
Отображение целостного образа непосредственно воздействующего предмета: Тестовые задания всероссийской олимпиады по обществознанию 11 класс. Школьный уровень
Тестовые задания всероссийской олимпиады по обществознанию 11 класс. Школьный уровень
ВСЕРОССИЙСКАЯ ОЛИМПИАДА ШКОЛЬНИКОВ
ПО ОБЩЕСТВОЗНАНИЮ. МУНИЦИПАЛЬНЫЙ ЭТАП. 11 КЛАСС. Максимальный балл —79 Задания
Фамилия______________________ имя___________________________Класс______
1. «Да» или «нет»? Если вы согласны с утверждением, напишите «Да», если не согласны — «Нет». Внесите свои ответы в таблицу.
1) Исторически первыми примитивными формами религиозности выступают анимизм, ведизм, тотемизм, фетишизм.
2) Поведение, не соответствующее принятым в обществе нормам, называется конформизмом.
3) Большинство ученых считают, что для представителей этнического меньшинства наиболее благоприятно достижение биэтнической социальной идентичности.
4) Культурология как наука изучает все стороны жизни общества.
5) В некоторых случаях прирожденный социальный статус может меняться.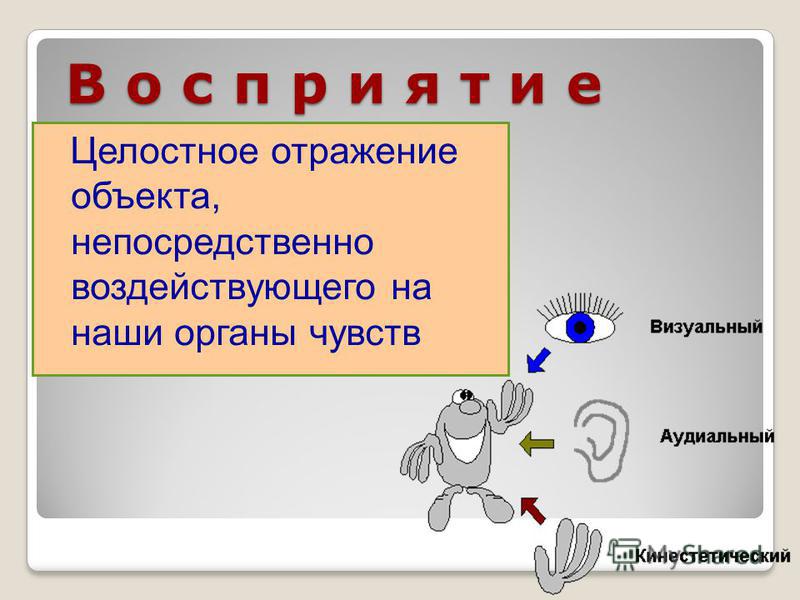
6) Т. Гоббс исходит из того, что законы природы развивают у людей эгоистические потребности, которые ведут к «войне всех против всех».
7) Дивиденд по привилегированным акциям является фиксированным.
8) Все правовые нормы одновременно являются и нормами морали.
9) Художественный образ может носить как визуально определенный, так и визуально не определенный характер.
10) Согласно евразийской доктрине, Россия есть третий, срединный материк – особый исторический и этнографический мир.
10 баллов: по 1 баллу за каждую позицию.2.Выберите все правильные ответы. Запишите их в таблицу.
2.1. Характеристики чувственного познания:
а) отображение целостного образа непосредственно воздействующего предмета
б) отражение отдельных свойств предметов, воспринимаемых в данный моментв) установление взаимосвязи различных понятий
г) обобщение и выделение группы предметов на основе общих признаков
д) получение новых суждений на основе уже имеющихся
е) сохранение в памяти целостного образа предмета
2. 2. Признаки, присущие только мажоритарной избирательной системы:
2. Признаки, присущие только мажоритарной избирательной системы:
а) консервативная идеология
б) голосование по партийным спискам
в) общенациональный избирательный округ
г) допускается выдвижение независимых кандидатов
д) возможны два тура голосования
е) одномандатные избирательные округа
ж) в день голосования запрещается ведение агитации
з) избирательный барьер
2.3. Юридические основания прекращения трудового договора:
а) инициатива работника
б) сдельная заработная плата
в) нарушение трудового законодательства
г) безработица
д) смена собственника
е) экономический спад
2.4. Проявления хозяйственно-экономической функции семьи:
а) организация семейного отдыха
б) социализация человека
в) планирование семейного бюджета
г) первичный социальный контроль
д) ведение домашнего хозяйства
е) распределение домашнего труда
2. 5. Позиции, характеризующие отношения между природой и обществом:
5. Позиции, характеризующие отношения между природой и обществом:
а) общество, обособившись от природы, утратило зависимость от неё
б) природа и общество оказывают воздействие друг на друга
в) в процессе своего развития человеческое общество преобразует часть природы, ставя её на службу себе
г) природные катаклизмы в современном мире серьезно угрожают человечеству
д) общество в своем развитии создает угрозу окружающей среде
е) общество и природа никак не связаны между собой
10 баллов: по 2 за каждый столбец таблицы, если в столбце 1 ошибка (лишняя буква или не хватает буквы) – 0 баллов за столбец.
3. Установите соответствие между авторами и их научными взглядами.
По 2 балла за каждую верную позицию, всего – 8 баллов.4. Что объединяет понятия, образующие каждый из представленных рядов? Дайте краткий ответ. 1) Событие абсолютное, событие относительное, правомерное действие, неправомерное действие, правоотношения. ________________________________________.
1) Событие абсолютное, событие относительное, правомерное действие, неправомерное действие, правоотношения. ________________________________________.
2) Единая территория, единая конституция, единая система законодательных, исполнительных и судебных органов, управление административными единицами из центра государственной власти. _________________________________________.
3) Требования группы, несоответствие их ожиданиям, ощущение внутреннего напряжения у индивидов. ___________________________________________
По 3 балла за каждую верную позицию, всего – 9 баллов
5.Что является лишним в ряду. Дайте КРАТКОЕ пояснение.
5.1. Трудовое право, гражданское право, административное право, государственное право, обязательственное право.
Ответ:____________________________________________________________________________________________________________________________________________________________
5. 2. Публичная власть, территория, идеология, суверенитет, налоги.
2. Публичная власть, территория, идеология, суверенитет, налоги.
Ответ:_____________________________________________________________________________________________________________________________________________________________
5.3. Выдача лицензий, установление квот, установление цен, надзор над качеством.
Ответ:____________________________________________________________________________________________________________________________________________________________
9 баллов: по 1 баллу за правильные ответы (всего – 3), + по 2 балла за объяснение.
6. Решите логическую задачу.
Встретились четыре профессора: Белов, Чернов, Рыжов и Седов. Один из них был блондином, другой брюнетом, третий рыжим, а четвертый – седым. «Ни у кого из нас цвет волос не совпадает с фамилией», – сказал Белов. «Ты прав», – подтвердил брюнет. «Тот, у кого цвет волос совпадает с моей фамилией, носит фамилию, совпадающую с цветом волос Белова» – вмешался в их беседу седовласый профессор.
____________________________________________________________________________________ ____________________________________________________________________________________ ____________________________________________________________________________________
До 8 баллов за решение задачи с обоснованием.
7.Определите обществоведческий термин на основе предложенного текста:
1. Времена кризиса нередко сопровождаются снижением покупательной способности денежной единицы.
2. На протяжении жизни человек может изменить свое положение в общество, которое он занимает в соответствии со своим возрастом, полом, происхождением, профессией, семейным положением.
За каждый правильный ответ 2 балла .Всего 4 балла
8. Реши кроссворд.
По горизонтали
4. Сокращение производства реального ввп, продолжающееся 6 или более месяцев
Сокращение производства реального ввп, продолжающееся 6 или более месяцев
6. Денежные средства, ценности, запасы, возможности, источники средств, доходов
9. Ситуация на рынке, когда несколько крупных конкурирующих фирм монополизируют производство и сбыт основной массы продукции в отрасли
10. Автор книги Исследование о природе и причинах богатства народов
15. Выраженные в денежной форме затраты организации на производство и реализацию продукции
18. Искусство управлять домашним хозяйством
21. Совокупность научно обоснованных правил, методов и принципов управления
По вертикали
1. Полезная деятельность, выполненная за деньги
2. Один из основоположников теории макроанализа
3. Продолжительный либо глубокий и резкий экономический спад
5. Подкрепленное денежной возможностью желание, намерение покупателей, потребителей приобрести данный товар
7. Процесс принятия решений, организация производства, контроль за деятельностью людей
8. Группа предприятий, производящих одинаковые продукты, использующих сходную технологию или одинаковое сырье
Группа предприятий, производящих одинаковые продукты, использующих сходную технологию или одинаковое сырье
11. Ситуация на рынке, когда одна компания выступает монополистом в области купли-продажи товаров и услуг
12. Любой институт или механизм, который сводит вместе покупателей и продавцов
13. Самостоятельный хозяйственный субъект, созданный в установленном законом порядке
14. Продукт труда, произведенный для купли-продажи
16. Отрасль экономической науки, изучающая такие экономические явления, как экономический рост, инфляция, безработица, конкуренция
17. Организация, обеспечивающая регулярное функционирование рынка товаров, валюты, ценных бумаг, рабочей силы и т.д
19. Знания и сведения, накопленные человечеством и необходимые для его жизнедеятельности
20. Вложение в реальные объекты предпринимательской деятельности, приносящие эффект и доход
По 1 баллу за правильную позицию. Всего 21 балл.
Тест по теме: “Познание и его виды”
Автор: andryushkevitchyulia · Опубликовано · Обновлено
Познание и его виды
- Установите соответствие между формами познания и видами познания:
А) ощущение Б) восприятие В) суждение Г) понятие Д) представление
Рациональное 2. Чувственное - Ниже приведен ряд терминов. Все они, за исключением двух, относятся к методам научного познания.
Теория 2. Наблюдение 3. Эксперимент 4. Проблема 5. Классификация 7. Систематизация - Найдите в приведенном списке характеристики чувственного познания.
Фиксация существенных свойств предмета 2. Сохранение в памяти обобщённого образа предмета 3. Утверждение или отрицание наличия у предмета каких- либо свойств 4. Отражение отдельных свойств предмета 5. Отражение предметов и их свойств в виде целостного образа 6. Создание новых суждений о предмете на основе уже имеющихся - Найдите в приведенном списке характеристики рационального познания:
Отражение в сознании человека внешних свойств предмета 2. Отражение предметов и их свойств в виде целостного образа 3. Фиксация существенных свойств предмета 4. Сохранение в памяти обобщенного образа предмета 5. Утверждение или отрицание наличия у предмета каких – либо свойств 6. Логический вывод новых суждений о предмете на основе имеющихся
Отражение предметов и их свойств в виде целостного образа 3. Фиксация существенных свойств предмета 4. Сохранение в памяти обобщенного образа предмета 5. Утверждение или отрицание наличия у предмета каких – либо свойств 6. Логический вывод новых суждений о предмете на основе имеющихся - Ниже приведен ряд терминов. Все они, за исключением двух, относятся к чувственному познанию.
Ощущение цвета, вкуса, запаха 2. Абстрактность 3. Наглядность 4. Обобщенность 5. Предметность 6. Воспроизведение внешних сторон и свойств объектов - Верны ли суждения о чувственном познании:
А) чувственное познание присущи всем живым существам Б) чувственное познание дает полное и исчерпывающее знание о предмете
Верно только а 2. Верно только б 3. Верны оба суждения 4. Оба суждения неверны - Верны ли суждения о чувственном познании:
А) одной из форм чувственного познания является восприятие Б) чувственное познание в сравнении с рациональным полнее и точнее отражает предмет изучения
Верно только а 2. Верно только б 3. Верны оба суждения 4. Оба суждения неверны
Верно только б 3. Верны оба суждения 4. Оба суждения неверны - Установите соответствие между видами и формами познания:
А) отражение вещей явлений, процессов в их существенных и отличительных признаках
Б) отражение отдельных свойств предмета, непосредственно воздействующих на человека
В) возникновение образа предмета, в данный момент не воспринимаемого
Г) утверждение или отрицание чего – либо о предметах, явлениях, их свойствах и отношениях
Д) отражение целостных образов предметов и являющих при их непосредственном воздействии на рецепторы
Чувственное 2. Рациональное - Верны ли суждения о рациональном познании:
Рациональное познание присуще только человеку
2. Одной из форм рационального познания является представление
3. Рациональное познание дает полное и исчерпывающее знание о предмете
4. Рациональное познание в отличие от чувственного способно привести к относительной истине - Исходным элементом рационального познания является понятие
- Установите соответствие между формами и этапами познания:
1. Чувственное познание 2. Рациональное познание
Чувственное познание 2. Рациональное познание
А) ощущение Б) понятие В) восприятие Г) представление Д) суждение - Установите соответствие между формами и этапами познания:
1. Чувственное познание 2. Рациональное познание
А) понятие Б) ощущение В) представление Г) суждение Д) умозаключение - Выберите верные суждения о познании:
1. Для чувственного этапа познания свойственно воспроизведение внешних сторон и свойств объектов
2. Рациональное познание позволяет выявить существенные признаки и связи объектов, закономерности их изменения
3. Чувственное познание предполагает непосредственный контакт органов чувств с познаваемым предметом
4. К формам чувственного познания относят понятия и суждения
5. Формами рационального познания являются ощущения, восприятия, представления - Выберите обобщающий термин:
1. Ощущение 2. Чувственное познание 3. Представление 4. Восприятие 5. Образ объекта - Выберите верные суждения о познании:
1. Для чувственного этапа познания свойственно воспроизведение внешних сторон и свойств объектов
Для чувственного этапа познания свойственно воспроизведение внешних сторон и свойств объектов
2. Благодаря ощущениям происходит выделение общего, существенного в информации о предмете
3. Чувственное и рациональное познание взаимосвязаны
4. Рациональное познание позволяет выявить существенные признаки и связи объектов, закономерности
5. Формами рационального познания являются ощущения, восприятия, представленияСкачать (DOCX, 14KB)
Автор публикации
4 Комментарии: 0Публикации: 293Регистрация: 28-12-2017Константность восприятия: определение термина, функции и значение, примеры
07.02.2019 Зорян Фрейдович Психология
Восприятие помогает человеку познать объективную действительность. Константность, которая является одним из основных его свойств, выражается в постоянстве цвета, формы и величины предметов, а также обеспечивает индивиду познание окружающего мира.
Восприятие и его свойства
Восприятие по своей сущности относится к сложному психическому процессу, которое заключается в целостном отражении явлений и предметов, действующих в определенное время на органы чувств. Условно восприятие представляют как совокупность мышления, памяти и ощущений. Специалисты выделяют следующие свойства восприятия:
Предлагаем рассмотреть каждый из вышеперечисленных свойств наиболее подробно.
Предметность
С помощью предметности и константности восприятия человек не способен воспринимать окружающую действительность в виде набора различных ощущений. А вместо этого он видит и различает отдельные друг от друга предметы, которые обладают определенными свойствами, вызывающими эти ощущения. После долгого изучения и проведения различных экспериментов ученые пришли к выводу, что отсутствие предметности восприятия способно вызвать дезориентацию в пространстве, нарушение восприятия цвета, формы и движения, а также галлюцинации и другие психические отклонения.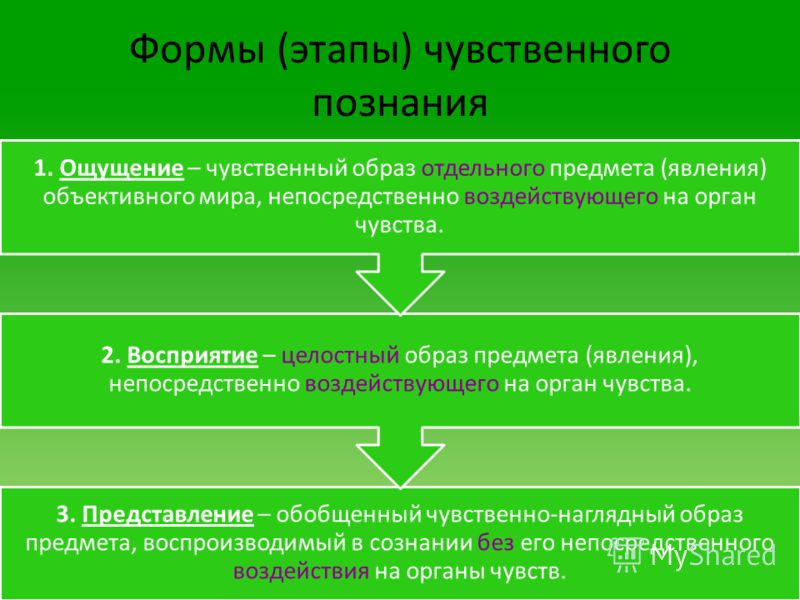
Один из таких подобных экспериментов заключался в следующем: испытуемого поместили в ванну с физиологическим раствором комфортной для него температуры, где его восприятие было ограничено. Он лишь видел блеклый белый свет и слышал монотонные отдаленные звуки, а покрытия на его руках мешали получить осязательные ощущения. Спустя несколько часов пребывания в таком состоянии у человека нарастало тревожное состояние, после которого он просил прекратить опыт. Во время эксперимента испытуемые отмечали отклонения в восприятии времени и галлюцинации.
Целостность
Стоит отметить, что целостность и константность восприятия взаимосвязаны между собой. Данное свойство восприятия позволяет создать целостный образ предмета, при помощи обобщенной полученной информации об отдельных качествах и признаков предмета. Благодаря целостности мы способны воспринимать определенным образом организованную действительность, а не хаотическое скопление прикосновений, отдельных звуков и цветовых пятен. Например, при прослушивании музыки нашему восприятию подвластно слышать не отдельные звуки (колебания частот), а мелодию в целом. Так и со всем происходящем — мы видим, слышим и чувствуем целостную картину, а не отдельные части происходящего.
Например, при прослушивании музыки нашему восприятию подвластно слышать не отдельные звуки (колебания частот), а мелодию в целом. Так и со всем происходящем — мы видим, слышим и чувствуем целостную картину, а не отдельные части происходящего.
Осмысленность
Суть этого свойства заключается в том, чтобы дать воспринимаемому явлению или объекту определенный смысл, обозначить его словом, а также отнести к определенной языковой группе, исходя из багажа знаний субъекта и его прошлого опыта. Одной из самых простых форм осмысливания явлений и предметов считается узнавание.
Швейцарский психолог Герман Роршах выявил, что даже случайные чернильные пятна воспринимаются человеком как что-то осмысленное (озеро, облако, цветы и т. д.), и только людям с психическими отклонениями свойственно воспринимать их просто как абстрактные пятна. Из этого следует, что восприятие осмысленности протекает в качестве процесса поиска ответов на вопрос: «Что это?».
Структурность
Это свойство помогает человеку объединять воздействующие стимулы в сравнительно простые и целостные структуры. Благодаря устойчивым признакам объектов человек способен узнавать и различать их. Внешне различные, но по существу однообразные предметы опознаются как таковые при помощи отражения их структурной организации.
Благодаря устойчивым признакам объектов человек способен узнавать и различать их. Внешне различные, но по существу однообразные предметы опознаются как таковые при помощи отражения их структурной организации.
Обобщенность
Определенное обобщение можно проследить в каждом процессе восприятия, а степень обобщения связана непосредственно с уровнем и объемом знаний. Например, белый цветок с шипами осознается человеком как роза, или как представитель семейства разноцветных. В обобщении главную роль играет слово, а называние синонимом определенного предмета помогает повысить уровень обобщения восприятия.
Избирательность
Подразумевает преимущественное выделение определенных объектов по отношению к другим, обусловленное отличительными чертами субъекта восприятия: его мотивами, потребностями, опытом и др. Из многочисленного количества окружающих нас явлений и предметов человек выделяет в определенный момент лишь некоторые из них, а остальные остаются лишь фоном. Константность восприятия, осмысленность, избирательность и другие его свойства имеют огромное биологическое значение. В противном случае существование и адаптация человека были бы невозможны в окружающей мире, если бы восприятие не отражало ее постоянных и стабильных свойств.
В противном случае существование и адаптация человека были бы невозможны в окружающей мире, если бы восприятие не отражало ее постоянных и стабильных свойств.
Константность
Целостность восприятия имеет тесную связь с константностью, под которой следует понимать относительную независимость определенных свойств предметов от их отображений на рецепторные поверхности. При помощи константности мы имеем возможность воспринимать явления и предметы как относительно постоянные по положению, величине, цвету и форме.
В психологии константность восприятия — это стабильность принятия разнообразных свойств явлений или предметов, сохраняющиеся при разных физических изменениях стимуляции: интенсивности скорости, расстояния, света и многого другого.
Значимость константности
Оа помогает индивиду различать размеры определенных предметов, его объективную форму, цвет и угол зрения воспринимаемых объектов. В качестве примера константности восприятия можно привести следующее: только представьте, если наше восприятие не имело бы такого свойства, то при каждом движении любой предмет потерял бы свои свойства.
В этом случае, вместо определенных вещей мы бы видели лишь постоянное мерцание непрерывно уменьшающихся и увеличивающихся, сдвигающихся, растягивающихся и сплющивающихся бликов и пятен невообразимой пестроты. При этом раскладе человеку не удалось бы воспринимать мир устойчивых объектов и явлений, что, соответственно, не смогло бы служить в качестве средства познания объективной действительности.
Таким образом, константность восприятия — это свойство перцептивного образа сохранять относительную неизменность при изменении условий восприятия, отсутствие которого привело бы к сплошному хаосу. Именно поэтому ученые уделяют данному аспекту особое внимание.
Константность восприятия: виды константности
Специалисты выделяют достаточно больше количество видов. Это свойство восприятия имеет место почти для любого воспринимаемых характеристик предмета. Рассмотрим самые популярные прямо сейчас.
Стабильность видимого мира
Одним из самых важных и фундаментальных среди видов константности является стабильность окружающего мира. Специалисты также называют этот вид константностью зрительного направления. Его суть заключается в следующем: при движении взгляда наблюдателя или его самого движущимся кажется сам человек, а окружающие его предметы воспринимаются неподвижными. Стоит отметить, что постоянным и воспринимаемым нами является и вес предмета. Несмотря на то, поднимаем ли мы груз всем телом, ногой, одной или двумя руками — оценка веса предмета будет примерно одинаковой.
Специалисты также называют этот вид константностью зрительного направления. Его суть заключается в следующем: при движении взгляда наблюдателя или его самого движущимся кажется сам человек, а окружающие его предметы воспринимаются неподвижными. Стоит отметить, что постоянным и воспринимаемым нами является и вес предмета. Несмотря на то, поднимаем ли мы груз всем телом, ногой, одной или двумя руками — оценка веса предмета будет примерно одинаковой.
Константность формы
Искажения восприятия формы предметов можно встретить в том случае, когда изменяется ориентация объектов или же самого субъекта. Этот вид является одним из важных свойств зрительной системы, так как правильное распознавание формы предметов— необходимое условие адекватного взаимодействия человека с окружающим миром. Одним из первых, кто выявил роль знаний наблюдателя и признаков удаленности в константности формы, стал Роберт Таулесс.
В 1931 г. психологом был проведен эксперимент, суть которого заключалась в следующем: он предложил испытуемым оценить и нарисовать или подобрать из определенного набора квадраты или круги, которые бы были похожи по форме на предложенные предметы, лежащие на горизонтальной поверхности на разном расстоянии от наблюдателя. В результате опыта испытуемые выбирали форму стимула, которая не совпадала ни с проекционной формой, ни с его реальной, а лежала между ними.
В результате опыта испытуемые выбирали форму стимула, которая не совпадала ни с проекционной формой, ни с его реальной, а лежала между ними.
Восприятие скорости
Считается, чем ближе траектория движения, тем выше станет скорость смещения ретинальной картины объектов.
Поэтому два далеко расположенных предмета кажутся медленнее, чем в реальном измерении. Воспринимаемая скорость близлежащих вещей зависит от феноменального расстояния, проходимого в единицу времени и, как правило, существенно не меняется.
Константность цвето- и светоощущения
Под константностью цвета подразумевается способность зрения корректировать восприятие цвета предметов, например, при естественном освещении в любое время суток или при изменении спектра их освещения, например, при выходе их темного помещения. Специалисты пришли к мнению, что механизм константности восприятия является приобретенным.
Об этом свидетельствует ряд исследований. В одном эксперименте ученые провели исследование на людях, постоянно проживающих в густом лесу. Их восприятие представляет интерес, так как ранее они не встречали объектов на большой дистанции. Когда наблюдавшим показали предметы, которые находились на большом расстоянии от них, им показались эти объекты не как удаленные, а как маленькие.
Их восприятие представляет интерес, так как ранее они не встречали объектов на большой дистанции. Когда наблюдавшим показали предметы, которые находились на большом расстоянии от них, им показались эти объекты не как удаленные, а как маленькие.
Аналогичные нарушения константности можно заметить у жителей равнин, когда они смотрят на объекты вниз с высоты. К тому же, из верхнего этажа высотного дома автомобили или проходящие люди кажутся нам крошечных размеров. Стоит отметить, что у ребенка с двух лет начинают формироваться такие виды константности, как величины, формы и цвета. К тому же, они имеют свойство совершенствоваться вплоть до четырнадцати лет.
Константность величины
Известным фактом является то, что изображение предмета, а также изображение его на сетчатке, уменьшается, когда дистанция до него увеличивается, и наоборот. Но несмотря на то, что при варьировании расстояния наблюдения величина предметов на сетчатке глаза изменяется, его воспринимаемые размеры остаются практически неизменными. К примеру, посмотрите на зрителей в кинотеатре: все лица нам будут казаться практически одинаковыми по величине, при всем том, что изображения лиц, находящихся далеко, намного меньше, чем расположенных близко от нас.
К примеру, посмотрите на зрителей в кинотеатре: все лица нам будут казаться практически одинаковыми по величине, при всем том, что изображения лиц, находящихся далеко, намного меньше, чем расположенных близко от нас.
В заключение
Ключевым источником константности является активная деятельность перцептивной системы. Ей удается корректировать и исправлять различные ошибки, вызванные многообразием окружающего мира предметов, а также создавать адекватные образы восприятия. Примером тому может стать следующее: если надеть очки и зайти в незнакомое помещение, то можно проследить, как зрительное восприятие будет искажать изображения и предметы, но спустя некоторое время человек перестает замечать искажения, вызванные очками, хотя они и будут отражаться на сетчатке глаза.
Адекватное соотношение между отображенными в восприятии предметами окружающего мира и самим восприятием ─ это главное соотношение, в результате которого регулируются все соотношения между состояниями сознания, раздражениями и раздражителями. Таким образом следует сделать вывод, что константность восприятия, формирующаяся в процессе предметной деятельности, можно считать необходимым условием жизни и деятельности человека. Без данного свойства восприятия любому человеку было бы сложно ориентироваться в изменчивом и бесконечно многообразном мире.
Таким образом следует сделать вывод, что константность восприятия, формирующаяся в процессе предметной деятельности, можно считать необходимым условием жизни и деятельности человека. Без данного свойства восприятия любому человеку было бы сложно ориентироваться в изменчивом и бесконечно многообразном мире.
Источник: fb.ru
Назовите четыре свойства образов восприятия и конкретизируйте их пояснениями (сначала назовите свойство, затем приведите пояснение).
Ощущение — это отражение отдельных, элементарных свойств (признаков) предмета и явлений окружающего мира при их непосредственном воздействии в данный момент на органы чувств человека. В реальной жизни ощущения отдельно, сами по себе, как правило, не существуют: они входят в сложные процессы восприятия, лежат в основе представления, воображения. Но именно с них начинаются эти сложные психические процессы. Поэтому ощущения выделяют из психической деятельности человека, рассматривают и изучают как относительно самостоятельный простейший психический процесс.
Из разных ощущений складываются целостные психические образы, к ним относятся образы восприятия и образы представления. Восприятие — это наглядно-образное отражение действующих в данный момент на органы чувств вещей, предметов, а не отдельных их свойств и признаков. Образы восприятия обладают рядом важных свойств. Образ восприятия — это целостное, осознанное отражение познаваемого предмета или явления психики. В образе восприятия отражается объект познания, а не процессы, происходящие в нервной системе человека, которые приводят к созданию этого образа. Создаваемый у человека образ восприятия недоступен постороннему наблюдателю и имеет существенные различия у разных людей. Они зависят от особенностей человека, от его убеждений и установок, от его жизненного опыта и знаний, обученности и способностей, от его интересов и того смысла, который имеет для него познание данного предмета или явления; наконец, от его настроения в данный момент.
Образы представления — психические образы не воспринимаемых в данный момент предметов или явлений, которые основаны на прошлом их восприятии. Иными словами, образы представления — это образы памяти. Образы представления существенно отличаются от соответствующих им образов восприятия, на основе которых они возникли. Если образы восприятия — результат одномоментного процесса и при исчезновении предмета восприятия исчезает образ восприятия (он или забывается, или же переходит в образ представления), то образы представления сохраняются долгое время. При этом они не остаются неизменными: с течением времени они приобретают более абстрактный, обобщённый характер.
Иными словами, образы представления — это образы памяти. Образы представления существенно отличаются от соответствующих им образов восприятия, на основе которых они возникли. Если образы восприятия — результат одномоментного процесса и при исчезновении предмета восприятия исчезает образ восприятия (он или забывается, или же переходит в образ представления), то образы представления сохраняются долгое время. При этом они не остаются неизменными: с течением времени они приобретают более абстрактный, обобщённый характер.
(Т.С. Назарова, Е.М. Тихомирова, И.Ю. Кудина и др.)
Тест по обществознанию ЕГЭ Человек
Тест по обществознанию ЕГЭ.
Блок № 1 «Человек».
Часть 1.
Ответами к заданиям 1–20 являются слово (словосочетание), цифра или последовательность цифр. Запишите ответы в поля ответов в тексте работы, а затем перенесите их в БЛАНК ОТВЕТОВ № 1 справа от номеров соответствующих заданий, начиная с первой клеточки, без пробелов, запятых и других дополнительных символов. Каждый символ пишите в отдельной клеточке в соответствии с приведёнными в бланке образцами.
Каждый символ пишите в отдельной клеточке в соответствии с приведёнными в бланке образцами.
З
1
апишите слово, пропущенное в приведенной ниже схеме.Ответ: __________________________________________________.
Н
2
айдите понятие, которое является обобщающим для всех остальных понятий представленного ниже ряда, и запишите цифру, под которой оно указано.1) мировоззрение; 2) миропонимание; 3) мировосприятие; 4) мироощущение.
О
3
твет:Ниже приведены потребности человека. Все из них, за исключением двух, являются социальными потребностями.
1) В трудовой деятельности; 2) в созидании; 3) в творчестве; 4) во взаимопонимании; 5) в отдыхе; 6) в пище.
Найдите два термина, «выпадающих» из общего ряда, и запишите в таблицу цифры, под которыми они указаны.
Ответ:В
4
ыберите верные суждения о деятельности человека и запишите цифры, под которыми они указаны.
1) Компонентами структуры любой деятельности являются средства, мотивы, эмоции.
2) Познавательная деятельность в отличие от коммуникативной. предполагает использование понятий и терминов.
3) Культура является результатом преобразующей деятельности человека.
4) Деятельность человека в отличие от поведения животных носит осознанный целенаправленный характер.
5) Трудовая деятельность является ведущей на протяжении всей жизни человека.
Ответ: _________________________.
У
5
становите соответствие между проявлениями качеств человека и природой этих качеств: к каждой позиции, данной в первом столбце, подберите соответствующую позицию из второго столбца.ПРОЯВЛЕНИЯ КАЧЕСТВ ЧЕЛОВЕКА ПРИРОДА КАЧЕСТВ
А) способность к продолжению рода 1) социальная
Б) способность приспосабливаться 2) биологическая
к условиям природной среды
В) способность накапливать знания
и трудовые навыки
Г) способность видеть цель своих действий
Д) способность оценивать себя и других
Запишите в таблицу выбранные цифры под соответствующими буквами.
М
6
ария поставила своей целью посетить Англию, пообщаться с англичанами. Она изучает английский язык, читает книги об истории и культуре Англии, на интернет-форумах общается со знатоками английского искусства. Она уже спланировала маршрут своего путешествия и приобрела путёвку.Найдите в приведённом списке примеры средств, используемых Марией для достижения указанной цели, и запишите цифры, под которыми они указаны.1) изучение английского языка
2) покупка туристической путёвки
3) желание общаться в Интернете
4) чтение книг об истории и культуре Англии
5) знатоки английского искусства
6) путешествие по Англии
Ответ: _______________________________.
В
7
ыберите верные суждения о самооценке личности и запишите цифры, под которыми они указаны.1) Самооценка выступает исходной точкой самопознания.
2) Человек формирует самооценку, сравнивая себя с другими.
3) Завышенная самооценка личности всегда является результатом ее реальных достижений.
4) Люди с низкой самооценкой проводят сравнение с другими, только будучи уверенными в успехе.
5) Заниженная самооценка способствует развитию лидерских качеств.
Ответ: ______________________________.
У
8
становите соответствие между примерами и видами потребностей: к каждой позиции, данной в первом столбце, подберите соответствующую позицию из второго столбца.ПРИМЕРЫ ВИДЫ ПОТРЕБНОСТЕЙ
А) отдых и сон 1) социальные
Б) общение 2) духовные
В) принадлежность к определённой группе 3) биологические
Г) познание мира
Д) осознание смысла своего существования
Запишите в таблицу выбранные цифры под соответствующими буквами.
Ответ:9
Найдите в приведенном ниже списке характеристики чувственного познания. Запишите цифры, под которыми они указаны.
Запишите цифры, под которыми они указаны.
1) отображение целостного образа непосредственно воздействующего предмета
2) отражение отдельных свойств предметов, воспринимаемых в данный момент
3) установление взаимосвязи различных понятий
4) обобщение и выделение группы предметов на основе общих признаков
5) получение новых суждений на основе уже имеющихся
6) сохранение в памяти целостного образа предмета
Ответ: _________________________________.
З
10
апишите слово, пропущенное в таблице.Ответ: __________________________________.
В
11
ыберите верные суждения о соотношении биологического и социального в человеке и запишите цифры, под которыми они указаны. 1) Последовательность основных стадий жизни человека, при которой детство сменяется зрелостью, а затем наступает старость, биологически обусловлена.
2) Становление человека как личности связано с приобретением социальных черт и качеств.
3) Человек наследует моральные ценности, также как задатки к определённым видам деятельности.
4) Влияние генетических факторов на развитие способностей человека служит выражением его социальной сущности.
5) Природная предрасположенность человека к тем или иным видам деятельности проявляется в социальных обстоятельствах.
Ответ: ___________________________________.
У
12
ченые опросили 25-летних и 60-летних жителей города Z. Им задавали вопрос: «Природа или общество определяют, по вашему мнению, способности человека?». Полученные результаты (в % от числа опрошенных) представлены в таблице.Найдите в приведенном списке выводы, которые можно сделать на основе таблицы, и запишите цифры, под которыми они указаны.
1) С возрастом увеличивается доля тех, кто считает, что способности определяются природой.
2) Около трети опрошенных в обеих группах затруднились с ответом на вопрос.
3) С возрастом увеличивается доля людей, считающих, что окружение раскрывает способности человека.
4) Около четверти опрошенных в обеих группах считают, что природные задатки могут быть не востребованы человеком.
5) Большинство опрошенных в обеих группах полагают, что способности человека открывает и развивает его окружение.
О
13
твет: ________________________________________.Выберите верные суждения о соотношении свободы, необходимости и ответственности в деятельности человека и запишите цифры, под которыми они указаны.
1) Многообразие выбора ограничивает свободу в деятельности человека.
2) Одним из проявлений необходимости в деятельности человека выступают объективные законы развития природы.
3) Ответственность человека повышается в условиях ограниченного выбора стратегий поведения в определенных ситуациях.
4) Неограниченная свобода является безусловным благом для человека и общества.
5) Готовность человека оценивать свои действия с точки зрения их последствий для окружающих служит одним из проявлений чувства ответственности.
У
14
становите соответствие между особенностями и видами деятельности: к каждой позиции, данной в первом столбце, подберите соответствующую позицию из второго столбца.Запишите в таблицу выбранные цифры под соответствующими буквами.
Ответ:15
Одиннадцатиклассники завершают изучение нового материала и начинают подготовку к экзаменам. Какие признаки характеризуют осуществляемую ими деятельность? Запишите цифры, под которыми они указаны. | |||
|
|
Ответ: _________________________________.
Ч
16
то из перечисленного ниже относится к социальным потребностям человека? Запишите цифры под которыми они указаны.1) потребность в общении
2) потребность в сне
3) потребность в достижении статуса
4) потребность в пище
5) потребность в труде
Ответ: _________________________________.
У
17
становите соответствие между особенностями и видами познания: к каждой позиции, данной в первом столбце, подберите соответствующую позицию из второго столбца.Запишите в таблицу выбранные цифры под соответствующими буквами.
Ответ:18
Иван выполнял задание по теме: «Человек как результат биологической и социокультурной эволюции». Он выписывал из учебника черты, свойственные человеку. Какие из них отражают специфику социальной природы человека, в отличие от животного? Запишите цифры, под которыми они указаны.
1) способность к целеполаганию
2) стремление понять окружающий мир
3) использование предметов, данных природой
4) приспособление к условиям окружающей среды
5) общение с помощью членораздельной речи
6) забота о потомстве
Ответ: __________________________________.
19
Старшеклассники организовали шефство над ветеранами Великой Отечественной войны, проживающими в микрорайоне школы. Они покупают продукты, лекарства, оказывают посильную помощь пожилым людям по хозяйству. Ребята организуют встречи с ветеранами, собирают их воспоминания и пополняют экспонатами школьный музей. Какие из приведённых ниже характеристик соответствуют проиллюстрированному данным примером виду деятельности? Запишите цифры, под которыми они указаны.
1)активное влияние на социализацию подростков
2)ценностно-ориентировочная деятельность
3)условный характер деятельности
4)прогностическая деятельность
5)целью деятельности в первую очередь является создание материального продукта
6)материально-производственная деятельность
Ответ: ________________________.
20
Прочитайте приведённый ниже текст, в котором пропущен ряд слов. Выберите из предлагаемого списка слова, которые необходимо вставить на место пропусков.
«Мировоззрение — система обобщенных взглядов на мир и место _______________(А) в нем, на отношение людей к окружающей их действительности и самим себе, а также обусловленные этими взглядами основные _______________(Б) людей, их убеждения, идеалы, принципы познания и деятельности, ценностные ориентации. Мировоззрение – это далеко не все взгляды и _______________(В) об окружающем мире, а только их предельное обобщение. Содержание мировоззрения группируется вокруг того или иного решения _______________(Г) философии. В качестве _______________(Д) мировоззрения реально выступают группа и личность. Мировоззрение является ядром общественного и индивидуального сознания. Выработка мировоззрения — существенный показатель зрелости не только личности, но и определенной _______________(Е), общественного класса. По своей сущности мировоззрение — общественно-политический феномен, возникший с появлением человеческого общества. »
»
Слова в списке даны в именительном падеже. Каждое слово может быть использовано только один раз.
Выбирайте последовательно одно слово за другим, мысленно заполняя каждый пропуск. Обратите внимание на то, что слов в списке больше, чем Вам потребуется для заполнения пропусков.
Список терминов:
1) предметы
2) субъект
3) социальная группа
4) жизненные позиции
5) человек
6) рассудок
7) способности
8) представления
9) основной вопрос
В данной ниже таблице приведены буквы, обозначающие пропущенные слова. Запишите в таблицу под каждой буквой номер, выбранного Вами слова.
Ответ:Не забудьте перенести все ответы в бланк ответов № 1 в соответствии с инструкцией по выполнению работы.
Часть 2.
Для записи ответов на задания этой части (21–29) используйте БЛАНК ОТВЕТОВ № 2. Запишите сначала номер задания (21, 22 и т.д.), а затем развёрнутый ответ на него. |
 Ответы записывайте чётко и разборчиво.
Ответы записывайте чётко и разборчиво. Прочитайте текст и выполните задания 21–24. |
«Общение – сложный многоплановый процесс установления и развития контактов и связей между людьми, порождаемый потребностями совместной деятельности и включающий в себя обмен информацией и выработку единой стратегии и взаимодействия.
Общение обычно включено в практическое взаимодействие людей (совместный труд, учение, коллективная игра и т.п.) и обеспечивает планирование, осуществление и контролирование их деятельности.
Если отношения определяются через понятия «связи», то общение понимают как процесс взаимодействия человека с человеком, осуществляемый с помощью средств речевого и неречевого воздействия и преследующий цель достижения изменений в мотивационной, эмоциональной и поведенческой сферах участвующих в общении лиц. В ходе общения его участники обмениваются не только своими физическими действиями или продуктами, результатами труда, но и мыслями, намерениями, идеями, переживаниями и т. д. В повседневной жизни человек учится общению с детства, овладевает разными его видами в зависимости от среды, в которой живёт, от людей, с которыми взаимодействует, причем происходит это стихийно, в житейском опыте. В большинстве случаев этого опыта бывает недостаточно для овладения особыми профессиями (педагога, актера, диктора, следователя), а иногда и просто для продуктивного и цивилизованного общения.
д. В повседневной жизни человек учится общению с детства, овладевает разными его видами в зависимости от среды, в которой живёт, от людей, с которыми взаимодействует, причем происходит это стихийно, в житейском опыте. В большинстве случаев этого опыта бывает недостаточно для овладения особыми профессиями (педагога, актера, диктора, следователя), а иногда и просто для продуктивного и цивилизованного общения.
По этой причине необходимо совершенствовать знание его закономерностей, накапливать навыки и умения их учета и использования.
Каждая общность людей располагает своими средствами воздействия, которые используются в разнообразных формах коллективной жизни. В них концентрируется социально-психологическое содержание образа жизни. Все это проявляется в обычаях, ритуалах, праздниках, танцах, песнях, сказаниях, мифах, в изобразительном, театральном и музыкальном искусстве, в художественной литературе, кино, радио и телевидении. Эти своеобразные массовые формы общения обладают мощным потенциалом взаимовлияния людей. В истории человечества они всегда служили средствами воспитания,… включения человека через общение в духовную атмосферу жизни.
В истории человечества они всегда служили средствами воспитания,… включения человека через общение в духовную атмосферу жизни.
Проблема человека находится в центре внимания всех аспектов общения. Увлечение лишь инструментальной стороной общения может нивелировать его духовную (человеческую) сущность и привести к упрощенной трактовке общения как информационно-коммуникативной деятельности. При неизбежном научно-аналитическом расчленении общения на составляющие элементы важно не терять в них человека как духовную и активную силу, преобразующую в этом процессе себя и других.
Общение по своему содержанию – сложнейшая психологическая деятельность партнеров».
(В.Г. Крысько)
Н
21
а основе текста назовите три характеристики понятия «общение».Ч
22
то, по мнению автора, влияет на обучение человека продуктивному и цивилизованному общению? (Назовите на основе текста любые три фактора влияния).П
23
о мнению автора, увлечение лишь инструментальной стороной общения (обменом информацией) может заслонить его духовную (человеческую) сущность. Опираясь на текст, знания курса и личный социальный опыт, приведите три аргумента, подтверждающих ограниченность понимания общения только как информационно-коммуникативной деятельности.
Опираясь на текст, знания курса и личный социальный опыт, приведите три аргумента, подтверждающих ограниченность понимания общения только как информационно-коммуникативной деятельности.А
24
втор указывает на «своеобразные массовые формы общения, которые в истории всегда служили средством воспитания, включения человека через общение в духовную атмосферу жизни». Опираясь на текст, знания истории, обществознания, социальный опыт, назовите любые две формы коллективного общения. Объясните на примерах, в чем проявляется воздействие каждой из них на людей.К
25
26
акой смысл обществоведы вкладывают в понятие «мышление»? Привлекая знания обществоведческого курса, составьте два предложения: одно предложение, содержащее информацию об основных операциях (приёмах) мышления, и одно предложение, раскрывающее творческий характер мышления.Назовите и проиллюстрируйте примерами любые три вида знаний.
У
27
ченые наблюдали за чайками, которые защищали от опасности птенцов. Когда в их колонию проникали хищники, взрослые птицы издавали крик, взлетали и атаковали хищника — могли даже ударить его одной или обеими лапами, когда он приближался к гнезду. Можно ли назвать данные действия животных целенаправленными? Опираясь на знание курса, приведите обоснование своего ответа и укажите любое принципиальное отличие описанных действий животных от защиты своих детей человеком.
Когда в их колонию проникали хищники, взрослые птицы издавали крик, взлетали и атаковали хищника — могли даже ударить его одной или обеими лапами, когда он приближался к гнезду. Можно ли назвать данные действия животных целенаправленными? Опираясь на знание курса, приведите обоснование своего ответа и укажите любое принципиальное отличие описанных действий животных от защиты своих детей человеком.В
28
ам поручено подготовить развёрнутый ответ по теме «Роль мировоззрения в жизни человека». Составьте план, в соответствии с которым Вы будете освещать эту тему. План должен содержать не менее трёх пунктов, из которых два или более детализированы в подпунктах.Выполняя задание 29, Вы можете проявить свои знания и умения на том содержании, которое для Вас более привлекательно. С этой целью выберите только ОДНО из предложенных ниже высказываний (29.1–29.5). |
29
Выберите одно из предложенных ниже высказываний, раскройте его смысл в форме мини-сочинения, обозначив при необходимости разные аспекты поставленной автором проблемы (затронутой темы).
При изложении своих мыслей по поводу поднятой проблемы (обозначенной темы), при аргументации своей точки зрения используйте знания, полученные при изучении курса обществознания, соответствующие понятия, а также факты общественной жизни и собственный жизненный опыт. (В качестве фактической аргументации приведите не менее двух примеров из различных источников.)
Природное и общественное в человеке | «Свойства личности никак не сводятся к её индивидуальным особенностям. Они включают и общее, и особенное, и единичное». (С.Л. Рубинштейн) |
Мировоззрение и его виды и формы | «Измени отношение к вещам, которые тебя беспокоят, и ты будешь от них в безопасности» (Марк Аврелий) |
Виды знаний | «Знание – сокровищница, но ключ к ней – практика». (Т. Фуллер). |
Понятие истины и ее критерии | «Заблуждение всегда противоречит себе, истина – никогда» (К. Гельвеций). |
Мышление и деятельность | «Особенностью живого ума является то, что ему нужно лишь немного увидеть и услышать для того, чтобы он мог потом долго размышлять и многое понять. » (Джордано Бруно) |
Потребности и интересы | Что нужно нам — того не знаем мы, Что ж знаем мы — того для нас не надо. (Иоганн Вольфганг Гете) |
Свобода и необходимость | Свободы хотят все. Но так кажется только со стороны. На самом же деле в глубине души свободы не хочет никто. Свобода подобна горному воздуху. Для слабых она непереносима. (Рюноскэ Акутагава) |

Обнаружение целостного вложенного края с помощью OpenCV и глубокого обучения
Щелкните здесь, чтобы загрузить исходный код этого сообщения
В этом руководстве вы узнаете, как применить обнаружение целостного вложенного края (HED) с OpenCV и глубоким обучением. Мы применим Holistically-Nested Edge Detection как к изображениям, так и к видеопотокам, а затем сравним результаты со стандартным детектором Canny Edge в OpenCV.
Обнаружение краев позволяет нам находить границы объектов на изображениях и было одним из первых примеров прикладного использования обработки изображений и компьютерного зрения.
Когда дело доходит до обнаружения краев с помощью OpenCV, вы, скорее всего, будете использовать детектор краев Canny; однако у есть несколько проблем с детектором края Canny, а именно:
- Установка нижних и верхних значений порога гистерезиса — это ручной процесс , который требует экспериментов и визуальной проверки.
- Пороговые значения гистерезиса, которые хорошо работают для одного изображения, могут не работать для другого (это почти всегда верно для изображений, снятых в различных условиях освещения).
- Детектор границ Canny часто требует ряда шагов предварительной обработки (например, преобразование в оттенки серого, размытие / сглаживание и т. Д.) Для получения хорошей карты границ.
Holistically-Nested Edge Detection (HED) пытается устранить ограничения краевого детектора Canny через сквозную глубокую нейронную сеть .
Эта сеть принимает изображение RGB в качестве входа и затем создает карту границ в качестве выхода. Кроме того, карта краев, созданная HED, лучше сохраняет границы объектов на изображении.
Чтобы узнать больше о целостном обнаружении краев с помощью OpenCV, просто продолжайте читать!
Обнаружение целостного вложенного края с помощью OpenCV и глубокого обучения
В этом руководстве мы узнаем о Holistically-Nested Edge Detection (HED) с использованием OpenCV и глубокого обучения.
Мы начнем с обсуждения алгоритма Holistically-Nested Edge Detection.
После этого мы рассмотрим структуру нашего проекта, а затем будем использовать HED для обнаружения краев как в изображениях , так и в видео .
Давай, приступим!
Что такое обнаружение целостного вложенного края?
Рисунок 1: Обнаружение целостных вложенных границ с помощью OpenCV и глубокого обучения (источник: Се и Ту, 2015 г. , рис. 1)
, рис. 1) Алгоритм, который мы будем использовать сегодня, взят из статьи Се и Ту 2015 г., Обнаружение целостных вложений , или просто «HED» для краткости.
В работе Се и Ту описывается глубокая нейронная сеть, способная автоматически изучать богатые иерархические карты границ, которые способны определять границу края / объекта объектов на изображениях.
Эта сеть обнаружения границ способна получать самые современные результаты на наборах данных Berkely BSDS500 и NYU Depth.
Полный обзор сетевой архитектуры и алгоритма выходит за рамки этой публикации, поэтому, пожалуйста, обратитесь к официальной публикации для получения более подробной информации.
Структура проекта
Возьмите сегодня «Загрузок» и распакуйте файлы.
Оттуда вы можете проверить каталог проекта с помощью следующей команды:
$ tree --dirsfirst .├── hed_model │ ├── deploy.prototxt │ └── hed_pretrained_bsds.caffemodel ├── изображения │ ├── cat.jpg │ ├── guitar.jpg │ └── janie.jpg ├── detect_edges_image.py └── detect_edges_video.py 2 каталога, 7 файлов
Наша модель HED Caffe включена в каталог hed_model / .
Я предоставил несколько образцов изображений / , включая мое изображение, изображение моей собаки и образец изображения кошки, которое я нашел в Интернете.
Сегодня мы рассмотрим сценарии detect_edges_image.py и detect_edges_video.py . Оба сценария используют один и тот же процесс обнаружения краев, поэтому большую часть времени мы будем тратить на сценарий изображения HED.
Обнаружение целостного вложенного края в изображениях
Пример Python и OpenCV Holistically-Nested Edge Detection, который мы рассматриваем сегодня, очень похож на пример HED в официальном репозитории OpenCV.
Мой основной вклад здесь:
- Предоставьте дополнительную документацию (при необходимости)
- И, что наиболее важно, покажет вам, как использовать Holistically-Nested Edge Detection в ваших собственных проектах.
Давайте продолжим и начнем — откройте файл detect_edge_image.py и вставьте следующий код:
# импортируем необходимые пакеты
import argparse
импорт cv2
импорт ОС
# создать парсер аргументов и проанализировать аргументы
ap = argparse.ArgumentParser ()
ap.add_argument ("- d", "--edge-Detector", type = str, required = True,
help = "путь к детектору границ глубокого обучения OpenCV")
ap. add_argument ("- i", "--image", type = str, required = True,
help = "путь к входному изображению")
args = vars (ap.parse_args ())
add_argument ("- i", "--image", type = str, required = True,
help = "путь к входному изображению")
args = vars (ap.parse_args ())
Наш импорт обрабатывается на строках 2-4 . Мы будем использовать argparse для анализа аргументов командной строки. Доступ к функциям и методам OpenCV осуществляется через импорт cv2 . Наш импорт os позволит нам создавать пути к файлам независимо от операционной системы.
Для этого сценария требуются два аргумента командной строки:
-
--edge-Detector: путь к детектору границ глубокого обучения OpenCV. Путь содержит два файла Caffe, которые позже будут использоваться для инициализации нашей модели. -
--image: путь к входному изображению для тестирования. Как я уже говорил ранее — я предоставил несколько изображений в «Загрузки» , но вам следует попробовать сценарий и на своих собственных изображениях.
Давайте определим наш класс CropLayer :
класс CropLayer (объект): def __init __ (self, params, blobs): # инициализируем начальную и конечную (x, y) -координаты # урожай self.startX = 0 я.startY = 0 self.endX = 0 self.endY = 0
Чтобы использовать модель Holistically-Nested Edge Detection с OpenCV, нам нужно определить собственный класс обрезки слоя — мы соответствующим образом назовем этот класс CropLayer .
В конструкторе этого класса мы сохраняем начальную и конечную (x, y) -координаты того места, где урожай будет начинаться и заканчиваться, соответственно ( строки 15–21, ).
Следующим шагом при применении HED с OpenCV является определение функции getMemoryShapes , метода, отвечающего за вычисление размера тома входов :
def getMemoryShapes (себя, входы): # слой обрезки получит два входа - нам нужно обрезать # первый входной BLOB-объект должен соответствовать форме второго, # сохранение размера пакета и количества каналов (inputShape, targetShape) = (входы [0], входы [1]) (batchSize, numChannels) = (inputShape [0], inputShape [1]) (H, W) = (targetShape [2], targetShape [3]) # вычисляем начальные и конечные координаты урожая я.startX = int ((inputShape [3] - targetShape [3]) / 2) self.startY = int ((inputShape [2] - targetShape [2]) / 2) self.endX = self.startX + W self.endY = self.startY + H # вернуть форму объема (мы выполним фактический # обрезка во время прямого прохода return [[batchSize, numChannels, H, W]]
Строка 27 определяет форму входного объема, а также целевую форму.
Строка 28 также извлекает размер пакета и количество каналов из входов .
Наконец, Line 29 извлекает высоту и ширину целевой формы соответственно.
Учитывая эти переменные, мы можем вычислить начальную и конечную координаты урожая (x, y) на строках 32-35 .
Затем мы возвращаем форму объема вызывающей функции в , строка 39 .
Последний метод, который нам нужно определить, — это функция forward . Эта функция отвечает за выполнение обрезки во время прямого прохода (т. е.е., вывод / прогнозирование края) сети:
е.е., вывод / прогнозирование края) сети:
def вперед (себя, входы): # используем производные (x, y) -координаты для обрезки return [входы [0] [:,:, self.startY: self.endY, self.startX: self.endX]]
Строки 43 и 44 используют преимущества удобного синтаксиса нарезки списков / массивов Python и NumPy.
Учитывая наш класс CropLayer , теперь мы можем загрузить нашу модель HED с диска и зарегистрировать CropLayer с сетью :
# загружаем наш сериализованный детектор края с диска
print ("[ИНФОРМАЦИЯ] детектор края загрузки. .. ")
protoPath = os.path.sep.join ([args ["edge_detector"],
"deploy.prototxt"])
modelPath = os.path.sep.join ([args ["edge_detector"],
"hed_pretrained_bsds.caffemodel"])
net = cv2.dnn.readNetFromCaffe (protoPath, modelPath)
# регистрируем наш новый слой с моделью
cv2.dnn_registerLayer ("Обрезка", CropLayer)
.. ")
protoPath = os.path.sep.join ([args ["edge_detector"],
"deploy.prototxt"])
modelPath = os.path.sep.join ([args ["edge_detector"],
"hed_pretrained_bsds.caffemodel"])
net = cv2.dnn.readNetFromCaffe (protoPath, modelPath)
# регистрируем наш новый слой с моделью
cv2.dnn_registerLayer ("Обрезка", CropLayer)
Наш путь к прототипу и путь к модели строятся с использованием аргумента командной строки --edge-detect , доступного через args ["edge_detector"] ( строки 48-51 ).
Отсюда и protoPath , и modelPath используются для загрузки и инициализации нашей модели Caffe на Line 52 .
Давайте продолжим и загрузим наш вход изображение :
# загружаем исходное изображение и получаем его размеры image = cv2.imread (args ["изображение"]) (H, W) = image.shape [: 2] # преобразовать изображение в оттенки серого, размыть его и выполнить Canny # обнаружение края print ("[ИНФОРМАЦИЯ] выполняет обнаружение края Canny... ") серый = cv2.cvtColor (изображение, cv2.COLOR_BGR2GRAY) размытый = cv2.GaussianBlur (серый, (5, 5), 0) canny = cv2.Canny (размытый, 30, 150)
Наше исходное изображение загружено, и пространственные размеры (ширина и высота) извлекаются в строках 58 и 59 .
Мы также вычисляем карту контуров Canny ( строк 64-66 ), чтобы мы могли сравнить наши результаты обнаружения границ с HED.
Наконец, мы готовы применить HED:
# создать blob из входного изображения для Holistically-Nested # Детектор края blob = cv2.dnn.blobFromImage (изображение, scalefactor = 1.0, size = (W, H), среднее = (104,00698793, 116,66876762, 122,678), swapRB = Ложь, обрезка = Ложь) # установить blob как вход в сеть и выполнить прямой проход # для вычисления ребер print ("[ИНФОРМАЦИЯ] выполняет целостное обнаружение краев ...") net.setInput (большой двоичный объект) hed = net.forward () hed = cv2.resize (hed [0, 0], (W, H)) hed = (255 * hed) .astype ("uint8") # показать результаты обнаружения края вывода для Canny и # Целостное обнаружение вложенных краев cv2.imshow ("Ввод", изображение) cv2.imshow ("Хитрый", хитрый) cv2.imshow ("HED", hed) cv2.waitKey (0)
Для применения Holistically-Nested Edge Detection (HED) с OpenCV и глубоким обучением мы:
- Создайте
blobиз нашего изображения ( строк 70-72 ). - Пропустите BLOB-объект через сеть HED, получив выход
hed(, строки 77 и 78, ).
- Измените размер вывода до наших исходных размеров изображения (, строка 79, ).
- Масштабируйте пиксели нашего изображения до диапазона [0, 255] и убедитесь, что тип равен
«uint8»(, строка 80, ).
Наконец, мы отобразим:
- Исходное входное изображение
- Изображение обнаружения края Canny
- Наши результаты обнаружения целостного вложенного края
Изображение и результаты HED
Чтобы применить обнаружение целостного вложенного края к вашим собственным изображениям с помощью OpenCV, убедитесь, что вы используете раздел «Загрузки» этого руководства, чтобы получить исходный код, обученную модель HED и примеры файлов изображений.Оттуда откройте терминал и выполните следующую команду:
$ python detect_edges_image.Рисунок 2: Обнаружение краев с помощью подхода HED с OpenCV и глубоким обучением (источник входного изображения).py --edge-Detector hed_model --image images / cat.jpg [ИНФОРМАЦИЯ] датчик края загрузки ... [ИНФОРМАЦИЯ] выполняется обнаружение края Canny ... [ИНФОРМАЦИЯ] выполнение целостного обнаружения краев ...
Слева у нас есть входное изображение.
В центре находится кромочный датчик Canny.
А на справа — наш окончательный результат после применения Holistically-Nested Edge Detection.
Обратите внимание, что детектор Canny edge не может сохранить границу объекта: кошка, горы или камень, на котором сидит кошка.
HED, с другой стороны, может сохранить все эти границы объекта.
Давайте попробуем другое изображение:
$ python detect_edges_image.Рисунок 3: Я играю на гитаре в своем офисе ( слева, ). Обнаружение канни края ( центр ). Обнаружение целостного вложенного края ( справа ).py --edge-Detector hed_model --image images / guitar.jpg [ИНФОРМАЦИЯ] датчик края загрузки ... [ИНФОРМАЦИЯ] выполняется обнаружение края Canny ... [ИНФОРМАЦИЯ] выполнение целостного обнаружения краев ...
На Рис. 3 выше мы можем видеть пример изображения, на котором я играю на гитаре. С детектором кромок Canny возникает много «шума», вызванного текстурой и рисунком ковра — HED, напротив, не имеет такого шума.
Более того, HED лучше справляется с захватом границ объектов моей рубашки, джинсов (включая дырку в джинсах) и моей гитары.
Рассмотрим последний пример:
$ python detect_edges_image.Рисунок 4: Моя гончая, Джени, проходит метод Canny и Holistically-Nested Edge Detection (HED) с помощью OpenCV и глубокого обучения.py --edge-Detector hed_model --image images / janie.jpg [ИНФОРМАЦИЯ] датчик края загрузки ... [ИНФОРМАЦИЯ] выполняется обнаружение края Canny ... [ИНФОРМАЦИЯ] выполнение целостного обнаружения краев ...
На этом изображении есть два объекта: (1) Джени, собака, и (2) стул позади нее.
Детектор края Canny ( в центре ) делает разумную работу, выделяя очертания стула, но не может должным образом уловить границу объекта собаки, в основном из-за переходов свет / темнота и темнота / свет в ее пальто. .
HED ( справа, ) может легче запечатлеть весь контур Джени.
Обнаружение целостных границ в видео
Мы применили обнаружение целостного вложенного края к изображениям с помощью OpenCV. Можно ли сделать то же самое для видео?
Давай узнаем.
Откройте файл detect_edges_video. и вставьте следующий код:  py
py
# импортируем необходимые пакеты
из imutils.video импорт VideoStream
import argparse
импорт imutils
время импорта
импорт cv2
импорт ОС
# создать парсер аргументов и проанализировать аргументы
ap = argparse.ArgumentParser ()
ap.add_argument ("- d", "--edge-Detector", type = str, required = True,
help = "путь к детектору границ глубокого обучения OpenCV")
ap.add_argument ("- i", "--input", type = str,
help = "путь к необязательному входному видео (в противном случае будет использоваться веб-камера)")
args = vars (ap.parse_args ())
Для нашего сценария видео требуется три дополнительных импорта:
-
VideoStream: считывает кадры из источника входного сигнала, например веб-камеры, видеофайла или другого источника.
-
imutils: Мой пакет вспомогательных функций, который я сделал доступным на GitHub и PyPi. Мы используем мою функциюresize. -
время: Этот модуль позволяет нам разместить команду сна, чтобы наш видеопоток установился и «разогрелся».
Два аргумента командной строки в строках 10-15 очень похожи:
-
--edge-Detector: путь к краевому детектору OpenCV HED. -
--input: необязательный путь к входному видеофайлу. Если путь не указан, будет использоваться веб-камера.
Наш класс CropLayer идентичен тому, который мы определили ранее:
класс CropLayer (объект): def __init __ (self, params, blobs): # инициализируем начальную и конечную (x, y) -координаты # урожай я.startX = 0 self.startY = 0 self.endX = 0 self.endY = 0 def getMemoryShapes (себя, входы): # слой обрезки получит два входа - нам нужно обрезать # первый входной BLOB-объект должен соответствовать форме второго, # сохранение размера пакета и количества каналов (inputShape, targetShape) = (входы [0], входы [1]) (batchSize, numChannels) = (inputShape [0], inputShape [1]) (H, W) = (targetShape [2], targetShape [3]) # вычисляем начальные и конечные координаты урожая я.startX = int ((inputShape [3] - targetShape [3]) / 2) self.startY = int ((inputShape [2] - targetShape [2]) / 2) self.endX = self.startX + W self.endY = self.startY + H # вернуть форму объема (мы выполним фактический # обрезка во время прямого прохода return [[batchSize, numChannels, H, W]] def вперед (себя, входы): # используем производные (x, y) -координаты для обрезки return [входы [0] [:,:, self.startY: self.endY, я.startX: self.endX]]
После определения нашего идентичного класса CropLayer , мы продолжим и инициализируем наш видеопоток и модель HED:
# инициализируем логическое значение, используемое для обозначения веб-камеры или входа
# видео используется
webcam = not args.get ("input"; False)
# если путь к видео не был указан, возьмите ссылку на веб-камеру
если веб-камера:
print ("[ИНФОРМАЦИЯ] запускает видеопоток ...")
vs = VideoStream (src = 0) .start ()
время.сон (2,0)
# в противном случае получить ссылку на видео файл
еще:
print ("[ИНФОРМАЦИЯ] открытие видеофайла ...")
vs = cv2.VideoCapture (args ["ввод"])
# загружаем наш сериализованный детектор края с диска
print ("[ИНФОРМАЦИЯ] детектор края загрузки ...")
protoPath = os.path.sep.join ([args ["edge_detector"],
"deploy.prototxt"])
modelPath = os.path.sep.join ([args ["edge_detector"],
"hed_pretrained_bsds.caffemodel"])
net = cv2.dnn.readNetFromCaffe (protoPath, modelPath)
# регистрируем наш новый слой с моделью
cv2.dnn_registerLayer ("Обрезка", CropLayer)
Независимо от того, выберем ли мы нашу веб-камеру или видеофайл, сценарий будет динамически работать для любого из них (, строки 51-62, ).
Наша модель HED загружена, и CropLayer зарегистрирован на строках 65-73 .
Давайте получим кадры в цикле и применим обнаружение краев!
# зацикливать кадры из видеопотока в то время как True: # взять следующий кадр и обработать, если мы читаем из любого # VideoCapture или VideoStream кадр = vs.читать() frame = frame, если веб-камера else frame [1] # если мы просматриваем видео и не захватили кадр, то мы # достигли конца видео если нет веб-камеры и рамки нет: сломать # изменить размер кадра и получить его размеры frame = imutils.resize (рамка, ширина = 500) (H, W) = frame.shape [: 2]
Начинаем перебирать кадры на строках 76-80 . Если мы дойдем до конца видеофайла (что происходит, когда кадр равен Нет ), мы выйдем из цикла (, строки 84 и 85, ).
Строки 88 и 89 изменяют размер нашего кадра так, чтобы он имел ширину 500 пикселей. Затем мы получаем размеры рамки после изменения размера.
Теперь давайте обработаем кадр точно , как в нашем предыдущем скрипте:
# преобразовать кадр в оттенки серого, размыть его и выполнить Canny
# обнаружение края
серый = cv2.cvtColor (рамка, cv2.COLOR_BGR2GRAY)
размытый = cv2.GaussianBlur (серый, (5, 5), 0)
canny = cv2.Canny (размытый, 30, 150)
# конструируем blob из входного фрейма для Holistically-Nested
# Edge Detector, установите blob и выполните прямой проход к
# вычисляем края
blob = cv2.dnn.blobFromImage (кадр, scalefactor = 1.0, size = (W, H),
среднее = (104,00698793, 116,66876762, 122,678),
swapRB = Ложь, обрезка = Ложь)
net.setInput (большой двоичный объект)
hed = net.forward ()
hed = cv2.resize (hed [0, 0], (W, H))
hed = (255 * hed) .astype ("uint8")
Обнаружение края Canny ( строк 93-95, ) и обнаружение края HED ( строк 100-106 ) вычисляются по входному кадру.
Оттуда мы отобразим результаты обнаружения края:
# показать результаты обнаружения края вывода для Canny и
# Целостное обнаружение вложенных краев
cv2.imshow ("Рамка", рамка)
cv2.imshow ("Хитрый", хитрый)
cv2.imshow ("HED", hed)
ключ = cv2.waitKey (1) & 0xFF
# если была нажата клавиша `q`, выйти из цикла
если ключ == ord ("q"):
сломать
# если мы используем веб-камеру, остановите видеопоток камеры
если веб-камера:
против остановки ()
# в противном случае отпустить указатель видеофайла
еще:
по сравнению с выпуском ()
# закрыть все открытые окна
cv2.destroyAllWindows ()
Наши три выходных кадра отображаются в строках 110-112 : (1) исходный кадр с измененным размером, (2) результат обнаружения края Canny и (3) результат HED.
нажатия клавиш фиксируются через , строка 113 . Если нажать "q" , мы прервем цикл и очистим (, строки 116-128, ).
Видео и результаты HED
Итак, как Holistically-Nested Edge Detection работает в реальном времени с OpenCV?
Давай узнаем.
Обязательно используйте раздел «Загрузки» этого сообщения в блоге, чтобы загрузить исходный код и модель HED.
Оттуда откройте терминал и выполните следующую команду:
$ python detect_edges_video.py - детектор края hed_model [INFO] запуск видеопотока ... [ИНФОРМАЦИЯ] датчик края загрузки ...
В приведенной выше короткой демонстрации в формате GIF вы можете увидеть демонстрацию модели HED в действии.
Обратите внимание, в частности, на то, как граница лампы на заднем плане полностью теряется при использовании детектора края Canny; однако при использовании HED граница сохраняется.
С точки зрения производительности, я использовал свой Intel Xeon W 3 ГГц, когда собирал демо выше.Мы достигаем производительности процессора в режиме реального времени, используя модель HED.
Для получения истинной производительности в реальном времени вам понадобится графический процессор; Однако имейте в виду, что поддержка графическим процессором модуля «dnn» OpenCV особенно ограничена (в частности, графические процессоры NVIDIA в настоящее время не поддерживаются).
А пока вы можете рассмотреть возможность использования привязок Caffe + Python, если вам нужна производительность в реальном времени.
Сводка
В этом руководстве вы узнали, как выполнять обнаружение целостного вложенного края (HED) с использованием OpenCV и глубокого обучения.
В отличие от детектора края Canny, который требует шагов предварительной обработки, ручной настройки параметров и часто не работает с изображениями, снятыми при различных условиях освещения, Holistically-Nested Edge Detection стремится создать сквозную границу для глубокого обучения. детектор.
Как показывают наши результаты, выходные карты границ, созданные HED, лучше справляются с задачей сохранения границ объекта, чем простой детектор границ Canny. Целостно вложенное обнаружение краев потенциально может заменить обнаружение краев Canny в приложениях, где окружающая среда и условия освещения потенциально неизвестны или просто не поддаются контролю.
Обратной стороной является то, что HED на значительно на вычислительно дороже, чем Canny. Детектор края Canny может работать на ЦП в супер-реальном времени; однако для работы в реальном времени с HED потребуется графический процессор.
Надеюсь, вам понравился сегодняшний пост!
Чтобы загрузить исходный код этого руководства и получать уведомления о публикации будущих руководств на PyImageSearch, просто введите свой адрес электронной почты в форму ниже!
Загрузите исходный код и БЕСПЛАТНОЕ 17-страничное руководство по ресурсам
Мягкое руководство по обнаружению объектов глубокого обучения
Сегодняшний пост в блоге вдохновлен читателем PyImageSearch Иезекиилем, который написал мне на прошлой неделе и спросил:
Привет, Адриан,
Я просмотрел вашу предыдущую запись в блоге об обнаружении объектов глубокого обучения по
с последующим руководством по обнаружению объектов глубокого обучения в реальном времени.Спасибо за это.Я использовал ваш исходный код в своих примерах проектов, но у меня возникли две проблемы:
- Как мне отфильтровать / игнорировать классы, которые меня не интересуют?
- Как мне добавить новые классы в детектор объектов? Это вообще возможно?
Я был бы очень признателен, если бы вы осветили это в своем блоге.
Спасибо.
Иезекииль — не единственный, кто задает эти вопросы. Фактически, если вы просмотрите раздел комментариев к двум моим последним сообщениям об обнаружении объектов глубокого обучения (ссылка приведена выше), вы обнаружите, что один из наиболее распространенных вопросов обычно (перефразированный):
Как мне изменить исходный код, чтобы включить в него мои собственные классы объектов?
Так как это, кажется, очень распространенный вопрос, а в конечном итоге является непониманием того, как на самом деле работают нейронные сети / детекторы объектов глубокого обучения , я решил вернуться к теме обнаружения объектов глубокого обучения в сегодняшнем сообщении в блоге.
В частности, из этого поста вы узнаете:
- Различия между классификацией изображений и обнаружением объектов
- Компоненты детектора объектов глубокого обучения , включая различия между платформой обнаружения объектов n и самой базовой моделью
- Как выполнить обнаружение объектов глубокого обучения с помощью предварительно обученной модели
- Как вы можете фильтровать и игнорировать предсказанные классы из модели глубокого обучения
- Распространенные заблуждения и недопонимания при добавлении или удалении классов из глубокой нейронной сети
Чтобы узнать больше об обнаружении объектов глубокого обучения и, возможно, даже развенчать некоторые неправильные представления или недопонимания, которые могут возникнуть при обнаружении объектов на основе глубокого обучения, просто продолжайте читать.
Мягкое руководство по обнаружению объектов глубокого обучения
Сегодняшняя запись в блоге предназначена для мягкого введения в обнаружение объектов на основе глубокого обучения.
Я сделал все возможное, чтобы предоставить обзор компонентов детекторов объектов глубокого обучения, включая исходный код OpenCV + Python для выполнения глубокого обучения с использованием предварительно обученного детектора объектов.
Используйте это руководство, чтобы помочь вам начать работу с обнаружением объектов глубокого обучения, но также понять, что обнаружение объектов очень тонко и детально. — я не мог включить каждую деталь обнаружения объектов глубокого обучения в отдельную запись в блоге.
Тем не менее, мы начнем сегодняшнюю запись в блоге с обсуждения фундаментальных различий между классификацией изображений и обнаружением объектов , включая то, может ли сеть, обученная классификации изображений, использоваться для обнаружения объектов (и при каких обстоятельствах).
Как только мы поймем, что такое обнаружение объектов, мы рассмотрим основные компоненты детектора объектов с глубоким обучением, в том числе структуру обнаружения объектов и базовую модель , два ключевых компонента, которые читатели, плохо знакомые с обнаружением объектов, обычно неправильно понимают .
После этого мы реализуем обнаружение объектов глубокого обучения в реальном времени с помощью OpenCV.
Я также продемонстрирую, как можно игнорировать и фильтровать классы объектов, которые вас не интересуют , без необходимости изменять архитектуру сети или переобучать модель.
Наконец, мы завершим сегодняшнее сообщение в блоге, обсудив, как можно добавить или удалить классы из детектора объектов глубокого обучения , включая рекомендуемые мной ресурсы, которые помогут вам начать работу.
Давайте продолжим и погрузимся в обнаружение объектов глубокого обучения!
Разница между классификацией изображений и обнаружением объектов
Рисунок 1: Разница между классификацией ( слева, ) и обнаружением объектов ( справа, ) интуитивно понятна и проста. Для классификации изображений все изображение классифицируется с помощью одной метки . В случае обнаружения объекта наша нейронная сеть локализует (потенциально несколько) объектов внутри изображения.При выполнении стандартной классификации изображений , учитывая входное изображение, мы представляем его нашей нейронной сети и получаем метку единственного класса и, возможно, вероятность, также связанную с меткой класса.
Эта метка класса предназначена для характеристики содержимого всего изображения или, по крайней мере, наиболее доминирующего видимого содержимого изображения.
Например, учитывая входное изображение в , рис. 1, выше ( слева, ) наша CNN пометила изображение как «бигль» .
Таким образом, мы можем думать о классификации изображений как:
- Одно изображение на
- и один ярлык класса
Обнаружение объектов , независимо от того, выполняется ли это с помощью глубокого обучения или других методов компьютерного зрения, основывается на классификации изображений и пытается локализовать именно там, где на изображении появляется каждый объект.
При обнаружении объекта по входному изображению мы хотим получить:
- Список ограничивающих рамок или (x, y) -координаты для каждого объекта на изображении
- Метка класса , связанная с каждой ограничивающей рамкой
- Оценка вероятности / достоверности , связанная с каждой ограничивающей рамкой и меткой класса
Рисунок 1 ( справа, ) демонстрирует пример выполнения обнаружения объектов глубокого обучения.Обратите внимание, как и человек, и собака локализованы с предсказанными ограничивающими рамками и метками классов.
Следовательно, обнаружение объектов позволяет нам:
- Вывести одно изображение в сеть
- и получают несколько ограничивающих рамок и меток классов
Можно ли использовать классификатор изображений с глубоким обучением для обнаружения объектов?
Рисунок 2: Непрерывный детектор объектов глубокого обучения использует подход «скользящее окно» ( слева, ) + пирамида изображений ( справа, ) в сочетании с классификацией.Хорошо, теперь вы понимаете фундаментальную разницу между классификацией изображений и обнаружением объектов :
- При выполнении классификации изображений мы представляем одно входное изображение в сеть и получаем одну метку класса.
- Но при выполнении обнаружения объекта мы можем представить одно входное изображение и получить несколько ограничивающих рамок и меток классов.
Это мотивирует вопрос:
Можем ли мы взять сеть, уже обученную классификации, и использовать ее для обнаружения объектов?
Ответ немного сложен, поскольку технически это «Да» , но по не столь очевидным причинам.
Решения включают:
- Применение стандартных методов обнаружения объектов на основе компьютерного зрения (то есть методов без глубокого обучения), таких как скользящих окон и пирамид изображений — этот метод обычно используется в ваших детекторах объектов на основе HOG + Linear SVM.
- Принимая предварительно обученную сеть и , используя ее в качестве базовой сети в структуре обнаружения объектов глубокого обучения (то есть, Faster R-CNN, SSD, YOLO).
Метод № 1. Традиционный конвейер обнаружения объектов
Первый метод — это , а не , чистый сквозной детектор объектов глубокого обучения.
Вместо этого мы используем:
- Раздвижные окна фиксированного размера , которые скользят слева направо и сверху вниз для локализации объектов в разных местах
- Пирамида изображений для обнаружения объектов разного масштаба
- Классификация с помощью предварительно обученной (классификационной) сверточной нейронной сети
На каждой остановке скользящего окна + пирамиды изображений мы извлекаем ROI, передаем ее в CNN и получаем выходную классификацию для ROI.
Если вероятность классификации метки L выше некоторого порогового значения T , мы помечаем ограничивающий прямоугольник ROI как метку ( L ). Повторяя этот процесс для каждой остановки скользящего окна и пирамиды изображений, мы получаем выходные детекторы объектов. Наконец, мы применяем подавление не максимальных значений к ограничивающим прямоугольникам, что дает наши окончательные выходные данные:
Рисунок 3: Применение подавления не максимальных значений подавит перекрывающиеся, менее надежные ограничивающие рамки.Этот метод может работать в некоторых конкретных случаях использования, но в целом он медленный, утомительный и немного подвержен ошибкам.
Тем не менее, стоит научиться применять этот метод, поскольку он может превратить произвольную сеть классификации изображений в детектор объектов, избегая необходимости явно обучать детектор объектов сквозного глубокого обучения. Этот метод может сэкономить вам массу времени и усилий в зависимости от вашего варианта использования.
Если вас интересует этот метод обнаружения объектов и вы хотите узнать больше о подходе к обнаружению объектов «скользящее окно + пирамида изображений + классификация изображений», обратитесь к моей книге Deep Learning for Computer Vision with Python .
Метод № 2: Базовая сеть инфраструктуры обнаружения объектов
Второй метод обнаружения объектов глубокого обучения позволяет рассматривать вашу предварительно обученную классификационную сеть как базовую сеть в среде обнаружения объектов глубокого обучения (например, Faster R-CNN, SSD или YOLO).
Преимущество здесь в том, что вы можете создать полный детектор объектов на основе сквозного глубокого обучения.
Обратной стороной является то, что для этого требуется немного глубоких знаний о том, как работают детекторы объектов глубокого обучения — мы обсудим это подробнее в следующем разделе.
Компоненты детектора объектов глубокого обучения
Рис. 4: Базовая сеть VGG16 является компонентом инфраструктуры обнаружения объектов глубокого обучения SSD.Существует , много компонентов, подкомпонентов и подкомпонентов детектора объектов глубокого обучения, но два, на которых мы собираемся сегодня сосредоточиться, — это два, которые большинство читателей, плохо знакомых с обнаружением объектов глубокого обучения, часто путают:
- Среда обнаружения объектов (например,Быстрее R-CNN, SSD, YOLO).
- Базовая сеть , которая вписывается в структуру обнаружения объектов.
Базовая сеть , с которой вы, вероятно, уже знакомы (вы просто не слышали раньше, чтобы на нее ссылались как на «базовую сеть»).
Базовые сети — это ваши общие (классификационные) архитектуры CNN, в том числе:
- VGGNet
- ResNet
- MobileNet
- DenseNet
Обычно эти сети предварительно обучены выполнять классификацию на большом наборе данных изображений, таком как ImageNet, чтобы изучить богатый набор различающих, различающих фильтров.
Среды обнаружения объектов состоят из множества компонентов и подкомпонентов.
Например, структура Faster R-CNN включает:
- Региональная сеть предложений (РПН)
- Набор анкеров
- Модуль объединения областей интересов (ROI)
- Окончательная сверточная нейронная сеть на основе регионов
При использовании Single Shot Detectors (SSD) у вас есть компоненты и подкомпоненты, такие как:
- MultiBox
- Приоры
- Фиксированные приоры
Имейте в виду, что базовая сеть — это лишь один из многих компонентов , которые вписываются в общую структуру обнаружения объектов глубокого обучения — На рисунке 4 в верхней части этого раздела изображена базовая сеть VGG16 внутри структуры SSD.
Обычно «сетевая операция» выполняется в базовой сети. Данная модификация:
- Делает его полностью сверточным (т.е. принимает произвольные входные размеры).
- Устраняет более глубокие уровни CONV / POOL в базовой сетевой архитектуре и заменяет их серией новых уровней (SSD), новыми модулями (Faster R-CNN) или некоторой их комбинацией.
Термин «сетевая хирургия» — это разговорный способ сказать, что мы удаляем некоторые из исходных слоев базовой сетевой архитектуры и заменяем их новыми уровнями.
Вы, вероятно, видели малобюджетные фильмы ужасов, где убийца, вероятно, вооруженный топором или большим ножом, нападает на свою жертву и бесцеремонно рубит ее.
Сетевая хирургия более точна и требовательна, чем типичный убийца из фильмов ужасов B.
Сетевая хирургия также очень тактична — мы удаляем части сети, которые нам не нужны, и заменяем их новым набором компонентов.
Затем, когда мы перейдем к обучению нашей платформы для выполнения обнаружения объектов, изменяются веса (1) новых слоев / модулей и (2) базовой сети.
Опять же, полный обзор того, как работают различные фреймворки для обнаружения объектов глубокого обучения (включая роль, которую играет базовая сеть), выходит за рамки этого сообщения в блоге.
Если вас интересует полный обзор обнаружения объектов глубокого обучения, включая теорию и реализацию, обратитесь к моей книге Deep Learning for Computer Vision with Python .
Как измерить точность детектора объектов глубокого обучения?
При оценке производительности детектора объектов мы используем метрику оценки, называемую , средняя точность (mAP), которая основана на пересечении через соединение (IoU) для всех классов в нашем наборе данных.
Пересечение над Союзом (IoU)
Рисунок 5: В этом наглядном примере пересечения через Union (IoU) ограничивающий прямоугольник наземной истинности ( зеленый, ) можно сравнить с предсказанным ограничивающим прямоугольником ( красный ). IoU используется со средней средней точностью (mAP) для оценки точности детектора объектов глубокого обучения. Простое уравнение для расчета IoU показано на справа .Обычно IoU и mAP используются для оценки производительности детекторов HOG + Linear SVM, каскадов Хаара и методов, основанных на глубоком обучении; однако имейте в виду, что фактический алгоритм, используемый для создания предсказанных ограничивающих рамок, не имеет значения.
Любой алгоритм, который предоставляет предсказанные ограничивающие рамки (и, возможно, метки классов) в качестве выходных данных, можно оценить с помощью IoU. Более формально, чтобы применить IoU для оценки детектора произвольных объектов, нам нужно:
- Наземные ограничивающие прямоугольники (т. Е. Помеченные вручную ограничивающие прямоугольники из нашего набора для тестирования, которые указывают, где находится изображение нашего объекта).
- Предсказанные ограничивающие рамки нашей модели.
- Если вы хотите вычислить отзыв наряду с точностью, вам также понадобятся метки класса достоверности и метки предсказанного класса.
На рис. 5 ( слева, ) я включил наглядный пример ограничивающей рамки наземной истинности (, зеленый, ) по сравнению с предсказанной ограничивающей рамкой (, красный, ). Вычисление IoU может быть определено с помощью уравнения на рис. , рис. 5, ( справа, ).
Изучив это уравнение, вы увидите, что IoU — это просто отношение.
В числителе мы вычисляем область перекрытия между предсказанной ограничивающей рамкой и ограничивающей рамкой на основе истинного значения.
Знаменатель — это площадь объединения, или, проще говоря, площадь, охватываемая как прогнозируемой ограничивающей рамкой, так и ограничивающей рамкой наземной истины.
Разделение области перекрытия на область объединения дает окончательный результат — пересечение над объединением.
Среднее значение средней точности (MAP)
Примечание: Я решил отредактировать этот раздел из его первоначального вида. Я хотел сохранить обсуждение mAP на более высоком уровне и избежать некоторых из более запутанных расчетов воспоминаний, но, как отметили несколько комментаторов, этот раздел был технически некорректным.Из-за этого я решил обновить пост.
Поскольку это мягкое введение в обнаружение объектов на основе глубокого обучения, я оставлю объяснение mAP в упрощенном виде, чтобы вы поняли основы.
Читателей и практиков, плохо знакомых с обнаружением объектов, может ввести в заблуждение расчет MAP. Частично это связано с тем, что MAP является более сложной метрикой оценки. Это также определение расчета MAP может даже варьироваться от одной задачи обнаружения объекта к другой (когда я говорю «задача обнаружения объекта», я имею в виду соревнования, такие как COCO, PASCAL VOC и т. Д.).
Вычисление средней точности (AP) для конкретного конвейера обнаружения объектов — это, по сути, трехэтапный процесс:
- Вычислите точность , которая представляет собой долю истинных положительных результатов.
- Вычислите отзыв , который представляет собой долю истинных положительных результатов от всех возможных положительных результатов.
- Усредните вместе максимальное значение точности на всех уровнях отзыва с шагом с.
Для вычисления точности мы сначала применяем наш алгоритм обнаружения объектов к входному изображению.Затем оценки ограничивающей рамки сортируются в порядке убывания их достоверности.
Мы знаем из априорных знаний (т.е. это пример проверки / тестирования и, следовательно, мы знаем общее количество объектов на изображении), что на этом изображении есть 4 объекта. Мы стремимся определить, сколько «правильных» обнаружений сделала наша сеть. «Правильный» прогноз здесь — это прогноз, при котором минимальное значение IoU равно 0,5 (это значение настраивается в зависимости от задачи, но 0,5 является стандартным значением).
Здесь вычисления начинают немного усложняться. Нам необходимо вычислить точность при различных значениях повторного вызова (также называемых «уровнями отзыва» или «шагами отзыва»).
Например, представим, что мы вычисляем значения точности и запоминания для трех самых популярных прогнозов. Из трех основных прогнозов нашего детектора объектов глубокого обучения мы сделали 2 правильных. Наша точность — это доля истинных положительных результатов: 2/3 = 0,667. Наш отзыв — это доля истинных положительных результатов из всех возможных положительных результатов на изображении: 2/4 = 0.5. Мы повторяем этот процесс (обычно) для прогнозов от 1 до 10. Этот процесс дает список из значений точности .
Следующим шагом является вычисление среднего для всех ваших верхних значений N , отсюда и термин Средняя точность (AP) . Мы перебираем все значения отзыва r , находим максимальную точность p , которую мы можем получить с нашим отзывом > r , а затем вычисляем среднее значение. Теперь у нас есть средняя точность для одного оценочного изображения.
После того, как мы вычислили среднюю точность для всех изображений в нашем наборе для тестирования / проверки, мы выполняем еще два вычисления:
- Вычислить среднее значение точек доступа для каждого класса , что даст нам карту MAP для каждого отдельного класса (для многих наборов данных / задач вы захотите изучить карту MAP по классам, чтобы вы могли определить, работает ли ваш детектор объектов глубокого обучения борется с определенным классом)
- Возьмите карты MAP для каждого отдельного класса и затем усредните их вместе, получая окончательный MAP для набора данных
Опять же, карта MAP более сложна, чем традиционная точность, поэтому не расстраивайтесь, если вы не поймете ее с первого раза.Это оценочный показатель, который вам нужно изучить несколько раз, прежде чем вы полностью поймете его. Хорошая новость заключается в том, что реализации обнаружения объектов глубокого обучения обрабатывают MAP за вас.
Обнаружение объектов на основе глубокого обучения с помощью OpenCV
Мы обсуждали глубокое обучение и обнаружение объектов в этом блоге в предыдущих сообщениях; однако давайте рассмотрим фактический исходный код в этом посте для полноты картины.
Наш пример включает детектор одиночного выстрела (каркас) с базовой моделью MobileNet.Модель была обучена пользователем GitHub chuanqi305 на наборе данных «Общие объекты в контексте» (COCO).
Для получения дополнительной информации ознакомьтесь с моим предыдущим постом , где я представил модель chuanqi305 с соответствующей справочной информацией.
Давайте вернемся к первому вопросу Иезекииля в начале этого сообщения:
- Как мне отфильтровать / игнорировать классы, которые меня не интересуют?
Я отвечу на этот вопрос в следующем примере скрипта.
Но сначала вам нужно подготовить вашу систему:
- Вам потребуется минимум OpenCV 3.3, установленного в вашей виртуальной среде Python (при условии, что вы используете виртуальные среды Python). OpenCV 3.3+ включает модуль DNN, необходимый для запуска следующего кода. Обязательно используйте одно из руководств по установке OpenCV на следующей странице, обращая особое внимание на то, какую версию OpenCV вы загружаете + устанавливаете.
- Вам также следует установить мой пакет imutils.Чтобы установить / обновить imutils в виртуальной среде Python, просто используйте pip:
pip install --upgrade imutils.
Когда будете готовы, создайте новый файл с именем filter_object_detection.py и начнем:
# импортируем необходимые пакеты из imutils.video импорт VideoStream из imutils.video импорт FPS импортировать numpy как np import argparse импорт imutils время импорта импорт cv2
На строках 2-8 мы импортируем наши необходимые пакеты и модули, в частности imutils и OpenCV.Мы будем использовать мой класс VideoStream для обработки захвата кадров с веб-камеры.
Мы вооружены необходимыми инструментами, поэтому давайте продолжим анализ аргументов командной строки:
# конструируем аргумент, разбираем и разбираем аргументы
ap = argparse.ArgumentParser ()
ap.add_argument ("- p", "--prototxt", required = True,
help = "путь к файлу прототипа Caffe 'deploy'")
ap.add_argument ("- m", "--model", required = True,
help = "путь к предварительно обученной модели Caffe")
ap.add_argument ("- c", "--confidence", type = float, по умолчанию = 0.2,
help = "минимальная вероятность отфильтровать слабые обнаружения")
args = vars (ap.parse_args ())
Нашему сценарию требуются два аргумента командной строки во время выполнения:
-
--prototxt: путь к файлу prototxt Caffe, который определяет определение модели. -
--model: Наша модель CNN взвешивает путь к файлу.
При желании вы можете указать --confidence , порог для фильтрации слабых обнаружений.
Наша модель может предсказать 21 класс объектов:
# инициализировать список меток классов MobileNet SSD был обучен # обнаружить, затем сгенерировать набор цветов ограничивающей рамки для каждого класса CLASSES = [«фон», «самолет», «велосипед», «птица», «лодка», «бутылка», «автобус», «машина», «кошка», «стул», «корова», «обеденный стол», «собака», «лошадь», «мотоцикл», «человек», «растение в горшке», «овца», «диван», «поезд», «твмонитор»]
Список CLASSES содержит все метки классов, которым была обучена сеть (т.е. Этикетки COCO).
Распространенное заблуждение относительно списка CLASSES состоит в том, что вы можете:
- Добавить новую метку класса в список
- Или удалить метку класса из списка
… и пусть сеть автоматически «знает», что вы пытаетесь достичь.
Это не так.
Вы, , не можете, просто изменить список текстовых меток и заставить сеть автоматически изменять себя для изучения, добавления или удаления шаблонов данных, на которых она никогда не обучалась. Нейронные сети работают не так.
Тем не менее, есть быстрый прием , который вы можете использовать для фильтрации и игнорирования прогнозов, которые вас не интересуют.
Решение:
- Определите набор
IGNOREметок (т. Е. Список меток классов, на которых была обучена сеть, которые вы хотите фильтровать и игнорировать). - Сделайте прогноз для входного изображения / видеокадра.
- Игнорировать любые прогнозы, если метка класса существует в наборе
IGNORE.
Реализованный на Python набор IGNORE выглядит следующим образом:
IGNORE = set (["человек"])
Здесь мы будем игнорировать все спрогнозированные объекты с меткой класса «человек» (оператор if , используемый для фильтрации, будет рассмотрен позже в этом обзоре кода).
Вы можете легко добавить в набор дополнительные элементы (метки классов из списка CLASSES ), которые будут игнорироваться.
Затем мы сгенерируем случайные цвета ярлыков / блоков, загрузим нашу модель и запустим видеопоток:
ЦВЕТА = np.random.uniform (0, 255, размер = (len (КЛАССЫ), 3))
# загружаем нашу сериализованную модель с диска
print ("[ИНФОРМАЦИЯ] загружает модель ...")
net = cv2.dnn.readNetFromCaffe (args ["prototxt"], args ["модель"])
# инициализировать видеопоток, дать датчику камеры прогреться,
# и инициализировать счетчик FPS
print ("[ИНФОРМАЦИЯ] запускает видеопоток ...")
vs = VideoStream (src = 0) .start ()
time.sleep (2.0)
fps = FPS (). start ()
В строке 27 генерируется случайный массив из ЦВЕТОВ , соответствующий каждому из 21 КЛАССА .Мы будем использовать эти цвета позже для демонстрации.
Наша модель Caffe загружается в , строка 31, с использованием функции cv2.dnn.readNetFromCaffe , и оба наших обязательных аргумента командной строки передаются в качестве параметров.
Затем мы создаем экземпляр объекта VideoStream как vs и запускаем наш счетчик с частотой кадров в секунду (, строки 36–38, ). Двухсекундный sleep дает нашей камере достаточно времени для разогрева.
На этом этапе мы готовы перебрать входящие с камеры кадры и отправить их через наш детектор объектов CNN:
# перебирать кадры из видеопотока в то время как True: # взять кадр из потокового видеопотока и изменить его размер # иметь максимальную ширину 400 пикселей кадр = vs.читать() frame = imutils.resize (рамка, ширина = 400) # возьмем размеры кадра и преобразуем его в blob (h, w) = frame.shape [: 2] blob = cv2.dnn.blobFromImage (cv2.resize (кадр, (300, 300)), 0,007843, (300, 300), 127,5) # передать BLOB-объект по сети и получить обнаружения и # прогнозов net.setInput (большой двоичный объект) обнаружения = net.forward ()
В строке , строка 44, мы захватываем кадр , а затем изменяем размер , сохраняя соотношение сторон для отображения ( строка 45 ).
Оттуда мы извлекаем высоту и ширину, поскольку эти значения нам понадобятся позже (, строка 48, ).
Строки 48 и 49 генерируют blob из нашего кадра. Чтобы узнать больше о большом двоичном объекте и о том, как он создается с помощью функции cv2.dnn.blobFromImage , см. Все подробности в предыдущем посте.
Затем мы отправляем этот blob через нашу нейронную сеть для обнаружения объектов ( строки 54 и 55 ).
Обследуем детекции:
# loop over the Detec
Превращение любого классификатора изображений CNN в детектор объектов с помощью Keras, TensorFlow и OpenCV
Щелкните здесь, чтобы загрузить исходный код этого сообщенияВ этом руководстве вы узнаете, как взять любой предварительно обученный классификатор изображений с глубоким обучением и превратить его в детектор объектов с помощью Keras, TensorFlow и OpenCV.
Сегодня мы начинаем серию из четырех частей о глубоком обучении и обнаружении объектов:
- Часть 1: Превращение любого классификатора изображений с глубоким обучением в детектор объектов с помощью Keras и TensorFlow (сегодняшняя публикация)
- Часть 2: OpenCV Selective Search for Object Detection
- Part 3: Предложение региона для обнаружения объектов с помощью OpenCV, Keras и TensorFlow
- Часть 4: Обнаружение объектов R-CNN с помощью Keras и TensorFlow
Цель этой серии публикаций - получить более глубокое понимание того, насколько глубоко детекторы объектов на основе обучения работают, а точнее:
- Как традиционные алгоритмы обнаружения объектов компьютерного зрения могут быть объединены с глубоким обучением
- Каковы мотивы сквозных обучаемых детекторов объектов и проблемы, связанные с ними
- И, что наиболее важно, как основополагающий Faster R-CNN возникла архитектура (в этой серии мы будем создавать вариант архитектуры R-CNN)
Сегодня мы начнем с основ обнаружения объектов, включая то, как взять предварительно обученный классификатор изображений и использовать пирамид изображений , скользящих окон и подавления не максимальных значений для создания базового детектора объектов (подумайте, как HOG + Linear SVM).
В ближайшие недели мы узнаем, как построить непрерывную обучаемую сеть с нуля.
Но сегодня давайте начнем с основ.
Чтобы узнать, как взять любой классификатор изображений сверточной нейронной сети и превратить его в детектор объектов с помощью Keras и TensorFlow, просто продолжайте читать.
Превращение любого классификатора изображений CNN в детектор объектов с помощью Keras, TensorFlow и OpenCV
В первой части этого руководства мы обсудим ключевые различия между классификацией изображений и задачами обнаружения объектов.
Затем я покажу вам, как можно взять любую сверточную нейронную сеть, обученную классификации изображений, и затем превратить ее в детектор объектов, всего в ~ 200 строках кода.
Оттуда мы реализуем код, необходимый для преобразования классификатора изображений в детектор объектов с помощью Keras, TensorFlow и OpenCV.
Наконец, мы рассмотрим результаты нашей работы, отметив некоторые проблемы и ограничения нашей реализации, в том числе то, как мы можем улучшить этот метод.
Классификация изображений и обнаружение объектов
Рисунок 1: Слева: Классификация изображений. Справа: Обнаружение объекта. В этом сообщении блога мы узнаем, как превратить любой CNN-классификатор изображений с глубоким обучением в детектор объектов с помощью Keras, TensorFlow и OpenCV.При выполнении классификации изображений , с учетом входного изображения, мы представляем его нашей нейронной сети и получаем одну метку класса и вероятность, связанную с предсказанием метки класса (, рисунок 1, , слева, ).
Эта метка класса предназначена для характеристики содержимого всего изображения или, по крайней мере, наиболее доминирующего видимого содержимого изображения.
Таким образом, мы можем думать о классификации изображений как:
- Одно изображение в
- Одна метка класса выходит
Обнаружение объекта, , с другой стороны, не только сообщает нам , что находится на изображении (т. Е. Метка класса), но также и , где на изображении объект находится через ограничивающую рамку (x, y) -координаты ( Рисунок 1, справа ).
Следовательно, алгоритмы обнаружения объектов позволяют нам:
- Введите одно изображение
- Получите нескольких ограничивающих прямоугольников и меток классов на выходе
По сути, любой алгоритм обнаружения объектов (независимо от традиционного компьютерного зрения или современного глубокого обучения) следует такой же узор:
- 1. Ввод: Изображение, к которому мы хотим применить обнаружение объекта
- 2.Выход: Три значения, в том числе:
- 2a. Список ограничивающих рамок, или (x, y) -координаты для каждого объекта на изображении
- 2b. Метка класса , связанная с каждой из ограничивающих рамок
- 2c. Оценка вероятности / достоверности , связанная с каждой ограничивающей рамкой и меткой класса
Сегодня вы увидите пример этого шаблона в действии.
Как мы можем превратить любой классификатор изображений с глубоким обучением в детектор объектов?
Здесь вы, вероятно, задаетесь вопросом:
Привет, Адриан, если у меня есть сверточная нейронная сеть, обученная для классификации изображений, как я собираюсь использовать ее для обнаружения объектов?
Исходя из вашего объяснения выше, кажется, что классификация изображений и обнаружение объектов принципиально разные, что требует двух разных типов сетевых архитектур.
И, по сути, является правильным - для обнаружения объектов требуется специализированная сетевая архитектура.
Любой, кто читал статьи о Faster R-CNN, Single Shot Detectors (SSD), YOLO, RetinaNet и т. Д., Знает, что сети обнаружения объектов более сложные, более сложные и требуют на несколько порядков и больших усилий для реализации по сравнению с традиционная классификация изображений.
Тем не менее, есть уловка, которую мы можем использовать, чтобы превратить наш классификатор изображений CNN в детектор объектов - и секретный соус кроется в традиционных алгоритмах компьютерного зрения .
Еще до появления детекторов объектов, основанных на глубоком обучении, самым современным решением было использование HOG + Linear SVM для обнаружения объектов на изображении.
Мы будем заимствовать элементы из HOG + Linear SVM для преобразования любого классификатора изображений глубокой нейронной сети в детектор объектов.
Первым ключевым элементом HOG + Linear SVM является использование пирамид изображений .
«Пирамида изображений» - это многомасштабное представление изображения:
Рисунок 2: Пирамиды изображений позволяют нам создавать изображения в различных масштабах.При превращении классификатора изображений в детектор объектов важно классифицировать окна в нескольких масштабах. Мы узнаем, как написать генератор Python пирамиды изображений и заставить его работать в наших скриптах Keras, TensorFlow и OpenCV.Использование пирамиды изображений позволяет нам находить объекты на изображениях в различных масштабах (т.е. размерах) изображения ( Рисунок 2 ).
Внизу пирамиды находится исходное изображение в исходном размере (с точки зрения ширины и высоты).
И на каждом последующем слое изображение изменяется (субдискретизируется) и, возможно, сглаживается (обычно с помощью размытия по Гауссу).
Изображение подвергается постепенной субдискретизации до тех пор, пока не будет выполнен некоторый критерий остановки, который обычно наступает, когда достигнут минимальный размер и не требуется никакой дополнительной субдискретизации.
Второй ключевой ингредиент, который нам нужен - это раздвижные окна :
Рисунок 3: Мы классифицируем области наших многомасштабных представлений изображений.Эти области создаются с помощью скользящих окон. Комбинация пирамид изображений и скользящих окон позволяет нам превратить любой классификатор изображений в детектор объектов с помощью Keras, TensorFlow и OpenCV.Как следует из названия, скользящее окно представляет собой прямоугольник фиксированного размера, который перемещается от слева направо, и сверху вниз, внутри изображения. (Как показывает Рисунок 3 , наше скользящее окно можно использовать для обнаружения лица на входном изображении).
На каждой остановке окна мы должны:
- Извлеките ROI
- Пропустите ее через наш классификатор изображений (например,, Линейный SVM, CNN и т. Д.)
- Получение прогнозов вывода
В сочетании с пирамидами изображений скользящие окна позволяют нам локализовать объекты в различных местах и нескольких масштабах входного изображения:
Последний ключевой ингредиент, который нам нужен, - подавление не максимальных значений .
При обнаружении объектов наш детектор объектов обычно создает несколько перекрывающихся ограничивающих рамок, окружающих объект на изображении.
Рисунок 4: Одним из ключевых компонентов превращения классификатора изображений CNN в детектор объектов с помощью Keras, TensorFlow и OpenCV является применение процесса, известного как подавление немаксимальных значений (NMS). Мы будем использовать NMS для подавления слабых, перекрывающихся ограничивающих рамок в пользу прогнозов с более высокой степенью достоверности.Это поведение совершенно нормальное, - это просто означает, что по мере приближения скользящего окна к изображению наш компонент классификатора возвращает все большую и большую вероятность положительного обнаружения.
Конечно, несколько ограничивающих прямоугольников создают проблему - там только и один объект , и нам нужно как-то свернуть / удалить лишние ограничивающие прямоугольники.
Решение проблемы заключается в применении подавления немаксимальных значений (NMS), которое сводит слабые перекрывающиеся ограничивающие рамки в пользу более надежных:
Рисунок 5: После применения подавления не максимальных значений (NMS) у нас остается одно обнаружение для каждого объекта на изображении.TensorFlow, Keras и OpenCV позволяют превратить классификатор изображений CNN в детектор объектов.На слева, у нас есть несколько обнаружений, в то время как на справа, у нас есть выход подавления не максимальных значений, который сворачивает несколько ограничивающих рамок в одно обнаружение .
Сочетание традиционного компьютерного зрения с глубоким обучением для создания детектора объектов
Рисунок 6: Шаги по превращению классификатора глубокого обучения в детектор объектов с использованием Python и таких библиотек, как TensorFlow, Keras и OpenCV.Чтобы взять любую сверточную нейронную сеть, обученную для классификации изображений , и вместо этого использовать ее для обнаружения объектов , мы собираемся использовать три ключевых компонента традиционного компьютерного зрения:
- Пирамиды изображений: Локализация объектов в различных масштабах / размерах.
- Скользящие окна: Обнаружение точно , где на изображении находится данный объект.
- Подавление не максимальных значений: Слабое свертывание, перекрывающиеся ограничивающие рамки.
Общий поток нашего алгоритма будет:
- Шаг № 1: Введите изображение
- Шаг № 2: Построение пирамиды изображений
- Шаг № 3: Для каждого масштаба пирамиды изображений запустите скользящее окно.
- Шаг № 3a: Для каждой остановки скользящего окна извлеките ROI
- Шаг # 3b: Возьмите ROI и передайте ее через нашу CNN, изначально обученную для классификации изображений
- Шаг № 3c: Изучите вероятность метки высшего класса CNN, и, если соответствует минимальной достоверности, запишите (1) метку класса и (2) местоположение скользящего окна
- Шаг № 4: Примените классовое подавление не максимальных значений к ограничивающим прямоугольникам
- Шаг № 5: Возврат результатов в вызывающую функцию
Это может показаться сложным процессом, но, как вы увидите в оставшейся части этого поста, мы можем реализовать всю процедуру обнаружения объекта в <200 строк кода!
Настройка среды разработки
Чтобы настроить вашу систему для этого руководства, я сначала рекомендую следовать одному из этих руководств:
Оба руководства помогут вам настроить вашу систему со всем необходимым программным обеспечением для этого сообщения в блоге в удобной виртуальной среде Python.
Обратите внимание, что PyImageSearch не рекомендует и не поддерживает Windows для проектов CV / DL.
Структура проекта
После извлечения .zip из раздела «Загрузки» этого сообщения в блоге ваш каталог будет организован следующим образом:
. ├── изображения │ ├── hummingbird.jpg │ ├── lawn_mower.jpg │ └── stingray.jpg ├── pyimagesearch │ ├── __init__.py │ └── detect_helpers.py └── detect_with_classifier.ру 2 каталога, 6 файлов
Сегодняшний модуль pyimagesearch содержит файл Python - detect_helpers.py , состоящий из двух вспомогательных функций:
-
image_pyramid: Помогает в создании копий нашего изображения в разных масштабах, чтобы мы могли находить объекты разных размеров. -
slide_window
Используя вспомогательные функции, наш detect_with_classifier.py Сценарий драйвера Python выполняет обнаружение объектов с помощью классификатора (с использованием подхода скользящего окна и пирамиды изображений). Классификатор, который мы используем, представляет собой предварительно обученную CNN ResNet50, обученную на наборе данных ImageNet. Набор данных ImageNet состоит из 1000 классов объектов.
Три изображения / предоставлены для тестирования. Вы также должны протестировать этот скрипт с собственными изображениями - учитывая, что наш детектор объектов на основе классификатора может распознавать 1000 типов классов, можно распознать большинство повседневных предметов и животных.Удачи!
Реализация наших служебных функций пирамиды изображений и скользящего окна
Чтобы превратить наш классификатор изображений CNN в детектор объектов, мы должны сначала реализовать вспомогательные утилиты для создания скользящих окон и пирамид изображений.
Давайте теперь реализуем эту вспомогательную функцию - откройте файл detect_helpers.py в модуле pyimagesearch и вставьте следующий код:
# импортируем необходимые пакеты импорт imutils def slide_window (изображение, шаг, ws): # передвигаем окно по изображению для y в диапазоне (0, image.shape [0] - ws [1], шаг): для x в диапазоне (0, image.shape [1] - ws [0], шаг): # вывести текущее окно yield (x, y, изображение [y: y + ws [1], x: x + ws [0]])
Далее мы переходим к определению нашей функции-генератора slide_window . Эта функция ожидает трех параметров:
-
изображение: Входное изображение , которое мы собираемся перебрать и сгенерировать окна. Это входное изображение может быть получено на выходе нашей пирамиды изображений. -
шаг: наш размер шага , , который указывает, сколько пикселей мы собираемся «пропустить» в обоих направлениях (x, y) . Обычно мы бы , а не захотели перебирать каждый пиксель изображения (т.е.шаг = 1), поскольку это было бы недопустимо с вычислительной точки зрения, если бы мы применяли классификатор изображения в каждом окне. Вместо этого размер шага определяется для каждого набора данных и настраивается для обеспечения оптимальной производительности на основе вашего набора данных изображений.На практике обычно используется шаг4до8пикселей. Помните, чем меньше размер вашего шага, тем больше окон вам нужно будет изучить. -
ws: Размер окна определяет ширину и высоту (в пикселях) окна, которое мы собираемся извлечь из нашего изображения
Фактическое «скольжение» нашего окна происходит на строках 6-9 согласно следующему:
- Строка 6 - это наш цикл по нашим строкам посредством определения диапазона
- Строка 7 - это наш цикл по нашим столбцам (диапазон
- Строка 9 в конечном итоге дает окно нашего изображения
ws) и размером шага.
Ключевое слово yield используется вместо ключевого слова return , потому что наша функция slide_window реализована как генератор Python.
Теперь, когда мы успешно определили нашу процедуру скользящего окна, давайте реализуем наш генератор image_pyramid , используемый для создания многомасштабного представления входного изображения:
def image_pyramid (изображение, масштаб = 1.5, minSize = (224, 224)): # вернуть исходное изображение дать изображение # продолжаем перебирать пирамиду изображений в то время как True: # вычисляем размеры следующего изображения в пирамиде w = int (image.shape [1] / масштаб) изображение = imutils.resize (изображение, ширина = ш) # если изображение с измененным размером не соответствует указанному минимуму # size, затем прекратите построение пирамиды если image.shape [0]Наша функция
image_pyramidтакже принимает три параметра:
изображение: входное изображение , для которого мы хотим сгенерировать многомасштабные представления.масштаб: наш масштабный коэффициент определяет, насколько изменяется размер изображения на каждом слое. Меньшие значения масштаба дают больше слоев в пирамиде, а большие значения масштаба дают меньше слоев.: Управляет минимальным размером выходного изображения (слой нашей пирамиды). Это важно, потому что мы могли бесконечно эффективно создавать постепенно уменьшающиеся масштабированные представления нашего входного изображения. Без параметраminSizeminSizeнаш циклибудет продолжаться бесконечно (это , а не , что мы хотим).Теперь, когда мы знаем параметры, которые должны быть введены в функцию, давайте погрузимся во внутреннее устройство нашей функции генератора пирамиды изображений.
Ссылаясь на Рисунок 2 , обратите внимание, что наибольшее представление нашего изображения - это само входное изображение. Строка 13 нашего генератора просто дает исходное неизмененное изображение
в первый раз, когда нашему генератору предлагается создать слой нашей пирамиды.Последующие сгенерированные изображения управляются бесконечным циклом
, в то время как цикл Trueначинается с , строка 16 .Внутри цикла мы сначала вычисляем размеры следующего изображения в пирамиде в соответствии с нашим масштабом
и исходным размеромизображения(, строка 18, ). В этом случае мы просто делим ширину входного изображения на масштаб, чтобы определить отношение ширины (к).Далее мы продолжаем и
изменяем размеризображениядо ширины, сохраняя соотношение сторон (, строка 19, ).Как видите, мы используем помощник по изменению размера с учетом аспектов, встроенный в мой пакет imutils.Пока мы фактически закончили (мы изменили размер нашего изображения
, и теперь мы можемдатьего), нам нужно реализовать условие выхода , чтобы наш генератор знал, что нужно остановиться. Как мы узнали, когда определили наши параметры для функцииimage_pyramid, условие выхода определяется параметромminSize. Следовательно, условие в строках 23 и 24 определяет, является ли изображение с измененным размером слишком маленьким (высотаили ширина), и соответственно выходит из цикла.Предполагая, что наше масштабированное выходное изображение
изображениепроходит наше пороговое значениеminSize, Строка 27 передает его вызывающему.Для получения более подробной информации, пожалуйста, обратитесь к моей статье «Пирамиды изображений с Python и OpenCV », которая также включает альтернативную реализацию пирамиды изображений scikit-image, которая может быть вам полезна.
Использование Keras и TensorFlow для превращения предварительно обученного классификатора изображений в детектор объектов
Теперь, когда реализованы наши функции
скользящее окноиimage_pyramid, давайте воспользуемся ими, чтобы взять глубокую нейронную сеть, обученную классификации изображений, и превратить ее в детектор объектов.Откройте новый файл, назовите его
detect_with_classifier.pyи начнем кодирование:# импортируем необходимые пакеты из tenorflow.keras.applications импортировать ResNet50 из tensorflow.keras.applications.resnet импорт preprocess_input из tensorflow.keras.preprocessing.image import img_to_array из tensorflow.keras.applications импортировать imagenet_utils из imutils.object_detection import non_max_suppression из pyimagesearch.detection_helpers импорт скользящего_окна из pyimagesearch.Detection_helpers import image_pyramid импортировать numpy как np import argparse импорт imutils время импорта импорт cv2Этот сценарий начинается с выбора импорта, включая:
ResNet50: популярный классификатор сверточной нейронной сети ResNet (CNN), разработанный He et al. представили в своей статье 2015 года Deep Residual Learning for Image Recognition . Мы загрузим в эту CNN предварительно обученные веса ImageNet.non_max_suppression: Реализация NMS в моем пакете imutils.скользящее окно: Наша функция генератора скользящего окна, как описано в предыдущем разделе.image_pyramid: генератор пирамиды изображений, который мы определили ранее.# построить аргумент, синтаксический анализ и синтаксический анализ аргументов ap = argparse.ArgumentParser () ap.add_argument ("- i", "--image", required = True, help = "путь к входному изображению") ap.add_argument ("- s", "--size", type = str, default = "(200, 150)", help = "Размер ROI (в пикселях)") ap.add_argument ("- c", "--min-conf", type = float, по умолчанию = 0.9, help = "минимальная вероятность отфильтровать слабые обнаружения") ap.add_argument ("- v", "--visualize", type = int, по умолчанию = -1, help = "показывать ли дополнительные визуализации для отладки") args = vars (ap.parse_args ())Следующие аргументы должны быть предоставлены этому сценарию Python во время выполнения с вашего терминала:
: путь к входному изображению для обнаружения объектов на основе классификации.--image: кортеж, описывающий размер скользящего окна. Этот кортеж должен быть заключен в кавычки, чтобы наш синтаксический анализатор аргументов мог получить его прямо из командной строки.--size: минимальный порог вероятности для фильтрации слабых обнаружений.--min-conf--visualize: переключатель для определения необходимости отображения дополнительных визуализаций для отладки.Теперь у нас есть несколько констант, которые нужно определить для наших процедур обнаружения объектов:
.