмерно большие двери | Высокая зависимость от окружающих людей |
| Двери парадные, расположенные на фронтальной стене | Контактность |
| Распахнутые двери | Сильная потребность в тепле извне |
| Наличие второй двери | Значимый человек вне дома, любовник или любовница |
Признак: двор
Наличие двора помимо дома (дерево, цветы) свидетельствует о личных актуальных проблемах, имеющих корни в доме
| Характеристика | Интерпретация |
| Цветы вокруг дома | Аутизация |
| Деревья | Люди внешние, но значимые для автора рисунка |
| Забор вокруг дома | Стремление к изоляции, защите от внешнего мира |
Эволюция рисунка человека
-
3-4 года – головастик
-
4-5 лет – пупок
-
5 лет – половая дифференциация
-
5-6 лет – изображение пальцев, ладоней
-
6 лет – руки с туловищем больше, чем голова
-
6-7 лет – пуговицы
-
8 лет – плечи
-
8 лет – переход к двумерному изображению с перспективой
Дерево символизирует жизненные силы развития человека.
Существенные детали:
Есть два варианта дерева, когда сразу можно понять, что человек не желал проходить этот тест. Такими вариантами являются:
Разница между ними лишь в демонстрации настроения, которое вызывает эта тема. В первом случае – депрессивная, во втором – нарочито радостная.
Отношение рисунка к листу бумаги
| Характеристика | Интерпретация |
| Занимает маленькую площадь | Чувство неполноценности. Человек хочет избежать реальную жизнь |
| Занимает всю страницу | Сильная фрустрация, вызванная ограничивающими воздействиями окружающей среды, враждебность, раздражительность |
| Забор вокруг дома | Стремление к изоляции, защите от внешнего мира |
| В центре | Незащищенность, не умение приспособиться к окружающей среде |
| Слева | Ностальгическое настроение, акцент на переживания, которые были в прошлом, ориентир только на опыт прошлого |
| Справа | Стремление приблизить будущее, неудовлетворенность нынешним положением, жажда изменений к лучшему |
| Внизу | Неуверенность в себе, нерешительность, не заинтересованность в повышении своей значимости |
| Вверху | Довольно высокая самооценка, недовольство своим положением в обществе, ощущение недостатка признания со стороны окружающих |
Тест оценки поведения «Не дай человеку упасть»
ТЕСТ
Ф.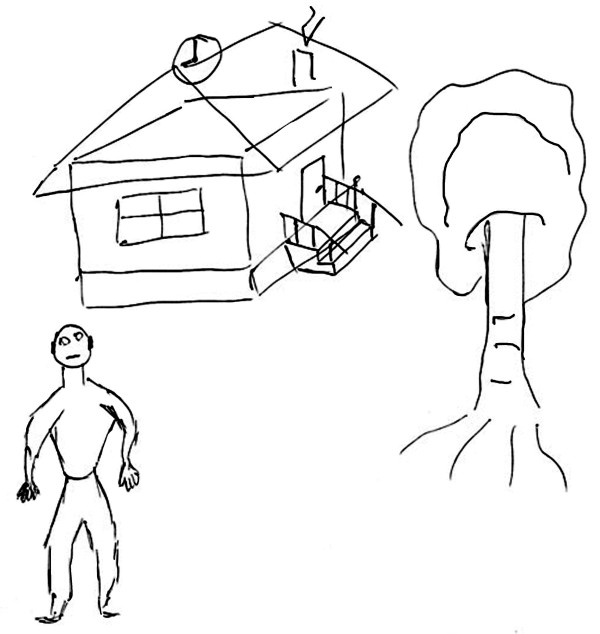 И. О. оцениваемого И. О. оцениваемого |
___________________________________________ |
| Возраст (полных лет) |
___________________________________________ |
| Должность |
___________________________________________ |
| Подразделение |
___________________________________________ |
| Дата заполнения |
___________________________________________ |
Инструкция
На этой картинке изображен обрыв и человек, то ли падающий, то ли прыгающий с него.
Вы должны спасти человека от неминуемой травмы, не дать ему упасть. Как вы это сделаете, решать вам. Дополните картину необходимыми деталями.
Тестовое задание
Спасибо!
Ключ к тесту оценки поведения «Не дай человеку упасть»
Описание теста
Проективная методика «Не дай человеку упасть» позволяет на основе принципов целостной психологии выявить особенности поведения оцениваемого в стрессовых, форс-мажорных ситуациях.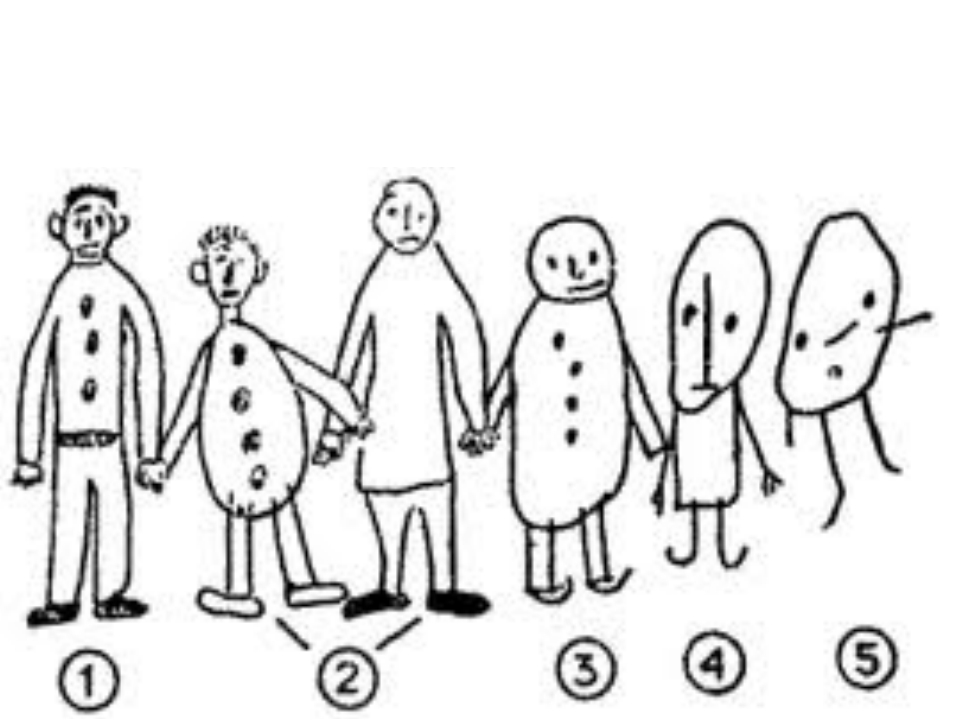
Оцениваемый дорисовывает рисунок, на котором изображен обрыв и человек, то ли падающий, то ли прыгающий с него. Он должен спасти человека от неминуемой травмы, не дать ему упасть. По нарисованному сюжету делаются выводы о возможном поведении человека в критической ситуации.
Интерпретация результата
Во-первых, прежде чем что-то нарисовать, оцениваемый должен был определить для себя, прыгает человек или падает. Если, по его мнению, человек добровольно прыгает с обрыва, то это говорит о решительности и активности оцениваемого, он предпочитает действие размышлениям, практик, а не теоретик. Если же оцениваемому кажется, что человек падает, то это значит, что он нерешительный и терпеливый, готов ждать, пока все утрясется само собой. Он не любитель активных действий.
Далее подробно остановитесь на тех деталях рисунка, которые были дорисованы в качестве первой помощи человеку и призваны не дать ему упасть и расшибиться. Если оцениваемый нарисовал воду под ногами у человека (реку, озеро, море), то это говорит о склонности все пускать на самотек. Нередко он сам доводит ситуацию до критического состояния, не предпринимая никаких шагов по ее урегулированию. Он бездействует в те моменты, когда нужно быть активным и решительным и брать быка за рога.
Нередко он сам доводит ситуацию до критического состояния, не предпринимая никаких шагов по ее урегулированию. Он бездействует в те моменты, когда нужно быть активным и решительным и брать быка за рога.
Если оцениваемый нарисовал под ногами у человека батут или натянутое одеяло, чтобы смягчить падение и поймать человека, то это говорит о предусмотрительности. Он очень редко попадает в критические ситуации, потому что всегда тщательно просчитывает все возможные варианты развития событий и старается предугадать все, что может случиться. Но даже если оцениваемый чего-то не учтет, то у него все равно всегда окажется готовое средство по спасению ситуации. На такого оцениваемого можно положиться, он не подведет.
Если оцениваемый нарисовал под обрывом человека с вытянутыми руками, готового поймать падающего в объятия, то это значит, что он неосмотрительный и доверчивый, в критической ситуации склонен доверяться кому ни попадя. Он не способен самостоятельно найти выход из тупика и ищет человека, который бы ему помог. Но так как оцениваемый не очень хорошо разбирается в людях, то они его часто обманывают и подводят.
Но так как оцениваемый не очень хорошо разбирается в людях, то они его часто обманывают и подводят.
Если оцениваемый превратил обрыв в небольшой холмик, тем самым прекратив падение человека, то это означает, что он обладает лидерскими качествами и способен вести людей за собой. В критической ситуации он не растеряется и сделает все, что нужно, чтобы исправить случившееся.
Если оцениваемый нарисовал человеку крылья, то это говорит о том, что он всегда найдет остроумный выход из сложного положения.
конструктивный рисунок человека из геометрических форм
Читайте также
Общий анализ особенностей изображения
Общий анализ особенностей изображения Общий анализ рисунков осуществляется по нескольким параметрам, которыми являются:• использование свободного пространства листа;• размеры рисунка относительно всего свободного поля;• наклон рисунка – без наклона, наклон
Пропорции изображения
Пропорции изображения
К восьми годам ребенок может выполнять рисунок фигуры человека с точными пропорциями. Нарушение пропорций изображения после восьми лет относится к психологическим симптомам осознаваемого или неосознаваемого усиленного внимания к аспектам
Нарушение пропорций изображения после восьми лет относится к психологическим симптомам осознаваемого или неосознаваемого усиленного внимания к аспектам
Глава 5. Особенности изображения головы и лица
Глава 5. Особенности изображения головы и лица Конкретные параметры изображения человека на четвертом уровне интерпретируются по отдельным элементам рисунка. Содержательный анализ рисунков позволяет выявить индивидуально-психологические особенности – черты и
Особенности изображения головы
Особенности изображения головы В особенностях изображения головы проявляются характерные для человека способы социального поведения и адаптации в социуме, наличие конформности или проявление негативизма.Голова круглой формыЭто самое распространенное изображение
Особенности изображения лица
Особенности изображения лица
Изображение черт лица указывает на коммуникативные признаки, потребность в общении и особенности установления эмоционального контакта. В изображении лица отражаются ведущие выразительные средства социальной адаптации.Заполненность
В изображении лица отражаются ведущие выразительные средства социальной адаптации.Заполненность
Глава 6. Психологический анализ изображения тела
Глава 6. Психологический анализ изображения тела Интерпретация изображения тела зависит от его формы, составных частей и особенностей их расположения. Изображение тела показывает особенности взаимоотношений в социальном окружении, в том числе в близких и семейных
Глава 7. Психологический анализ изображения шеи
Глава 7. Психологический анализ изображения шеи
Изображение шеи в рисунке говорит об особенностях саморегуляции. Шея регулирует отношения между головой и телом, мыслительными процессами и соматическими ощущениями, личными желаниями и социальными предписаниями. Форма и
Форма и
Глава 8. Психологический анализ изображения рук
Глава 8. Психологический анализ изображения рук Графически верхние и нижние конечности символизируют две основные сферы жизни человека – макросоциальную, отражающуюся в проекции рук, и микросоциальную, личную, проецирующуюся в изображении ног. Изображение рук и ног
Особенности изображения рук
Особенности изображения рук В изображении рук отражается способ коммуникации, стиль общения, особенности социальных взаимоотношений, определяется зависимое или независимое положение среди других. В частотном словаре русского языка характерные особенности руки
Глава 9. Особенности изображения ног
Глава 9. Особенности изображения ног
Ноги дают человеку опору, приводят все тело в движение, позволяют ему продвигаться вперед по жизни. Таким образом, помимо обеспечения устойчивости, ноги также позволяют человеку осваивать социальную территорию вокруг себя.
Особенности изображения ног
Ноги дают человеку опору, приводят все тело в движение, позволяют ему продвигаться вперед по жизни. Таким образом, помимо обеспечения устойчивости, ноги также позволяют человеку осваивать социальную территорию вокруг себя.
Глава 11. Психологический анализ способов изображения
Глава 11. Психологический анализ способов изображения Как отмечалось выше, параметры изображения фигуры человека на четвертом уровне интерпретировались по отдельным элементам рисунка. Следующий, пятый, уровень интерпретации позволяет по комбинации используемых
Анализ характера линии изображения
Анализ характера линии изображения
Характер линии изображения определяется по таким параметрам, как сплошная или разорванная, с нажимом или без нажима, твердая, уверенная или неуверенная. Карен Маховер справедливо считает нажим и четкость линий одним из основных
Карен Маховер справедливо считает нажим и четкость линий одним из основных
4.4. Первые изображения человека
4.4. Первые изображения человека Большинство взрослых пасует перед просьбой нарисовать человека. Но чем меньше ребенок, тем проще он соглашается на подобное предприятие. Он не ведает страха и не чувствует сложности. Как и в других рисунках, он изображает не человека, а его
Упражнение 3. Увеличение и уменьшение изображения
Упражнение 3. Увеличение и уменьшение изображения Рассмотрев цветную карточку (открытку), представим ее на левом луче настолько близко от лица, насколько вам удобно. Начинаем постепенно увеличивать картинку. Увеличив изображение в несколько раз, начинаем его уменьшать
15.
 Метапрограммирование изображения тела
Метапрограммирование изображения тела
15. Метапрограммирование изображения тела Некоторые метапрограммы представления своего тела данным человеческим биокомпьютером являются наиболее глубоко укоренившимися и ранее всего приобретенными. К важным для нас здесь программам относятся программы позы,
Используйте изображения, графики и диаграммы
Используйте изображения, графики и диаграммы PowerPoint поможет вам сделать выступление более наглядным. Используйте изображения, графики и диаграммы, если они подкрепляют ваше сообщение. PowerPoint предназначен для показа изображений, а не для слов. Следите, чтобы на слайде было
краткое описание и общие положения
Внутренний мир человека, его переживания и противоречия всегда сопряжены с миром внешним. Они не могут постоянно находиться запертыми, а находят всевозможные пути выхода, сигнализируя о себе в привычках, поведении и творческих поисках. Так, например, детские рисунки часто рассказывают больше психологам, чем простое общение с ребенком. Они способны извлечь информацию из самых потайных уголков детской души и на ранней стадии выявить серьезные психические проблемы. Отталкиваясь от этих принципов взаимодействия души и окружающего мира, была создана рисуночная методика «Человек под дождем». Применительно к детям она способна рассказать, как реагирует ребенок на стресс, способен ли он преодолевать жизненные трудности, каковы его защитные функции в опасных ситуациях. В чем же заключается суть методики и по каким параметрам формируются выводы?
Они не могут постоянно находиться запертыми, а находят всевозможные пути выхода, сигнализируя о себе в привычках, поведении и творческих поисках. Так, например, детские рисунки часто рассказывают больше психологам, чем простое общение с ребенком. Они способны извлечь информацию из самых потайных уголков детской души и на ранней стадии выявить серьезные психические проблемы. Отталкиваясь от этих принципов взаимодействия души и окружающего мира, была создана рисуночная методика «Человек под дождем». Применительно к детям она способна рассказать, как реагирует ребенок на стресс, способен ли он преодолевать жизненные трудности, каковы его защитные функции в опасных ситуациях. В чем же заключается суть методики и по каким параметрам формируются выводы?
Описание методики
Одной из версий психологического теста «Рисунок человека» является методика «Человек под дождем». Описание ее довольно просто. Испытуемого просят нарисовать соответствующую картинку, где дождь ассоциируется со стрессом, а нарисованный человек — с образом самого автора. В зависимости от того, какие действия выполняет этот человечек и что окружает его, можно сказать, какие модели поведения и эмоции проживает ребенок в некомфортной для него ситуации. Пытается ли он ее преодолеть или, наоборот, пасует, пытается всячески обойти, убежать…
В зависимости от того, какие действия выполняет этот человечек и что окружает его, можно сказать, какие модели поведения и эмоции проживает ребенок в некомфортной для него ситуации. Пытается ли он ее преодолеть или, наоборот, пасует, пытается всячески обойти, убежать…
Практическое применение методики
Методика «Человек под дождем» применительна к людям любого возраста, но наибольшей популярности и результативности она достигла в исследованиях школьной адаптации. Так, для многих педагогов и психологов одной из главных целей является изучение взаимодействия первоклассников и помощь им в быстром освоении в новом коллективе. Нужно помочь детям побороть страхи и комплексы, справиться со стрессовыми ситуациями вне школы, чтобы они в дальнейшем не препятствовали учебному процессу. Чтобы достичь этого, необходимо выбрать правильное средство. Оно должно быстро и четко охватывать весь поток первоклассников и давать обширные сведения для составления корректной психологической картины.
Проективная методика «Человек под дождем» — самая точная и выверенная система оценки характера и волевых качеств ребенка. Она поможет в сжатые сроки провести диагностику и дать специалисту нужные сведения. Авторами этого рисуночного метода являются Е. С. Романова и Т. И. Сытько. Они исходили из того, что личные ресурсы и защитные механизмы человека более четко и полно проявляются, когда он сталкивается с неблагоприятной ситуацией — в данном случае дождем. Дети особенно остро и чутко воспринимают окружающий мир, поэтому изображение природного явления и встречи человека с ним может дать очень эмоциональный и глубокий ответ на вопросы социальной адаптации и поможет сформировать корректное решение в устранении психологических блоков, страхов и комплексов.
Основные положения
Методика «Человек под дождем» для детей в своем классическом варианте реализуется в два этапа. Сначала предлагается нарисовать просто человека, затем добавляется условие — дождь. Таким образом, психолог получает от ребенка два рисунка. Разница иногда просто поражает. Изменяется не только эмоциональный фон за счет пейзажа, но и само изображение человека, использование красок. Также специалистами выявлена разница между рисунками девочек и мальчиков, что говорит о гендерных особенностях социальной адаптации. В целом выделяют несколько ключевых положений или параметров, на которых строится методика «Человек под дождем». Анализ рисунков происходит именно по размеру рисунка и фигуры человека, его действиям, возрасту и полу, цветовой палитре, а также по пейзажу и дополнительным предметам.
Разница иногда просто поражает. Изменяется не только эмоциональный фон за счет пейзажа, но и само изображение человека, использование красок. Также специалистами выявлена разница между рисунками девочек и мальчиков, что говорит о гендерных особенностях социальной адаптации. В целом выделяют несколько ключевых положений или параметров, на которых строится методика «Человек под дождем». Анализ рисунков происходит именно по размеру рисунка и фигуры человека, его действиям, возрасту и полу, цветовой палитре, а также по пейзажу и дополнительным предметам.
Размер рисунка
В этой категории происходит соотнесение человеческой фигуры с негативными атрибутами (каплями дождя, лужами, тучами, молниями). Обилие и нестандартные размеры последних говорят о неспособности принимать стрессовые ситуации и пытаться их быстро разрешить. Обратная ситуация в дополнении с аккуратностью рисунка, его эстетикой указывает на достаточный личный ресурс, который позволяет ребенку легко адаптироваться к непривычной обстановке.
Размер фигуры
Немалый акцент при анализе падает и на размер человеческой фигуры. Маленький размер говорит о некотором бессилии и необходимости в поддержке. Показателем потери опоры (почвы под ногами) может служить и слишком большой размер фигуры «человека под дождем», когда она увеличена настолько, что на лист бумаги помещен только корпус, ноги остаются «за пределами рисунка».
Уделяется внимание и расположению самой фигуры относительно центра картинки. Потеря его и смещение говорят о внутреннем дискомфорте ребенка, утрате внутреннего стержня или «центра», которые возникли вследствие неблагоприятных ситуаций. К ним относится та же адаптация к новым условиям и обстановке.
Действие человека
Каждая деталь в детском рисунке дает ответ на ряд вопросов, которые ставят специалисты и проективная методика «Человек под дождем». Интерпретация действий или бездействий главного персонажа говорит о готовности преодолевать трудности или пасовать перед ними. Однако характер действий может быть различен. Человек может стоять, спокойно гулять, спасаться бегством, прыгать и радоваться, сидеть или лежать в луже. Каждый вариант, как правило, напрямую соотносится с реальным поведением ребенка при неблагоприятных факторах.
Человек может стоять, спокойно гулять, спасаться бегством, прыгать и радоваться, сидеть или лежать в луже. Каждый вариант, как правило, напрямую соотносится с реальным поведением ребенка при неблагоприятных факторах.
Пол и возраст
На готовность принимать решения указывает и пол фигуры. Многочисленные исследования доказали, что мальчики не всегда рисуют мужскую фигуру, а девочки — женскую. В данном случае пол символизирует модель поведения при разрешении стрессовой ситуации, а именно: мужскую и женскую. Первая характеризуется решительностью, ответственностью, активными действиями в поиске выхода. Женской модели поведения свойственны пассивность, ранимость, доминирование интуиции. «Смена пола» человека в рисунке — это четкий указатель на изменение стиля поведения, реагирования.
Нередко в детских работах происходит и смена возраста главного персонажа. Понятно, что изображаемый человек — это прямая проекция автора рисунка. Поэтому возраст в данном случае может интерпретироваться как уровень качеств, помогающих ребенку принимать решения. Так, изображение взрослого человека может свидетельствовать о рассудительности, даже некой мудрости в сложных ситуациях либо говорит о потребности в опоре, поддержке со стороны взрослых. Изображение ребенка под дождем указывает на детское начало автора. Аналитическая справка методики «Человек под дождем» в этой ситуации дает оценку характеру автора по действиям нарисованной фигуры и общему настроению рисунка.
Так, изображение взрослого человека может свидетельствовать о рассудительности, даже некой мудрости в сложных ситуациях либо говорит о потребности в опоре, поддержке со стороны взрослых. Изображение ребенка под дождем указывает на детское начало автора. Аналитическая справка методики «Человек под дождем» в этой ситуации дает оценку характеру автора по действиям нарисованной фигуры и общему настроению рисунка.
Цвет
Немаловажную роль отдает методика «Человек под дождем» и цветовой палитре детского рисунка. Обычно ребенок использует любимые цвета, поэтому могут быть изображены фиолетовые лужи, синий или розовый дождь. Сама человеческая фигура, как правило, такая же цветная и радужная. Однако при исследованиях встречались и контрастные рисунки, где дождь и тучи были окрашены в темный и мрачный цвет, а человек, наоборот, представлен светлыми или яркими тонами. Использование широкой палитры цвета и противопоставление человека природной стихии говорит о четком осознании ребенком стресса и себя в этой дискомфортной ситуации. Таким образом, цвет — это проявление бессознательного, показатель отношения автора к себе, дождю и ситуации.
Таким образом, цвет — это проявление бессознательного, показатель отношения автора к себе, дождю и ситуации.
Средства защиты
Дополнительные атрибуты на рисунке также попадают под психологическую оценку. Так, самыми предсказуемыми являются изображения зонта, плаща, капюшона, накидки. Человек, надевая на себя эти средства защиты, может спокойно продолжать заниматься привычными делами — это вполне естественно. Однако иногда, несмотря на зонт и другие элементы, дождь все равно проникает в пространство человека. Для специалиста это служит сигналом о том, что привычные защитные механизмы уже не работают, и необходим новый стиль поведения и реагирования на негативные воздействия извне. Существует и другой тип рисунка, когда он изображается в плаще или с зонтом, но при этом нет ни дождя, ни туч. С такой композицией довольно редко сталкивается методика «Человек под дождем». Интерпретация ее сводится к характеристике автора как человека сверхзащищенного, всегда готового к удару. Он вполне успешно преодолевает стресс, но при этом находится в постоянном напряжении. А стоит ли игра свеч? Именно этот вопрос предстоит решить ребенку вместе с психологом.
А стоит ли игра свеч? Именно этот вопрос предстоит решить ребенку вместе с психологом.
Пейзаж
Помимо самого дождя, на рисунках изображены тучи — причина дождя, и лужи — его следствие. Иногда из огромных туч сыплет мелкий дождик. Это значит, что негативные ожидания, страхи автора часто превосходят действительность. Лужи методика «Человек под дождем» интерпретирует как чрезмерную чувствительность ребенка, способность долго переживать по поводу неприятных факторов, «носить в себе осадок».
Однако встречаются и позитивные образы (например, радуга, проглядывающее солнце, цветы). Как правило, они указывают на ресурсы, способствующие благоприятной психологической адаптации. Негативные же символы, напротив, усугубляют стрессовую ситуацию и требуют вмешательства специалиста.
Эмоциональный фон рисунка (позитивный или негативный) строится из совокупности его параметров. Если фигура человека под дождем активна, нарисованы сопутствующие положительные символы, то у ребенка вполне достаточно личных ресурсов, чтобы противостоять стрессу. Если в рисунке доминируют негативные параметры, то ребенку предлагают устно составить рассказ к изображению. А уже из него можно получить информацию о возможностях противостоять неблагоприятным факторам.
Если в рисунке доминируют негативные параметры, то ребенку предлагают устно составить рассказ к изображению. А уже из него можно получить информацию о возможностях противостоять неблагоприятным факторам.
Психологический комментарий
Проективная методика «Человек под дождем» — это занимательный и удивительно точный способ собрать необходимую информацию об эмоциональном состоянии ребенка, его потребностях, безопасности, защитных механизмах при стрессовых ситуациях. А также она способна показать уровень потребности в самоуважении, самореализации и личностном самосовершенствовании. Для психологов результаты рисуночного теста определяют степень работы над стилем детского поведения, реагирования на стресс. При выявлении проблем и психологических барьеров специалисты должны заняться корректным формированием осмысленного отношения ребенка к неблагоприятным воздействиям, понимания их причин и следствий.
Методика «Человек под дождем» для дошкольников — это уникальная возможность предугадать и предупредить психологические проблемы, подготовить детей к возможным ситуациям, тем самым сгладить резкие и негативные реакции.
Наблюдения
Наибольший интерес вызывают рисунки детей, которые воспитываются в интернатах. Ведь каждый из них уже имеет за плечами огромный багаж переживаний (развод или смерть родителей, их алкоголизм и лишение родительских прав и т. п.). Как правило, изображаемые фигуры беззащитны перед дождем, что является символической проекцией. Деформированное изображение, невозможность разобрать пол и возраст персонажа, нечеткость линий указывают на то, что травматические ситуации не позволяют быть устойчивым к воздействиям, меняют восприятие мира ребенка и образ его «Я».
(PDF) Анализ задач как краеугольный метод анализа надежности человека
Ссылки
1. Forester, J., Dang, VN, Bye, A., Lois, E., Massaiu, S., Broberg, H., Брааруд, П. Ø., Скучно,
Р., Мяннистё, И., Ляо, Х., Джулиус, Дж., Парри, Г., и Нельсон, П .: The International HRA Em-
, финальное исследование пирика. Отчет: уроки, извлеченные из сравнения прогнозов методов HRA с данными симулятора
HAMMLAB. HPR-373 / NUREG-2127, Проект реактора Халдена ОЭСР,
HPR-373 / NUREG-2127, Проект реактора Халдена ОЭСР,
2013.
2. Ляо, Х., Форестер, Дж., Данг, В. Н., Бай, А., Лоис, Э. и Чанг, Дж .: Уроки, извлеченные из эмпирического исследования
US HRA. В: PSAM 12 Вероятностная оценка и управление безопасностью,
Гавайи, 22-27 июня 2014 г.
3. Тейлор, Ч .: Улучшение анализа сценариев для HRA. В: PSAM 12 Вероятностная оценка безопасности —
сессия и управление, Гавайи, 22-27 июня 2014 г.
4. Скучно, Р .: Сколько факторов, влияющих на производительность, необходимо для обеспечения надежности человека
Анализ? В: PSAM 10 Probabilistic Safety Assessment and Management, Seattle, Wash-
ington, 7-11 июня 2010 г.
5. Оксстранд, Дж., Келли, Д. Л., Шен, С., Мосле, А., и Грот, К. М .: Модельно-ориентированный подход
к HRA: Методология качественного анализа. В: 11-я Международная конференция по вероятностной безопасности
по оценке и управлению и ESREL 2012, Хельсинки, Финляндия, 25–29 июня,
2012.
6. Ле Бот, П .: Данные о надежности человека, модели человеческих ошибок и аварий — Иллюстрация
Анализ происшествий на Три-Майл-Айленд.В области проектирования и системы надежности
Безопасность, № 83, 153 — 157, 2004.
7. NUREG-1921: EPRI / NRC-RES Руководство по анализу надежности персонала при пожаре, окончательный отчет.
Номер отчета EPRI 1023001, Исследовательский институт электроэнергии, Калифорния, июль 2012 г.
8. Парри, GW, Forester, JA, Dang, VN, Hendrikson, SML, Presley, M., Lois, E. &
Xing , Дж .: IDHEAS — новый подход к анализу надежности человека. В: PSA 2013 Inter-
, национальное тематическое совещание по вероятностной оценке и анализу безопасности, Колумбия, Южная
Каролина, 22-26 сентября 2013 г.
9. Бай, А., Лауман, К., Тейлор, К., Расмуссен, М., Эйе, С., ван де Мерве, К., Эйен, К., Бор-
, Р., Paltrinieri, N., Wæro, I., Massaiu, S. & Gould, K .: Petro-HRA, Новый метод анализа надежности человека
в нефтяной промышленности. В: PSAM 13 Вероятностная безопасность
Оценка и управление. Сеул, Корея, 2–7 октября 2016 г.
10. Тейлор, К .: Как HRA может способствовать совершенствованию предприятий. В: ESREL 2015 25-я конференция
Европейской ассоциации безопасности и надежности, Цюрих, Швейцария, 7-10 сентября 2015 г.
11. Тейлор, К .: Важность участия оператора в анализе надежности человека. В: PSA 2015
Международное тематическое совещание по вероятностной оценке безопасности, Сан-Вэлли, Айдахо, 26-30
апреля 2015 года.
12. Кирван, Б.: Руководство по практической оценке надежности человека. Тейлор и Фрэнсис, Лондон,
,, Дон, 1994.
,. 13. Кирван, Б. и Эйнсворт, Л.К .: Руководство по анализу задач. Тейлор и Фрэнсис, Лондон,
1992.
14. Скучно, Р. Л.: Библиотека задач для нефтяных приложений в анализе надежности человека.
В: PSAM 13 Вероятностная оценка и управление безопасностью. Сеул, Корея, 2-7 октября
2016.
Простой метод выделения геномной ДНК из образцов человека для анализа ПЦР-ПДРФ
Реферат
Выделение ДНК из крови и буккальных мазков в достаточных количествах является неотъемлемой частью судебно-медицинские исследования и анализ. Настоящее исследование было проведено для определения качества и количества ДНК, выделенной из четырех общедоступных образцов, и для оценки продолжительности последующей амплификации ПЦР.Здесь мы демонстрируем, что образцы волос и мочи также могут стать альтернативным источником для надежного получения небольшого количества готовой к ПЦР ДНК. Мы разработали быстрый, экономичный и неинвазивный метод сбора образцов и простого выделения ДНК из буккальных мазков, мочи и волос с использованием фенол-хлороформного метода. Буккальные образцы подвергали экстракции ДНК сразу или после охлаждения (4–6 ° C) в течение 3 дней. Чистоту и концентрацию экстрагированной ДНК определяли спектрофотометрически, а адекватность экстрактов ДНК для анализа на основе ПЦР оценивали путем амплификации участка митохондриальной D-петли размером 1030 п.н.Хотя ДНК из всех образцов подходила для ПЦР, образцы крови и волос предоставили ДНК хорошего качества для рестрикционного анализа продукта ПЦР по сравнению с образцами буккального мазка и образцами мочи. В настоящем исследовании образцы волос оказались хорошим источником геномной ДНК для методов, основанных на ПЦР. Следовательно, ДНК образцов волос может также использоваться для анализа геномных нарушений в дополнение к судебно-медицинскому анализу в результате простоты сбора образцов неинвазивным способом, меньших требований к объему образца и хорошей способности к хранению.
Ключевые слова: митохондриальный, быстродействующий, рестрикционный фермент
ВВЕДЕНИЕ
Недавние достижения в области геномных заболеваний потребовали сбора больших количеств ДНК хорошего качества, которые необходимо получить из различных источников образцов. Типирование ДНК в настоящее время является наиболее проверенным методом личной идентификации пятен физиологических жидкостей человека, обнаруженных на местах преступлений. В широком спектре генетических исследований обычно используется метод получения геномной ДНК из ядерных клеток периферической крови; в результате инвазивности этого подхода может быть трудно получить образцы от субъектов исследования. 1 , 2 Схемы изоляции были утомительными, и общее время анализа также было довольно долгим. Другие альтернативные источники выделения ДНК включают буккальные клетки, волосы с фолликулами и мочу, которые легче получить неинвазивным способом, чем инвазивным сбором крови. 2 Забор клеток в букке можно легко выполнить с помощью буккального тампона с ватным тампоном или с помощью процедуры полоскания рта. 3 Выделение ДНК с использованием буккальных мазков дает много преимуществ, таких как экономичная обработка, меньший объем образца, долгосрочное архивирование и возможность самостоятельного сбора.Это более комфортно для пациента, и буккальные мазки обеспечивают достаточное количество ДНК для ПЦР, поскольку для них требуется всего несколько нанограмм ДНК. 3
Человеческий волос является одним из наиболее распространенных биологических материалов, связанных с юридическими расследованиями, и использовался для статистической работы с населением и анализа ДНК в криминологии. 4 Самый ценный метод тестирования ДНК — это анализ ядерной ДНК с короткими тандемными повторами. 5 Это возможно, когда присутствует корневая часть волоса и / или прилипшая ткань.Однако телогеновые волосы (выпавшие волосы), часто связанные с местом преступления, могут не содержать каких-либо ядерных материалов. 5 Клеточные митохондрии и митохондриальная ДНК (мтДНК) все еще остаются нетронутыми, 5 , 6 , в то время как ядро разлагается по мере затвердевания стержня волоса во время кератинизации, и анализ мтДНК возможен из кератинизированных волос. К сожалению, богатая белком природа образцов волос требует дополнительных шагов для разрушения стержня и высвобождения ДНК (например, фрагментация с помощью микроскопической шлифовальной машины для стекла с последующей экстракцией органическим растворителем) 7 — 9 , таким образом подвергая образец повышенному риску загрязнения.Судебно-медицинское исследование пятен мочи человека имеет большое значение при установлении точного места совершения преступления и типа смерти. 10 Человеческая моча является подходящим образцом для токсикологического анализа в тестах на допинг и скрининг наркотиков. 11
Однако из-за практических трудностей и методологических причин важно оптимизировать условия, чтобы максимизировать выход и чистоту ДНК, полученной из разных типов образцов с использованием различных методов.Упрощенный метод, продемонстрированный в настоящем исследовании, для извлечения ДНК из стержней волос, который сокращает количество ненужных шагов, практически исключает контаминацию ДНК, а также существенно экономит время анализа, что было бы полезно для судебно-медицинского сообщества, а также для Сообщество популяционных исследований. Кроме того, требование меньшего объема выборки в сочетании с отбором образцов неинвазивным способом позволяет осуществлять отбор проб у детей, что легко проявляется в более широком привлечении к исследованию в тематических исследованиях на популяционной основе.Кроме того, можно предусмотреть разработку этого упрощенного метода, поскольку он может применяться в качестве медицинского диагностического инструмента с анализом ДНК, который может быть выполнен в достаточно короткие сроки (~ 8 часов) для выявления болезненных состояний, которые в настоящее время используются в диагностической области медицины. страстно желает.
МАТЕРИАЛЫ И МЕТОДЫ
Сбор и обработка образцов
В текущем исследовании было набрано пять здоровых взрослых добровольцев (возрастной диапазон 22–35 лет) и предоставлена демографическая информация, включая возраст, состояние здоровья, пол, происхождение населения, волосы цвета и обработки волос.Набранных добровольцев попросили прополоскать рот водопроводной водой за 30 секунд до взятия проб из буккальных мазков, чтобы избежать заражения частицами пищи. Для каждого человека обе стороны слизистой оболочки щеки протирали ватным тампоном в течение 15 с, и в общей сложности было собрано пять образцов в 500 мкл 10 М трис-HCl, 10 мМ ЭДТА, 2% SDS, содержащих 1,5-мл микроцентрифужные пробирки. . Было выполнено выделение ДНК из ватных тампонов (см. Ниже).
Образцы волос (по три волоска каждый) от пяти испытуемых были промыты путем погружения их в пресную воду для удаления поверхностной грязи и других загрязнений.Образцы волос отбирали чистыми пинцетами, промывали 500 мкл 70% этанола в 1,5-мл микроцентрифужной пробирке и затем хранили в пробирке, содержащей стерильную деионизированную воду. Образцы волос были дополнительно исследованы под увеличительным стеклом для удаления любых жидкостей организма, если они есть. Волосы срезали на 5–10 мм от проксимального (корневого) конца для переваривания.
Все набранные добровольцы были полностью проинформированы об исследовании и получили соответствующие инструкции по сбору мочи. Образцы мочи собирали в стерильные флаконы для образцов и осторожно переворачивали в течение не менее 30 мин перед обработкой.Чтобы избежать контаминации в результате повторного отбора проб и изучить влияние хранения на целостность пробы, образцы каждой пробы мочи были дополнительно помещены на аликвоты (5 мл) в соответствующие контейнеры. PBS (500 мкл) добавляли в 1 мл образца мочи, содержащую 2-мл микроцентрифужную пробирку с 0,5 М ЭДТА (pH 8,0), до конечной концентрации 10 мМ ЭДТА для ингибирования любой возможной нуклеазной активности в образце мочи. Затем пробирки тщательно встряхивали в течение 1 мин. Растворы мочи использовали сразу или заморозили (-20 ° C).
Образцы крови были получены от тех же доноров путем прокалывания пальцами стерильных ланцетов в асептических условиях и помещены в микроцентрифужную пробирку, промытую ЭДТА. Образцы крови (50 мкл) обрабатывали свежими и служили эталоном для выделения ДНК субъектов.
Экстракция ДНК из буккальных мазков
Образцы буккальных мазков суспендировали в 500 мкл лизирующего буфера [10 мМ Трис (pH 8,0), 10 мМ ЭДТА и 2,0% SDS] и 50 мкл 10% SDS, а затем 5– Добавляли 10 мкл 20 мг / мл протеиназы K (Himedia, Mumbai, India).Образцы инкубировали 1–3 ч при 56 ° C до полного растворения ткани. Затем ДНК экстрагировали из каждого образца равным объемом раствора фенол: хлороформ: изоамиловый спирт (25: 24: 1) и осторожно перемешивали, переворачивая пробирки в течение 3 минут. Затем образцы центрифугировали (Eppendorf 5415R; Гамбург, Германия) в течение 10 минут с 10000 г (4 ° C), и верхний водный слой переносили в свежую стерилизованную микроцентрифужную пробирку. Добавляли РНКазу A (10 мкл 10 мг / мл; Fermentas, Thermo Scientific, Германия) и раствор инкубировали при 37 ° C в течение 30 мин.Добавляли равные объемы раствора хлороформ: изоамиловый спирт и центрифугировали (Eppendorf 5415R) снова с 10 000 г (4 ° C) в течение 10 мин. Верхний водный слой переносили в стерилизованную микроцентрифужную пробирку и добавляли удвоенный объем охлажденного изопропанола (Merck, Whitehouse Station, Нью-Джерси, США) вместе с одной десятой объема 3 М ацетата натрия и охлаждали при -20 °. C в течение 1 ч для осадков. Через 1 час образец центрифугировали (Eppendorf 5415R) при 10000 g (4 ° C) в течение 10 минут.После декантации супернатанта добавляли 250 мкл 70% этанола (Merck) и осадок растворяли; смесь центрифугировали при 10000 об / мин в течение 10 мин, и супернатант осторожно декантировали. Осадок сушили на воздухе в ламинарном потоке воздуха, и высушенный осадок ресуспендировали в 50 мкл воды, свободной от нуклеаз, или 1 × 10 мМ Трис-HCl, 1 мМ EDTA, pH 7,6 (TE), буфер и замораживали при -20 °. C или при −80 ° C для хранения.
Экстракция ДНК из образца волос
ДНК выделяли из стержней волос с использованием модифицированных версий микроскопического измельчения стекла и протокола экстракции органическим растворителем. 12–14 Поскольку эти протоколы подвергают образец повышенному риску контаминации, настоящее исследование заменило утомительный метод физического переваривания гладким методом химического расщепления с использованием дитиотреитола (DTT) (Hi-media), поскольку он является сильным восстанавливающим агентом. с относительно высоким содержанием соли, а также анионным моющим средством. Буфер для разложения (500 мкл; 10 мМ Трис-HCl, 10 мМ EDTA, 50 мМ NaCl, 20% SDS, pH 7,5) добавляли в 1,5-мл микроцентрифужную пробирку вместе с 40 мкл 1 M DTT (до конечной концентрации ~ 80 мМ, 240 мМ ацетата натрия, pH 5.2) и 15 мкл 10 мг / мл протеиназы К (до конечной концентрации ∼0,3 мг / мл; Himedia). К этому раствору добавляли образец волос перед встряхиванием и инкубацией в течение 2 ч при 56 ° C. После 2 ч инкубации пробирку с образцом снова встряхивали и добавляли дополнительно 40 мкл 1 M DTT и 15 мкл 10 мг / мл протеиназы K с последующим осторожным перемешиванием и инкубацией при 60 ° C еще 2 часа или до полного растворения волос.
Затем ДНК экстрагировали из каждого образца равным объемом раствора фенол: хлороформ: изоамиловый спирт (25: 24: 1) и осторожно перемешивали, переворачивая пробирку в течение нескольких минут.Образцы центрифугировали (Eppendorf 5415R) в течение 10 минут с 10000 g (4 ° C) с последующим переносом верхнего водного слоя в свежую стерилизованную микроцентрифужную пробирку. Добавляли РНКазу A (10 мкл 10 мг / мл; Fermentas, Thermo Scientific) и выдерживали для инкубации при 37 ° C в течение 30 мин. Добавляли равный объем хлороформ: изоамиловый спирт и снова центрифугировали пробирку (Eppendorf 5415R) при 10000 g (4 ° C) в течение 10 мин. Верхний водный слой переносили в свежую стерилизованную микроцентрифужную пробирку перед добавлением двойного объема охлажденного изопропанола и одной десятой объема 3 М ацетата натрия.Образец охлаждали при -20 ° C в течение 1 ч для осаждения ДНК. Образец центрифугировали (Eppendorf 5415R) при 10000 g (4 ° C) в течение 10 мин. Супернатант отбрасывали, добавляли 250 мкл 70% этанола и осадок осторожно удаляли перед дальнейшим центрифугированием (Eppendorf 5415R) при 10000 об / мин в течение 10 мин. Супернатант отбрасывали, осадок сушили на воздухе в ламинарном потоке воздуха, ресуспендировали в 50 мкл воды, свободной от нуклеаз, или в 1 × TE-буфере и замораживали при -20 ° C или -80 ° C для хранения.
Экстракция ДНК из образца мочи
Замороженные образцы мочи размораживали при комнатной температуре, а затем сразу же помещали на лед перед выделением ДНК. Образец мочи переворачивали или вращали в чашке для образцов для создания гомогенной суспензии клеток. Один миллилитр образца переносили в пробирку Эппендорфа и центрифугировали (Eppendorf 5415R) в течение 10 минут при 10000 g (4 ° C). Супернатант удаляли, и сухой осадок, содержащий клетки, охлаждали при -20 ° C в течение 15 минут.Буфер для лизиса (500 мкл; 10 мМ Трис, 1,2 мМ EDTA, 10% SDS, pH 9,0) добавляли к сухому осадку, и образец встряхивали для ресуспендирования осадка. Добавляли протеиназу K (20 мкл 20 мг / мл; Himedia) и инкубировали пробирку на водяной бане (CW-30G; Jeio Tech, Сеул, Корея) при 56 ° C в течение 2 часов. Добавляли ацетат натрия (60 мкл 3 М) и 0,5 мл холодного изопропанола, смешивали и охлаждали при -20 ° C в течение 1 часа с последующим центрифугированием при 10000 g (при 4 ° C) в течение 20 минут. Супернатант отбрасывали, добавляли 250 мкл 70% этанола и осторожно отбирали осадок с последующим центрифугированием при 10000 об / мин в течение 10 мин, после чего супернатант аккуратно удаляли.Осадок сушили на воздухе в ламинарном потоке воздуха, и высушенный осадок ресуспендировали в 50 мкл воды, свободной от нуклеаз, или в 1 × TE-буфере и замораживали при -20 ° C или -80 ° C для хранения.
Экстракция ДНК из образца крови
Лимфоциты из цельной крови были отделены лизированием красных кровяных телец (эритроцитов) с использованием гипотонического буфера (бикарбонат аммония и хлорид аммония; Himedia) с минимальным лизирующим действием на лимфоциты. Три объема буфера для лизиса эритроцитов добавляли к образцу крови и перемешивали путем встряхивания и тщательного переворачивания в течение 5 минут и центрифугировали (Eppendorf 5415R) при 20,00 g в течение 10 минут.Супернатант в основном сливали, оставляя около 1 мл, чтобы предотвратить потерю клеток. К осадку добавляли 3 объема буфера для лизиса эритроцитов, и этапы встряхивания, переворачивания и центрифугирования повторяли два-три раза до получения прозрачного супернатанта и чистого белого осадка. После последней промывки супернатант полностью сливали, а осадок ресуспендировали в 500 мкл PBS с последующим добавлением 400 мкл буфера для лизиса клеток (10 мМ трис-HCl, 10 мМ EDTA, 50 мМ NaCl, 10% SDS, pH 7.5) и 10 мкл протеиназы К (исходный раствор 10 мг / мл; Himedia).Образец встряхивали для полного растворения осадка и инкубировали в течение 2 ч при 56 ° C на водяной бане (CW-30G; Jeio Tech) для лизиса. Затем в пробирку добавляли равный объем фенола (уравновешенного Трис, pH 8) и хорошо перемешивали путем переворачивания в течение 1 мин. Пробирку центрифугировали при 10000 g (при 4 ° C) в течение 10 мин, и верхний водный слой переносили в свежую пробирку, содержащую равные объемы (1: 1) фенола и хлороформа: изоамилового спирта (24: 1). . Пробирку перемешивали переворачиванием в течение 1 мин и центрифугировали в течение 10 мин при 10000 g (при 4 ° C).Затем супернатант переносили в свежую пробирку и добавляли 10 мкл 10 мг / мл РНКазы A (Fermentas, Thermo Scientific).
Образец инкубировали при 37 ° C в течение 30 минут, затем добавляли равный объем хлороформа: изоамиловый спирт (24: 1) и перемешивали путем переворачивания пробирки в течение 1 минуты и центрифугирования при 10000 g (при 4 ° C ) в течение 10 мин. Супернатант переносили в свежую пробирку, добавляли удвоенный объем абсолютного спирта (Merck), осторожно переворачивали несколько раз и охлаждали при -20 ° C с последующим центрифугированием при 10000 г при (4 ° C) в течение 20 мин.Супернатант отбрасывали, добавляли 250 мкл 70% этанола, осадок осторожно удаляли с последующим центрифугированием при 10000 об / мин в течение 10 мин и осторожным декантированием супернатанта. Осадок сушили на воздухе в ламинарном потоке воздуха, и высушенный осадок ресуспендировали в 50 мкл воды, свободной от нуклеаз, или в 1 × TE-буфере и замораживали при -20 ° C или -80 ° C для хранения.
Определение концентрации и чистоты
Количественный спектрофотометрический анализ ДНК проводили с использованием спектрофотометра Cary 60 UV-visible (Agilent Technologies, Санта-Клара, Калифорния, США).Поглощение измеряли на длинах волн 260 и 280 (A 260 и A 280 , соответственно) нм. Коэффициент поглощения (OD 260 / OD 280 ) обеспечивает оценку чистоты ДНК. Значение коэффициента поглощения 1,8 <отношение (R) <2,0 считалось хорошей очищенной ДНК. Отношение <1,8 указывает на загрязнение белком, а соотношение> 2,0 указывает на загрязнение РНК.
Целостность ДНК
Целостность геномной ДНК проверяли путем разделения экстрактов ДНК на 0.8% агарозный гель с помощью электрофореза (Bio-Rad, Геркулес, Калифорния, США) с последующей визуализацией окрашиванием бромистым этидием. Каждый образец ДНК оценивали в соответствии с электрофоретической миграцией образца ДНК по сравнению с известным маркером молекулярной массы (Fermentas, Thermo Scientific).
ПЦР-амплификация области D-петли мтДНК для анализов на основе ПЦР
Адекватность экстрактов ДНК буккального канала, волос, мочи и крови для анализов на основе ПЦР оценивалась путем амплификации участка D-петли мтДНК, который был амплифицирован с помощью ПЦР с использованием праймеров митохондрий человека (HMt) -F (5′-CACCATTAGCACCCAAAGCT-3 ‘) и HMt-R (5′-CTGTTAAAAGTGCATACCGCCA-3’), как описано Salas et al. 12 для региона HVI. ПЦР (vapo.protect; Eppendorf) проводили в 25 мкл общих реакционных объемов, каждый из которых содержал 100 нг матричной ДНК, 0,2 пМ каждого праймера, 2,5 мкл 10-кратного буфера для ПЦР (последний 1-кратный буфер для ПЦР), 1,5 мМ MgCl 2 , 200 мМ dNTP и 1 единица ДНК-полимеразы Taq. Реакционную смесь нагревали до 94 ° C в течение 5 минут, после чего следовали 40 циклов, каждый из которых состоял из 1 мин денатурации при 94 ° C, 1 мин отжига при 63 ° C, 1,5 мин удлинения при 72 ° C и заключительного 10- мин. удлинение при 72 ° C.Продукты амплификации ПЦР (10 мкл) подвергали электрофорезу (Bio-Rad) в 1,2% агарозном геле в 1 × буфере трис-ацетат-ЭДТА при 80 В в течение 30 мин и окрашивали бромидом этидия (Himedia), при этом были получены изображения. в документации по гелевым системам (G-Box; Syngene, Кембридж, Великобритания).
Рестрикционное расщепление области D-петли мтДНК Продукт ПЦР
Полиморфизм длины рестрикционных фрагментов (ПДРФ) области D-петли мтДНК выполняли для проверки загрязнения выделенной ДНК. 13 ПЦР-продукты расщепляли Hae III и Alu I (Fermentas, Thermo Scientific) в общем объеме 20 мкл (10 мкл реакционных растворов, 2 мкл ферментных буферов, 0,2 мкл ферментов и 7,8 мкл). дистиллированная вода) и помещают в инкубатор при 37 ° C на 4 ч. Продукты рестрикции анализировали электрофорезом (Bio-Rad) на 2% агарозном геле, а молекулярную массу ограниченных фрагментов анализировали с помощью систем гель-документации (G-Box; Syngene) после окрашивания бромидом этидия (Himedia).
РЕЗУЛЬТАТЫ
В настоящем исследовании мы продемонстрировали быстрый, надежный и надежный метод получения готовой к ПЦР геномной ДНК из буккальных мазков, волос и мочи человека, требующий очень малого объема образца с временем выделения / амплификации, равным по крайней мере в два раза короче по сравнению с традиционными методами. Кровь использовали в качестве эталонного образца для выделения ДНК. Изменяя традиционный метод фенол-хлороформ, мы также успешно разработали и продемонстрировали надежный протокол, который является быстрым, экономичным и легко реализуемым для выделения ДНК с оптимальной концентрацией и чистотой.
Выход и чистота
Выход экстрагированной ДНК из четырех различных источников образцов оценивали с использованием двухлучевого спектрофотометра в УФ-видимой области и гель-электрофореза (). Мелкомасштабная экстракция ДНК из буккальных мазков (из 1 мл) привела к выделению 60–85 нг / мкл геномной ДНК / выделению, 49–72 нг / мкл в волосах (из четырех частей), 25–42 нг / мкл в моче (из четырех частей). 5 мл) и 57–94 нг / мкл в образцах крови (от 50 мкл) (). Точно так же чистота экстрагированной ДНК из мочи (1,42–1.58) и буккальных мазков (1,54–1,67) было ниже, чем образцов крови (1,76–1,86) и волос (1,72–1,97) (). Хранение экстрагированной ДНК из мочи, волос, крови и буккальных мазков в течение более 1 месяца, замороженных при -20 ° C, не влияло на эффективность ПЦР.
Изолированная геномная мтДНК из образцов крови, буккального мазка, волос и мочи (R1 — R5: пять отдельных повторов).
Таблица 1
Общий выход и качество ДНК при немедленной обработке биологических образцов или при хранении
| Спектрофотометрия | |||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Биологический образец | Немедленная обработка | ||||||||||||||||||||||||||||||||||||
| Обработка при хранении | Общий выход | A 260 : A 280 | Общий выход ДНК (нг / мкл) | A 260 : A 280 | |||||||||||||||||||||||||||||||||
| R1 | |||||||||||||||||||||||||||||||||||||
| R2 | R3 | R4 | R5 | R1 | R2 | R3 | R4 | R5 | R1 | R2 | R3 | R4 | 902 902 903R5 | ||||||||||||||||||||||||
| Образец крови | 86 | 74 | 92 | 57 | 94 | 1.82 | 1.86 | 1.77 | 1.82 | 1.76 | 79 | 91 | 83 | 82 | 71 | 1.89 | 1.65 | 1.81 1.84 | 83 | 62 | 85 | 60 | 65 | 1,57 | 1,62 | 1,54 | 1,67 | 1,62 | 55 | 51 | 58 | 42 | 4762 | 1,67 | 1,62 | 1,83 | 1,75 |
| Образец волос | 49 | 62 | 68 | 57 | 72 | 1,72 | 1,82 | 1,82 9035 | 1.50 Обработка образцов на целостность ДНК Наблюдали разную интенсивность полос для экстрагированной ДНК из только что собранных и / или сохраненных образцов. Не было деградации ДНК, выделенной сразу после взятия проб мочи и буккального канала.Однако выделение ДНК из хранимых буккальных мазков и образцов мочи показало полосы с некоторой степенью деградации ДНК (полосы низкой интенсивности) и сопутствующее смазывание дорожек. Однако для волос и образцов крови хранение замораживанием (-20 ° C или -80 ° C) не повлияло на целостность экстрагированной ДНК (). Влияние обработки образца на ПЦР-RFLPЧтобы проверить качество выделенной ДНК в небольшом масштабе из буккальных мазков, волос, мочи и образцов крови, мы амплифицировали область D-петли мтДНК с помощью анализа ПЦР.Область D-петли мтДНК была успешно амплифицирована из всех образцов, независимо от статуса образца, независимо от того, обрабатывались ли они сразу после сбора или сохранялись (). Таким образом, моча, буккальный мазок и волосы являются хорошим альтернативным источником в дополнение к образцу крови, когда требуется геномная ДНК, готовая к ПЦР. Однако наблюдается значительный разброс выхода, а также качества или чистоты между типами образцов. Следовательно, надежная реакция ПЦР может быть проведена с использованием даже гораздо меньшего количества изолированной ДНК.Интенсивность продукта ПЦР была выше для ДНК-матрицы крови и волос, чем для образцов мочи и буккальных мазков. Образцы полос ПЦР-ПДРФ были хорошими в случае ДНК волос и крови, но образцы мочи и буккальных мазков не показали удовлетворительной интенсивности полос. Однако среди выделенных образцов ДНК не было обнаруживаемого загрязнения, так как все переваренные образцы были одинаковой длины (и). ПЦР-амплификация области D-петли мтДНК. M — маркер, BL — ДНК крови, H — ДНК волос, BS — ДНК буккального мазка, U — ДНК мочи. Рестрикционное переваривание продукта ПЦР области D-петли мтДНК с помощью AluI. M — маркер, BS — ДНК буккального мазка, U — ДНК мочи, H — ДНК волос, BL — ДНК крови. Рестрикционное переваривание продукта ПЦР области D-петли мтДНК с помощью HaeIII. M — маркер, BS — ДНК буккального мазка, U — ДНК мочи, H — ДНК волос, BL — ДНК крови. ОБСУЖДЕНИЕВыходы ДНК, полученные из буккальных мазков и мочи, сильно меняются в зависимости от мазка или типа мочи, индивидуума, метода мазка и количества клеток, захваченных тампоном и в моче. 6 , 11 Ожидаемый результат при использовании этого протокола составляет 60–85 нг / мкл / тампон, а для мочи — сбор 25–45 нг / мкл / 15 мл (), что, по крайней мере, составляет на два выше по сравнению с обычными методами. Выход и чистота выделенной ДНК также зависят от методов работы исследователей. Снижение качества и количества ДНК наблюдали, когда материал не помещали сразу в буфер для лизиса клеток для дальнейшей обработки. Разрушение полос ДНК наблюдали в буккальных мазках и образцах мочи, обработанных с задержкой по времени, тогда как разложение в образцах крови и волос не наблюдается, вероятно, в результате природы образца и степени концентрации фермента нуклеазы в образце. перед перевариванием.Хотя в образцах, хранившихся при низких температурах в течение 3 дней, наблюдалась определенная степень деградации ДНК, настоящее исследование не выявило каких-либо значительных различий между экстрагированными продуктами ПЦР-амплификации ДНК из буккальных клеток сразу после сбора образца или из буккальных клеток. заморозить 3 дня при −20 ° C. Более того, 1 неделя хранения при охлаждении при 4 ° C или замораживании при -20 ° C также не влияла на выход экстрагированной ДНК или ПЦР-амплификацию ДНК. В случае образцов волос и крови можно получить ДНК высокого качества для последующего использования, даже после хранения образца волос в этаноле более 2 месяцев и образца крови во флаконе с покрытием EDTA более 4 месяцев. при -20 ° С. В целом, для исследований по типированию ДНК свежая цельная кровь или окрашенный кровью материал является основным источником «отпечатка пальца» ДНК человека и используется в качестве стандарта для сравнения. Представленные здесь результаты позволили нам продемонстрировать использование буккальных мазков и мочи в качестве альтернативных источников для экстракции ДНК. Однако существует заметная разница между образцами мочи мужчин и женщин в отношении количества доступной ДНК; поскольку в большинстве случаев информация о поле отсутствует, когда моча собирается с места преступления, 10 ее всегда следует собирать с самых крупных пятен мочи, которые доступны.Большой объем слюны и мочи можно собрать неинвазивным способом без какой-либо боли. Фактически, мазок со слизистой оболочки рта и моча были легко получены с минимальными усилиями для подробного анализа даже у младенца. 14 Мы также можем амплифицировать вирусные и бактериальные гены из ДНК мочи и буккальных мазков для исследования присутствия или отсутствия каких-либо патогенов с помощью описанного анализа ПЦР. Изолированная ДНК из всех образцов дает продукты ПЦР с аналогичным размером пары оснований целевого митохондриального гена.Однако в случае рестрикционного переваривания продукты ПЦР для волос и крови давали превосходные перевариваемые продукты. Это может быть результатом наличия хорошей концентрации продуктов амплификации ПЦР и отсутствия каких-либо примесей в образце ПЦР, а не в образцах мочи и буккальных мазков, которые не были должным образом переварены рестрикционным ферментом. Следовательно, мы можем использовать образцы волос вместо образцов крови для молекулярного анализа на основе ПЦР-ПДРФ. Существует вероятность того, что низкие уровни примесей, которые могут присутствовать в ДНК, выделенной из сыворотки или плазмы, гораздо менее распространены, чем те, которые присутствуют в образцах мочи и буккальных мазков. 15 В этих методах количество загрязняющих веществ меньше, поэтому вероятность вмешательства загрязняющих веществ во время процесса ПЦР очень мала. Harty et al. 16 сообщили, что амплификация ПЦР была успешной после длительного хранения образцов, даже несмотря на то, что хранение снизило выход ДНК. В настоящем исследовании выделенная ДНК из всех образцов, хранящихся в замороженном виде при -20 ° C, была пригодна для дальнейшего использования. ДНК, выделенная из образца мочи, который хранился более 1 месяца в замороженном состоянии при -20 ° C, показала себя так же хорошо, как и образец свежей мочи.Хотя ДНК в образце мочи, кажется, со временем разлагается, образец мочи, хранящийся до 3 месяцев в замороженном виде при -20 ° C, все же можно использовать для ПЦР-амплификации. Изолированная ДНК из волос и крови очень хороша на основе стабильности ДНК для хранения, замороженной при -20 ° C для дальнейшего анализа. ЗаключениеУспешный сбор образцов и извлечение геномной ДНК из буккальных мазков, мочи и волос являются неинвазивными и надежными альтернативами колючему инвазивному забору крови как для субъектов, так и для сборщиков образцов. 17 — 20 Мы продемонстрировали здесь простой и новый метод сбора образцов и экстракции ДНК, который является экономичным, легким и быстрым, обеспечивая достаточное количество и качество ДНК для Анализ на основе ПЦР-ПДРФ. Сравнение процедур экстракции показывает, что простой фенол-хлороформный метод является наиболее подходящим для экстракции ДНК из буккальных мазков, мочи, волос и образцов крови. При соответствующих условиях хранения ДНК, выделенная из буккальных клеток, мочи и волос, может быть успешно использована для проведения анализов на основе ПЦР.Метод экстракции мтДНК из раствора анионного детергента с высоким содержанием соли DTT, разработанный в этом исследовании, представляет собой быстрый и простой протокол, который превосходит по показателям успешности амплификации мтДНК стандартные методы измельчения стекла / экстракции органическим растворителем, которые в настоящее время используются во многих судебно-медицинских лабораториях. Относительно меньшее количество шагов, используемых в этом методе, сокращает время и, кроме того, приводит к значительному снижению вероятности загрязнения с минимальной потерей пробы. В методе химического разложения DTT используются реагенты, расходные материалы и оборудование, доступные в любой базовой лаборатории.Его простота поможет в анализе мтДНК в тех лабораториях, которым еще предстоит провести судебно-медицинское тестирование мтДНК, а также в популяционных исследованиях с использованием образцов волос. Однако еще предстоит изучить важные вопросы, касающиеся выхода и качества ДНК человека, которую можно получить с помощью различных методов экстракции ДНК. Что вам нужно знатьЕсли вы получаете огромные объемы неструктурированных данных в виде текста (электронные письма, разговоры в социальных сетях, чаты), вы, вероятно, знаете о проблемах, которые возникают при анализе этих данных. Ручная обработка и систематизация текстовых данных требует времени, утомительна, неточна и может быть дорогостоящей, если вам нужно нанять дополнительный персонал для сортировки текста. Автоматизация анализа текста с помощью инструмента без кода В этом руководстве вы узнаете больше о том, что такое анализ текста, как выполнять анализ текста с помощью инструментов искусственного интеллекта, и почему как никогда важно автоматически анализировать текст в реальном времени. время.
Что такое анализ текста?Анализ текста (TA) — это метод машинного обучения, используемый для автоматического извлечения ценной информации из неструктурированных текстовых данных.Компании используют инструменты анализа текста, чтобы быстро обрабатывать онлайн-данные и документы и превращать их в полезные идеи. Вы можете использовать анализ текста для извлечения конкретной информации, такой как ключевые слова, имена или сведения о компании, из тысяч электронных писем или категоризировать ответы на опросы по настроениям и темам. Анализ текста, анализ текста и анализ текстаВо-первых, давайте развеем миф о том, что анализ текста и анализ текста — это два разных процесса.Эти термины часто используются как синонимы для объяснения одного и того же процесса получения данных посредством изучения статистических паттернов. Во избежание путаницы остановимся на анализе текста. Итак, анализ текста vs. анализ текста : в чем разница? Анализ текста дает качественные результаты, а анализ текста дает количественные результаты. Если компьютер выполняет анализ текста, он определяет важную информацию в самом тексте, но если он выполняет анализ текста, он выявляет закономерности в тысячах текстов, в результате чего создаются графики, отчеты, таблицы и т. Д. Допустим, менеджер службы поддержки клиентов хочет знать, сколько обращений в службу поддержки было обработано отдельными членами команды. В этом случае они использовали бы текстовую аналитику, чтобы создать график, который визуализирует частоту разрешения отдельных заявок. Однако вполне вероятно, что менеджер также хочет знать, какая доля заявок привела к положительному или отрицательному результату? Анализируя текст в каждом тикете и последующих обменах, менеджеры службы поддержки могут видеть, как каждый агент обрабатывал тикеты и довольны ли клиенты результатом. По сути, задача текстового анализа — расшифровать двусмысленность человеческого языка, а в текстовой аналитике — выявить закономерности и тенденции на основе численных результатов. Почему важен анализ текста?Когда вы заставляете машины работать над организацией и анализом ваших текстовых данных, вы получаете огромные выводы и выгоды. Давайте рассмотрим некоторые преимущества анализа текста, ниже: Масштабируемость анализа текстаИнструменты анализа текста позволяют предприятиям структурировать огромные объемы информации, например электронные письма, чаты, социальные сети, заявки в службу поддержки, документы и т. Д. и так далее, в считанные секунды, а не дни, чтобы вы могли перенаправить дополнительные ресурсы на более важные бизнес-задачи. Анализируйте текст в режиме реального времениКомпании завалены информацией, и в наши дни комментарии клиентов могут появляться где угодно в Интернете, но может быть трудно следить за всем этим. Текстовый анализ меняет правила игры, когда дело доходит до выявления неотложных вопросов, где бы они ни появлялись, 24 часа в сутки, 7 дней в неделю и в режиме реального времени. Обучая модели анализа текста для выявления выражений и настроений, которые подразумевают негативность или срочность, компании могут автоматически отмечать твиты, обзоры, видео, билеты и тому подобное и принимать меры раньше, чем позже. Анализ текста AI обеспечивает согласованные критерииЛюди делают ошибки. Факт. И чем более утомительной и трудоемкой является задача, тем больше ошибок она делает. Обучая модели анализа текста в соответствии с вашими потребностями и критериями, алгоритмы могут анализировать, понимать и сортировать данные гораздо точнее, чем когда-либо могли бы люди. Методы и методы анализа текстаСуществуют базовые и более сложные методы анализа текста, каждый из которых используется для разных целей.Во-первых, узнайте о более простых методах анализа текста и примерах, когда вы можете использовать каждый из них. Классификация текстаКлассификация текста — это процесс присвоения предварительно определенных тегов или категорий неструктурированному тексту. Он считается одним из самых полезных методов обработки естественного языка, потому что он настолько универсален и может организовывать, структурировать и категоризировать практически любую форму текста для предоставления значимых данных и решения проблем. Обработка естественного языка (NLP) — это метод машинного обучения, который позволяет компьютерам разбирать текст и понимать его так же, как это сделал бы человек. Ниже мы сосредоточимся на некоторых из наиболее распространенных задач классификации текста, которые включают анализ тональности, моделирование темы, определение языка и обнаружение намерений. Анализ настроенийКлиенты свободно оставляют свое мнение о компаниях и продуктах во время взаимодействия с клиентами, в опросах и по всему Интернету. Анализ настроений использует мощные алгоритмы машинного обучения для автоматического считывания и классификации по полярности мнений (положительное, отрицательное, нейтральное) и за ее пределами, чувствам и эмоциям писателя, даже контексту и сарказму. Например, с помощью анализа настроений компании могут отмечать жалобы или срочные запросы, чтобы с ними можно было немедленно разобраться — даже во избежание PR-кризиса в социальных сетях. Классификаторы настроений могут оценивать репутацию бренда, проводить исследования рынка и помогать улучшать продукты с учетом отзывов клиентов. Попробуйте предварительно обученный классификатор MonkeyLearn. Просто введите свой текст, чтобы увидеть, как это работает:
Тест с собственным текстомМне нравится новое обновление. Это супер быстро! Классифицируйте текстАнализ темыДругой распространенный пример классификации текста — анализ темы (или моделирование темы), который автоматически организует текст по теме или теме.Например: «Приложение действительно простое и легкое в использовании» Если мы используем тематические категории, такие как Цены, Поддержка клиентов, и Простота использования, этот отзыв о продукте будет отнесен к Простота использования . Попробуйте предварительно обученный тематический классификатор MonkeyLearn, который можно использовать для категоризации ответов NPS для продуктов SaaS. Обнаружение намеренияКлассификаторы текста также могут использоваться для обнаружения намерения текста.Обнаружение намерений или классификация намерений часто используются для автоматического понимания причины обратной связи с клиентами. Это жалоба? Или клиент пишет с намерением купить продукт? Машинное обучение может читать разговоры или электронные письма чат-бота и автоматически направлять их в соответствующий отдел или сотрудника. Попробуйте классификатор намерений электронной почты MonkeyLearn. Извлечение текста — еще один широко используемый метод анализа текста, который извлекает фрагменты данных, которые уже существуют в любом заданном тексте.Вы можете извлекать такие вещи, как ключевые слова, цены, названия компаний и спецификации продуктов из новостных отчетов, обзоров продуктов и т. Д. Вы можете автоматически заполнять таблицы этими данными или выполнять извлечение совместно с другими методами анализа текста, чтобы одновременно классифицировать и извлекать данные. Ключевые слова — это наиболее часто используемые и наиболее релевантные термины в тексте, слова и фразы, которые обобщают содержание текста. [Извлечение ключевых слов] (] (https: // monkeylearn.com / keyword-extract /) можно использовать для индексации данных для поиска и для создания облаков слов (визуального представления текстовых данных). Попробуйте предварительно обученный экстрактор ключевых слов MonkeyLearn, чтобы увидеть, как он работает. Просто введите свой текст ниже:
Тест с вашим собственным текстомИлон Маск поделился фотографией скафандра, разработанного SpaceX. Это второе изображение нового дизайна и первое, на котором изображен скафандр в полный рост. Извлечь текстEntity RecognitionИзвлечение именованных сущностей (NER) находит сущности, которые могут быть людьми, компаниями или местоположениями. и существуют в текстовых данных.Результаты отображаются с соответствующей меткой объекта, как в предварительно обученном экстракторе имен MonkeyLearn:
Тест с вашим собственным текстомSpaceX — производитель аэрокосмической продукции и компания, предоставляющая услуги космического транспорта, со штаб-квартирой в Калифорнии. Он был основан в 2002 году предпринимателем и инвестором Илоном Маском с целью снижения затрат на космические перевозки и обеспечения возможности колонизации Марса. Выдержка текстаЧастота словЧастота слов — это метод анализа текста, который измеряет наиболее часто встречающиеся слова или понятия. в заданном тексте с использованием числовой статистики TF-IDF (термин «частота-обратная частота документа»). Вы можете применить этот метод для анализа слов или выражений, которые клиенты чаще всего используют в разговорах в службу поддержки. Например, если слово «доставка» чаще всего встречается в наборе отрицательных обращений в службу поддержки, это может означать, что клиенты недовольны вашей службой доставки. CollocationCollocation помогает определить слова, которые часто встречаются вместе. Например, в отзывах клиентов на веб-сайте бронирования отелей слова «воздух» и «кондиционирование» чаще встречаются вместе, чем по отдельности.Биграммы (два соседних слова, например, «кондиционер» или «поддержка клиентов») и триграммы (три соседних слова, например, «вне офиса» или «продолжение следует») являются наиболее распространенными типами словосочетания, на которые вам нужно обратить внимание. . Совместное размещение может быть полезно для выявления скрытых семантических структур и повышения детализации выводов путем подсчета биграмм и триграмм как одного слова. ConcordanceConcordance помогает идентифицировать контекст и экземпляры слов или набор слов.Например, ниже приводится соответствие слова «простой» в наборе обзоров приложений: В этом случае соответствие слова «простой» может дать нам быстрое представление о том, как рецензенты используют это слово. Его также можно использовать для декодирования неоднозначности человеческого языка до определенной степени, глядя на то, как слова используются в разных контекстах, а также для анализа более сложных фраз. Устранение неоднозначности смысла словаОчень часто слово имеет несколько значений, поэтому устранение неоднозначности смысла слова является серьезной проблемой при обработке естественного языка.Возьмем, к примеру, слово «свет». Относится ли текст к весу, цвету или электрическому прибору? Интеллектуальный анализ текста с устранением неоднозначности слов может различать слова, которые имеют более одного значения, но только после обучения моделей этому. КластеризацияТекстовые кластеры способны понимать и группировать большие объемы неструктурированных данных. Хотя алгоритмы кластеризации менее точны, чем алгоритмы классификации, их можно реализовать быстрее, потому что вам не нужно помечать примеры для обучения моделей.Это означает, что эти умные алгоритмы собирают информацию и делают прогнозы без использования обучающих данных, что также называется неконтролируемым машинным обучением. Google — отличный пример того, как работает кластеризация. Когда вы ищете термин в Google, вы когда-нибудь задумывались, как всего за секунды появляются релевантные результаты? Алгоритм Google разбивает неструктурированные данные с веб-страниц и группирует страницы в кластеры вокруг набора похожих слов или n-граммов (всех возможных комбинаций соседних слов или букв в тексте).Таким образом, страницы из кластера, которые содержат большее количество слов или n-граммов, релевантных поисковому запросу, появятся первыми в результатах. Как работает анализ текста?Чтобы действительно понять, как работает автоматический анализ текста, вам необходимо понять основы машинного обучения. Начнем с определения из «Машинного обучения» Тома Митчелла: «Считается, что компьютерная программа учится выполнять задачу T на основе опыта E». Другими словами, если мы хотим, чтобы программное обеспечение для анализа текста выполняло желаемые задачи, нам необходимо научить алгоритмы машинного обучения тому, как анализировать, понимать и извлекать значение из текста.Но как? Простой ответ — пометить примеры текста. Как только машина получает достаточно примеров помеченного текста для работы, алгоритмы могут начать различать и создавать ассоциации между частями текста, а также сами делать прогнозы. Это очень похоже на то, как люди учатся различать темы, предметы и эмоции. Допустим, у нас есть срочные и не приоритетные проблемы. Мы не осознаем разницу между ними инстинктивно — мы учимся постепенно, ассоциируя срочность с определенными выражениями. Например, когда мы хотим выявить срочные проблемы, мы обращаем внимание на такие выражения, как «пожалуйста, помогите мне как можно скорее!» или «срочно: нельзя зайти на платформу, система ВЫКЛЮЧЕНА !!» . С другой стороны, чтобы выявить проблемы с низким приоритетом, мы будем искать более положительные выражения, такие как «спасибо за помощь!» Действительно цените его « или », новая функция работает как мечта ». Как анализировать текстовые данныеАнализ текста может расширить свои ИИ-крылья по диапазону текстов в зависимости от желаемых результатов.Его можно применить к:
Когда вы знаете, как вы хотите разбить данные, вы можете приступить к их анализу. Давайте посмотрим, как работает анализ текста, шаг за шагом, и более подробно рассмотрим различные доступные алгоритмы и методы машинного обучения. Сбор данныхВы можете собирать данные о своем бренде, продукте или услуге как из внутренних, так и из внешних источников: Внутренние данныеЭто данные, которые вы генерируете каждый день, от электронных писем и чатов до опросов, запросов клиентов, и билеты в службу поддержки клиентов. Вам просто нужно экспортировать его из своего программного обеспечения или платформы в виде файла CSV или Excel или подключить API, чтобы получить его напрямую. Некоторые примеры внутренних данных:
Внешние данныеЭто текстовые данные о вашем бренде или товарах со всего Интернета. Вы можете использовать инструменты веб-парсинга, API-интерфейсы и открытые наборы данных для сбора внешних данных из социальных сетей, новостных отчетов, онлайн-обзоров, форумов и т. Д. И анализа их с помощью моделей машинного обучения. Инструменты для парсинга веб-страниц:
API-интерфейсыFacebook, Twitter и Instagram, например, имеют свои собственные API-интерфейсы и позволяют извлекать данные с их платформ.Основные средства массовой информации, такие как New York Times или The Guardian, также имеют свои собственные API-интерфейсы, и вы можете использовать их, среди прочего, для поиска в их архиве или сбора комментариев пользователей. ИнтеграцииИнструменты SaaS, такие как MonkeyLearn, предлагают интеграцию с инструментами, которые вы уже используете. Вы можете напрямую подключаться к Twitter, Google Sheets, Gmail, Zendesk, SurveyMonkey, Rapidminer и другим. И выполните текстовый анализ данных Excel, загрузив файл. 2. Подготовка данныхЧтобы автоматически анализировать текст с помощью машинного обучения, вам необходимо организовать свои данные.Большая часть этого делается автоматически, и вы даже не заметите этого. Однако важно понимать, что автоматический анализ текста использует ряд методов обработки естественного языка (НЛП), как показано ниже. Токенизация, тегирование части речи и анализТокенизация — это процесс разбиения строки символов на семантически значимые части, которые могут быть проанализированы (например, слова), с отбрасыванием бессмысленных фрагментов (например, пробелов). В примерах ниже показаны два различных способа токенизации строки «Анализировать текст не так сложно» . (Неверно): анализировать текст не так сложно. = [«Analyz», «ing text», «is n», «ot that», «hard».] (правильно): Анализировать текст не так сложно. = [«Анализируем», «текст», «есть», «нет», «это», «сложно», «.»] После того, как токены были распознаны, пора классифицировать их . Маркировка части речи относится к процессу присвоения грамматической категории, такой как существительное, глагол и т. Д., Для обнаруженных токенов. Вот теги PoS токенов из вышеприведенного предложения: «Анализ»: ГЛАГОЛ, «текст»: СУЩЕСТВИТЕЛЬНОЕ, «есть»: ГЛАГОЛ, «не»: ADV, «тот»: ADV, «жесткий». : ADJ, «.”: PUNCT Со всеми категоризированными токенами и языковой моделью (т. Е. Грамматикой) система теперь может создавать более сложные представления текстов, которые она будет анализировать. Этот процесс известен как синтаксический анализ . Другими словами, синтаксический анализ относится к процессу определения синтаксической структуры текста. Для этого алгоритм синтаксического анализа использует грамматику языка, на котором был написан текст. Разные представления будут результатом синтаксического анализа одного и того же текста с разными грамматиками. В приведенных ниже примерах показаны зависимости и представления контингента предложения «Анализировать текст не так сложно» . Анализ зависимостейГрамматики зависимостей можно определить как грамматики, которые устанавливают направленные отношения между словами предложений. Анализ зависимостей — это процесс использования грамматики зависимостей для определения синтаксической структуры предложения: Анализ постоянных группГрамматики структуры фраз постоянных групп моделируют синтаксические структуры, используя абстрактные узлы, связанные со словами и другими абстрактными категориями (в зависимости от тип грамматики) и неориентированные отношения между ними. Анализ группы интересов относится к процессу использования грамматики группы интересов для определения синтаксической структуры предложения: Как вы можете видеть на изображениях выше, выходные данные алгоритмов синтаксического анализа содержат большой объем информации, которая может помочь вам понять синтаксическая (и отчасти семантическая) сложность текста, который вы собираетесь анализировать. В зависимости от решаемой проблемы вы можете попробовать разные стратегии и методы синтаксического анализа. Однако в настоящее время синтаксический анализ зависимостей превосходит другие подходы. Лемматизация и стеммингСтемминг и лемматизация относятся к процессу удаления всех аффиксов (т. Е. Суффиксов, префиксов и т. Д.), Прикрепленных к слову, для сохранения его лексической основы, также известной как корень или ствол или его словарная форма или le mma . Основное различие между этими двумя процессами состоит в том, что , основание обычно основано на правилах, которые обрезают начало и окончание слов (и иногда приводят к несколько странным результатам), тогда как лемматизация использует словари и гораздо более сложный морфологический анализ. В таблице ниже показаны результаты работы NLTK Snowball Stemmer и лемматизатора Spacy для токенов в предложении «Анализировать текст не так сложно» . Различия в выводе выделены жирным шрифтом: Удаление стоп-словаЧтобы обеспечить более точный автоматический анализ текста, нам нужно удалить слова, которые предоставляют очень мало семантической информации или вообще не имеют смысла. Эти слова также известны как стоп-слов: а, и, или, и т. Д. Для каждого языка существует множество различных списков стоп-слов.Однако важно понимать, что вам может потребоваться добавить слова или удалить слова из этих списков в зависимости от текстов, которые вы хотите проанализировать, и анализа, который вы хотите выполнить. Возможно, вы захотите провести какой-то лексический анализ области, из которой происходят ваши тексты, чтобы определить слова, которые следует добавить в список запрещенных слов. Анализируйте свои текстовые данныеТеперь, когда вы узнали, как анализировать неструктурированные текстовые данные и основы подготовки данных, как вы анализируете весь этот текст? Что ж, анализ неструктурированного текста — непростая задача.Существует бесчисленное множество методов анализа текста, но два из них — это классификация текста и извлечение текста. Классификация текстаКлассификация текста (также известная как классификация текста или тегирование текста ) относится к процессу присвоения тегов текстам на основе их содержимого. Раньше классификация текста выполнялась вручную, что было трудоемким, неэффективным и неточным. Но модели автоматизированного машинного обучения для анализа текста часто работают всего за секунды с непревзойденной точностью. К наиболее популярным задачам классификации текста относятся анализ тональности (то есть определение того, когда в тексте говорится что-то положительное или отрицательное о данной теме), определение темы (то есть определение того, о каких темах говорится в тексте) и обнаружение намерения (то есть определение цели или основной смысл текста), среди прочего, но существует гораздо больше приложений, которые могут вас заинтересовать. шаблон, который можно найти в тексте и теге.Правила обычно состоят из ссылок на морфологические, лексические или синтаксические шаблоны, но они также могут содержать ссылки на другие компоненты языка, такие как семантика или фонология. Вот пример простого правила классификации описаний продуктов по типу продукта, описанному в тексте: (HDD | RAM | SSD | Memory) → Hardware В этом случае система назначит Hardware tag к тем текстам, которые содержат слова HDD , RAM , SSD или Memory . Наиболее очевидным преимуществом систем, основанных на правилах, является то, что они легко понятны людям. Однако создание сложных систем, основанных на правилах, требует много времени и хороших знаний как в лингвистике, так и в тематике текстов, которые система должна анализировать. Кроме того, системы, основанные на правилах, сложно масштабировать и поддерживать, потому что добавление новых правил или изменение существующих требует большого анализа и тестирования влияния этих изменений на результаты прогнозов. Системы на основе машинного обученияСистемы на основе машинного обучения могут делать прогнозы на основе того, что они узнают из прошлых наблюдений. В эти системы необходимо добавить несколько примеров текстов и ожидаемых прогнозов (тегов) для каждого из них. Это называется обучающими данными . Чем более согласованными и точными будут ваши данные о тренировках, тем точнее будут окончательные прогнозы. При обучении классификатора на основе машинного обучения данные обучения необходимо преобразовать во что-то, что может понять машина, то есть в вектора (т.е. списки чисел, которые кодируют информацию). Используя векторы, система может извлекать соответствующие функции (фрагменты информации), которые помогут ей извлекать уроки из существующих данных и делать прогнозы относительно будущих текстов. Есть несколько способов сделать это, но один из наиболее часто используемых — это пакет слов, векторизация . Вы можете узнать больше о векторизации здесь. После преобразования текстов в векторы они загружаются в алгоритм машинного обучения вместе с ожидаемыми результатами для создания модели классификации, которая может выбирать, какие функции лучше всего представляют тексты, и делать прогнозы относительно невидимых текстов: Обученная модель преобразует невидимый текст в вектор, извлекает его соответствующие характеристики и делает прогноз: Алгоритмы машинного обученияСуществует множество алгоритмов машинного обучения, используемых при классификации текста.Наиболее часто используются семейство алгоритмов Naive Bayes (NB), , машины опорных векторов (SVM) и алгоритмы глубокого обучения. Наивное семейство алгоритмов Байеса основано на теореме Байеса и условных вероятностях появления слов образца текста в словах набора текстов, принадлежащих данному тегу. Векторы, представляющие тексты, кодируют информацию о том, насколько вероятно, что слова в тексте встретятся в текстах данного тега.С помощью этой информации можно вычислить вероятность принадлежности текста любому заданному тегу в модели. После того, как все вероятности были вычислены для входного текста, модель классификации вернет тег с наибольшей вероятностью в качестве выходных данных для этого входного текста. Одним из основных преимуществ этого алгоритма является то, что результаты могут быть довольно хорошими даже при небольшом количестве обучающих данных. Машины опорных векторов (SVM) — это алгоритм, который может разделить векторное пространство помеченных текстов на два подпространства: одно пространство, которое содержит большую часть векторов, принадлежащих данному тегу, и другое подпространство, которое содержит большинство векторов, которые не являются принадлежат этому одному тегу. Классификационные модели, использующие SVM в своей основе, будут преобразовывать тексты в векторы и определять, к какой стороне границы, разделяющей векторное пространство для данного тега, принадлежат эти векторы. В зависимости от того, где они приземляются, модель будет знать, принадлежат ли они данному тегу или нет. Самым важным преимуществом использования SVM является то, что результаты обычно лучше, чем результаты, полученные с помощью наивного байесовского метода. Однако для SVM требуется больше вычислительных ресурсов. Глубокое обучение — это набор алгоритмов и методов, которые используют «искусственные нейронные сети» для обработки данных во многом так же, как это делает человеческий мозг.Эти алгоритмы используют огромные объемы обучающих данных (миллионы примеров) для создания семантически богатых представлений текстов, которые затем могут быть введены в модели на основе машинного обучения различного типа, которые будут делать гораздо более точные прогнозы, чем традиционные модели машинного обучения: Гибрид СистемыГибридные системы обычно содержат в своей основе системы на основе машинного обучения и системы на основе правил для улучшения прогнозов ОценкаПроизводительность классификатора обычно оценивается с помощью стандартных показателей, используемых в области машинного обучения: точность , точность , отзывают и F1 балл .Понимание того, что они означают, даст вам более четкое представление о том, насколько хороши ваши классификаторы при анализе ваших текстов. Также важно понимать, что оценка может выполняться на фиксированном тестовом наборе (т. Е. Наборе текстов, для которого нам известны ожидаемые выходные теги) или с помощью перекрестной проверки (т. Е. Метода, который разделяет ваши обучающие данные в разные сгибы, чтобы вы могли использовать некоторые подмножества своих данных для целей обучения, а некоторые — для целей тестирования, см. ниже). Оценка точности, точности, отзыва и F1Точность — это количество правильных прогнозов, сделанных классификатором, деленное на общее количество прогнозов. В общем, точность сама по себе не является хорошим показателем производительности. Например, когда категории несбалансированы, то есть когда есть одна категория, которая содержит намного больше примеров, чем все другие, прогнозирование всех текстов как принадлежащих этой категории вернет высокий уровень точности. Это известно как парадокс точности.Чтобы получить лучшее представление о производительности классификатора, вы можете вместо этого рассмотреть вопрос о точности и отзыве. Точность указывает, сколько текстов было предсказано правильно из тех, которые были предсказаны как принадлежащие данному тегу. Другими словами, точность берет количество текстов, которые были правильно предсказаны как положительные для данного тега, и делит его на количество текстов, которые были предсказаны (правильно и неправильно) как принадлежащие этому тегу. Мы должны помнить, что точность дает информацию только в тех случаях, когда классификатор предсказывает, что текст принадлежит данному тегу.Это может быть особенно важно, например, если вы хотите генерировать автоматические ответы на пользовательские сообщения. В этом случае, прежде чем отправлять автоматический ответ, вы хотите знать наверняка, что отправите правильный ответ, верно? Другими словами, если ваш классификатор говорит, что сообщение пользователя принадлежит определенному типу сообщения, вы хотите, чтобы классификатор сделал правильное предположение. Это означает, что вам нужна высокая точность для этого типа сообщения. Напомним, что указывает, сколько текстов было предсказано правильно из тех, которые должны были быть предсказаны как принадлежащие данному тегу.Другими словами, функция отзыва берет количество текстов, которые были правильно предсказаны как положительные для данного тега, и делит его на количество текстов, которые были либо правильно предсказаны как принадлежащие тегу, либо которые были неправильно предсказаны как не принадлежащие тегу. Отзыв может оказаться полезным при маршрутизации заявок в службу поддержки, например, соответствующей группе. Может быть желательно, чтобы автоматизированная система обнаруживала как можно больше заявок для критического тега (например, заявок о «Беспорядки / время простоя» ) за счет выполнения некоторых неверных прогнозов в процессе.В этом случае прогнозирование поможет выполнить начальную маршрутизацию и как можно скорее решить большинство этих критических проблем. Если прогноз неверен, билет будет перенаправлен членом команды. При обработке тысяч заявок в неделю высокий уровень отзыва (конечно же, с хорошим уровнем точности) может сэкономить командам поддержки много времени и позволить им быстрее решать критические проблемы. Оценка F1 — гармоничное средство точности и отзывчивости. Он сообщает вам, насколько хорошо работает ваш классификатор, если одинаковое значение придается точности и отзыву.В целом, оценка F1 является гораздо лучшим показателем эффективности классификатора, чем точность. Перекрестная проверкаПерекрестная проверка довольно часто используется для оценки производительности текстовых классификаторов. Метод прост. Прежде всего, обучающий набор данных случайным образом разбивается на несколько подмножеств одинаковой длины (например, 4 подмножества по 25% исходных данных каждое). Затем все подмножества, кроме одного, используются для обучения классификатора (в данном случае 3 подмножества с 75% исходных данных), и этот классификатор используется для прогнозирования текстов в оставшемся подмножестве.Затем вычисляются все показатели производительности (то есть точность, точность, отзыв, F1 и т. Д.). Наконец, процесс повторяется с новой тестовой складкой до тех пор, пока все складки не будут использованы для целей тестирования. После использования всех складок вычисляются средние показатели производительности и процесс оценки завершается. Извлечение текста относится к процессу распознавания структурированной информации из неструктурированного текста. Например, может быть полезно автоматически определять наиболее релевантные ключевые слова из фрагмента текста, определять названия компаний в новостной статье, обнаруживать арендодателей и арендаторов в финансовом контракте или определять цены в описаниях продуктов. Регулярные выраженияРегулярные выражения (также известные как регулярные выражения) работают как эквивалент правил, определенных в задачах классификации. В этом случае регулярное выражение определяет шаблон символов, который будет связан с тегом. Например, шаблон ниже обнаружит большинство адресов электронной почты в тексте, если им предшествуют и следуют пробелы: (? I) \ b (?: [A-zA-Z0-9 _-.] +) @ ( ?: (?: [[0-9] {1,3}. [0-9] {1,3}. [0-9] {1,3}.) | (?: (?: [A- zA-Z0-9 -] +.) +)) (?: [a-zA-Z] {2,4} | [0-9] {1,3}) (?:]?) \ b Обнаружив это совпадение в текстах и присвоив ему тег email , мы можем создать элементарный инструмент для извлечения адресов электронной почты. У такого подхода есть очевидные плюсы и минусы. С другой стороны, вы можете быстро создавать экстракторы текста и получать хорошие результаты при условии, что вы найдете правильные шаблоны для того типа информации, которую хотите обнаружить. С другой стороны, регулярные выражения могут быть чрезвычайно сложными и их может быть действительно сложно поддерживать и масштабировать, особенно когда требуется много выражений для извлечения желаемых шаблонов. Условные случайные поляУсловные случайные поля (CRF) — это статистический подход, часто используемый при извлечении текста на основе машинного обучения.Этот подход изучает образцы, которые должны быть извлечены, путем взвешивания набора характеристик последовательностей слов, которые появляются в тексте. Используя CRF, мы можем добавить несколько переменных, которые зависят друг от друга, к шаблонам, которые мы используем для обнаружения информации в текстах, такой как синтаксическая или семантическая информация. Это обычно генерирует гораздо более богатые и сложные шаблоны, чем использование регулярных выражений, и потенциально может кодировать гораздо больше информации. Однако для его реализации необходимы дополнительные вычислительные ресурсы, поскольку все функции должны быть рассчитаны для всех рассматриваемых последовательностей, и все веса, присвоенные этим функциям, должны быть изучены до определения, должна ли последовательность принадлежать тегу. или не. Одним из основных преимуществ подхода CRF является его способность к обобщению. После того, как экстрактор был обучен с использованием подхода CRF для текстов определенной области, он будет иметь возможность достаточно хорошо обобщить то, что он изучил, на другие области. Экстракторы иногда оцениваются путем расчета тех же стандартных показателей производительности, которые мы объяснили выше для классификации текста, а именно: точность , точность , отзыв и оценка F1 .Однако эти показатели не учитывают частичное совпадение шаблонов. Чтобы извлеченный сегмент был действительно положительным для тега, он должен идеально совпадать с сегментом, который должен был быть извлечен. Рассмотрим следующий пример: ‘Ваш рейс отправится 14 января 2020 года в 15:30 из SFO’ Если мы создали средство извлечения даты, мы ожидаем, что он вернется 14 января 2020 года в виде дата из текста выше, верно? Итак, если бы вывод экстрактора был 14 января 2020 г., мы бы засчитали его как истинное положительное значение для тега DATE . А что, если бы выход экстрактора был 14 января? Вы бы сказали, что добыча была плохой? Вы бы сказали, что для тега DATE это было ложное срабатывание? Чтобы зафиксировать частичные совпадения, подобные этому, можно использовать некоторые другие показатели производительности для оценки производительности экстракторов. Одним из примеров этого является семейство показателей ROUGE. ROUGE (ориентированный на отзыв дублер для оценки Gisting) — это семейство показателей, используемых в областях машинного перевода и автоматического резюмирования, которые также можно использовать для оценки производительности экстракторов текста.Эти метрики в основном вычисляют длину и количество последовательностей, которые перекрываются между исходным текстом (в данном случае нашим исходным текстом) и переведенным или обобщенным текстом (в данном случае нашим извлечением). В зависимости от длины единиц, перекрытие которых вы хотите сравнить, вы можете определить метрики ROUGE-n (для единиц длины n ) или вы можете определить метрику ROUGE-LCS или ROUGE-L, если вы намереваетесь сравнить самую длинную общую последовательность (LCS). 4. Визуализируйте текстовые данныеТеперь вы знаете множество методов анализа текста для разбивки данных, но что вы делаете с результатами? Инструменты бизнес-аналитики (BI) и визуализации данных позволяют легко понять ваши результаты на поразительных информационных панелях, выявить закономерности, тенденции и незамедлительно дать действенную информацию в общих чертах или мельчайших деталях. Визуализация данных повышает ценность результатов интеллектуального анализа текста за счет преобразования сложных концепций в убедительные и легкие для понимания визуальные эффекты. Все дело в высококачественной аналитической информации, которая приводит к умным бизнес-решениям, основанным на данных! MonkeyLearn Studio — это универсальный инструмент для сбора, анализа и визуализации данных. Методы машинного обучения глубокого обучения позволяют выбрать необходимый анализ текста (извлечение ключевых слов, анализ тональности, классификация аспектов и т. Д.) И объединить их вместе для одновременной работы. Вы сразу поймете важность текстовой аналитики. Просто загрузите свои данные и визуализируйте результаты, чтобы получить ценные сведения. Все это работает вместе в едином интерфейсе, поэтому вам больше не нужно выгружать и скачивать между приложениями. Взгляните на панель управления MonkeyLearn Studio ниже, где мы провели анализ мнений клиентов на основе отзывов клиентов о Zoom. Обзоры сначала организуются по «аспектам» или категориям (удобство использования, поддержка, надежность и т. Д.), Затем каждая категория анализируется по настроениям, чтобы показать полярность мнений. Вы можете видеть, что отдельные обзоры организованы по дате и времени, поэтому вы можете отслеживать аспекты и настроения, поскольку они меняются с течением времени. Представьте, что этот анализ используется для тысяч упоминаний вашего бренда в социальных сетях, в обзорах продуктов или в обращениях в службу поддержки клиентов. Теперь вы можете поиграть с общедоступной информационной панелью MonkeyLearn Studio, чтобы убедиться, насколько легко ею пользоваться. Поиск по индивидуальному настроению, дате, категории и т. Д. Самое лучшее в MonkeyLearn Studio — это то, что вы можете добавлять или удалять анализы, добавлять новые данные и изменять визуализации прямо на панели инструментов. Бесплатный инструмент визуализации Google позволяет создавать интерактивные отчеты с использованием самых разных данных. После того, как вы импортировали данные, вы можете использовать различные инструменты для создания отчета и превратить ваши данные в впечатляющую визуальную историю. Делитесь результатами с отдельными людьми или группами, публикуйте их в Интернете или встраивайте на свой веб-сайт. Looker — это платформа для анализа бизнес-данных, предназначенная для передачи значимых данных любому сотруднику компании. Идея состоит в том, чтобы позволить командам получить более полное представление о том, что происходит в их компании. Вы можете подключаться к различным базам данных и автоматически создавать модели данных, которые можно полностью настроить в соответствии с конкретными потребностями. Взгляните сюда, чтобы начать. Tableau — это инструмент бизнес-аналитики и визуализации данных с интуитивно понятным и удобным для пользователя подходом (не требующий технических навыков). Tableau позволяет организациям работать практически с любым существующим источником данных и предоставляет мощные возможности визуализации с более продвинутыми инструментами для разработчиков. Для всех, кто хочет попробовать, доступна пробная версия.Узнайте, как выполнять анализ текста в Tableau. Приложения и примеры анализа текстаЗнаете ли вы, что 80% бизнес-данных — это текст? Текст присутствует во всех основных бизнес-процессах, от заявок в службу поддержки до отзывов о продуктах и онлайн-взаимодействий с клиентами. Автоматический анализ текста в реальном времени может помочь вам справиться со всеми этими данными с помощью широкого спектра бизнес-приложений и вариантов использования. Повысьте эффективность и сократите повторяющиеся задачи, которые часто имеют большое влияние на текучесть кадров.Лучшее понимание мнения клиентов без необходимости разбирать миллионы сообщений в социальных сетях, онлайн-обзоры и ответы на опросы. Если вы работаете в сфере обслуживания клиентов, продуктов, маркетинга или продаж, существует ряд приложений для анализа текста, которые автоматизируют процессы и позволяют получать реальные сведения. И, что самое главное, для этого вам не понадобится опыт в области науки о данных или инженерии. Мониторинг социальных сетейДопустим, вы работаете в Uber и хотите знать, что пользователи говорят о бренде.Вы читали положительные и отрицательные отзывы в Twitter и Facebook. Но каждый день отправляется 500 миллионов твитов, а Uber ежемесячно получает тысячи упоминаний в социальных сетях. Можете ли вы представить себе анализ всех их вручную? Здесь на помощь приходит анализ тональности, чтобы проанализировать мнение о данном тексте. Анализируя ваши упоминания в социальных сетях с помощью модели анализа настроений, вы можете автоматически классифицировать их на положительных , нейтральных или отрицательных .Затем пропустите их через анализатор тем, чтобы понять тему каждого текста. Запуская аспектно-ориентированный анализ настроений, вы можете автоматически определять причины положительных или отрицательных упоминаний и получать такую информацию, как:
Допустим, вы только что добавили новую услугу в Uber.Например, Uber Eats. Это решающий момент, и ваша компания хочет знать, что люди говорят о Uber Eats, чтобы вы могли как можно скорее исправить любые сбои и усовершенствовать лучшие функции. Вы также можете использовать аспектный анализ настроений в своих профилях в Facebook, Instagram и Twitter для любых упоминаний Uber Eats и обнаружения таких вещей, как:
Вы можете использовать анализ текста не только для отслеживания упоминаний вашего бренда в социальных сетях, но и для отслеживания упоминаний ваших конкурентов.Клиент жалуется на услуги конкурента? Это дает вам возможность привлечь потенциальных клиентов и показать им, насколько лучше ваш бренд. Мониторинг брендаСледите за комментариями о вашем бренде в реальном времени, где бы они ни появлялись (социальные сети, форумы, блоги, сайты обзоров и т. Д.). Вы сразу поймете, когда возникнет что-то негативное, и сможете использовать положительные комментарии в своих интересах. Сила отрицательных отзывов достаточно велика: 40% потребителей откладывают покупку, если у компании есть отрицательные отзывы.Сердитый клиент, жалующийся на плохое обслуживание клиентов, может распространиться как лесной пожар за считанные минуты: друг поделится этим, затем другой, затем еще один… И прежде, чем вы это узнаете, негативные комментарии стали вирусными.
Служба поддержки клиентовНесмотря на опасения и ожидания многих людей, анализ текста не означает, что обслуживание клиентов будет полностью автоматизировано.Это просто означает, что компании могут оптимизировать процессы, чтобы команды могли тратить больше времени на решение проблем, требующих взаимодействия с людьми. Таким образом компании смогут увеличить удержание, учитывая, что 89 процентов клиентов меняют бренды из-за плохого обслуживания клиентов. Но как анализ текста может помочь службе поддержки вашей компании? Маркировка билетовПозвольте машинам делать всю работу за вас. Анализ текста автоматически определяет темы и маркирует каждый тикет. Вот как это работает:
Это происходит автоматически при поступлении нового запроса, освобождая агентов клиентов, чтобы они могли сосредоточиться на более важных задачах. Маршрутизация и сортировка билетов: найдите подходящего человека для работыМашинное обучение может считывать заявку на предмет или срочность и автоматически направлять ее в соответствующий отдел или сотрудника. Например, для SaaS-компании, которая получает билет клиента с просьбой о возмещении, система интеллектуального анализа текста определит, какая команда обычно занимается вопросами выставления счетов, и отправит им билет. Если в билете написано что-то вроде «Как мне интегрировать ваш API с python?» , он пойдет прямо к команде, отвечающей за помощь в интеграции. Аналитика билетов: узнавайте больше от своих клиентовЧто обычно оценивается для определения эффективности работы группы обслуживания клиентов? Общие KPI: время первого отклика , среднее время до разрешения (т.е.е. сколько времени требуется вашей команде для решения проблем) и удовлетворенность клиентов (CSAT). И, давайте посмотрим правде в глаза, общая удовлетворенность клиентов во многом зависит от первых двух показателей. Но как мы можем получить актуальную информацию CSAT из разговоров с клиентами? Как мы можем определить, доволен ли клиент способ решения проблемы? Или если они выразили разочарование по поводу решения проблемы? В этой ситуации можно использовать анализ тональности на основе аспектов. Этот тип анализа текста исследует чувства и темы, стоящие за словами по различным каналам поддержки, таким как заявки в службу поддержки, разговоры в чате, электронные письма и опросы CSAT.Модель анализа текста может понимать слова или выражения, чтобы определить взаимодействие со службой поддержки как Положительное , Отрицательное или Нейтральное , понимать, что было упомянуто (например, Service или UI / UX ), и даже определять настроения за словами (например, Печаль , Гнев и т. д.). Обнаружение срочности: уделите приоритетное внимание обращению срочно«С чего начать?» — это вопрос, который часто задают себе представители службы поддержки клиентов.Срочность, безусловно, хорошая отправная точка, но как определить уровень срочности, не тратя драгоценное время на размышления? Программное обеспечение для интеллектуального анализа текста может определять уровень срочности заявки клиента и соответствующим образом маркировать ее. Тикеты поддержки со словами и выражениями, обозначающими срочность, например «как можно скорее» или «сразу же» , должным образом помечены как Priority . Чтобы увидеть, как анализ текста работает для определения срочности, ознакомьтесь с этой демонстрационной моделью обнаружения срочности MonkeyLearn. Голос клиента (VoC) и отзывы клиентовКогда вы получаете клиента, удержание становится ключевым моментом, поскольку привлечение новых клиентов обходится в 5-25 раз дороже, чем удержание уже имеющихся. Вот почему пристальное внимание к голосу клиента может дать вашей компании четкое представление об уровне удовлетворенности клиентов и, как следствие, их удержании. Кроме того, это может дать вам полезную информацию, чтобы расставить приоритеты в дорожной карте продукта с точки зрения клиента. Анализ ответов NPSВозможно, у вашего бренда уже есть опрос об удовлетворенности клиентов, наиболее распространенным из которых является Net Promoter Score (NPS). В этом опросе задается вопрос: «Насколько вероятно, что вы порекомендуете [бренд] другу или коллеге?» . Ответ — оценка от 0 до 10, и результат делится на три группы: промоутера , пассивных и недоброжелателей . Но здесь наступает сложный момент: в конце есть открытый вопрос с ответом. «Почему вы выбрали Х-балл?» Ответ может дать вашей компании бесценную информацию.Без текста вам остается только догадываться, что пошло не так. А теперь, благодаря анализу текста, вам больше не нужно вручную читать эти открытые ответы. Вы можете делать то же, что и Promoter.io: извлекать основные ключевые слова из отзывов клиентов, чтобы понять, что хвалят или критикуют в вашем продукте. Упоминается ли ключевое слово «продукт» в основном промоутерами или недоброжелателями? Обладая этой информацией, вы сможете использовать свое время, чтобы получить максимальную отдачу от ответов NPS и начать действовать. Другой вариант — следовать по стопам Retently, используя текстовый анализ для классификации ваших отзывов по различным темам, таким как Поддержка клиентов, Дизайн продукта, и Характеристики продукта, затем проанализируйте каждый тег с анализом настроений, чтобы увидеть, насколько положительно или отрицательно клиенты чувствовать по каждой теме. Теперь они знают, что они на правильном пути с дизайном продукта, но им еще нужно работать над функциями продукта. Анализ опросов клиентовЕсть ли у вашей компании другая система опросов клиентов? Если это система баллов или закрытые вопросы, проанализировать ответы будет несложно: просто вычислите числа. Однако, если у вас есть опрос с открытым текстом, независимо от того, предоставляется ли он по электронной почте или в виде онлайн-формы, вы можете отказаться от ручной пометки каждого отдельного ответа, позволив анализу текста сделать эту работу за вас. Помимо экономии времени, вы также можете иметь согласованные критерии маркировки без ошибок, 24/7. Business IntelligenceАнализ данных лежит в основе каждой операции бизнес-аналитики. Итак, что может сделать компания, чтобы понять, например, тенденции продаж и показатели с течением времени? С помощью числовых данных команда бизнес-аналитики может определить, что происходит (например, продажи X снижаются), но не , почему .Цифры легко анализировать, но они также несколько ограничены. С другой стороны, текстовые данные являются наиболее распространенным форматом деловой информации и могут предоставить вашей организации ценное представление о ваших операциях. Анализ текста с помощью машинного обучения может автоматически анализировать эти данные для немедленного анализа. Например, вы можете запустить извлечение ключевых слов и анализ настроений в ваших упоминаниях в социальных сетях, чтобы понять, на что люди жалуются на ваш бренд. Вы также можете запустить анализ настроений на основе аспектов для отзывов клиентов, в которых упоминается плохое качество обслуживания клиентов. В конце концов, 67% потребителей называют плохой клиентский опыт одной из основных причин ухода. Может быть, это плохая поддержка, неисправная функция, неожиданный простой или внезапное изменение цены. Анализ отзывов клиентов может пролить свет на детали, и команда сможет принять соответствующие меры. А как же ваши конкуренты? Что говорят их обзоры? Пропустите их через свою модель анализа текста и посмотрите, что они делают правильно, а что неправильно, и улучшите ваше собственное принятие решений. Продажи и маркетингПоисковые закупки — самая сложная часть процесса продаж. И становится все труднее и труднее. Отдел продаж всегда хочет заключать сделки, что требует повышения эффективности процесса продаж. Но 27% торговых агентов тратят более часа в день на ввод данных вместо продажи, что означает, что критическое время теряется на административную работу, а не на закрытие сделок. Анализ текста упрощает выполнение ручных задач по продажам, в том числе:
GlassDollar, компания, которая связывает учредителей с потенциальными инвесторами, использует текстовый анализ для поиска наиболее качественных совпадений. Как? Они используют текстовый анализ для классификации компаний по их описаниям. Результаты, достижения? Они сэкономили дни ручной работы, и прогнозы были точными на 90% после обучения модели классификации текста.Вы можете узнать больше об их опыте работы с MonkeyLearn здесь. Анализ текста может не только автоматизировать ручные и утомительные задачи, но также может улучшить вашу аналитику, чтобы сделать воронки продаж и маркетинга более эффективными. Например, вы можете автоматически анализировать ответы на ваши электронные письма и разговоры о продажах, чтобы понять, скажем, падение продаж:
А теперь представьте, что цель вашего отдела продаж — нацелиться на новый сегмент вашего SaaS: людей старше 40 лет.Первое впечатление — товар им не нравится, но почему ? Просто отфильтруйте разговоры о продажах этой возрастной группы и запустите их в своей модели анализа текста. Команды продаж могут принимать более обоснованные решения, используя углубленный текстовый анализ разговоров с клиентами. Наконец, вы можете использовать машинное обучение и анализ текста, чтобы улучшить общий процесс продаж. Например, Drift, маркетинговая платформа для общения, интегрировала MonkeyLearn API, чтобы позволить получателям автоматически отказываться от коммерческих писем в зависимости от того, как они отвечают. Пора увеличить продажи и перестать тратить драгоценное время на потенциальных клиентов, которые никуда не денутся. Компания Xeneta, занимающаяся морскими перевозками, разработала алгоритм машинного обучения и обучила его определять, какие компании являются потенциальными клиентами, на основе описаний компаний, собранных через FullContact (SaaS-компания, имеющая описания миллионов компаний). Вы можете сделать то же самое или настроить таргетинг на пользователей, которые посещают ваш веб-сайт, для:
Product AnalyticsПредставим, что у вашего стартапа есть приложение в магазине Google Play. Вы получаете несколько необычно негативных комментариев.В чем дело? Вы можете узнать, что происходит за считанные минуты, используя модель анализа текста, которая группирует обзоры по различным тегам, таким как Ease of Use и Integrations. Затем запустите их с помощью модели анализа настроений, чтобы выяснить, положительно или отрицательно отзываются о товарах клиенты. Наконец, с помощью MonkeyLearn Studio можно создавать графики и отчеты для визуализации и определения приоритетов проблем продукта. Мы сделали это с помощью обзоров Slack с сайта обзора продуктов Capterra и получили довольно интересные выводы.Вот как это сделать:
Ресурсы для анализа текстаСуществует ряд ценных ресурсов, которые помогут вам начать работу со всем, что может предложить анализ текста. API анализа текстаВы можете использовать библиотеки с открытым исходным кодом или API SaaS для создания решения для анализа текста, которое соответствует вашим потребностям. Библиотеки с открытым исходным кодом требуют много времени и технических ноу-хау, в то время как инструменты SaaS часто могут быть запущены сразу же и практически не требуют опыта программирования. Библиотеки с открытым исходным кодомPythonPython — наиболее широко используемый язык в научных вычислениях, точка. Такие инструменты, как NumPy и SciPy, сделали его быстрым, динамичным языком, который вызывает библиотеки C и Fortran там, где требуется производительность. Эти вещи в сочетании с процветающим сообществом и разнообразным набором библиотек для реализации моделей обработки естественного языка (NLP) сделали Python одним из наиболее предпочтительных языков программирования для анализа текста. NLTKNLTK, набор инструментов для естественного языка, является лучшей в своем классе библиотекой для задач анализа текста. NLTK используется во многих университетских курсах, поэтому на нем написано много кода, и нет недостатка в пользователях, знакомых как с библиотекой, так и с теорией NLP, которые могут помочь ответить на ваши вопросы. SpaCySpaCy — это промышленная статистическая библиотека НЛП. Помимо обычных функций, он добавляет интеграцию с глубоким обучением и модели сверточных нейронных сетей для нескольких языков. В отличие от NLTK, которая является исследовательской библиотекой, SpaCy стремится быть проверенной на практике производственной библиотекой для анализа текста. Scikit-learnScikit-learn — это полный и зрелый набор инструментов для машинного обучения для Python, построенный на основе NumPy, SciPy и matplotlib, что дает ему отличную производительность и гибкость для построения моделей анализа текста. TensorFlowРазработанная Google, TensorFlow на сегодняшний день является наиболее широко используемой библиотекой для распределенного глубокого обучения. Глядя на этот график, мы видим, что TensorFlow опережает конкурентов: PyTorchPyTorch — это платформа глубокого обучения, созданная Facebook и специально предназначенная для глубокого обучения. PyTorch — это библиотека, ориентированная на Python, которая позволяет вам определять большую часть архитектуры вашей нейронной сети в терминах кода Python и только внутренне имеет дело с низкоуровневым высокопроизводительным кодом. KerasKeras — широко используемая библиотека глубокого обучения, написанная на Python. Он разработан для обеспечения быстрых итераций и экспериментов с глубокими нейронными сетями, и как библиотека Python он уникально удобен для пользователя. Важной особенностью Keras является то, что он предоставляет, по сути, абстрактный интерфейс для глубоких нейронных сетей. Фактические сети могут работать поверх Tensorflow, Theano или других бэкэндов. Эта внутренняя независимость делает Keras привлекательным вариантом с точки зрения его долгосрочной жизнеспособности. Разрешающая лицензия MIT делает его привлекательным для предприятий, стремящихся разрабатывать собственные модели. RR — лучший язык для решения любых статистических задач. Его коллекция библиотек (13711 на момент написания статьи о CRAN намного превосходит возможности любого другого языка программирования для статистических вычислений и больше, чем у многих других экосистем. Короче говоря, если вы решите использовать R для чего-либо, связанного со статистикой, вы не будете окажетесь в ситуации, когда вам придется изобретать велосипед, не говоря уже о целой пачке. CaretCaret — это пакет R, предназначенный для создания полных конвейеров машинного обучения с инструментами для всего, от приема и предварительной обработки данных, выбора функций и автоматической настройки модели. mlrПроект «Машинное обучение в R» (сокращенно mlr) предоставляет полный набор инструментов машинного обучения для языка программирования R, который часто используется для анализа текста. JavaJava не нуждается в представлении. Язык может похвастаться впечатляющей экосистемой, которая выходит за рамки самой Java и включает библиотеки других языков JVM, таких как Scala и Clojure.Помимо этого, JVM протестирована в боевых условиях, на нее были потрачены тысячи человеко-лет разработки и настройки производительности, поэтому Java, вероятно, обеспечит вам лучшую в своем классе производительность для всей вашей работы по НЛП с анализом текста. CoreNLPСтэнфордский проект CoreNLP предоставляет проверенный и активно поддерживаемый инструментарий НЛП. Хотя он написан на Java, у него есть API для всех основных языков, включая Python, R и Go. OpenNLPПроект Apache OpenNLP — еще один набор инструментов машинного обучения для НЛП.Его можно использовать на любом языке платформы JVM. WekaWeka — это библиотека Java для машинного обучения под лицензией GPL, разработанная в Университете Вайкато в Новой Зеландии. В дополнение к исчерпывающему набору API-интерфейсов машинного обучения Weka имеет графический пользовательский интерфейс под названием Explorer , который позволяет пользователям в интерактивном режиме разрабатывать и изучать свои модели. Weka поддерживает извлечение данных из баз данных SQL напрямую, а также глубокое обучение с помощью платформы deeplearning4j. SaaS APIИспользование SaaS API для анализа текста имеет множество преимуществ: Большинство инструментов SaaS представляют собой простые plug-and-play решения без библиотек для установки и без новой инфраструктуры. API-интерфейсы SaaS предоставляют готовые к использованию решения. Вы даете им данные, а они возвращают анализ. Все остальные проблемы — производительность, масштабируемость, ведение журнала, архитектура, инструменты и т. Д. — перекладываются на сторону, ответственную за поддержку API. Часто вам просто нужно написать несколько строк кода, чтобы вызвать API и получить обратно результаты. API-интерфейсы SaaS обычно предоставляют готовые интеграции с инструментами, которые вы, возможно, уже используете. Это позволит вам создать действительно решение без кода. Узнайте, как интегрировать анализ текста с Google Таблицами. Некоторые из наиболее известных SaaS-решений и API-интерфейсов для анализа текста включают: В настоящее время ведутся дебаты между сборками и покупками, когда речь идет о приложениях для анализа текста: создайте свой собственный инструмент с помощью программного обеспечения с открытым исходным кодом или используйте Инструмент анализа текста SaaS? Создание собственного программного обеспечения с нуля может быть эффективным и полезным, если у вас есть годы опыта в области науки о данных и инженерии, но это требует много времени и может стоить сотни тысяч долларов. Инструменты SaaS, с другой стороны, представляют собой отличный способ погрузиться прямо в дело. Они могут быть простыми, легкими в использовании и столь же мощными, как создание собственной модели с нуля. MonkeyLearn — это платформа для анализа текста SaaS с десятками предварительно обученных моделей. Или вы можете настроить свой собственный, часто всего за несколько шагов для получения столь же точных результатов. И все это без опыта программирования. Учебные наборы данныхЕсли вы поговорите с любым специалистом в области науки о данных, он скажет вам, что истинным узким местом для построения лучших моделей являются не новые и лучшие алгоритмы, а больше данных. Действительно, в машинном обучении данные являются королем: простая модель, учитывая тонны данных, вероятно, превзойдет ту, которая использует все уловки из книги, чтобы превратить каждый бит обучающих данных в осмысленный ответ. Итак, вот несколько высококачественных наборов данных, которые вы можете использовать для начала: Классификация тем
Анализ настроений
Другие популярные наборы данных
Поиск больших объемов и высококачественных наборов обучающих данных — самая важная часть анализа текста, более важная, чем выбор языка программирования или инструментов для создания моделей. Помните, что конвейер машинного обучения с наилучшей архитектурой бесполезен, если его модели основаны на ненадежных данных. Учебники по анализу текстаЛучший способ учиться — это делать. Сначала мы рассмотрим учебники для конкретных языков программирования с использованием инструментов с открытым исходным кодом для анализа текста.Это поможет вам глубже понять доступные инструменты для выбранной вами платформы. Затем мы рассмотрим пошаговое руководство по MonkeyLearn, чтобы вы могли сразу приступить к анализу текста. Учебные пособия с использованием библиотек с открытым исходным кодомВ этом разделе мы рассмотрим различные учебные пособия по анализу текста на основных языках программирования для машинного обучения, которые мы перечислили выше. PythonNLTKОфициальная книга NLTK — это полный ресурс, который учит вас NLTK от начала до конца.Кроме того, справочная документация является полезным ресурсом для консультации во время разработки. Другие полезные руководства включают: SpaCyspaCy 101: все, что вам нужно знать: часть официальной документации, это руководство показывает вам все, что вам нужно знать, чтобы начать использовать SpaCy. Из этого туториала Вы узнаете, как создать конвейер WordNet с помощью SpaCy. Кроме того, есть официальная документация по API, в которой объясняется архитектура и API SpaCy. Если вы предпочитаете длинный текст, существует ряд книг о SpaCy или с его участием: Scikit-learnОфициальная документация scikit-learn содержит ряд руководств по базовому использованию scikit-learn, построению конвейеров. , и оценивающих оценщиков. Scikit-learn Tutorial: Machine Learning in Python показывает, как использовать scikit-learn и Pandas для исследования набора данных, его визуализации и обучения модели. Для читателей, которые предпочитают книги, есть несколько вариантов: KerasНа официальном веб-сайте Keras есть обширный API, а также учебная документация.Для читателей, которые предпочитают длинный текст, рекомендуется обратиться к книге «Глубокое обучение с Керасом». В книге используются примеры из реальной жизни, чтобы дать вам четкое представление о Керасе. Другие руководства:
TensorFlowTensorFlow Tutorial For Beginners знакомит с математикой, лежащей в основе TensorFlow, и включает примеры кода, которые запускаются в браузере, что идеально для исследования и обучения. Цель учебного пособия — классифицировать уличные знаки. Книга «Практическое машинное обучение с помощью Scikit-Learn и TensorFlow» поможет вам получить интуитивное понимание машинного обучения с помощью TensorFlow и scikit-learn. Наконец, есть официальное руководство по началу работы с TensorFlow. PyTorchОфициальное руководство по началу работы от PyTorch показывает вам основы PyTorch. Если вас интересует что-то более практичное, ознакомьтесь с этим руководством по чат-боту; он показывает вам, как создать чат-бота с помощью PyTorch. Учебник «Глубокое обучение для НЛП с помощью PyTorch» — это мягкое введение в идеи, лежащие в основе глубокого обучения, и их применение в PyTorch. Наконец, официальный справочник API объясняет функционирование каждого отдельного компонента. RCaretКраткое введение в пакет Caret показывает, как обучить и визуализировать простую модель. Практическое руководство по машинному обучению в R показывает, как подготовить данные, построить и обучить модель, а также оценить ее результаты. Наконец, у вас есть официальная документация, которая очень полезна для начала работы с Caret. mlrДля тех, кто предпочитает длинный текст, на arXiv можно найти обширный учебник по mlr. Это больше похоже на книгу, чем на статью, и в ней есть обширные и подробные образцы кода для использования mlr. JavaCoreNLPЕсли вы хотите узнать о CoreNLP, вам следует ознакомиться с учебным пособием Linguisticsweb.org, в котором объясняется, как быстро начать работу и выполнить ряд простых задач NLP из командной строки. Кроме того, в этом руководстве CloudAcademy показано, как использовать CoreNLP и визуализировать его результаты. Вы также можете ознакомиться с этим руководством, посвященным анализу настроений с помощью CoreNLP. Наконец, есть это руководство по использованию CoreNLP с Python, которое полезно для начала работы с этой структурой. OpenNLPПерво-наперво: официальное руководство Apache OpenNLP должно быть отправная точка. Книга «Укрощение текста» была написана разработчиком OpenNLP и использует фреймворк, чтобы показать читателю, как реализовать анализ текста. Кроме того, это руководство проведет вас по OpenNLP, включая токенизацию, часть тегов речи, синтаксический анализ предложений и разбиение на части. WekaВ библиотеке Weka есть официальная книга «Интеллектуальный анализ данных: практические инструменты и методы машинного обучения», которая пригодится для знакомства с Weka. Если вы предпочитаете видео тексту, существует также ряд MOOC, использующих Weka: Практическое руководство по анализу текста с MonkeyLearnПредставьте, что производительность вашей службы поддержки падает: вручную классифицируйте темы и отправьте каждый запрос в соответствующий отдел. делая их работу очень сложной. Вы готовы к использованию решения для машинного обучения, но у вашей команды разработчиков просто нет времени или опыта, и вы не хотите нанимать новых сотрудников. Хорошая новость заключается в том, что MonkeyLearn предлагает простую и удобную платформу для создания собственных моделей анализа текста без использования кода или машинного обучения. Следуйте приведенным ниже пошаговым руководствам по классификации и извлечению текста, чтобы узнать, как начать анализ текста с помощью машинного обучения всего за несколько минут. Это безболезненно и легко. Создайте свой собственный классификатор текста1. Создайте новую модель Сначала перейдите на панель управления и нажмите «Создать модель», затем выберите «Классификатор»: 2. Теперь выберите «Тема» Классификация ‘ 3. Загрузите данные для обучения классификатора Первое, что нужно вашей новой модели, — это данные.Вы можете импортировать данные из файлов CSV или Excel, а также из Twitter, Gmail, Zendesk, Freshdesk и др.: После загрузки данных вы приступите к обучению своей модели. 4. Определите теги Следующим шагом является определение тегов, которые вы хотите использовать в текстовом классификаторе при сортировке данных: 5. Начните обучение вашей модели, добавляя теги к примерам. критерии. Обучить вашу модель очень просто. Просто назначьте соответствующий тег каждому фрагменту текста, как в примере ниже:
Если вы заметите, что некоторые примеры уже помечены, значит машинное обучение выполняет свою работу! Помните, что это первые шаги модели с вашими данными, поэтому она может делать некоторые ошибки на этом пути.Просто поменяйте теги, если что-то не так, и вы увидите более точные результаты в кратчайшие сроки. Чем больше данных вы пометите, тем точнее станет модель. 6. Протестируйте свой классификатор Последним шагом является проверка классификатора текста. После того, как вы закончите пометить начальный набор примеров, перейдите на вкладку «Выполнить» и введите новый текст, чтобы увидеть, как он работает:
Если вы все еще видите ошибки, вы можете вернуться на вкладку «Сборка» для дальнейшее обучение. Заставьте ваш новый классификатор текста работатьТеперь, когда ваш новый классификатор тем запущен и работает, все, что вам нужно сделать, это загрузить новые данные и позволить модели делать свое дело.С помощью MonkeyLearn вы можете просто загрузить дополнительные файлы CSV и Excel для анализа новых данных или использовать одну из наших интеграций: Если вы знаете, как кодировать, вы также можете использовать API MonkeyLearn для запуска своей модели анализа текста на Python, Ruby, PHP, Javascript или Java: После того, как ваши данные проанализированы, вы можете увидеть все это с поразительными визуальными деталями с помощью MonkeyLearn Studio. А теперь перейдем к извлечению текста. Предположим, что только что получены результаты вашего последнего опроса об удовлетворенности клиентов, и вам нужно найти способ просеять открытые ответы, чтобы заменить ручные процедуры, которые тратят впустую время.Эти ответы содержат важную информацию о том, как клиенты относятся к вашим услугам. Ваша цель — извлечь из этих ответов наиболее релевантные ключевые слова и получить полезную информацию. Объедините это с анализом настроений, и вы также узнаете, как они относятся к этим темам: положительно , отрицательно или нейтрально . 1. Создайте новый экстрактор Войдите в MonkeyLearn и перейдите на свою панель инструментов, нажмите «Создать модель», а затем «Экстрактор»: 2.Выберите способ загрузки данных модели Теперь вы можете загружать данные с таких платформ, как Twitter или Gmail, или из служб поддержки клиентов, таких как Front, Zendesk и Freshdesk, а также из RSS и файлов CSV или Excel. 3. Создайте теги для вашей модели для извлечения Вам понадобится как минимум два тега, чтобы начать обучение модели извлечения текста, но вы всегда можете добавить больше по ходу, если чувствуете, что отсутствуют важные данные: В приведенном выше примере мы выбираем теги, которые дадут нам представление о том, как клиенты видят три важных аспекта нашего сервиса.Мы извлекли данные из нашего последнего опроса, используя теги Support , UX / UI и Pricing . 4. Обучите свой новый экстрактор текста После того, как вы сказали своему экстрактору, на какие теги нужно обращать внимание, пришло время вручную пометить некоторые примеры, выделив слова и выражения, связанные с ними. После небольшого обучения вы начнете замечать, что экстрактор начинает предсказывать теги на основе ваших критериев:
. Вы можете вернуться на вкладку «Построить» и продолжить обучение своей модели, если она не предсказывает должным образом. Что дальше? Вы готовы использовать новую модель извлечения текста. Вы можете передать ему новые данные, загрузив новые файлы CSV и Excel или используя одну из интеграций MonkeyLearn: Как мы упоминали ранее, MonkeyLearn также позволяет интегрировать экстрактор с его API, используя Python, Ruby, PHP, Javascript или Java: TakeawayАнализ текста больше не является эксклюзивной темой для инженеров-программистов с опытом машинного обучения. Он стал мощным инструментом, который помогает компаниям во всех отраслях получать полезные и действенные идеи из своих текстовых данных.Экономия времени, автоматизация задач и повышение производительности никогда не были такими простыми, как никогда, позволяя компаниям избавиться от громоздких задач и помогать своим командам предоставлять более качественные услуги своим клиентам. Если вы хотите попробовать анализ текста, посетите MonkeyLearn и начните обучение своим собственным классификаторам и экстракторам текста — кодирование не требуется благодаря нашему удобному интерфейсу и интеграции. Анализируйте текст с помощью ИИ для получения ценной информации И взгляните на общедоступную информационную панель MonkeyLearn Studio, чтобы увидеть, что может сделать визуализация данных, чтобы увидеть ваши результаты в общих чертах или в мельчайших деталях. Свяжитесь с нашей командой, если у вас есть какие-либо сомнения или вопросы по поводу анализа текста и машинного обучения, и мы поможем вам начать работу! Введение в обработку естественного языка (NLP)Обработка естественного языка (NLP) — это область информатики и искусственного интеллекта, связанная с взаимодействием между компьютерами и людьми на естественном языке. Конечная цель НЛП — помочь компьютерам понимать язык так же хорошо, как и мы. Это движущая сила таких вещей, как виртуальные помощники, распознавание речи, анализ тональности, автоматическое суммирование текста, машинный перевод и многое другое.В этом посте мы рассмотрим основы обработки естественного языка, погрузимся в некоторые из ее методов, а также узнаем, как НЛП помогло последним достижениям в области глубокого обучения. Содержание
I. ВведениеОбработка естественного языка (NLP) — это пересечение информатики, лингвистики и машинного обучения.Эта область фокусируется на общении между компьютерами и людьми на естественном языке, а НЛП — на том, чтобы заставить компьютеры понимать и генерировать человеческий язык. Применения методов НЛП включают голосовых помощников, таких как Amazon Alexa и Apple Siri, а также такие вещи, как машинный перевод и фильтрация текста. NLP сильно выиграл от последних достижений в области машинного обучения, особенно от методов глубокого обучения. Поле разделено на три части:
II. Почему НЛП — это сложноЧеловеческий язык особенный по нескольким причинам. Он специально разработан, чтобы передать смысл говорящего / писателя. Это сложная система, хотя маленькие дети могут освоить ее довольно быстро. Еще одна примечательная черта человеческого языка — это то, что все дело в символах.По словам Криса Мэннинга, профессора машинного обучения из Стэнфорда, это дискретная, символическая, категориальная сигнальная система. Это означает, что мы можем передавать одно и то же значение разными способами (например, речь, жест, знаки и т. Д.). Кодирование человеческим мозгом — это непрерывный паттерн активации, посредством которого символы передаются через непрерывные звуковые и визуальные сигналы. Понимание человеческого языка считается сложной задачей из-за его сложности. Например, существует бесконечное количество различных способов расположить слова в предложении.Кроме того, слова могут иметь несколько значений, и для правильной интерпретации предложений необходима контекстная информация. Каждый язык более или менее уникален и неоднозначен. Достаточно взглянуть на следующий заголовок в газете «Папа папа наступает на геев». Это предложение явно имеет две очень разные интерпретации, что является довольно хорошим примером проблем в НЛП. Обратите внимание, что идеальное понимание языка компьютером привело бы к созданию ИИ, способного обрабатывать всю информацию, доступную в Интернете, что, в свою очередь, вероятно, привело бы к созданию общего искусственного интеллекта. III. Синтаксический и семантический анализСинтаксический анализ (синтаксис) и семантический анализ (семантический) — это два основных метода, которые приводят к пониманию естественного языка. Язык — это набор действительных предложений, но что делает предложение действительным? Синтаксис и семантика. Синтаксис — это грамматическая структура текста, а семантика — это передаваемое значение. Однако синтаксически правильное предложение не всегда является семантически правильным.Например, «коровы безраздельно текут» грамматически корректно (подлежащее — глагол — наречие), но не имеет никакого смысла. Синтаксический анализ
Синтаксический анализ, также называемый синтаксическим анализом или синтаксическим анализом, представляет собой процесс анализа естественного языка с использованием правил формальной грамматики. Грамматические правила применяются к категориям и группам слов, а не к отдельным словам. Синтаксический анализ в основном придает тексту семантическую структуру. Например, предложение включает подлежащее и сказуемое, где подлежащее — это существительная фраза, а предикат — глагольная фраза.Взгляните на следующее предложение: «Собака (существительная фраза) ушла (глагольная фраза)». Обратите внимание, как мы можем комбинировать каждую именную фразу с глагольной фразой. Опять же, важно повторить, что предложение может быть синтаксически правильным, но не иметь смысла. Семантический анализТо, как мы понимаем сказанное, — это бессознательный процесс, основанный на нашей интуиции и знаниях о самом языке. Другими словами, то, как мы понимаем язык, во многом зависит от значения и контекста.Однако к компьютерам нужен другой подход. Слово «семантический» является лингвистическим термином и означает «относящийся к значению или логике».
Семантический анализ — это процесс понимания значения и интерпретации слов, знаков и структуры предложения. Это позволяет компьютерам частично понимать естественный язык так, как это делают люди. Я говорю отчасти потому, что семантический анализ — одна из самых сложных частей НЛП, и она еще не решена полностью. Распознавание речи, например, стало очень хорошим и работает почти безупречно, но нам все еще не хватает такого уровня знаний в понимании естественного языка.Ваш телефон в основном понимает то, что вы сказали, но часто ничего не может с этим поделать, потому что не понимает стоящего за этим смысла. Кроме того, некоторые из существующих технологий только заставляют вас думать, что они понимают значение текста. Подход, основанный на ключевых словах или статистике, или даже на чистом машинном обучении, может использовать метод сопоставления или частоты для подсказок о том, «о чем» текст. Эти методы ограничены, потому что они не рассматривают истинный смысл. IV.Методы понимания текстаДавайте рассмотрим некоторые из самых популярных методов, используемых при обработке естественного языка. Обратите внимание, как некоторые из них тесно взаимосвязаны и служат только подзадачами для решения более крупных проблем. РазборЧто такое парсинг? Согласно словарю, синтаксический анализ означает «разложить предложение на составные части и описать их синтаксические роли». Это действительно помогло, но могло бы быть немного более исчерпывающим.Под синтаксическим анализом понимается формальный анализ предложения компьютером на его составные части, в результате которого создается дерево синтаксического анализа, показывающее их синтаксические отношения друг с другом в визуальной форме, которое можно использовать для дальнейшей обработки и понимания. Ниже представлено дерево синтаксического анализа для предложения «Вор ограбил квартиру». Включено описание трех различных типов информации, передаваемых в предложении.
Буквы непосредственно над отдельными словами показывают части речи для каждого слова (существительное, глагол и определитель).Уровень выше — это некая иерархическая группировка слов во фразы. Например, «вор» — это существительное, «ограбил квартиру» — глагольное словосочетание, и, сложив вместе эти две фразы, образуют предложение, которое отмечается на один уровень выше. Но что на самом деле означает существительное или глагольная фраза? Существительные фразы — это одно или несколько слов, которые содержат существительное и, возможно, некоторые дескрипторы, глаголы или наречия. Идея состоит в том, чтобы сгруппировать существительные со словами, которые к ним относятся. Дерево синтаксического анализа также предоставляет нам информацию о грамматических отношениях слов из-за структуры их представления.Например, в структуре мы видим, что «вор» является субъектом «ограблен». Под структурой я подразумеваю, что у нас есть глагол («ограблен»), который отмечен буквой «V» над ним и буквой «VP» над ним, которая связана буквой «S» с подлежащим («вор» ), над которым есть «NP». Это похоже на шаблон для отношений подлежащее-глагол, и есть много других для других типов отношений. СтволСтемминг — это метод, основанный на морфологии и поиске информации, который используется в НЛП для предварительной обработки и повышения эффективности.В словаре это определяется как «возникать или быть вызванным». По сути, выделение корней — это процесс сокращения слов до их основы. «Основа» — это часть слова, которая остается после удаления всех аффиксов. Например, основа слова «тронутый» — «прикоснуться». «Прикосновение» также является основой «прикосновения» и так далее. Вы можете спросить себя, зачем нам вообще стебель? Итак, основа необходима, потому что мы встретимся с разными вариантами слов, которые на самом деле имеют одну основу и одно и то же значение.Например: Я ехал на машине. Я ехал в машине. Эти два предложения означают одно и то же, и использование этого слова идентично. А теперь представьте себе все английские слова в словаре со всеми их различными фиксациями в конце. Для их хранения потребуется огромная база данных, содержащая множество слов, которые на самом деле имеют одинаковое значение. Это решается путем сосредоточения внимания только на основе слова.Популярные алгоритмы выделения включают алгоритм вывода Портера из 1979 года, который до сих пор хорошо работает. Сегментация текстаСегментация текста в НЛП — это процесс преобразования текста в значимые единицы, такие как слова, предложения, различные темы, лежащее в основе намерение и многое другое. В основном текст разбивается на составляющие слова, что может быть сложной задачей в зависимости от языка. Это опять же из-за сложности человеческого языка. Например, в английском языке относительно хорошо работает разделение слов пробелами, за исключением таких слов, как «icebox», которые принадлежат друг другу, но разделены пробелом.Проблема в том, что люди иногда также пишут это как «ледяной ящик». Признание именной организации Распознавание именованных объектов (NER) концентрируется на определении того, какие элементы в тексте (т. Е. «Именованные объекты») могут быть обнаружены и классифицированы по заранее определенным категориям. Эти категории могут варьироваться от имен людей, организаций и местоположений до денежных значений и процентов. Например: До NER: Мартин купил 300 акций SAP в 2016 году. После NER: [Мартин] Человек купил 300 акций [SAP] Organization за [2016] Время. Извлечение отношений При извлечении отношений используются названные объекты NER и предпринимаются попытки идентифицировать семантические отношения между ними. Это может означать, например, выяснение, кто с кем женат, что человек работает в определенной компании и так далее. Эта проблема также может быть преобразована в проблему классификации, и модель машинного обучения может быть обучена для каждого типа отношений. Анализ тональности С помощью анализа настроений мы хотим определить отношение (то есть настроение) говорящего или писателя по отношению к документу, взаимодействию или событию. Следовательно, это проблема обработки естественного языка, когда текст необходимо понимать, чтобы предсказать лежащее в основе намерение. Настроения в основном делятся на положительные, отрицательные и нейтральные категории. С помощью анализа настроений, например, мы можем захотеть спрогнозировать мнение и отношение клиента к продукту на основе написанного ими обзора.Анализ тональности широко применяется к обзорам, опросам, документам и многому другому. Если вам интересно использовать некоторые из этих методов с Python, взгляните на Jupyter Notebook о наборе инструментов естественного языка Python (NLTK), который я создал. Вы также можете ознакомиться с моим сообщением в блоге о построении нейронных сетей с помощью Keras, где я обучаю нейронную сеть выполнять анализ настроений. V. Глубокое обучение и NLPЦентральное место в глубоком обучении и естественном языке занимает «значение слова», когда слово и особенно его значение представлены в виде вектора действительных чисел.С помощью этих векторов, которые представляют слова, мы помещаем слова в многомерное пространство. Интересно то, что слова, представленные векторами, будут действовать как семантическое пространство. Это просто означает, что слова, которые похожи и имеют похожее значение, имеют тенденцию группироваться вместе в этом многомерном векторном пространстве. Вы можете увидеть визуальное представление значения слова ниже:
Вы можете узнать, что означает группа сгруппированных слов, выполнив анализ главных компонентов (PCA) или уменьшение размерности с помощью T-SNE, но иногда это может вводить в заблуждение, поскольку они упрощают и оставляют много информации на стороне.Это хороший способ начать работу (например, логистическая или линейная регрессия в науке о данных), но он не является передовым и можно сделать это лучше. Мы также можем думать о частях слов как о векторах, которые представляют их значение. Представьте себе слово «нежелательность». Используя морфологический подход, который включает в себя различные части слова, мы могли бы думать, что оно состоит из морфем (частей слова), например: «Un + желание + способность + ity». Каждая морфема получает свой вектор. Исходя из этого, мы можем построить нейронную сеть, которая может составить значение более крупной единицы, которая, в свою очередь, состоит из всех морфем. Глубокое обучение также может определять структуру предложений с помощью синтаксических анализаторов. Google использует подобные методы анализа зависимостей, хотя и в более сложной и широкой манере, с их «McParseface» и «SyntaxNet». Зная структуру предложений, мы можем начать пытаться понять смысл предложений. Мы начинаем со значения слов, являющихся векторами, но мы также можем сделать это с целыми фразами и предложениями, где значение также представлено в виде векторов.И если мы хотим знать взаимосвязь предложений или между ними, мы обучаем нейронную сеть принимать эти решения за нас. Глубокое обучение также хорошо подходит для анализа настроений. Возьмем, к примеру, этот обзор фильма: «В этом фильме нет дела до ума, с каким-либо другим умным юмором». Традиционный подход попался бы в ловушку, полагая, что это положительный отзыв, потому что «сообразительность или любой другой вид умного юмора» звучит как положительное намерение, но нейронная сеть распознала бы его реальное значение.Другие приложения — это чат-боты, машинный перевод, Siri, предлагаемые ответы в почтовом ящике Google и так далее. В машинном переводе также произошел огромный прогресс благодаря появлению рекуррентных нейронных сетей, о которых я также написал сообщение в блоге. В машинном переводе, выполняемом с помощью алгоритмов глубокого обучения, язык переводится, начиная с предложения и генерируя векторные представления, которые его представляют. Затем он начинает генерировать слова на другом языке, содержащие ту же информацию. Подводя итог, НЛП в сочетании с глубоким обучением — это все о векторах, которые представляют слова, фразы и т. Д. И до некоторой степени их значения. VI. Список литературыНиклас Донгес — предприниматель, технический писатель и эксперт в области искусственного интеллекта. В течение 1,5 лет он работал в команде SAP в области искусственного интеллекта, после чего основал компанию Markov Solutions. Компания из Берлина специализируется на искусственном интеллекте, машинном обучении и глубоком обучении, предлагая индивидуальные программные решения на базе искусственного интеллекта и консалтинговые программы для различных компаний.
СвязанныеПодробнее о Data Science Nominal Group Technique (NGT) — Nominal Brainstorming StepsГлоссарий качества Определение: Метод номинальной группы Метод номинальной группы (NGT) определяется как структурированный метод группового мозгового штурма, который поощряет вклад каждого и способствует быстрому соглашению об относительной важности вопросов, проблем или решений. Члены команды начинают с того, что записывают свои идеи, а затем выбирают, какая идея, по их мнению, лучше всего.Когда члены команды готовы, каждый представляет свою любимую идею, а затем предложения обсуждаются и распределяются по приоритетам всей группой с использованием балльной системы. NGT объединяет рейтинги важности отдельных членов группы в окончательные взвешенные приоритеты группы. Когда использовать метод номинальной группыИспользуйте NGT, когда:
Номинальная группа шагов техникиНеобходимые материалы: Бумага и ручка или карандаш для каждого человека, флипчарт, маркеры и лента.
Номинальная группа Рекомендации по технике
Адаптировано из The Quality Toolbox, Second Edition , ASQ Quality Press. Интерпретация в юнгианском анализе: искусство и техникаОписание книгиФиналист книжной премии Американского совета и Академии психоанализа 2019! Аналитическая интерпретация лежит в основе процесса психоанализа, юнгианского анализа и психоаналитической психотерапии.Интерпретация — это средство передачи психоаналитического искусства. Что человек хочет сказать в анализе, почему он выбирает это, как он это говорит, когда он это говорит; это строительные блоки процесса интерпретации и фокус Интерпретация в юнгианском анализе: Искусство и техника . Этот том является первым в своем роде в литературе по аналитической психологии. До сих пор процесс интерпретации в общих юнгианских текстах рассматривался лишь кратко. Интерпретация в юнгианском анализе обеспечивает глубокое исследование процесса, включая историю аналитической техники, роль языка в аналитической терапии, поэтику и метафору интерпретации, а также взаимосвязь между интерпретацией и аналитической установкой. Кроме того, четко обозначены этапы создания ясных, значимых и преобразующих интерпретаций. В книге приведены клинические примеры и упражнения для чтения, которые помогут углубить процесс обучения.Обрисовывается влияние юнгианской точки зрения на процесс интерпретации, а также использование аналитической мечтательности и конфронтации во время аналитического процесса. Помимо исторических, технических и теоретических аспектов интерпретации, эта книга также фокусируется на художественных и творческих элементах, которые часто упускаются из виду в процессе интерпретации. В конечном счете, культивирование гибкости в процессе интерпретации необходимо для задействования глубины и сложности психики. Интерпретация в юнгианском анализе будет представлять большой интерес для психоаналитиков и психотерапевтов всех теоретических направлений и будет важным чтением для студентов, изучающих аналитическую психологию. СодержаниеСОДЕРЖАНИЕ Список рисунков Благодарности Разрешения Введение
Техника аналитической психологии Заключение Приложение: Исследование интерпретации Библиография Индекс Отзывы
Техника «перемотки» | Институт Человека ГивенсаУЛУЧШЕННАЯ версия Техники перемотки * (как преподается в колледже HG) — это ненавязчивый, безопасный и высокоэффективный психологический метод для детравматизации людей, который также может использоваться для устранения фобий.Его должен проводить опытный практик и выполнять только тогда, когда человек находится в состоянии глубокого расслабления. Когда они полностью расслаблены, их побуждают вывести на поверхность свою тревогу, а затем снова успокаивают, побуждая вспомнить или представить себе место, где они чувствуют себя совершенно непринужденно. Затем их расслабленное состояние углубляется, и их просят представить, что в их специальном безопасном месте у них есть телевизор или экран с дистанционным управлением.Их просят представить, как они плывут в сторону, выходят из тела, и наблюдать, как они смотрят на экран, не видя изображения на самом деле (создавая двойную диссоциацию). Они смотрят, как смотрят «фильм» о травмирующем событии, которое все еще переживает их. Фильм начинается в точке до того, как травма произошла, и заканчивается в точке, на которой травма закончилась. ДВУХДНЕВНЫЙ КУРС Быстрое лечение травм (ПТСР) и фобий Затем их просят в своем воображении вернуться в свое тело и ощутить, как они быстро проходят через травму, от того, как она закончилась, до того, как она началась, как если бы они были персонажами в видео, которое перематывается.Затем они смотрят те же изображения, но как на экране телевизора, нажимая кнопку перемотки вперед (диссоциация). Все это повторяется взад и вперед, с любой удобной скоростью, и столько раз, сколько необходимо, пока сцены не вызовут у клиента никаких эмоций. Если обстоятельство, которого боятся, снова встретится в будущем — например, при вождении автомобиля или использовании лифта, — человека просят, пока он все еще расслаблен, визуализировать, что он делает это уверенно. Помимо того, что этот метод безопасен, быстр и безболезнен, он имеет то преимущество, что он не вуайерист. Интимные или болезненно огорчающие подробности не подлежат разглашению. Это уменьшает стресс для клиента, а также помогает защитить терапевта от возможности косвенно травмировать себя, детравмируя особенно тревожные события. История болезни: Наконец-то обретя мир * Эта техника возникла из НЛП и часто называлась техникой визуальной / кинестетической диссоциации, термин «техника перемотки назад» первоначально был придуман доктором Дэвидом Массом.Джо Гриффин и Айвэн Тиррелл доработали версию техники перемотки назад, которую используют терапевты, чтобы сделать ее максимально эффективной, согласовав ее с их представлениями о том, как травмы и фобии обрабатываются в мозгу.
| ||||||||||||||||||||||||||||