Интерпретация равена: Недопустимое название — Psylab.info
Интерпретация результатов МНК—ArcMap | Документация
- Разделы статистического отчета
- Дополнительные ресурсы
Результатами работы инструмента Метод наименьших квадратов являются:
- Выходной класс пространственных объектовКарта невязок МНК
- Окно сообщения с отчётом о статистических результатахСтатистический отчет МНК
- Дополнительный файл отчёта в формате PDF
- Дополнительная пояснительная таблица для коэффициентов переменныхТаблица коэффициентов модели МНК
- Дополнительная таблица результатов диагностикиТаблица диагностики моделирования МНК
Ниже представлено отображение и описание каждого из этих элементов в виде серии шагов от запуска МНК до интерпретации результатов его работы.
(A) Чтобы запустить инструмент МНК, укажите входной класс объектов с полем уникального ID, зависимую переменную, которую требуется смоделировать/объяснить/спрогнозировать, и список независимые значения.
Диалоговое окно инструмента Метод наименьших квадратов
После запуска МНК прежде всего вам захочется увидеть отчет МНК, записанный в виде сообщений во время выполнения инструмента в файл, хранящийся по указанному вами в параметре Выходной файл отчета пути.
(B) Просмотрите сводный отчет, используя приведенные ниже инструкции:
Компоненты Статистического отчета о МНК
Разделы статистического отчета
- Оценка производительности модели. Оба значения Multiple R-Squared и Adjusted R-Squared являются показателями производительности модели. Возможные значения варьируются от 0.0 до 1.0. Значение Adjusted R-Squared всегда несколько ниже, нежели Multiple R-Squared, поскольку отражает сложность модели (количество переменных), что, в свою очередь, связано с целостностью данных, поэтому гораздо точнее отражает производительность модели.
 Добавление дополнительных независимых переменных в модель, как правило, повышает значение Multiple R-Squared, но понижает при этом значение Adjusted R-Squared. Предположим, вы создаете регрессионную модель домовых краж (количество домовых краж по каждому кварталу является зависимой переменной, y). Значение Adjusted R-Squared, равное 0,39 показывает, что ваша модель (или независимые переменные, промоделированные с использованием линейной регрессии) объясняет порядка 39 процентов случаев поведения зависимой переменной. Иными словами, ваша модель описывает около 39% домовых краж.Значения R-Squared определяют производительность модели
Добавление дополнительных независимых переменных в модель, как правило, повышает значение Multiple R-Squared, но понижает при этом значение Adjusted R-Squared. Предположим, вы создаете регрессионную модель домовых краж (количество домовых краж по каждому кварталу является зависимой переменной, y). Значение Adjusted R-Squared, равное 0,39 показывает, что ваша модель (или независимые переменные, промоделированные с использованием линейной регрессии) объясняет порядка 39 процентов случаев поведения зависимой переменной. Иными словами, ваша модель описывает около 39% домовых краж.Значения R-Squared определяют производительность модели - Оценка каждой независимой переменной в модели: Coefficient (коэффициент), Probability (Вероятность) или Robust Probability (Устойчивая вероятность) и Variance Inflation Factor (VIF) (Фактор, увеличивающий дисперсию). Коэффициент для каждой независимой переменной отражает силу и тип отношений между независимой и зависимой переменной. Если коэффициент отрицательный, отношения являются «негативными» (например, чем больше расстояние от центра города, тем меньше количество домовых краж).
 Если значение положительно, связь между показателями прямая (например, чем больше население, тем больше количество домовых краж). Коэффициенты приводятся в тех же единицах, что и связанные с ними независимые переменные (коэффициент 0.005 связан с переменной, представляющей численность населения, которую можно указать как 0.005 человек). Коэффициент отражает ожидаемое изменение в зависимой переменной для каждого изменения в связанной независимой переменной, хранящей все остальные константы переменных (например, при добавлении очередного жильца в квартал (который «хранит» все остальные независимые переменные), ожидается повышение значения домовых краж на 0,005). Тест T используется для проведения оценки того, являются ли независимые переменные значимыми. Нулевая гипотеза означает, что для всех случаев коэффициент близок к нулю (и, соответственно, не подходит для моделирования). В случаях, когда вероятность или устойчивая вероятность (p-значения) являются очень маленькими, шанс того, что коэффициент равен нулю, также невелик.
Если значение положительно, связь между показателями прямая (например, чем больше население, тем больше количество домовых краж). Коэффициенты приводятся в тех же единицах, что и связанные с ними независимые переменные (коэффициент 0.005 связан с переменной, представляющей численность населения, которую можно указать как 0.005 человек). Коэффициент отражает ожидаемое изменение в зависимой переменной для каждого изменения в связанной независимой переменной, хранящей все остальные константы переменных (например, при добавлении очередного жильца в квартал (который «хранит» все остальные независимые переменные), ожидается повышение значения домовых краж на 0,005). Тест T используется для проведения оценки того, являются ли независимые переменные значимыми. Нулевая гипотеза означает, что для всех случаев коэффициент близок к нулю (и, соответственно, не подходит для моделирования). В случаях, когда вероятность или устойчивая вероятность (p-значения) являются очень маленькими, шанс того, что коэффициент равен нулю, также невелик. Если тест Koenker (см. ниже) является статистически значимым, используйте значения устойчивой вероятности для оценки статистической значимости независимых переменных. Статистические значимости вероятности помечены звездочкой (*). Независимая переменная, связанная со статистически значимым коэффициентом, важна для модели регрессии, если теоретическое/часто встречаемое значение поддерживает корректное отношение с зависимой переменной, если моделируемое отношение является, в основном, линейным и если переменная не является избыточной для всех остальных независимых переменных в модели. Фактор, увеличивающий дисперсию, измеряет избыточность среди независимых переменных. По опыту, независимые переменные, связанные со значениями фактора VIF, больше, чем 7,5 должны быть удалены (по одному) из модели регрессии. Если, например, в модели имеется переменная населения (количество человек) и переменная трудящихся (количество работающих человек), явную связь между ними можно найти по высокому значению VIF, увеличивающего дисперсию, который показывает, что обе переменных говорят об одном и том же, следовательно, одну из них из модели можно удалить.
Если тест Koenker (см. ниже) является статистически значимым, используйте значения устойчивой вероятности для оценки статистической значимости независимых переменных. Статистические значимости вероятности помечены звездочкой (*). Независимая переменная, связанная со статистически значимым коэффициентом, важна для модели регрессии, если теоретическое/часто встречаемое значение поддерживает корректное отношение с зависимой переменной, если моделируемое отношение является, в основном, линейным и если переменная не является избыточной для всех остальных независимых переменных в модели. Фактор, увеличивающий дисперсию, измеряет избыточность среди независимых переменных. По опыту, независимые переменные, связанные со значениями фактора VIF, больше, чем 7,5 должны быть удалены (по одному) из модели регрессии. Если, например, в модели имеется переменная населения (количество человек) и переменная трудящихся (количество работающих человек), явную связь между ними можно найти по высокому значению VIF, увеличивающего дисперсию, который показывает, что обе переменных говорят об одном и том же, следовательно, одну из них из модели можно удалить. Оценка того, какие переменные являются статистически значимыми.
Оценка того, какие переменные являются статистически значимыми. - Оценка значимости модели. Показатели Соединенная F-статистика и Соединенная статистика Вальда отвечают за общую статистическую значимость модели. Соединенная F-статистика является надежным только в том случае, когда Статистика Кенкера (BP) (см. ниже) не является статистически значимым. В противном случае желательно проанализировать Соединенную статистику Вальда, чтобы определить общую значимость модели. Нулевая гипотеза для обоих тестов подразумевает, что независимые переменные в модели являются неэффективными. Для уровня надежности в 95%, a p-значение (вероятность) менее 0.05 показывает статистическую значимость модели.Оценка общей статистической значимости регрессионной модели.
- Оценка стационарности. Статистика Кенкера (BP) (стьюдентизированная Кенкером статистика Бреуша-Пагана) – это тест на определение того, имеют ли независимые переменные в модели постоянную связь с зависимой переменной как в географическом пространстве, так и в пространстве данных.
 Если модель согласована в географическом пространстве, то процессы, представленные независимыми переменными, ведут себя одинаково по всей области исследования (являются стационарными). Если модель согласована в пространстве данных, то разница в отношениях между предсказанными значениями и каждой независимой переменной не меняется при изменении самой переменной (в модели нет гетероскедастичности). Предположим, вы хотите предсказать преступление, и на входе у вас есть одна независимая переменная. У модели будет сомнительная гетероскедастичность, если предсказания были более точными для участков с низкими значениями медианы, нежели для участков с большим значением. Нулевая гипотеза для этого теста заключается в том, что модель является стационарной. Для 95% уровня надежности p-значение (вероятность) менее 0.05 означает статистически значимую гетероскедастичность и/или нестационарность. В случае, когда результаты теста являются статистически значимыми, проанализируйте стандартные ошибки и вероятности коэффициента надежности для оценки эффективности каждой независимой переменной.
Если модель согласована в географическом пространстве, то процессы, представленные независимыми переменными, ведут себя одинаково по всей области исследования (являются стационарными). Если модель согласована в пространстве данных, то разница в отношениях между предсказанными значениями и каждой независимой переменной не меняется при изменении самой переменной (в модели нет гетероскедастичности). Предположим, вы хотите предсказать преступление, и на входе у вас есть одна независимая переменная. У модели будет сомнительная гетероскедастичность, если предсказания были более точными для участков с низкими значениями медианы, нежели для участков с большим значением. Нулевая гипотеза для этого теста заключается в том, что модель является стационарной. Для 95% уровня надежности p-значение (вероятность) менее 0.05 означает статистически значимую гетероскедастичность и/или нестационарность. В случае, когда результаты теста являются статистически значимыми, проанализируйте стандартные ошибки и вероятности коэффициента надежности для оценки эффективности каждой независимой переменной. Регрессионные модели со статистически значимой нестационарностью зачастую являются отличными данными для анализа Географически взвешенной регрессии (GWR).Оценка стационарности: если критерий Кенкера статистически значимый (*), примите во внимание устойчивые вероятности, чтобы оценить, статистически значимые ваши независимые коэффициенты или нет.
Регрессионные модели со статистически значимой нестационарностью зачастую являются отличными данными для анализа Географически взвешенной регрессии (GWR).Оценка стационарности: если критерий Кенкера статистически значимый (*), примите во внимание устойчивые вероятности, чтобы оценить, статистически значимые ваши независимые коэффициенты или нет. - Оценка смещения модели. Статистика Жака-Бера показывает, являются ли невязки (полученные/известные зависимые переменные минус предсказанные/ожидаемые значения) нормально распределенными. Нулевая гипотеза для данного теста заключается в том, что невязки распределены нормально, поэтому, если вы построите для них гистограмму, она будет выглядеть как классическая колоколообразная кривая или Гауссово распределение. Когда p-значение (вероятность) для этого теста мала (например, менее 0.05 для 95% уровня надежности), невязки не распределены нормально, это значит, что модель смещена. Если у вас есть статистически значимая пространственная автокорреляция невязок (см.
 ниже), смещение может быть результатом ошибок спецификации модели (потеря ключевой переменной в модели). Результаты такой модели являются ненадежными. Статистически значимый тест Жака-Бера также может возникнуть, если вы пытаетесь смоделировать нелинейные отношения, а данные содержат значительные выбросы или сильно зависимы дисперсии от случайной величины.Оценка смещения модели.
ниже), смещение может быть результатом ошибок спецификации модели (потеря ключевой переменной в модели). Результаты такой модели являются ненадежными. Статистически значимый тест Жака-Бера также может возникнуть, если вы пытаетесь смоделировать нелинейные отношения, а данные содержат значительные выбросы или сильно зависимы дисперсии от случайной величины.Оценка смещения модели. - Оценка пространственной автокорреляции невязок. Всегда запускайте инструмент Пространственная автокорреляция (Индекс Морана I) для невязок регрессии, чтобы убедиться, что они пространственно случайны. Статистически значимая кластеризация высоких и/или низких невязок (пере- или недооценка модели) показывает, что в модели потеряна ключевая переменная (ошибка спецификации). Результаты МНК не могут быть достоверными в таком случае.Используйте инструмент Пространственная автокорреляция, чтобы убедиться, что данные о невязках модели не являются пространственно автокоррелированными.
- Наконец, обратитесь к разделу Почему не работает модель регрессии в документации Основы регрессионного анализа, чтобы убедиться, что ваша модель настроена соответствующим образом.
 Если возникают трудности при поиске правильной модели регрессии, инструмент Исследовательская регрессия может оказаться полезным. Замечания по интерпретации в конце сводного отчета МНК напоминают о цели каждого статистического теста и помогают найти решений, если ваша модель не проходит один или несколько диагностических проверок. Отчет о МНК включает замечания, которые помогают интерпретировать выходные данные.
Если возникают трудности при поиске правильной модели регрессии, инструмент Исследовательская регрессия может оказаться полезным. Замечания по интерпретации в конце сводного отчета МНК напоминают о цели каждого статистического теста и помогают найти решений, если ваша модель не проходит один или несколько диагностических проверок. Отчет о МНК включает замечания, которые помогают интерпретировать выходные данные.
(C) Если вы указали путь к дополнительному выходному файлу отчета, создается PDF-файл со всей информацией в сводном отчете и дополнительными графиками, позволяющими оценить вашу модель. На первой странице отчета представлены сведения о каждой независимой переменной. Как и в первом разделе сводного отчета (см. пункт 2 выше), вы используете эту информацию, чтобы определить, являются ли коэффициенты для каждой независимой переменной статистически значимыми и содержат ли ожидаемый знак (+/-). Если критерий Кенкера статистически значимый (см. пункт 4 выше), то можно доверять только устойчивым вероятностям, чтобы оценить, помогает ли переменная вашей модели или нет. Статистически значимые коэффициенты содержат знак звездочки (*) рядом со своими p-значениями для вероятностей и/или столбцов устойчивой вероятности. По информации на этой странице также можно определить, являются ли независимые переменные избыточными (проблемная мультиколлинеарность). Если теория не говорит иное, независимые переменные с большими значениями Фактора увеличения дисперсии (VIF) следует удалить по одной, пока значения VIF для всех оставшихся независимых переменных не будут меньше 7,5.
Статистически значимые коэффициенты содержат знак звездочки (*) рядом со своими p-значениями для вероятностей и/или столбцов устойчивой вероятности. По информации на этой странице также можно определить, являются ли независимые переменные избыточными (проблемная мультиколлинеарность). Если теория не говорит иное, независимые переменные с большими значениями Фактора увеличения дисперсии (VIF) следует удалить по одной, пока значения VIF для всех оставшихся независимых переменных не будут меньше 7,5.
Раздел 1 выходного отчета
В следующей разделе выходного файла отчета перечисляются результаты диагностических проверок МНК. На этой странице также представлены замечания по интерпретации, описывающие необходимость каждой проверки. Если ваша модель не проходит одну из этих проверок, в таблице типичных проблем с регрессией можно найти серьезность каждой проблемы и возможный путь ее устранения. Графики на остальных страницах отчета также помогают вам выявить и устранить проблемы с моделью.
Раздел 2 выходного отчета
В третьем разделе выходного файла отчета представлены гистограммы с распределением каждой переменной в модели, а также диаграммы рассеивания, показывающие отношения зависимой и независимой переменной. Если у вас возникают проблемы со смещением модели (это обозначается статистически значимым p-значением Жака-Бера), найдите в гистограммах распределения с асимметрией и попробуйте преобразовать эти переменные, чтобы увидеть, устраняет ли это смещение и улучшается ли производительность модели. Диаграммы рассеивания показывают, какие переменные являются лучшими предикторами. Используйте эти диаграммы рассеивания, чтобы проверить переменные на наличие нелинейных отношений. В некоторых случаях преобразование одной или нескольких переменных устраняет нелинейные отношения и смещение модели. Выбросы в данных также могут привести к получению смещенной модели. Проверьте гистограммы и диаграммы рассеивания на наличие таких данных или отношений. Попробуйте запустить модель с выбросами и без них, чтобы оценить, как они влияют на результаты. Вы можете обнаружить, что выброс – это некорректные данные (введенные или записанные с ошибкой) и сможете удалить связанный объект из набора данных. Если выброс отражает корректные данные и сильно влияет на результаты анализа, вы можете провести ваш анализ с выбросами и без них.
Вы можете обнаружить, что выброс – это некорректные данные (введенные или записанные с ошибкой) и сможете удалить связанный объект из набора данных. Если выброс отражает корректные данные и сильно влияет на результаты анализа, вы можете провести ваш анализ с выбросами и без них.
Раздел 3 выходного отчета
После получения правильно настроенной модели переоценки и недооценки будут отражать случайный шум. Если вам нужно создать гистограмму случайного шума, обычно это кривая с нормальным распределением (в виде колокола). Четвертый раздел выходного файла отчета представляет гистограмму переоценок и недооценок модели. Полосы на гистограмме отображают фактическое распределение, а синяя линия сверху диаграммы показывает форму, которую бы приняла гистограмма, если остатки имели нормальное распределение. Вряд ли вы получите идеальные результаты, поэтому следует проверить тест Жака-Бера, чтобы определить, является ли отклонение от нормального распределение статистически значимым или нет.
Раздел 4 выходного отчета
Диагностика Кенкера позволяет определить, меняются ли моделируемые отношения в изучаемой области (нестационарность) или зависят от величины переменной, которую вы пытаетесь предсказать (зависимость дисперсии от случайной величины). Географически взвешенная регрессия позволяет устранить проблемы с нестационарностью. На графике в разделе 5 файла выходного отчета будет показано, имеется ли проблема с зависимостью дисперсии от случайной величины. На диаграмме рассеивания (см. ниже) показано отношение остаточных и прогнозируемых значений модели. Предположим, вы моделируете частоту преступлений. Если на графике показана коническая форма с точкой слева и расширением справа от графика, это указывает на то, что ваша модель хорошо прогнозирует расположения с низкой частотой преступлений, и плохо прогнозирует расположения с высокой частотой преступлений.
Раздел 5 выходного отчета
На последней странице отчета показаны все настройки параметров, использованные при создании отчета.
(D) Изучите невязки модели в выходном классе объектов. Пере- и недооценки для правильно настроенной модели регрессии будут распределены случайно. Кластеризация переоценок и/или недооценок является доказательством того, что потеряна как минимум одна независимая переменная. Проверьте «рисунок» невязок модели, чтобы посмотреть, не говорит ли он о том, какие переменные могли быть утеряны. Иногда запуск инструмента Анализ горячих точек для нее может помочь определить более общие закономерности. Дополнительные стратегии для обработки неправильно определенной модели см. в разделе Что вам не говорят о регрессионном анализе.
Результат МНК: Картографическое представление невязок (E) Просмотрите таблицы коэффициентов и диагностики. Создавать их необязательно. Если вы находитесь в процессе поиска эффективной модели, можно обойтись без них. Но этот процесс итеративен, поэтому может быть перепробовано огромное количество моделей (с разными независимыми переменными) до тех пор, пока не будет найдена лучшая. Вы можете использовать Скорректированный информационный критерий Акаике в отчете, чтобы сравнить модели между собой. Модель с меньшим значением AICc лучше (то есть, наиболее точно отражает данные наблюдений).
Вы можете использовать Скорректированный информационный критерий Акаике в отчете, чтобы сравнить модели между собой. Модель с меньшим значением AICc лучше (то есть, наиболее точно отражает данные наблюдений).
Создание таблиц коэффициентов и диагностики для ваших итоговых моделей МНК позволяет фиксировать важные элементы отчета МНК. Таблица коэффициентов содержит список использованных в модели независимых переменных с их коэффициентами, стандартизированными коэффициентами, стандартными ошибками и вероятностями. Коэффициент представляет собой оценку того, насколько изменится зависимая переменная при изменении связанной с ней независимой переменной на 1 единицу. Единицы коэффициентов соответствуют независимым переменным. Если, например, у вас есть независимая переменная для общего количества населения, то и единица коэффициента для этой переменной будет отражать население; если другая независимая переменная будет для расстояния (в метрах) от железнодорожной станции, то единицы такого коэффициента будут отражать метры. Если эти коэффициенты конвертировать в среднеквадратические отклонения, то они будут называться стандартизированными коэффициентами. Стандартизированные коэффициенты могут использоваться для того, чтобы можно было сравнить силу влияния, которое имеют другие независимые переменные на зависимую переменную. Независимая переменная с наибольшим абсолютным значением стандартизированного коэффициента (т.е. после того, как вы отбросите знаки +/-) будет иметь наибольшую силу влияния на зависимую переменную. Следует иметь ввиду, что при интерпретации коэффициентов необходимо принимать в расчет стандартную ошибку. Стандартные ошибки указывают, насколько вероятно получить такие же коэффициенты при повторном отборе данных и перекалибровке модели множество раз. Большие значения стандартных ошибок для коэффициента означают, что в процессе повторов будет получен широкий диапазон возможных значений коэффициента; малые значения стандартных ошибок явно говорят о его постоянстве.
Если эти коэффициенты конвертировать в среднеквадратические отклонения, то они будут называться стандартизированными коэффициентами. Стандартизированные коэффициенты могут использоваться для того, чтобы можно было сравнить силу влияния, которое имеют другие независимые переменные на зависимую переменную. Независимая переменная с наибольшим абсолютным значением стандартизированного коэффициента (т.е. после того, как вы отбросите знаки +/-) будет иметь наибольшую силу влияния на зависимую переменную. Следует иметь ввиду, что при интерпретации коэффициентов необходимо принимать в расчет стандартную ошибку. Стандартные ошибки указывают, насколько вероятно получить такие же коэффициенты при повторном отборе данных и перекалибровке модели множество раз. Большие значения стандартных ошибок для коэффициента означают, что в процессе повторов будет получен широкий диапазон возможных значений коэффициента; малые значения стандартных ошибок явно говорят о его постоянстве.
Таблица диагностики содержит результаты для каждого теста, а также пояснения по интерпретации этих результатов.
Таблица диагностики включает заметки об интерпретации результатов теста диагностики модели.Дополнительные ресурсы
Существует целый ряд хороших ресурсов, которые помогут вам узнать больше о регрессии МНК на странице Ресурсы о пространственной статистике. Начните с чтения документации по Основам регрессионного анализа или просмотрите видео Regression Analysis Basics. Затем поработайте с обучающим руководством по Регрессионный анализ. Примените регрессионный анализ к собственным данным, изучите таблицу типичных проблем и статью Что вам не говорят о регрессионном анализе для поиска дополнительных стратегий. Если возникают трудности при поиске правильной модели регрессии, инструмент Исследовательская регрессия может оказаться полезным.
Интерпретация результатов инструмента Исследовательская регрессия—Справка
- Отчет
- 1. Лучшие модели по числу независимых переменных
- 2.
 Глобальная сводка исследовательской регрессии
Глобальная сводка исследовательской регрессии - 3. Сводка значимости переменных
- 4. Сводка мультиколлинеарности
- 5. Дополнительные сводные данные диагностики
- Таблица
- Дополнительные ресурсы
При запуске инструмента Исследовательская регрессия основным результатом является отчет. Отчет можно просмотреть в окне сообщений геообработки в фоновом режиме либо в окне Результаты. При необходимости также создается таблица, которая может помочь исследовать протестированные модели. Одна из целей отчета – показать, дают ли потенциальные независимые переменные правильные модели OLS. Если не удалось получить проходящие модели (модели, соответствующие всем указанным критериям после запуска инструмента Исследовательская регрессия, в отчете также будет показано, какие переменные являются согласованными предикторами, что позволяет определить, в каких диагностических тестах возникла ошибка. Стратегии по устранению проблем, связанных с каждым диагностическим тестом, указаны в документе Основы регрессионного анализа (см.
Отчет
В отчете инструмента Исследовательская регрессия пять разделов. Каждый из них описывается ниже.
1. Лучшие модели по числу независимых переменных
Первый набор сводных данных в отчете группируется по числу независимых переменных в проверенных моделях. Если указать число 1 для параметра Минимальное число независимых переменных (Minimum Number of Explanatory Variables) и значение 5 для параметра Максимальное число независимых переменных (Maximum Number of Explanatory Variables), в отчете будет 5 сводных разделов. В каждом из них указывается три модели с наибольшими скорректированными значениями R2, а также все проходящие модели. В каждом разделе также указаны диагностические значения для каждой модели: скорректированный информационный критерий Акаике – AICc, p-значение Жака-Бера – JB, стьюдентизированное Кенкером p-значение Бреуша-Пагана – K(BP), наибольший Фактор увеличения дисперсии – VIF, а также измерение пространственной автокорреляции отклонений (p-значение глобального индекса Морана I) – SA. Эти сводные сведения позволяют понять, как хорошо ваши модели прогнозируют данные (Adj R2) и проходят ли модели все указанные диагностические критерии. Если вы приняли все критерии поиска по умолчанию (параметры Минимальный допустимый скорректированный коэффициент детерминации (Minimum Acceptable Adj R Squared), Максимальный порог p-значения коэффициента (Maximum Coefficient p-value Cutoff), Максимальный порог значения VIF (Maximum VIF Value Cutoff), Минимально допустимое p-значение Жака-Бера (Minimum Acceptable Jarque Bera p-value) и Минимально допустимое p-значение пространственной автокорреляции (Minimum Acceptable Spatial Autocorrelation p-value)), все модели в списке Проходящие модели (Passing Models) будут правильными моделями OLS.
В каждом разделе также указаны диагностические значения для каждой модели: скорректированный информационный критерий Акаике – AICc, p-значение Жака-Бера – JB, стьюдентизированное Кенкером p-значение Бреуша-Пагана – K(BP), наибольший Фактор увеличения дисперсии – VIF, а также измерение пространственной автокорреляции отклонений (p-значение глобального индекса Морана I) – SA. Эти сводные сведения позволяют понять, как хорошо ваши модели прогнозируют данные (Adj R2) и проходят ли модели все указанные диагностические критерии. Если вы приняли все критерии поиска по умолчанию (параметры Минимальный допустимый скорректированный коэффициент детерминации (Minimum Acceptable Adj R Squared), Максимальный порог p-значения коэффициента (Maximum Coefficient p-value Cutoff), Максимальный порог значения VIF (Maximum VIF Value Cutoff), Минимально допустимое p-значение Жака-Бера (Minimum Acceptable Jarque Bera p-value) и Минимально допустимое p-значение пространственной автокорреляции (Minimum Acceptable Spatial Autocorrelation p-value)), все модели в списке Проходящие модели (Passing Models) будут правильными моделями OLS.
Если проходящих моделей нет, в остальном отчете все равно будет представлена полезная информация о переменных отношений, которая может помочь при принятии решений о дальнейших действиях.
2. Глобальная сводка исследовательской регрессии
Раздел Глобальная сводка исследовательской регрессии – это важное место для начала анализа, особенно если вы не нашли проходящие модели, так как в нем показано, почему модели не прошли проверки. В данном разделе перечислены пять диагностических тестов и процент моделей, прошедших каждый из них. Если проходящих моделей нет, эта информация позволит определить, в каком тесте возникают проблемы.
Часто неприятности возникают с тестом глобального индекса Морана I для пространственной автокорреляции (SA). Если у всех проверенных моделей есть невязки регрессии с пространственной автокорреляцией, чаще всего это указывает на отсутствие важных независимых переменных. Один из лучших способов узнать, отсутствуют ли независимые переменные – изучить карту невязок, созданную инструментом Регрессия методом наименьших квадратов (OLS). Выберите одну из моделей исследовательской регрессии, которая хорошо прошла все другие критерии (используйте списки наибольших значений скорректированных коэффициентов детерминации или выберите модель из дополнительной выходной таблицы) и запустите OLS с использованием этой модели. Выходные данные инструмента Регрессия методом наименьших квадратов (OLS) – это карта невязок модели. Изучите невязки модели, чтобы получить сведения о недостающих данных. Попробуйте сформировать наибольшее число потенциальных пространственных переменных, таких как расстояние до центра города, больниц и других географических объектов. Попробуйте использовать переменные пространственного режима. Например, если все недооценки расположены в сельских областях, создайте бинарную переменную и посмотрите, улучшатся ли результаты регрессионного анализа.
Выберите одну из моделей исследовательской регрессии, которая хорошо прошла все другие критерии (используйте списки наибольших значений скорректированных коэффициентов детерминации или выберите модель из дополнительной выходной таблицы) и запустите OLS с использованием этой модели. Выходные данные инструмента Регрессия методом наименьших квадратов (OLS) – это карта невязок модели. Изучите невязки модели, чтобы получить сведения о недостающих данных. Попробуйте сформировать наибольшее число потенциальных пространственных переменных, таких как расстояние до центра города, больниц и других географических объектов. Попробуйте использовать переменные пространственного режима. Например, если все недооценки расположены в сельских областях, создайте бинарную переменную и посмотрите, улучшатся ли результаты регрессионного анализа.
Другой диагностический тест, которые вызывает проблемы – это тест Жака-Бера для невязок с нормальным распределением. Если ни одна из моделей не проходит тест Жака-Бера (JB), налицо проблема со смещением модели. Распространенные причины смещения модели:
Распространенные причины смещения модели:
- Нелинейные отношения
- Выбросы данных
При просмотре матрицы рассеивания возможных независимых значений по отношению к зависимой переменной, вы увидите, имеет ли место одна из этих проблем. Дополнительные стратегии описаны в документе Основы регрессионного анализа. Если модели не проходят тест пространственной автокорреляции (SA), исправьте сначала эти проблемы. Смещение может быть вызвано отсутствием важных независимых переменных.
3. Сводка значимости переменных
В разделе Сводка значимости переменных (Summary of Variable Significance) представлены сведения об отношениях переменных и их согласованности. В нем указана каждая потенциальная независимая переменная с отношением количества раз, когда она была статистически значимой. У первых нескольких переменных в списке самые большие значения столбца % Significant. Вы также можете увидеть стабильность отношений переменных, изучив столбцы % Negative и % Positive. Сильные предикторы будут постоянно значимы (% Significant), а отношения будут стабильными (в основном отрицательными или в основном положительными).
Сильные предикторы будут постоянно значимы (% Significant), а отношения будут стабильными (в основном отрицательными или в основном положительными).
Эта часть отчета также позволяет повысить эффективность модели. Это особенно важно при работе с множеством возможных независимых значений (больше 50) и использовании моделей с пятью или большим числом предикторов. При наличии большого числа независимых переменных и проверке многих комбинаций, вычисления могут занять длительное время. В некоторых случаях, фактически, инструмент не закончит работу из-за ошибок памяти. Рекомендуется постепенно увеличить число проверяемых моделей: начните с установки для параметров Минимальное число независимых переменных (Minimum Number of Explanatory Variables) и Максимальное число независимых переменных (Maximum Number of Explanatory Variables) значение 2, затем 3, затем 4 и т. д. С каждым запуском удаляются переменные, которые редко являются статистически значимыми для проверяемых моделей. В разделе Сводка значимости переменных (Summary of Variable Significance) вы сможете найти эти переменные, а также сильные предикторы. Удаление даже одной потенциальной независимой переменной из списка может значительно сократить время работы инструмента Исследовательская регрессия.
Удаление даже одной потенциальной независимой переменной из списка может значительно сократить время работы инструмента Исследовательская регрессия.
4. Сводка мультиколлинеарности
Раздел отчета Сводка мультиколлинеарности (Summary of Multicollinearity) можно использовать вместе с разделом Сводка значимости переменных (Summary of Variable Significance) для определения того, какие потенциальные независимые переменные можно удалить из анализа для улучшения производительности. Раздел Сводка мультиколлинеарности (Summary of Multicollinearity) позволяет узнать, сколько раз каждая независимая переменная была включена в модель с высокой степенью мультиколлинеарности, а также узнать другие независимые переменные, также включенные в эти модели. Если две (или более) независимых переменных часто обнаруживаются в моделях с высокой мультиколлинеарностью, эти переменные могут описывать один и тот же аспект явления. Так как требуется включать только переменные, которые описывают уникальный аспект зависимой переменной, можно выбрать только одну из избыточных переменных для дальнейшего анализа. Можно выбрать самую полезную переменную в разделе Сводка значимости переменных (Summary of Variable Significance).
Можно выбрать самую полезную переменную в разделе Сводка значимости переменных (Summary of Variable Significance).
5. Дополнительные сводные данные диагностики
Конечные сводные данные диагностики отображают наибольшие p-значения Жака-Бера (Сводка нормальности остатков (Summary of Residual Normality)) и наибольшие p-значения глобального индекса Морана I (Сводка пространственной автокорреляции остатков (Summary of Residual Autocorrelation)). Чтобы пройти эти диагностические тесты, необходимы большие p-значения.
Эти сводные данные не слишком полезны, если модели проходят тест Жака-Бера и тест пространственной автокорреляции (глобальный индекс Морана I), так как если критерий статистической значимости равен 0,1, все модели со значениями более 0,1 также будут проходящими. Но эти сводные данные полезны, если у вас нет проходящих моделей, и вы хотите узнать, насколько вы далеки от нормально распределенных невязок или невязок без статистически значимой пространственной автокорреляции. Например, если p-значения для сводки Жака-Бера равны 0,000000, ясно, что вы очень далеки от нормально распределенных невязок. Или же, если p-значения равны 0,092, то вы близки к нормально распределенным невязкам (к слову, в зависимости от выбранного уровня значимости p-значение 0,092 может быть достаточным). Эти сводные данные демонстрируют, насколько серьезна проблема, и, если ни одна из моделей не является проходящей, какие переменные, связанные с моделями, хотя бы близки к прохождению тестов.
Например, если p-значения для сводки Жака-Бера равны 0,000000, ясно, что вы очень далеки от нормально распределенных невязок. Или же, если p-значения равны 0,092, то вы близки к нормально распределенным невязкам (к слову, в зависимости от выбранного уровня значимости p-значение 0,092 может быть достаточным). Эти сводные данные демонстрируют, насколько серьезна проблема, и, если ни одна из моделей не является проходящей, какие переменные, связанные с моделями, хотя бы близки к прохождению тестов.
Таблица
Если указано значение для параметра Выходная таблица результатов (Output Results Table), будет создана таблица со всеми моделями, соответствующими критериям Максимальный порог p-значения коэффициента (Maximum Coefficient p-value Cutoff) и Максимальный порог значения VIF (Maximum VIF Value Cutoff). Даже если проходящих моделей нет, существует вероятность того, что в выходной таблице будут какие-то модели. Каждая строка в таблице представляет модель, соответствующую критериям коэффициентов и значений VIF. Столбцы в таблице описывают диагностические тесты и независимые переменные модели. Диагностические данные: скорректированный коэффициент детерминации (R2), скорректированный информационный критерий Акаике – AICc, p-значение Жака-Бера – JB, стьюдентизированное Кенкером p-значение Бреуша-Пагана – K(BP), наибольший Фактор увеличения дисперсии – VIF, а также p-значение глобального индекса Морана I – SA. Вы можете отсортировать модели по их значениям AICc. Чем меньше значение AICc, тем лучше работает модель. Вы можете отсортировать значения AICc в ArcMap, дважды щелкнув столбец AICc. Если вы выбираете модель для применения в анализе OLS (для изучения невязок), то помните о том, что нужно выбрать модель с малым значением AICc и проходящими значениями для максимального числа других диагностических данных. Например, если вы изучили выходной отчет и поняли, что тест Жака-Бера вызвал проблемы, ищите модель с наименьшим значением AICc, которая соответствует всем критериям, кроме Жака-Бера.
Столбцы в таблице описывают диагностические тесты и независимые переменные модели. Диагностические данные: скорректированный коэффициент детерминации (R2), скорректированный информационный критерий Акаике – AICc, p-значение Жака-Бера – JB, стьюдентизированное Кенкером p-значение Бреуша-Пагана – K(BP), наибольший Фактор увеличения дисперсии – VIF, а также p-значение глобального индекса Морана I – SA. Вы можете отсортировать модели по их значениям AICc. Чем меньше значение AICc, тем лучше работает модель. Вы можете отсортировать значения AICc в ArcMap, дважды щелкнув столбец AICc. Если вы выбираете модель для применения в анализе OLS (для изучения невязок), то помните о том, что нужно выбрать модель с малым значением AICc и проходящими значениями для максимального числа других диагностических данных. Например, если вы изучили выходной отчет и поняли, что тест Жака-Бера вызвал проблемы, ищите модель с наименьшим значением AICc, которая соответствует всем критериям, кроме Жака-Бера.
Дополнительные ресурсы
Если у вас нет опыта регрессионного анализа в ArcGIS, настоятельно рекомендуем просмотреть бесплатный семинар по регрессии Esri Virtual Campus, а затем запустить Руководство по регрессионному анализу перед использованием инструмента Исследовательская регрессия.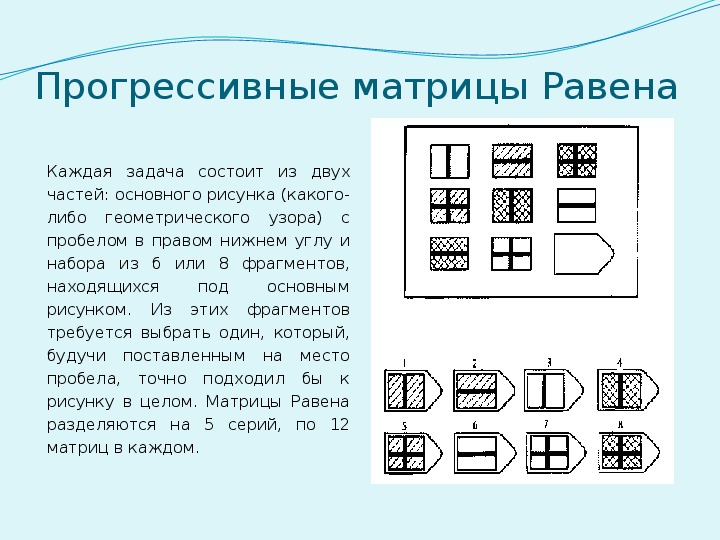
Возможно, вы также захотите просмотреть следующие разделы:
- Более подробно о работе инструмента Исследовательская регрессия
- Что вам не говорят о регрессионном анализе
- Основы регрессионного анализа
Burnham, K.P. and D.R. Anderson. 2002. Model Selection and Multimodel Inference: a practical information-theoretic approach, 2nd Edition. New York: Springer. Section 1.5.
Кроме того, на странице ресурсов по пространственной статистике можно найти новые видео, учебные пособия и другие материалы.
Интерпретация — определение, значение и синонимы
ПЕРЕЙТИ К СОДЕРЖАНИЮ
Другие формы: интерпретации
Когда ваша любимая группа делает кавер на классическую мелодию, их версия — это их интерпретация — их перевод — музыки. Он лучше оригинала? Это для интерпретации .
Интерпретация — это действие по объяснению, переформулированию или иному показу собственного понимания чего-либо.
Определения толкования
-
существительное
акт интерпретации чего-либо, выраженный в художественном исполнении
-
синонимы:
рендеринг, рендеринг
-
существительное
объяснение, которое следует из интерпретации чего-либо
«отчет включал его интерпретация судебных доказательств»
-
существительное
«Эдикт подвергся многим интерпретации ”
-
синонимы:
интерпретация, рендеринг, исполнение
-
существительное
мысленное представление значения или значения чего-либо
-
синонимы:
чтение, версия
ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ: Эти примеры предложений появляются в различных источниках новостей и книгах, чтобы отразить использование слова «интерпретация» .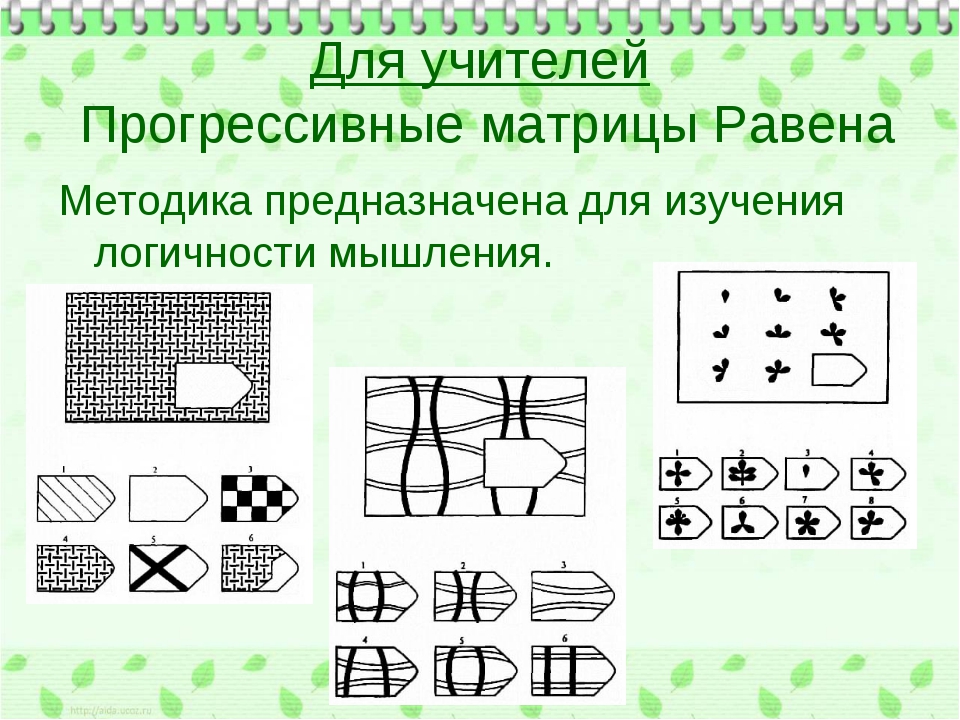 Мнения, выраженные в примерах, не отражают мнение Vocabulary.com или его редакции.
Отправьте нам отзыв
Мнения, выраженные в примерах, не отражают мнение Vocabulary.com или его редакции.
Отправьте нам отзыв
ВЫБОР РЕДАКЦИИ
Посмотрите
интерпретацию в последний разЗакройте пробелы в словарном запасе с помощью персонализированного обучения, которое фокусируется на обучении слова, которые нужно знать.
Начните изучение словарного запаса
Независимо от того, являетесь ли вы учителем или учеником, Vocabulary.com может направить вас или ваш класс на путь систематического улучшения словарного запаса.
НачатьИнтерпретация Определение и значение – Merriam-Webster
интерпретация in-ˌtər-prə-ˈtā-shən
-pə-
1
: действие или результат интерпретации : объяснение
2
: особая адаптация или версия произведения, метода или стиля метод обучения который сочетает в себе фактическую информацию со стимулирующей пояснительной информацией
программа интерпретации естественной истории
интерпретационный
ин-ˌtər-prə-ˈtā-sh(ə-)nəl
-pə-
прилагательное
интерпретирующий
in-ˈtər-prə-ˌtā-tiv
также -prə-tə-tiv
прилагательное
интерпретативный наречие
интерпретирующий
in-ˈtər-prə-tiv-pə-
прилагательное
по интерпретации наречие
Синонимы
- уточнение
- строительство
- разъяснение
- толкование
- объяснение
- пояснение
- экспозиция
- освещение
- иллюстрация
- дорожная карта
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
буквальная интерпретация 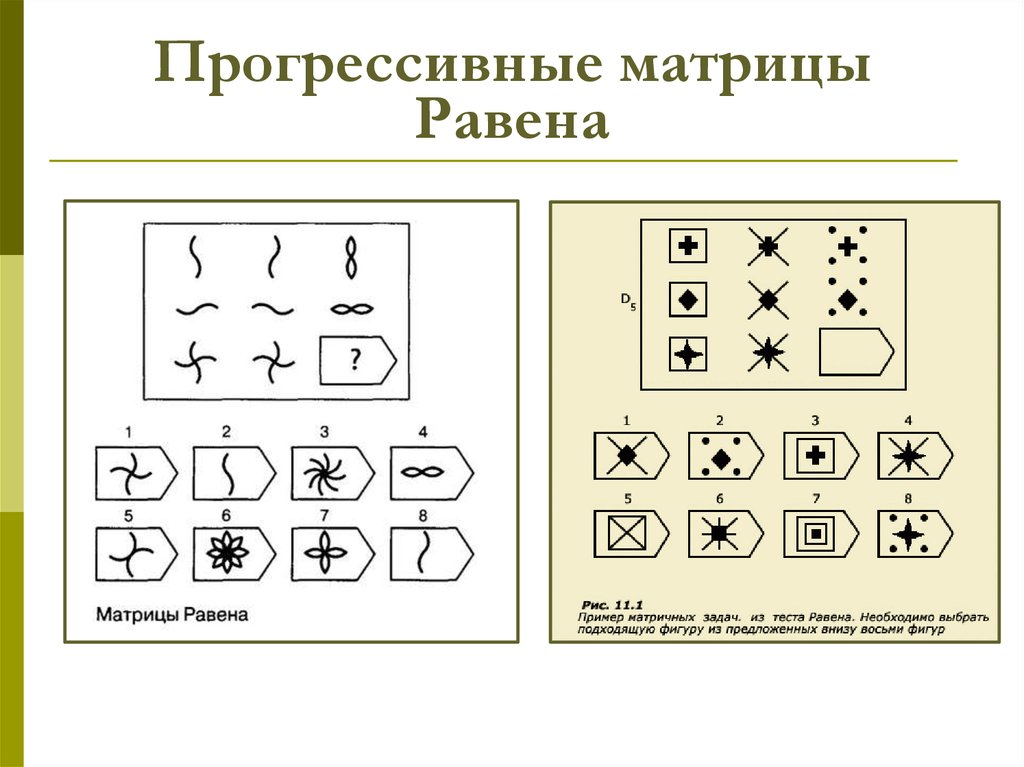 Его замечания нуждаются в дальнейшем толковании .
актерская интерпретация роли Гамлета
Его замечания нуждаются в дальнейшем толковании .
актерская интерпретация роли Гамлета
Недавние примеры в Интернете Но Республиканская партия полностью присоединилась к широкой интерпретации Второй поправки, и межпартийный раскол может расти — промежуточные выборы 2022 года были первыми за 25 лет, когда NRA не дала ни одному кандидату от демократов высокий рейтинг. — Юлиан Зелизер, 9 лет.0067 CNN
, 1 апреля 2023 г. Но компании покинули телеконференцию с совершенно разными интерпретациями того, что было сказано, по словам четырех человек, знакомых с переговорами, и документа, просмотренного The New York Times. — Чан Че, New York Times , 29 марта 2023 г.
Не все согласны с этой интерпретацией .
— Деннис Пиллион | [email protected], al , 27 марта 2023 г.
У разных людей разные интерпретации этого.
— Гэри Баум, The Hollywood Reporter
— Чан Че, New York Times , 29 марта 2023 г.
Не все согласны с этой интерпретацией .
— Деннис Пиллион | [email protected], al , 27 марта 2023 г.
У разных людей разные интерпретации этого.
— Гэри Баум, The Hollywood Reporter 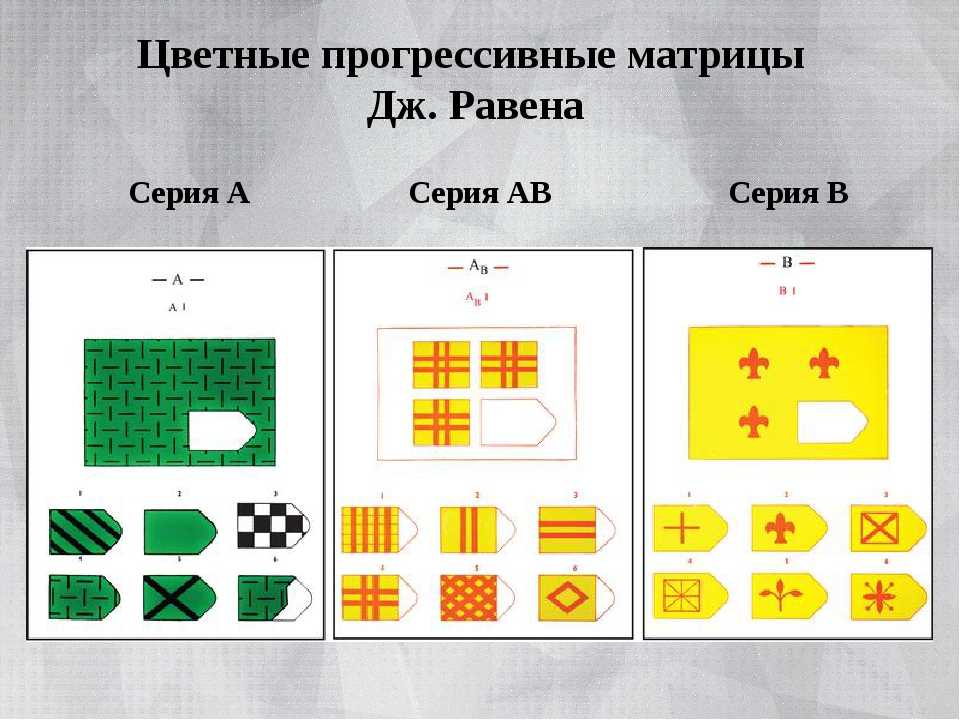 Вдохновленный этим — и тем, как солнечный свет отражается от поверхности озера — Кума создает единый образ с двумя совершенно разными интерпретаций блеска.
— Дайанна Маццоне, Allure , 16 марта 2023 г.
В результате небольшие изменения в изображении, невидимые для людей, могут привести к совершенно иным (а иногда и странным) интерпретациям алгоритма машинного обучения.
— IEEE Spectrum , 14 марта 2023 г.
Узнать больше
Вдохновленный этим — и тем, как солнечный свет отражается от поверхности озера — Кума создает единый образ с двумя совершенно разными интерпретаций блеска.
— Дайанна Маццоне, Allure , 16 марта 2023 г.
В результате небольшие изменения в изображении, невидимые для людей, могут привести к совершенно иным (а иногда и странным) интерпретациям алгоритма машинного обучения.
— IEEE Spectrum , 14 марта 2023 г.
Узнать больше
Эти примеры программно скомпилированы из различных онлайн-источников, чтобы проиллюстрировать текущее использование слова «интерпретация».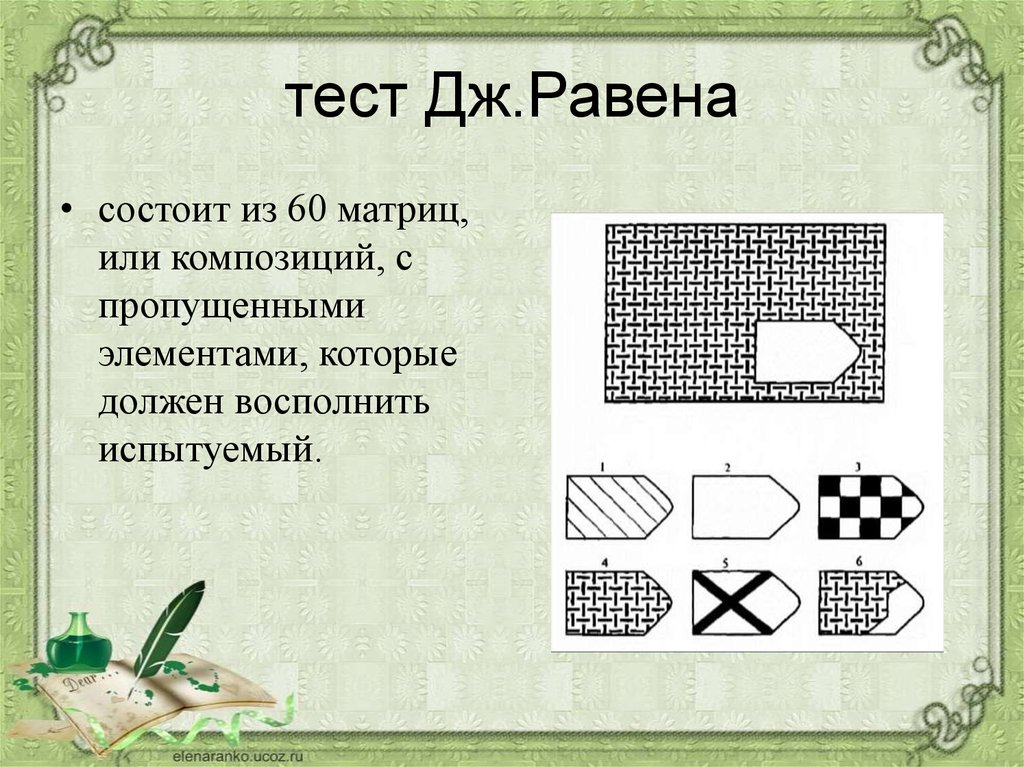 Любые мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв об этих примерах.
Любые мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв об этих примерах.
История слов
Первое известное использование
14 век, в значении, определенном в смысле 1
Путешественник во времени
Первое известное использование интерпретации было в 14 веке
Посмотреть другие слова из того же века интерпретировать
интерпретация
оговорка о толковании
Посмотреть другие записи поблизости
Процитировать эту запись «Интерпретация».
Словарь Merriam-Webster. com , Merriam-Webster, https://www.merriam-webster.com/dictionary/interpretation. По состоянию на 19 апреля 2023 г.
com , Merriam-Webster, https://www.merriam-webster.com/dictionary/interpretation. По состоянию на 19 апреля 2023 г. Копия цитирования
Детское определение
Интерпретация
существительное
интерпретация in-ˌtər-prə-tā-shən
1
: действие или результат интерпретации : объяснение
2
: экземпляр художественной интерпретации в исполнении или адаптации
интерпретирующий
-ˈtər-prə-ˌtāt-iv
прилагательное
с интерпретацией наречие
Медицинское определение
интерпретация
существительное
интерпретация ин-ˌtər-prə-ˈtā-shən, -pə-
: действие или результат объяснения чего-либо
интерпретация симптомов болезни
особенности : объяснение в понятной форме пациенту в психотерапии более глубокого смысла в соответствии с психологической теорией материала, связанного с поведением пациента во время лечения
интерпретировать
in-ˈtər-prət, -pət
переходный глагол
интерпретирующий
-prət-iv, -pət-
прилагательное
или толкование
-prə-ˌtāt-iv -prət-ət-iv
Legal Definition
толкование
существительное
интерпретация ин-ˌtər-prə-ˈtā-shən
: действие или результат интерпретации
сравнение конструкции
интерпретирующий
ин-ˈtər-prə-ˌtā-tiv, -tə-tiv
прилагательное
интерпретирующий
in-ˈtər-prə-tiv
прилагательное
Еще от Merriam-Webster о переводе
Нглиш: перевод устный перевод для говорящих на испанском языке
Britannica English: перевод устный перевод для говорящих на арабском языке
Последнее обновление: — Определение пересмотрено
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
Можете ли вы решить 4 слова сразу?
Можете ли вы решить 4 слова сразу?
подпояс
См.