
Что такое дистрактор: ДИСТРАКТОР — Гипертекстовый словарь методических терминов
Дистракторы и фиксаторы
Идеи, которые российский хирург Гаврил Илизаров получил в 1950-х годах, сегодня являются стандартными знаниями, и клиническая практика была бы немыслима без этого. Более того: во многих случаях дистракционный остеогенез в настоящее время представляет собой метод выбора. Благодаря многочисленным инновационным и революционным системам дистракции, KLS Martin внесла большой вклад в внедрение этой техники в черепно-лицевую хирургию для использования в операционных по всему миру. Вряд ли существует какая-либо черепно-лицевая проблема, на которую мы не ответили, разработав специальный дистрактор для ее решения.
Но мы не ограничиваемся этим: с новыми, инновационными деталями продукта мы помогаем улучшить комфорт пациента, клиническую безопасность и дать возможность пользователям решать даже самые сложные задачи.
Видео демонстрация
Портфолио дистракторов
Краниальные дистракторы по Арнауду и Маршаку
Устройства для коррекции черепно-лицевых пороков развития. Предназначены для внутренней дистракции при лечении черепно-лицевой дисплазии, особенно черепно-лицевых синостозов.
Предназначены для внутренней дистракции при лечении черепно-лицевой дисплазии, особенно черепно-лицевых синостозов.
Дистракторы Кавамомо
Предназначены для внутренней дистракции при лечении черепно-лицевой дисплазии, особенно черепно-лицевых синостозов.
Дистракторы для заднего черепного свода
Используются для лечения пороков развития черепа, таких как синдромальный краниосиностоз и врожденные дефекты.
Педиатрические дистракторы Цюриха для верхней челюсти
Подходит для дистракции верхней челюсти младенцев и молодых людей в случаях врожденных или приобретенных пороков развития.
Телескопические верхнечелюстные дистракторы
Подходят для дистракции верхней челюсти, где необходимо постепенное удлинение кости, особенно в результате врожденных и приобретенных пороков развития.
Дистракторы TS-MD
Инструменты для коррекции черепно-лицевых паталогий.
Дистракторы Лиу Клефта
Предназначен для горизонтальной дистракции верхнечелюстного альвеолярного отростка.
Дистракторы TRACK
Устройства для дистракции альвеолярного отростка.
Небные дистракторы Роттердама (RPD)
Инструменты для поперечной небной дистракции.
Небные эспандеры (RPE)
Инстурменты для поперечной небной дистракции.
Дистракторы RED-II
Внешний инструмент для коррекции черепно-лицевых паталогий.
Дистракторы Цюриха II
Используются для дистракции в двух случаях: врожденный порок развития и приобретенная гипоплазия нижней челюсти.
Горизонтальные дистракторы
Подходят для лечения: врожденного порока развития или деформации или приобретенной гипоплазии
Цюрих Рамус педиатрические дистракторы
Подходят для дистракции восходящей части нижней челюсти, а также нижней челюсти у младенцев и молодых людей в случае врожденных или приобретенных дефектов.
Дистракторы для ветвей нижней челюсти
Предназначены для дистракции восходящей ветви нижней челюсти.
Телескопические дистракторы для нижней челюсти
Подходят для дистракции боковой нижней челюсти в случаях, когда требуется постепенное удлинение кости, особенно для коррекции врожденных или приобретенных пороков развития и гипоплазии.
Право угольные (RAD) дистракторы
Подходят для лечения: врожденного порока развития или деформации или приобретенной гипоплазии нижней челюсти
Дистракторы Цюриха-Вуда
Внутриротовые, двунаправленные инструменты для удлинения восходящей ветви нижней челюсти в горизонтальном направлении.
Двунаправленные дистракторы Цюриха
Внутриротовые, двунаправленные инструменты для удлинения восходящей ветви нижней челюсти в горизонтальном направлении.
Транспортные дистракторы Ramus
Устройства для транспортной дистракции мыщелковой головки
Транспортные дистракторы ThreadLock
Позволяют исправить дефекты непрерывности в нижней челюсти.
Транспортные дистракторы Herford
Внутриротовая система, которая позволяет транспортировать сегменты и восстанавливать дефекты непрерывности в нижней челюсти.
Xternal 3D дистрактор
Наружное устройство для коррекции пороков развития нижней челюсти.
Дистракторы Молина
Используются для лечения врожденных или приобретенных пороков развития нижней челюсти, дефицита и гипоплазии в случаях, когда требуется экстраоральный доступ.
Срединные дистракторы Роттердама
Используются для дистракционного остеогенеза нижнечелюстного симфиза в случаях сильной скученности области нижней челюсти и поперечного дефицита.
Срединные дистракторы Болона
Используются для дистракционного остеогенеза нижнечелюстного симфиза в случаях сильной скученности области нижней челюсти.
Черепно-нижнечелюстной фиксатор Мэтьюса
Внутрикапсулярный осколочный перелом и одновременно: задний неправильный прикус, который предотвращает использование шины против открытого прикуса; тяжелая черепно-мозговая травма (пациент не реагирует, постоянная кома).
X-Fix
Внешний фиксатор X-Fix предназначен для стабилизации нижней челюсти.
Горизонтальная дистракция челюстей с последующей ортогнатической хирургией
Р. А. Хачатрян
к. м. н., челюстно-лицевой хирург, имплантолог, научный советник компаний Biotech International (Франция) и «Медтроник» (Россия), консультант стоматологических клиник «Колибри» (Краснодар), «Визит» (Анапа)
Микрогнатия челюстей является одной из частых патологий среди пациентов с дисгармонией лицевого скелета.
Она выражается в трансверсальном недоразвитии челюстных костей в сочетании с неизбежной скученностью зубных рядов, аномалиями прикуса, сокращенным объемом полости рта, нарушением функций жевания и речи. Отдельный контингент составляют больные с обструктивным апноэ сна.

Часто трансверсальная дисгармония зубных рядов сочетается со скелетными аномалиями челюстей (рис. 1, 2).
- Рис. 1. Больная с сочетанной патологией лицевого черепа — ретромикрогенией верхней челюсти в комбинации с прогенией нижней челюсти, III класс окклюзии.
- Рис. 2. Больная с сочетанной патологией лицевого черепа — ретромикрогенией верхней челюсти в комбинации с прогенией нижней челюсти, III класс окклюзии.
Эстетические пропорции лица при данной патологии нарушены, что часто приводит к выраженным нарушениям психоэмоционального статуса пациентов.
Общеизвестные методы лечения данной патологии, состоящие в билатеральном удалении премоляров с последующей ортодонтической коррекцией зубных рядов, не приводят к полноценному восстановлению сокращенных трансверсальных объемов челюстей и полости рта, а также соответствующих функциональных параметров зубочелюстной системы.
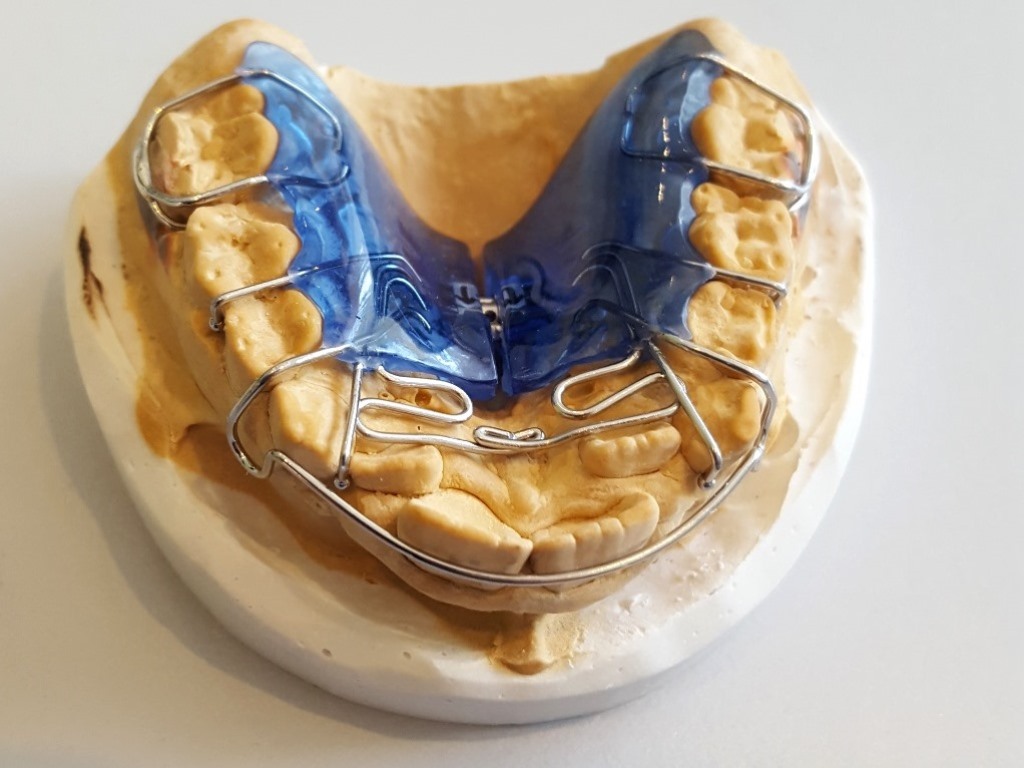
Ортопедические методы коррекции трансверсального дефицита тела верхней челюсти были описаны впервые в 1860 году, впоследствии многократно модифицировались и совершенствовались. Цель заключалась в быстром расширении верхней челюсти посредством активации внутриротового дистрактора, зафиксированного полукольцами и штангами в зоне зубного ряда. Скорость экспансии составляла 0,5 мм в день.
Подобное ортопедическое расширение верхней челюсти при помощи несъемных ортодонтических аппаратов имеет множество недостатков и осложнений. В мировой литературе и по нашим наблюдениям отмечаются нежелательные вторичные эффекты ортопедической экспансии, выражающиеся в резорбции кортикальных пластин челюстей и корней зубов, рецессий десны с возникновением патологии пародонта и частыми рецидивами деформаций. Метод также имеет ограниченные возрастные показания и применяется в юном возрасте в период активного роста костей лицевого черепа до 14 лет у девушек и до 17 у юношей.
Быстрая экспансия челюстей при помощи предварительно выполненной остеотомии является техникой выбора у пациентов с завершенным ростом костей лицевого черепа, так как исключает всякое костное сопротивление при латеральном перемещении остеотомированных фрагментов челюстей. Этот тип хирургии основан на растяжении ретрагированного между остеотомированными фрагментами кровяного сгустка с его последующей минерализацией и оссификацией, известен в литературе как феномен дистракционного остеогенеза (рис. 3—5).
Этот тип хирургии основан на растяжении ретрагированного между остеотомированными фрагментами кровяного сгустка с его последующей минерализацией и оссификацией, известен в литературе как феномен дистракционного остеогенеза (рис. 3—5).
- Рис. 3. Скученность зубного ряда верхней челюсти, микрогнатия.
- Рис. 4. Установленный интраоперационно транспалатинальный дистрактор — конец дистракционного периода.
- Рис. 5. Окончательная ортодонтическая коррекция окклюзии.
В настоящей работе представляются методы хирургической остеотомии челюстей с последующим применением дистракционного метода при помощи фиксированных ортодонтических конструкций или челюстных дистракторов. Дистракционные аппараты устанавливаются за день до оперативного вмешательства или интраоперационно в зависимости от планируемой конструкции.
На верхней челюсти ортодонтический дистрактор фиксируется при помощи полуколец и штанг к зубному ряду (рис.
Рис. 6. Стандартный дистрактор верхней челюсти, зафиксированный в области зубного ряда.
При имеющихся проблемах с зубными рядами или частичной вторичной адентии верхней челюсти применяются внутриротовые дистракторы, устанавливающиеся интраоперационно (рис. 4).
Оперативное вмешательство проводится преимущественно под общей анестезией — назотрахеальная интубация с ИВЛ. После инфильтрации в области преддверия полости рта производится разрез по межзубным десневым сосочкам. Разрезы в преддверии полости рта практически исключены из ервопейских протоколов по ортогнатической хирургии.
После тщательной отслойки слизисто-надкостничных лоскутов оголяется тело верхней челюсти. Остеотомия верхний челюсти представляет классический распил по линии Le-Fort I в сочетании с остеотомией перегородки носа, латеральных стенок верхнечелюстных синусов и крылочелюстных областей (рис. 7).
Рис. 7. Этап горизонтальной остеотомии верхней челюсти.
Затем рассекается область срединного небного шва (рис. 8).
8).
Рис. 8. Рассечение срединного небного шва.
После контроля адекватной мобильности остеотомированных фрагментов челюстей лоскуты ушиваются.
В области нижней челюсти фиксация дистрактора производится в области зубного ряда с расположением винта вестибулярно или язычно. Разрез во фронтальной области производится по межзубным сосочкам в сочетании с боковыми разрезами в области клыков (рис. 9).
Рис. 9. Разрез во фронтальном отделе по сосочкам зубов.
После отслойки слизисто-надкостничного лоскута производится линейный распил в области симфиза по средней линии или ступенчатой остеотомией перед клыками с распространением на среднюю линию (рис. 10).
Рис. 10. Срединная симфизарная остеотомия.
После полной мобилизации фрагментов раны зашиваются наглухо. Период госпитализации составляет 24 часа.
Послеоперационное ведение больного включает прием нестероидных противовоспалительных, носовых сосудосуживающих препаратов и антисептического полоскания полости рта. Активация дистракторов начинается на 8-й день послеоперационного периода самим больным или персоной из его близкого окружения. Степень активации винта зависит от необходимого размера коррекции.
Активация дистракторов начинается на 8-й день послеоперационного периода самим больным или персоной из его близкого окружения. Степень активации винта зависит от необходимого размера коррекции.
После завершения дистракции на запланированную ширину ретенционный период до 6 недель способствует оссификации зоны дистракции и консолидации фрагментов челюстей.
Послеоперационное ортодонтическое лечение завершает морфологическое формирование зубных рядов. В отдаленном послеоперационном периоде при необходимости некоторым больным со скелетической аномалией производится также ортогнатическая хирургия.
Клинический случай комбинированной патологии зубных рядов, окклюзии и костей лицевого черепа
Пациентка, 26 лет, страдает тяжелым зубочелюстно-лицевым дисморфозом, выражающимся в микрогнатии, скученности зубов, ретрогении и синдроме длинного лица (рис. 11, 12).
- Рис. 11. Окклюзия больной до начала лечения.
-
Рис. 12. Окклюзия больной до начала лечения.

На первом этапе лечения после установки внутриротового экспандера осуществляется хирургическая компактостеотомия верхней и нижней челюстей. Отмечается спонтанное зактрытие диастемы еще до начала ортодонтического лечения (рис. 13—16).
- Рис. 13. Больная через 8 дней после начала активации дистрактора.
- Рис. 14. Больная через 8 дней после начала активации дистрактора.
- Рис. 15. Пациентка через 3 мес после дистракции — конец ретенционного периода.
- Рис. 16. Пациентка через 3 мес после дистракции — конец ретенционного периода.
Ортодонт фиксирует брекет-системы на зубные ряды с целью подготовки окклюзии ко второму этапу хирургической коррекции — ортогнатической хирургии.
Клинический осмотр больной до ортогнатической хирургии выявляет сочетанную патологию черепа — горизонтальную гипертрофию верхней челюсти в сочетании с микрогеней. Центральные резцы чрезмерно выступают из-под верхней губы, рот открыт, губы не смыкаются. Отмечается также заднее положение нижней челюсти, губо-подбородочная складка сглажена, ткани приротовой области напряжены.
Центральные резцы чрезмерно выступают из-под верхней губы, рот открыт, губы не смыкаются. Отмечается также заднее положение нижней челюсти, губо-подбородочная складка сглажена, ткани приротовой области напряжены.
Пациентке произведено сочетание горизонтальной остеотомии верхней челюсти на поднятие и ротацию, билатеральной остеотомии ветвей нижней челюсти и эстетической гениопластики (рис. 17, 18).
- Рис. 17. Окклюзия больной в конце дистракционного периода до ортогнатической хирургии.
- Рис. 18. Окклюзия больной после ортогнатической хирургии.
Таким образом, методика хирургическо-ортодонтической экспансии челюстей позволяет исключить сопротивление челюстных костей латеральному перемещению остеотомированных фрагментов, резко сокращает сроки лечения и реабилитации больных, доводит до минимума количество рецидивов деформаций.
В оперированной группе больных наблюдается полное восстановление функции жевания и речи, гармонизация лицевых признаков и, как следствие, значительное улучшение эмоционального состояния пациентов.
Что такое дистрактор, зачем и как его используют в стоматологии
Информация носит справочный характер. Не занимайтесь самодиагностикой и самолечением. Обращайтесь ко врачу.
Проблема, связанная с наращиванием костной ткани в стоматологии, не теряет своей актуальности. Дело в том, что удаление зуба приводит к тому, что костная ткань истончается, то есть происходит ее дистрофия.
Если своевременно не произвести костную пластику, то решить проблему отсутствующего зуба установкой имплантатов не получится. В современной стоматологии, чтобы восстановить атрофированную костную ткань, используются специальные устройства дистракторы.
Содержание
- Что за устройство такое?
- Цели применения
- Особенности дистракционного остеогенеза
- Послеоперационный период
Что за устройство такое?
Дистрактором называю устройство, которое позволяет произвести измеримую, постепенную, контролируемую дистракцию черепно-лицевых костей, то есть их вытягивание и растягивание в различные стороны.
Данный механизм предназначается для наращивания кости. Он применяется, когда объем челюстной кости недостаточен, чтобы установить имплантаты, а также при необходимости стимуляции роста ткани кости в вертикальном направлении.
Дистракционные аппараты классифицируются за размещением, по применению и по количеству векторов воздействия. Так, в зависимости от размещения они бывают внеротовыми и внутриротовыми.
По целям применения дистракторы предназначаются для альвеолярного отростка, верхней и нижней челюсти, а также для средней зоны лицевой области. За числом векторов устройства могут быть одновекторными и многовекторными.
Цели применения
При дистрофии костная ткань утончается, поэтому необходимо ее восстановление. Эта проблема может возникнуть по разным причинам, в частности, при травмах и переломах челюсти, после удаления зубов, вследствие индивидуальных анатомических особенностей и воспалительных заболеваний.
Для успешного восстановления ткани и используется дистрактор, который стимулирует процессы естественной регенерации кости.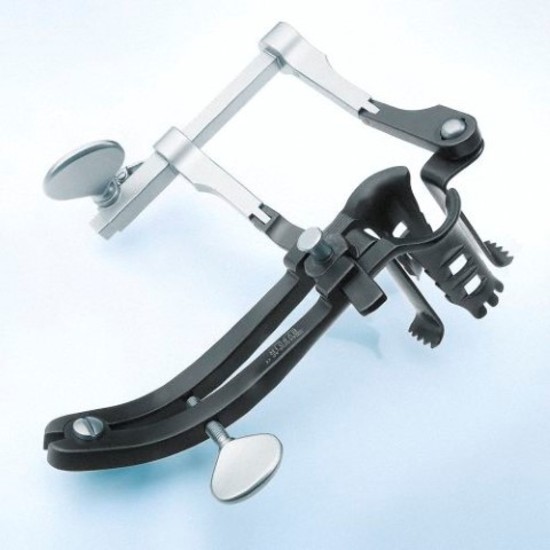
К классическим процедурам дистракционного остеогенеза в челюстно-лицевой области обращаются, если необходимо:
- удлинение ветвей нижней челюсти;
- перемещение средней части лица за LeFort ІІІ;
- удлинение тела нижней челюсти;
- расширение челюсти;
- расширение симфиза;
- увеличение параметров альвеолярной кости;
- перемещение верхней челюсти за LeFort ІІІ.
Особенности дистракционного остеогенеза
Процедура начинается с того, что десна, которая находится над участком кости, вскрывается, чтобы оголить участок. После этого целостность ткани кости, которая нуждается в растяжении, нарушается за счет разделения кости на 2 части.
Далее дистракционное устройство устанавливается в полученный разрыв. Затем наступает так называемый латентный период, при котором какие-либо силы в устройстве не прилагаются.
Как указывалось выше, в челюсти высверливается отверстие, которое необходимо, чтобы закрепить там дистрактор.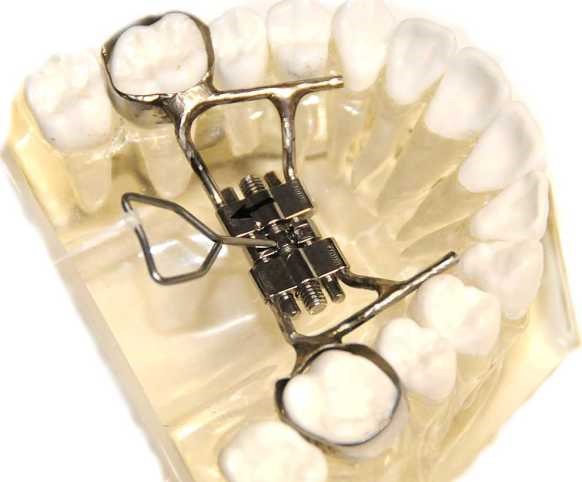 Чтобы не повредить кости нагреванием, при хирургическом вмешательстве бор охлаждается водой. Когда отверстие просверлено, дистрактор закрепляется с помощь небольших винтов. После того, как кость восстановится, то все эти части будут полностью удалены.
Чтобы не повредить кости нагреванием, при хирургическом вмешательстве бор охлаждается водой. Когда отверстие просверлено, дистрактор закрепляется с помощь небольших винтов. После того, как кость восстановится, то все эти части будут полностью удалены.
После вживления дистракционного устройства оно зашивается под слизистую. Когда порезы заживают, то костный блок начинает передвигаться со слизистой вверх. В это время они подрастают.
В ротовой полости будет виден только винт, с помощью которого человек самостоятельно сможет контролировать процесс дистракции. Спустя 10 дней после вживления аппарата пациенту необходимо каждый день один раз поворачивать винт. Так следует делать, пока ни произойдет окончательная коррекция костного дефекта. Во время последующей имплантации дистрактор удаляется.
При успешном проведении операции сохраняется кровоснабжение сегмента, который был транспортирован. Аппарат правильно позиционируется, слизистой оболочке обеспечивается достаточное кровоснабжение над фрагментом.
Послеоперационный период
Стоматологическая пластика с помощью дистрактора имеет множество преимуществ. Так, время аугментации, то есть наращивания кости, происходит за 3-4 месяца, поэтому носится этот аппарат недолго.
Полная реабилитация наступает спустя 7 месяцев. Кроме того, с помощью данной процедуры увеличивается объем мягких тканей, образуются полноценные кости, гладко заживают раны, уровень инфицирования во время послеоперационного периода очень низкий. Поэтому в дальнейшем не нужно будет принимать антибиотики.
А процент приживаемости имплантатов очень высокий. К положительным аспектам стоит отнести еще и то, что для забора кости донорская область не используется, после процедуры можно получить достаточную высоту кости.
Таким образом, с помощью дистракционного устройства можно успешно нарастить кость. При этом сроки лечения и период реабилитации больного сокращены, а количество рецидивов – минимально.
Среди больных, которые были оперированы, отмечается полное восстановление таких функций, как речь и жевание, лицевые признаки гармонизируются, а это приводит к тому, что эмоциональное состояние человека значительно улучшается.
Оценка статьи
Стоматологический дистрактор
Наращивание костной ткани – одна из самых актуальных стоматологических проблем. В результате удаления зуба костная ткань истончается, происходит ее дистрофия. При отсутствии своевременно выполненной костной пластики не получится провести установку имплантатов. Восстановление атрофированной костной ткани в современной стоматологии осуществляется при помощи специальных устройств – дистракторов.
Что это такое?
Дистрактор – устройство, предназначенное для проведения измеримого и контролируемого вытягивания и растягивания черепно-лицевых костей.
Механизм используется для наращивания кости, в случаях, когда объем челюстной кости недостаточен для установки имплантата. Методика применяется для стимуляции роста ткани в вертикальном направлении.
Классификация аппаратов:
- В зависимости от размещения:
- внеротовые;
- внутриротовые.
- В зависимости от применения:
- для альвеолярного отростка;
- для верхней и нижней челюсти;
- для средней зоны лицевой области.
- В зависимости от числа векторов воздействия:
- одновектроные;
- многовекторные.
Цели применения
При дистрофии происходит утончение костной ткани и требуется ее восстановление. Причинами возникновения проблемы являются травматические повреждения и переломы челюсти, удаление зубов, индивидуальные анатомические особенности, воспалительные процессы.
Применение дистрактора способствует успешному восстановлению. Приспособление стимулирует процессы естественной костной регенерации.
Показания к проведению процедуры дистракционного остеогенеза:
- удлиненные ветви нижней челюсти;
- средняя часть лица за пределами LeFort III;
- удлиненное тело нижней челюсти;
- расширенная челюсть;
- расширенный симфиз;
- увеличенные параметры альвеолярной кости;
- перемещенная верхняя челюсть за LeFort III.
Особенности проведения процедуры
Врач вскрывает десну для оголения интересующего участка кости. Кость, нуждающаяся в растяжении, разделяется на две части. В полученный разрыв устанавливается устройство. После этого наступает латентный период, не требующий прикладывания усилий к устройству.
Для закрепления дистрактора в челюсти сверлится специальное отверстие. При проведении хирургической операции бор остужается водой. Так предотвращается повреждение костной ткани нагреванием. В отверстии прибор фиксируется специальными винтами. После восстановления ткани кости все элементы удаляются.
Вживленный прибор зашивается под слизистую оболочку. После заживления порезов костный блок передвигается со слизистой вверх и растет.
Во рту пациента визуализируется только винт, позволяющий контролировать процесс дистракции. Через 10 дней после процедуры пациент ежедневно однократно прокручивает винт. Подобные манипуляции проводятся до окончательной коррекции дефекта кости. Дистрактор удаляется в ходе последующей имплантации.
Дистрактор удаляется в ходе последующей имплантации.
В случае успешного проведения процедуры кровоснабжение транспортированного сегмента сохраняется. Устройство правильно размещается и к слизистой оболочке над фрагментом поступает достаточное кровообращение.
Послеоперационный период
Применение дистрактора в стоматологической пластике обладает рядом преимуществ. Время наращивания кости занимает до 4 месяцев.
Полная реабилитация наступает через семь месяцев. Процедура способствует увеличению объема мягких тканей, образованию кости, заживлению ран без шрамов. Минимальный риск инфицирования в послеоперационный период. Нет необходимости в проведении антибиотикотерапии.
Высокий процент приживаемости имплантатов. Еще один положительный аспект – отсутствие необходимости применения донорской крови. В результате операции достигается достаточная высота кости.
Дистракционное устройство – решение для успешного наращивания кости. Для него характерны сокращенный период лечения и реабилитации и минимальное число рецидивов.
У пациентов, прошедших операцию отмечается полное восстановление речевых и жевательных функций, гармонизация лицевых признаков и улучшение эмоционального состояния.
Перед проведением операции пациент проходит полное обследование и консультацию, позволяющие оценить масштабы ситуации.
Противопоказания
Как и к другим стоматологическим манипуляциям к проведению наращивания костной массы существует ряд противопоказаний:
- повышенная ломкость костей вследствие остеопороза;
- беременность и лактация;
- заболевания крови;
- психические патологии;
- иммунодефицит.
Запрещено проводить процедуру при выявлении в ротовой полости ран, язвенных поражений, инфекции, кариеса. При значительных дефектах зубов стоимость костной пластики возрастает, поскольку перед ее проведением выполняется лечение поврежденных участков.
ПРИМЕНЕНИЕ МЕЖОСТИСТОГО ДИСТРАКТОРА ИЗ НИТИНОЛА ПРИ ХИРУРГИЧЕСКОМ ЛЕЧЕНИИ СЕГМЕНТАРНОЙ НЕСТАБИЛЬНОСТИ В ПОЯСНИЧНОМ ОТДЕЛЕ ПОЗВОНОЧНИКА | Давыдов
1. Вознесенская Т.Г. Боли в спине и конечностях // Болевые синдромы в неврологической практике / Под ред. А.М. Вейна и др. М., 1999. С. 217-283.
Вознесенская Т.Г. Боли в спине и конечностях // Болевые синдромы в неврологической практике / Под ред. А.М. Вейна и др. М., 1999. С. 217-283.
2. Ильин А.А., Коллеров М.Ю., Давыдов Е.А. Устройство для дистракции остистых отростков. Патент № 2453289. Дата подачи заявки 12.11.2010; дата публ. 20.06.2012, бюл. 17.
3. Коновалов Н.А. Прогнозирование микрохирургического лечения межпозвонковых дисков на пояснично-крестцовом уровне: Автореф. дис.. канд. мед. наук. М., 1999.
4. Левченко С.К. Экспериментально-клиническое обоснование функциональной транспедикулярной стабилизации позвоночника: Дис.. канд. мед. наук. М., 2004.
5. Маркин С.П. Задняя динамическая фиксация в хирургическом лечении поясничного остеохондроза: Дис.. канд. мед. наук. Новосибирск, 2010.
6. Миронов С.П., Ветрилэ С.Т., Ветрилэ М.С. и др. Оперативное лечение спондилолистеза позвонка L5 с применением транспедикулярных фиксаторов // Хирургия позвоночника. 2004. № 1. С. 39-46.
7. Панаськов А.В. Нестабильность позвоночника при поясничном остеохондрозе: Дис. . канд. мед. наук. СПб., 2003.
. канд. мед. наук. СПб., 2003.
8. Романенков В.М., Самошенков А.Г. Отдаленные результаты хирургического лечения грыж межпозвонковых дисков поясничного отдела позвоночника // III съезд нейрохирургов России: Мат-лы. СПб., 2002. С. 275-276.
9. Сидоров Е.В. Клиника, диагностика и хирургическое лечение стеноза поясничного отдела позвоночного канала: Автореф. дис.. канд. мед. наук. М., 2003.
10. Симонович А.Е. Хирургическое лечение дегенеративных поражений поясничного отдела позвоночника: Дис.. д-ра мед. наук. Новосибирск, 2005.
11. Biering-Sorensen F. Low back trouble in a general population of 30-, 40-, 50-, and 60-year-old men and women: Study design, representativeness and basic results. Dan Med Bull. 1982; 29: 289-299.
12. Bridwell, KH, Sedgewick TA, O’Brien MF, et al. The role of fusion and instrumentation in the treatment of degenerative spondylolisthesis with spinal stenosis. J Spinal Disord. 1993; 6: 461-467.
13. Cauchoix J, Ficat C, Girard B. Repeat surgery after disc excision. Spine. 1978; 3: 256-259.
Spine. 1978; 3: 256-259.
14. Christie SD, Song JK, Fessler RG. Dynamic interspinous process technology. Spine. 2005; 30( 16 Suppl): S73-S78.
15. Dillingham T. Evaluation and management of low back pain: an overview. State Art Rev. 1995; 9: 559-574.
16. Fischgrund JS, Mackay M, Herkowitz HN, et al. 1997 Volvo Award winner in clinical studies. Degenerative lumbar spondylolisthesis with spinal stenosis: a prospective, randomized study comparing decompressive laminectomy and arthrodesis with and without spinal instrumentation. Spine. 1997; 22: 2807-2812.
17. Friberg O. Lumbar instability: a dynamic approach by traction-compression radiography. Spine. 1987; 12: 119-129.
18. Fritsch EW, Heisel J, Rupp S. The failed back surgery syndrome: reasons, intraoperative findings, and long-term results: a report of 182 operative treatments. Spine. 1996; 21: 626-633.
19. Fritzell P, Hagg O, Wessberg P, et al. Chronic low back pain and fusion: a comparison of three surgical techniques: a prospective multicenter randomized study from Swedish lumbar spine study group. Spine. 2002; 27: 1131-1141.
Spine. 2002; 27: 1131-1141.
20. Hides J, Richardson C, Jull GA. Multifidus recovery is not automatic following resolution of acute first-episode low back pain. Spine. 1996; 21: 2763-2769.
21. Indahl A, Velund L, Reikeraas O. Good prognosis for low back pain when left untampered. Spine. 1995; 20: 473-477.
22. Jonsson B, Stromqvist B. Clinical characteristics of recurrent sciatica after lumbar discectomy. Spine. 1996; 21: 500-505.
23. Kotilainen E. Long-term outcome of patients suffering from clinical instability after microsurgical treatment of lumbar disc herniation. Acta Neurochir (Wien). 1998; 140: 120-125.
24. Kotilainen E, Valtonen S. Clinical instability of the lumbar spine after microdiscectomy. Acta Neurochir (Wien). 1993; 125: 120-126.
25. Long DM, BenDebba M, Torgenson WS, et al. Persistent back pain and sciatica in the United States: patient characteristics. J Spinal Disord. 1996; 9: 40-58.
26. Lonstein JE, Denis F, Perra JH, et al. Complications associated with pedicle screws. J Bone Joint Surg Am. 1999; 81: 1519-1528.
J Bone Joint Surg Am. 1999; 81: 1519-1528.
27. Mascarenhas AA, Thomas I, Sharma G, et al. Clinical and radiological instability following standard fenestration discectomy. Indian J Orthop. 2009; 43: 347-351. doi: 10.4103/0019-5413.55465
28. Masferrer R, Gomez CH, Karahalios DG, et al. Efficacy of pedicle screw fixation in the treatment of spinal instability and failed back surgery: a 5-year review. J Neurosurg. 1998; 89: 371-377.
29. Nagi SZ, Riley LE, Newby LG. A social epidemiology of back pain in a general population. J Chron Dis. 1973; 26: 769-779.
30. Panjabi MM. Clinical spinal instability and low back pain. J Electromyogr Kinesiol. 2003; 13: 371-379.
31. Park P, Garton HJ, Gala VC, et al. Adjacent segment disease after lumbar or lumbosacral fusion: review of the literature. Spine. 2004; 29: 1938-1944.
32. Pope MH, Panjabi M. Biomechanical definition of spinal instability. Spine. 1985; 10: 255-256.
33. Swanson KE, Lindsey DP, Hsu KY, et al. The effects of an interspinous implant on intervertebral disc pressures. Spine. 2003; 28: 26-32.
The effects of an interspinous implant on intervertebral disc pressures. Spine. 2003; 28: 26-32.
34. Weiler PJ, King GJ, Gertzbein SD. Analysis of sagittal plane instability of the lumbar spine in vivo. Spine. 1990; 15: 1300-1306.
35. White AA, Panjabi MM. Clinical Biomechanics of the Spine. 2nd ed. Philadelphia: JB Lippincott, 1990. 752 p.
А. Р. Лурия, внимание, индивидуальные различия и локализация функций в лобных долях (целевой стимул)
A. P. Лурия также подчеркивал динамическую природу функционирования мозга. Мы изменяли требования задач к различным процессам внимания для того, чтобы, изучая поражения мозга, изучать динамические нейронные сети (Stuss, Murphy & Binns, 1999). Задача пространственного обнаружения (найди “что” – ответь “где”) позволяла оценить три различных процесса внимания: а) интерференция – торможение нерелевантной информации, предъявленной одновременно с целевым объектом; б) отрицательный эффект прайминга – влияние предшествующего торможения нерелевантной информации на дальнейшую переработку информации; в) торможение возврата – торможение моторного ответа на стимулы, предъявляемые на месте другого стимула, информация о котором только что была переработана. При трех уровнях сложности задачи измерялись показатели трех процессов внимания. При наименьшей сложности целевой стимул и дистракторы были все время одними и теми же простыми знаками, что позволяло просто связывать их с определенными ответами. На втором уровне сложности целевым стимулом была заглавная буква (A, D, Е или G в случайном порядке), которая задавалась в каждой пробе при помощи центральной подсказки, а в качестве дистрактора предъявлялась одна из оставшихся букв, также заглавная. Наконец, при третьем условии центральная подсказка, указывавшая, какая буква является стимулом, предъявлялась как строчная, а целевой стимул и дистракторы – как заглавные, что требует для успешною решения задачи по крайней мере опознать букву, то есть выйти за рамки чисто перцептивного сопоставления (достаточного для выполнения задачи при втором условии).
При трех уровнях сложности задачи измерялись показатели трех процессов внимания. При наименьшей сложности целевой стимул и дистракторы были все время одними и теми же простыми знаками, что позволяло просто связывать их с определенными ответами. На втором уровне сложности целевым стимулом была заглавная буква (A, D, Е или G в случайном порядке), которая задавалась в каждой пробе при помощи центральной подсказки, а в качестве дистрактора предъявлялась одна из оставшихся букв, также заглавная. Наконец, при третьем условии центральная подсказка, указывавшая, какая буква является стимулом, предъявлялась как строчная, а целевой стимул и дистракторы – как заглавные, что требует для успешною решения задачи по крайней мере опознать букву, то есть выйти за рамки чисто перцептивного сопоставления (достаточного для выполнения задачи при втором условии).
Независимо от той теоретической интерпретации, которую можно дать полученным результатам, данное исследование позволяет понять всю сложность функциональной системы внимания, указывает на взаимодействие ее лобных и внелобных компонентов, а также позволяет продвинуться в разграничении отдельных процессов внутри лобных долей и понимании сенситивности нервной системы к малейшим изменениям требований задачи. На степень интерференции оказывает влияние (но только на самом высоком уровне сложности задачи) поражение правой лобной доли (только правой и/ или двустороннее поражение, но не левое одностороннее). Похоже, что торможение внимания к нерелевантной информации является функцией правой лобной доли. С другой стороны, на торможении возврата сказывается поражение левой лобной доли, но весьма специфическим образом, зависящим от требований задачи. Более того, при третьем условии на деятельности испытуемого сказывалось и левостороннее поражение задних отделов мозга. Можно предположить, что отличия в условиях задачи или возрастание ее сложности заставили левое полушарие целиком включиться в ее решение. Отрицательный эффект прайминга не возникал при поражениях правого полушария на самом простом уровне сложности задачи, исходя из чего можно предположить существование правосторонней нейронной передне-задней системы, осуществляющей торможение пространственного выбора. По мере изменения (усложнения) требований задачи, нарушения появлялись во всех группах лобных больных, что говорит о недостаточности ресурсов либо необходимости участия дополнительных процессов, протекающих в лобных долях, в решении этой задачи.
На степень интерференции оказывает влияние (но только на самом высоком уровне сложности задачи) поражение правой лобной доли (только правой и/ или двустороннее поражение, но не левое одностороннее). Похоже, что торможение внимания к нерелевантной информации является функцией правой лобной доли. С другой стороны, на торможении возврата сказывается поражение левой лобной доли, но весьма специфическим образом, зависящим от требований задачи. Более того, при третьем условии на деятельности испытуемого сказывалось и левостороннее поражение задних отделов мозга. Можно предположить, что отличия в условиях задачи или возрастание ее сложности заставили левое полушарие целиком включиться в ее решение. Отрицательный эффект прайминга не возникал при поражениях правого полушария на самом простом уровне сложности задачи, исходя из чего можно предположить существование правосторонней нейронной передне-задней системы, осуществляющей торможение пространственного выбора. По мере изменения (усложнения) требований задачи, нарушения появлялись во всех группах лобных больных, что говорит о недостаточности ресурсов либо необходимости участия дополнительных процессов, протекающих в лобных долях, в решении этой задачи.
Заключение
А. Р. Лурия выделял различные процессы, относящиеся к высшим формам внимания: мобилизация произвольного внимания, избирательное распознавание определенных стимулов, торможение ответов на нерелевантные стимулы, поддержание целенаправленного поведения и способность изменять критерий ответа.
Наши результаты соответствуют этому предположению Лурия и также указывают на то, что по крайней мере некоторые из этих процессов связаны с разными областями мозга (см. также Stuss & Levine, 2002; Stuss et al., 2001; Stuss, et al., 2000). Мобилизация активного намерения, которую мы называем тонусом или активацией, связана с верхней медиальной лобной системой. Согласно результатам, полученным с помощью теста Струпа, эта область также может иметь отношение к поддержанию целенаправленного поведения. Избирательное распознавание определенных стимулов, по-видимому, сходно с нашим понятием постановки задачи, или установления определенного порога ответа на внешние стимулы. Этот процесс связан с левой дорсолатералыюй лобной системой.
Этот процесс связан с левой дорсолатералыюй лобной системой.
Благодаря системе, расположенной в правой дорсолатеральной области, осуществляется направление внимания на целевые стимулы или стимулы, заданные некоторой индивидуальной схемой (критерием ответа) и торможение ответов на конкурирующие стимулы. Поддержание стабильности выбранных ответов, которое мы описали как интраиндивидуальную изменчивость (Sluss, Murphy & Bines, 1999; Stuss et al., 1989; Stuss, Pogue, Buckie, & Bondar, 1994), также очевидно связано с лобными долями. Не существует единого лобного дефицита внимания. Когнитивная архитектура лобных долей оказывается дискретной – и анатомически, и функционально.
Поскольку очевидно, что внимание представляет собой многокомпонентную систему, и что лобные доли вносят вклад в целый ряд процессов, наши результаты также свидетельствуют в пользу комплексной динамической природы как высших, так и низших уровней внимания. Таким образом, аналогично компонентным процессам системы внимания в задних отделах мозга (Posner, 1988), в системе внимания, связанной с передними отделами мозга, существуют, как это и было предсказано Stuss, Shаllice, Alexander, and Picton (1995), раздельные процессы, связанные с различными областями лобных долей (см. Pardo et al., 1991; Posner, Petersen, Fox, & Raichle, 1988). Внимание – комплексная система, состоящая из многих компонентов, в которой динамически взаимодействуют различные процессы, определяемые требованиями задачи и протекающие как в лобных долях, так и в задних отделах мозга.
Pardo et al., 1991; Posner, Petersen, Fox, & Raichle, 1988). Внимание – комплексная система, состоящая из многих компонентов, в которой динамически взаимодействуют различные процессы, определяемые требованиями задачи и протекающие как в лобных долях, так и в задних отделах мозга.
Благодарность. Финансовую поддержку исследований, обобщенных в данной работе, осуществлял преимущественно Канадский институт исследований здоровья (# MRC-GR 1497). Мы благодарны всем нашим испытуемым, принимавшим участие в исследованиях, сотрудникам за их помощь в организации экспериментов, а также коллегам, выступавшим соавторами в тех публикациях, по которым был подготовлен Этот обзор. Помощь в подготовке рукописи оказали D. Derkzen and S. Gillingham.
ложные тревоги – предыдущая | следующая – типология нормы
А. Р. Лурия и психология XXI века. Содержание
Определение
в кембриджском словаре английского языка
По-видимому, нет, потому что другие отвлекающие факторы не имеют такого же негативного эффекта.
Из Вашингтон Пост
В основном пункты, которые поднимают критики, являются отвлекающими факторами.
Из Вашингтон Пост
Игра включает в себя сопоставление изображений транспортных средств с запоминанием местоположения определенного дорожного знака, поскольку по мере продвижения игрока появляется все больше и больше «отвлекающих факторов».
От Хаффингтон Пост
Два целевых игрушечных животных вместе с несколькими игрушечными животными-дистракторами были помещены в ряд.
Из Кембриджского корпуса английского языка
Это похожее на привыкание снижение на 9Эффективность дистрактора 0018 выше у детей старшего возраста.
Из Кембриджского корпуса английского языка
Сначала мы подсчитали процент саккад, выполненных для каждого типа дистракторов , в испытаниях, в которых начальная саккада выполнялась для дистракторов.0018 дистрактор .
Из Кембриджского корпуса английского языка
В неоднородных условиях каждая из пяти дистракторных цветностей была случайным образом назначена двум стимулам на дисплее с одним исключением.
Из Кембриджского корпуса английского языка
В этом испытании правильная альтернатива и дистрактор были наиболее близки с точки зрения общего сходства.
Из Кембриджского корпуса английского языка
Мы измерили эффективность, основываясь на точном зарегистрированном времени, чтобы написать или классифицировать дистрактор .
Из Кембриджского корпуса английского языка
Мы измерили качество отвлекающего фактора как процент категоризаций, соответствующих его предполагаемому типу.
Из Кембриджского корпуса английского языка
Дополнительным критерием оценки было время: мы хотели знать, сколько времени потребовалось людям, чтобы классифицировать или написать каждый тип дистракторов .
Из Кембриджского корпуса английского языка
В нашем сравнении качества дистракторов обязательно использовалось ограниченное количество судей (пять), текстов (семь) и основ вопросов (шестнадцать).
Из Кембриджского корпуса английского языка
На низком уровне мы определили качество дистрактор по тому, как часто он воспринимался как предполагаемый тип.
Из Кембриджского корпуса английского языка
Выбор бессмысленного дистрактора указывает на неспособность обнаружить локальное семантическое несоответствие с остальной частью предложения.
Из Кембриджского корпуса английского языка
Мы определяем отвлекаемость дистрактора как частоту, с которой учащиеся предпочитают его правильному ответу.
Из Кембриджского корпуса английского языка
Эти примеры взяты из корпусов и источников в Интернете. Любые мнения в примерах не отражают мнение редакторов Кембриджского словаря, издательства Кембриджского университета или его лицензиаров.
Любые мнения в примерах не отражают мнение редакторов Кембриджского словаря, издательства Кембриджского университета или его лицензиаров.
Жаргон ABA: Отвлекающий — Люблю моего поставщика услуг
Итак, сегодняшний термин, современный жаргонный термин — «отвлекающий». Теперь мы не говорим о СДВГ и отвлекаемся на вещи. Я люблю в фильме «Вверх» собаку, которая-, он говорит, и он очень разговорчив, и «Да, это…», а потом вдруг: «Белка!». Он отвлекается, да? Это не тот вид. Мы не говорим о белках здесь, для отвлечения внимания. Но это то, что очень важно как инструмент обучения. Так о чем именно мы говорим? Давайте сначала посмотрим на наше фактическое определение.
Дистрактор — дополнительный раздражитель. Я знаю, разве у тебя не начинает болеть голова всякий раз, когда ты слышишь слово «стимул»? Дополнительный стимул, который предъявляется вместе с целью во время дискриминационного обучения. . . обучение дискриминации, извините. Дистракторами могут быть ранее усвоенные стимулы или неизвестные стимулы. О, есть это слово, которое я ненавижу, ненавижу и презираю, а потом вы говорите: «Какое это имеет отношение ко мне? Почему бы им не перевести это на другой английский язык?»
О, есть это слово, которое я ненавижу, ненавижу и презираю, а потом вы говорите: «Какое это имеет отношение ко мне? Почему бы им не перевести это на другой английский язык?»
Хорошо, мы сделаем это за вас. Ваше рабочее определение «отвлекающего» — это дополнительный элемент вместо стимулов, представленный рядом с мишенью, чтобы проверить, может ли ребенок по-прежнему выбирать правильный ответ, когда у него есть более чем один вариант выбора. Хорошо, я могу сказать вам, что мне немного помог BCBA, потому что я бы существенно изменил это. Так что «отвлекайте», когда вы чему-то обучаете, особенно когда мы используем действительно хороший ABA и проводим DTT, что является дискриминационным. . . Правильно? ДТТ? У меня нет сегодня утром, это не… Дискриминационная пробная тренировка. Да, это то, что это такое. Я думаю. Но это тип обучения.
Дискретное пробное обучение, обучение. Где моя голова? Можно ли сказать, что я был в отпуске? ДТТ, я знаю, как это выглядит, но не могу произнести. Итак, мы начинаем часто учить чему-то безошибочное обучение. Мы хотим убедиться, что человек, которого мы учим, все сделает правильно, несмотря ни на что, с самого начала. Итак, если то, чему я пытаюсь научить, наша цель — это то, чему мы пытаемся научить, и если прямо сейчас то, чему я пытаюсь научить, — это «ручка». Тогда я, вероятно, нашел бы лучшую ручку, чем эта, потому что это очень интересная ручка, которую я буду использовать позже, но, тем не менее, это ручка, и поэтому я могу начать учить ребенка «ручке», и я, вероятно, начну. с рецептивной целью, заставить их понять, что, когда я говорю «ручка», я имею в виду вот что.
Итак, мы начинаем часто учить чему-то безошибочное обучение. Мы хотим убедиться, что человек, которого мы учим, все сделает правильно, несмотря ни на что, с самого начала. Итак, если то, чему я пытаюсь научить, наша цель — это то, чему мы пытаемся научить, и если прямо сейчас то, чему я пытаюсь научить, — это «ручка». Тогда я, вероятно, нашел бы лучшую ручку, чем эта, потому что это очень интересная ручка, которую я буду использовать позже, но, тем не менее, это ручка, и поэтому я могу начать учить ребенка «ручке», и я, вероятно, начну. с рецептивной целью, заставить их понять, что, когда я говорю «ручка», я имею в виду вот что.
Позже я бы попытался поставить выразительную цель, когда они говорят «ручка», верно? И я бы сделал их взаимозаменяемыми, но я мог бы начать со слов. . . Ну, много раз мы начинаем с . . . Я тянусь за реквизитом. Начнем с сопоставления. Итак, если бы у меня были две совершенно одинаковые ручки, я бы начал с двух совершенно одинаковых ручек. Я бы положил одну ручку и дал бы эту ручку человеку, и я бы сказал: «Положи такой же», верно? Чтобы они посмотрели и сказали: «Это такие же», а я говорю: «Да, это ручка». Верно? Тогда я бы начал с того, что сказал. . . после этого я говорил: «Прикоснись к ручке» и мог даже взять ребенка за руку и попросить его прикоснуться к ручке.
Верно? Тогда я бы начал с того, что сказал. . . после этого я говорил: «Прикоснись к ручке» и мог даже взять ребенка за руку и попросить его прикоснуться к ручке.
Ребенок уже знает, что это ручка? Нет, не знают. Особенность DTT в том, что когда вы смотрите его как родитель, как учитель, вы думаете: «Ну, на самом деле вы их ничему не учите». Не в той первой фазе, верно? Мы просто приучаем их к этому и вознаграждаем за это. Итак, вы говорите: «Прикоснитесь к ручке». «О, ты дотронулся до ручки, это ручка». Верно? И я мог бы сделать это десять раз, верно? «Прикоснитесь к ручке», и они прикоснутся к ручке: «Ура!» И после десяти раз они получили огромную награду, между ними они получили похвалу, верно?
Итак, я больше не подсказываю, а говорю: «Прикоснись к ручке», они прикасаются к ручке, но там нет ничего, кроме ручки, к которой они могли бы прикоснуться, верно? Вот почему это безошибочное обучение.
Итак, в конце концов, я должен поместить другие элементы в то, что они называют «полем» или «массивом», чтобы они могли заметить разницу. Итак, у меня есть чашка здесь, поэтому я ставлю ручку и чашку сюда и говорю: «Прикоснись к ручке», так что чашка отвлекает внимание, и я могу сказать вам, что в начале ребенок идет, и они собирается коснуться чашки. Потому что, возможно, чашка является для них более подкрепляющей, они хотят видеть, что в чашке, что угодно, и мы не придаем этому большого значения, но мы подскажем им и скажем: «Прикоснись к ручке», и пусть они положат свои рука на ручке.
Итак, у меня есть чашка здесь, поэтому я ставлю ручку и чашку сюда и говорю: «Прикоснись к ручке», так что чашка отвлекает внимание, и я могу сказать вам, что в начале ребенок идет, и они собирается коснуться чашки. Потому что, возможно, чашка является для них более подкрепляющей, они хотят видеть, что в чашке, что угодно, и мы не придаем этому большого значения, но мы подскажем им и скажем: «Прикоснись к ручке», и пусть они положат свои рука на ручке.
Затем я менял порядок, и, в конце концов, мы доходили до массива из трех, затем я говорил: «Прикоснись к ручке», и они касались ручки, и мы щедро вознаграждали их за то, что они прикоснулись к ручке. Проходит некоторое время, прежде чем они на самом деле узнают, что такое ручка, и, конечно, есть еще много шагов к этому, но дистрактор — это то, что помогает им увидеть, что «это не ручка», и мы не обращаясь к этому прямо сейчас. Мы просто кладем его туда, говоря: «Прикоснись к ручке», и они прикасаются к ручке, и они начинают узнавать, что такое ручка. Это требует терпения, но это работает.
Это требует терпения, но это работает.
Разработка отвлекающих элементов с множественным выбором с использованием подходов тематического моделирования
- Список журналов
- Фронт Психол
- PMC6524712
Передний психол. 2019; 10: 825.
Опубликовано в сети 25 апреля 2019 г. doi: 10.3389/fpsyg.2019.00825
Информация об авторе Примечания к статье Информация об авторских правах и лицензии Отказ от ответственности
- Дополнительные материалы
Написание высококачественного тестового задания с множественным выбором — сложный процесс. Создание правдоподобных, но неправильных вариантов для каждого элемента создает серьезные проблемы для специалиста по контенту, потому что эта задача часто выполняется без применения систематического метода. В текущем исследовании мы описываем и демонстрируем систематический метод создания правдоподобных, но неправильных вариантов, также называемых отвлекающими факторами, на основе неверных представлений учащихся. Эти заблуждения извлечены из помеченных письменных ответов. Для демонстрации метода были использованы тысяча пятьсот пятнадцать письменных ответов учащихся 10-х классов из существующего задания на построение ответов по биологии. Используя процедуру тематического моделирования, обычно используемую с машинным обучением и обработкой естественного языка, называемую скрытым распределением Дирихле, были выявлены 22 правдоподобных заблуждения из письменных ответов учащихся, которые использовались для составления списка вероятных отвлекающих факторов на основе ответов учащихся. Эти отвлекающие факторы, в свою очередь, использовались как часть новых заданий с множественным выбором. Обсуждаются последствия для разработки пункта.
В текущем исследовании мы описываем и демонстрируем систематический метод создания правдоподобных, но неправильных вариантов, также называемых отвлекающими факторами, на основе неверных представлений учащихся. Эти заблуждения извлечены из помеченных письменных ответов. Для демонстрации метода были использованы тысяча пятьсот пятнадцать письменных ответов учащихся 10-х классов из существующего задания на построение ответов по биологии. Используя процедуру тематического моделирования, обычно используемую с машинным обучением и обработкой естественного языка, называемую скрытым распределением Дирихле, были выявлены 22 правдоподобных заблуждения из письменных ответов учащихся, которые использовались для составления списка вероятных отвлекающих факторов на основе ответов учащихся. Эти отвлекающие факторы, в свою очередь, использовались как часть новых заданий с множественным выбором. Обсуждаются последствия для разработки пункта.
Ключевые слова: задания с множественным выбором, дистракторы, неверные представления, генерация дистракторов, латентное распределение Дирихле
Тестирование с множественным выбором является одной из самых устойчивых и успешных форм образовательной оценки, которая остается на практике сегодня. Задания с множественным выбором используются в образовательном тестировании, поскольку они позволяют измерять различные типы знаний, навыков и компетенций (Haladyna, 2004; Downing, 2006; Popham, 2008). Элементы с множественным выбором эффективны в управлении; их легко объективно оценить; их можно использовать для выборки широкого спектра контента; для их введения требуется относительно короткое время (Haladyna, 2004; Haladyna and Rodriguez, 2013; Rodriguez, 2016). Даунинг (2006, стр. 288) в своей основополагающей главе в Handbook of Test Development , утверждалось, что элементы с выбранным ответом, такие как множественный выбор, являются наиболее подходящим форматом для измерения когнитивных достижений или способностей, особенно когнитивных навыков более высокого порядка, таких как решение проблем, синтез и оценка. Он также заявил, что этот формат заданий полезен и подходит для создания экзаменов, предназначенных для измерения широкого спектра знаний, способностей или когнитивных навыков во многих областях.
Задания с множественным выбором используются в образовательном тестировании, поскольку они позволяют измерять различные типы знаний, навыков и компетенций (Haladyna, 2004; Downing, 2006; Popham, 2008). Элементы с множественным выбором эффективны в управлении; их легко объективно оценить; их можно использовать для выборки широкого спектра контента; для их введения требуется относительно короткое время (Haladyna, 2004; Haladyna and Rodriguez, 2013; Rodriguez, 2016). Даунинг (2006, стр. 288) в своей основополагающей главе в Handbook of Test Development , утверждалось, что элементы с выбранным ответом, такие как множественный выбор, являются наиболее подходящим форматом для измерения когнитивных достижений или способностей, особенно когнитивных навыков более высокого порядка, таких как решение проблем, синтез и оценка. Он также заявил, что этот формат заданий полезен и подходит для создания экзаменов, предназначенных для измерения широкого спектра знаний, способностей или когнитивных навыков во многих областях.
Благодаря этим важным преимуществам задания с множественным выбором по-прежнему пользуются широкой популярностью и, следовательно, могут применяться в образовании, несмотря на некоторые потенциальные недостатки, такие как эффект угадывания и непреднамеренное предоставление учащимся неверной информации. Учащиеся из Северной Америки проходят сотни тестов с несколькими вариантами ответов и отвечают на тысячи вопросов с несколькими вариантами ответов в рамках своего образовательного опыта. Chingos (2012) сообщил, что треть жителей Соединенных Штатов используют задания с несколькими вариантами ответов исключительно для оценки навыков математики и чтения учащихся 4-х и 8-х классов. В высшем образовании тест с несколькими вариантами ответов является распространенным и широко используемым форматом оценки для измерения знаний студентов, особенно на вводных курсах с большой группой студентов. Тестирование с множественным выбором также широко используется для международных оценок. Например, в отчете The Trends in International Mathematics and Science Study (TIMSS) за 2015 год половина предметов по математике и естественным наукам использовала формат множественного выбора (Mullis et al. , 2016). При проведении в 2015 году Программы международной оценки учащихся (PISA) две трети заданий по чтению, математике и естественным наукам оценивались с множественным выбором (OECD, 2016).
, 2016). При проведении в 2015 году Программы международной оценки учащихся (PISA) две трети заданий по чтению, математике и естественным наукам оценивались с множественным выбором (OECD, 2016).
Элемент множественного выбора состоит из основы, опций и вспомогательной информации. Основа содержит контекст, содержание и/или вопрос, на который студент должен ответить. Варианты включают набор альтернативных ответов с одним правильным вариантом и одним или несколькими неправильными вариантами или отвлекающими факторами. Вспомогательная информация включает в себя любой дополнительный контент в основе или опции, необходимый для создания элемента, включая текст, изображения, таблицы, графики, диаграммы, аудио и/или видео. Чтобы ответить на вопрос с несколькими вариантами ответов, учащемуся предлагается основа и два или более вариантов ответа, различающихся своей относительной правильностью. Студенты должны различать варианты ответов, некоторые из которых могут быть частично правильными, чтобы выбрать лучший или наиболее правильный вариант.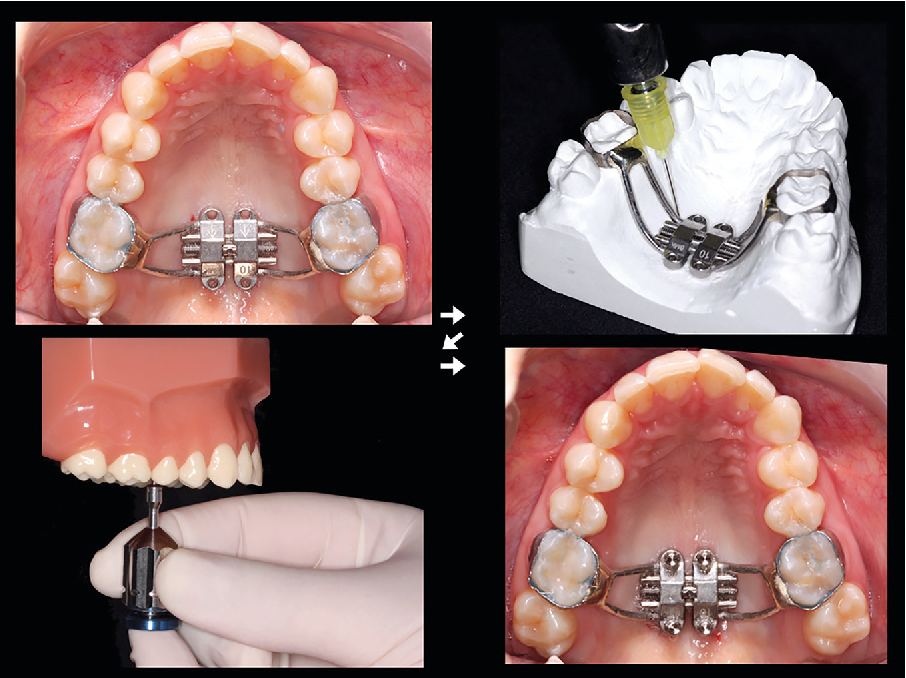 Следовательно, учащийся должен использовать свои знания и навыки решения проблем, чтобы определить взаимосвязь между содержанием основы и правильным вариантом. Неправильные варианты называются отвлекающими факторами, потому что они считаются «отвлекающими» учащихся с частичными знаниями из-за их вероятности получения правильного варианта.
Следовательно, учащийся должен использовать свои знания и навыки решения проблем, чтобы определить взаимосвязь между содержанием основы и правильным вариантом. Неправильные варианты называются отвлекающими факторами, потому что они считаются «отвлекающими» учащихся с частичными знаниями из-за их вероятности получения правильного варианта.
Создание элементов с множественным выбором — сложная задача, особенно когда речь идет о разработке отвлекающих факторов, из-за огромного объема требуемой работы. Например, чтобы создать 100 элементов с множественным выбором, состоящих из одного правильного и четырех неверных вариантов, специалист по контенту должен создать 100 основ и 100 правильных вариантов. Контентщику также необходимо создать 400 правдоподобных, но неверных вариантов. Эта задача разработки отвлекающих факторов одновременно сложна и часто безуспешна. Галадина и Даунинг (1993) оценивали дистракторы по четырем стандартизированным тестам с множественным выбором. Они оценивали качество и правдоподобие отвлекающих факторов на основе привлекательности отвлекающих факторов. В частности, они подчеркнули, что правдоподобные отвлекающие факторы должны привлекать более 5% учащихся с низкой успеваемостью, которые не смогли определить правильный ответ. Основываясь на таких критериях, они обнаружили, что только 8% предметов содержали эффективные отвлекающие факторы.
В частности, они подчеркнули, что правдоподобные отвлекающие факторы должны привлекать более 5% учащихся с низкой успеваемостью, которые не смогли определить правильный ответ. Основываясь на таких критериях, они обнаружили, что только 8% предметов содержали эффективные отвлекающие факторы.
Чтобы решить проблему создания большого количества эффективных отвлекающих факторов, исследователи и практики изучили и внедрили различные стратегии. Наиболее распространенная стратегия фокусируется на списке правдоподобных, но неверных альтернатив, связанных с распространенными заблуждениями или ошибками в мышлении, рассуждениях и решении проблем (Халадина и Даунинг, 19).89; Кейс и Суонсон, 2001 г.; Vacc и др., 2001; Коллинз, 2006 г.; Морено и др., 2006, 2015; де ла Торре, 2009 г.; Таррант и др., 2009 г.; Родригес, 2011, 2016). Haladyna and Rodriguez (2013) в своем учебнике «Разработка и проверка валидности заданий » утверждают, что наиболее эффективным способом разработки правдоподобных отвлекающих факторов с использованием неверных представлений является выявление «общих ошибок», вызванных определенной основой в подсказке задания. Эти распространенные ошибки служат кандидатами на роль вероятных отвлекающих факторов. Халадина и Родригес заявляют, что распространенные ошибки можно определить двумя способами. Во-первых, их можно определить, используя суждения специалистов по содержанию, которые хорошо разбираются в преподавании и обучении в конкретной предметной области и могут указать распространенные ошибки и заблуждения, возникающие при изучении новой темы или концепции. Во-вторых, их можно выявить, оценив ответы учащегося на задание со сконструированным ответом (т. е. задание, которое содержит основу без вариантов), когда в ответах учащегося задокументированы ошибки в рассуждениях, мышлении и решении проблем. Второй подход — извлечение ответов учащихся из элементов с построенными ответами — является предпочтительной стратегией выявления распространенных ошибок, поскольку он основан на фактических процессах ответов учащихся, а не на ожидаемых процессах ответов, выведенных из суждений специалистов по содержанию о том, как учащиеся реагируют на заданные вопросы.
Эти распространенные ошибки служат кандидатами на роль вероятных отвлекающих факторов. Халадина и Родригес заявляют, что распространенные ошибки можно определить двумя способами. Во-первых, их можно определить, используя суждения специалистов по содержанию, которые хорошо разбираются в преподавании и обучении в конкретной предметной области и могут указать распространенные ошибки и заблуждения, возникающие при изучении новой темы или концепции. Во-вторых, их можно выявить, оценив ответы учащегося на задание со сконструированным ответом (т. е. задание, которое содержит основу без вариантов), когда в ответах учащегося задокументированы ошибки в рассуждениях, мышлении и решении проблем. Второй подход — извлечение ответов учащихся из элементов с построенными ответами — является предпочтительной стратегией выявления распространенных ошибок, поскольку он основан на фактических процессах ответов учащихся, а не на ожидаемых процессах ответов, выведенных из суждений специалистов по содержанию о том, как учащиеся реагируют на заданные вопросы. тестовые задания. Однако выявление и извлечение распространенных ошибок и неправильных представлений из реальных процессов реагирования является сложной задачей, поскольку необходимо обрабатывать большие объемы данных реагирования, и эти данные, в свою очередь, должны быть точно классифицированы, чтобы определить результаты, которые могут быть использованы в качестве отвлекающих факторов.
тестовые задания. Однако выявление и извлечение распространенных ошибок и неправильных представлений из реальных процессов реагирования является сложной задачей, поскольку необходимо обрабатывать большие объемы данных реагирования, и эти данные, в свою очередь, должны быть точно классифицированы, чтобы определить результаты, которые могут быть использованы в качестве отвлекающих факторов.
Целью данного исследования является внедрение подхода с использованием расширенного интеллекта для систематического выявления и классификации неправильных представлений из письменных ответов учащихся, предварительно помеченных для создания отвлекающих факторов, которые можно использовать для заданий с множественным выбором. Дополненный интеллект — это область искусственного интеллекта, которая касается того, как компьютерные системы могут эмулировать и расширять когнитивные способности человека, тем самым помогая улучшить выполнение человеком задач и улучшить решение проблем человеком (Zheng et al. , 2017). Требуется взаимодействие между человеком и компьютерной системой, чтобы система могла выдать результат или решение. Дополненный интеллект сочетает способность человека к суждениям с возможностями современных вычислений, использующих вычислительный анализ и хранение данных для решения сложных и, как правило, неструктурированных задач. Таким образом, расширенный интеллект можно использовать для характеристики любого процесса или системы, которые улучшают способность человека решать сложные проблемы, полагаясь на партнерство между человеком и машиной (Pan, 2016; Popenici and Kerr, 2017).
, 2017). Требуется взаимодействие между человеком и компьютерной системой, чтобы система могла выдать результат или решение. Дополненный интеллект сочетает способность человека к суждениям с возможностями современных вычислений, использующих вычислительный анализ и хранение данных для решения сложных и, как правило, неструктурированных задач. Таким образом, расширенный интеллект можно использовать для характеристики любого процесса или системы, которые улучшают способность человека решать сложные проблемы, полагаясь на партнерство между человеком и машиной (Pan, 2016; Popenici and Kerr, 2017).
Мы представляем и демонстрируем метод расширенного интеллекта, который можно использовать для развития дистракторов с использованием латентного выделения Дирихле (LDA; Blei et al., 2003). LDA — это статистическая модель, используемая в машинном обучении и обработке естественного языка, которая определяет определенные темы и понятия в письменных текстах. Ожидается, что определенные слова будут появляться в письменном тексте более или менее часто в зависимости от конкретной темы. LDA можно использовать для отражения этого ожидаемого результата в математической структуре, сосредоточив внимание на том, сколько раз слова появлялись в письменном тексте по разным темам. Используя LDA, специалисты по контенту могут выявлять фактические заблуждения на основе процессов ответов учащихся, чтобы создавать списки вероятных отвлекающих факторов.
LDA можно использовать для отражения этого ожидаемого результата в математической структуре, сосредоточив внимание на том, сколько раз слова появлялись в письменном тексте по разным темам. Используя LDA, специалисты по контенту могут выявлять фактические заблуждения на основе процессов ответов учащихся, чтобы создавать списки вероятных отвлекающих факторов.
Традиционный подход к разработке отвлекающих факторов
Отвлекающие факторы являются одним из ключевых компонентов, влияющих на общее качество заданий с множественным выбором, а также на их статистические характеристики (Gierl et al., 2017). Дистракторы предназначены для того, чтобы отличать учащихся, которые еще не приобрели знания, необходимые для правильного ответа на вопрос, от тех, кто понимает содержание. Таким образом, дистракторы в задании с множественным выбором предназначены для того, чтобы содержать правдоподобные, но неправильные ответы, основанные на распространенных ошибках или заблуждениях учащихся, чтобы этот вариант мог измерять уровень мастерства учащихся в определенной области содержания (например, Кейс и Суонсон, 2001; Ascalon et al. , 2007; Hoshino, 2013; Towns, 2014; Lai et al., 2016). Создание отвлекающих факторов с использованием распространенных ошибок и неправильных представлений приводит к заданиям с множественным выбором с повышенной диагностической ценностью, а также к более высокому качеству заданий (Халадина и Даунинг, 19).89; Кейс и Суонсон, 2001 г.; Бриггс и др., 2006 г.; Морено и др., 2006, 2015; де ла Торре, 2009 г.; Таррант и др., 2009 г.; Родригес, 2011, 2016).
, 2007; Hoshino, 2013; Towns, 2014; Lai et al., 2016). Создание отвлекающих факторов с использованием распространенных ошибок и неправильных представлений приводит к заданиям с множественным выбором с повышенной диагностической ценностью, а также к более высокому качеству заданий (Халадина и Даунинг, 19).89; Кейс и Суонсон, 2001 г.; Бриггс и др., 2006 г.; Морено и др., 2006, 2015; де ла Торре, 2009 г.; Таррант и др., 2009 г.; Родригес, 2011, 2016).
Haladyna and Rodriguez (2013) утверждали, что распространенные ошибки и заблуждения можно выявить с помощью двух разных подходов. При первом подходе специалисты по контенту вручную создают отдельные отвлекающие факторы, которые содержат эти распространенные ошибки и заблуждения. Коллинз (2006) рекомендовал, чтобы специалисты по контенту имитировали процессы решения задач учащимися, отвечая на такие вопросы, как «Какая распространенная ошибка при решении этой проблемы?» и «с чем студенты обычно путают это понятие или идею?» для выявления возможных отвлекающих факторов. Наиболее привлекательным аспектом этого метода является его практичность и простота реализации. Дистракторы создаются специалистами по контенту, знакомыми с учащимися и областью контента, чтобы имитировать типичные и распространенные проблемы, которые могут возникнуть с наибольшей вероятностью. Хотя этот подход возможен, он также основан на трех допущениях. Во-первых, специалисты по контенту могут указать правдоподобные алгоритмы, правила или источники информации. Во-вторых, с помощью этих источников можно создавать правдоподобные, но неправильные дистракторы. В-третьих, заблуждения, выявленные специалистами по контенту из этих источников, на самом деле являются теми же заблуждениями, которых придерживаются студенты. Правильное согласование предположений имеет решающее значение для создания отвлекающих факторов, которые измеряют фактические ошибки и неправильные представления учащихся. Более того, выравнивание должно выполняться для каждого отвлекающего фактора в каждом элементе множественного выбора.
Наиболее привлекательным аспектом этого метода является его практичность и простота реализации. Дистракторы создаются специалистами по контенту, знакомыми с учащимися и областью контента, чтобы имитировать типичные и распространенные проблемы, которые могут возникнуть с наибольшей вероятностью. Хотя этот подход возможен, он также основан на трех допущениях. Во-первых, специалисты по контенту могут указать правдоподобные алгоритмы, правила или источники информации. Во-вторых, с помощью этих источников можно создавать правдоподобные, но неправильные дистракторы. В-третьих, заблуждения, выявленные специалистами по контенту из этих источников, на самом деле являются теми же заблуждениями, которых придерживаются студенты. Правильное согласование предположений имеет решающее значение для создания отвлекающих факторов, которые измеряют фактические ошибки и неправильные представления учащихся. Более того, выравнивание должно выполняться для каждого отвлекающего фактора в каждом элементе множественного выбора. Используя наш предыдущий пример, если специалист по контенту пишет 100 элементов с множественным выбором, и каждый элемент содержит пять вариантов (т. е. один правильный вариант и четыре отвлекающих фактора), тогда специалист по контенту должен определить 400 правдоподобных, но неправильных альтернатив, которые удовлетворяют этим трем предположениям.
Используя наш предыдущий пример, если специалист по контенту пишет 100 элементов с множественным выбором, и каждый элемент содержит пять вариантов (т. е. один правильный вариант и четыре отвлекающих фактора), тогда специалист по контенту должен определить 400 правдоподобных, но неправильных альтернатив, которые удовлетворяют этим трем предположениям.
При втором подходе ответы учащихся на существующие задания со сконструированными ответами оцениваются для выявления распространенных ошибок и неправильных представлений. То есть специалисты по контенту просматривают ответы учащихся на элементы с построенным ответом, чтобы выявить ошибки, ошибки и непонимание, а затем классифицируют эти результаты, чтобы создать скомпилированный список вероятных отвлекающих факторов (например, Bekkink et al., 2016). Этот подход решил проблему логического вывода, связанную с предыдущим подходом, поскольку он основан на фактических данных ответов учащихся, а не на суждениях об ожидаемых процессах ответов. Другими словами, второй подход основан на данных. Распространенные ошибки и заблуждения, выявленные с помощью второго подхода, возникают из-за алгоритмов, правил или источников информации, используемых учащимися для получения неправильных ответов. К сожалению, второй подход страдает от проблемы практичности и простоты реализации, поскольку он не практичен и не прост в использовании. В том виде, в каком он реализован в настоящее время, второй подход является пугающим, поскольку он предполагает всесторонний обзор письменных ответов учащихся с использованием ручного процесса с целью выявления распространенных ошибок и неправильных представлений, которые возникают последовательно и систематически. Это также процесс, сопряженный с интерпретационными проблемами, поскольку выявление типичных ошибок и неверных представлений, которые возникают систематически, может быть субъективной задачей (например, каковы характеристики систематического заблуждения). И, несмотря на потенциальные преимущества использования подхода, основанного на данных, практически также диктуется, что процесс разработки элементов должен быть относительно быстрым и эффективным, даже когда требуется большое количество элементов с множественным выбором.
Другими словами, второй подход основан на данных. Распространенные ошибки и заблуждения, выявленные с помощью второго подхода, возникают из-за алгоритмов, правил или источников информации, используемых учащимися для получения неправильных ответов. К сожалению, второй подход страдает от проблемы практичности и простоты реализации, поскольку он не практичен и не прост в использовании. В том виде, в каком он реализован в настоящее время, второй подход является пугающим, поскольку он предполагает всесторонний обзор письменных ответов учащихся с использованием ручного процесса с целью выявления распространенных ошибок и неправильных представлений, которые возникают последовательно и систематически. Это также процесс, сопряженный с интерпретационными проблемами, поскольку выявление типичных ошибок и неверных представлений, которые возникают систематически, может быть субъективной задачей (например, каковы характеристики систематического заблуждения). И, несмотря на потенциальные преимущества использования подхода, основанного на данных, практически также диктуется, что процесс разработки элементов должен быть относительно быстрым и эффективным, даже когда требуется большое количество элементов с множественным выбором. Это требование сложно выполнить с помощью второго подхода, особенно когда большое количество письменного текста доступно из элемента построенного ответа.
Это требование сложно выполнить с помощью второго подхода, особенно когда большое количество письменного текста доступно из элемента построенного ответа.
На сегодняшний день было проведено ограниченное количество исследований по изучению применения расширенного интеллекта для разработки отвлекающих факторов. Исследователи изучили важность использования неправильных представлений и распространенных ошибок учащихся для создания отвлекающих факторов. Подход, использованный в этих исследованиях, был основан на выявлении неправильных представлений с использованием письменных или устных ответов учащихся, которые, в свою очередь, вручную классифицировались специалистами по контенту для выявления распространенных ошибок и неправильных представлений (например, Vacc et al., 2001; Haladyna and Rodriguez, 2013; Moreno et al., 2015; Bekkink et al., 2016; Rodriguez, 2016). Как отмечалось ранее, подход на основе данных с использованием ответов учащихся по своей сути полезен для выявления фактических ошибок и неправильных представлений, которые используют учащиеся, когда они дают неправильные ответы. Но он также по своей природе ограничен, потому что выявление и классификация ошибок в письменном тексте с использованием процесса ручного просмотра требует чрезмерно много времени и труда. Чтобы преодолеть это ограничение, мы представляем и иллюстрируем основанный на данных метод создания отвлекающих факторов на основе распространенных ошибок и заблуждений учащихся с использованием LDA.
Но он также по своей природе ограничен, потому что выявление и классификация ошибок в письменном тексте с использованием процесса ручного просмотра требует чрезмерно много времени и труда. Чтобы преодолеть это ограничение, мы представляем и иллюстрируем основанный на данных метод создания отвлекающих факторов на основе распространенных ошибок и заблуждений учащихся с использованием LDA.
Моделирование темы и скрытое распределение Дирихле
Поиск ключевых слов и тем для понимания текста — это простой и эффективный способ классификации текстовой информации. Например, для сбора информации по определенным темам мы часто начинаем с генерации одного или двух ключевых слов, чтобы найти соответствующие документы с общими темами. К сожалению, этот подход быстро становится неуправляемым для человека, когда объем текстовой информации начинает увеличиваться. Например, если специалисты по контенту вручную просматривают тысячи ответов учащихся, чтобы выявить, а затем классифицировать распространенные ошибки, это будет трудоемким и неэффективным упражнением по классификации.
Чтобы преодолеть эту проблему кластеризации, было разработано тематическое моделирование, которое используется с алгоритмами машинного обучения и обработки естественного языка для выявления скрытых тем в документе (Blei, 2012). Эти скрытые темы могут быть идентифицированы без какой-либо предварительной маркировки, что означает, что тематические модели не требуют предварительно категоризированных или помеченных темами документов. В машинном обучении эти проблемы описываются как подход к обучению без учителя, что означает, что структура проблемы включает в себя цели или результаты, которые неизвестны, и, следовательно, основное внимание в обучении уделяется пониманию структуры данных. Поэтому при тематическом моделировании мы пытаемся выявить скрытые или ненаблюдаемые цели, темы, используя полностью наблюдаемую информацию, слова.
Если мы предположим, что последовательность слов в документе определяется одной и той же ненаблюдаемой темой, то мы можем просто вычислить вероятность того, что документ представляет определенную тему, чтобы определить основную тему документа в неконтролируемой обстановке. Чтобы найти общие темы, моделирование тем использует информацию о встречаемости слов, где ожидается, что определенные слова будут появляться в документе более или менее часто в зависимости от конкретной темы. LDA представляет собой генеративный вероятностный алгоритм моделирования темы (Blei et al., 2003), где каждый документ воспринимается как смесь нескольких тем. Генеративные модели принимают во внимание информацию о том, как были сгенерированы наблюдаемые данные, для построения модели. Предположим, например, что у нас есть документы, сгенерированные сложными неизвестными процедурами.
Чтобы найти общие темы, моделирование тем использует информацию о встречаемости слов, где ожидается, что определенные слова будут появляться в документе более или менее часто в зависимости от конкретной темы. LDA представляет собой генеративный вероятностный алгоритм моделирования темы (Blei et al., 2003), где каждый документ воспринимается как смесь нескольких тем. Генеративные модели принимают во внимание информацию о том, как были сгенерированы наблюдаемые данные, для построения модели. Предположим, например, что у нас есть документы, сгенерированные сложными неизвестными процедурами.
Скрытое распределение Дирихле пытается синтезировать аппроксимированную процедуру генерации и наблюдаемую информацию (например, слова) для выявления скрытых тем без каких-либо меток. Более того, в отличие от других подходов к моделированию тем, LDA может не только создавать интерпретируемые темы, но и обрабатывать невидимые документы для назначения тем. Генеративный процесс LDA состоит из трех уровней выборки распределения тем, выборки тем и выборки слов по темам. Например, после определения количества слов (или длины документа) и количества тем указывается распределение тем (например, 40 % биологии, 30 % кинетики и 30 % психологии). Затем тема выбирается на основе распределения смеси тем, а слово выбирается на основе распределения слов, соответствующих теме. Затем этот процесс повторяется до тех пор, пока не будут сгенерированы все слова для каждого документа. описывает графическое представление генеративного процесса LDA.
Например, после определения количества слов (или длины документа) и количества тем указывается распределение тем (например, 40 % биологии, 30 % кинетики и 30 % психологии). Затем тема выбирается на основе распределения смеси тем, а слово выбирается на основе распределения слов, соответствующих теме. Затем этот процесс повторяется до тех пор, пока не будут сгенерированы все слова для каждого документа. описывает графическое представление генеративного процесса LDA.
Открыть в отдельном окне
Концептуальное представление скрытого распределения дирихле (LDA).
Учитывая этот процесс, LDA пытается исследовать скрытые темы в документе, вычисляя апостериорное распределение скрытых переменных для данного документа. Из-за большого количества возможных тематических структур вычисление вероятности определенных слов по определенной теме (т. Е. Распределение по словам, соответствующим теме) становится невозможным. Чтобы решить эту проблему, LDA использует метод, называемый выборкой Гиббса (Porteous et al. , 2008), при котором каждое слово в документе случайным образом присваивается одной из тем, что обеспечивает начальное предположение о соотношении слово-тема и слово-документ. распределение. LDA предполагает, что все назначения тем, кроме текущего рассматриваемого слова, верны, и затем обновляет назначение текущего слова. Этот процесс повторяется для улучшения задания, пока не будет достигнуто устойчивое состояние. Как только окончательное задание определено, оно используется для оценки сочетания тем каждого документа.
, 2008), при котором каждое слово в документе случайным образом присваивается одной из тем, что обеспечивает начальное предположение о соотношении слово-тема и слово-документ. распределение. LDA предполагает, что все назначения тем, кроме текущего рассматриваемого слова, верны, и затем обновляет назначение текущего слова. Этот процесс повторяется для улучшения задания, пока не будет достигнуто устойчивое состояние. Как только окончательное задание определено, оно используется для оценки сочетания тем каждого документа.
Оценка моделей и расширенный интеллект
В то время как тематические модели могут использоваться для извлечения осмысленных и интерпретируемых тематических заданий, оценка окончательного задания с использованием неконтролируемого подхода является сложной задачей (Chang et al., 2009). Неконтролируемые задачи обучения не включают предварительно помеченные цели. Вместо этого требуется человеческое суждение для оценки практичности и полезности эффективности тематического моделирования (Конрад, 2017). Например, практичность тематической модели может быть оценена с использованием подхода дополненного интеллекта «человек в цикле», когда людей просят найти случайно замененное слово или тему (Chang et al., 2009).). Если человек может достоверно сказать, кто из них является случайным злоумышленником, то мы можем сказать, что обученная тема дает связную и различимую тему (Chang et al., 2009). Кроме того, для оценки модели также следует учитывать внутренние показатели (т. е. статистические показатели). Такие меры помогают оценить, насколько хорошо модель соответствует наблюдаемым данным.
Например, практичность тематической модели может быть оценена с использованием подхода дополненного интеллекта «человек в цикле», когда людей просят найти случайно замененное слово или тему (Chang et al., 2009).). Если человек может достоверно сказать, кто из них является случайным злоумышленником, то мы можем сказать, что обученная тема дает связную и различимую тему (Chang et al., 2009). Кроме того, для оценки модели также следует учитывать внутренние показатели (т. е. статистические показатели). Такие меры помогают оценить, насколько хорошо модель соответствует наблюдаемым данным.
Логарифмическое правдоподобие оценивает вероятность наблюдаемых данных с учетом модели (Griffiths and Steyvers, 2004). Таким образом, мы можем найти наилучшую модель, пытаясь получить меру наивысшего логарифмического правдоподобия. Мера расхождения Кульбака-Лейблера (KL) фокусируется на измерении расхождения между тематическими распределениями. Дивергенция KL явно фокусируется на оценке того, сколько информации мы теряем при выборе определенной модели, путем вычисления симметричной дивергенции KL между распределением дисперсии в распределении тематических слов и распределением маргинальных тем (Cao et al. , 2008; Arun et al. др., 2010). Таким образом, наилучшую модель можно определить, найдя точку, в которой мера расхождения KL достигает наименьшего значения (Arun et al., 2010).
, 2008; Arun et al. др., 2010). Таким образом, наилучшую модель можно определить, найдя точку, в которой мера расхождения KL достигает наименьшего значения (Arun et al., 2010).
Предыдущее исследование было проведено, чтобы продемонстрировать полезность LDA для различных типов заданий по тематическому моделированию. В образовании, например, LDA использовался для выявления тем для целей оценки эссе (Meisner, 2018), внедрения систем рекомендаций по курсам (Apaza et al., 2014) и оценки учителей (Moretti et al., 2015). Однако, насколько нам известно, LDA никогда не использовался для выявления ошибок и неверных представлений учащихся с целью создания отвлекающих факторов, которые можно было бы использовать для создания заданий с множественным выбором. Поэтому целью исследования является описание метода создания дистрактора путем выявления неверных представлений учащихся с использованием подхода тематического моделирования LDA. В отличие от традиционного подхода, при котором специалисты по содержанию отвечали за использование своих суждений для анализа и оценки ответов учащихся, чтобы выявить правдоподобные неправильные представления о развитии отвлекающих факторов, настоящее исследование предоставило систематический и основанный на данных метод группировки письменных ответов учащихся с аналогичными базовыми элементами. концепции, чтобы найти распространенные ошибки. После группировки эти ответы становятся основой для создания правдоподобных отвлекающих факторов.
концепции, чтобы найти распространенные ошибки. После группировки эти ответы становятся основой для создания правдоподобных отвлекающих факторов.
Данные
В исследовании 1 использовался набор данных из открытых источников, собранный и опубликованный в ходе конкурса по подсчету кратких ответов под названием Automated Student Assessment Prize (ASAP). Поскольку набор данных общедоступен, в исследовании не запрашивалось этическое одобрение. ASAP был проведен в 2012 году. Конкурс был разработан для продвижения возможностей эффективной системы оценки с использованием автоматизированных сред оценки эссе и предоставления эффективных инструментов оценки эссе в классе для практиков. Конкурс включал два этапа. На первом этапе основное внимание уделялось разработке надежных автоматизированных систем оценки относительно длинных ответов (до 650 слов). Второй этап был сосредоточен на подсчете коротких ответов (до 50 слов). Оба конкурса внесли значительный вклад в продвижение открытой и строгой модели автоматизированной оценки эссе (Шермис, 2014, 2015).
Для конкурса по подсчету очков было выпущено 10 наборов данных, и каждый набор данных был сгенерирован из одной подсказки. Ответы были подготовлены учащимися 10-го класса. Каждый набор данных был основан на уникальной подсказке в разных дисциплинах, таких как словесность, биология и естествознание. Все ответы были предварительно помечены и оценены двумя людьми-оценщиками. В текущем исследовании использовался шестой набор данных из биологии для демонстрации предлагаемого метода. Эти данные были выбраны для демонстрации предлагаемого метода по трем причинам. Во-первых, текущий метод требует предварительно размеченного набора данных, а шестой набор данных состоит из разрешенной оценки (или окончательной оценки), основанной на соглашении двух оценщиков-людей. Во-вторых, подсказка требовала, чтобы учащиеся отвечали, используя несколько ответов, тем самым создавая множество разнообразных ответов на одну подсказку. Кроме того, исходную подсказку с построенным ответом можно было легко переформатировать в основу с множественным выбором.
В частности, мы использовали 1515 ответов из исходной обучающей выборки, в которой студентов просили перечислить и описать три процесса, используемых клетками для контроля движения веществ через клеточную мембрану (см. Приложение А). Конкретное количество тренировочных ответов было выбрано на основе оценки, присвоенной двумя независимыми оценщиками. Окончательная оценка соответствовала количеству правильно определенных ответов, и мы отобрали только те ответы, в которых учащиеся не смогли назвать ни одного правильного ответа (т. е. оценка 0), поскольку основное внимание в этом исследовании уделяется выявлению распространенных ошибок и неправильных представлений.
Этап разработки отвлекающего фактора 1: подготовка данных
Для получения четких и интерпретируемых кластеров тем требуется предварительная обработка. Во-первых, все слова с ошибками были исправлены. Во-вторых, слова были преобразованы в нижний регистр и лемматизированы с помощью библиотеки Python NLTK (Bird et al. , 2009). Лемматизация — это процесс группировки слов вместе, чтобы их можно было анализировать как единый элемент на основе их словарной формы. Например, слова ‘studies’ и ‘studing’ будут лемматизированы в ‘study’. В-третьих, цифры, небуквенные слова (например, #, %, &, @) и стоп-слова (например, a, и, но, как) были удалены, а все знаки препинания указаны в виде отдельного слова. В-четвертых, ответы были разделены на предложения, что позволило обозначить каждое предложение как отдельную тему.
, 2009). Лемматизация — это процесс группировки слов вместе, чтобы их можно было анализировать как единый элемент на основе их словарной формы. Например, слова ‘studies’ и ‘studing’ будут лемматизированы в ‘study’. В-третьих, цифры, небуквенные слова (например, #, %, &, @) и стоп-слова (например, a, и, но, как) были удалены, а все знаки препинания указаны в виде отдельного слова. В-четвертых, ответы были разделены на предложения, что позволило обозначить каждое предложение как отдельную тему.
Предварительная обработка также направлена на исправление орфографии с использованием комбинации нескольких подходов. Мы использовали модель, основанную на встраивании слов, для исправления правописания. Модели на основе встраивания слов используют семантическое сходство слов для определения лучшего кандидата на слово с ошибкой (Nagata et al., 2017, см. Приложение C). Мы использовали список слов, представленный в предварительно обученном встраивании GloVe (Pennington et al., 2014), который был обучен на шести миллиардах слов из Wikipedia 2014 и Gigaword 5. Мы попытались найти лучшего кандидата неправильного слова из списка. Список слов для встраивания перчаток на основе оценки косинусного сходства. Используя исправление орфографии на основе встраивания, мы смогли успешно исправить более 95% слов с ошибками, в то время как некоторые из оставшихся слов с ошибками, которые не удалось исправить с помощью методов, были исправлены вручную. Этот подход был выбран после того, как были опробованы существующие средства проверки орфографии в Python, и результаты исправления оказались относительно ниже ожидаемых (например, расстояние редактирования NLTK с исправлением 78 %). Такие случаи часто включали слова, которые были значительно искажены, что обеспечивало очень ограниченное сходство с правильной формой.
Мы попытались найти лучшего кандидата неправильного слова из списка. Список слов для встраивания перчаток на основе оценки косинусного сходства. Используя исправление орфографии на основе встраивания, мы смогли успешно исправить более 95% слов с ошибками, в то время как некоторые из оставшихся слов с ошибками, которые не удалось исправить с помощью методов, были исправлены вручную. Этот подход был выбран после того, как были опробованы существующие средства проверки орфографии в Python, и результаты исправления оказались относительно ниже ожидаемых (например, расстояние редактирования NLTK с исправлением 78 %). Такие случаи часто включали слова, которые были значительно искажены, что обеспечивало очень ограниченное сходство с правильной формой.
Этап разработки отвлекающих факторов 2: тематическая кластеризация и оценка кластера
Модель LDA была построена с использованием библиотеки Python lda 1.0.5. Чтобы создать четкие и интерпретируемые кластеры тем, обучение и оценка моделей проводились одновременно. Чтобы обеспечить гибкое и надежное обучение, необходимо определить диапазоны нескольких параметров модели, чтобы можно было определить модель с оптимальным диапазоном. Например, перед началом обучения необходимо указать количество тематических групп. Количество итераций выборки Гиббса также должно быть указано для обучения модели. Для начала количество тем и итераций выборки варьировалось от 1 до 50 и до 800 итераций соответственно. Эти диапазоны были выбраны таким образом, чтобы мы могли извлечь как можно больше потенциальных неправильных представлений со стабильной оценкой. Мы установили наш первоначальный диапазон количества тем как относительно большое число, 50, чтобы модель могла провести всестороннюю категоризацию распространенных ошибок и неправильных представлений. Что касается количества итераций, мы оценили отрицательную логарифмическую вероятность модели на каждых 10 итерациях и проверили, произошло ли значительное уменьшение или увеличение логарифмической вероятности. Значимость оценивали на основе выбранного значения допуска 0,5.
Чтобы обеспечить гибкое и надежное обучение, необходимо определить диапазоны нескольких параметров модели, чтобы можно было определить модель с оптимальным диапазоном. Например, перед началом обучения необходимо указать количество тематических групп. Количество итераций выборки Гиббса также должно быть указано для обучения модели. Для начала количество тем и итераций выборки варьировалось от 1 до 50 и до 800 итераций соответственно. Эти диапазоны были выбраны таким образом, чтобы мы могли извлечь как можно больше потенциальных неправильных представлений со стабильной оценкой. Мы установили наш первоначальный диапазон количества тем как относительно большое число, 50, чтобы модель могла провести всестороннюю категоризацию распространенных ошибок и неправильных представлений. Что касается количества итераций, мы оценили отрицательную логарифмическую вероятность модели на каждых 10 итерациях и проверили, произошло ли значительное уменьшение или увеличение логарифмической вероятности. Значимость оценивали на основе выбранного значения допуска 0,5. Результаты показали, что логарифмическая вероятность стабилизировалась примерно после 800 итераций. Производительность нашей исходной модели оценивалась с использованием меры недоумения. Недоумение — это обычно используемая мера тематической модели, которая вычисляется путем деления отрицательного логарифмического правдоподобия на количество слов (см. Приложение C). Как следует из названия, растерянность обеспечивает степень «неопределенности» или «путаницы», которую модель имеет при назначении вероятностей тексту. Таким образом, мы могли бы определить оптимальное количество тем, найдя модель с наименьшей сложностью.
Результаты показали, что логарифмическая вероятность стабилизировалась примерно после 800 итераций. Производительность нашей исходной модели оценивалась с использованием меры недоумения. Недоумение — это обычно используемая мера тематической модели, которая вычисляется путем деления отрицательного логарифмического правдоподобия на количество слов (см. Приложение C). Как следует из названия, растерянность обеспечивает степень «неопределенности» или «путаницы», которую модель имеет при назначении вероятностей тексту. Таким образом, мы могли бы определить оптимальное количество тем, найдя модель с наименьшей сложностью.
Затем тематические кластеры были визуализированы для оценки кластеризации. Тематические кластеры были спроектированы в двумерном пространстве путем вычисления расстояния между темами с использованием t-распределенного стохастического встраивания соседей (t-SNE). T-SNE — это алгоритм уменьшения размерности для визуализации многомерных данных. Идея t-SNE состоит в том, чтобы найти распределение вероятности, которое является функцией наименьшего числа координат, и создать аналогичную функцию распределения для уменьшения размерности. Предположим, что мы хотим вычислить вероятность нахождения двух точек i и j на квадрате евклидова расстояния между точками || x i − x j || 2 . T-SNE пытается сопоставить распределение, используя распределение Стьюдента- t , пытаясь узнать координаты y точек (т. . Если визуализированные кластеры значительно перекрываются и искажены, то количество тем следует скорректировать. Кроме того, расхождение KL использовалось в качестве критерия оценки для визуализации, поскольку оно помогает определить сходство двух распределений. Алгоритм обучения пытается создать четкую визуализацию отличительных тематических кластеров, минимизируя расхождение KL, чтобы найти оптимальную модель. Для этого потребовалось несколько корректировок, чтобы определить количество итераций, скорость обучения и скорость недоумения. В то время как количество итераций и скорость обучения определяют эффективность и точность обучения модели за счет контроля корректировки веса, скорость недоумения контролирует эффективное количество соседей кластера.
Предположим, что мы хотим вычислить вероятность нахождения двух точек i и j на квадрате евклидова расстояния между точками || x i − x j || 2 . T-SNE пытается сопоставить распределение, используя распределение Стьюдента- t , пытаясь узнать координаты y точек (т. . Если визуализированные кластеры значительно перекрываются и искажены, то количество тем следует скорректировать. Кроме того, расхождение KL использовалось в качестве критерия оценки для визуализации, поскольку оно помогает определить сходство двух распределений. Алгоритм обучения пытается создать четкую визуализацию отличительных тематических кластеров, минимизируя расхождение KL, чтобы найти оптимальную модель. Для этого потребовалось несколько корректировок, чтобы определить количество итераций, скорость обучения и скорость недоумения. В то время как количество итераций и скорость обучения определяют эффективность и точность обучения модели за счет контроля корректировки веса, скорость недоумения контролирует эффективное количество соседей кластера. Наконец, интерпретируемость кластеров оценивалась путем суммирования сгруппированных предложений с использованием обобщения генизма библиотеки Python. Обобщение Gensim выполняет обобщение на основе текстового ранга с использованием варианта алгоритма TextRank (Барриос и др., 2016). TextRank пытается построить граф из документа, где предложения (или узлы) связаны друг с другом ребрами. Края представляют сходство между предложениями, которое часто вычисляется на основе совпадения слов между двумя предложениями. TextRank предполагает, что самое важное предложение в тексте является наиболее часто связанным в графе. Мы выбрали этот подход, так как предыдущие исследования продемонстрировали относительно хорошую производительность с использованием этого метода, хотя он не требует ручной аннотации (Mihalcea and Tarau, 2004). Резюме были созданы для того, чтобы специалисты по контенту могли эффективно оценить правдоподобность извлеченных распространенных ошибок и заблуждений.
Наконец, интерпретируемость кластеров оценивалась путем суммирования сгруппированных предложений с использованием обобщения генизма библиотеки Python. Обобщение Gensim выполняет обобщение на основе текстового ранга с использованием варианта алгоритма TextRank (Барриос и др., 2016). TextRank пытается построить граф из документа, где предложения (или узлы) связаны друг с другом ребрами. Края представляют сходство между предложениями, которое часто вычисляется на основе совпадения слов между двумя предложениями. TextRank предполагает, что самое важное предложение в тексте является наиболее часто связанным в графе. Мы выбрали этот подход, так как предыдущие исследования продемонстрировали относительно хорошую производительность с использованием этого метода, хотя он не требует ручной аннотации (Mihalcea and Tarau, 2004). Резюме были созданы для того, чтобы специалисты по контенту могли эффективно оценить правдоподобность извлеченных распространенных ошибок и заблуждений.
В исследовании мы называем специалистов по контенту экспертов, имеющих опыт написания заданий по конкретным предметам. При таком виде экспертизы контента проверка правдоподобия обобщенных распространенных ошибок и неправильных представлений может улучшить качество отвлекающих факторов, генерируемых по каждому тематическому кластеру. Для этого специалисты по контенту могли бы обсудить и попытаться определить, откуда возникло каждое заблуждение. Например, если содержание кластера включает морфологически или фонетически сходные слова с правильными ответами, специалисты могут сделать вывод, что неправильное представление возникло из-за путаницы при воспоминании определенных терминов или ассоциации термина с правильным определением. Кроме того, можно предложить специалистам по контенту отвечать на более конкретные вопросы для оценки качества кластеров. Такие вопросы могут включать: «Сколько кластеров вы считаете значимыми?» и «Описывает ли кластер общеизвестное заблуждение по теме?» Это помогло бы специалистам по контенту тщательно оценить отвлекающие факторы, а также предоставить важную информацию для оценки возможностей текущей системы.
При таком виде экспертизы контента проверка правдоподобия обобщенных распространенных ошибок и неправильных представлений может улучшить качество отвлекающих факторов, генерируемых по каждому тематическому кластеру. Для этого специалисты по контенту могли бы обсудить и попытаться определить, откуда возникло каждое заблуждение. Например, если содержание кластера включает морфологически или фонетически сходные слова с правильными ответами, специалисты могут сделать вывод, что неправильное представление возникло из-за путаницы при воспоминании определенных терминов или ассоциации термина с правильным определением. Кроме того, можно предложить специалистам по контенту отвечать на более конкретные вопросы для оценки качества кластеров. Такие вопросы могут включать: «Сколько кластеров вы считаете значимыми?» и «Описывает ли кластер общеизвестное заблуждение по теме?» Это помогло бы специалистам по контенту тщательно оценить отвлекающие факторы, а также предоставить важную информацию для оценки возможностей текущей системы.
Этап разработки отвлекающих факторов 3: Формирование элементов и отвлекающих факторов
На третьем этапе специалисты по содержанию формулируют отвлекающие факторы, используя распространенные ошибки и кластеры заблуждений, выявленные на предыдущем этапе. Мы предлагаем несколько методов, которые могли бы способствовать более систематическому развитию дистракторов с использованием неправильных представлений учащихся. Процесс генерации отвлекающих факторов можно отличить на основе типа вопроса (или основы), который специалисты по контенту задают по теме. Во-первых, специалисты по контенту могут принять решение об изменении формата исходного вопроса с элемента с построенным ответом на формат элемента с множественным выбором, пытаясь измерить тот же интересующий конструкт (например, какая из следующих процедур верна в отношении перемещения ячеек). ?). В этом случае мы могли бы напрямую использовать обобщения кластеров, а также ключевые слова и фразы. На этапе 2 мы исследовали, как каждый кластер заблуждений может быть представлен с помощью ключевых слов и обобщения. Таким образом, использование ключевых слов или кратких предложений в качестве отвлекающих факторов может эффективно привлечь учащихся с разным уровнем понимания. В качестве альтернативы специалисты по контенту могут разработать вопрос, посвященный конкретным подконцепциям темы. Активный или пассивный транспорт могут быть хорошими примерами подконцепций для оценки, которые тесно связаны с исходным вопросом. В этом случае отвлекающие факторы могли быть непосредственно обнаружены на основе ответов учащихся из кластера, где у учащихся возникли проблемы с пониманием концепций активного и пассивного транспорта. Мы представим, как эти два метода можно использовать более подробно, используя примеры в следующем разделе.
Таким образом, использование ключевых слов или кратких предложений в качестве отвлекающих факторов может эффективно привлечь учащихся с разным уровнем понимания. В качестве альтернативы специалисты по контенту могут разработать вопрос, посвященный конкретным подконцепциям темы. Активный или пассивный транспорт могут быть хорошими примерами подконцепций для оценки, которые тесно связаны с исходным вопросом. В этом случае отвлекающие факторы могли быть непосредственно обнаружены на основе ответов учащихся из кластера, где у учащихся возникли проблемы с пониманием концепций активного и пассивного транспорта. Мы представим, как эти два метода можно использовать более подробно, используя примеры в следующем разделе.
Создание отвлекающих факторов с использованием неправильных представлений учащихся было определено как один из наиболее эффективных способов разработки заданий с множественным выбором (Haladyna and Rodriguez, 2013). Однако с нашим подходом к расширенному интеллекту, который требует суждений специалистов по контенту в процессе эволюции, мы считаем, что эффективность отвлекающих факторов все еще может в значительной степени зависеть от суждений специалистов по контенту. Поэтому, хотя мы поощряем дальнейшие исследования эффективности отвлекающих факторов, созданных с помощью предложенных методов, в наши задачи не входило предоставление эмпирических результатов о поведении отвлекающих факторов в реальных условиях тестирования. Мы обсудим такие проблемы более подробно в разделе ограничений с несколькими предложениями для будущих исследований.
Поэтому, хотя мы поощряем дальнейшие исследования эффективности отвлекающих факторов, созданных с помощью предложенных методов, в наши задачи не входило предоставление эмпирических результатов о поведении отвлекающих факторов в реальных условиях тестирования. Мы обсудим такие проблемы более подробно в разделе ограничений с несколькими предложениями для будущих исследований.
Тематическая кластеризация и результаты кластерной оценки
В исходном задании с построенным ответом учащихся просили дать три правильных ответа на следующий вопрос: «Перечислите и опишите три процесса, используемых клетками для контроля движения веществ через клеточную мембрану». ». Результаты показали, что оптимальная модель LDA выявила 22 распространенных заблуждения. Количество тематических кластеров было выбрано на основе логарифмической меры правдоподобия, а также расхождения KL. Модель достигла недоумения 34,76 после 800 итераций и наименьшего расхождения KL 40,50 с 22 темами. Как обсуждалось ранее, логарифмическая мера правдоподобия обеспечивает вероятность наблюдаемых данных с учетом модели (Griffiths and Steyvers, 2004).
Кроме того, интерпретируемость и достоверность каждого тематического блока оценивались с использованием извлеченных ключевых слов и резюме. Полный список ключевых слов темы и резюме можно найти в Приложении B. Для каждой тематической группы использовалось от шести до восьми ключевых слов темы. Они были выбраны на основе силы ассоциации для представления тематического кластера, и сила измерялась весами, присвоенными каждому слову. Кроме того, для каждого кластера были созданы сводки, чтобы повысить их интерпретируемость. Эта информация была разработана, чтобы помочь специалистам по содержанию интерпретировать распространенные ошибки и заблуждения учащихся и оценить репрезентативность кластеров для формирования правдоподобных отвлекающих факторов. Например, тема 20 включала несколько ключевых слов, таких как «мРНК», «РНК», «тРНК», «ДНК», «информация», «перевод», «транскрипция» и «сообщения». впечатление на каждое заблуждение, основанное на этих ключевых словах. Кроме того, прочитав сводку, в которой говорится, что «мРНК переносит сообщения от ядра к другим органам, тРНК переносит ДНК в места с рРНК в клетке», специалисты по контенту могут лучше понять конкретные контексты и ассоциации между ключевыми словами, чтобы они могли сделать больше. обоснованное решение о том, можно ли использовать кластер для создания правдоподобного отвлекающего фактора, который представляет собой распространенную ошибку или неправильное представление.
обоснованное решение о том, можно ли использовать кластер для создания правдоподобного отвлекающего фактора, который представляет собой распространенную ошибку или неправильное представление.
Результаты формирования заданий и дистракторов
Набор дистракторов был создан с использованием оцененных кластеров распространенных ошибок и заблуждений учащихся. В дополнение к созданию дистракторов для первоначально предложенного задания, где учащиеся должны были описать три процесса, используемых клетками для управления перемещением веществ через клеточную мембрану, мы исследовали возможности текущего метода в создании дистракторов для дополнительных предметов, специфичных для кластера. . В следующих примерах представлена пошаговая разбивка процедур создания дистракторов.
Пример 1. Создание отвлекающих факторов для исходной подсказки
Как показано на рисунке, элемент с множественным выбором был создан из исходного элемента с построенным ответом. Отражая исходную подсказку, основа была изменена на «Какие три процесса используются клетками для контроля движения вещества через клеточную мембрану?» Чтобы создать отвлекающие факторы, каждый из которых может отражать различные распространенные ошибки и заблуждения, был создан список вариантов путем поиска ответов учащихся по ключевым словам из основы, таким как «процессы», «движение» или «вещества» из каждого тематического кластера заблуждений. . Точнее, вариант 9.0018 г представляет кластер 13 (см. Приложение Б), где учащиеся описывают движение жгутика как часть движения вещества через клеточную мембрану. В этом примере правильный ответ — i, в то время как другие варианты были созданы для представления неправильных представлений учащихся.
. Точнее, вариант 9.0018 г представляет кластер 13 (см. Приложение Б), где учащиеся описывают движение жгутика как часть движения вещества через клеточную мембрану. В этом примере правильный ответ — i, в то время как другие варианты были созданы для представления неправильных представлений учащихся.
Открыть в отдельном окне
Пример вопроса и отвлекающих факторов, сгенерированных для оригинальной подсказки.
Пример 2. Создание отвлекающих факторов с использованием дополнительных подсказок
Как показано на рисунке , предлагаемый метод можно расширить для создания отвлекающих факторов для конкретных элементов кластера. Элементы, специфичные для кластера, относятся к элементам, которые создаются для дальнейшей оценки понимания учащихся и отражают неправильные представления, зафиксированные в конкретном кластере контента. Например, вводит два предмета, относящихся к кластеру, которые были заданы на основе ответов учащихся в кластере 2 (см. Приложение B). В кластере 2 учащимся было трудно правильно объяснить и провести различие между двумя концепциями активного и пассивного транспорта. Поэтому, чтобы оценить понимание учащимися активного и пассивного транспорта, были созданы две дополнительные основы с множественным выбором: «Что из следующего верно в отношении активного транспорта?» и «Что из следующего верно о пассивном транспорте?» Чтобы создать отвлекающие факторы для элементов, относящихся к кластеру, мы внедрили тот же процесс, в котором ключевые слова и фразы (например, активный перенос, пассивный перенос) использовались для поиска ответов учащихся, которые включали эти ключевые термины. В отличие от первого примера, отвлекающие факторы находились только среди ответов кластера 2, так как задания были созданы на основе кластера 2. Правильный вариант — 9.0018 a и b соответственно.
В кластере 2 учащимся было трудно правильно объяснить и провести различие между двумя концепциями активного и пассивного транспорта. Поэтому, чтобы оценить понимание учащимися активного и пассивного транспорта, были созданы две дополнительные основы с множественным выбором: «Что из следующего верно в отношении активного транспорта?» и «Что из следующего верно о пассивном транспорте?» Чтобы создать отвлекающие факторы для элементов, относящихся к кластеру, мы внедрили тот же процесс, в котором ключевые слова и фразы (например, активный перенос, пассивный перенос) использовались для поиска ответов учащихся, которые включали эти ключевые термины. В отличие от первого примера, отвлекающие факторы находились только среди ответов кластера 2, так как задания были созданы на основе кластера 2. Правильный вариант — 9.0018 a и b соответственно.
Открыть в отдельном окне
Примеры вопросов и отвлекающих факторов, сгенерированных для подтем оригинальной подсказки.
Недавнее внедрение различных приложений расширенного интеллекта в систему оценивания образования привело к кардинальным изменениям в этой области, способствуя внедрению новых эффективных процедур разработки и администрирования тестов (Popenici and Kerr, 2017). Дополненный интеллект, который является ответвлением искусственного интеллекта, помогает экспертам по контенту расширять свои возможности и своевременно принимать более обоснованные решения при соответствующей технологической поддержке. Например, с помощью автоматизированной системы подсчета баллов эксперты могут более эффективно оценивать эссе, поскольку с помощью машины можно отличить проблемные эссе, которые не соответствуют оценочной рубрике, от более последовательных эссе. В настоящее время было проведено мало исследований для изучения применения дополненного интеллекта в разработке предметов, особенно в том, что касается создания отвлекающих факторов. Эффективные отвлекающие факторы могут привлекать учащихся с частичным пониманием, другими словами, различать учащихся, которые еще не достигли уровня мастерства понимания концепции. Таким образом, создание эффективных отвлекающих факторов напрямую связано с повышением качества предмета и его характеристик (т. е. сложности предмета и различения; ДиБаттиста и Курзава, 2011).
Дополненный интеллект, который является ответвлением искусственного интеллекта, помогает экспертам по контенту расширять свои возможности и своевременно принимать более обоснованные решения при соответствующей технологической поддержке. Например, с помощью автоматизированной системы подсчета баллов эксперты могут более эффективно оценивать эссе, поскольку с помощью машины можно отличить проблемные эссе, которые не соответствуют оценочной рубрике, от более последовательных эссе. В настоящее время было проведено мало исследований для изучения применения дополненного интеллекта в разработке предметов, особенно в том, что касается создания отвлекающих факторов. Эффективные отвлекающие факторы могут привлекать учащихся с частичным пониманием, другими словами, различать учащихся, которые еще не достигли уровня мастерства понимания концепции. Таким образом, создание эффективных отвлекающих факторов напрямую связано с повышением качества предмета и его характеристик (т. е. сложности предмета и различения; ДиБаттиста и Курзава, 2011). Были проведены исследования, чтобы изучить значение использования неправильных представлений учащихся и распространенных ошибок для создания отвлекающих факторов (например, Vacc et al., 2001; Moreno et al., 2015; Rodriguez, 2016). Неправильные представления обычно собираются с помощью письменных или устных ответов учащихся на похожие или связанные темы, а эксперты по контенту вручную классифицируют и выявляют правдоподобные заблуждения, используя письменные доказательства ответов (Bekkink et al., 2016). В других случаях эксперты по содержанию пытаются имитировать мыслительные процессы учащихся, чтобы выявить возможные ошибки (Haladyna and Rodriguez, 2013). Однако эти подходы неосуществимы, когда необходимо создать большое количество элементов. Чтобы преодолеть это ограничение, мы представили и проиллюстрировали основанный на данных метод создания отвлекающих факторов на основе неверных представлений из письменных ответов учащихся с использованием рабочего процесса, представленного в .
Были проведены исследования, чтобы изучить значение использования неправильных представлений учащихся и распространенных ошибок для создания отвлекающих факторов (например, Vacc et al., 2001; Moreno et al., 2015; Rodriguez, 2016). Неправильные представления обычно собираются с помощью письменных или устных ответов учащихся на похожие или связанные темы, а эксперты по контенту вручную классифицируют и выявляют правдоподобные заблуждения, используя письменные доказательства ответов (Bekkink et al., 2016). В других случаях эксперты по содержанию пытаются имитировать мыслительные процессы учащихся, чтобы выявить возможные ошибки (Haladyna and Rodriguez, 2013). Однако эти подходы неосуществимы, когда необходимо создать большое количество элементов. Чтобы преодолеть это ограничение, мы представили и проиллюстрировали основанный на данных метод создания отвлекающих факторов на основе неверных представлений из письменных ответов учащихся с использованием рабочего процесса, представленного в .
Открыть в отдельном окне
Комплексная схема процесса генерации дистракторов.
Важно признать, что современные методы пытаются гармонично объединить подходы, управляемые машиной или данными, и экспертами на каждом этапе. Хотя подход, основанный на данных, обеспечивает заметные преимущества в облегчении систематического и эффективного процесса создания отвлекающих факторов, мы считаем, что вмешательство экспертов может помочь улучшить систему, выступая в качестве привратника для обеспечения качества конечного продукта, отвлекающих факторов. Решения экспертов по контенту, особенно в образовательных оценках, часто считаются эталоном или золотым стандартом при принятии окончательных решений с высокими ставками. Этапы рабочего процесса были использованы для выявления 22 различных кластеров распространенных ошибок и неправильных представлений с использованием письменных ответов учащихся на задание с построенным ответом по биологии. На первом этапе обработки данных мы в основном использовали подход, основанный на данных, для предварительной обработки ответов (например, лемматизация, токенизация, удаление знаков препинания и неалфавитных слов).![]() Кроме того, несмотря на то, что мы исправили большинство слов с ошибками, используя подход, основанный на встраивании, по-прежнему требовалось провести несколько исправлений вручную. На этапе анализа ответов кластеры были созданы автоматически с использованием подхода тематического моделирования, затем экспертам по контенту требовалось оценить интерпретируемость и правдоподобие извлеченных кластеров. Информация использовалась для создания списка из 22 вероятных отвлекающих факторов, которые, в свою очередь, , помогли создать параллельный элемент с множественным выбором. Параллельный элемент с множественным выбором относится к элементу, первоначально представленному как задание с построенным ответом, которое было переформатировано в задание с выборочным ответом. Качество сгенерированных отвлекающих факторов может быть дополнительно оценено эмпирически путем экспериментального тестирования в классе, и мы обсудим более подробную информацию об оценке характеристик предметов в следующем разделе.
Кроме того, несмотря на то, что мы исправили большинство слов с ошибками, используя подход, основанный на встраивании, по-прежнему требовалось провести несколько исправлений вручную. На этапе анализа ответов кластеры были созданы автоматически с использованием подхода тематического моделирования, затем экспертам по контенту требовалось оценить интерпретируемость и правдоподобие извлеченных кластеров. Информация использовалась для создания списка из 22 вероятных отвлекающих факторов, которые, в свою очередь, , помогли создать параллельный элемент с множественным выбором. Параллельный элемент с множественным выбором относится к элементу, первоначально представленному как задание с построенным ответом, которое было переформатировано в задание с выборочным ответом. Качество сгенерированных отвлекающих факторов может быть дополнительно оценено эмпирически путем экспериментального тестирования в классе, и мы обсудим более подробную информацию об оценке характеристик предметов в следующем разделе.
Последствия для будущих исследований
Текущее исследование имеет последствия для методов письма с использованием дистракторов, в частности, и разработки заданий в целом. Тематическое моделирование позволяет экспертам по контенту использовать ответы учащихся более адаптивным и продуктивным образом. Письменные ответы представляют собой огромный источник ценной информации о понимании учащимися, которое связано не только с интересующим конструктом, но и с неправильными представлениями об этом конструкте. На сегодняшний день было затрачено мало усилий на изучение использования методов машинного обучения для сбора и использования информации о неправильных представлениях, которые могут быть обнаружены в ответах, построенных учащимися. Используя метод, описанный и проиллюстрированный в этом исследовании, исследователи и практики теперь могут использовать письменные ответы, собранные в заданиях и тестах, для планирования будущих уроков и создания более адаптированных к учащимся учебных мероприятий и оценок. Этот метод также можно использовать для предоставления доказательств уровня развития учащихся в понимании определенных концепций. Например, анализируя ответы группы с более высокими способностями и сравнивая кластеры неправильных представлений с кластерами из группы с более низкими способностями, можно собрать более подробную информацию, чтобы создать полную картину того, как развивается уровень понимания учащихся. конкретных концепций и в рамках конкретных содержательных областей.
Этот метод также можно использовать для предоставления доказательств уровня развития учащихся в понимании определенных концепций. Например, анализируя ответы группы с более высокими способностями и сравнивая кластеры неправильных представлений с кластерами из группы с более низкими способностями, можно собрать более подробную информацию, чтобы создать полную картину того, как развивается уровень понимания учащихся. конкретных концепций и в рамках конкретных содержательных областей.
Разработка отвлекающих элементов и генерация элементов
Потенциально наиболее важным будущим применением этого метода является его применение для автоматического создания элементов (AIG; Irvine and Kyllonen, 2002; Gierl and Haladyna, 2013). AIG — это относительно новая, но быстро развивающаяся область исследований, в которой методы когнитивного и психометрического моделирования определяют производство тестов, включающих элементы, созданные с помощью компьютерных технологий. Гирл и Лай (2013, 2016) разработали трехэтапный процесс для AIG. На первом этапе специалисты по контенту создают когнитивную модель для AIG.
На первом этапе специалисты по контенту создают когнитивную модель для AIG.
В настоящее время разработка дистракторов представляет собой уникальную и важную проблему в AIG на этапе моделирования элемента 2. Для формата выбранного ответа элементы должны включать не только основу с соответствующим правильным вариантом ответа, но и набор отвлекающих факторов. Отвлекающие элементы в AIG обычно создаются из списка правдоподобных, но неверных альтернатив, связанных с неправильными представлениями, выявленными специалистами по контенту. Поскольку AIG производит сотни предметов, необходимы стратегии для создания соответственно большого количества правдоподобных, но ошибочных отвлекающих факторов. При разработке дистракторов для AIG теперь используется метод пула дистракторов со случайным выбором (Gierl and Lai, 2016). Чтобы определить контент для отвлекающих факторов, специалисты по контенту определяют список правдоподобных, но неправильных вариантов, которые подходят для всех возможных элементов, созданных с помощью данной модели элементов. Затем из этого пула правдоподобного, но ошибочного контента случайным образом выбираются отвлекающие факторы и добавляются к каждому сгенерированному элементу. Этот метод основан на предположении, что можно создать пул вероятных отвлекающих факторов. Выборка этих вероятных отвлекающих факторов выбирается случайным образом для завершения процесса создания элемента. Сила этого метода в его простоте. Этот метод может дать большое количество отвлекающих факторов. Слабость этого метода заключается в сильном предположении, что все объединенные отвлекающие факторы одинаково правдоподобны и подходят для всех сгенерированных элементов. Равное правдоподобие и уместность является сильным и во многих случаях ограничительным предположением. Кроме того, мало аргументов в пользу того, как дистракторы сочетаются с правильным вариантом, потому что объединение достигается случайным назначением.
Затем из этого пула правдоподобного, но ошибочного контента случайным образом выбираются отвлекающие факторы и добавляются к каждому сгенерированному элементу. Этот метод основан на предположении, что можно создать пул вероятных отвлекающих факторов. Выборка этих вероятных отвлекающих факторов выбирается случайным образом для завершения процесса создания элемента. Сила этого метода в его простоте. Этот метод может дать большое количество отвлекающих факторов. Слабость этого метода заключается в сильном предположении, что все объединенные отвлекающие факторы одинаково правдоподобны и подходят для всех сгенерированных элементов. Равное правдоподобие и уместность является сильным и во многих случаях ограничительным предположением. Кроме того, мало аргументов в пользу того, как дистракторы сочетаются с правильным вариантом, потому что объединение достигается случайным назначением.
Чтобы улучшить правдоподобие и уместность отвлекающих факторов, можно использовать правила и обоснования, приводящие к ошибкам или неправильным представлениям, для создания отвлекающих факторов. Обоснования отвлекающих факторов — это краткие описания, в которых указывается аргументация, лежащая в основе каждого варианта. Эти обоснования в настоящее время предоставляются специалистами по контенту. Но правила также могут быть созданы с использованием метода, представленного в нашем исследовании, для создания отвлекающих факторов, которые соответствуют конкретным, эмпирически обоснованным заблуждениям учащихся. Следовательно, отвлекающие факторы можно создавать систематически, чтобы каждый отвлекающий фактор соответствовал обоснованию. Предлагаемый подход можно назвать систематическая генерация с использованием метода обоснования . Он будет основан на предположении, что алгоритмы, правила и процедуры могут быть сначала сформулированы специалистами по содержанию, а затем использованы для создания правдоподобных, но неправильных альтернатив, связанных с фактическими неправильными представлениями учащихся или ошибками в мышлении, рассуждениях и решении проблем. Сила этого метода в том, что дистракторы гораздо более специфичны и, следовательно, правдоподобны и уместны, особенно по сравнению с методом пула дистракторов со случайным распределением.
Обоснования отвлекающих факторов — это краткие описания, в которых указывается аргументация, лежащая в основе каждого варианта. Эти обоснования в настоящее время предоставляются специалистами по контенту. Но правила также могут быть созданы с использованием метода, представленного в нашем исследовании, для создания отвлекающих факторов, которые соответствуют конкретным, эмпирически обоснованным заблуждениям учащихся. Следовательно, отвлекающие факторы можно создавать систематически, чтобы каждый отвлекающий фактор соответствовал обоснованию. Предлагаемый подход можно назвать систематическая генерация с использованием метода обоснования . Он будет основан на предположении, что алгоритмы, правила и процедуры могут быть сначала сформулированы специалистами по содержанию, а затем использованы для создания правдоподобных, но неправильных альтернатив, связанных с фактическими неправильными представлениями учащихся или ошибками в мышлении, рассуждениях и решении проблем. Сила этого метода в том, что дистракторы гораздо более специфичны и, следовательно, правдоподобны и уместны, особенно по сравнению с методом пула дистракторов со случайным распределением. Следовательно, объединение результатов методов тематического моделирования, представленных в этой статье, с новыми разработками в AIG следует рассматривать как важную область будущих исследований.
Следовательно, объединение результатов методов тематического моделирования, представленных в этой статье, с новыми разработками в AIG следует рассматривать как важную область будущих исследований.
Ограничение и будущие исследования
Несмотря на то, что исследование было тщательно разработано и структурировано, чтобы свести к минимуму потенциальную ошибку с результатами и дальнейшими интерпретациями, мы обнаружили три ключевых ограничения, которые следует рассмотреть и тщательно рассмотреть для будущих исследований: основные цели нашего исследования должны были ввести новый метод систематического выявления неправильных представлений учащихся, чтобы стимулировать эффективное создание отвлекающих факторов для разработки заданий с множественным выбором. Таким образом, наше исследование не могло исследовать поведение предметов со сгенерированными дистракторами в условиях реального теста. Изучение поведения предметов в зависимости от качества отвлекающих факторов поможет нам лучше понять важность разработки предметов с хорошо работающими отвлекающими факторами. Например, ДиБаттиста и Курзава (2011) продемонстрировали, как правдоподобие отвлекающих факторов значительно влияет на характеристики предметов (например, различение предметов) при оценивании в классе. Поэтому мы призываем будущих исследователей оценить правдоподобие и эффективность сгенерированных отвлекающих факторов, чтобы тщательно изучить значение предлагаемого нами метода. Во-вторых, наш текущий метод требовал помеченных ответов, чтобы идентифицировать ответы учащихся с неправильными ответами. Оценка ответов учащихся вручную может быть очень дорогой и утомительной процедурой, особенно при крупномасштабном оценивании. Однако, поскольку текущий метод пытается извлечь неправильные представления учащихся, которые могут быть выявлены из их неправильных ответов, необходимо оценить или использовать предварительно размеченный набор данных для правильной реализации предлагаемого метода. Это может несколько ограничить удобство использования предлагаемого метода, поскольку поиск специфичных для предметной области и предварительно помеченных данных может оказаться непростой задачей.
Например, ДиБаттиста и Курзава (2011) продемонстрировали, как правдоподобие отвлекающих факторов значительно влияет на характеристики предметов (например, различение предметов) при оценивании в классе. Поэтому мы призываем будущих исследователей оценить правдоподобие и эффективность сгенерированных отвлекающих факторов, чтобы тщательно изучить значение предлагаемого нами метода. Во-вторых, наш текущий метод требовал помеченных ответов, чтобы идентифицировать ответы учащихся с неправильными ответами. Оценка ответов учащихся вручную может быть очень дорогой и утомительной процедурой, особенно при крупномасштабном оценивании. Однако, поскольку текущий метод пытается извлечь неправильные представления учащихся, которые могут быть выявлены из их неправильных ответов, необходимо оценить или использовать предварительно размеченный набор данных для правильной реализации предлагаемого метода. Это может несколько ограничить удобство использования предлагаемого метода, поскольку поиск специфичных для предметной области и предварительно помеченных данных может оказаться непростой задачей. Тем не менее, мы считаем, что такие ограничения можно легко преодолеть, используя автоматизированные системы оценки эссе (см. Приложение C) для предварительного создания помеченных ответов для реализации текущего метода. Наконец, расширенный интеллектуальный подход нашего метода направлен на создание систематического метода для отвлечения внимания, помогающего экспертам по контенту принимать обоснованные решения с использованием кластеров заблуждений. Поэтому важно выяснить, действительно ли специалисты по контенту чувствуют поддержку в принятии обоснованных решений при создании отвлекающих факторов. Мы рекомендуем будущим исследованиям тщательно оценить аффективные факторы экспертов по контенту при использовании этого метода, чтобы полностью оценить возможности текущего метода.
Тем не менее, мы считаем, что такие ограничения можно легко преодолеть, используя автоматизированные системы оценки эссе (см. Приложение C) для предварительного создания помеченных ответов для реализации текущего метода. Наконец, расширенный интеллектуальный подход нашего метода направлен на создание систематического метода для отвлечения внимания, помогающего экспертам по контенту принимать обоснованные решения с использованием кластеров заблуждений. Поэтому важно выяснить, действительно ли специалисты по контенту чувствуют поддержку в принятии обоснованных решений при создании отвлекающих факторов. Мы рекомендуем будущим исследованиям тщательно оценить аффективные факторы экспертов по контенту при использовании этого метода, чтобы полностью оценить возможности текущего метода.
JS, QG и MG внесли свой вклад в концептуализацию и формализацию исследовательских идей исследования. JS нашел и организовал данные. JS и QG выполнили анализ. JS и MG написали первый черновик рукописи. Все авторы внесли свой вклад в доработку рукописи, прочитали и одобрили представленную версию.
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Подсказка — элемент клеточной мембраны
Перечислите и опишите три процесса, используемых клеткой для контроля перемещения веществ через клеточную мембрану.
Рубрика для клеточной мембраны
Ключевые элементы:
-
простой •
Избирательная проницаемость используется клеточной мембраной, чтобы позволить определенным веществам проходить через нее.
-
простой •
Пассивный транспорт происходит, когда вещества перемещаются из области с более высокой концентрацией в область с более низкой концентрацией.
-
простой •
Осмос — это диффузия воды через клеточную мембрану.
-
простой •
Облегченная диффузия возникает, когда мембрана контролирует путь проникновения частицы в клетку или выхода из нее.

-
простой •
Активный транспорт возникает, когда клетка использует энергию для перемещения вещества через клеточную мембрану и/или вещество перемещается из области с низкой концентрацией в область с высокой концентрацией или против градиента концентрации.
-
простой •
Насосы используются для перемещения заряженных частиц, таких как ионы натрия и калия, через мембраны с использованием энергии и белков-переносчиков.
-
простой •
Мембранный транспорт происходит, когда мембрана пузырька сливается с клеточной мембраной, вытесняя большие молекулы из клетки, как при экзоцитозе.
-
простой •
Мембранный транспорт происходит, когда молекулы поглощаются клеточной мембраной, как при эндоцитозе.
-
простой •
Мембранный транспорт происходит, когда везикулы образуются вокруг крупных молекул, как при фагоцитозе.
-
простой •
Мембранный транспорт происходит, когда везикулы образуются вокруг капель жидкости, как при пиноцитозе.

-
простой •
Белковые каналы или белковые каналы обеспечивают перемещение определенных молекул или веществ в клетку или из нее.
Рубрика:
3 балла
Три ключевых элемента
2 балла
Два ключевых элемента
1 балл
Один ключевой элемент
0 баллов
Другое.
Репрезентативные ключевые слова тематических кластеров
| Тема | Ключевые слова | РЕЗЮМЕ | |
|---|---|---|---|
| 1 | |||
| 1 | 331 | ||
| 1 | 333331, | ||
| 1 | 333333333, obsfors, 9043, | , | |
| 1 | 333333, obsfors. используются клетками для контроля движения веществ через клеточную мембрану, являются селективными или полупроницаемыми, осмосными и диффузионными используются клетками для контроля движения веществ через клеточную мембрану, являются селективными или полупроницаемыми, осмосными и диффузионными | ||
| 2 | Транспорт, активный, диффузионный, пассивный, осмос, процессы, облегченные, тип | Три типа контролируемого перемещения веществ через клеточную мембрану включают пассивный транспорт, активный транспорт и диффузию | |
| 3 | Клетка, вещество, мембрана, путь, движется, цитоплазма, идет, организм | Другой — когда организм вытягивает участки своей клеточной мембраны и заполняет ее цитоплазмой, в то время как противоположный конец уходит и движется ползучим движением | |
| 4 | Клетки, кровь, тело, делают, текут, нуждаются, мозг, посылают помощь, ядро, вещи, снаружи, внутри | Три процесса, используемые клетками для управления движением веществ через клеточную мембрану, — это жгутики, которые помогают клетке пройти через мембрану, ядро, которое является центром управления, и клеточная стенка, чтобы защитить ячейку от любых нежелательных ячеек или чего-либо нежелательного | |
| 6 | Клетка, отходы, пища, получает, вещество, питательные вещества, необходимо, нуждается | Тельца Гольджи помогают избавиться от ненужного в клетке вещества | |
| 7 | Белок, белки, клетка , ферменты, синтез, канал | Клетка использует три основных процесса для движения через мембрану: жгутик, цитоплазма и, наконец, белок в рибонуклеазе.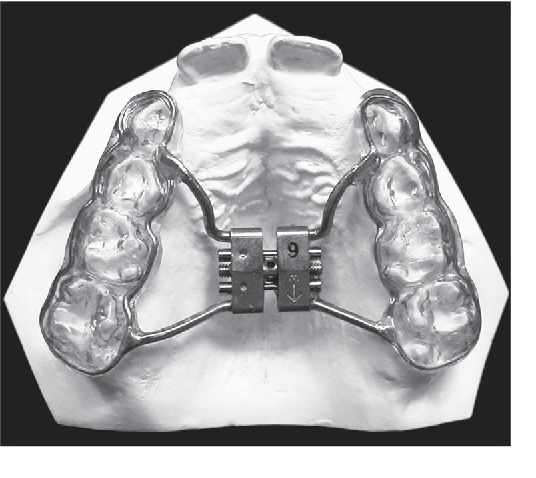 , помогает, плазма, разные , помогает, плазма, разные | Поры в мембране позволяют веществам входить и выходить из клетки, а тельца Гольджи помогают транспортировать вещества в клетку и из клетки |
| 9 | Клетки, использование, белки, путь, мембрана, рибосомы, перенос, белки | Клетки использовать везикулы, транспортные цепи и белки для управления движением веществ через клеточную мембрану | |
| 10 | Клетка, вещество, мембрана, диффузия, концентрация, вещества, движение, использование | от низкой концентрации до высокой концентрации в клеточной мембране | |
| 11 | Гольджи, ядро, белки, аппарат, рибосомы, ретикулум, эндоплазматический, использование | Рибосомы производят энергию для клетки Аппарат Гольджи избавляется от отходов, а ядро содержит всю информацию и ДНК | |
| 12 | Клетка, вещи, стенка, мембрана, внутри, попадание, вещества, позволяет | Клеточная стенка делает растительную клетку жесткой, но также удерживает нежелательные предметы или клеточная мембрана организма позволяет вещам входить и выходить из клетки с разрешения ядро и хлоропласт помогают растениям сохранять энергию | |
| 13 | Подобно, жгутик, жгутик, использование, реснички, клетка, помогает, помощь | Один из способов передвижения — использование жгутика, который представляет собой структуру, напоминающую длинный хвост, который движется позади клетки | |
| 14 | Клетки, вещества, использование, процесс, место, органеллы, движение, помощь | Другие процессы, которые клетки используют для контроля над веществами, проникающими через клеточные мембраны, — это фосфолипиды, выстилающие клеточную стенку, они также помогают удерживать нежелательные вещества. | |
| 15 | Движение, клетки, контроль, используемые, клетка, процессы, вещества, мембрана | Три процесса, которые клетки используют для контроля движения веществ через клеточную мембрану, — это синтез белка, переливание и выведение отходов | |
| 16 | Клетки, митоз, процесс мейоза, размножение, производство, создание, мейоз | Другие процессы, которые клетки используют для контроля над веществами, пересекающими клеточные мембраны, — это фосфолипиды, выстилающие клеточную стенку, они помогают удерживать нежелательные вещества также | |
| 17 | Клетка, контролирует, мембрана, ядро, идет, стенка, говорит, приходит | , энергия, вещи, мембрана, движения, митохондрии, эндоцитоз | Ядро управляет всем, а митохондрии сообщают, что входит и выходит из клетки |
| 19 | Дыхание, клеточное, размножение, фотосинтез, процесс, питание, деление, гомеостаз | Эндоцитоз, являющийся частью активного транспорта, при котором клетка использует энергию для протаскивания элементов через избирательно проницаемую мембрану | |
| 20 | мРНК, тРНК, РНК, ДНК, информация, трансляция, транскрипция, сообщения | Он делает это для поддержания гомеостаза клетка перемещает кислород внутрь и углекислый газ из клетки в процессе клеточного дыхания | |
| 21 | Клетка, мембрана, определенные, впускать, вещи, вещества, входить, позволять | мРНК переносит сообщения от ядра к другим органам тРНК транспортирует ДНК к местам внутри клетки рРНК клетки используют для управления движением в клеточную мембрану и из нее, белковые каналы, которые позволяют веществам проходить через них, эндосимбиоз позволяет входить большим веществам, а экзоцитоз позволяет более крупным веществам выходить из клетки |
Открыть в отдельном окне
1 www. kaggle.com/c/asap-sas
kaggle.com/c/asap-sas
Дополнительные материалы к этой статье можно найти в Интернете по адресу: https://www.frontiersin.org /articles/10.3389/fpsyg.2019.00825/full#supplementary-material
Щелкните здесь, чтобы просмотреть файл с дополнительными данными. (9.2K, pdf)
- Апаза Р. Г., Сервантес Э. В., Киспе Л. К., Луна Дж. О. (2014). «Рекомендация онлайн-курсов на основе LDA», в материалах симпозиума по управлению информацией и большими данными — SIMBig , Перу, 42–48. [Google Scholar]
- Арун Р., Суреш В., Мадхаван К. В., Мурти М. Н. (2010). «О нахождении натурального числа тем со скрытым распределением Дирихле: некоторые наблюдения», в материалах Тихоокеанско-азиатской конференции по обнаружению знаний и интеллектуальному анализу данных (Берлин: Springer;), 391–402. 10.1007/978-3-642-13657-3_43 [CrossRef] [Google Scholar]
- Аскалон М. Э., Мейерс Л. С., Дэвис Б. В., Смитс Н. (2007). Сходство отвлекающих факторов и структура элемента: влияние на сложность предмета.
 Заявл. Изм. Образовательный
20
153–170. 10.1080/08957340701301272 [CrossRef] [Google Scholar]
Заявл. Изм. Образовательный
20
153–170. 10.1080/08957340701301272 [CrossRef] [Google Scholar] - Барриос Ф., Лопес Ф., Аргерих Л., Вахенхаузер Р. (2016). Вариации функции сходства textrank для автоматизированного суммирования. arXiv [Препринт]. arXiv:1602.03606 [Google Scholar]
- Беккинк М.О., Дондерс А.Р., Кулуос Дж.Г., де Ваал Р.М., Руитер Д.Дж. (2016). Выявление заблуждений учащихся путем оценки их письменных вопросов. БМС Мед. Образовательный 16:221. 10.1186/с12909-016-0739-5 [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
- Bird S., Klein E., Loper E. (2009). Обработка естественного языка с помощью PYTHON: анализ текста с помощью набора инструментов для работы с естественным языком. Ньютон, Массачусетс: O’Reilly Media, Inc. [Google Scholar]
- Blei DM (2012). Вероятностные тематические модели. Комм. АКМ 55 77–84. 10.1145/2133806.2133826 [CrossRef] [Google Scholar]
- Блей Д.
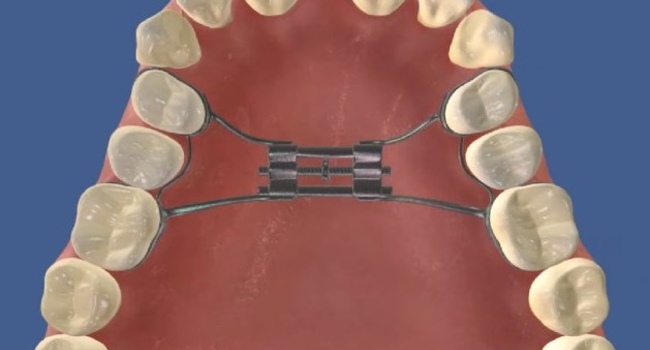 М., Нг А. Ю., Джордан М. И. (2003). Скрытое распределение Дирихле.
Дж. Мах. Учиться. Рез.
3
993–1022. [Google Scholar]
М., Нг А. Ю., Джордан М. И. (2003). Скрытое распределение Дирихле.
Дж. Мах. Учиться. Рез.
3
993–1022. [Google Scholar] - Briggs D.C., Alonzo A.C., Schwab C., Wilson M. (2006). Диагностическая оценка с упорядоченным множественным выбором [Google Scholar]
- Cao J., Xia T., Li J., Zhang Y., Tang S. (2008). Основанный на плотности метод выбора адаптивной модели LDA. Нейрокомпьютинг 72 1775–1781 гг. 10.1016/j.neucom.2008.06.011 [CrossRef] [Google Scholar]
- Case S.M., Swanson DB (2001). Составление письменных тестовых вопросов по фундаментальным и клиническим наукам , 2-е изд. Филадельфия, Пенсильвания: Национальный совет медицинских экспертов. [Google Scholar]
- Чанг Дж., Герриш С., Ван С., Бойд-Грабер Дж. Л., Блей Д. М. (2009). «Чтение чайных листьев: как люди интерпретируют тематические модели», в материалах 23-й ежегодной конференции по системам обработки нейронной информации (Айова-Сити: NIPC;), 288–296. [Google Scholar]
- Чингос М.
 М. (2012). Сила в цифрах: государственные расходы на системы оценки K-12. Доступно по ссылке: https://www.brookings.edu/research/strength-in-numbers-state-spending-on-k-12-assessment-systems/ [по состоянию на 29 ноября, 2012] [Google Scholar]
М. (2012). Сила в цифрах: государственные расходы на системы оценки K-12. Доступно по ссылке: https://www.brookings.edu/research/strength-in-numbers-state-spending-on-k-12-assessment-systems/ [по состоянию на 29 ноября, 2012] [Google Scholar] - Коллинз Дж. (2006). Написание вопросов с несколькими вариантами ответов для непрерывного медицинского образования и модулей самооценки. Рентгенография 26 543–551. 10.1148/гр.262055145 [PubMed] [CrossRef] [Google Scholar]
- де ла Торре Дж. (2009). Модель когнитивной диагностики для вариантов множественного выбора, основанных на когнитивных способностях. Заяв. Психол. Изм. 33 163–183. 10.1177/0146621608320523 [CrossRef] [Google Scholar]
- ДиБаттиста Д., Курзава Л. (2011). Проверка качества заданий с множественным выбором на классных тестах. Кан. Дж. Схоларш. Учить. Учиться. 2:4 10.5206/cjsotl-rcacea.2011.2.4 [CrossRef] [Google Scholar]
- Даунинг С. М. (2006). «Форматы элементов с выбранными ответами в разработке тестов», в Справочник по разработке тестов , ред.
 Халадына Т. М., Даунинг С. М. (Дидкот: Taylor & Francis Group;), 287–301. [Google Scholar]
Халадына Т. М., Даунинг С. М. (Дидкот: Taylor & Francis Group;), 287–301. [Google Scholar] - Gierl M.J., Bulut O., Guo Q., Zhang X. (2017). Разработка, анализ и использование отвлекающих факторов для тестов с множественным выбором в образовании: всесторонний обзор. Ред. Образ. Рез. 87 1082–1116 гг. 10.3102/0034654317726529 [CrossRef] [Google Scholar]
- Gierl MJ, Haladyna T.M. (2013). Автоматическое создание предметов: введение. Автоматическое создание предметов: теория и практика. Нью-Йорк, штат Нью-Йорк: Рутледж. [Google Scholar]
- Гирл М. Дж., Лай Х. (2013). Использование автоматизированных процессов для создания тестовых заданий. Учеб. Изм. 32 36–50. 10.1080/10401334.2016.1146608 [CrossRef] [Google Scholar]
- Gierl MJ, Lai H. (2016). «Автоматическая генерация предметов», в Справочник по разработке тестов , 2-е изд., ред. Лейн С., Рэймонд М., Халадина Т. (Нью-Йорк, штат Нью-Йорк: Routledge;), 410–429. [Google Scholar]
- Гриффитс Т.
 Л., Стейверс М. (2004). Поиск научных тем.
Проц. Натл. акад. науч. США
101 (Приложение 1), 5228–5235. 10.1073/пнас.0307752101
[Бесплатная статья ЧВК] [PubMed] [CrossRef] [Google Scholar]
Л., Стейверс М. (2004). Поиск научных тем.
Проц. Натл. акад. науч. США
101 (Приложение 1), 5228–5235. 10.1073/пнас.0307752101
[Бесплатная статья ЧВК] [PubMed] [CrossRef] [Google Scholar] - Галадина Т. М. (2004). Разработка и проверка тестовых заданий с множественным выбором , 3-е изд. Махва, Нью-Джерси: Эрлбаум. [Академия Google]
- Галадина Т. М., Даунинг С. М. (1989). Действительность таксономии правил написания элементов с множественным выбором. Заяв. Изм. Образовательный 2 37–50. 10.1207/s15324818ame0201_4 [CrossRef] [Google Scholar]
- Галадина Т. М., Даунинг С. М. (1993). Сколько вариантов достаточно для тестового задания с несколькими вариантами ответов? Учеб. Психол. Изм. 53 999–1010. 10.1177/0013164493053004013 [CrossRef] [Google Scholar]
- Халадына Т. М., Родригес М. К. (2013). Разработка и проверка тестовых заданий. Нью-Йорк, штат Нью-Йорк: Рутледж; 10.4324/9780203850381 [CrossRef] [Google Scholar]
- Хосино Ю.
 (2013). Взаимосвязь между типами отвлекающих факторов и сложностью словесных тестов с множественным выбором в сентенциальном контексте.
Ланг. Тест. Азия
3
1–14. 10.1186/2229-0443-3-16 [CrossRef] [Google Scholar]
(2013). Взаимосвязь между типами отвлекающих факторов и сложностью словесных тестов с множественным выбором в сентенциальном контексте.
Ланг. Тест. Азия
3
1–14. 10.1186/2229-0443-3-16 [CrossRef] [Google Scholar] - Ирвин С., Киллонен П. (2002). Создание элементов для разработки тестов. Махва, Нью-Джерси: Эрлбаум. [Google Scholar]
- Конрад М. (2017). Оценка модели темы в Python с помощью Tmtoolkit. Доступно по ссылке: https://datascience.blog.wzb.eu/2017/11/09/topic-modeling-evaluation-in-python-with-tmtoolkit/ [по состоянию на 2 октября 2018 г.]. [Google Scholar]
- Lai H., Gierl M.J., Touchie C., Pugh D., Boulais A., De Champlain A. (2016). Использование автоматической генерации предметов для улучшения качества дистракторов MCQ. Учить. Учиться. Мед. 28 166–173. 10.1080/10401334.2016.1146608 [PubMed] [CrossRef] [Google Scholar]
- Мейснер Р. (2018). Влияние семантического сходства с тренировочными ответами на точность автоматической оценки.
 Документ, представленный на ежегодном собрании Национального совета по измерениям в образовании , Нью-Йорк, штат Нью-Йорк. [Google Scholar]
Документ, представленный на ежегодном собрании Национального совета по измерениям в образовании , Нью-Йорк, штат Нью-Йорк. [Google Scholar] - Михалча Р., Тарау П. (2004). «Textrank: наведение порядка в тексте», в Трудах конференции 2004 г. по эмпирическим методам обработки естественного языка , Барселона. [Google Scholar]
- Морено Р., Мартинес Р. Дж., Муньис Дж. (2006). Новые рекомендации по разработке заданий с множественным выбором. Методология 2 65–72. 10.1027/1614-2241.2.2.65 [CrossRef] [Академия Google]
- Морено Р., Мартинес Р. Дж., Муньис Дж. (2015). Руководящие принципы, основанные на критериях достоверности для разработки элементов множественного выбора. Псикотема 27 388–394. 10.7334/псикотема2015.110 [PubMed] [CrossRef] [Google Scholar]
- Моретти А., Макнайт К., Саллеб-Ауисси А. (2015). «Применение анализа настроений и темы к политике оценки учителей в США», в материалах 8-й Международной конференции по интеллектуальному анализу данных в образовании , Мадрид, 628–629.
 [Академия Google]
[Академия Google] - Муллис И. В. С., Коттер К. Э., Фишбейн Б. Г., Центурино В. А. С. (2016). «Разработка элементов достижений TIMSS Advanced 2015», в Методы и процедуры в TIMSS 2015 , ред. Мартин М. О., Маллис И. В. С., Хупер М. (Честнат-Хилл, Массачусетс: TIMSS & PIRLS; ), 1.1–1.17. [Google Scholar]
- Нагата Р., Такамура Х., Нойбиг Г. (2017). Адаптивные модели исправления орфографических ошибок для изучающих английский язык. Вычисл. науч. 112 474–483. 10.1016/j.procs.2017.08.065 [CrossRef] [Google Scholar]
- ОЭСР (2016 г.). Результаты PISA 2015 (Том I): Совершенство и равенство в образовании. Париж: Издательство ОЭСР; 10.1787/9789264266490-en [CrossRef] [Google Scholar]
- Пан Ю. (2016). На пути к искусственному интеллекту 2.0. Машиностроение 2 409–413. 10.1016/J.ENG.2016.04.018 [CrossRef] [Google Scholar]
- Pennington J., Socher R., Manning C. (2014). «Перчатка: глобальные векторы для представления слов», в Трудах конференции 2014 г.
 по эмпирическим методам обработки естественного языка (EMNLP) г., Доха, 1532–1543 гг. 10.3115/v1/D14-1162 [CrossRef] [Google Scholar]
по эмпирическим методам обработки естественного языка (EMNLP) г., Доха, 1532–1543 гг. 10.3115/v1/D14-1162 [CrossRef] [Google Scholar] - Попеничи С. А., Керр С. (2017). Изучение влияния искусственного интеллекта на преподавание и обучение в высших учебных заведениях. Рез. Практика. Технол. Увеличить Учиться. 12:22. 10.1186/с41039-017-0062-8 [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
- Popham WJ (2008). Трансформационная оценка. Александрия, Вирджиния: ASCD. [Google Scholar]
- Портеус И., Ньюман Д., Илер А., Асунсьон А., Смит П., Веллинг М. (2008). «Быстрая коллапсная выборка Гиббса для скрытого выделения Дирихле», в Материалы 14-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных (Нью-Йорк, штат Нью-Йорк: ACM;), 569–577. 10.1145/1401890.1401960 [CrossRef] [Google Scholar]
- Rodriguez MC (2011). «Практика написания заданий и доказательства», в Справочник по доступным тестам успеваемости для всех учащихся: устранение пробелов между исследованиями, практикой и политикой , ред.
 Эллиот С. Н., Кеттлер Р. Дж., Беддоу П. А., Курц А. (Нью-Йорк, штат Нью-Йорк: Springer;), 201–216. 10.1007/978-1-4419-9356-4_11 [CrossRef] [Google Scholar]
Эллиот С. Н., Кеттлер Р. Дж., Беддоу П. А., Курц А. (Нью-Йорк, штат Нью-Йорк: Springer;), 201–216. 10.1007/978-1-4419-9356-4_11 [CrossRef] [Google Scholar] - Rodriguez MC (2016). «Разработка элементов с выбранными ответами», в Справочник по разработке тестов , 2-е изд., ред. Лейн С., Рэймонд М., Халадина Т. (Нью-Йорк, штат Нью-Йорк: Routledge;), 259–273. [Google Scholar]
- Шермис, доктор медицины (2014). Современная автоматическая оценка эссе: конкурс, результаты и будущие направления из демонстрации в США. Оценка. Письм. 20 53–76. 10.1016/j.asw.2013.04.001 [CrossRef] [Google Scholar]
- Шермис, доктор медицинских наук (2015). Контрастное состояние в области машинного подсчета ответов, построенных по краткой форме. Учеб. Оценивать. 20 46–65. 10.1080/10627197.2015.997617 [CrossRef] [Google Scholar]
- Таррант М., Уэр Дж., Мохаммед А. М. (2009). Оценка функционирующих и нефункционирующих дистракторов в вопросах с несколькими вариантами ответов: описательный анализ.
.jpg) БМС Мед. Образовательный
9:1–8. 10.1186/1472-6920-9-40
[Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
БМС Мед. Образовательный
9:1–8. 10.1186/1472-6920-9-40
[Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar] - Таунс М. Х. (2014 г.). Руководство по разработке высококачественных, надежных и достоверных оценок с множественным выбором. J. Chem. Образовательный 9:40 10.1021/ed500076x [CrossRef] [Google Scholar]
- Vacc N.A., Loesch LC, Lubik R.E. (2001). «Написание тестовых заданий с множественным выбором», в Assessment: Issues and Challenges for the Millennium , eds Walz GR, Bleuer JC (Гринсборо, Северная Каролина: ERIC;), 215–222. [Google Scholar]
- Чжэн Н. Н., Лю З. Ю., Жэнь П. Дж., Ма Ю. К., Чен С. Т., Ю С. Ю. и др. (2017). Гибридно-дополненный интеллект: сотрудничество и познание. Фронт. Поставить в известность. Технол. Электрон. англ. 18:153–179. 10.1631/FITEE.1700053 [CrossRef] [Google Scholar]
Здесь представлены статьи Frontiers in Psychology с разрешения Frontiers Media SA
3 способа создания отвлекающих факторов (неправильный выбор) для MCQ с использованием обработки естественного языка | by Ramsri Goutham
Использование алгоритмов Wordnet, Conceptnet и Sense2vec для создания отвлекающих факторов
Изображение автора Отвлекающие факторы — это неправильных ответов в вопросе с несколькими вариантами ответов.
Например, если заданный вопрос с несколькими вариантами ответов содержит игру Крикет в качестве правильного ответа, тогда нам нужно сгенерировать неправильные варианты ответов (отвлекающие факторы), такие как Футбол, Гольф, Ultimate Frisbee и т. д.
Изображение автораMultiple- вопросы выбора являются самыми популярными вопросов оценки созданы ли это для школьного теста или выпускного конкурсного экзамена.
Разработка эффективных отвлекающих факторов для заданного вопроса — очень трудоемкий процесс для авторов вопросов/преподавателей. Учитывая возросшую нагрузку на учителей/составителей оценок из-за Covid, было бы очень полезно, если бы мы могли создать автоматизированную систему для создания этих отвлекающих факторов .
В этой статье мы увидим, как мы можем использовать методы обработки естественного языка для решения этой практической проблемы.
В частности, мы увидим, как мы можем генерировать дистракторы, используя 3 разных алгоритма —
- WordNet
- ConceptNet
- Sense2Vec
Дистракторы не должны быть слишком похожими или слишком разными. Дистракторы должны быть однородными по содержанию. Например: розовый, синий, часы, зеленый делает очевидным, что ответом могут быть часы.
Дистракторы должны быть взаимоисключающими . Поэтому не следует включать синонимы.
Начнем.
- WordNet® — это большая лексическая база данных английского языка.
- Аналогичен тезаурусу, но охватывает еще более широкие отношения между словами.
- WordNet также является бесплатным и общедоступным для скачивания.
- WordNet маркирует семантические отношения между словами. Например: Синонимы — автомобиль и автомобиль
- WordNet также фиксирует различные значения слова. Например: мышь может означать животное или компьютерную мышь.
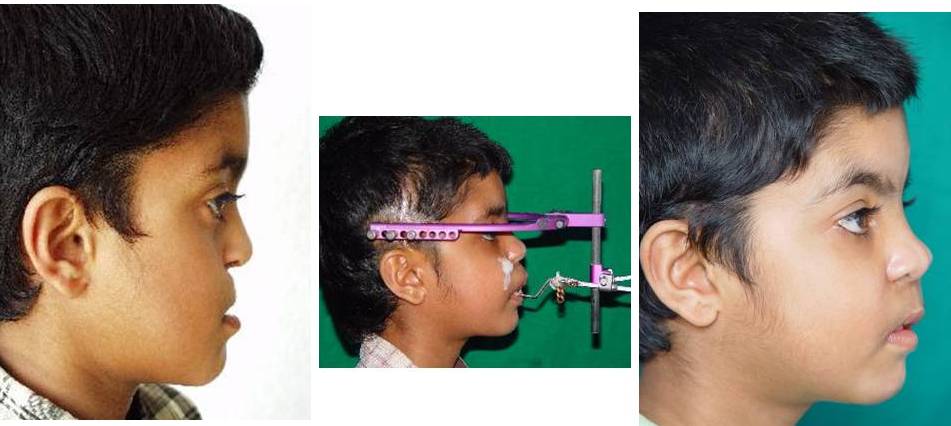
Генерация дистракторов с помощью Wordnet
Если у нас есть предложение «Летучая мышь улетела в джунгли и приземлилась на дерево» и ключевое слово «летучая мышь» , мы автоматически знаем, что здесь речь идет о млекопитающем летучей мыши у которого есть крылья, а не крикетная или бейсбольная бита.
Хотя мы, люди, умеем это делать, алгоритмы не очень хорошо умеют отличать одно от другого. Это называется устранение неоднозначности смысла слова (WSD).
В Wordnet «летучая мышь» может иметь несколько значений (значений) одно для крикетной биты, одно для летающего млекопитающего и т. д. Устранение неоднозначности смысла слова с помощью НЛП является отдельной темой, поэтому для этого руководства мы предполагаем, что точный «смысл» определяется пользователем вручную или верхний смысл выбирается автоматически.
Допустим, мы получаем слово типа « Красный » и идентифицируем его смысл , затем мы переходим к его гиперниму с помощью Wordnet. Гипероним является категорией более высокого уровня для данного слова. В нашем примере цвет является гипернимом для Red .
Гипероним является категорией более высокого уровня для данного слова. В нашем примере цвет является гипернимом для Red .
Затем мы находим все гипонимы (подкатегории) цвета , которые могут быть фиолетовыми, синими, зелеными и т. д., принадлежащими к цветовой группе. Таким образом, мы можем использовать Фиолетовый, Синий, Зеленый в качестве отвлекающих факторов (неправильный выбор ответа) для данного MCQ, который имеет Красный как правильный ответ. Пурпурный, синий, зеленый также называют согипонимами красного.
Таким образом, используя Wordnet, извлекая согипонимов данного слова, мы получаем отвлекающих факторов этого слова. Итак, на изображении ниже отвлекающими факторами красного цвета являются синий, зеленый и фиолетовый.
Источник: https://en.wikipedia.org/wiki/Hyponymy_and_hypernymyКод Wordnet
Начнем с установки NLTK
!pip install nltk==3.5.0
Импорт wordnet
import nltk
nltk.download('wordnet')
from nltk.corpus import wordnet as wn
Получить все отвлекающие факторы для слова « лев». Здесь мы извлекаем первый смысл слова лев и извлекаем согипонимы слова лев в качестве отвлекающих факторов.
# Отвлекающие факторы из Wordnet
def get_distractors_wordnet (syn,word):
distractors=[]
word= word.lower()
orig_word = word
if len(word.split())>0:
word = word.replace(" ","_")
hypernym = syn.hypernyms()
if len(hypernym) == 0:
вернуть отвлекающие факторы
для элемента в hypernym[0].hyponyms():
имя = item.lemmas()[0].name()
#print ("name", name, " word", orig_word)
if name == orig_word:
continue
name = name.replace ("_"," ")
name = " ".join(w.capitalize() for w in name.split())
, если имя не None и имя не в дистракторах:
dirtysors.append(name)
return dirtyoriginal_word = "Lion"
SYNSET_TO_USE = WN.SYNSETS (ORIGINAL_WORD, 'n') [0]
Distractors_Calculated = Get_distractors_wordnet (synset_to_use, Original_word) 9094Выход выше:
Выход выше:
. 8 . ['Гепард', 'Ягуар', 'Леопард', 'Лигр', 'Саблезубый Тигр', 'Снежный Барс', 'Тигр', 'Тиглон']Аналогично, для слова сверчок , у которого есть два чувства (одно для насекомых и одно для игры) мы получаем разные отвлекающие факторы для каждого в зависимости от того, какое чувство мы используем.
# Пример слова с двумя разными смыслами
original_word = "cricket" syns = wn.synsets(original_word,'n')for syn in syns:
print (syn, ": ",syn.definition( ),"\n" )synset_to_use = wn.synsets(original_word,'n')[0]
distractors_calculated = get_distractors_wordnet(synset_to_use,original_word)print ("\noriginal word: ",original_word.capitalize())
print (distractors_calculated)original_word = "cricket"
synset_to_use = wn.synsets(original_word,'n')[1]
distractors_calculated = get_distractors_wordnet(synset_to_use,original_word)print ("\noriginal word: ",original_word.capitalize())
print (distractors_calculated)Output:
Synset('cricket.n.019') 9019 насекомое; самец чирикает, потирая передние крылья друг о друга Synset('cricket.n.02') : игра с мячом и битой, в которую играют две команды по 11 игроков; команды по очереди пытаются набрать очки Исходное слово: Крикет
дистракторы: ['Кузнечик'] оригинальное слово: Крикет
дистракторы: ['Игра в мяч', 'Хоккей на траве', 'Футбол', 'Хёрлинг', 'Лакросс', 'Поло', 'Пушбол ', 'Ultimate Frisbee']
- Conceptnet — это бесплатный многоязычный граф знаний.
- Включает знания из краудсорсинговых ресурсов и ресурсов, созданных экспертами.

- Подобно WordNet, Conceptnet маркирует семантические отношения между словами. Они более подробные, чем Wordnet. Например: является, частью, сделан из, похож на, используется для и т. д. Фиксируются отношения между словами.
Генерация дистракторов с помощью Conceptnet
Концептнет удобен для создания дистракторов для таких вещей, как места, предметы и т. д., которые имеют отношения «Partof» . Например, такой штат, как «Калифорния» , может быть частью Соединенных Штатов. «Кухня» может быть частью дома и т. д.
В Conceptnet нет возможности устранять неоднозначность между разными смыслами слов, как мы обсуждали выше на примере летучей мыши. Следовательно, нам нужно использовать любой смысл, который дает нам Conceptnet, когда мы запрашиваем данное слово.
Давайте посмотрим, как мы можем использовать Conceptnet в нашем случае. Нам не нужно ничего устанавливать, потому что мы можем напрямую использовать API Conceptnet.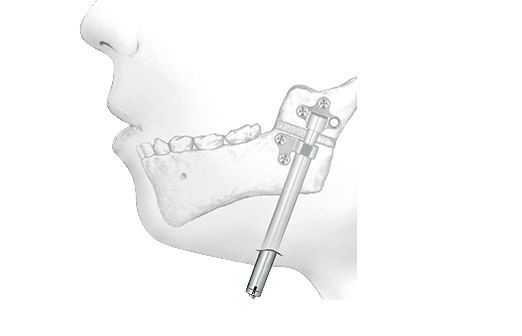 Обратите внимание, что существует почасовое ограничение скорости API, поэтому остерегайтесь этого.
Обратите внимание, что существует почасовое ограничение скорости API, поэтому остерегайтесь этого.
Получив такое слово, как «Калифорния» , мы запрашиваем его у Conceptnet и извлекаем все слова, которые имеют с ним отношение « Partof ». В нашем примере «Калифорния» является частью «США».
Теперь переходим к «США» и посмотреть, с какими другими вещами он имеет отношение «Partof» . Это могут быть другие штаты, такие как «Техас», «Аризона», «Сиэтл» и т. д.
Подобно Wordnet, мы извлекаем согипонимов , используя отношение «partof» для нашего слова запроса «Калифорния», и мы получаем отвлекающие факторы «Техас». », «Аризона» и т. д.
Изображение автораКод для Conceptnet
Результат:
Исходное слово: Калифорния Дистракторы: ['Техас', 'Аризона', 'Нью-Мексико', 'Невада', ' Канзас», «Новая Англия», «Флорида», «Монтана», «Твин», «Алабама», «Йосемити», «Коннектикут», «Среднеатлантические штаты»]
В отличие от Wordnet и Conceptnet отношения между словами в Sense2vec не курируются человеком , а автоматически генерируются из текстового корпуса.
Алгоритм нейронной сети обучается на миллионах предложений, чтобы предсказывать основное слово по другим словам или предсказывать окружающие слова по заданному слову. Благодаря этому мы генерируем векторов фиксированного размера или представление массива для каждого слова. Мы называем эти векторов слов.
Интересно, что эти векторы фиксируют ассоциации между разными видами слов. Например, слова подобного типа в реальном мире падают на 90 148 ближе, чем на 90 149 в векторном пространстве.
Также сохраняются отношений между разными словами. Если мы возьмем вектор слова «Король», вычтем вектор «Мужчина» и добавим вектор «Женщина», мы получим вектор Королевы. Реальные отношения «что король для мужчины, королева то же самое для женщины» сохраняется.
Источник: https://blog.acolyer.Король — Мужчина + Женщина = Королева
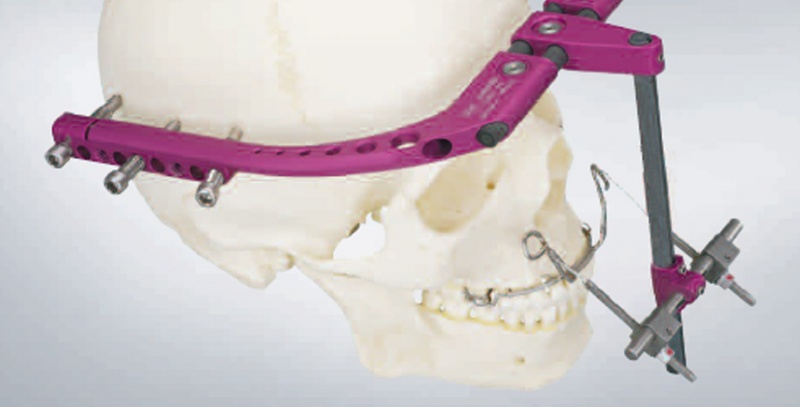 org/2016/04/21/the-amazing-power-of-word-vectors/
org/2016/04/21/the-amazing-power-of-word-vectors/ Sense2vec обучается на Reddit Комментарии. Фразы-существительные и именованные объекты аннотируются во время обучения, поэтому многословных фраз, таких как «обработка естественного языка» , также имеют запись, в отличие от некоторых алгоритмов вектора слов, которые обучаются только с отдельными словами.
Мы будем использовать подготовленные векторы Reddit 2015 года, а не 2019 года.так как результаты были немного лучше в моем эксперименте.
код для Sense2VEC
Установить Sense2VEC из PIP
! PIP Установка SENSE2VEC == 1.0.2
Скачать и Unzip Sense2VEC VECTOR Sense2Vec
s2v = Sense2Vec().from_disk('s2v_old')
Получить отвлекающие факторы для заданного слова. Например: обработка естественного языка
Выход:
Дистракторы для обработки естественного языка:
['Машинное обучение', 'Компьютерное зрение', 'Глубокое обучение', 'Анализ данных', 'Нейронные сети', 'Реляционные базы данных', 'Алгоритмы' , «Нейронные сети», «Обработка данных», «Распознавание изображений», «NLP», «Большие данные», «Наука о данных», «Анализ больших данных», «Поиск информации», «Распознавание речи», «Языки программирования».]
Я запустил очень интересный курс Udemy под названием «Генерация вопросов с использованием НЛП», расширяющий некоторые методы, обсуждаемые в этом посте в блоге. Если вы хотите взглянуть на это, вот ссылка.
Надеюсь, вам понравилось, как мы решили реальную проблему генерации отвлекающих факторов (неправильного выбора) в MCQ с помощью НЛП.
Счастливого изучения НЛП, и если вам понравился контент, не стесняйтесь найти меня в Твиттере.
Если вы хотите изучить современное НЛП с помощью трансформеров, посмотрите мой курс Генерация вопросов с использованием НЛП
Дистракционный остеогенез — Сиэтлская детская школа
Что такое дистракционный остеогенез?
Дистракционный остеогенез — это способ сделать более длинную кость из более короткой.
После разреза кости во время операции устройство, называемое дистрактором, медленно разделяет 2 фрагмента кости. Медленное растяжение кости безболезненно. Дети говорят, что это менее болезненно, чем брекеты, которые они носят для выравнивания зубов.
Новая кость вырастает (остеогенез), чтобы заполнить щель. Это происходит дома после выписки ребенка из больницы. Процесс занимает пару месяцев.
Дистракционный остеогенез позволяет добиться большей коррекции положения кости, чем это возможно при одной традиционной операции. Это улучшает результаты и может уменьшить количество хирургических вмешательств, необходимых ребенку в течение всей жизни.
Детский центр Сиэтла является лидером в области дистракционного остеогенеза при черепно-лицевых синдромах. Благодаря исследованиям мы разработали более короткий процесс по сравнению с другими больницами. Наши методы также помогают предотвратить образование рубцов на лице вашего ребенка.
Как работает дистракционный остеогенез?
Как при дистракционном остеогенезе, так и при традиционных процедурах хирурги делают разрез в кости. Процедуру можно назвать остеотомией, что означает рассечение кости.
- В традиционной хирургии врач использует костные трансплантаты для удлинения костей.
 В некоторых случаях кость перемещают и удерживают в новом положении с помощью металлических пластин и винтов.
В некоторых случаях кость перемещают и удерживают в новом положении с помощью металлических пластин и винтов. - При дистракционном остеогенезе хирург прикрепляет к разрезанной кости устройство, называемое дистрактором. Иногда дистрактор помещают под кожу. В других случаях он прикрепляется к черепу ребенка и костям лица на внешней стороне кожи.
Тип используемого дистрактора зависит от костей, которые должны расти. Устройства одобрены Управлением по санитарному надзору за качеством пищевых продуктов и медикаментов. Все устройства изготовлены из легкого гипоаллергенного металла, называемого титаном.
Для дистракционной хирургии средней зоны лица устройство обычно представляет собой головной каркас U-образной формы. Хирург закрепляет его вокруг верхней части головы вашего ребенка и прикрепляет специальными винтами, называемыми «шпильками».
Вертикальная металлическая планка крепится к раме головы перед лбом ребенка. На уровне рта вертикальная планка присоединяется к горизонтальной планке с поворотным рычагом. Хирург прикрепляет поворотный рычаг к зубной шине, прикрепленной к верхним зубам. Иногда провода также подключаются к крошечным булавкам, размещенным на лице вашего ребенка.
Хирург прикрепляет поворотный рычаг к зубной шине, прикрепленной к верхним зубам. Иногда провода также подключаются к крошечным булавкам, размещенным на лице вашего ребенка.
На задней раме имеется отверстие. Дети говорят, что спать с включенным устройством не проблема.
Для дистракции нижней челюсти используются устройства меньшего размера. Часто они подходят под кожу. Через кожу проходит небольшой штифт для регулировки устройства.
В течение 2–3 недель после операции, пока ваш ребенок находится дома, родитель или опекун закручивает 1 или более винтов на дистракторе на 1–2 миллиметра в день. Это удерживает натяжение проводов и раздвигает лицевые кости. Затем вырастает новая кость, которая заполняет промежутки. Новая кость начинается как ириска и со временем затвердевает.
Как только кости окажутся в правильном положении, поворот прекратится. Кости срастаются в новом положении. Это называется консолидацией или «фазой заживления». Он длится от 1 до 2 месяцев.
Ваш ребенок должен есть мягкую пищу все время, пока дистрактор включен. Им нужно будет часто посещать детский сад Сиэтла, чтобы мы могли проверить, правильно ли работает дистрактор, и решить, когда перестать поворачиваться. Во время некоторых посещений вашему ребенку сделают рентгеновские снимки лица. Возможно, нам придется внести небольшие коррективы в дистрактор.
Когда новая кость становится достаточно прочной, дистрактор удаляется во время очень короткой второй операции.
Каков опыт детей в Сиэтле с дистракционным остеогенезом?
У нас есть опыт лечения детей всех возрастов с дистракционным остеогенезом. Среди наших пациентов:
- Новорожденные с затрудненным дыханием
- Дети младшего возраста, у которых маленькая челюсть требует использования дыхательной трубки в трахее
- Дети, чьи скулы и глазницы недостаточно защищают глаза
- Подростки, чьи челюсти не выстраиваются должным образом
Мы подбираем лечение в зависимости от состояния вашего ребенка.
Чтобы помочь спланировать лечение вашего ребенка, наши краниофациальные пластические хирурги и хирурги-ортодонты используют 3D-изображения и передовое программное обеспечение для создания точных карт лица и черепа вашего ребенка. Трехмерное изображение позволяет нашим врачам прогнозировать, как движение в одной части лица может повлиять на другие области. Программное обеспечение также объясняет ожидаемый рост. Это помогает хирургам точно спланировать, насколько и в каком направлении следует перемещать различные кости лица.
Более короткий процесс с лучшими результатами
Процесс, который мы разработали в Seattle Children’s, сокращает время использования дистрактора по сравнению с методом, используемым в других больницах.
Наши методы помогают предотвратить образование рубцов на лице. Например, чтобы соединить верхнюю челюсть с дистрактором, хирург использует небольшие надрезы (разрезы) и специальную шину, которая помещается во рту вашего ребенка. Хирург не разрезает рот или веки вашего ребенка. Мы не вешаем им за щеки штыри, как это делают в большинстве других больниц. Волосы вашего ребенка вскоре скроют единственный шрам на макушке.
Мы не вешаем им за щеки штыри, как это делают в большинстве других больниц. Волосы вашего ребенка вскоре скроют единственный шрам на макушке.
Какие виды дистракционного остеогенеза проводятся в детской больнице Сиэтла?
Дистракционный остеогенез является вариантом для многих операций, при которых кости черепа и лица перемещаются в лучшее положение. Наша команда работает вместе с вами, чтобы решить, будет ли достигнут наилучший результат с дистракционным остеогенезом или без него.
Хирурги нашего Черепно-лицевого центра используют дистракционный остеогенез в следующих процедурах:
- Дистракция заднего свода черепа, чтобы дать мозгу возможность расти
- Моноблочное лобно-лицевое продвижение для изменения положения лба и средней части лица
- Сегментарная субкраниальная дистракция для нормализации пропорций лица
- Отвлечение подчерепного вращения для улучшения проходимости дыхательных путей и положения челюсти
- Выдвижение верхней челюсти по Le Fort I для коррекции неправильно сросшихся верхних челюстей
- Продвижение средней части лица Le Fort III для перемещения средней части лица вперед
- Дистракция нижней челюсти для нижней челюсти не сформировалась должным образом
Свяжитесь с нами
Свяжитесь с Черепно-лицевым центром по телефону 206-987-2208, чтобы записаться на прием, получить второе мнение или получить дополнительную информацию.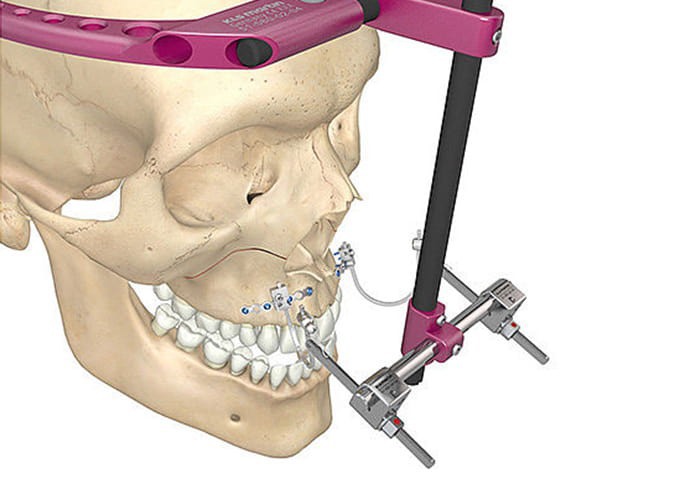
Хорошо, лучше, лучше: построение экзамена с несколькими вариантами ответов
Помните ли вы следующую детскую песенку? «Хороший лучше наилучший. Никогда не позволяйте ему отдыхать. «Пока твое добро не станет лучше, а твое лучшее не станет лучшим». Эта песенка напоминает нам, учителям, которые пишут экзамены с несколькими вариантами ответов, о том, что всегда есть место для совершенствования. Написание более качественных экзаменов позволяет лучше оценивать обучение наших студентов.
Прежде чем мы рассмотрим примеры ошибок, которых следует избегать, следующий пример поможет нам установить общий язык в отношении частей экзаменационного задания с несколькими вариантами ответов.
| 3. Чем в основном объясняется увеличение средней продолжительности жизни в США за последние пятьдесят лет? | = ШТОК | |
| дистрактор— | а. Обязательные курсы здоровья и физического воспитания в государственных школах. Обязательные курсы здоровья и физического воспитания в государственных школах. |
|
| ответ — | *б. Снижение смертности среди младенцев и детей раннего возраста | |
| дистрактор— | с. Движение за безопасность, которое значительно снизило количество смертей от несчастных случаев | = Альтернативы |
| дистрактор — | д. Замена человеческого труда машинами. | |
Чтобы ваши хорошие экзамены стали лучше, а лучшие экзамены стали лучше, старайтесь избегать этих ошибок при написании экзаменов.
1. Плохо написанные основы
Основа – это часть задания с несколькими вариантами ответов, в которой ставится задача, на которую учащиеся должны ответить. Основы могут быть в форме вопроса или неполного предложения. Плохо написанные основы не могут четко указать на проблему, когда они расплывчаты, полны нерелевантных данных или написаны негативно.
Плохо написанные основы не могут четко указать на проблему, когда они расплывчаты, полны нерелевантных данных или написаны негативно.
а. Избегайте неясных основ, формулируя проблему в основе:
Плохой пример
Калифорния:
a. Содержит самую высокую гору в Соединенных Штатах.
б. На государственном флаге изображен орел.
с. Является вторым по величине штатом по площади.
*д. Был местом золотой лихорадки 1849 года.
Хороший пример
Какова главная причина, по которой так много людей переехало в Калифорнию в 1849 году?
а. Земля в Калифорнии была плодородной, обильной и недорогой.
*б. Золото было обнаружено в центральной Калифорнии.
с. Восток готовился к гражданской войне.
д. Они хотели основать религиозные поселения.
б. Избегайте многословных основ, удаляя нерелевантные данные:
Плохой пример
Предположим, вы профессор математики, который хочет определить, оказало ли ваше преподавание модуля вероятности существенное влияние на ваших студентов.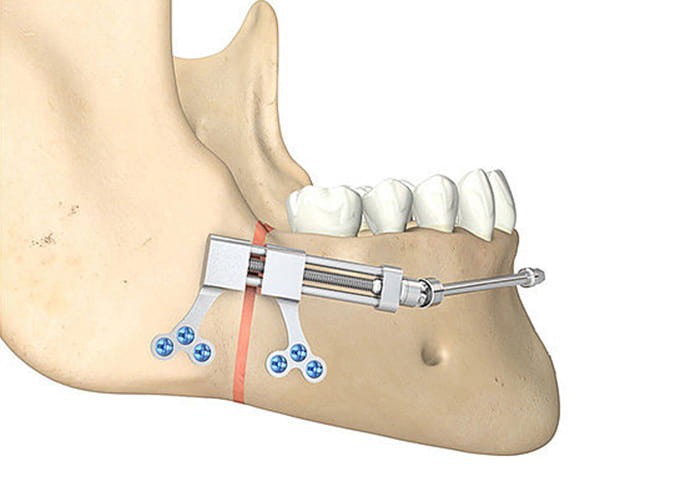 Вы решаете проанализировать их баллы по тесту, который они сдали перед инструкцией, и их баллы по другому экзамену, сданному после инструктажа. Какой из следующих t-тестов подходит для использования в этой ситуации?
Вы решаете проанализировать их баллы по тесту, который они сдали перед инструкцией, и их баллы по другому экзамену, сданному после инструктажа. Какой из следующих t-тестов подходит для использования в этой ситуации?
*а. Зависимые образцы.
б. Гетерогенные образцы.
с. Однородные образцы.
д. Независимые образцы.
Хороший пример
При анализе результатов предварительного и итогового тестирования ваших учащихся для определения того, оказало ли ваше обучение значительный эффект, подходящей статистикой для использования является t-критерий для:
*a. Зависимые образцы.
б. Гетерогенные образцы.
с. Однородные образцы.
д. Независимые образцы.
гр. Избегайте отрицательно сформулированных основ, формулируя основу в положительной форме:
Плохой пример
Медсестра осматривает клиента с пневмонией. Какой из этих результатов оценки указывает на то, что клиенту НЕ нужно проводить аспирацию?
а.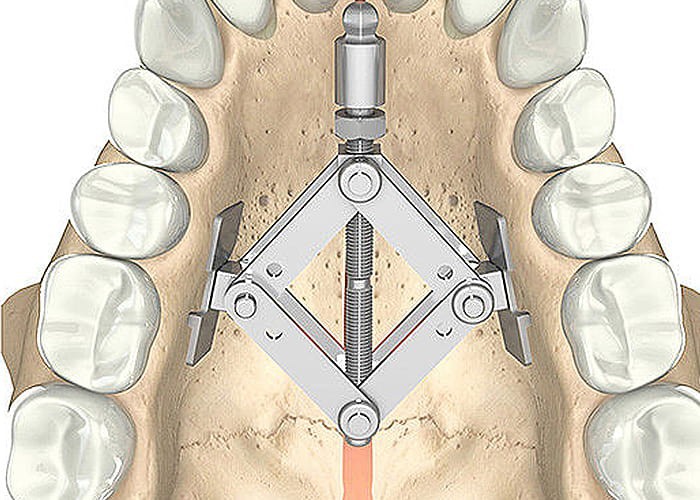 Ослабление дыхательных шумов.
Ослабление дыхательных шумов.
*б. Отсутствие посторонних дыхательных шумов.
с. Невозможность откашлять мокроту.
д. Свистящее дыхание после терапии бронхолитиками.
Хороший пример
Какие из этих результатов обследования, если они выявлены у клиента с пневмонией, указывают на то, что клиенту требуется аспирация?
а. Отсутствие посторонних дыхательных шумов.
б. Частота дыхания 18 вдохов в минуту.
*с. Невозможность откашлять мокроту.
д. Свистящее дыхание до терапии бронхолитиками.
Примечание: Эксперты по письменному тесту считают, что основы с отрицательными формулировками сбивают учащихся с толку.
2. Плохо написанные альтернативы
Альтернативы в задании с множественным выбором состоят из ответа и отвлекающих факторов, которые хуже или неправильнее. Преподаватели часто обнаруживают, что создание достаточного количества отвлекающих факторов является самой сложной частью написания экзамена. Распространенные ошибки при написании альтернатив экзамена связаны с тем, как соотносятся различные альтернативы. Они должны быть взаимоисключающими, однородными, правдоподобными и последовательно сформулированными.
Распространенные ошибки при написании альтернатив экзамена связаны с тем, как соотносятся различные альтернативы. Они должны быть взаимоисключающими, однородными, правдоподобными и последовательно сформулированными.
а. Избегайте дублирования альтернатив
Плохой пример
Какова средняя эффективная доза облучения при КТ грудной клетки?
а. 1-8 мЗв
б. 8-16 мЗв
в. 16-24 мЗв
d. 24–32 мЗв
Хороший пример
Какова средняя эффективная доза облучения при КТ грудной клетки?
а. 1-7 мЗв
б. 8-15 мЗв
в. 16-24 мЗв
d. 24-32 мЗв
б. Избегайте непохожих альтернатив
Плохой пример
Айдахо широко известен как:
*a. Крупнейший производитель картофеля в США.
б. Расположение самой высокой горы в США.
с. Государство с бобром на флаге.
д. «Состояние сокровищ».
Хороший пример
Айдахо широко известен своими:
a.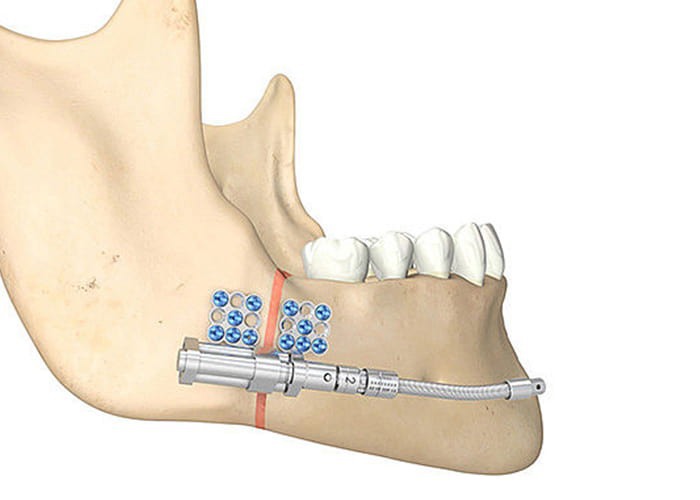 Яблоки.
Яблоки.
б. Кукуруза.
*с. Картофель.
д. Пшеница
Примечание. Хороший пример проверяет знания учащихся о сельском хозяйстве штата Айдахо. Плохой пример сбивает с толку, потому что студенты не уверены, отвечают ли они на вопрос о сельском хозяйстве Айдахо, географии, флаге или прозвище.
с. Избегайте неправдоподобных альтернатив:
Плохой пример
Кто из следующих художников известен росписью потолка Сикстинской капеллы?
а. Уорхол.
б. Флинстон.
*с. Микеланджело.
д. Санта Клаус.
Хороший пример
Кто из следующих художников известен росписью потолка Сикстинской капеллы?
а. Боттичелли.
б. Да Винчи.
*с. Микеланджело.
д. Рафаэль
д. Избегайте непоследовательных формулировок альтернатив:
Плохой пример
Термин оперантное обусловливание относится к обучающей ситуации, в которой:
a. Знакомая реакция связана с новым стимулом.
б. Отдельные ассоциации последовательно соединяются друг с другом.
*с. Реакция учащегося играет важную роль в том, чтобы привести к последующему подкрепляющему событию.
д. На словесные раздражители даются вербальные ответы.
Хороший пример
Термин оперантное обусловливание относится к учебной ситуации, в которой:
a. Знакомая реакция связана с новым стимулом.
б. Отдельные ассоциации последовательно соединяются друг с другом.
*с. Реакция ученика приводит к подкреплению.
д. На словесные раздражители даются вербальные ответы.
Примечание. Длина ответа в плохом примере больше, чем у отвлекающих факторов. Некоторые учащиеся стремятся обнаружить эти изменения. Кроме того, язык в плохом примере взят из учебника, а отвлекающие факторы — собственными словами инструктора. Хороший пример делает фразу последовательной по длине и использует язык инструктора.
Источники:
- Части задания с множественным выбором и примеры в 1a, 1b, 2b, 2c и 2d взяты из Стивена Дж.
