
Нереферентная группа: 54.Референтные и нереферентные группы. Понятие коллектива.
Группа. Межличностные отношения в группе. (стр. 1 из 3)
Группа. Межличностные отношения в группе
Понятие о социальной группе. Классификация групп
Группа — ограниченная в размерах общность людей, выделяемая из социального целого на основе определенных признаков (характера выполняемой деятельности, структуры, уровня развития и т.д.)
Рассмотрим одну из наиболее распространенных классификаций групп.
По размеру
Большая группа (условная) – количественно неограниченная условная общность людей, выделяемая на основе определенных социальных признаков (пол, возраст, национальность и т.п.)
Большая группа (реальная) – значительная по размерам и сложно организованная общность людей, вовлеченных в ту или иную общественную деятельность (например, коллектив вуза, предприятия и т.д.)
Малая группа – (от двух до нескольких десятков человек) относительно небольшое число непосредственно контактирующих индивидов, объединенных общими целями и задачами.
По общественному статусу
Формальная (официальная) группа – реальная или условная социальная общность, имеющая юридически фиксированный статус, члены которой в условиях общественного разделения труда объединены социально заданной деятельностью, организующей их труд.
Формальные группы всегда имеют определенную нормативно закрепленную структуру, назначенное или избранное руководство, нормативно закрепленные права и обязанности ее членов.
Неформальная (неофициальная) группа – реальная социальная общность, не имеющая юридически фиксированного статуса, добровольно объединенная на основе интересов, дружбы и симпатий.
Группы неформальные могут выступать как изолированные общности или складываться внутри формальных групп.
По непосредственности взаимосвязей
Условная группа – объединенная по определенному признаку (характер деятельности, пол, возраст и т.д.)
Реальная группа – это объединение, где люди связанны реальными контактами (например, группа однокурсников).
По личностной значимости
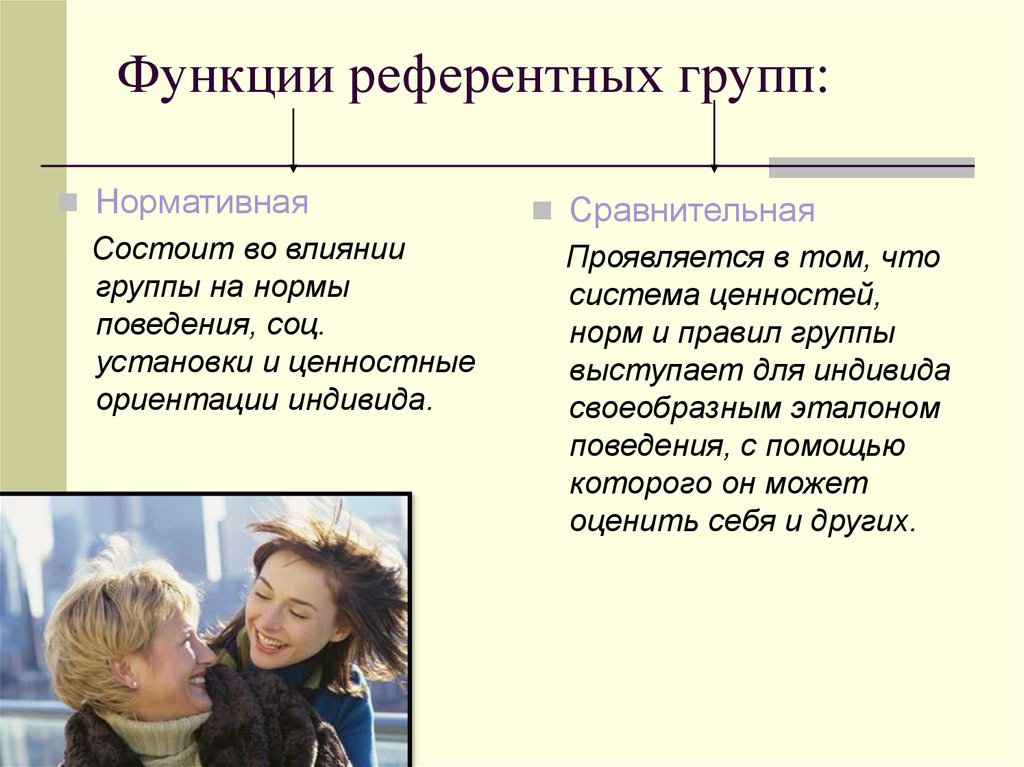
Референтная группа – реальная или условная социальная общность, с которой индивид соотносит себя и на нормы, мнения, ценности и оценки которой он ориентируется в своем поведении и самооценке.
Нереферентная группа – это группа, психология и поведение которой чужды или безразличны для человека.
Антиреферентная группа – это группа, поведение и психологию членов которой человек не приемлет, осуждает и отвергает.
По уровню развития
Низкий уровень
Диффузная группа – это общность, в которой отсутствует сплоченность как ценностно-ориентационное единство, нет совместной деятельности, способной опосредовать отношения ее участников.
Ассоциация – группа, в которой отсутствуют объединяющая ее совместная деятельность, организация и управление, а ценностные ориентации, опосредующие межличностные отношения, проявляются в условиях группового общения.
В зависимости от общественной направленности опосредующих факторов различают просоциальные ассоциации и асоциальные ассоциации.
Просоциальнальные ассоциации – это группы, в которые позитивные нравственные ценности привнесены из широкой социальной среды, сформированы и упрочены в процессе трудовой деятельности. В случае включения этих ассоциаций в совместную деятельность, обусловленную общественно значимыми задачами и соответствующей им организацией и руководством, они проходят путь коллективообразования. Например, студенческая группа в начале процесса обучения.
Асоциальные ассоциации – это группы, ценностные ориентации которых имеют негативный, иногда антиобщественный характер. Например, группа агрессивно настроенных подростков. Эти группы, в условиях антиобщественно направленной организации и руководства, легко превращаются в асоциальные корпорации.
Корпорация просоциальная – это организованная группа, характеризующаяся замкнутостью и максимальной централизацией. Например, промышленные корпорации.
Корпорация асоциальная (антиобщественная) – это группа, противопоставляющая себя другим социальным общностям на основе своих узко индивидуалистических интересов. Межличностные отношения в корпорациях опосредуются асоциальными, а зачастую антисоциальными ценностными ориентациями. Например, группа рэкетиров или мафия.
Межличностные отношения в корпорациях опосредуются асоциальными, а зачастую антисоциальными ценностными ориентациями. Например, группа рэкетиров или мафия.
Высокий уровень
Коллектив – группа объединенных общими целями и задачами людей, достигшая в процессе социально ценной совместной деятельности высокого уровня развития. В коллективе формируется особый тип межличностных отношений, характеризующийся высокой сплоченностью как ценностно-ориентационным единством, коллективистической идентификацией и т.д.
Особенности зрелого коллектива
Ценности и цели коллектива и личности совпадают, жизнь коллектива насыщена социально-полезной, совершенствующей деятельностью
Каждый член коллектива видит перспективы движений и проявляет личную заинтересованность в его развитии.
Товарищеское равноправие его членов, каждый член коллектива участвует в организации отдельных сторон его жизнедеятельности.
Личность защищена коллективом и ответственна перед ним.
Группа и ее структурная организация
Проблема группы, как важнейшей формы социального объединения людей в процессе совместной деятельности и общения – одна из центральных в психологии.
Малая социальная группа – это немногочисленная по составу группа, члены которой объедены общей целью деятельности и находятся в непосредственном личном контакте (общении), что является основой для возникновения и развития группы как целого.
Основные параметры, с помощью которых возможен социально-психологический анализ группы – это характеристики собственно группы и характеристики, определяющие положения человека в группе.
К характеристике группы относятся ее композиция, структура и групповые процессы.
К характеристикам, определяющим положения человека в группе, относятся система групповых ожиданий, статусов и ролей членов группы.
Композиция группы, или ее состав – это совокупность характеристик членов группы, важных с точки зрения анализа группы как целого. Например, численность группы, ее возрастной или половой состав, национальность и т.д.
Структура малой группы рассматривается с точки зрения тех функций, которые выполняют ее отдельные члены, а также с точки зрения межличностных отношений в ней.
Структура социальной власти в малой группе
Группа представляет собой чрезвычайно сложный организм, активность которого разворачивается одновременно во многих направлениях и требует особых усилий по сохранению целенаправленности групповых усилий, объединения индивидуальных активностей в единое целое.
Структура социальной власти в малой группе – это система взаиморасположений членов группы в зависимости от их способности оказывать влияние в группе. Социальная власть в группе может осуществляться в различных формах, среди которых наиболее изучены феномены лидерства и руководства.
Руководство – процесс управления группой, осуществляемый руководителем или посредником между социальной властью и членами общности на основе правовых полномочий и норм, данных ему[1].
Руководитель – лицо, на которое официально возложены функции управления коллективом и организации его деятельности.
Руководитель группы должен обладать рядом качеств, среди которых первостепенными являются высокая деловая активность, гибкость мышления, адаптируемость к изменяющимся условиям, коммуникативная культура и т. п.
п.
Основным инструментом психологического влияния руководителя на группу является его авторитет.
Стиль руководства (управления) коллективом – это интегральная характеристика индивидуальных особенностей личности руководителя, а также чаще всего применяемых ею способов и средств управленческой деятельности, которые характеризуют способности и особенности решения управленческих задач.
В научной литературе описан широкий спектр стилей управления современного руководителя. Наибольшее распространение получили такие стили, как авторитарный (доминирующий), демократический (коллегиальный) и либеральный (попустительский).
Стили руководства
Авторитарный. Характеризуется единоличным принятием всех решений, субъективной оценкой результатов деятельности, устранением подчиненных от участия в решении вопросов и подавлением их инициативы и творчества. За счет постоянного контроля обеспечиваются приемлемые результаты работы. Неудовлетворенность людей своей работой, положением в коллективе, неблагоприятным психологическим климатом ведет к постоянным стрессам, влияющим на психологическое и физическое здоровье.
Демократический. Управленческие решения принимаются на основе обсуждения проблем, учета мнения, интересов, потребностей подчиненных. Выполнение принятых решений контролируется руководителем и сотрудниками.
Данный стиль управления является эффективным, т.к. обеспечивает высокую продуктивность, активность сотрудников и сплоченность коллектива. Его реализация возможна при высоких интеллектуальных, организаторских, психологических и коммуникативных способностях руководителя.
Либеральный. Характеризуется, с одной стороны, «максимумом демократий», а с другой – «минимумом контроля». Подчиненные сами решают возникшие перед ними проблемы, не особенно считаясь с мнением своего руководителя, поэтому результаты работы низкие. Неудовлетворенность результатами своей деятельности, руководителем, климатом в группе ведут к скрытым или явным конфликтам.
Лидерство – это спонтанно возникающее внутри группы психологическое влияние одного члена группы на других.
Лидер – член группы, за которым она признает право принимать ответственные решения в значимых для нее ситуациях, т. е. наиболее авторитетная личность, реально играющая центральную роль в организации совместной деятельности и регулировании взаимоотношений в группе.
е. наиболее авторитетная личность, реально играющая центральную роль в организации совместной деятельности и регулировании взаимоотношений в группе.
Глава 2 Группы. Общая психология
Глава 2 Группы
2.1. Группы и их виды
Личность человека раскрывается через особенности его общения с другими людьми, его принадлежность к тем или иным социальным группам. Все социальные группы можно разделить на большие и малые.
Большие группы – государства, нации, народы, партии, классы, а также целый ряд профессиональных, экономических, культурных, образовательных общностей.
Малая группа – немногочисленное объединение людей (от двух до 20–30 человек), объединенных общей деятельностью и находящихся в прямом контакте друг с другом.
Именно в процессе взаимодействия в малых группах человек проводит большую часть своей жизни. Примерами малых групп являются семья, учебная группа, трудовой коллектив, объединение друзей и т.п.
В качестве признаков малой группы называют:
– наличие постоянной цели деятельности;
– наличие организующего начала в группе – лидера, начальника;
– разделение персональных ролей, играемых каждым членом группы;
– наличие эмоциональных отношений между членами группы;
– выработка групповых норм, правил и стандартов поведения, характерных для группы.
Рассмотрим классификацию малых групп.
1. Первичные и вторичные группы.
Первичные группы – группы, в которых взаимодействие людей основывается на непосредственной эмоциональной близости (круг близких друзей, семья).
Вторичные группы характеризуются безличным, строго официальным взаимодействием ее членов (производственная группа).
2. Формальные и неформальные.
Формальные группы характеризуются четко заданной групповой структурой, системой управления.
Неформальные группы характеризуются отсутствием предписанной системы управления, четкой структуры группы.
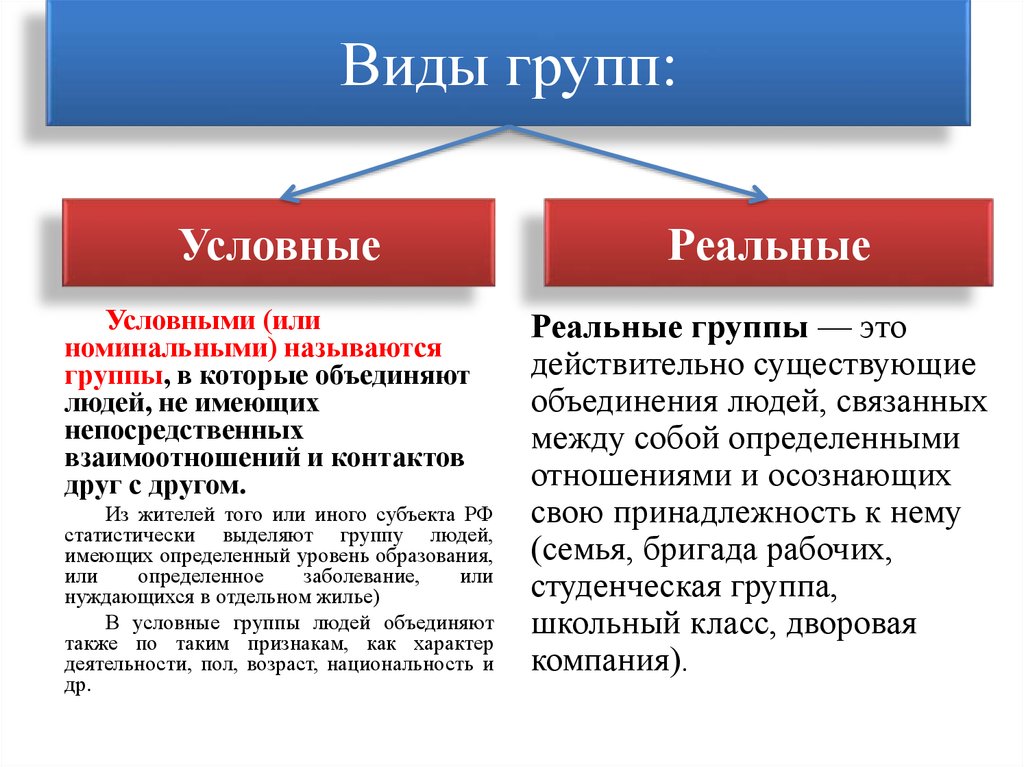
3. Условные и реальные.
Реальные группы – действительно существующие группы.
Условные (номинальные) группы объединяют людей, реально не взаимодействующих в рамках одной группы. Условные группы применяют в исследовательских целях для сравнения результатов, полученных в реальных группах, и результатов, полученных у случайного объединения людей, не имеющих постоянных контактов друг с другом и общей цели.
4. Естественные и лабораторные.
Естественные группы складываются сами по себе, независимо от воли экспериментатора.
Лабораторные группы специально создаются экспериментатором с целью проведения какого-либо исследования.
5. Просоциальные и асоциальные.
Просоциальные группы – группы, участники которых трудятся на благо общества, разделяют общие культурные и духовные ценности.
Асоциальные группы руководствуются в своих действиях аморальными взглядами и антиобщественными установками; обычно такие группы приносят вред обществу.
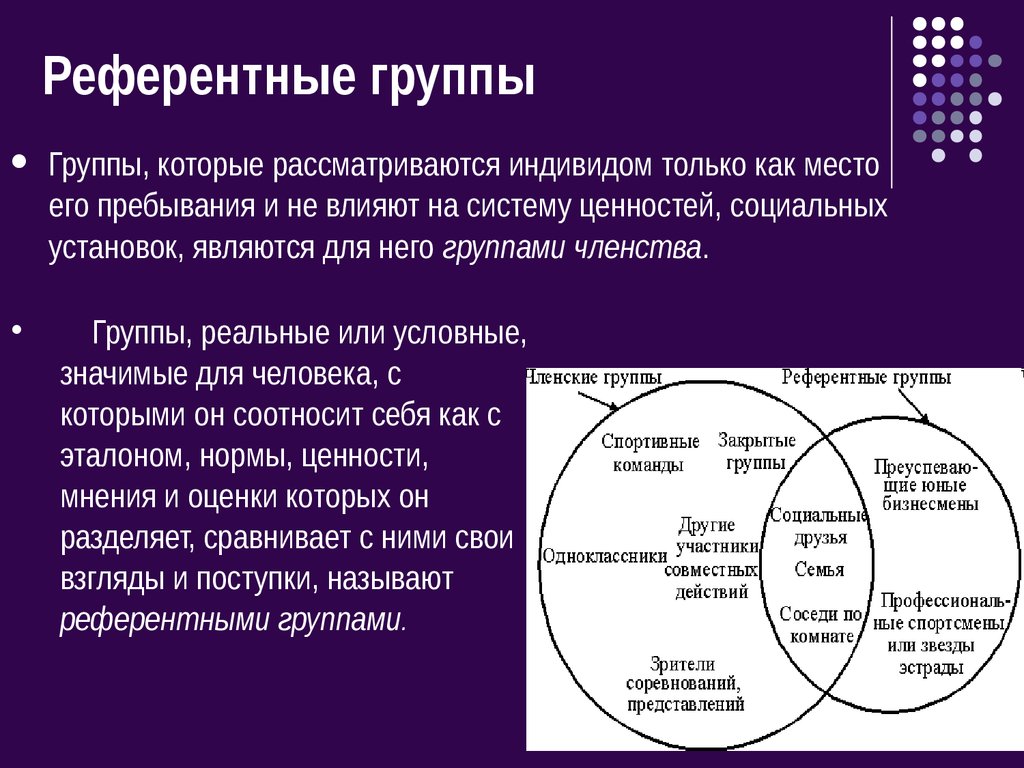
6. Референтные и нереферентные.
Референтная группа – та малая группа, к которой человек себя причисляет или членом которой он хотел бы стать. В этом случае группа в целом и ее отдельные участники становятся объектами подражания для человека. Референтные группы могут быть как реальными (в случае действительно наличествующей принадлежности человека к группе), так и воображаемыми (при желании попасть в некий «идеальный» коллектив).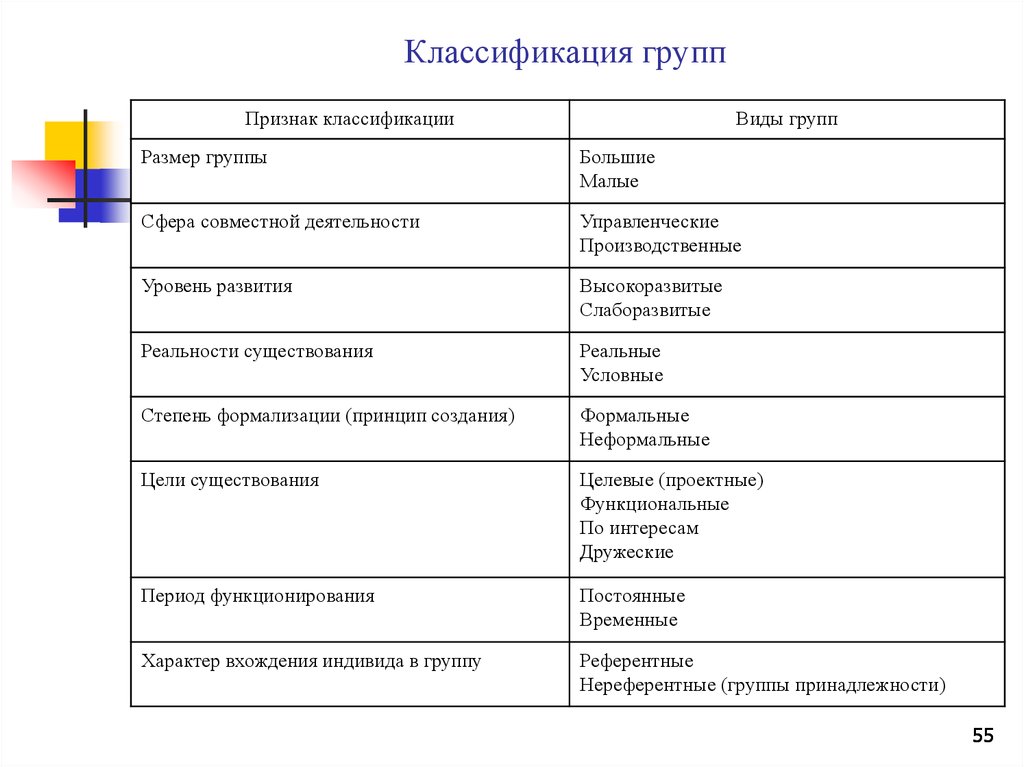
Нереферентная группа – такая группа, психология и поведение которой безразличны для человека. Разновидностью такой группы можно считать и антиреферентную группу, поведение и психологию членов которой человек не приемлет, осуждает и отвергает.
7. Высокоразвитые и слаборазвитые.
Слаборазвитые группы характеризуются отсутствием общности, налаженных взаимоотношений, четкого распределения обязанностей, эффективной работы.
Высокоразвитые группы, напротив, обладают вышеназванными факторами. Примером высокоразвитой группы является коллектив. Коллектив – группа людей, связанных устойчивой, совместной деятельностью, которая предполагает наличие единых целей, четкой структуры организации и управления.
Основными признаками коллектива являются:
– эффективное выполнение возложенных на группу задач;
– добровольный характер объединения людей;
– хорошие отношения между членами группы;
– целостность организационной структуры, четкое распределение рабочих функций, наличие структуры управления;
– наличие возможностей для личностного развития каждого члена группы.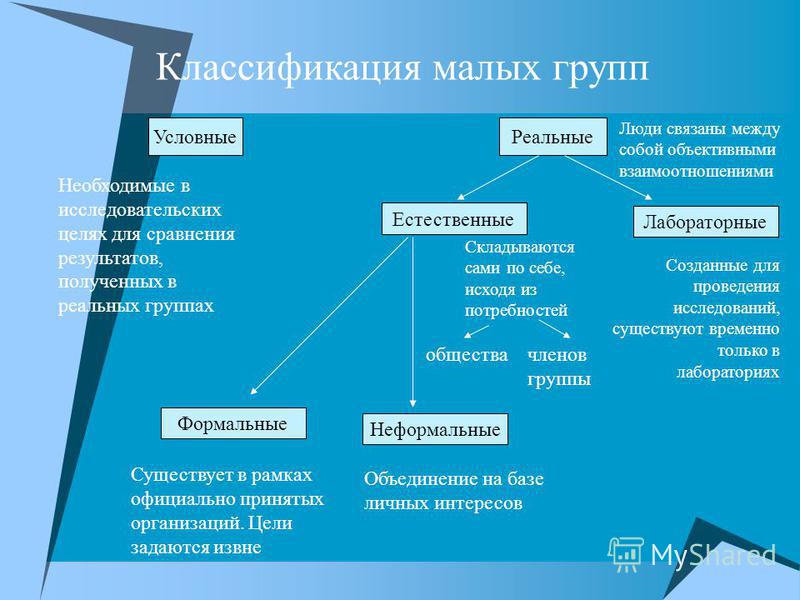
Отечественным психологом Артуром Владимировичем Петровским (1924–2006) была предложена следующая классификация групп по уровню их развития.
– Диффузная группа характеризуется низким уровнем развития, отсутствием совместно выполняемой работы, поверхностным общением между ее членами. Примерами диффузных групп можно считать группы случайно собранных людей – на улице, в общественном транспорте и т.д.
– Ассоциацией является группа людей, объединенных деловыми отношениям. Межличностные отношения при этом развиты на достаточном для успешной работы уровне, но не переходят на уровень дружеских. Ассоциацией можно считать рабочие бригады, учебные группы, какие-либо команды и т.д.
– Коллектив – наиболее развитая группа, характеризующаяся высокой сплоченностью людей, четкой организацией труда, добросовестностью и ответственностью работников. Межличностные отношения построены на дружбе, взаимопомощи, поддержке. Существует множество видов коллективов – рабочие, учебные, спортивные и т. д.
д.
– Корпорация представляет собой высокоорганизованное объединение людей с некоторыми экономическими целями. Такая группа стремится осуществить свои цели любой ценой, зачастую за счет других групп.
Говоря о типах групп, необходимо упомянуть о том, что они отличаются также по такому основанию, как коммуникационная структура. Исходя из каналов коммуникации выделяют два типа групп – централизованные и децентрализованные.
Централизованные группы характеризуются тем, что один из ее членов (как правило, руководитель) находится на пересечении направления общения прочих людей. Все общение в группе строится через данного человека. Выделяют три основные структуры, характерные для централизованных групп:
– Фронтальная структура заключается в том, что все члены группы находятся лицом к лицу.
– Радиальная группа характеризуется тем, что работники не могут видеть и слышать друг друга, поэтому вынуждены общаться через центральное лицо.
– Иерархическая структура имеет несколько уровней, некоторые из которых предполагают непосредственное общение, а другие – нет.
Децентрализованные группы не имеют связующего звена, а все участники общения обладают равными возможностями для общения. В рамках децентрализованных групп выделяют две основные структуры:
– Цепная структура заключается в общении работников по цепочке, передаче информации от одного к другому.
– Круговая структура характеризуется тем, что каждый член группы способен к общению с любым другим человеком, имея равные возможности как для приема, так и для передачи информации.Данный текст является ознакомительным фрагментом.
Группы игр
Группы игр
Игры маленьких детей
Обратимся к описанию отдельных групп игр. Начнем с важной разновидности игр, которую можно назвать игры маленьких детей. Можно спросить — насколько маленьких? Мы наблюдали первую игру у ребенка 3,5 месяцев от роду.
Глава 2. ТРИ ГРУППЫ ЖЕЛАНИЙ
Глава 2. ТРИ ГРУППЫ ЖЕЛАНИЙ Происходящее с человеком в жизни обусловлено желаниями. Можно считать, что не все зависит только от желания, есть еще и внешние обстоятельства. Но такова уж природа человека, что он не хочет признаваться себе в том, что событие, участником
Глава 25 Великие религиозные группы
Глава 25 Великие религиозные группы ИудаизмПалестина представляет собой узкую полоску земли, лежащую на восток от Средиземного моря и к югу от Аравийской пустыни. В не есть ка высокие горы, так и плодородные долины. Палестина имеет 70 миль в ширину и 125 миль в длину, и по
ГЛАВА 21. ГРУППЫ
ГЛАВА 21. ГРУППЫ
Если только вы не в пещере под ледяной глыбой где-то на Северном Полюсе, вы вряд ли избежите того, что вас попросят присоединиться, пожертвовать, подписаться под или поверить в одну группу или другую. Сегодня, кажется, существует больше групп, клубов,
Сегодня, кажется, существует больше групп, клубов,
3.3. Группы и коллективы
3.3. Группы и коллективы Общение, взаимодействие людей происходит в разнообразных группах. Под группой понимается совокупность элементов, имеющих нечто общее.Выделяют несколько разновидностей групп: 1) условные и реальные; 2) постоянные и временные; 3) большие и малые.
1.6. Диагностика группы
1.6. Диагностика группы Руководитель обычно знает о существовании неформальных групп. Увы, часто он еще и в курсе интриг в них, а вот расстановка сил ему не очень ясна. Если это так, не исключено, что он подвергнется давлению той или иной неформальной группы. И фактически
3.6. Семейные группы
3.6. Семейные группы
В годы застоя довольно часто произносили, и не без основания, слова Ф. Энгельса: «Семья – ячейка государства». Взгляните на рис. 8.Если семья прочная, если между мужем и женой совет да любовь, то объединяются их семьи, производственные коллективы и друзья.
Энгельса: «Семья – ячейка государства». Взгляните на рис. 8.Если семья прочная, если между мужем и женой совет да любовь, то объединяются их семьи, производственные коллективы и друзья.
Глава 8. Влияние группы
Глава 8. Влияние группы В нашем мире не только 6 миллиардов индивидуумов, но и 200 национально-государственных образований, 4 миллиона общин местного значения, 20 миллионов экономических организаций и сотни миллионов иных формальных и неформальных групп — влюбленные пары,
Глава 21. Организация группы поддержки при работе с книгой как дополнительный ресурс для достижения цели
Глава 21. Организация группы поддержки при работе с книгой как дополнительный ресурс для достижения цели Когда я занималась составлением этой книги, то ставила перед собой две основные задачи. Первая – это дать всю информацию, предоставляемую участникам групп по работе
Группы самопомощи
Группы самопомощи
Группы самопомощи предоставляют застенчивым людям возможность безбоязненно встречаться друг с другом. Оптимальной формой организации такой группы, по моему мнению, является объединение по интересам (спортивные, религиозные, литературные кружки,
Оптимальной формой организации такой группы, по моему мнению, является объединение по интересам (спортивные, религиозные, литературные кружки,
Глава 2. Кластеры – группы людей с разным уровнем Сознания
Глава 2. Кластеры – группы людей с разным уровнем Сознания «Всем, с милю ростом, покинуть зал!» «Алиса в Стране Чудес» Итак, каждый из нас довольно сложный биоробот, который выполняет, одновременно, и программу, заложенную в него Сознанием, и генетическую программу своего
Возрастные группы
Возрастные группы После определения «воспитания» зададим следующий вопрос. А для всех ли возрастных групп должен быть один и тот же педагогический подход, ведь дети в процессе роста очень меняются?Для ответа снова обратимся к нашим источникам. Царь Давид в своих
Завершение группы
Завершение группы
Мой семилетний опыт работы с семейными расстановками подсказывает мне, что расстановки нужно завершать кругом с обратной связью, как и любую другую психотерапевтическую группу. Мне не хочется, чтобы заместители чувствовали себя использованными,
Мне не хочется, чтобы заместители чувствовали себя использованными,
Личность и общество. Все о человеке
«Мы» большое и малое
Государства, нации, партии, социальные классы и другие крупные устойчивые общности людей называются большими группами. В них входят тысячи человек, большинство из которых не знакомы друг с другом. Группы, объединяющие от 2—3 до 20—30 человек, занятых одним делом и непосредственно общающихся друг с другом, называют малыми группами. К таким группам относят друзей, дворовую компанию, соседей, класс, спортивную команду и, конечно, семью. Малую группу отличает территориальная общность (соседи) или общность занятий, норм поведения, интересов.
Формальными малыми группами называют объединения людей в рамках официальных организаций, например предприятий или школ. К таким группам можно отнести рабочий коллектив или школьный класс. Задачи и цели для таких групп задаются организациями, в которые они входят, и объединены они только для решения этих задач. Неформальные малые группы возникают сами собой на базе общих личных интересов участников.
Неформальные малые группы возникают сами собой на базе общих личных интересов участников.
По степени влияния на личность малые группы делятся на референтные и нереферентные. Представьте, что некоего Вову родители заставили ходить в музыкальную школу. Вова, однако, разделяет мнение мальчишек во дворе, что музыка — это «занятие для девчонок» и гораздо полезнее научиться забивать голы. Музыкальный класс и дворовые мальчишки — это две малые группы, в которые входит Вова, но взгляды одноклассников по музыкальной школе ему чужды, а позиция приятелей со двора близка и понятна. Вова хотел бы быть таким же, как ребята во дворе. Для него, как и для них, один Пеле стоит ста Моцартов. Когда дети из музыкального класса упрекают его за то, что он не знает Бетховена, Вове это безразлично, так как во дворе никто не знает Бетховена. Но своим приятелям Вова стыдится сказать, что не видел последний матч, потому что увлекся изучением нотной грамоты. Для Вовы дворовая компания является референтной группой, то есть группой, в которой он находит образцы для подражания, мнение и нормы поведения которой он разделяет. Музыкальный класс для Вовы — нереферентная группа, ее интересы для него безразличны. Если бы существовала организация врагов футбола, она бы стала для Вовы и его приятелей антиреферентной группой, то есть группой, поведение и взгляды которой для них категорически неприемлемы и вызывают резкое осуждение.
Музыкальный класс для Вовы — нереферентная группа, ее интересы для него безразличны. Если бы существовала организация врагов футбола, она бы стала для Вовы и его приятелей антиреферентной группой, то есть группой, поведение и взгляды которой для них категорически неприемлемы и вызывают резкое осуждение.
Один за всех и все за одного
Каждый член группы занимает в ней определенное место, это положение характеризуется несколькими понятиями. Позиция — это официальное положение человека в группе, например должность. Статус — это степень авторитетности, влияния человека на других членов группы. Статус не всегда может соответствовать позиции: например, староста в классе далеко не всегда пользуется должным уважением одноклассников, тогда как слово озорника с последней парты иногда бывает очень веским. Реальный статус члена группы может не совпадать с внутренней установкой, т.е. с тем, как этот человек представляет себе свое положение.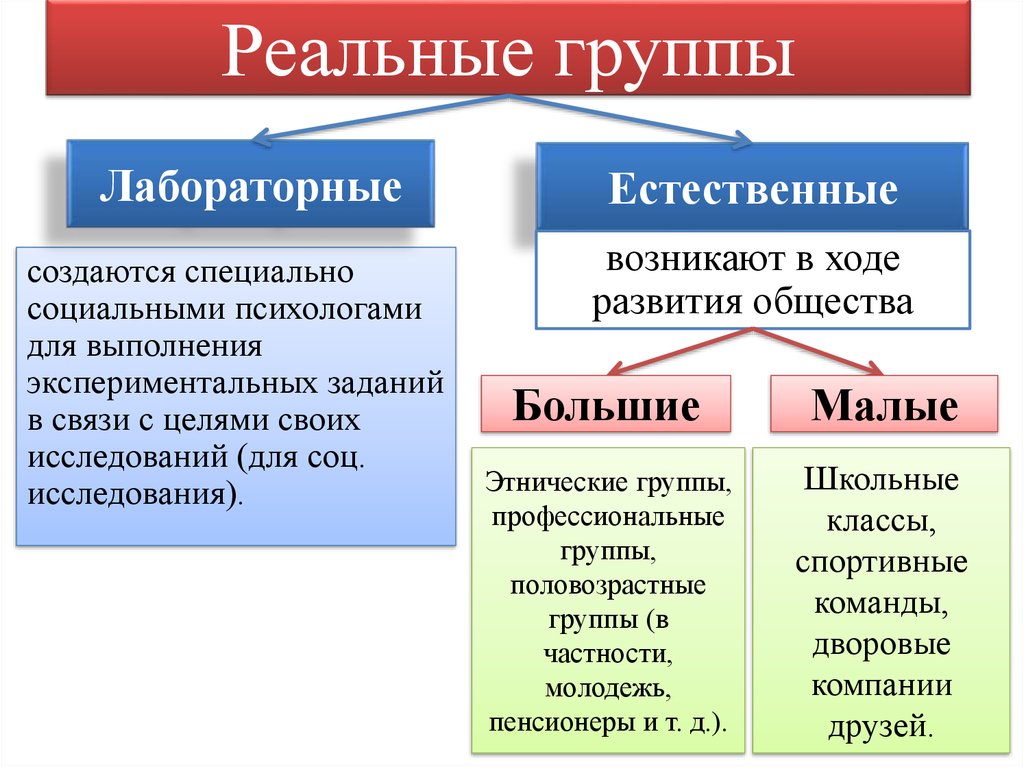 Одни переоценивают свое влияние на окружающих, другие — недооценивают его.
Одни переоценивают свое влияние на окружающих, другие — недооценивают его.
Важна роль человека в группе. Под ролью понимается норма поведения, принятая человеком и ожидаемая от него другими членами группы. Иногда роль соответствует должности — например, начальник исполняет роль лидера. В других случаях член группы может избрать роль вне зависимости от своей позиции. Роль может быть даже навязана группой (роль шута, роль дамского угодника, роль козла отпущения).
Чем больше общего у членов малой группы, тем она более сплоченная. Отношения между членами группы называют межличностными. Фон отношений в эмоциональном и нравственном плане называют психологическим климатом группы. Правила поведения, принятые в группе, называют групповыми нормами.
В группе складываются несколько типов отношений. Официальные отношения соответствуют официальным правилам, утвержденным для данной группы. Пример: отношение «начальник — подчиненный». Неофициальные отношения складываются под влиянием личных интересов, симпатий и антипатий и не зависят от официальных. Деловые отношения касаются только вопросов, связанных с совместной деятельностью; личные отношения складываются независимо от выполняемой работы. Рациональные отношения основаны на объективных оценках знаний друг о друге. Эмоциональные отношения касаются только личного восприятия.
Пример: отношение «начальник — подчиненный». Неофициальные отношения складываются под влиянием личных интересов, симпатий и антипатий и не зависят от официальных. Деловые отношения касаются только вопросов, связанных с совместной деятельностью; личные отношения складываются независимо от выполняемой работы. Рациональные отношения основаны на объективных оценках знаний друг о друге. Эмоциональные отношения касаются только личного восприятия.
«Я знаю, он отличный специалист…» — рациональное отношение; «…но он мне не нравится» — эмоциональное отношение.
Коллектив — это сплоченная группа, в которой хороший психологический климат, развитые деловые и личные отношения, четко распределенные обязанности. В коллективе есть лидер, которого все уважают, и каждый участник имеет возможность развиваться как личность. Деятельность коллектива эффективна, ее результаты полезны не только для членов этой группы, но и для многих других людей.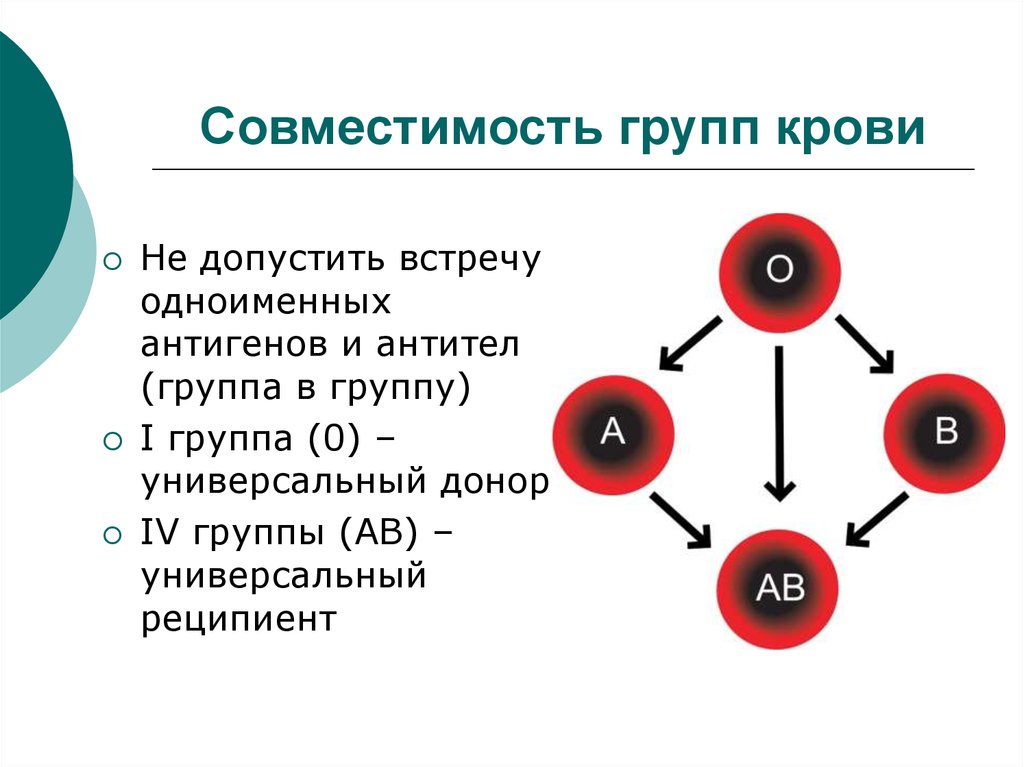 В хорошем коллективе люди дополняют друг друга. Коллектив легче справится с поставленными задачами, чем люди, не объединенные в коллектив.
В хорошем коллективе люди дополняют друг друга. Коллектив легче справится с поставленными задачами, чем люди, не объединенные в коллектив.
Всегда ли хорошо быть вместе
В значительной мере личность — плод влияния множества больших и малых групп. Именно под влиянием групп людей (особенно референтных групп), в которые мы входим на протяжении жизни, складываются интересы, представления о добре и зле, формируется характер.
Для формирующейся личности группа — это зеркало, в котором человек видит свое отражение в восприятии других людей. Получая групповую оценку своих действий, личность корректирует свое поведение. В группе всегда найдутся люди, обладающие большими знаниями и готовые ими поделиться. Чем в большее количество разнообразных групп человек входил на протяжении жизни, тем больше он обогащался духовно. Близкое и продолжительное общение с другими людьми обогащает наш опыт, позволяет отрабатывать приемы общения, учит понимать окружающих.
Есть немало и отрицательных сторон группового воспитания. В группе человек всегда испытывает на себе давление окружающих. Далеко не всякий может или хочет противостоять этому давлению. Умение приспосабливаться к окружающим, уступать общему мнению называется конформизмом.
В группе человек всегда испытывает на себе давление окружающих. Далеко не всякий может или хочет противостоять этому давлению. Умение приспосабливаться к окружающим, уступать общему мнению называется конформизмом.
Конформизм не однозначен. С одной стороны, плохо всегда «прогибаться» под окружающих, поступаться своими убеждениями, если они отличаются от убеждений большинства, действовать по принципу «я как все». Так можно отучиться самостоятельно принимать решения, отстаивать свои интересы.
С другой стороны, нет такой общности, где все бы имели одинаковые убеждения и принципы. Всегда в чем-то человек не сходится с мнением большинства. Получается, тогда надо вечно спорить и ввязываться в конфликты? Человек, действующий таким образом, не уживется ни в одном коллективе.
Вывод прост — надо найти «золотую середину». В мелочах можно и уступить, когда-то лучше промолчать, а иногда стоит убедить окружающих в своей правоте. По-настоящему бороться за свою точку зрения нужно лишь тогда, когда это имеет принципиальное значение и другой исход абсолютно неприемлем. Это и называют «здоровым конформизмом». Будучи членом коллектива, следует уважать его членов и заботиться о целостности своей личности, не позволить подчинить свою волю и свои убеждения коллективной воле и убеждениям.
Это и называют «здоровым конформизмом». Будучи членом коллектива, следует уважать его членов и заботиться о целостности своей личности, не позволить подчинить свою волю и свои убеждения коллективной воле и убеждениям.
В группе есть проблема разделения ответственности. Ее можно рассмотреть на следующем примере. Группа подростков разбила чужую машину. Каждый из этих подростков в отдельности не решился бы на это, но вместе они разделили ответственность за этот поступок, и на совести каждого осталась лишь незначительная ее доля. Принять какое-либо решение совместно проще, чем взять ответственность только на себя. Люди, привыкшие принимать коллективные решения, менее самостоятельны.
Толпа — общность безликих
Наиболее ярко отрицательное влияние группы на личность проявляется на примере толпы. Толпой в психологии называют большую неорганизованную общность людей. В толпе на первый план выходят низменные, скрытые проявления человеческой природы.
Каждый человек в толпе теряет свойства личности, так как он никому из рядом стоящих не известен и не интересен.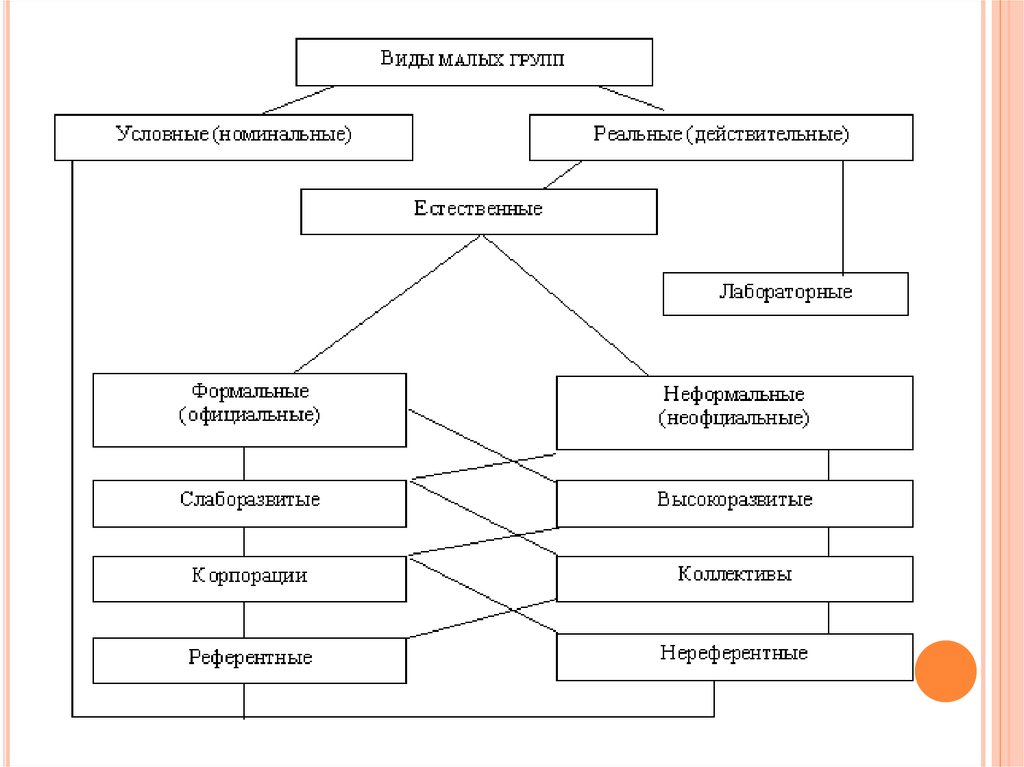 Он становится анонимным — не Иванов или Сидоров, которого любят в семье и уважают на работе, а просто «человек из толпы». Это делает каждого более безответственным. В толпе человек перестает отдавать себе отчет в своих поступках, теряет способность анализировать ситуацию. Утрачивая самоконтроль, он больше наблюдает за развитием ситуации, за поведением окружающих, заражаясь возбуждением толпы.
Он становится анонимным — не Иванов или Сидоров, которого любят в семье и уважают на работе, а просто «человек из толпы». Это делает каждого более безответственным. В толпе человек перестает отдавать себе отчет в своих поступках, теряет способность анализировать ситуацию. Утрачивая самоконтроль, он больше наблюдает за развитием ситуации, за поведением окружающих, заражаясь возбуждением толпы.
Эти факторы делают среднего человека в толпе более доверчивым, агрессивным и ожесточенным. Чтобы заставить что-либо сделать отдельного человека или небольшую группу людей, надо привести убедительные доводы. Чтобы сдвинуть с места толпу, достаточно привести ее в возбуждение сильными высказываниями, затрагивающими интересы большинства. О разумности и убедительности аргументов можно не беспокоиться. Этими свойствами толпы пользуются революционеры, политики и общественные деятели.
Подобный эффект наблюдается и во время массовых мероприятий, например на эстрадных концертах. Представьте, что вы попали на выступление юмориста. Публика хохотала над его шутками, вам тоже было очень смешно. Но если потом вы просмотрите запись его выступления, вы уже не будете так хохотать. Дело в том, что причина вашего смеха была не только в шутках артиста — вы заражались весельем окружающих.
Публика хохотала над его шутками, вам тоже было очень смешно. Но если потом вы просмотрите запись его выступления, вы уже не будете так хохотать. Дело в том, что причина вашего смеха была не только в шутках артиста — вы заражались весельем окружающих.
От улыбки станет всем светлей…
Одна из основных потребностей человека состоит в том, чтобы его замечали, уделяли внимание. Причем эта потребность так высока, что у каждого народа есть традиции отмечать присутствие другого человека. Чаще всего это какая-то форма приветствия. Поздороваться, увидев знакомого, улыбнуться ему, пожать руку, сказать пару добрых слов — очень важно. Это поднимает настроение, создает психологический комфорт и для того, кого приветствуют, и для самого приветствующего.
Сильнее всего от невнимания окружающих страдают дети. Когда родители перестают разговаривать с ребенком — для него это самая суровая форма наказания. Такие способы воспитания оказывают скорее не положительный, а отрицательный эффект и могут нанести серьезные психологические травмы развивающейся личности.
Как лучше понять друг друга
Для человека важно не только, чтобы его замечали, но и чтобы понимали и правильно оценивали. В основе понимания лежит восприятие человека человеком. Такое восприятие всегда субъективно, то есть отражает личный опыт воспринимающего человека. Поэтому один и тот же человек у одних вызывает симпатию (расположение, влечение), а у других — антипатию (неприязнь).
Внешность человека играет существенную роль в его восприятии другими людьми. Оценивая внешность, человек непроизвольно извлекает из памяти образы людей с похожими внешними чертами и приписывает эти черты новому знакомому. Недаром те, кто напоминает нам приятных людей, сразу вызывают симпатию, и, наоборот, если у человека есть что- то общее с вашим врагом, вы начинаете невольно испытывать к нему антипатию. Обычно симпатию вызывает у нас человек, у которого есть что-либо общее с нами: род занятий, место жительства, жизненная ситуация и т.д. Такое восприятие редко бывает осознанным и происходит на уровне подсознания. Там же кроются необъяснимые причины симпатий и антипатий.
Там же кроются необъяснимые причины симпатий и антипатий.
В восприятии немалую роль играют стереотипы — обобщенные и упрощенные представления о чем-либо. Например, считается, что полные люди — добрые. Увидев полного человека, мы начинаем общение с ним, имея в виду, что он добрый. Манеры поведения, одежда, род занятий, социальное положение и даже национальность, так же, как и внешность, воспринимаются под воздействием опыта и стереотипов. Носит очки — значит «ботаник» и зануда, рубашка застегнута под горло — значит, неуверен в себе и неконтактен, англичанин — значит сноб, библиотекарша — синий чулок или серая мышка. Но может случиться, что именно этот очкарик — душа компании и заводила, а рубашка застегнута под горло, потому что на шее порез от бритья и т.д.
В восприятии людей важную роль играет первое и последнее впечатление. Эти впечатления зачастую зависят от обстоятельств знакомства. Если вы познакомились с человеком на вечеринке, где вам понравилось, то и об этом человеке у вас останется хорошее впечатление. Плохое настроение во время первого знакомства часто бывает причиной неприязненного отношения к новому знакомому. Первое впечатление обычно очень стойкое, и, чтобы изменить его, нужны веские причины.
Плохое настроение во время первого знакомства часто бывает причиной неприязненного отношения к новому знакомому. Первое впечатление обычно очень стойкое, и, чтобы изменить его, нужны веские причины.
Иногда последняя информация о человеке, оставшаяся в памяти, бывает сильнее первого впечатления и сохраняется дольше. Это последнее впечатление также очень трудно изменить. Однако надо помнить, что эти впечатления зависят от многих факторов и часто бывают ошибочными.
Восприятие человека человеком начинается со «считывания» выражения лица и движений рук. Эти детали наиболее полно отражают психологическое состояние человека. На основе этой информации строится предположение о личности воспринимаемого человека. Выстроив в воображении образ личности воспринимаемого человека, как мы его поняли, мы выбираем манеру поведения, подходящую к данному человеку, опять же пользуясь своим опытом и памятью.
Если выводы о личности человека были сделаны неверно, могут произойти недоразумения и отношения не сложатся. Каковы же причины неправильных оценок человека человеком?
Каковы же причины неправильных оценок человека человеком?
Во-первых, нам мешает объективно воспринимать личность другого человека уже сложившееся мнение: если вы слышали о новом знакомом, что он лжец, вам будет трудно ему верить. Во-вторых, наблюдая человека, мы можем сделать неверное заключение о мотивах его поведения или намерениях, о его самочувствии и настроении. Так, можно подумать о человеке, что он раздражителен, а у него просто нестерпимо болит голова. В-третьих, сложив однажды свое мнение о человеке, мы иногда не желаем его менять даже под воздействием новой информации. Ученику, который прослыл двоечником, будет сложно стать отличником, несмотря на то что его багаж знаний пополнился, — учителю трудно поменять свое мнение.
Поделиться ссылкой
Личность в системе межличностных отношений
1. Выберите номер правильного варианта ответа
НЕМНОГОЧИСЛЕННАЯ ПО СОСТАВУ (ОТ 3 ДО 50 ЧЕЛОВЕК), ХОРОШО ОРГАНИЗОВАННАЯ, САМОСТОЯТЕЛЬНАЯ ЕДИНИЦА СОЦИАЛЬНОЙ СТРУКТУРЫ ОБЩЕСТВА, ОБЪЕДИНЕННАЯ ОБЩЕЙ ЦЕЛЬЮ, СОВМЕСТНОЙ ДЕЯТЕЛЬНОСТЬЮ И НЕПОСРЕДСТВЕННЫМ ЛИЧНЫМ КОНТАКТОМ, – ЭТО
1. Малая группа
Малая группа
2. Этногруппа
3. Стихийная группа
4. Большая группа
2. Выберите номер правильного варианта ответа
ОБЪЕДИНЕНИЯ ЛЮДЕЙ, ВОЗНИКАЮЩИЕ НА ОСНОВЕ ВНУТРЕННИХ, ПРИСУЩИХ САМИМ ИНДИВИДАМ ПОТРЕБНОСТЕЙ В ОБЩЕНИИ, ПРИНАДЛЕЖНОСТИ, ПОНИМАНИИ, СИМПАТИИ И ЛЮБВИ, НАЗЫВАЮТСЯ
1. Неформальными
2. Реальными
3. Временными
4. Формальными
3. Выберите номер правильного варианта ответа
РЕАЛЬНАЯ ИЛИ УСЛОВНАЯ ОБЩНОСТЬ ЛЮДЕЙ, С КОТОРОЙ ИНДИВИД СООТНОСИТ СЕБЯ И ТЕ НОРМЫ, ЦЕННОСТИ И ОЦЕНКИ НА КОТОРЫЕ ОН ОРИЕНТИРУЕТСЯ В СВОЕМ ПОВЕДЕНИИ И ДЕЯТЕЛЬНОСТИ, – ЭТО
1. Нереферентная группа
2. Коллектив
3. Референтная группа
4. Ассоциация
4. Выберите номер правильного варианта ответа
ПАССАЖИРОВ ТРОЛЛЕЙБУСА МОЖНО НАЗВАТЬ
1. Корпорацией
Корпорацией
2. Коллективом
3. Диффузной группой
4. Ассоциацией
5. Выберите номер правильного варианта ответа
ГРУППА, ЦЕННОСТНЫЕ ОРИЕНТАЦИИ КОТОРОЙ ИМЕЮТ НЕГАТИВНЫЙ, ИНОГДА АНТИОБЩЕСТВЕННЫЙ ХАРАКТЕР, – ЭТО
1. Просоциальная корпорация
2. Асоциальная ассоциация
3. Асоциальная корпорация
4. Диффузная группа
6. Выберите номер правильного варианта ответа
ЧЛЕН ГРУППЫ, ЗА КОТОРЫМ ОНА ПРИЗНАЕТ ПРАВО ПРИНИМАТЬ ОТВЕТСТВЕННЫЕ РЕШЕНИЯ В ЗНАЧИМЫХ ДЛЯ НЕЕ СИТУАЦИЯХ, Т.Е. НАИБОЛЕЕ АВТОРИТЕТНАЯ ЛИЧНОСТЬ, РЕАЛЬНО ИГРАЮЩАЯ ЦЕНТРАЛЬНУЮ РОЛЬ В ОРГАНИЗАЦИИ СОВМЕСТНОЙ ДЕЯТЕЛЬНОСТИ И РЕГУЛИРОВАНИИ ВЗАИМООТНОШЕНИЙ В ГРУППЕ, – ЭТО
1. Руководитель
2. Статус
3. Роль
4. Лидер
7. Выберите номер правильного варианта ответа
СТИЛЬ РУКОВОДСТВА, ПРИ КОТОРОМ ЧЛЕНЫ ГРУППЫ РАССМАТРИВАЮТСЯ КАК РАВНОПРАВНЫЕ ПАРТНЕРЫ, КАК КОЛЛЕГИ В СОВМЕСТНОМ ПРИНЯТИИ РЕШЕНИЙ, – ЭТО
1. Демократический
Демократический
2. Авторитарный
3. Либеральный
4. Попустительский
8. Выберите номер правильного варианта ответа
СТИЛЬ РУКОВОДСТВА, ХАРАКТЕРИЗУЮЩИЙСЯ ЕДИНОЛИЧНЫМ ПРИНЯТИЕМ ВСЕХ РЕШЕНИЙ, СУБЪЕКТИВНОЙ ОЦЕНКОЙ РЕЗУЛЬТАТОВ ДЕЯТЕЛЬНОСТИ, УСТРАНЕНИЕМ ПОДЧИНЕННЫХ ОТ УЧАСТИЯ В РЕШЕНИИ ВАЖНЕЙШИХ ВОПРОСОВ И ПОДАВЛЕНИЕМ ИХ ИНИЦИАТИВЫ И ТВОРЧЕСТВА, – ЭТО
1. Демократический стиль
2. Попустительский стиль
3. Авторитарный стиль
4. Либеральный стиль
9. Выберите номер правильного варианта ответа
ПОДАТЛИВОСТЬ ЧЕЛОВЕКА РЕАЛЬНОМУ ИЛИ ВООБРАЖАЕМОМУ ДАВЛЕНИЮ ГРУППЫ, ПРОЯВЛЯЮЩАЯЯ В ИЗМЕНЕНИИ ЕГО ПОВЕДЕНИЯ И УСТАНОВОК В СООТВЕТСТВИИ С ПЕРВОНАЧАЛЬНО НЕ РАЗДЕЛЯВШЕЙСЯ ИМ ПОЗИЦИЕЙ БОЛЬШИНСТВА, – ЭТО
1. Идентификация
2. Нонконформизм
3. Конформизм
4. Персонализация
10. Выберите номер правильного варианта ответа
Выберите номер правильного варианта ответа
ОТНОСИТЕЛЬНО УСТОЙЧИВЫЙ ЭМОЦИОНАЛЬНЫЙ НАСТРОЙ, ПРЕОБЛАДАЮЩИЙ В ГРУППЕ, В КОТОРОМ СОЕДИНЯЮТСЯ НАСТРОЕНИЯ ЛЮДЕЙ, ИХ ДУШЕВНЫЕ ПЕРЕЖИВАНИЯ И ВОЛНЕНИЯ, ОТНОШЕНИЕ ДРУГ К ДРУГУ, К РАБОТЕ И ОКРУЖАЮЩИМ СОБЫТИЯМ, – ЭТО
1. Ценностно-ориентационное единство
2. Коллективистическое самоопределение
3. Коллективистическая идентификация
4. Социально-психологический климат
11. Выберите номер правильного варианта ответа
ДАННЫЙ ФЕНОМЕН МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЙ ХАРАКТЕРИЗУЕТ ЕДИНСТВО ГРУППЫ, ГРУППОВУЮ И ИНДИВИДУАЛЬНУЮ ЗАЩИТУ ГРУППЫ В ЦЕЛОМ И КАЖДОГО ЕЕ ЧЛЕНА В ЧАСТНОСТИ, ВЗАИМОПОМОЩЬ И ВЗАИМОПОДДЕРЖКУ, – ЭТО
1. Ценностно-ориентационное единство
2. Коллективистическое самоопределение
3. Социально-психологический климат
4. Коллективистическая идентификация
12. Выберите номер правильного варианта ответа
ВИД ДЕЯТЕЛЬНОСТИ СУБЪЕКТА УПРАВЛЕНИЯ, НАПРАВЛЕННЫЙ НА ОСЛАБЛЕНИЕ И ОГРАНИЧЕНИЕ КОНФЛИКТА, ОБЕСПЕЧЕНИЕ ЕГО РАЗВИТИЯ В СТОРОНУ РАЗРЕШЕНИЯ, – ЭТО
1. Прогнозирование конфликта
Прогнозирование конфликта
2. Предупреждение конфликта
3. Регулирование конфликта
4. Разрешение конфликта
13. Выберите номер правильного варианта ответа
СТРАТЕГИЯ ПОВЕДЕНИЯ В КОНФЛИКТЕ, ОРИЕНТИРОВАННАЯ НА ТО, ЧТО-БЫ ДЕЙСТВУЯ АКТИВНО И САМОСТОЯТЕЛЬНО, ДОБИВАТЬСЯ ОСУЩЕСТВЛЕНИЯ СОБСТВЕННЫХ ИНТЕРЕСОВ, НЕВЗИРАЯ НА ДРУГИЕ СТОРОНЫ, НЕПОСРЕДСТВЕННО УЧАСТВУЮЩИЕ В КОНФЛИКТЕ, А ТО И В УЩЕРБ ИМ, – ЭТО
1. Компромисс
2. Избегание
3. Сотрудничество
4. Соперничество
«Верно» или «неверно»
14. Группа – это человеческая общность, выделяемая на основе определенного признака, например, социальной принадлежности, характера совместной деятельности, особенностей организации и т.д.
15. Под малой социальной группой понимается немногочисленная по составу группа, члены которой объединены общей целью своей деятельности и находятся в непосредственном личном контакте (общении).
16. К большим по численности группам относятся, с одной стороны, стихийные, кратковременно существующие, случайно возникающие общности типа толпы, публики, аудитории, а с другой стороны, длительно существующие, исторически обусловленные, устойчивые образования, такие как этнические, профессиональные или социальные группы.
17. Референтная группа – это реальная или идеальная группа, на которую ориентирован человек, чьи ценности, идеалы и нормы поведения он разделяет.
18. Уровень группового развития – характеристика межличностных отношений, результат процесса формирования группы.
19. Коллектив – устойчивая во времени организационная группа взаимодействующих людей со специфическими органами управления, объединенных целями общественно-полезной совместной деятельности и сложной динамикой формальных (деловых) и неформальных взаимоотношений между членами группы.
20. Социометрическая структура – это совокупность соподчиненных позиций членов группы в системе внутригрупповых межличностных предпочтений.
21. Коммуникативная структура группы – это совокупность позиций членов группы в системах информационных потоков, связывающих членов группы между собой и внешней средой, а также концентрация у них того или иного объема групповой информации.
22. Структура социальной власти в малой группе – это система взаиморасположения членов группы в зависимости от их способности оказывать влияние в группе.
23. Стиль лидерства – это совокупность средств психологического воздействия, которыми пользуется лидер для оказания влияния на других членов группы, среди которых он имеет высокий статус.
24. Демократичный стиль характеризуется выраженной властностью лидера, директивностью его действий, единоначалием в принятии решений, систематическим контролем за действиями ведомых.
25. Авторитарный стиль лидерства отличается тем, что лидер постоянно обращается к мнению зависимых от него людей, советуется с ними, привлекает их к выработке и принятию решений, к сотрудничеству в управлении группой.
26. Либеральный стиль лидерства – это такая форма поведения лидера, при которой он фактически уходит от своих обязанностей по руководству группой и ведет себя так, как будто он не лидер, а рядовой член группы.
27. Критерием эффективности руководства является степень авторитета руководителя.
28. Лидером группы может стать только тот человек, кто способен привести группу к разрешению тех или иных групповых ситуаций, проблем, задач, кто несет в себе наиболее важные для этой группы личностные черты, кто несет в себе и разделяет те ценности, которые присущи группе.
Общепсихологическая характеристика деятельности
1. Выберите номер правильного варианта ответа
АКТИВНОЕ ВЗАИМОДЕЙСТВИЕ ЧЕЛОВЕКА СО СРЕДОЙ, ПРИ КОТОРОМ ОН ДОСТИГАЕТ СОЗНАТЕЛЬНО ПОСТАВЛЕННОЙ ЦЕЛИ, ВОЗНИКАЮЩЕЙ КАК СЛЕДСТВИЕ ОПРЕДЕЛЕННОЙ ЕГО ПОТРЕБНОСТИ, МОТИВА, ЯВЛЯЕТСЯ
1. Операцией
2. Действием
3. Деятельностью
Деятельностью
4. Умением
2. Выберите номер правильного варианта ответа
СРЕДИ ТАКИХ ПОНЯТИЙ, КАК АКТИВНОСТЬ, ТРУД, ТРУДОВЫЕ ДЕЙСТВИЯ, ДЕЯТЕЛЬНОСТЬ, ЛОГИЧЕСКИ НАИБОЛЕЕ ШИРОКИМ ПОНЯТИЕМ ЯВЛЯЕТСЯ
1. Активность
2. Труд
3. Трудовое действие
4. Деятельность
3. Выберите номер правильного варианта ответа
ДЕЙСТВИЕ, СФОРМУЛИРОВАННОЕ ПУТЕМ ПОВТОРЕНИЯ, ХАРАКТЕРИЗУЮЩЕЕСЯ ВЫСОКОЙ СТЕПЕНЬЮ ОСВОЕНИЯ И ОТСУТСТВИЕМ СОЗНАТЕЛЬНОЙ РЕГУЛЯЦИИ И КОНТРОЛЯ, НАЗЫВАЕТСЯ
1. Действием
2. Навыком
3. Операцией
4. Привычкой
Установите соответствие
| ЭЛЕМЕНТ ДЕЯТЕЛЬНОСТИ | Характеристика |
| 1. Действие | А. Побуждение человека к определенной деятельности |
| 2. Операции | Б.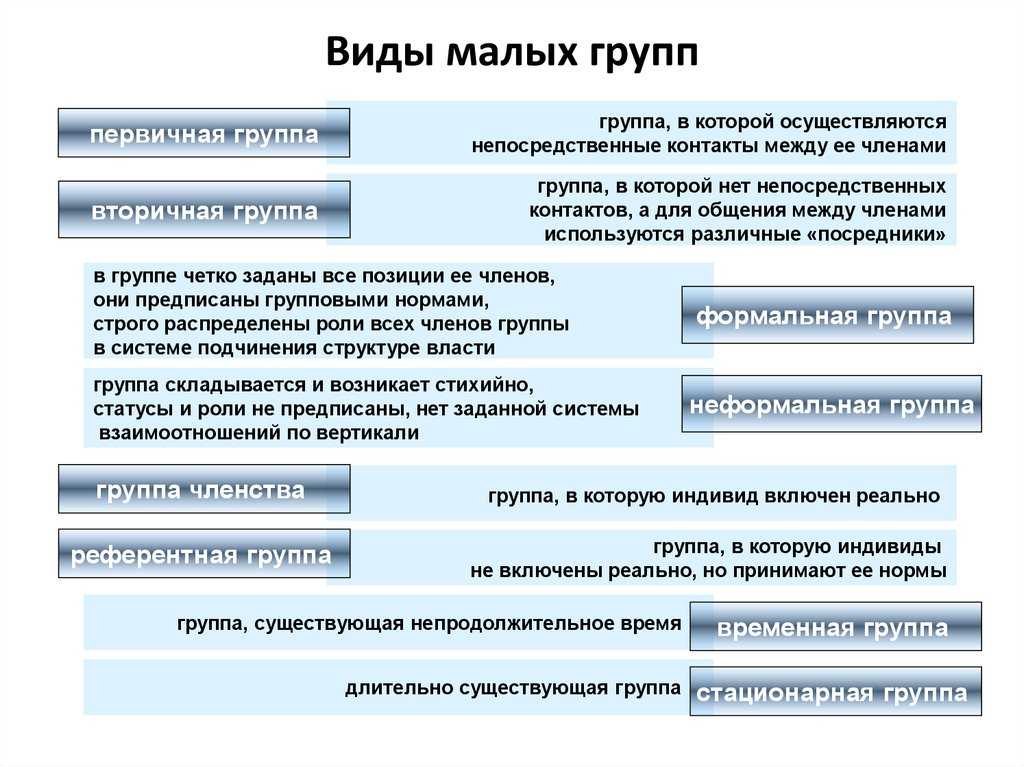 Представляемый результат деятельности Представляемый результат деятельности
|
| 3. Потребности | В. Способ выполнения действия, определяемый условиями наличной ситуации |
| 4. Цель | Г. Относительно завершенный элемент деятельности, направленный на достижение промежуточной цели |
| 5. Мотив | Д. Основной источник активности личности, внутреннее состояние нужды, выражающее зависимость от условий существования |
5. Выберите номер правильного варианта ответа
ПРИ ОБУЧЕНИИ РАБОТЕ НА МЕТАЛЛОРЕЖУЩЕМ СТАНКЕ УЧАЩИЕСЯ ВЫПОЛНЯЮТ СПЕЦИАЛЬНЫЕ УПРАЖНЕНИЯ ПО УСТАНОВКЕ ЗАГОТОВКИ, ПО ЗАКРЕПЛЕНИЮ РЕЖУЩЕГО ИНСТРУМЕНТА И ПО НАСТРОЙКЕ СТАНКА,– ЭТО
1. Действие
2. Навык
3. Операция
4. Упражнение
6. Выберите номер правильного варианта ответа
В ЦЕХЕ РАБОТАЕТ МОСТОВОЙ КРАН. В КАБИНЕ КРАНОВЩИКА ТРИ РЫЧАГА: ОДИН – ПОДНИМАЕТ И ОПУСКАЕТ ГРУЗ, ДРУГОЙ – ПРОДВИГАЕТ КРАН ПОПЕРЁК ЦЕХА, ТРЕТИЙ ПЕРЕМЕЩАЕТ МОСТ КРАНА ВДОЛЬ ОСИ. РАБОТАЯ ВСЕМИ РЫЧАГАМИ, КРАНОВЩИК ПЕРЕМЕЩАЕТ ГРУЗ ПО ТРЁМ ОСЯМ ТАК, ЧТО ГРУЗ ДВИЖЕТСЯ ПО ПРЯМОЙ ЛИНИИ, – ЭТО
РАБОТАЯ ВСЕМИ РЫЧАГАМИ, КРАНОВЩИК ПЕРЕМЕЩАЕТ ГРУЗ ПО ТРЁМ ОСЯМ ТАК, ЧТО ГРУЗ ДВИЖЕТСЯ ПО ПРЯМОЙ ЛИНИИ, – ЭТО
1. Знания
2. Умения
3. Навыки
4. Привычки
7. Выберите номер правильного варианта ответа
НЕОПЫТНЫЙ КРАНОВЩИК ПЕРЕДВИГАЕТ ГРУЗ ПО КАЖДОЙ ОСИ, РАБОТАЯ ПО ОЧЕРЕДИ КАЖДЫМ РЫЧАГОМ. ГРУЗ ДВИЖЕТСЯ КАК БЫ СКАЧКАМИ И ПО ЛОМАНОЙ ЛИНИИ: ПОЙДЁТ, ОСТАНОВИТСЯ, ЗАТЕМ ПОЙДЕТ В ДРУГОМ НАПРАВЛЕНИИ, – ЭТО
1. Привычки
2. Умения
3. Навыки
4. Знания
8. Выберите номер правильного варианта ответа
КОГДА НАЧИНАЮЩИЙ СПОРТСМЕН УЧИТСЯ ПЕРЕЗАРЯЖАТЬ ВИНТОВКУ, ОН НЕРЕДКО ШЕПЧЕТ: «РАЗ — ПОВЕРНУТЬ НАЛЕВО, ДВА – ПОТЯНУТЬ К СЕБЕ, ТРИ – ТОЛКНУТЬ ОТ СЕБЯ, ЧЕТЫРЕ – ПОВЕРНУТЬ НАПРАВО», – ЭТО
1. Знания
2. Умения
3. Навыки
4. Привычки
9. Выберите номер правильного варианта ответа
ПЕРЕХОДЯ УЛИЦУ С ОДНОСТОРОННИМ ДВИЖЕНИЕМ И ПОСМОТРЕВ НАЛЕВО, НАВСТРЕЧУ ДВИЖУЩЕМУСЯ ТРАНСПОРТУ, ВЫ, ДОЙДЯ ДО СЕРЕДИНЫ, ПОЧУВСТВУЕТЕ ПОТРЕБНОСТЬ ПОСМОТРЕТЬ НАПРАВО, ХОТЯ И ЗНАЕТЕ, ЧТО ТРАНСПОРТ ОТТУДА НЕ МОЖЕТ ИДТИ, – ЭТО
1. Умения
Умения
2. Привычки
3. Знания
4. Навыки
10. Выберите номер правильного варианта ответа
В ПЕРВОЕ ВРЕМЯ УЧЕНИК ДУМАЕТ НАД ТЕМ, СТАВИТЬ ИЛИ НЕ СТА-ВИТЬ ЗАПЯТУЮ В ПРЕДЛОЖЕНИИ. ДЛЯ ЭТОГО ОН ВСПОМИНАЕТ ПРАВИЛА ПУНКТУАЦИИ, ВЫБИРАЕТ ИЗ НИХ ПОДХОДЯЩИЕ ДАННОМУ СЛУЧАЮ. ОН ЗАТРУДНЯЕТСЯ СРАЗУ ОПРЕДЕЛИТЬ, НУЖНО ИЛИ НЕ НУЖНО СТАВИТЬ ЗАПЯТУЮ В ПРЕДЛОЖЕНИИ, – ЭТО
1. Привычки
2. Умения
3. Навыки
4. Знания
11. Выберите номер правильного варианта ответа
ОСНОВНОЙ ЕДИНИЦЕЙ АНАЛИЗА ДЕЯТЕЛЬНОСТИ ВЫСТУПАЕТ
1. Операция
2. Действие
3. Мотив
4. Цель
Установите соответствие
ЭТАПЫ
ФОРМИРОВАНИЯ СОДЕРЖАНИЕ ЭТАПА
НАВЫКА
1. Аналитический
2. Синтетический
3. Автоматизация Автоматизация
| А. Объединение элементов в целостное действие Б. Упражнение с целью придания действию плавности, нужной скорости В. Вычленение отдельных элементов действия и овладение ими |
13. Выберите номер правильного варианта ответа
ОТРИЦАТЕЛЬНОЕ, ВЗАИМОРАЗРУШАЮЩЕЕ ДЕЙСТВИЕ НЕСОВМЕСТИМЫХ ДРУГ С ДРУГОМ НАВЫКОВ НАЗЫВАЕТСЯ
1. Переносом
2. Экстериоризацией
3. Интериоризацией
4. Интерференцией
14. Выберите номер правильного варианта ответа
ВОЗМОЖНОСТЬ ИСПОЛЬЗОВАНИЯ СФОРМИРОВАННОГО НАВЫКА В СХОДНЫХ ИЛИ НОВЫХ УСЛОВИЯХ ИНТЕРПРЕТИРУЕТСЯ КАК
1. Перенос
2. Экстериоризация
3. Интериоризация
4. Интерференция
15. Выберите номер правильного варианта ответа
ПРОЦЕСС ПЕРЕХОДА ОТ ВНЕШНЕЙ ПРЕДМЕТНОЙ ДЕЯТЕЛЬНОСТИ К ЕЕ ВНУТРЕННЕМУ (ИДЕАЛЬНОМУ) ПЛАНУ НАЗЫВАЕТСЯ
1. Интериоризацией
Интериоризацией
2. Экстериоризацией
3. Интерференцией
4. Интеракцией
16. Выберите номер правильного варианта ответа
ДЕЯТЕЛЬНОСТЬ ЧЕЛОВЕКА, НАПРАВЛЕННАЯ НА ИЗМЕНЕНИЕ И ПРЕОБРАЗОВАНИЕ ДЕЙСТВИТЕЛЬНОСТИ РАДИ УДОВЛЕТВОРЕНИЯ СВОИХ ПОТРЕБНОСТЕЙ, НА СОЗДАНИЕ МАТЕРИАЛЬНЫХ И ДУХОВНЫХ ЦЕННОСТЕЙ, НАЗЫВАЕТСЯ
1. Трудовой
2. Учебной
3. Предметной
4. Ведущей
«Верно» или «неверно»
17 Деятельность – это активное взаимодействие человека со средой, в котором он достигает сознательно поставленной цели, возникшей в результате появления у него определенной потребности, мотива.
18. Под поведением в психологии принято понимать внешние проявления психической деятельности человека.
19. Поступок – действие, выполняя которое, человек осознает его значение для других людей, т. е. его социальный смысл.
20. Действие – основная единица анализа деятельности – это процесс, направленный на достижение цели.
Действие – основная единица анализа деятельности – это процесс, направленный на достижение цели.
Предыдущая123456789Следующая
Перечень всех учебных материаловГосударство и правоДемография История Международные отношения Педагогика Политические науки Психология Религиоведение Социология |
16.2. Виды групп Каждая личность является членом какой-либо группы. Существует множество видов групп, которые различаются по величине, форме организации, уровню развития и социальной направленности.
|
||||
|
© www.txtb.ru |
 д. Большие группы являются составной частью общества, государства, страны и народа. Они обеспечивают нормальную производственную, хозяйственную, политическую, культурную и духовную жизнь общества. Большие группы людей является объектом изучения науки социологии.
д. Большие группы являются составной частью общества, государства, страны и народа. Они обеспечивают нормальную производственную, хозяйственную, политическую, культурную и духовную жизнь общества. Большие группы людей является объектом изучения науки социологии. Такие взаимоотношения имеют место в семье, в компании друзей, коллег по работе, партнеров различных командах, экипажах и т.д.
Такие взаимоотношения имеют место в семье, в компании друзей, коллег по работе, партнеров различных командах, экипажах и т.д. Референтная группа является для личности наиболее важной из всех групп, в которые она входит. В ней она видит образец для подражания. Все ее ценности, формы поведения, взгляды и идеалы являются эталоном для личности. Мнением членов референтной группы личность дорожит в большей степени, чем мнением всех остальных людей. Нереферентная группа не имеет никакого значения для личности, хотя она может формально входить в ее состав. Все что происходит в этой группе является безразличным для индивида и не оказывает на него никакого влияния. Кроме этих двух групп Р. С. Немов выделяет антиреферентную группу, к которой субъект относится отрицательно. Поведение, взгляды, ценности и идеалы членов этой группы вызывают у него отвращение и чувство протеста.
Референтная группа является для личности наиболее важной из всех групп, в которые она входит. В ней она видит образец для подражания. Все ее ценности, формы поведения, взгляды и идеалы являются эталоном для личности. Мнением членов референтной группы личность дорожит в большей степени, чем мнением всех остальных людей. Нереферентная группа не имеет никакого значения для личности, хотя она может формально входить в ее состав. Все что происходит в этой группе является безразличным для индивида и не оказывает на него никакого влияния. Кроме этих двух групп Р. С. Немов выделяет антиреферентную группу, к которой субъект относится отрицательно. Поведение, взгляды, ценности и идеалы членов этой группы вызывают у него отвращение и чувство протеста. Условные группы — это искусственно создаваемые группы людей, между которыми нет непосредственных связей и контактов. Лица, зачисленные в эти группы, даже не подозревают об этом. Создание условных групп осуществляется на основе выделения общих социальных и психологических характеристик, свойственных определенным категориям людей.
Условные группы — это искусственно создаваемые группы людей, между которыми нет непосредственных связей и контактов. Лица, зачисленные в эти группы, даже не подозревают об этом. Создание условных групп осуществляется на основе выделения общих социальных и психологических характеристик, свойственных определенным категориям людей.
 д.
д. Отношения между членами корпорации построены на основе эгоистических интересов и имеют индивидуалистическую направленность. Примером корпорации являются мафиозные объединения, организованные группы преступников, организации перекупщиков, адвокатские коллегии.
Отношения между членами корпорации построены на основе эгоистических интересов и имеют индивидуалистическую направленность. Примером корпорации являются мафиозные объединения, организованные группы преступников, организации перекупщиков, адвокатские коллегии. Такими группами являются компании хулиганов, рекетиров, наркоманов, наркодельцов и других преступных объединений.
Такими группами являются компании хулиганов, рекетиров, наркоманов, наркодельцов и других преступных объединений.|
Навигация: Главная Случайная страница Обратная связь ТОП Интересно знать Избранные Топ: Выпускная квалификационная работа: Основная часть ВКР, как правило, состоит из двух-трех глав, каждая из которых, в свою очередь… Определение места расположения распределительного центра: Фирма реализует продукцию на рынках сбыта и имеет постоянных поставщиков в разных регионах. Оснащения врачебно-сестринской бригады. Интересное: Берегоукрепление оползневых склонов: На прибрежных склонах основной причиной развития оползневых процессов является подмыв водами рек естественных склонов… Распространение рака на другие отдаленные от желудка органы: Характерных симптомов рака желудка не существует. Выраженные симптомы появляются, когда опухоль… Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является… Дисциплины: Автоматизация Антропология Археология Архитектура Аудит Биология Бухгалтерия Военная наука Генетика География Геология Демография Журналистика Зоология Иностранные языки Информатика Искусство История Кинематография Компьютеризация Кораблестроение Кулинария Культура Лексикология Лингвистика Литература Логика Маркетинг Математика Машиностроение Медицина Менеджмент Металлургия Метрология Механика Музыкология Науковедение Образование Охрана Труда Педагогика Политология Правоотношение Предпринимательство Приборостроение Программирование Производство Промышленность Психология Радиосвязь Религия Риторика Социология Спорт Стандартизация Статистика Строительство Теология Технологии Торговля Транспорт Фармакология Физика Физиология Философия Финансы Химия Хозяйство Черчение Экология Экономика Электроника Энергетика Юриспруденция |
⇐ ПредыдущаяСтр 13 из 15Следующая ⇒
Понятие о социальной группе. Классификация групп
Группа — ограниченная в размерах общность людей, выделяемая из социального целого на основе определенных признаков (характера выполняемой деятельности, структуры, уровня развития и т.д.) Рассмотрим одну из наиболее распространенных классификаций групп (рис. 102). По размеру Большая группа (условная) – количественно неограниченная условная общность людей, выделяемая на основе определенных социальных признаков (пол, возраст, национальность и т.п.) Большая группа (реальная) – значительная по размерам и сложно организованная общность людей, вовлеченных в ту или иную общественную деятельность (например, коллектив вуза, предприятия и т.д.) Малая группа – (от двух до нескольких десятков человек) относительно небольшое число непосредственно контактирующих индивидов, объединенных общими целями и задачами. По общественному статусу Формальная (официальная) группа – реальная или условная социальная общность, имеющая юридически фиксированный статус, члены которой в условиях общественного разделения труда объединены социально заданной деятельностью, организующей их труд. Формальные группы всегда имеют определенную нормативно закрепленную структуру, назначенное или избранное руководство, нормативно закрепленные права и обязанности ее членов.
Рис. 102. Классификация групп Неформальная (неофициальная) группа– реальная социальная общность, не имеющая юридически фиксированного статуса, добровольно объединенная на основе интересов, дружбы и симпатий. Группы неформальные могут выступать как изолированные общности или складываться внутри формальных групп. По непосредственности взаимосвязей Условная группа – объединенная по определенному признаку (характер деятельности, пол, возраст и т. Реальная группа – это объединение, где люди связанны реальными контактами (например, группа однокурсников). По личностной значимости Референтная группа–реальная или условная социальная общность, с которой индивид соотносит себя и на нормы, мнения, ценности и оценки которой он ориентируется в своем поведении и самооценке. Нереферентная группа – это группа, психология и поведение которой чужды или безразличны для человека. Антиреферентная группа – это группа, поведение и психологию членов которой человек не приемлет, осуждает и отвергает. По уровню развития Низкий уровень Диффузная группа – это общность, в которой отсутствует сплоченность как ценностно-ориентационное единство, нет совместной деятельности, способной опосредовать отношения ее участников. Ассоциация – группа, в которой отсутствуют объединяющая ее совместная деятельность, организация и управление, а ценностные ориентации, опосредующие межличностные отношения, проявляются в условиях группового общения. В зависимости от общественной направленности опосредующих факторов различают просоциальные ассоциации и ассоциальные ассоциации. Просоциальнальные ассоциации– это группы, в которые позитивные нравственные ценности привнесены из широкой социальной среды, сформированы и упрочены в процессе трудовой деятельности. В случае включения этих ассоциаций в совместную деятельность, обусловленную общественно значимыми задачами и соответствующей им организацией и руководством, они проходят путь коллективообразования. Например, студенческая группа в начале процесса обучения. Асоциальные ассоциации – это группы, ценностные ориентации которых имеют негативный, иногда антиобщественный характер. Например, группа агрессивно настроенных подростков. Эти группы, в условиях антиобщественно направленной организации и руководства, легко превращаются в асоциальные корпорации. Корпорация просоциальная – это организованная группа, характеризующаяся замкнутостью и максимальной централизацией. Корпорация асоциальная (антиобщественная) – это группа, противопоставляющая себя другим социальным общностям на основе своих узко индивидуалистических интересов. Межличностные отношения в корпорациях опосредуются асоциальными, а зачастую антисоциальными ценностными ориентациями. Например, хорошо организованная группа рэкетиров или мафия. Высокий уровень Коллектив – группа объединенных общими целями и задачами людей, достигшая в процессе социально ценной совместной деятельности высокого уровня развития. В коллективе формируется особый тип межличностных отношений, характеризующийся высокой сплоченностью как ценностно-ориентационным единством, коллективистической идентификацией и т.д. (рис. 103).
Рис. 103 . Основные особенности зрелого коллектива ⇐ Предыдущая6789101112131415Следующая ⇒ Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого. Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим… Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства… Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов (88‰)… |
 Увеличение объема продаж…
Увеличение объема продаж… Классификация групп
Группа и ее структурная организация
Структура социальной власти в малой группе
Феномены межличностных отношений
Классификация групп
Группа и ее структурная организация
Структура социальной власти в малой группе
Феномены межличностных отношений

 д.)
д.)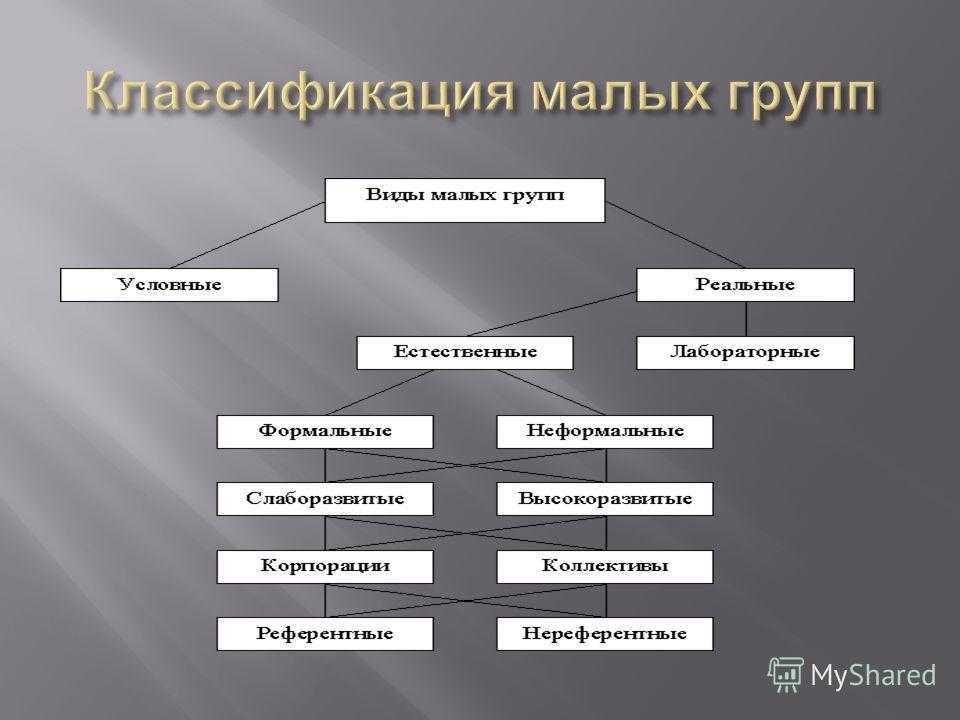
 Например, промышленные корпорации.
Например, промышленные корпорации.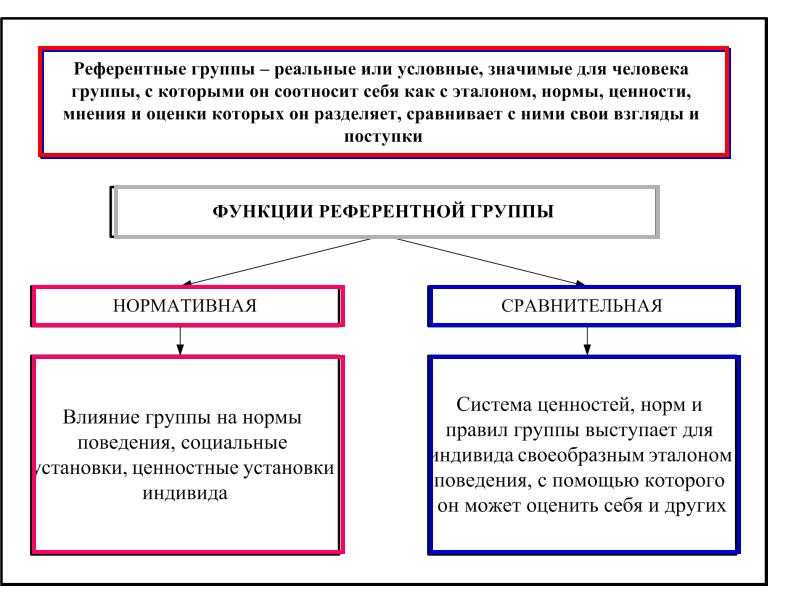 ..
..5.8 Категориальные независимые переменные | Статистика и аналитика для социальных и компьютерных наук
До сих пор мы имели дело с непрерывными независимыми переменными (\(X\)), (например, расходы, годы, возраст, числа, …). В этом разделе мы рассматриваем категориальные независимые переменные (например, пол, этническая принадлежность, семейное положение, цвет кнопки поиска и т. д.).
Давайте рассмотрим пример, моделирующий зависимость продаж зонтиков от погоды.
\[\text{Продажи зонтов} = b_0 + b_1 \text{Погода}\]
Эти категориальные переменные принимают одно из небольшого набора фиксированных значений. Давайте предположим, что в этом простом мире погода бывает только солнечной или дождливой.
Давайте предположим, что в этом простом мире погода бывает только солнечной или дождливой.
5.8.1 Dummy Coding
Dummy Coding (метод по умолчанию в R) — это метод, с помощью которого мы создаем и используем фиктивные переменные в нашей регрессионной модели 5 .
В этом примере мы можем определить переменную: Rainy , которая равна 1, если Weather==Rainy , и 0, если Weather==Sunny .
Rainy называется фиктивной переменной (иногда называемой индикаторной переменной)
Мы можем заменить Weather фиктивной переменной Rainy :
\[\text{UmbrellaSales} = b_0 + b_1 \text{Weather } \; \правая стрелка \; \color{brown}{\text{UmbrellaSales} = b_0 + b_1 \text{Дождь}}\]
Таким образом, это разбивается на два уравнения (технически, кусочное уравнение):
- Если солнечно, \(\ text{Продажи зонтиков} = b_0 + b_1(0) = b_0\)
- Если дождь, \(\text{Продажи зонтов} = b_0 + b_1(1) = b_0 + b_1\)
Теперь мы можем интерпретировать значения этих коэффициентов. Глядя на первое уравнение, мы видим, что \(b_0\) — это просто средние продажи зонтов в солнечную погоду. Аналогично, из второго уравнения мы видим, что \(b_0\) ПЛЮС \(b_1\) — это средние продажи зонтов в дождливую погоду.
Глядя на первое уравнение, мы видим, что \(b_0\) — это просто средние продажи зонтов в солнечную погоду. Аналогично, из второго уравнения мы видим, что \(b_0\) ПЛЮС \(b_1\) — это средние продажи зонтов в дождливую погоду.
Это означает, что \(b_1\) есть разность между этими уравнениями: Это средняя разница в продажах зонтов в дождливую погоду по сравнению с солнечной.
В следующей таблице приведены эти интерпретации:
| (\(b_0\)) | Средняя продажа зонтов в солнечную погоду |
| (\(b_0+b_1\)) | Средняя продажа зонтов в дождливую погоду |
| (\(b_1\)) | Средняя разница в продажах зонтов в дождливую погоду, по сравнению с в солнечную погоду (Продажи в дождливую погоду — Продажи в солнечную погоду) |
В: Как вы думаете, $b_1$ будет больше 0 или меньше 0?
5.
 8.2 Три уровня фиктивного кодирования
8.2 Три уровня фиктивного кодирования Теперь рассмотрим более сложный мир, в котором Погода может принимать одно из трех значений: солнечно, дождливо или облачно.
Затем мы можем определить две фиктивные переменные, Дождь и Облачно ,
-
Дождь= 1, если погода дождливая, 0 в противном случае -
Облачно= 1, если погода облачная, 0 иначе
Мы говорим, что Sunny является эталонной группой для категориальной переменной Weather .
\[\text{Продажи зонтов} = b_0 + b_1 \text{Дождь} + b_2\text{Облачно}\]
Это разбивается на три уравнения:
- Если солнечно, \(\text{Продажи зонтов} = b_0 + b_1(0) + b_2(0) = b_0\)
- Если дождь, \(\text{Продажи зонтов} = b_0 + b_1(1) + b_2(0) = b_0 + b_1\)
- Если облачно, \(\text{Продажи зонтов} = b_0 + b_1(0) + b_2(1) = b_0 + b_2\)
Как и выше, мы можем интерпретировать значения коэффициентов в следующей таблице:
| (\(b_0\)) | Средняя продажа зонтов в солнечную погоду |
| (\(b_0+b_1\)) | Средняя продажа зонтов в дождливую погоду |
| (\(b_1\)) | Средняя разница в продажах зонтов в дождливую погоду, по сравнению с в солнечную погоду (Продажи в дождливую погоду — Продажи в солнечную погоду) |
| (\(b_0+b_2\)) | Средняя продажа зонтов в облачную погоду |
| (\(b_2\)) | Средняя разница в продажах зонтиков в облачную погоду, по сравнению с в солнечную погоду (Продажи в пасмурную погоду — Продажи в солнечную погоду) |
Таким образом, в общем случае категориальная переменная с \(n\) уровнями будет иметь \((n-1)\) фиктивных переменных. И общая интерпретация этих \(i\) фиктивных переменных такова:
И общая интерпретация этих \(i\) фиктивных переменных такова:
| (\(b_0\)) | Среднее значение Y для контрольной группы. |
| (\(b_i\)) | Средняя разница Y для фиктивной группы i по сравнению с эталонной группой. |
5.8.3 Контрольная группа
Теперь, когда мы выполняем фиктивное кодирование, одна из групп автоматически становится контрольной группой. Выбор референтной группы не фиксирован. А правильный выбор референтной группы (в зависимости от ваших целей) сделает ваш анализ более удобным и интерпретируемым.
Например, для примера продажи зонтов (солнечно, дождливо, облачно) я думаю, что «солнечно» является хорошей контрольной группой. Почему?
Или, скажем, я хочу посмотреть, как люди реагируют на цвет кнопки на моей веб-странице. Итак, я провел эксперимент со следующими четырьмя кнопками 6 :
- Текущая кнопка
- Кнопка А
- Кнопка В
- Кнопка С
Что выбрать в качестве референтной группы? Я думаю, что «Текущая кнопка» должна быть эталонной группой, поскольку это статус-кво, и мне интересно, как изменение кнопок повлияет на клики по сравнению с моей текущей кнопкой.
Хорошие новости: R обрабатывает фиктивное кодирование для вас с использованием факторов. Вам не нужно создавать свои собственные фиктивные переменные. Просто беги: lm(продажи ~ погода, df) и если погода является фактором с n уровнями, R по умолчанию создаст n-1 фиктивных переменных Плохая новость: R не знает ваших гипотез, поэтому использует эвристику для выбор референтной группы. Если вы не укажете, R по умолчанию ранжирует группы в алфавитном порядке. Таким образом, в примере с погодой будет выбрано «Облачно», а в примере с кнопкой "Кнопка A" в качестве контрольной группы. Если ваша переменная (df$var) является фактором, вы можете проверить, используя уровни(df$var). Первый уровень будет референтной группой. Используйте relevel(df$var, "desiredReferenceLevel") для настройки эталонной группы. (если df$var является строкой символов, level() вернет NULL, но если вы поместите его в lm(), R будет рассматривать его как категориальную переменную, с наименьшей по алфавиту строкой в качестве контрольной группы)
5.
 8.4 Интерпретация категориальных и непрерывных независимых переменных
8.4 Интерпретация категориальных и непрерывных независимых переменных Всякий раз, когда в модели есть категориальные независимые переменные, интерпретация коэффициентов должна выполняться по отношению к контрольной группе, даже для других непрерывных независимых переменных.
Давайте добавим непрерывную переменную в нашу трехпогодную модель.
-
UmbrellaSales— непрерывная переменная, измеряемая в долларах. -
ДождливоиОблачно— фиктивные переменные («Солнечно» — эталонная группа) -
Расходы на рекламутакже является непрерывной переменной, измеряемой в долларах.
Допустим, мы подгоняем следующую модель и получаем следующие коэффициенты:
\[\text{Продажи зонтов} = 10 + 50 \text{Дождь} + 20 \text{Облачно} + 2,5\text{Расходы на рекламу}\]
Вот как мы интерпретируем каждый из этих коэффициентов:
| 10 | Средние продажи зонтов в солнечную погоду и 0 долларов, потраченных на рекламу. |
| 50 | Средние продажи зонтов в дождливую погоду по сравнению с солнечными и $0, потраченными на рекламу. |
| 20 | Средние продажи зонтов в пасмурную погоду по сравнению с солнечными и $0, потраченными на рекламу. |
| 2,5 | Когда солнечно, каждый доллар, потраченный на рекламу, увеличивает продажи на 2,50 доллара |
-
Помимо фиктивного кодирования (по умолчанию R), существуют другие схемы кодирования, которые можно использовать для проверки более конкретной гипотезы, например. кодирование эффектов, кодирование различий и т. д. Но здесь мы сосредоточимся на фиктивном кодировании.↩︎
-
Это может показаться легкомысленным, но Google провел много таких тестов в свое время с различными оттенками синего/зеленого/красного, чтобы установить их текущие «цвета Google». ↩︎
Справочник по регулярным выражениям: захват групп и обратных ссылок
| Введение |
| Содержание |
| Краткий справочник |
| Символы |
| Basic Features |
| Character Classes |
| Shorthands |
| Anchors |
| Word Boundaries |
| Quantifiers |
| Unicode |
| Capturing Groups & Backreferences |
| Named Группы и обратные ссылки |
| Специальные группы |
| Модификаторы режима |
| Recursion & Balancing Groups |
| Characters |
| Matched Text & Backreferences |
| Context & Case Conversion |
| Conditionals |
| Introduction |
| Regular Expressions Quick Start |
| Учебное пособие по регулярным выражениям |
| Учебное пособие по замене строк |
| Applications and Languages |
| Regular Expressions Examples |
| Regular Expressions Reference |
| Replacement Strings Reference |
| Book Reviews |
| Printable PDF |
| About This Site |
| RSS Feed & Blog |
JGsoft. NETJavaPerlPCREPCRE2PHPDelphiRJavaScriptVBScriptXRegExpPythonRubystd::regexBoostTcl AREPOSIX BREPOSIX EREGNU BREGNU EREOracleXMLXPathJGsoft.NETJavaPerlPCREPCRE2PHPDelphiRJavaScriptVBScriptXRegExpPythonRubystd::regexBoostTcl AREPOSIX BREPOSIX EREGNU BREGNU EREOracleXMLXPath
NETJavaPerlPCREPCRE2PHPDelphiRJavaScriptVBScriptXRegExpPythonRubystd::regexBoostTcl AREPOSIX BREPOSIX EREGNU BREGNU EREOracleXMLXPathJGsoft.NETJavaPerlPCREPCRE2PHPDelphiRJavaScriptVBScriptXRegExpPythonRubystd::regexBoostTcl AREPOSIX BREPOSIX EREGNU BREGNU EREOracleXMLXPath
| Feature | Syntax | Description | Example | JGsoft | .NET | Java | Perl | PCRE | PCRE2 | PHP | Delphi | R | JavaScript | VBScript | XRegExp | Python | Ruby | std::regex | Boost | Tcl ARE | POSIX BRE | POSIX ERE | GNU BRE | GNU ERE | Oracle | XML | XPath | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Группа захвата | (регулярное выражение) | Круглые скобки группируют между собой регулярное выражение. Они захватывают текст, соответствующий регулярному выражению внутри них, в пронумерованную группу, которую можно повторно использовать с пронумерованной обратной ссылкой. Они позволяют применять операторы регулярных выражений ко всему сгруппированному регулярному выражению. Они позволяют применять операторы регулярных выражений ко всему сгруппированному регулярному выражению. |
(abc){3} соответствует abcabcabc. Первая группа соответствует abc. | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | ECMA extended egrep awk | ECMA Extended EGREP AWK | Да | NO | Да | Нет | Да | Да | Да | Да | да | Да0063 | Группа захвата | \(регулярное выражение\) | Экранированные круглые скобки группируют между собой регулярное выражение. Они захватывают текст, соответствующий регулярному выражению внутри них, в пронумерованную группу, которую можно повторно использовать с пронумерованной обратной ссылкой. Они позволяют применять операторы регулярных выражений ко всему сгруппированному регулярному выражению. Они позволяют применять операторы регулярных выражений ко всему сгруппированному регулярному выражению. |
\(abc\){3} соответствует abcabcabc. Первая группа соответствует abc. | нет | нет | нет | нет | нет | no | no | no | no | no | no | no | no | no | basic grep | basic grep | no | YES | no | YES | № | № | № | № | ||||||
| Группа без захвата | (?:регулярное выражение) | Незахватывающие круглые скобки группируют регулярное выражение, поэтому вы можете применять операторы регулярного выражения, но ничего не захватывает. | (?:abc){3} соответствует abcabcabc. Нет групп. | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | ECMA | ECMA | YES | нет | нет | нет | нет | нет | нет | ДА | ||||||||||||||||||||||||||||||||||||
| Обратная ссылка | от \1 до \9 | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 9-й. |
(abc|def)=\1 соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | ECMA basic grep | ECMA basic grep | YES | YES | no | YES | YES | YES | no | YES | ||||||||||||||||||||||||||||||||||||
| Backreference | от \10 до \99 | Заменяется текстом, совпадающим между группами захвата с номерами с 10-й по 99-ю. | ДА | ДА | ДА | ДА | ДА | YES | YES | YES | YES | YES | YES | YES | YES | YES | ECMA | no | YES | no | no | no | no | no | нет | ДА | |||||||||||||||||||||||||||||||||||||
| Обратная ссылка | от \k<1> до \k<99> | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 99-й. |
(abc|def)=\k<1> соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. | YES | YES | no | no | no | no | no | no | no | no | no | YES | no | 1.9 | no | ECMA 1.47– 1.77 | нет | нет | нет | нет | нет | нет | нет | нет | ||||||||||||||||||||||||||||||||||||
| Обратная ссылка | от \k’1′ до \k’99’ | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 99-й. | (abc|def)=\k’1′ соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. | Да | Да, | № | № | № | № | № | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | 0065 | no | 1. 9 9 | no | ECMA 1.47–1.77 | no | no | no | no | no | no | no | no | |||||||||||||||||||
| Backreference | от \g1 до \g99 | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 99-й. | (abc|def)=\g1 соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. | no | no | no | 5.10 | 7.0 | YES | 5.2.2 | YES | YES | no | no | no | no | no | no | ECMA 1,42–1,77 | нет | нет | нет | нет | нет | нет | нет | нет 65 | ||||||||||||||||||||||||||||||||||||
| от \g{1} до \g{99} | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 99-й. | (abc|def)=\g{1} соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. |
no | no | no | 5.10 | 7.0 | YES | 5.2.2 | YES | YES | no | no | no | no | no | no | ECMA 1,42–1,77 | нет | нет | нет | нет | нет | нет | нет | нет | |||||||||||||||||||||||||||||||||||||
| Обратная ссылка | от \g<1> до \g<99> | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 99-й. | (abc|def)=\g<1> соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. | нет | нет | нет | нет | нет | no | no | no | no | no | no | no | no | no | no | ECMA 1.47–1.77 | no | no | no | no | нет | нет | нет | нет | ||||||||||||||||||||||||||||||||||||
| Обратная ссылка | от \g’1′ до \g’99’ | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 99-й. |
(abc|def)=\g’1′ соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. | no | no | no | no | no | no | no | no | no | no | no | no | no | no | no | ECMA 1.47– 1.77 | нет | нет | нет | нет | нет | нет | нет | нет | ||||||||||||||||||||||||||||||||||||
| Обратная ссылка | от(?P=1) до (?P=99) | Заменяется текстом, совпадающим между группами захвата с номерами от 1-й до 99-й. | (abc|def)=(?P=1) соответствует abc=abc или def=def, но не соответствует abc=def или def=abc. | YES | no | no | no | no | no | no | no | no | no | no | no | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | NO | 6666666666666666666666666666.
| \k<-1>, \k<-2> и т. д. | Заменяется текстом, соответствующим захватываемой группе, который можно найти, подсчитав столько открывающих скобок именованных или пронумерованных захватываемых групп, сколько указано числом справа налево, начиная с обратной ссылки. | (a)(b)(c)(d)\k<-3> соответствует abcdb. | V2 | no | no | no | no | no | no | no | no | no | no | no | no | 1.9 | no | ECMA 1.47– 1.77 | нет | нет | нет | нет | нет | нет | нет | нет | 9 Относительный0065 | \к’-1′, \к’-2′ и т. д. | Заменяется текстом, соответствующим захватываемой группе, который можно найти, подсчитав столько открывающих скобок именованных или пронумерованных захватываемых групп, сколько указано числом справа налево, начиная с обратной ссылки.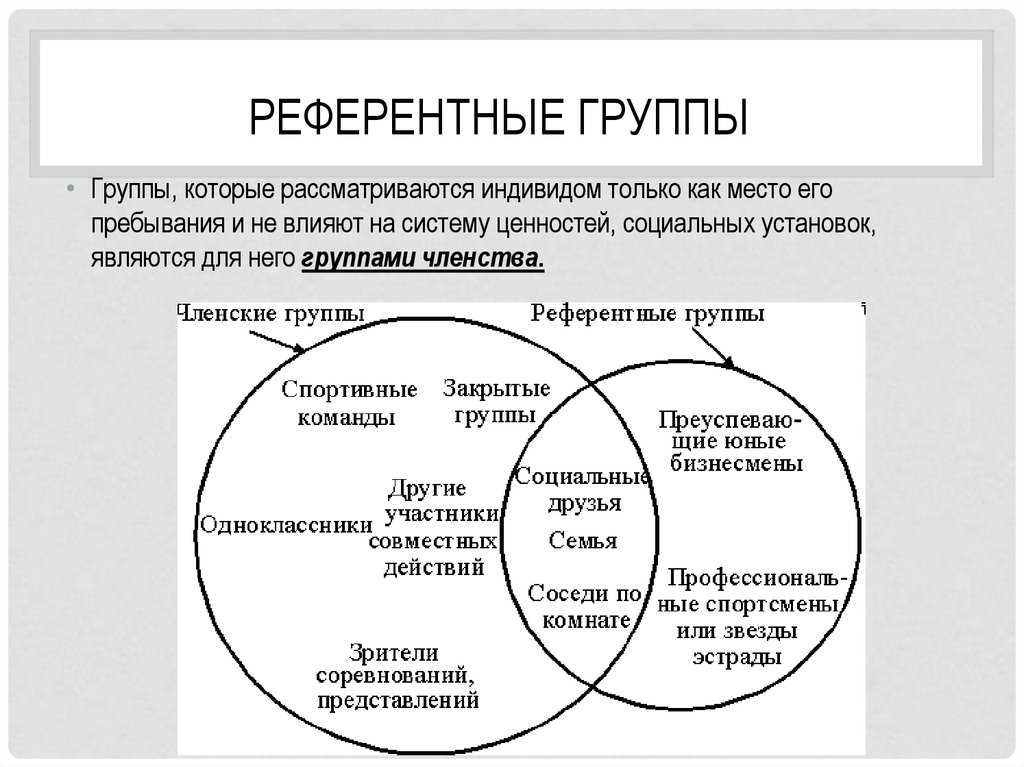 |
(a)(b)(c)(d)\k’-3′ соответствует abcdb. | V2 | нет | нет | нет | нет | нет | нет | нет | нет | no | no | no | no | 1.9 | no | ECMA 1.47–1.77 | no | no | no | no | no | no | no | no |
| Относительная обратная ссылка | \г-1, \г-2 и т. д. | Заменяется текстом, соответствующим захватываемой группе, который можно найти, подсчитав столько открывающих скобок именованных или пронумерованных захватываемых групп, сколько указано числом справа налево, начиная с обратной ссылки. | (a)(b)(c)(d)\g-3 соответствует abcdb. | no | no | no | 5.10 | 7.0 | YES | 5.2.2 | YES | YES | no | no | no | no | no | no | ECMA Относительный0065 | \g{-1}, \g{-2} и т. д. д. |
Заменяется текстом, соответствующим захватываемой группе, который можно найти, подсчитав столько открывающих скобок именованных или пронумерованных захватываемых групп, сколько указано числом справа налево, начиная с обратной ссылки. | (a)(b)(c)(d)\g{-3} соответствует abcdb. | нет | нет | нет | 5.10 | 7.0 | ДА | 5.2.2 | ДА | YES | no | no | no | no | no | no | ECMA 1.42–1.77 | no | no | no | no | no | no | no | № | |||||||||||||||||
| Относительная обратная ссылка | \g<-1>, \g<-2> и т. д. | Заменяется текстом, соответствующим захватываемой группе, который можно найти, подсчитав столько открывающих скобок именованных или пронумерованных захватываемых групп, сколько указано числом справа налево, начиная с обратной ссылки. |
(a)(b)(c)(d)\g<-3> соответствует abcdb. | no | no | no | no | no | no | no | no | no | no | no | no | no | no | no | ECMA 1.47– 1.77 | нет | нет | нет | нет | нет | нет | нет | нет | 9 Относительный0065 | \g’-1′, \g’-2′ и т. д. | Заменяется текстом, соответствующим захватываемой группе, который можно найти, подсчитав столько открывающих скобок именованных или пронумерованных захватываемых групп, сколько указано числом справа налево, начиная с обратной ссылки. | (a)(b)(c)(d)\g’-3′ соответствует abcdb. | нет | нет | нет | нет | нет | нет | нет | нет | нет | no | no | no | no | no | no | ECMA 1.  47–1.77 47–1.77 | no | no | no | no | no | no | no | no | ||||||||
| Неудачная обратная ссылка | Любая пронумерованная обратная ссылка | Обратные ссылки на группы, которые не участвовали в попытке сопоставления, не совпадают. | (a)?\1 соответствует aa, но не соответствует b. | YES | non‑ECMA | YES | YES | YES | YES | YES | YES | YES | ignored | ignored | ignored | YES | YES | ECMA basic grep Игнорировал | ECMA 1,47–1,77 | Да | Да | N/A | Да | Да | Да | N/A | 65 | N/A | 6669 | N/A | 6669 | N/A | 665 | N/A | 65 | N/A | N/A | . 0063 0063 | Неверная обратная ссылка | Любая пронумерованная обратная ссылка | Обратные ссылки на несуществующие группы действительны, но не соответствуют чему-либо. | (a)?\2|b соответствует b в aab. | error | error | YES | error | error | error | error | error | error | error | error | error | error | 1.8 only | ECMA basic grep error | ECMA basic grep error | error | error | n/a | error | error | error | n/a | error |
| Вложенная обратная ссылка | Любая пронумерованная обратная ссылка | Обратные ссылки можно использовать внутри группы, на которую они ссылаются. | (a\1?){3} соответствует aaaaaa. | YES | YES | YES | YES | YES | YES | YES | YES | YES | ignored | YES | ignored | error | fail | ECMA basic grep error | ECMA BASIC GREP Ошибка | Ошибка | Ошибка | N/A | Ошибка | Ошибка | ошибка | N/A | N/A | N/A | N/A | N/A | N/A | 0068 | |||||||||||||||||||||||||||||||
| Прямая ссылка | Любая пронумерованная обратная ссылка | Обратные ссылки можно использовать перед группой, на которую они ссылаются. |
(\2?(a)){3} соответствует aaaaaa. | YES | non‑ECMA | YES | YES | YES | YES | YES | YES | YES | ignored | error | error | error | YES | ECMA basic grep error | ECMA basic grep error | error | error | n/a | error | error | error | n/a | error | ||||||||||||||||||||||||||||||||||||
| Feature | Syntax | Описание | Пример | JGSOFT | .NET | JAVA | PERL | PCRE | PCRE2 | PCRE | PCRE2 | 9443 PCR0443 JavaScriptVBScript | XRegExp | Python | Ruby | std::regex | Boost | Tcl ARE | POSIX BRE | POSIX ERE | GNU BRE | GNU ERE | Oracle | XML | XPath |
| Быстрый старт | Учебник | Инструменты и языки | Примеры | Ссылка | Обзоры книг |
| Введение | Содержание | Краткий справочник | Персонажи | Основные характеристики | Классы персонажей | Сокращения | Якоря | Границы слов | Квантификаторы | Юникод | Захват групп и обратных ссылок | Именованные группы и обратные ссылки | Специальные группы | Модификаторы режима | Группы рекурсии и балансировки |
| Персонажи | Совпадающий текст и обратные ссылки | Преобразование контекста и регистра | Условные операторы |
Глава 10 Контрасты | Анализ данных с использованием линейных моделей
10.
 1 Введение
1 Введение В главе 6, где мы обсуждали дисперсионный анализ, мы увидели, что можно сравнивать средние значения разных групп. Предположим, мы хотим сравнить средний рост в трех странах A, B и C. Когда мы запускаем линейную модель, мы видим, что обычно первая группа (страна A) становится контрольной группой. Таким образом, на выходе точка пересечения равна среднему значению в этой контрольной группе, а два параметра наклона представляют собой разницу между странами B и A и разницу между странами C и A соответственно. Этот выбор того, какие сравнения выполняются, является выбором по умолчанию. Возможно, у вас возникнет желание провести другие сравнения. Предположим, вы хотите рассматривать страну C в качестве эталонной категории или, возможно, вы хотите провести сравнение между средними значениями стран B и C? В этой главе основное внимание уделяется тому, как сделать выбор в отношении того, какие сравнения вы хотели бы провести. Мы также объясним, как это сделать в R, и в то же время расскажем вам немного больше о том, как работают линейные модели.
10.2 Идея контраста
В этой главе рассматриваются контрасты . Мы начнем с объяснения того, что мы подразумеваем под контрастами и какую роль они играют в линейных моделях с категориальными переменными. В последующих разделах мы обсудим, как указание контрастов может помочь нам сделать стандартный вывод lm() более актуальным и простым для интерпретации.
Контраст представляет собой линейную комбинацию параметров или статистики. Другое название линейной комбинации — 9.0267 взвешенная сумма . Уравнение регрессии, подобное \(b_1 X_1 + b_2X_2\), также является линейной комбинацией: линейной комбинацией независимых переменных \(X_1\) и \(X_2\) с весами \(b_1\) и \(b_2\ ) (поэтому и говорим о линейных моделях ).
Вместо переменных давайте сейчас сосредоточимся на двух выборочных статистических данных: среднем кровяном давлении \(M_{голландский}\) в случайной выборке двух голландцев и среднем кровяном давлении \(M_{немецкий}\) в случайной выборке два немца. Мы можем взять сумму этих двух средних и назвать ее \(L1\).
Мы можем взять сумму этих двух средних и назвать ее \(L1\).
\[L1 = M_{немецкий} + M_{голландский}\]
Обратите внимание, что это эквивалентно определению \(L1\) как
\[L1 = 1 \times M_{немецкий} + 1 \times M_ {Голландский}\] Это взвешенная сумма, где веса двух статистик равны 1 и 1 соответственно. В качестве альтернативы вы можете использовать другие веса, например 1 и -1. Назовем такой контраст \(L2\):
\[L2 = 1 \times M_{немецкий} — 1 \times M_{голландский}\] Это \(L2\) можно упростить до
\[L2 = M_{немецкий} — M_{голландский}\] что показывает, что тогда \(L2\) равно разнице между средним немецким и голландским средним. Если \(L2\) положителен, это означает, что среднее немецкое значение выше, чем среднее голландское. Когда \(L2\) отрицательное, это означает, что среднее голландское значение выше. Мы также можем сказать, что \(L2\) противопоставляет немецкое среднее значение голландскому среднему.
Пример
Если мы определим \(L2 = M_{немецкий} — M_{голландский}\) и обнаружим, что \(L2\) равно +2,13, это означает, что среднее значение немцев на 2,13 единицы выше чем среднее значение голландцев. Если мы находим 95% доверительный интервал для \(L2\) <1,99, 2,27>, это означает, что наилучшее предположение состоит в том, что среднее значение населения Германии на 1,99–2,27 единицы выше, чем среднее значение населения Нидерландов.
Если мы находим 95% доверительный интервал для \(L2\) <1,99, 2,27>, это означает, что наилучшее предположение состоит в том, что среднее значение населения Германии на 1,99–2,27 единицы выше, чем среднее значение населения Нидерландов.
Если бы мы зафиксировали порядок двух средних \(M_{немецкий}\) и \(M_{голландский}\), мы могли бы сделать хороший краткий обзор для контраста. Предположим, мы расположим группы в алфавитном порядке: сначала голландцы, затем немцы. Это означает, что мы также фиксируем порядок весов: первый вес принадлежит группе, которая идет первой по алфавиту, а второй вес принадлежит группе, которая идет второй по алфавиту. Затем мы могли бы обобщить \(L1\), указав только веса: 1 и 1. Более распространенный способ отображения этих значений — использование вектор-строка :
\[\textbf{L1} = \begin{bmatrix} 1 и 1 \end{bmatrix}\]
, представляющее \(1 \times M_{голландский} + 1 \times M_{немецкий}\). Контраст \(L2\) можно представить как -1 и 1, чтобы представить \(-1 \times M_{голландский} + 1\times M_{немецкий}\). Записав вектор-строку, мы получим
Записав вектор-строку, мы получим
\[\textbf{L2} = \begin{bmatrix} -1 и 1 \end{bmatrix}\]
Мы можем объединить эти два вектора-строки, наклеив их друг на друга, и отобразить их как контрастную матрицу \(\textbf{L}\) с двумя строками и двумя столбцами:
\[\textbf{L} = \begin{bmatrix} \textbf{L1} \\ \textbf{L2} \end{bmatrix} = \begin{bmatrix} 1 и 1 \\ -1 и 1 \end{bmatrix}\]
Таким образом, контраст является взвешенной суммой групповых средних и может быть суммирован весами для соответствующих групповых средних. Несколько контрастов, представленных в виде векторов-строк, могут быть объединены в матрицу контрастов. Ниже мы обсудим, почему эта простая идея контрастов представляет интерес при обсуждении линейных моделей. Но сначала давайте сделаем краткий обзор того, что мы узнали в предыдущих главах.
10.3 Краткий обзор
Давайте кратко повторим, что мы узнали ранее о линейных моделях при работе с категориальными переменными. В главе 4 мы познакомились с простейшей линейной моделью: числовая зависимая переменная Y и одна числовая независимая переменная X . В главе 6 мы видели, что мы можем использовать эту структуру, когда мы хотим использовать категориальную переменную X . Предположим, что X имеет две категории, скажем, «голландский» и «немецкий», чтобы указать национальность участников исследования артериального давления. Мы увидели, что можем создать числовую переменную, состоящую только из 1 и 0, которая передает ту же информацию о национальности. Такая числовая переменная, содержащая только 1 и 0, обычно называется фиктивной переменной. Давайте используем фиктивную переменную для кодирования национальности и назовем эту переменную 9.0027 немецкий . Все участники, которые являются немцами, кодируются как 1 для этой переменной, а все остальные участники кодируются как 0. В таблице 10.1 показан небольшой пример воображаемых данных о диастолическом артериальном давлении.
В главе 6 мы видели, что мы можем использовать эту структуру, когда мы хотим использовать категориальную переменную X . Предположим, что X имеет две категории, скажем, «голландский» и «немецкий», чтобы указать национальность участников исследования артериального давления. Мы увидели, что можем создать числовую переменную, состоящую только из 1 и 0, которая передает ту же информацию о национальности. Такая числовая переменная, содержащая только 1 и 0, обычно называется фиктивной переменной. Давайте используем фиктивную переменную для кодирования национальности и назовем эту переменную 9.0027 немецкий . Все участники, которые являются немцами, кодируются как 1 для этой переменной, а все остальные участники кодируются как 0. В таблице 10.1 показан небольшой пример воображаемых данных о диастолическом артериальном давлении.
| участник | Национальность | Немецкий | bp_diastolic |
|---|---|---|---|
| 1 | Голландский | 0 | 92 |
| 2 | Немецкий | 1 | 97 |
| 3 | Немецкий | 1 | 89 |
| 4 | Голландский | 0 | 92 |
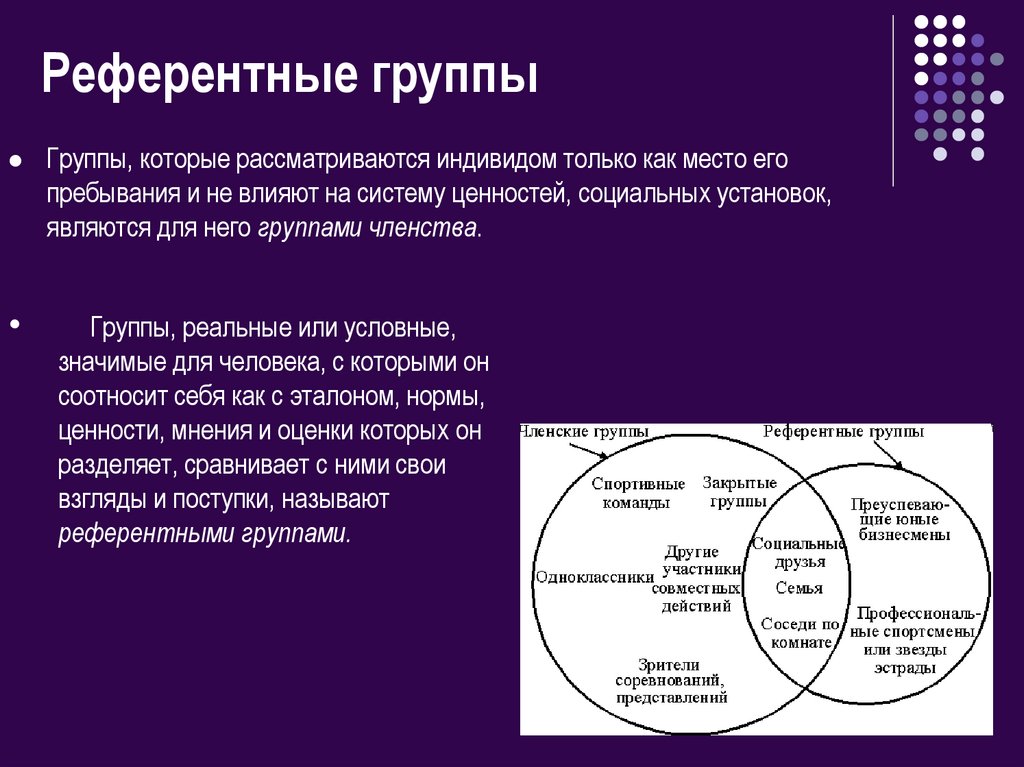
Мы узнали, что можем включить такую фиктивную переменную в качестве числового предиктора в модель линейной регрессии, здесь с bp_diastolic (диастолическое кровяное давление) в качестве зависимой переменной. Данные и линия регрессии МНК представлены на рис. 10.1.
Рисунок 10.1: Линейная регрессия диастолического артериального давления по фиктивной переменной German.
Мы узнали, что наклон модели с такой фиктивной переменной можно интерпретировать как разницу средних значений для двух групп. В этом случае наклон равен разнице средних значений двух групп в выборочных данных. Среднее кровяное давление у голландцев составляет \(\frac{92+92}{2}=\) 92, а у немцев это \(\frac{89+97}{2}=\) 93. увеличивают среднее кровяное давление на , если перейти от немецкого = 0 (голландский ) на немецкий = 1 (немецкий), следовательно, равен +1.
В этом случае наклон равен разнице средних значений двух групп в выборочных данных. Среднее кровяное давление у голландцев составляет \(\frac{92+92}{2}=\) 92, а у немцев это \(\frac{89+97}{2}=\) 93. увеличивают среднее кровяное давление на , если перейти от немецкого = 0 (голландский ) на немецкий = 1 (немецкий), следовательно, равен +1.
Это также то, что мы увидим, если R вычислит для нас регрессию, см. Таблицу 10.2.
| срок | оценивать | стандартная ошибка | статистика | р.значение |
|---|---|---|---|---|
| (Перехват) | 92 | 2,828 | 32,527 | 0,0009 |
| Немецкий | 1 | 4.000 | 0,250 | 0,8259 |
Мы видим, что принадлежность к немцам влияет на +1 единицу по шкале артериального давления, при этом референтной группой являются лица, не являющиеся немцами (голландцами). Перехват имеет значение 92, и это среднее кровяное давление в ненемецкой группе. Таким образом, мы можем рассматривать этот +1 как разницу между средним артериальным давлением в Германии и средним артериальным давлением в Нидерландах.
Перехват имеет значение 92, и это среднее кровяное давление в ненемецкой группе. Таким образом, мы можем рассматривать этот +1 как разницу между средним артериальным давлением в Германии и средним артериальным давлением в Нидерландах.
Теперь предположим, что у нас не две группы, а три. В главе 6 мы узнали, что у нас может быть гипотеза о средних значениях нескольких групп. Предположим, у нас есть данные из трех групп, скажем, голландской, немецкой и итальянской. Данные приведены в таблице 10.3.
| участник | Национальность | bp_diastolic |
|---|---|---|
| 1 | Голландский | 92 |
| 2 | Немецкий | 97 |
| 3 | Немецкий | 89 |
| 4 | Голландский | 92 |
| 5 | итальянский | 91 |
| 6 | итальянский | 96 |
Когда мы запускаем дисперсионный анализ, нулевая гипотеза утверждает, что средние значения трех групп в совокупности равны. Например, среднее диастолическое кровяное давление может быть 92 для голландцев, 93 для немцев и 93,5 для итальянцев, но это может получиться, когда фактические средние значения в популяции одинаковы: \(\mu_{голландцы}= \mu_{ немецкий} = \mu_{итальянский}\).
Например, среднее диастолическое кровяное давление может быть 92 для голландцев, 93 для немцев и 93,5 для итальянцев, но это может получиться, когда фактические средние значения в популяции одинаковы: \(\mu_{голландцы}= \mu_{ немецкий} = \mu_{итальянский}\).
Если бы мы запустили дисперсионный анализ, мы могли бы получить следующие результаты
выход %>% анова() %>% tidy()
## # Набор символов: 2 × 6 ## term df sumsq означает q статистика p.value #### 1 национальность 2 2,33 1,17 0,0787 0,926 ## 2 Остатки 3 44,5 14,8 NA NA
Мы видим \(F\)-критерий с 2 и 3 степенями свободы. 2 получается из-за того, что у нас есть три группы. Этот тест касается равенства трех групповых средних. Сравните это с эффектами автоматически созданных фиктивных переменных в lm() анализ ниже:
out %>% tidy()
## # tibble: 3 × 5 ## оценка срока std.error statistic p.value #### 1 (Перехват) 92,0 2,72 33,8 0,0000570 ## 2 национальностьнемец 1,00 3,85 0,260 0,812 ## 3 национальностьитальянец 1. 50 3.85 0.389 0.723
В выводе первый \(t\)-критерий (33.8) говорит о равенстве среднего АД в первой группе и 0. Второй \(t\)-критерий (0.26) — о равенстве средних в группах 1 и 2, а третий \(t\)-критерий (0,389) о равенстве средних в группах 1 и 3. \(F\)-критерий из дисперсионного анализа можно рассматривать как комбинацию двух отдельных \(t\)-тестов: второго и третьего в этом примере , которые касаются равенства двух последних групповых средних и первого. Эти два эффекта получены из двух фиктивных переменных, созданных для кодирования категориальной переменной национальность .
В ходе исследования, которое вы проводите, важно четко понимать, что вы на самом деле хотите узнать из данных. Если вы хотите узнать, могли ли данные быть получены в результате ситуации, когда средние значения всех групп населения равны, то наиболее подходящим является \(F\)-тест. Если вас больше интересует, равны ли различия между определенными странами и первой страной (эталонной страной) в населении 0, обычные lm() таблица со стандартными \(t\)-тестами более уместна.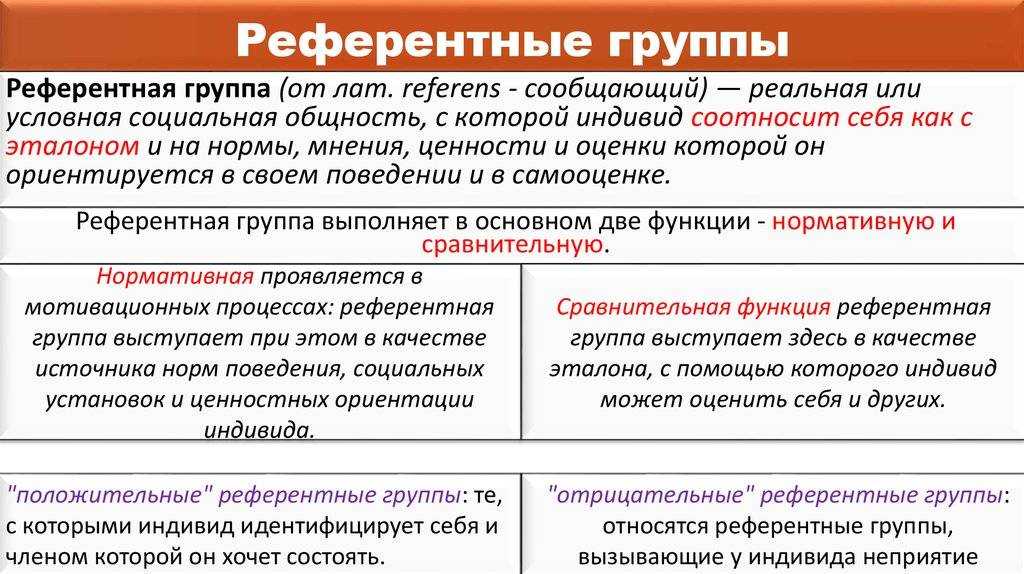 Если вас интересуют другие типы вопросов, продолжайте читать.
Если вас интересуют другие типы вопросов, продолжайте читать.
10.4 Контрасты и фиктивное кодирование
В предыдущем разделе мы видели, что когда мы запускаем линейную модель с категориальным предиктором с двумя категориями, мы фактически запускаем линейную регрессию с фиктивной переменной. Когда фиктивная переменная кодирует категорию немецкий язык, мы видим, что наклон такой же, как среднее значение немецкой категории минус среднее значение контрольной группы. И мы видим, что точка пересечения такая же, как среднее значение контрольной группы (негерманской группы). Мы видим, что фиктивная переменная равна 1 для немцев и 0 для голландцев, и что использование этой фиктивной переменной в анализе приводит к двум параметрам: (1) точке пересечения и (2) наклону. На самом деле эти два параметра представляют два контрастирует с . Первый параметр противопоставляет разницу между голландским средним значением и 0 (опять же, голландцы идут первыми по алфавиту, а затем вес для немцев):
\[L1 = M_{голландский} = M_{голландский} — 0 = 1 \times M_{Голландский} — 0 \times M_{Немецкий}\]
В выводе R этот параметр (или контраст) называется ‘(Intercept)’.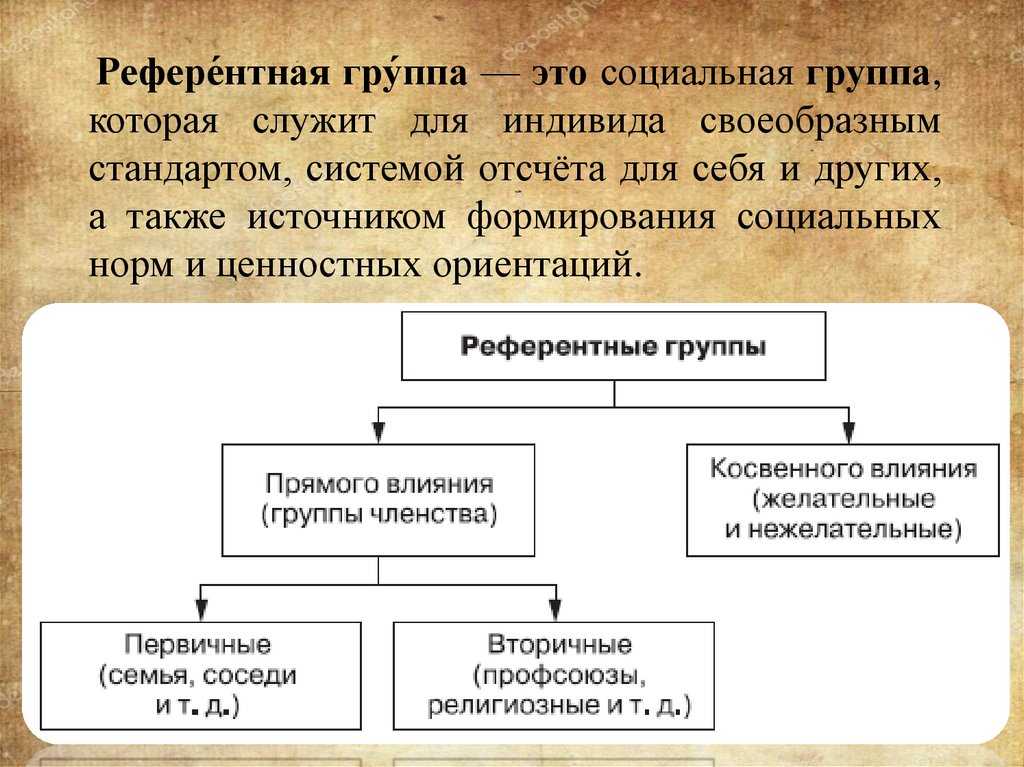 Второй параметр сравнивает немецкое среднее со средним голландским:
Второй параметр сравнивает немецкое среднее со средним голландским:
\[L2 = M_{немецкий} — M_{голландский} = — 1 \times M_{голландский} + 1 \times M_{немецкий}\] Этот параметр часто обозначается как наклон. В таблице 10.2 выше он обозначен как «немецкий».
Эти два контраста могут быть представлены в виде матрицы контрастов, содержащей две строки
\[\textbf{L} = \begin{bmatrix} 1 и 0 \\ -1 и 1 \end{bmatrix}\]
Предположим, мы хотим получить другой результат. Предположим, вместо этого мы хотим сначала увидеть в выходных данных среднее значение для немцев, а затем дополнительное кровяное давление для голландцев. Ранее мы узнали, что мы можем получить это, используя фиктивную переменную для того, чтобы быть голландцем, так что немецкая группа становится контрольной группой. Здесь мы сосредоточимся на контрастах. Предположим, мы хотим, чтобы немцы составили референтную группу, тогда мы должны оценить контраст:
\[L3: M_{немецкий} = 0\times M_{голландский} + 1 \times M_{немецкий}\]
, и тогда мы можем противопоставить голландцев этой контрольной группе:
\[L4: M_{ Голландский} — M_{Немецкий} = 1 \times M_{Голландский} -1 \times M_{Немецкий}\] Тогда у нас есть следующая контрастная матрица:
\[\textbf{L} = \begin{bmatrix} 0 и 1 \\ 1 и -1 \end{bmatrix}\]
Вы видите, что когда вы делаете выбор в отношении фиктивной переменной (либо кодирование немца, либо кодирование голландца), этот выбор напрямую влияет на контрасты, которые вы делаете в регрессионном анализе (т.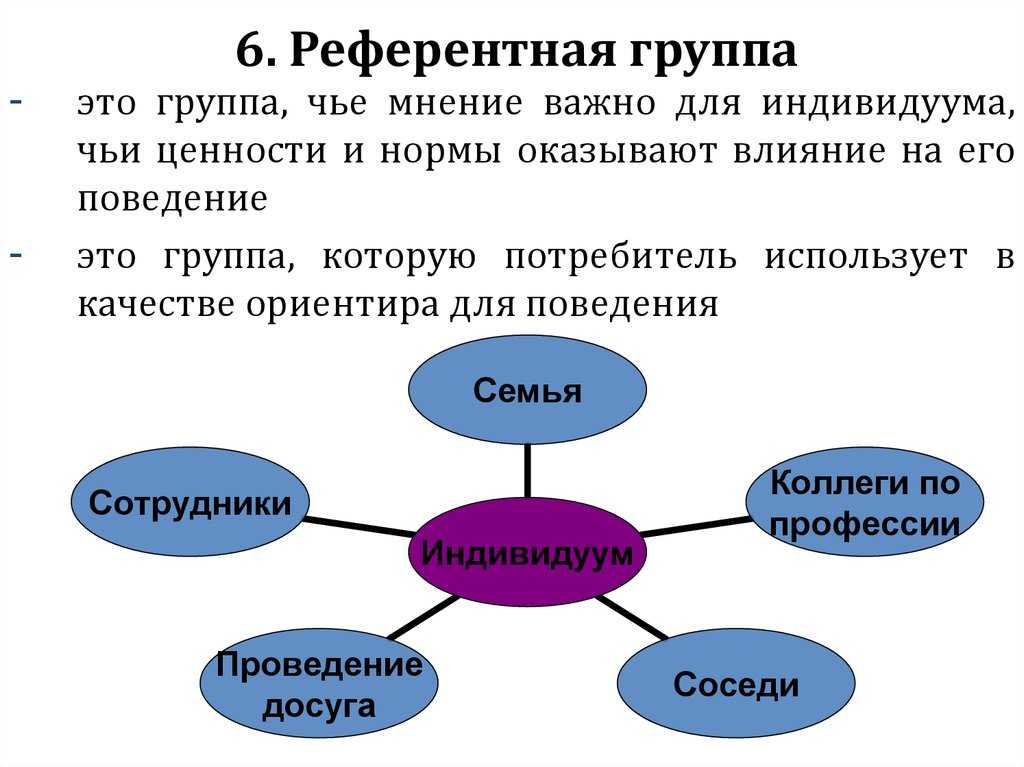 е. результат, который вы получите). При использовании фиктивной переменной German , вывод дает контрасты \(L1\) и \(L2\), тогда как использование фиктивной переменной Dutch приводит к выводу контрастов \(L3\) и \(L4\).
е. результат, который вы получите). При использовании фиктивной переменной German , вывод дает контрасты \(L1\) и \(L2\), тогда как использование фиктивной переменной Dutch приводит к выводу контрастов \(L3\) и \(L4\).
Чтобы было немного интереснее, давайте рассмотрим пример данных с тремя национальностями: голландцами, немцами и итальянцами. Предположим, мы хотим использовать немецкую группу в качестве контрольной группы. Затем мы можем использовать следующий контраст (перехват):
\[L1: M_{немецкий}\] Далее нас интересует разница между голландцами и этой референтной группой:
\[L2 : M_{голландский} — M_{немецкий}\]
и разница между итальянским и этой контрольной группой:
\[L3: M_{итальянский} — M_{немецкий}\] Если мы снова расположим три категории в алфавитном порядке, мы можем суммировать эти три контраста с помощью матрицы контрастов
\[\textbf{L} = \begin{bmatrix} 0 и 1 и 0\\ 1 и -1 и 0 \\ 0 и -1 и 1 \end{bmatrix}\]
(пожалуйста, проверьте это сами).
Основываясь на том, что мы узнали из предыдущих глав, мы знаем, что можем получить эти сравнения, вычислив фиктивную переменную для того, чтобы быть голландцем, и фиктивную переменную для того, чтобы быть итальянцем, и использовать их в линейной регрессии. Мы видим эти фиктивные переменные голландский и итальянский в таблице 10.4.
| участник | Национальность | Голландский | итальянский | bp_diastolic |
|---|---|---|---|---|
| 1 | Голландский | 1 | 0 | 92 |
| 2 | Немецкий | 0 | 0 | 97 |
| 3 | Немецкий | 0 | 0 | 89 |
| 4 | Голландский | 1 | 0 | 92 |
| 5 | итальянский | 0 | 1 | 91 |
| 6 | итальянский | 0 | 1 | 96 |
В этом разделе показано, что если вы измените фиктивное кодирование, вы измените контрасты, которые вы вычисляете в анализе. Существует тесная связь между контрастами и фактическими фиктивными переменными, которые используются в анализе. Мы обсудим это в следующем разделе.
Существует тесная связь между контрастами и фактическими фиктивными переменными, которые используются в анализе. Мы обсудим это в следующем разделе.
10.5 Связь между схемами контраста и кодирования
Мы видели, что то, какое фиктивное кодирование вы используете, определяет контрасты, которые вы получаете на выходе линейной модели. В этом разделе мы обсудим эту сложную связь. Как мы видели ранее, контрасты могут быть представлены в виде матрицы \(\mathbf{L}\), где каждая строка представляет контраст. Теперь давайте сосредоточимся на фиктивном кодировании. То, как мы кодируем фиктивные переменные, можно представить в виде матрицы \(\mathbf{S}\), где каждый столбец дает информацию о том, как кодировать новую числовую переменную.
В качестве простого примера см. следующую матрицу
\[\mathbf{S} =\begin{bmatrix} 1 и 0 \\ 0 и 1 \end{bmatrix}\]
Каждая строка в этой матрице представляет категорию: первая строка для первой категории, а вторая строка для второй категории. Столбцы представляют схему кодирования для новых переменных. В первом столбце указана схема кодирования для первой новой переменной. Значения — это значения, которые следует использовать при построении новых переменных. Первый столбец \(\mathbf{S}\) определяет фиктивную переменную, где первая категория кодируется как 1, а вторая категория как 0. Второй столбец указывает обратное: фиктивная переменная, которая кодирует первую категорию как 0 и вторая категория как 1.
Столбцы представляют схему кодирования для новых переменных. В первом столбце указана схема кодирования для первой новой переменной. Значения — это значения, которые следует использовать при построении новых переменных. Первый столбец \(\mathbf{S}\) определяет фиктивную переменную, где первая категория кодируется как 1, а вторая категория как 0. Второй столбец указывает обратное: фиктивная переменная, которая кодирует первую категорию как 0 и вторая категория как 1.
Если вам нужна короткая история о том, как связаны (фиктивное) кодирование и контрасты: матрица \(\mathbf{S}\) (схема кодирования) представляет собой , обратную матрицы контраста \(\mathbf{L} \). То есть, если у вас есть матрица \(\mathbf{L}\) и вы хотите узнать схему кодирования \(\mathbf{S}\), вы можете просто попросить R вычислить обратную \(\mathbf{L }\). Это также происходит и наоборот: если вы знаете, какое кодирование используется, вы можете использовать обратную схему кодирования, чтобы определить, что представляет собой вывод. Если вы хотите узнать, что подразумевается под инверсией, см. расширенный интерактивный раздел ниже, хотя это не обязательно знать. Чтобы работать с линейными моделями в R, достаточно знать, как вычислить обратную модель в R.
Если вы хотите узнать, что подразумевается под инверсией, см. расширенный интерактивный раздел ниже, хотя это не обязательно знать. Чтобы работать с линейными моделями в R, достаточно знать, как вычислить обратную модель в R.
Пристальный взгляд на матрицы \(\mathbf{L}\) и \(\mathbf{S}\) и их связь
По умолчанию R упорядочивает категории фактора в алфавитном порядке. Если у нас есть две группы, R по умолчанию использует следующую схему кодирования :
\[\textbf{S} = \begin{bmatrix} 1 и 0 \\ 1 и 1 \end{bmatrix}\]
Эта матрица состоит из двух строк и двух столбцов. Каждая строка представляет категорию. В нашем предыдущем примере первая категория — «Голландский», а вторая — «Немецкий» (категории отсортированы по алфавиту). Каждая столбец матрицы \(\mathbf{S}\) представляет новую числовую переменную, которую R будет вычислять для кодирования категориальной факторной переменной. Первый столбец (представляющий новую числовую переменную) говорит, что для обеих категорий (строк) новая переменная получает значение 1. Второй столбец содержит 0 и 1. Он говорит, что первая категория закодирована как 0, а вторая категория кодируется как 1.
Первый столбец (представляющий новую числовую переменную) говорит, что для обеих категорий (строк) новая переменная получает значение 1. Второй столбец содержит 0 и 1. Он говорит, что первая категория закодирована как 0, а вторая категория кодируется как 1.
Таким образом, эта матрица говорит о том, что мы должны создать две новые переменные. Они показаны в таблице 10.5, где мы называем их 9.0027 Intercept и немецкий соответственно. Почему мы называем вторую новую переменную German , очевидно: это просто фиктивная переменная для кодирования «немецкого» как 1. Почему мы называем первую переменную Intercept менее очевидно, но мы вернемся к этому позже.
| участник | Национальность | Перехват | Немецкий | bp_diastolic |
|---|---|---|---|---|
| 1 | Голландский | 1 | 0 | 92 |
| 2 | Немецкий | 1 | 1 | 97 |
| 3 | Немецкий | 1 | 1 | 89 |
| 4 | Голландский | 1 | 0 | 92 |

Таким образом, с матрицей \(\mathbf{S}\) у вас есть вся информация, необходимая для выполнения линейного регрессионного анализа только с числовыми переменными.
С матрицей \(\mathbf{S}\) по умолчанию, какие контрасты мы получим и как это узнать? Оказывается, как только вы знаете \(\mathbf{S}\), вы можете немедленно вычислить (или заставить вычислить R), какую контрастную матрицу \(\mathbf{L}\) вы получите. Связь между матрицами \(\mathbf{L}\) и \(\mathbf{S}\) такая же, как связь между 4 и \(\frac{1}{4}\). {-1}= \mathbf{I}\), где матрица \(\mathbf{I}\) является матричным аналогом 1 и называется 9{-1}=\mathbf{L}\). Отсюда следует, что \(\mathbf{L} \mathbf{S} = \mathbf{I}\). Единственная разница с обратными числами состоит в том, что \(\mathbf{L}\) и \(\mathbf{S}\) являются матрицами, так что мы фактически выполняем матричную алгебру , которая немного отличается от алгебры с единичные номера. Тем не менее, если мы умножим матрицы \(\mathbf{L}\) и \(\mathbf{S}\), мы получим матрицу \(\mathbf{I}\). Эта матрица, как мы сказали, представляет собой единичную матрицу , что означает, что она имеет только 1 по диагонали (сверху слева вниз справа) и 0 в других местах:
{-1}= \mathbf{I}\), где матрица \(\mathbf{I}\) является матричным аналогом 1 и называется 9{-1}=\mathbf{L}\). Отсюда следует, что \(\mathbf{L} \mathbf{S} = \mathbf{I}\). Единственная разница с обратными числами состоит в том, что \(\mathbf{L}\) и \(\mathbf{S}\) являются матрицами, так что мы фактически выполняем матричную алгебру , которая немного отличается от алгебры с единичные номера. Тем не менее, если мы умножим матрицы \(\mathbf{L}\) и \(\mathbf{S}\), мы получим матрицу \(\mathbf{I}\). Эта матрица, как мы сказали, представляет собой единичную матрицу , что означает, что она имеет только 1 по диагонали (сверху слева вниз справа) и 0 в других местах:
\[\mathbf{L}\mathbf{S} = \mathbf{S}\mathbf{L} = \mathbf{I} = \begin{bmatrix} 1 и 0 \\ 0 и 1 \end{bmatrix}\]
Оказывается, если у нас есть \(\mathbf{S}\), как определено выше (схема кодирования по умолчанию), матрица контраста \(\mathbf{L}\) может быть только
\[\mathbf{L} = \begin{bmatrix} 1 и 0 \\ -1 и 1 \end{bmatrix}\]
или полностью:
\[\mathbf{S}\mathbf{L} = \begin{bmatrix} 1 и 0 \\ 1 и 1 \end{bmatrix} \times \begin{bmatrix} 1 и 0 \\ -1 и 1 \end{bmatrix} = \begin{bmatrix} 1 и 0 \\ 0 и 1 \end{bmatrix}\]
Обратите внимание, что при изучении этой книги вам не обязательно знать матричную алгебру, но она помогает понять, что происходит при выполнении линейного регрессионного анализа с категориальными переменными. Поручив R выполнять матричную алгебру за вас, вы можете полностью контролировать, какой результат вы хотите получить от анализа.
Поручив R выполнять матричную алгебру за вас, вы можете полностью контролировать, какой результат вы хотите получить от анализа.
10.6 Работа с матрицами \(\mathbf{S}\) и \(\mathbf{L}\) в R
В предыдущем разделе мы видели, что матрица схемы кодирования \(\mathbf{S}\) является обратная матрица контраста \(\mathbf{L}\), а матрица контраста \(\mathbf{L}\) является обратной матрицей схемы кодирования \(\mathbf{S}\). В этом разделе мы увидим, как вычислить обратную матрицу R.
Давайте снова возьмем пример с кровяным давлением, где у нас были данные по трем национальностям: в алфавитном порядке данные по Голландии, затем данные по Германии и, наконец, данные по Италии.
Предположим, мы хотим использовать немецкую группу в качестве эталонной группы. Затем нам понадобится матрица \(\mathbf{L}\), подобная той, что использовалась в предыдущем разделе, с национальностями голландец, немец и итальянец (в алфавитном порядке), с немецким языком в качестве эталонной категории (вторая группа). Мы вводим эту контрастную матрицу \(\mathbf{L}\) в R следующим образом:
Мы вводим эту контрастную матрицу \(\mathbf{L}\) в R следующим образом:
L <- матрица(с(0, 1, 0,
1, -1, 0,
0, -1, 1), по ряду = ИСТИНА, по ряду = 3)
L ## [1] [2] [3] ## [1,] 0 1 0 ## [2,] 1 -1 0 ## [3,] 0 -1 1
Первая строка представляет собой контраст среднего значения второй группы (немецкой). Второй ряд противопоставляет первую группу (голландский) второй группе (немецкий). В третьем ряду третья группа (итальянская) противопоставляется второй группе (немецкой).
Если нас интересует матрица схемы кодирования, мы возьмем обратную матрицу \(\mathbf{L}\), чтобы получить матрицу \(\mathbf{S}\), используя Функция ginv() , доступная в пакете MASS .
библиотека(МАСС) S <- ginv(L) # S вычисляется как величина, обратная L S %>%fractions() # чтобы получить более читаемый вывод
## [1] [2] [3] ## [1,] 1 1 0 ## [2,] 1 0 0 ## [3,] 1 0 1
Вывод представляет собой матрицу схемы кодирования с 3 столбцами :
\[\textbf{S} = \begin{bmatrix} 1 и 1 и 0\\ 1 и 0 и 0 \\ 1 и 0 и 1 \end{bmatrix}\]
Эта матрица схемы кодирования \(\mathbf{S}\) говорит нам, какие переменные нужно вычислить, чтобы получить эти контрасты в \(\mathbf{L}\) на выходе линейной модели. Каждый столбец \(\mathbf{S}\) содержит информацию для каждой новой переменной. Поскольку у нас есть три столбца, мы знаем, что нам нужно вычислить три переменные. Первый столбец сообщает нам, что первая переменная состоит из значения 1 для всех групп. Мы вернемся к этой переменной в 1 с позже (она представляет собой перехват). Второй столбец указывает, что нам нужна фиктивная переменная, которая кодирует первую группу (голландский язык) как 1, а две другие группы как 0. В третьем столбце говорится, что нам нужна третья переменная, которая также является фиктивной переменной, кодирующей 1 для группы 3 ( итальянский) и 0 для двух других групп.
Каждый столбец \(\mathbf{S}\) содержит информацию для каждой новой переменной. Поскольку у нас есть три столбца, мы знаем, что нам нужно вычислить три переменные. Первый столбец сообщает нам, что первая переменная состоит из значения 1 для всех групп. Мы вернемся к этой переменной в 1 с позже (она представляет собой перехват). Второй столбец указывает, что нам нужна фиктивная переменная, которая кодирует первую группу (голландский язык) как 1, а две другие группы как 0. В третьем столбце говорится, что нам нужна третья переменная, которая также является фиктивной переменной, кодирующей 1 для группы 3 ( итальянский) и 0 для двух других групп.
Если мы применим эту схему кодирования к нашему набору данных, то мы получим следующую матрицу данных:
| участник | Национальность | bp_diastolic | v1 | v2 | v3 |
|---|---|---|---|---|---|
| 1 | Голландский | 92 | 1 | 1 | 0 |
| 2 | Немецкий | 97 | 1 | 0 | 0 |
| 3 | Немецкий | 89 | 1 | 0 | 0 |
| 4 | Голландский | 92 | 1 | 1 | 0 |
| 5 | итальянский | 91 | 1 | 0 | 1 |
| 6 | итальянский | 96 | 1 | 0 | 1 |
Теперь давайте проделаем упражнение наоборот. Если вы знаете схему кодирования (как кодируются ваши фиктивные переменные), вы можете легко определить, что будет представлять вывод. Например, пусть \(\mathbf{S}\) будет схемой кодирования для фиктивной переменной для группы 1 (голландский) и фиктивной переменной для группы 2 (немецкий) (с контрольной группой «Итальянский»). Мы вводим это в R:
Если вы знаете схему кодирования (как кодируются ваши фиктивные переменные), вы можете легко определить, что будет представлять вывод. Например, пусть \(\mathbf{S}\) будет схемой кодирования для фиктивной переменной для группы 1 (голландский) и фиктивной переменной для группы 2 (немецкий) (с контрольной группой «Итальянский»). Мы вводим это в R:
S <- матрица(с(1, 0,
0, 1,
0, 0), byrow = TRUE, nrow = 3) По умолчанию любой анализ lm() включает перехват, а перехват всегда кодируется как 1. Поэтому мы добавляем переменную только из 1 для представления перехвата (почему включены эти 1, станет ясно).
S <- cbind(1, S) S
## [1] [2] [3] ## [1,] 1 1 0 ## [2,] 1 0 1 ## [3,] 1 0 0
Затем мы можем определить, к каким контрастам приведут эти три переменные, взяв обратную для вычисления матрицы контраста \(\mathbf{L}\):
Л <- ginv(S) L %>% дроби() # для удобочитаемости
## [1] [2] [3] ## [1,] 0 0 1 ## [2,] 1 0 -1 ## [3,] 0 1 -1
Эта матрица \(\mathbf{L}\) содержит три строки, по одной для каждого контраста. Первая строка дает контраст \(L1\), который равен \(0 \times M_1 + 0 \times M_2 + 1 \times M_3\), что равно \(M_3\) (итальянское среднее значение). Вторая строка дает контраст \(1\times M_1 + 0 \times M_2 - 1\times M_3\), который составляет среднее значение первой группы минус последнее, \(M_1 - M_3\) (разница между голландским и итальянским). Третья строка дает контраст \(0\times M_1 + 1\times M_2 - 1\times M_3\), который равен \(M_2 - M_3\) (разница между немецким и итальянским языками).
Первая строка дает контраст \(L1\), который равен \(0 \times M_1 + 0 \times M_2 + 1 \times M_3\), что равно \(M_3\) (итальянское среднее значение). Вторая строка дает контраст \(1\times M_1 + 0 \times M_2 - 1\times M_3\), который составляет среднее значение первой группы минус последнее, \(M_1 - M_3\) (разница между голландским и итальянским). Третья строка дает контраст \(0\times M_1 + 1\times M_2 - 1\times M_3\), который равен \(M_2 - M_3\) (разница между немецким и итальянским языками).
Помните, что матрица контраста \(\mathbf{L}\) организована в строк , тогда как матрица схемы кодирования \(\mathbf{S}\) организована в столбцов . Один из способов запомнить это — понять, что матрица схемы кодирования \(\mathbf{S}\) определяет новые переменные, а переменные организованы как столбцы в матрице данных, как вы помните из главы 1.
Вы можете задаться вопросом, что эта переменная только с 1 делает в этой истории? Разве мы не узнали, что нам нужно вычислить только 2 фиктивные переменные для категориальной переменной с 3 категориями? Короткий ответ: переменная только с 1 (для всех категорий) представляет точку пересечения, которая всегда включена в линейную модель по умолчанию. Для получения дополнительных пояснений нажмите на ссылку ниже.
Пристальный взгляд на точку пересечения, представленную в виде переменной с единицами
В большинстве регрессионных анализов мы хотим включить точку пересечения в линейную модель. Это происходит так часто, что мы забываем, что здесь у нас есть выбор. Например, в R перехват включен по умолчанию. Например, если вы используете код с формулой bp_diastolic ~ национальность , вы получите тот же результат, что и с bp_diastolic ~ 1 + национальность 9.0018 . Другими словами, по умолчанию R вычисляет переменную, состоящую только из единиц. Это можно увидеть, если мы воспользуемся функцией model.matrix() . Эта функция показывает фактические переменные, которые вычисляются R и используются в анализе.
лм(bp_diastolic ~ национальность, данные = кровяное давление) %>% model.matrix()
## (Перехват) национальностьнемецкая национальностьитальянец ## 1 1 0 0 ## 2 1 1 0 ## 3 1 1 0 ## 4 1 0 0 ## 5 1 0 1 ## 6 1 0 1 ## атрибут(,"назначить") ## [1] 0 1 1 ## attr(,"контрасты") ## attr(,"contrasts")$национальность ## [1] "контр.обработка"
В выходных данных мы видим фактические числовые переменные, которые используются в анализе для шести наблюдений в наборе данных (шесть строк). В совокупности эти переменные, отображаемые в виде столбцов в матрице, называются матрицей проекта .
Мы видим переменную с именем (Intercept) , состоящую только из единиц и двух фиктивных переменных, одну кодировку для немцев с именем nationalityGerman и одну кодировку для итальянцев с именем nationalityItalian . Эти имена переменных мы снова видим, когда смотрим на результаты lm() анализ:
lm(bp_diastolic ~ национальность, данные = кровяное давление) %>% tidy()
## # Набор символов: 3 × 5 ## оценка срока std.error statistic p.value #### 1 (Перехват) 92,0 2,72 33,8 0,0000570 ## 2 национальностьнемец 1,00 3,85 0,260 0,812 ## 3 национальностьитальянец 1,50 3,85 0,389 0,723
Теперь имена вновь вычисляемых переменные стали именами параметров (параметры пересечения и наклона). Эти значения параметров на самом деле представляют (по умолчанию) контрастов \(L1\), \(L2\) и \(L3\), здесь количественно выраженные как 92,0, 1,0 и 1,5 соответственно. «Пересечение» 92,0 — это просто величина, которую мы находим для первого контраста (первая строка в матрице контрастов \(\mathbf{L}\)).
Таким образом, когда у вас есть три группы, вы можете изобрести количественную переменную, называемую (отрезок), которая равна 1 для всех наблюдений в вашей матрице данных. Если затем вы также изобретете фиктивную переменную для того, чтобы быть немцем, и фиктивную переменную для того, чтобы быть итальянцем, и подвергнуть эти три переменные анализу линейной модели, результат даст среднее значение для голландцев, разницу между средним значением для Германии и средним значением для Нидерландов. , и разница между средним значением в Италии и средним значением в Нидерландах. В приведенном ниже коде вы видите, что на самом деле происходит: вычисление трех переменных и отправка этих трех переменных в лм() анализ. Обратите внимание, что R по умолчанию включает перехват. Чтобы подавить это поведение, мы включаем -1 в формулу:
dummy_German <- c(0, 1, 1, 0, 0, 0) dummy_Italian <- c(0, 0, 0, 0, 1, 1) ИНТЕРЦЕПТ <- c(1, 1, 1, 1, 1, 1) bp_diastolic <- c(92, 97, 89, 92, 91, 96) lm(bp_diastolic ~ iNtErCePt + dummy_немецкий + dummy_итальянский - 1) %>% tidy()
## # Набор символов: 3 × 5 ## оценка срока std.error statistic p.value #### 1 ИНТЕРЦЕПТ 92,0 2,72 33,8 0,0000570 ## 2 манекен_Немецкий 1,00 3,85 0,260 0,812 ## 3 dummy_Italian 1.50 3.85 0.389 0.723
Вы видите, что получаете те же результаты, что и по умолчанию, задав категориальную переменную национальность :
национальность <- factor(c(1, 2, 2, 1 , 3,3 ),
labels = c("Голландский", "Немецкий", "Итальянский"))
lm(bp_diastolic ~ национальность) %>%
tidy() ## # Набор символов: 3 × 5 ## оценка срока std.error statistic p.## 1 (Перехват) 92,0 2,72 33,8 0,0000570 ## 2 национальностьнемец 1,00 3,85 0,260 0,812 ## 3 национальностьитальянец 1.50 3.85 0.389 0.723
Или при самостоятельном фиктивном кодировании:
lm(bp_diastolic ~ dummy_German + dummy_Italian) %>% tidy()
## # Набор символов: 3 × 5 ## оценка срока std.error statistic p.value #### 1 (Перехват) 92,0 2,72 33,8 0,0000570 ## 2 манекен_Немецкий 1,00 3,85 0,260 0,812 ## 3 манекен_итальянский 1,50 3,85 0,3890,723
и таким образом, что мы явно включаем точку пересечения 1 с:
лм(bp_diastolic ~ 1 + национальность) %>% tidy()
## # Набор символов: 3 × 5 ## оценка срока std.error statistic p.value #### 1 (Перехват) 92,0 2,72 33,8 0,0000570 ## 2 национальностьнемец 1,00 3,85 0,260 0,812 ## 3 национальностьитальянец 1,50 3,85 0,3890,723
лм(bp_диастолический ~ 1 + фиктивный_немецкий + фиктивный_итальянский) %>% tidy()
## # Набор символов: 3 × 5 ## оценка срока std.## 1 (Перехват) 92,0 2,72 33,8 0,0000570 ## 2 манекен_Немецкий 1,00 3,85 0,260 0,812 ## 3 dummy_Italian 1.50 3.85 0.389 0.723
с той лишь разницей, что первый параметр теперь называется ‘(Intercept)’.
В заключение: линейные модели по умолчанию включают «перехват», который на самом деле закодирован как независимая переменная, состоящая из всех единиц.
10.7 Выбор эталонной группы в R для фиктивного кодирования
Давайте посмотрим, как запустить анализ в R, когда мы хотим контролировать, какие контрасты фактически вычисляются. На этот раз мы хотим, чтобы немцы сформировали контрольную группу, а затем сравнили средние значения в Нидерландах и Италии со средним значением в Германии.
Давайте сначала поместим данные из таблицы 10.3 в R, чтобы вы могли следовать им на своем компьютере (скопируйте приведенный ниже код в R-скрипт).
кровяное давление <- табличка(
участник = с (1, 2, 3, 4, 5, 6),
национальность = c("голландец", "немец", "немец", "голландец", "итальянец", "итальянец"),
bp_diastolic = c(92, 97, 89, 92, 91, 96))
кровяное давление ## # Таблица: 6 × 3 ## национальность участника bp_diastolic #### 1 1 Голландский 92 ## 2 2 немецкий 97 ## 3 3 немецкий 89 ## 4 4 Голландский 92 ## 5 5 Итальянский 91 ## 6 6 Italian 96
Обратите внимание, что мы пока опускаем фиктивные переменные. Затем мы превращаем переменную национальность в таблице кровяное давление в факторную переменную. Это гарантирует, что R знает, что это категориальная переменная.
кровяное давление <- кровяное давление %>% mutate(национальность = as.factor(национальность))
Если мы посмотрим на этот фактор,
кровяное давление %>% pull(национальность)
## [1] Голландский Немецкий Немецкий Голландский Итальянский Итальянский ## Уровни: голландский немецкий итальянский
мы видим, что он имеет три уровня. С помощью функции level() мы видим, что первый уровень — голландский, второй — немецкий, а третий — итальянский. Это поведение по умолчанию: R выбирает порядок в алфавитном порядке.
кровяное давление %>% pull(национальность) %>% level()
## [1] "голландский" "немецкий" "итальянский"
Это означает, что если мы запустим стандартный lm() анализ, первый уровень (голландцы) будет формировать контрольную группу, и что два параметра наклона обозначают контрасты кровяного давления у немцев и итальянцев по сравнению с голландцами соответственно:
кровяное давление %>% lm(bp_diastolic ~ национальность, данные = .
## ## Вызов: ## lm(formula = bp_diastolic ~ национальность, данные = .) ## ## Коэффициенты: ## (Перехват) национальностьнемецкая национальностьитальянец ## 92,0 1,0 1,5
В случае, если мы хотим использовать немцев в качестве эталонной группы вместо голландцев, мы должны указать набор контрастов, отличный от этого набора контрастов по умолчанию.
Один из простых способов сделать это — установить референтную группу на другой уровень переменной национальности . Мы работаем с переменной национальность во фрейме данных (или табличка ) под названием кровяное давление . Мы используем функцию relevel() , чтобы изменить контрольную группу на «немецкую».
кровяное давление <- кровяное давление %>% mutate(nationality = relevel(nationality, ref = "немец"))
Если мы проверим это с помощью функции level() снова, мы увидим, что первая группа теперь немецкая, а не голландская:
кровяное давление %>% pull(национальность) %>% level()
## [1] "немецкий" "голландский" "итальянский"
группа теперь действительно является немецкой группой (т. Е. С контрастами голландцев и итальянцев).
артериальное давление %>% lm(bp_diastolic ~ национальность, данные = .)
## ## Вызов: ## lm(formula = bp_diastolic ~ национальность, данные = .) ## ## Коэффициенты: ## (Перехват) национальностьГолландская национальностьИтальянец ## 93.0 -1.0 0.5
Чтобы проверить это полностью, мы можем попросить R показать нам фиктивные переменные, которые он создал для анализа, используя функцию model.matrix() .
кровяное давление %>% lm(bp_diastolic ~ национальность, данные = .) %>% модель.матрица()
## (Перехват) национальностьГолландская национальностьИтальянец ## 1 1 1 0 ## 2 1 0 0 ## 3 1 0 0 ## 4 1 1 0 ## 5 1 0 1 ## 6 1 0 1 ## атрибут(,"назначить") ## [1] 0 1 1 ## attr(,"контрасты") ## attr(,"contrasts")$национальность ## [1] "конт.лечение"
Выходные данные содержат значения новых переменных для всех лиц в исходном наборе данных. Мы видим, что R создал фиктивную переменную для того, чтобы быть голландцем (с именем nationalityDutch ), и еще одну фиктивную переменную для того, чтобы быть итальянцем (с именем nationalityItalian ). Поэтому референтную группу сейчас составляют немцы. Обратите внимание, что R также создал переменную с именем (Intercept) , которая состоит только из 1 для всех шести человек.
Переменная национальность в фрейме данных кровяное давление теперь постоянно изменено. Отныне каждый раз, когда мы будем использовать эту переменную в анализе, референтную группу будут формировать немцы. Снова используя mutate() и relevel() , мы можем вернуть все обратно или выбрать другую контрольную группу.
Эта фиксация эталонной категории очень полезна при анализе экспериментальных данных. Предположим, исследователь хочет количественно оценить влияние вакцины А и вакцины В на госпитализацию по поводу COVID-19.. Она случайным образом распределяет людей в одну из трех групп: A, B и C, где группа C — это контрольное состояние, в котором люди получают инъекцию физиологического раствора (плацебо). Лица из групп А и В получают вакцины А и В соответственно. Чтобы количественно оценить эффект вакцины А, вы хотели бы противопоставить группу А группе С, а чтобы количественно оценить эффект вакцины Б, вы хотели бы противопоставить группу В группе С. В этом случае полезно если эталонной группой является группа C. По умолчанию R использует первую категорию в качестве эталонной категории в алфавитном порядке. Поэтому по умолчанию R выбрал бы группу A в качестве эталонной группы. Затем R по умолчанию вычисляет контраст между B и A, а также между C и A, кроме среднего значения группы A (отрезка). Изменив контрольную категорию на группу C, результаты будут более полезными для ответа на вопрос исследования.
Резюме
Общие шаги для использования фиктивного кодирования и выбора эталонной категории:
- Используйте
level(), чтобы проверить, какая группа названа первой. Эта группа, как правило, будет референтной группой. Например, сделайтеуровней (переменная данных $). - Если эталонная группа не подходит, используйте
mutate()иrelevel(), чтобы изменить эталонную группу, например, сделайте что-то вроде:data <- data %>% mutate(переменная = relevel(переменная, ссылка = "немецкий")). - Проверьте с помощью
levels(), правильно ли указана категория ссылок. Любой новый анализ с использованиемlm()теперь будет давать анализ с фиктивными переменными для всех категорий, кроме первой.
10.8 Альтернативные схемы кодирования
По умолчанию R использует фиктивное кодирование. Контрасты, которые рассчитываются с использованием фиктивных переменных, называются контрастами лечения : эти контрасты представляют собой разницу между отдельными группами и контрольной группой. Подобно определению эталонной группы для конкретной переменной (так что первое значение параметра в выходных данных является средним значением этой эталонной группы, обычно называемой (Intercept) ), вы можете установить все контрасты, которые используются в анализе линейной модели. Например, набрав
кровяное давление %>% pull(национальность) %>% контрасты()
## Голландский Итальянский ## немецкий 0 0 ## Голландский 1 0 ## Italian 0 1
вы видите, что первая созданная переменная (первый столбец) является фиктивной переменной для того, чтобы быть голландцем, а вторая переменная является фиктивной для того, чтобы быть итальянцем. Что вы видите в контрастах() 9Матрица 0018 - это не контрасты как таковые , а схема кодирования для новых переменных, созданных R. Другими словами, с помощью контрастов() вы можете увидеть матрицу схемы кодирования \(\mathbf{S} \). Однако обратите внимание, что переменная по умолчанию с 1 с (перехват) не отображается.
Это кодирование обработки по умолчанию (фиктивное кодирование) подходит для линейной регрессии, но не очень подходит для дисперсионного анализа. Мы вернемся к этому вопросу позже, когда будем обсуждать модерацию. Пока достаточно знать, что если вас интересует дисперсионный анализ, а не линейный регрессионный анализ, лучше всего использовать влияет на кодирование (иногда называемое суммой к нулю контрастов ). Выше мы видели, что сумма первого столбца после функции counters() (называемой «Голландский») равна 1, а сумма второго столбца (называемого «Итальянский») также равна 1. С другой стороны, при кодировании эффектов веса для каждой суммы контрастов до 0 (отсюда и название сумма-к-нулю контрастов ). Кодирование эффектов также полезно, если у нас есть конкретные вопросы исследования, когда нас интересуют различия между комбинациями групп. Через мгновение мы увидим, что это значит. Ниже мы обсудим кодирование эффектов более подробно, а также обсудим другие стандартные способы кодирования ( Helmert противопоставляет и последовательные отличия контрастное кодирование ).
10.8.1 Кодирование эффектов
Ниже мы проиллюстрируем, как использовать и интерпретировать линейную модель при применении кодирования эффектов. Вы можете ввести R.
Во-первых, давайте проверим, что у нас все в исходном алфавитном порядке. Так легче не отвлекаться на детали.
кровяное давление %>% pull(nationality) %>%levels() # Немецкий язык теперь является первой группой
## [1] "немецкий" "голландский" "итальянский"
# изменить порядок так, чтобы "голландский" стал первой группой кровяное давление <- кровяное давление %>% mutate (национальность = переуровень (национальность, ссылка = "голландский")) кровяное давление %>% pull(nationality) %>%levels() # Проверяем, что голландский язык теперь является первой группой
## [1] "Голландский" "Немецкий" "Итальянский"
Далее нам нужно изменить фиктивное кодирование по умолчанию на кодирование эффектов для национальность переменная в кадре данных кровяное давление . Мы делаем это, снова постоянно фиксируя что-то для этой переменной. Мы используем функцию code_deviation() из пакета codingMatrices .
библиотека (codingMatrices) # установить, если это еще не сделано контрасты(кровяное давление$национальность) <- code_deviation
Когда мы снова запустим контрасты() , мы увидим другой набор столбцов, где сумма каждого столбца теперь равна 0. Мы больше не видим фиктивного кодирования.
контрасты(кровяное давление$национальность)
## MD1 MD2 ## Голландский 1 0 ## немецкий 0 1 ## Italian -1 -1
Значения в этой матрице схемы кодирования используются для кодирования новых числовых переменных. В первом столбце указано, что переменная должна быть создана с 1 для голландцев, 0 для немцев и -1 для итальянцев. Во втором столбце указано, что должна быть создана еще одна переменная с нулями для голландцев, единицами для немцев и -1 для итальянцев. Любой новый анализ с переменной национальность во фрейме данных кровяное давление теперь будет по умолчанию использовать эту схему кодирования суммы к нулю. Если мы запустим анализ линейной модели с этой факторной переменной, то увидим, что получаем очень разные значения параметров.
кровяное давление %>% lm(bp_diastolic ~ национальность, данные = .) %>% tidy()
## # Набор символов: 3 × 5 ## оценка срока std.error statistic p.value #### 1 (Перехват) 92,8 1,57 59,0 0,0000107 ## 2 национальностьMD1 -0,833 2,22 -0,375 0,733 ## 3 nationalityMD2 0,167 2,22 0,0750 0,945
Давайте проверим, что мы понимаем, как вычисляются новые переменные.
кровяное давление %>% lm(bp_diastolic ~ национальность, данные = .) %>% model.matrix()
## (Перехват) nationalityMD1 nationalityMD2 ## 1 1 1 0 ## 2 1 0 1 ## 3 1 0 1 ## 4 1 1 0 ## 5 1 -1 -1 ## 6 1 -1 -1 ## атрибут(,"назначить") ## [1] 0 1 1 ## attr(,"контрасты") ## attr(,"contrasts")$национальность ## MD1 MD2 ## Голландский 1 0 ## немецкий 0 1 ## итальянский -1 -1
У нас все еще есть переменная с именем (Intercept) только с 1, которая используется по умолчанию, как мы видели ранее. Есть также две другие новые переменные, одна называется nationalityMD1 , а другая называется nationalityMD2 , где есть 1, 0 и -1.
На основе этой схемы кодирования трудно сказать, что представляют собой новые значения в выходных данных. Но мы видели ранее, что выходные значения — это просто значения контрастов, а контрасты можно определить, взяв обратную матрицу схемы кодирования \(\mathbf{S}\).
Матрица \(\mathbf{S}\) теперь состоит из схемы кодирования эффектов. Таким образом, \(\mathbf{S}\) совпадает с результатом контрастов(кровяное давление$национальность) .
S <- контрасты(кровяное давление$национальность) S
## MD1 MD2 ## Голландский 1 0 ## немецкий 0 1 ## Italian -1 -1
Мы видим, что у него есть две новые числовые переменные. Однако мы упускаем переменную с единицами, которая используется в анализе по умолчанию. Если мы добавим это, мы получим полную матрицу \(\mathbf{S}\) с тремя новыми переменными.
С <- cbind(1, С) S
## MD1 MD2 ## Голландский 1 1 0 ## немецкий 1 0 1 ## Итальянский 1 -1 -1
Затем мы используем обратную операцию для вычисления контрастной матрицы \(\mathbf{L}\).
L <- ginv(S) L
## [1] [2] [3] ## [1,] 0,3333333 0,3333333 0,3333333 ## [2,] 0,6666667 -0,3333333 -0,3333333 ## [3,] -0.3333333 0.6666667 -0.3333333
L %>% дроби()
## [1] [2] [3] ## [1,] 1/3 1/3 1/3 ## [2,] 2/3 -1/3 -1/3 ## [3,] -1/3 2/3 -1/3
Это дает нам то, что нам нужно знать о том, как интерпретировать вывод. Вкратце, первый параметр в выходных данных теперь представляет собой так называемое общее среднее . Это среднее всех групповых средних. Это так, потому что если мы расположим групповые средние в правильном порядке и воспользуемся весами из первой строки в \(\mathbf{L}\), мы получим
\[L1: \frac{1}{ 3} M_{голландский} + \frac{1}{3} M_{немецкий} + \frac{1}{3} M_{итальянский}\] который можно упростить до
\[L1: \frac{ M_{голландский} + M_{немецкий} + M_{итальянский}}{3}\]
что является средним из трех групповых средних. Мы обычно называем среднее групповых средних среднее .
Для определения значения второго параметра смотрим на вторую строку матрицы контраста и заполняем цифры для второго контраста:
\[L2: \frac{2}{3} M_{Dutch} - \frac {1}{3} M_{немецкий} - \frac{1}{3} M_{итальянский}\]
\(L2\) можно переписать как
\[L2: \frac{2}{3} \times \large(M_{голландский} - \frac{M_{немецкий} + M_{итальянский}}{2}\large)\] Таким образом, \(L2\) представляет собой разницу между средним голландским значением и средним значением двух других средних значений, умноженную на \(\frac{2}{3}\).
Хотя этот контраст имеет смысл интерпретировать как разницу между голландским средним и двумя другими средними, дробь \(\frac{2}{3}\) здесь выглядит странно. Поэтому давайте перепишем контраст \(L2\) по-другому:
\[\begin{aligned} L2&: \frac{2}{3} M_{голландский} - \frac{1}{3} M_{немецкий} - \frac{1}{3} M_{итальянский} \\ &= \frac{2}{3} M_{голландский} + \frac{1}{3} M_{голландский} - \frac{1}{3} M_{голландский} - \frac{1}{3} M_ {Немецкий} - \frac{1}{3} M_{Итальянский}\\ &= M_{голландский} - \frac{ M_{голландский} + M_{немецкий} + M_{итальянский}}{3}\end{выравнивание}\]
Другими словами, это противопоставление касается разницы между голландским средним и общим средним.
Для определения значения третьего параметра смотрим на третью строку матрицы контраста и заполняем цифры для второго контраста:
\[L3: -\frac{1}{3} M_{Dutch} + \ frac{2}{3} M_{немецкий} - \frac{1}{3} M_{итальянский}\] что можно записать как
\[L3: \frac{2}{3} \times \large(M_{немецкий} - \frac{M_{голландский} + M_{итальянский}}{2}\large)\]
и интерпретируется как разница между немецким средним значением и средним значением двух других средних значений, умноженная на \(\frac{2}{3}\), или, при записи, как
\[L3: M_{немецкий} - \frac{ M_{голландский} + M_{немецкий} + M_{итальянский}}{3}\]
как разница между немецким средним и общим средним.
Давайте проверим, имеет ли это смысл. Давайте получим обзор средних значений группы в данных и снова коэффициенты:
кровяное давление %>% group_by(национальность) %>% summarise(mean = mean(bp_diastolic))
## # tibble: 3 × 2 ## национальность означает ## <фкт> <дбл> ## 1 Голландский 92 ## 2 немецкий 93 ## 3 Итальянский 93.
кровяное давление %>% lm(bp_diastolic ~ nationality, data = .) %>% coef()
## (Intercept) nationalityMD1 nationalityMD2 ## 92,8333333 -0,8333333 0,1666667
Первый параметр «(Intercept)» равен 92,833, и это действительно равно большому среднему \(\frac{(92 + 93 + 93,5)}{3} = 92,833\).
Второй параметр «nationalityMD1» равен -0,833, и это равно разнице между средним значением в Нидерландах 92, а немецкое и итальянское означает вместе взятые, \(\frac{(93 + 93,5)}{2} = 93,25\), поэтому \(92 - 93,25 = -1,25\). Когда мы умножаем это на \(\frac{2}{3}\), мы получаем \(-1,25 \times \frac{2}{3} = -0,833\).
Третий параметр 'nationalityMD2' равен 0,167, и это действительно равно разнице между немецким средним значением 93 и голландским и итальянским средним значением вместе взятым, \(\frac{(92 + 93,5)}{2} = 92,75\), поэтому \(93 - 92,75 = 0,25\). При умножении на \(\frac{2}{3}\) мы получаем \(0,25 \times \frac{2}{3} = 0,167\). Это умножение объяснено более подробно ниже.
Он также вычисляется, когда мы определяем контрасты в терминах общего среднего. Давайте сначала вычислим общее среднее (среднее значение всех трех средних):
кровяное давление %>% group_by(национальность) %>% summarise(mean = mean(bp_diastolic)) %>% # группа означает summarise(grandmean = mean(mean)) # вычислить среднее значение группы
## # tibble: 1 × 1 ## бабка ## <дбл> ## 1 92,8
и сравните его со средним значением группы:
кровяное давление %>% group_by(национальность) %>% суммировать (среднее = среднее (bp_diastolic))
## # Тиббл: 3 × 2 ## национальность означает ## <фкт> <дбл> ## 1 Голландский 92 ## 2 немецкий 93 ## 3 Итальянский 93,5
Мы видим, что \(L2\) должно быть \(92 - 92,8 = -0,8\), а \(L3\) должно быть \(93 - 92,8 = 0,2\), что в точности равно что мы находим в качестве коэффициентов на выходе (безопасное округление).
кровяное давление %>% lm(bp_diastolic ~ nationality, data = .) %>% coef()
## (Intercept) nationalityMD1 nationalityMD2 ## 92,8333333 -0,8333333 0,1666667
Кодирование эффектов интересно во всех случаях, когда вы хотите проверить нулевую гипотезу об одной группе относительно среднего значения других групп (или относительно общего среднего). Как мы видели выше, второй параметр в выходных данных касается разницы между средним значением первой группы и средним значением всех средних значений группы (большое среднее). \(t\)-критерий, сопровождающий этот параметр, информирует нас о нулевой гипотезе о том, что первая группа имеет то же среднее значение генеральной совокупности, что и среднее всех других групповых средних (другими словами, групповое среднее равно то же, что и среднее значение). Это полезно в ситуации, когда вы, например, хотите сравнить контрольное состояние/условие плацебо с несколькими объединенными экспериментальными условиями: дают ли в целом различные варианты лечения другое среднее значение, чем при бездействии?
Предположим, например, что мы проводим исследование различных видов терапии для отказа от курения. В одной группе людей помещают в список ожидания, во второй группе люди получают лечение с помощью никотиновых пластырей, а в третьей группе люди получают лечение с помощью когнитивно-поведенческой терапии.
Если ваши основные вопросы: (1) каково влияние никотиновых пластырей на количество выкуриваемых сигарет и (2) каково влияние когнитивно-поведенческой терапии на количество выкуриваемых сигарет, вы можете выбрать вариант по умолчанию. фиктивную стратегию кодирования и убедитесь, что условие контроля является первым уровнем вашего фактора. Параметры и \(t\)-тесты, которые имеют отношение к вашим исследовательским вопросам, затем находятся во второй и третьей строке вашей таблицы регрессии.
Однако, если ваш главный вопрос звучит так: «Помогают ли такие методы лечения, как никотиновые пластыри и когнитивно-поведенческая терапия, уменьшить количество выкуриваемых сигарет по сравнению с бездействием?» вы можете выбрать стратегию суммирования к нулю (кодирование эффектов), при которой вы убедитесь, что контрольное условие (список ожидания) является первым уровнем вашего фактора. Соответствующий тест нулевой гипотезы для вашего исследовательского вопроса затем дается во второй строке вашей таблицы регрессии (сопоставление контрольной группы с двумя группами лечения, т. е. сопоставление контрольной группы с общим средним).
Подводя итог, можно сказать, что существует несколько способов проведения анализа линейной модели с категориальными переменными. Способ по умолчанию R — использовать фиктивное кодирование, а второй способ — кодирование эффектов. Если вас особенно не интересует дисперсионный анализ с несколькими независимыми категориальными переменными или комбинациями групп, способ по умолчанию с фиктивным кодированием вполне подойдет. Что касается дисперсионного анализа, то большинство программных пакетов и функций, выполняющих дисперсионный анализ, фактически используют кодирование эффектов по умолчанию, поэтому важно с ним ознакомиться. Однако следует сказать, что на результаты анализа с одной независимой переменной не повлияет использование другой схемы кодирования. Схема кодирования, лежащая в основе дисперсионного анализа, имеет значение только в том случае, если у вас есть несколько независимых переменных.
В предыдущих главах мы научились читать результаты анализа lm() , когда он основан на фиктивном кодировании. В текущем подразделе мы увидели, как выяснить, что представляют числа в выводе в случае кодирования эффектов. Теперь мы рассмотрим ряд других вариантов кодирования категориальных переменных, после чего мы рассмотрим, как создавать пользовательские контрасты, которые помогут вам ответить на ваш конкретный исследовательский вопрос.
10.8.2 Гельмерт контрастирует
Другой хорошо известной схемой кодирования является схема кодирования Гельмерта. Мы можем указать, что нам нужны контрасты Helmert для переменной национальности , если мы закодируем следующие контрасты
(кровяное давление $ национальность) <- code_helmert контрасты(кровяное давление$национальность) %>% дроби()
## h3 h4 ## Голландский -1/2 -1/3 ## немецкий 1/2 -1/3 ## Итальянский 0 2/3
В первом столбце указано, как закодирована первая новая переменная (голландский как \(-\frac{1}{2}\), немецкий как \(\frac{1}{2}\ ) и итальянцы как 0), а во втором столбце указана новая переменная с \(-\frac{1}{3}\) для немцев и голландцев и \(\frac{2}{3}\) для итальянцев. По умолчанию другая переменная вычисляется как 1 для всех групп, что представляет собой некоторый перехват.
Если мы проделаем тот же трюк с этой матрицей, что и раньше, добавив столбец с единицами, а затем используя ginv() , мы получим следующие веса для контрастов, которые мы количественно определяем таким образом
S <- cbind( 1, контрасты(кровяное давление$национальность)) L <- ginv(S) L %>% дроби()
## [1] [2] [3] ## [1,] 1/3 1/3 1/3 ## [2,] -1 1 0 ## [3,] -1/2 -1/2 1
Снова в каждой строке указаны веса вычисляемых контрастов. Как и в случае с кодированием эффектов, первое отличие представляет общее среднее (среднее значение группы):
\[L1: \frac{M_{голландский} + M_{немецкий} + M_{итальянский}}{3}\]
Вторая строка представляет разницу между немецкими и голландскими средними значениями:
\[L2: - 1 \times M_{голландский} + 1 \times M_{немецкий} + 0 \times M_{итальянский}= M_{немецкий} - M_{голландский}\]
, а третья строка представляет разницу между средним итальянским значением на с одной стороны, а голландские и немецкие средства вместе взятые.
\[ -\frac{1}{2} \times M_{голландский} - \frac{1}{2} \times M_{немецкий} + 1 \times M_{итальянский} = M_{итальянский} - \frac {M_{голландский} + M_{немецкий}}{2})\] Как правило, при использовании схемы кодирования Гельмерта (1) первая группа сравнивается со второй группой, (2) первая и вторая группы вместе сравниваются с третьей группой, (3) первая, вторая и третья группы вместе сравниваются. до четвертой группы и так далее. Давайте представим, что у нас есть переменная фактора страны с пятью уровнями. Давайте тогда укажем, что мы хотим иметь контрасты Гельмерта.
страна <- c("A", "B", "C", "D", "E") %>% as.factor()
контрасты (страна) <- code_helmert
контрасты(страна) ## h3 h4 h5 H5 ## А -0,5 -0,3333333 -0,25 -0,2 ## В 0,5 -0,3333333 -0,25 -0,2 ## С 0,0 0,6666667 -0,25 -0,2 ## Д 0,0 0,0000000 0,75 -0,2 ## E 0.0 0.0000000 0.00 0.8
затем мы делаем трюк, чтобы получить строки с весами контрастов
S <- cbind(1, counters(country)) L <- ginv(S) L %>% Fractions() # для облегчения чтения
## [1] [2] [3] [4] [5] ## [1,] 1/5 1/5 1/5 1/5 1/5 ## [2,] -1 1 0 0 0 ## [3,] -1/2 -1/2 1 0 0 ## [4,] -1/3 -1/3 -1/3 1 0 ## [5,] -1/4 -1/4 -1/4 -1/4 1
Тогда мы видим, что первое отличие является общим средним. Вторая строка — сравнение между А и В, третья — сравнение между (А+В)/2 и С, четвертая — сравнение между (А+В+С)/3 и D, пятая — сравнение сравнение между (A+B+C+D)/4 и E. Другими словами, контрасты Гельмерта сравнивают каждый уровень со средним значением «предшествующих» уровней. Таким образом, мы можем сравнивать категории переменной со средним значением предыдущих категорий переменной.
Вы также можете пойти наоборот. Если мы используем функцию code_helmert_forward вместо code_helmert
контрасты (страна) <- code_helmert_forward S <- cbind(1, контрасты(страна)) L <- ginv(S) L %>% Fractions() # для облегчения чтения
## [1] [2] [3] [4] [5] ## [1,] 1/5 1/5 1/5 1/5 1/5 ## [2,] 1 -1/4 -1/4 -1/4 -1/4 ## [3,] 0 1 -1/3 -1/3 -1/3 ## [4,] 0 0 1 -1/2 -1/2 ## [5,] 0 0 0 1 -1
вы видите, что мы идем «вперед»: после общего среднего мы видим, что страна А сравнивается с (B+C+D+E)/4, затем страна B сравнивается с (C+D+E)/ 3; затем страна C сравнивается с (D + E)/2 и, наконец, D сравнивается с E. Этот прямой тип кодирования Гельмерта обычно является кодированием Гельмерта по умолчанию в других статистических пакетах.
Противопоставления Гельмерта полезны, когда у вас есть определенная логика для упорядочения уровней категориальной переменной (т. е. если у вас есть порядковая переменная). Примером, когда контраст Гельмерта может быть полезен, является случай, когда вы хотите узнать минимальную эффективную дозу в исследовании доза-реакция. Предположим, у нас есть новое лекарство, и мы хотим знать, сколько его нужно, чтобы избавиться от головной боли. Мы разделили людей с головной болью на четыре группы. В группе А люди принимают таблетку плацебо, в группе В люди принимают 1 таблетку нового лекарства, в группе С люди принимают 3 таблетки, а в группе D люди принимают 4 таблетки. При анализе данных мы сначала хотим установить, приводит ли 1 таблетка к значительному снижению по сравнению с плацебо. Если это не так, мы можем проверить, работают ли 3 таблетки (группа C) лучше, чем 1 таблетка или отсутствие таблетки (группы A и B вместе взятые). Если это также не показывает значительного улучшения, мы можем сравнить 6 таблеток (группа D) с меньшим количеством таблеток (группы A, B и C вместе взятые).
В R есть несколько других стандартных опций для кодирования ваших переменных. Контрастное кодирование последовательных различий также является опцией для осмысленно упорядоченных категорий. Он сравнивает второй уровень с первым уровнем, третий уровень со вторым уровнем, четвертый уровень с третьим уровнем и так далее. Используемая функция — code_diff (доступна в пакете codingMatrices ). Это может быть полезной альтернативой кодированию Гельмерта для исследования доза-реакция. Другие варианты приведены в таблице 10.7.
| вариант | описание |
|---|---|
| code_control | противопоставляет сравнение групповых средних («лечения») со средними значениями первого класса (контрольная группа) |
| code_control_last |
Аналогично code_control , но с использованием конечного среднего класса в качестве эталонной группы
|
| code_diff |
Контрастами являются последовательные различия средств лечения, т. е. 2 группа - 1 группа, 3 группа - 2 группа и т.д.
|
| code_diff_forward |
Очень похоже на code_diff , но с использованием прямых различий: группа 1 против группы 2, группа 2 - группа 3 и т. д.
|
| code_helmert | Контраст теперь сравнивает среднее значение каждой группы, начиная со второго, со средним значением всех групп предыдущей группы. |
| code_helmert_forward | Аналогичен code_helmert, но сравнивает каждое среднее значение класса, вплоть до предпоследнего, со средним значением всех классов, следующих за ним. |
| code_deviation | Кодирование с эффектом или кодирование суммы к нулю. Более точное описание могло бы состоять в том, чтобы сказать, что контрасты — это отклонения среднего значения каждой группы от среднего значения других. Во избежание избыточности последнее отклонение опущено. |
| code_deviation_first |
Очень похоже на code_deviation, но во избежание избыточности опускают первое отклонение, а не последнее.
|
| code_poly | code_poly |
| контр.дифф |
по действию очень похож на code_diff , дает те же различия, что и контрасты, но использует первое среднее значение группы в качестве точки пересечения, а не простое среднее оставшихся средних классов, как с code_diff . Некоторые сочли бы это непригодным для использования в некоторых нестандартных таблицах ANOVA, поэтому используйте его с осторожностью.
|
Обзор
Предустановленные схемы кодирования в R с использованием пакета codingMatrices (со ссылкой на матрицу \(\mathbf{L}\)). R может вычислить эту матрицу схемы кодирования, используя code_control . При таком кодировании в качестве референтной группы используется первый уровень факторной переменной. Как вариант, с code_control_last используется фиктивное кодирование с последним уровнем факторной переменной в качестве контрольной группы.
code_deviation . code_helmert . Другим вариантом является последовательное контрастное кодирование различий с использованием code_diff или code_diff_forward .
10.9 Индивидуальные контрасты
Иногда стандартные контрасты, доступные в пакете codingMatrices , — это не то, что вам нужно. В этом разделе мы рассмотрим ситуацию, когда у нас есть более сложные исследовательские вопросы, на которые мы можем ответить только с помощью специальных, специально подобранных контрастов. Приведем пример набора данных с десятью группами.
До сих пор мы видели разные способы определения контрастов, и в каждом случае количество контрастов было равно количеству категорий . В примерах фиктивного кодирования с двумя категориями вы видели две категории, и выходные данные показывают точку пересечения (контрастность 1) и наклон (контрастность 2). В фиктивном примере с тремя категориями мы увидели пересечение для одной категории (эталонная группа), один уклон для второй категории по сравнению с первой категорией и один уклон для третьей категории по сравнению с первой категорией. В примере с Гельмертом мы видели то же самое: для трех категорий и кодирования Гельмерта мы видели одно общее среднее (отрезок), затем разницу между группой 2 и 1, а затем разницу между группой 3 с одной стороны и группой 1 и 2 вместе взятые, с другой стороны. Таким образом, в целом мы утверждаем, что если мы запускаем модель для переменной с категориями \(J\), мы видим параметры \(J\) на выходе (включая перехват). Мы не будем вдаваться здесь в подробности, но крайне важно, чтобы даже если у вас меньше \(J\) вопросов, в вашем анализе все равно должны быть \(J\) контрасты. Мы проиллюстрируем этот принцип здесь. В этом разделе мы покажем вам пример, в котором может быть очень полезно получить полный контроль над контрастами, которые R вычисляет для вас, но где мы должны убедиться, что количество параметров в выводе соответствует общему количеству категорий.
Предположим, вы проводите исследование дегустации вин, где у вас есть десять разных вин, каждое из которых сделано из одного из десяти разных сортов винограда, и каждое оценивается одной из десяти разных групп людей. Каждый человек пробует только одно вино и дает оценку от 1 (наихудшее качество, какое только можно вообразить) до 100 (наилучшее качество, какое только можно вообразить). В таблице 10.8 дается обзор десяти вин, изготовленных из десяти разных сортов винограда.
| Wine_ID | виноград | источник | цвет |
|---|---|---|---|
| 1 | Каберне Совиньон | Французский | Красный |
| 2 | Мерло | Французский | Красный |
| 3 | Айрен | испанский | Белый |
| 4 | Темпранильо | испанский | Красный |
| 5 | Шардоне | Французский | Белый |
| 6 | Сира (Шираз) | Французский | Красный |
| 7 | Гарнача (Гарнаш) | испанский | Красный |
| 8 | Совиньон блан | Французский | Белый |
| 9 | Треббьяно Тоскана (Уни Блан) | итальянский | Белый |
| 10 | Пино-Нуар | Французский | Красный |
Единицами этого исследования являются люди, которые пробуют вино. Тип вина является групповой переменной: некоторые люди пробуют Совиньон Блан, тогда как другие люди пробуют Пино Нуар. В таблице 10.9 показана небольшая часть данных.
| винтестерID | Wine_ID | виноград | источник | рейтинг |
|---|---|---|---|---|
| 1 | 9 | Треббьяно Тоскана (Уни Блан) | итальянский | 20 |
| 2 | 8 | Совиньон блан | Французский | 8 |
| 3 | 8 | Совиньон блан | Французский | 27 |
| 4 | 1 | Каберне Совиньон | Французский | 70 |
| 5 | 9 | Треббьяно Тоскана (Уни Блан) | итальянский | 32 |
Предположим, мы хотим ответить на следующие исследовательские вопросы:
- Насколько велика разница в качестве красных и белых вин?
- Насколько велика разница в качестве винограда французского и испанского происхождения?
- Насколько велика разница в качестве между виноградом итальянского и двух других сортов?
Обратите внимание, что эти три вопроса можно рассматривать как три контраста данных о дегустации вин, тогда как группирующая переменная имеет десять категорий. Мы вернемся к этому вопросу позже.
Мы обращаемся к этим трем исследовательским вопросам, переводя их в три контраста для факторной переменной Wine_ID . Предположим, что порядок винограда аналогичен приведенному выше, где Каберне Совиньон — первый уровень, Мерло — второй уровень и т. д.
Контраст \(L1\) представляет собой разницу между средним значением 6 сортов винограда для красного вина и средним значением для 4 сортов винограда для белого вина:
\[L1: \frac{M_1 + M_2 + M_4 + M_6 + M_7 + M_{ 10}}{6} - \frac{M_3 + M_5 + M_8 + M_9}{4} \] Это эквивалентно:
\[L1: \frac{1}{6}M_1 + \frac{1}{6}M_2 - \frac{1}{4}M_3 + \frac{1}{6}M_4 - \frac{1}{4}M_5 + \frac{1}{6}M_6 + \frac{1}{6}M_7 - \frac{1}{4}M_8 - \frac{1}{4}M_9 + \frac{1}{6}M_{10}\] Мы можем сохранить этот контраст для переменной винограда как вектор-строку 9.0003
\[\begin{bmatrix} \frac{1}{6} & \frac{1}{6} & -\frac{1}{4} & \frac{1}{6} & -\frac{1}{4} & \frac{ 1}{6} & \frac{1}{6} & -\frac{1}{4} & -\frac{1}{4} &\frac{1}{6} \end{bmatrix}\]
На второй вопрос можно ответить следующим сравнением, где у нас есть среднее значение 6 французских средних рейтингов минус среднее 3 испанских средних рейтингов:
\[L2: \frac{M_1 + M_2 + M_5 + M_6 + M_8 + M_{10}}{6} - \frac{M_3 + M_4 + M_7}{3}\] Это эквивалентно
\[L2: \frac{1}{6}M_1 + \frac{1}{6}M_2 - \frac{1}{3}M_3 - \frac{1}{3}M_4 + \frac{1 {6}M_5 + \frac{1}{6}M_6 - \frac{1}{3}M_7 + \frac{1}{6}M_8 + 0 \times M_9 + \frac{1}{6}M_ {10}\] Мы можем сохранить этот контраст для переменной винограда как вектор-строку
\[\begin{bmatrix} \frac{1}{6} & \frac{1}{6} & -\frac{1}{3} &- \frac{1}{3} & \frac{1}{6} & \frac{ 1}{6} & -\frac{1}{3} & \frac{1}{6} & 0 &\frac{1}{6} \end{bmatrix}\]
Третий вопрос можно сформулировать как противопоставление
\[L3: M_{9} - \frac{\left(\frac{M_1 + M_2 + M_5 + M_6 + M_8 + M_{10}}{6} + \frac{M_3 + M_4 + M_7}{3 }\справа)} {2}\]
Другими словами, мы берем общее среднее для 6 французских вин, общее среднее для 3 испанских вин и берем среднее значение этих двух средних. Затем мы сопоставляем это среднее значение со средним рейтингом отдельного итальянского вина. Этот контраст эквивалентен
\[L3: -\frac{1}{12}M_1 - \frac{1}{12}M_2 - \frac{1}{6}M_3 - \frac{1}{6} M_4 - \frac{1}{12}M_5 - \frac{1}{12}M_6 - \frac{1}{6}M_7 - \frac{1}{12}M_8 + 1 \times M_9- \frac{1}{12} M_{10} \]
и может храниться в векторе-строке
\[\begin{bmatrix} -\frac{1}{12} & -\frac{1}{12} & -\frac{1}{6} & -\frac{1}{6} & -\frac{1}{12} & -\frac{1}{12}& -\frac{1}{6} & -\frac{1}{12} & 1 & -\frac{1}{12} \end{bmatrix}\]
Объединив три вектора-строки, вы получите контрастную матрицу \(\mathbf{L}\)
\[\mathbf{L} = \begin{bmatrix} \frac{1}{6} & \frac{1}{6} & -\frac{1}{4} & \frac{1}{6} & -\frac{1}{4} & \frac{ 1}{6} & \frac{1}{6} & -\frac{1}{4} & -\frac{1}{4} &\frac{1}{6} \\ \frac{1}{6} & \frac{1}{6} & -\frac{1}{3} &- \frac{1}{3} & \frac{1}{6} & \frac{ 1}{6} & -\frac{1}{3} & \frac{1}{6} & 0 &\frac{1}{6} \\ -\frac{1}{12} & -\frac{1}{12} & -\frac{1}{6} & -\frac{1}{6} & -\frac{1}{12} & -\frac{1}{12}& -\frac{1}{6} & -\frac{1}{12} & 1 & -\frac{1}{12} \end{bmatrix}\]
Мы можем ввести эту матрицу \(\mathbf{L}\) в R, а затем вычислить обратную:
l1 <- c(1/6, 1/6, -1/4, 1/6, - 1/4, 1/6, 1/6, -1/4, -1/4, 1/6) l2 <- c(1/6, 1/6, -1/3, -1/3, 1/6, 1/6, -1/3, 1/6, 0, 1/6) l3 <- c(-1/12, -1/12, -1/6, -1/6, -1/12, -1/12, -1/6, -1/12, 1, -1/ 12) L <- rbind(l1, l2, l3) # связываем строки вместе L %>% дроби()
## [1] [2] [3] [4] [5] [6] [7] [8] [9] [10 ] ## l1 1/6 1/6 -1/4 1/6 -1/4 1/6 1/6 -1/4 -1/4 1/6 ## l2 1/6 1/6 -1/3 -1/3 1/6 1/6 -1/3 1/6 0 1/6 ## l3 -1/12 -1/12 -1/6 -1/6 -1/12 -1/12 -1/6 -1/12 1 -1/12
S <- ginv(L) # вычислить обратную S
## [1] [2] [3] ## [1,] 0,4000000000000000222045 0,3333333 0,000000000000000016 ## [2,] 0,4000000000000002997602 0,3333333 0,000000000000000057 ## [3,] -0,8000000000000001554312 -0,6166667 -0,29999999999999976685316 ## [4,] 0,4000000000000001887379 -0,6666667 -0,00000000000000020716296 ## [5,] -0,8000000000000001554312 0,3833333 -0,29999999999999971134201 ## [6,] 0,40000000000000018873790,3333333 -0,000000000000000004451563 ## [7,] 0,4000000000000001887379 -0,6666667 -0,00000000000000020716296 ## [8,] -0,8000000000000001554312 0,3833333 -0,29999999999999971134201 ## [9,] -0.000000000013322676 ## [10,] 0.4000000000000001887379 0.3333333 -0.000000000000000004451563
Обратите внимание, что нам нужно вычислить три новые переменные. Перехват отсутствует, но R будет включать его по умолчанию при запуске линейной модели.
Давайте придумаем некоторые данные и отправим их R.
# придумать по две оценки для каждого из 10 вин
winedata <- табличка (рейтинг = c(70,88,81,25,59,2,93,27,32,23,13,21,8,7,76,5,57,8,20,96),
Wine_ID = rep(1:10, 2) %>% as.factor(),
виноград = с("Каберне Совиньон",
"Мерло",
"Айрен",
"Темпранильо",
"Шардоне",
"Сира (Шираз)",
«Гарнача (Гарнаш)»,
"Совиньон блан",
«Треббьяно Тоскана (Уни Блан)»,
"Пино Нуар") %>% реп(2),
цвет = фактор (с (1, 1, 2, 1, 2, 1, 1, 2, 2, 1),
labels = c("Красный", "Белый")) %>% rep(2),
происхождение = фактор (с (1, 1, 3, 3, 1, 1, 3, 1, 2, 1),
labels = c("Французский", "Итальянский", "Испанский")) %>% rep(2)) Давайте взглянем на групповые значения на виноград:
winedata %>% group_by(виноград) %>% summarise(mean = mean(rating))
## # tibble: 10 × 2 ## виноградное среднее #### 1 Айрен 44,5 ## 2 Каберне Совиньон 41,5 ## 3 Шардоне 67,5 ## 4 Гарнача (Гарнаш) 75 ## 5 Мерло 54,5 ## 6 Пино Нуар 59.
Для первого исследовательского вопроса мы хотим оценить разницу в среднем рейтинге между красными и белыми винами.
Если мы посмотрим на средние значения и вычислим эту разницу вручную, рассчитав общие средние значения для красных и белых вин отдельно и взяв разницу, мы получим \(41,7-38,9=2,8\).
Немного утомительно и чревато ошибками вычислять вещи вручную, в то время как у нас есть такое замечательное вычислительное устройство, как R. Следовательно, в качестве альтернативы мы можем вычислить это, просто взяв взвешенную сумму всех средних с весами из первого контраста \(L1\). В R это легко: мы берем вектор средних для 10 различных групп и кусочно умножаем их на контрастные веса \(L1\), которые мы имеем в l1 , а затем суммируем их (в алгебре это называется внутренний продукт , если это звонит в колокол). Это точно так же, как вычисление взвешенной суммы средних.
# вычислить среднее значение выборки для каждого уровня переменной Wine_ID означает <- winedata %>% group_by(Wine_ID) %>% # для каждого уровня фактора Wine_ID summarise(mean = mean(rating)) %>% # вычислить среднее значение по уровню dplyr::select(mean) %>% # выбрать только столбец средних as_vector() # превращаем столбец в вектор означает
## среднее1 среднее2 среднее3 среднее4 среднее5 среднее6 среднее7 среднее8 среднее9среднее10 ## 41.5 54.5 44.5 16.0 67.5 3.5 75.0 17.5 26.0 59.5
l1 %*% означает # взять взвешенную сумму групповых средств
## [1] ## [1,] 2.7
Разницу между общими средними французскими и испанскими винными сортами винограда (вопрос исследования 2) можно вычислить, используя веса для сравнения \(L2\):
l2 %*% означает
## [1] ## [1,] -4.5
Мы видим, что разница между французскими и испанскими большими средними равна \(-4.5\).
Третий вопрос касался среднего значения итальянского вина по сравнению со средним значением общего среднего значения французских и испанских вин. если мы возьмем веса из контраста \(L3\), мы получим
l3 %*% означает
## [1] ## [1,] -16.
Вывод говорит нам, что разница в рейтинге итальянских вин и других вин вместе взятых равна \(-16.9\).
Если мы хотим получить информацию об этих различиях в совокупности , таких как стандартные ошибки, доверительные интервалы и проверка нулевой гипотезы, R нужна матрица схемы кодирования и запуск линейной модели. Мы можем сделать это, предоставив матрицу \(\mathbf{S}\) для соответствующего фактора анализа.
Сначала нам нужно присвоить матрицу \(\mathbf{S}\) переменной Wine_ID . Теперь обратите пристальное внимание. Помните, что \(\mathbf{S}\) содержит 3 переменные, по одной для каждого из вопросов исследования.
S %>% дроби()
## [1] [2] [3] ## [1,] 2/5 1/3 0 ## [2,] 2/5 1/3 0 ## [3,] -4/5 -37/60 -3/10 ## [4,] 2/5 -2/3 0 ## [5,] -4/5 23/60 -3/10 ## [6,] 2/5 1/3 0 ## [7,] 2/5 -2/3 0 ## [8,] -4/5 23/60 -3/10 ## [9,] 0 -3/20 9/10 ## [10,] 2/5 1/3 0
counters(winedata$Wine_ID) <- S
А теперь посмотрим на переменную winedata$Wine_ID :
counters(winedata$Wine_ID)
## [1] [2] [3] ## 1 0.0000000000013322676 ## 10 0,4000000000000001887379 0,3333333 -0,00000000000000004451563 ## [4] [5] ## 1 -0,465512812774
0000000000000000133643 0.000000000000000002109297
## 10 -0,05984724318329412 -0,1326887763238566 -0,07710845683022048147048
## 4 -0,3273037 2 96027 -0,016575501864466677
## 5 0,20387060346826 3260 -0,46144577158488964130356
## 6 -0,009661461346584975 -0,059847243183261913
## 7 0,735044997813823663 0,09586- 58062900
## 8 0,20387060346826
3260 0,53855422841511035869644
## 9 0.000000000000000030 0.000000000000000030
## 10 -0,009661461346584975 -0,059847243183261913
## [8] [9]
## 1 -0,2533805812177535865537 -0,370322165202
636474
## 2 -0,26936741210464747 -0,21420722451101067984602
## 3 -0,4703661047296714414756 0,15006381518- 04
## 4 0,65511422571329092 -0,107340777127137504
## 5 0,2351830523648356374711 -0,07504652881
6106981
## 6 0,02614011017484321 -0,132688776323255808
## 7 -0,2227354464125860800117 -0,04275228051101442883208
## 8 0,2351830523648356374711 -0,075046528816106981
## 9 0. 0000000000000002709825 0.00000000000000002109297
## 10 0.02614011017484321 0.867311223676047519 Похоже, R автоматически добавил еще шесть столбцов. Общее количество столбцов теперь равно девяти, и если мы запустим линейную модель вместе с перехватом, мы увидим десять параметров на выходе нашей линейной модели.
Мы говорим R запустить линейную модель с рейтингом в качестве зависимой переменной, Wine_ID в качестве независимой переменной, где матрица схемы кодирования — это новая матрица схемы кодирования.
данные вина %>%
lm(рейтинг ~ Wine_ID, данные = .) %>%
tidy(conf.int = TRUE)
## # Набор символов: 10 × 7
## оценка срока std.error statistic p.value conf.low conf.high
##
## 1 (Перехват) 40,5 7,21 5,62 0,000221 24,5 56,6
## 2 Wine_ID1 2.7914,7 0,190 0,853 -30,0 35,6
## 3 Wine_ID2 -4,50 16,1 -0,279 0,786 -40,4 31,4
## 4 Wine_ID3 -16,9 24,2 -0,699 0,500 -70,8 37,0
## 5 Wine_ID4 36,2 22,8 1,59 0,144 -14,6 87,0
## 6 Wine_ID5 -36,5 22,8 -1,60 0,140 -87,4 14,3
## 7 Wine_ID6 28,3 22,8 1,24 0,243 -22,5 79,1
## 8 Wine_ID7 -13,8 22,8 -0,604 0,559 -64,6 37,0
## 9Wine_ID8 -30,1 22,8 -1,32 0,216 -80,9 20,7
## 10 Wine_ID9 19. 5 22.8 0.854 0.413 -31.4 70.3
В выводе мы видим десять разных параметров. Первый (перехват) мы можем игнорировать, поскольку с ним не связан исследовательский вопрос. Следующие три параметра связаны с исследовательскими вопросами.
Мы видим значения 2,79 для исследовательского вопроса 1, -4,50 для исследовательского вопроса 2 и -16,9 для исследовательского вопроса 3, аналогичные тем, что мы нашли, взглянув на внутренние продукты (проверьте это сами). Эта проверка говорит нам, что мы действительно вычислили контрасты, которые хотели вычислить. В дополнение к этим оценкам контрастов мы видим стандартные ошибки, тесты нулевой гипотезы и 95% доверительные интервалы для этих контрастов. Мы можем игнорировать все остальные параметры (от Wine_ID4 до Wine_ID_ID9 ): они нужны только для того, чтобы убедиться, что у нас столько же параметров, сколько категорий, чтобы дисперсия остаточной ошибки вычислялась правильно.
Обратите внимание, что перехват также был включен автоматически. Чтобы увидеть, что она представляет, мы можем добавить эту точку пересечения 1 с к \(\mathbf{S}\) и выполнить обратную операцию, чтобы получить матрицу контраста
cbind(1, counters(winedata$Wine_ID)) %>% гинв ()
## [1] [2] [3] [4] [5] [6]
## [1,] 0.10000000 0.10000000 0.10000000 0.1000000 0.10000000 0.100000000
## [2,] 0,16666667 0,16666667 -0,25000000 0,1666667 -0,25000000 0,166666667
## [3,] 0,16666667 0,16666667 -0,33333333 -0,3333333 0,16666667 0,166666667
## [4,] -0,08333333 -0,08333333 -0,16666667 -0,1666667 -0,08333333 -0,083333333
## [5,] -0,46551281 0,50809884 -0,07710846 -0,0165755 0,53855423 -0,059847243
## [6,] -0,37032217 -0,21420722 0,15009306 -0,1073408 -0,07504653 0,867311224
## [7,] -0,07677688 -0,31164140 -0,40774121 -0,3273038 0,20387060 -0,009661462
## [8,] -0,46551281 0,50809884 -0,07710846 -0,0165755 -0,46144577 -0,059847243
## [9,] -0,25338058 -0,262 -0,47036610 0,6
6 0,23518305 0,0261
## [10,] -0,37032217 -0,21420722 0,15009306 -0,1073408 -0,07504653 -0,132688776
## [7] [8] [9] [10]
## [1,] 0. 10000000 0.10000000 0.0999999999999999
33 0.100000000
## [2,] 0,16666667 -0,25000000 -0,24999999999999975019982 0,166666667
## [3,] -0,33333333 0,16666667 -0,00000000000000028457238 0,166666667
## [4,] -0,16666667 -0,08333333 0,999999999999994388 -0,083333333
## [5,] 0,096 -0,46144577 -0,00000000000000007235857 -0,059847243
## [6,] -0,04275228 -0,07504653 0,00000000000000002264278 -0,132688776
## [7,] 0,73504500 0,20387060 0,00000000000000002782425 -0,009661462
## [8,] 0,096 0,53855423 0,000000000000000007834034 -0,059847243
## [9,] -0,22273545 0,23518305 0,00000000000000014075064 0,0261
## [10,] -0.04275228 -0.07504653 0.00000000000000008156353 0.867311224 Мы видим, что первая строка дает среднее значение по всем 10 винам:
\[\begin{aligned}
\frac{1}{10}M_1 + \frac{1}{10}M_2 + \frac{1}{10}M_3 + \frac{1}{10}M_4 + \frac{1}{10}M_5 + \frac{1}{10}M_6 + \frac{1}{10}M_7 + \frac{1}{10}M_8 + \frac{1}{10}M_9 + \frac{1}{10}M_{ 10}\номер\\
= \frac{M_1 + M_2 +M_3 +M_4 +M_5 + M_6 + M_7 + M_8 + M_9 + M_{10}}{10}
\end{aligned}\]
Вы можете игнорировать это значение в выводе, если оно не представляет интереса.
Обзор
Пользовательские контрасты в анализе lm()
- Проверьте порядок уровней, используя
level() .
- Укажите контрастные векторы-строки и объедините их в матрицу \(\mathbf{L}\).
- Пусть R вычисляет матрицу \(\mathbf{S}\), обратную матрице \(\mathbf{L}\), используя
ginv() из пакета MASS .
- Назначить матрицу \(\mathbf{S}\) группирующей переменной, например,
контрасты(данные$переменная) <- S .
- Запустите линейную модель.
- R автоматически создаст перехват. Его значение на выходе часто будет средним значением. Остальные параметры являются оценками ваших контрастов в \(\mathbf{L}\). Если количество строк в \(\mathbf{L}\) меньше, чем количество категорий, R автоматически добавит дополнительные столбцы в фактическую матрицу схемы кодирования. Параметры для этих столбцов в выводе можно игнорировать.
10.10 Контрасты в случае двух категориальных переменных
До сих пор мы обсуждали только ситуации с одной категориальной независимой переменной в вашем анализе данных. Здесь мы обсудим ситуацию, когда у нас есть две независимые переменные. Начнем с двух категориальных независимых переменных. В следующем разделе будет обсуждаться ситуация с одной числовой и одной категориальной независимой переменной.
Задание контрастов для двух категориальных переменных является прямым расширением того, что мы видели ранее. Для каждой категориальной переменной вы можете указать, какие контрасты вы хотели бы иметь на выходе.
Давайте посмотрим на набор данных под названием удовлетворенность работой , чтобы увидеть, как это делается на практике. Фрейм данных является частью пакета datarium (не забудьте установить этот пакет, если вы еще этого не сделали).
данные («удовлетворенность работой», пакет = «датариум»)
удовлетворенность работой %>%
glimpse()
## Строки: 58
## Столбцы: 4
## $ id 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,…
## $ гендер мужчина, мужчина, мужчина, мужчина, мужчина, мужчина, мужчина, мужчина, мужчина, …
## $ education_level школа, школа, школа, школа, школа, школа, школа…
## $ оценка 5,51, 5,65, 5,07, 5,51, 5,94, 5. 80, 5.22, 5.36, 4.78, …
Мы видим одну числовую переменную с результатом и три факторные переменные. Факторы всегда хранятся с категориями в определенном порядке. Давайте посмотрим на переменную пол.
jobsatisfaction$gender %>% level()
## [1] "мужской" "женский"
Переменный пол имеет два уровня, первым из которых является "мужской". Обратите внимание, что порядок не в алфавитном порядке, поэтому человек, подготовивший этот кадр данных, явно предполагал, что мужчины будут первой категорией.
Предварительно указанная матрица кодирования для этой переменной также может быть просмотрена:
контрасты(удовлетворенность работой$пол)
## женщина
## мужчина 0
## female 1
Мы видим, что это стандартное фиктивное кодирование (кодирование лечения) с фиктивной переменной для женского пола, так что «мужской» будет эталонной категорией, если мы ничего не изменим.
Теперь посмотрим на факторную переменную education_level .
удовлетворенность работой$education_level %>% уровней()
## [1] «школа» «колледж» «университет»
Опять же, порядок не в алфавитном порядке, а в упорядоченном порядке от «низшего» к «высшему» образованию.
Матрица схемы кодирования показывает стандартное фиктивное кодирование, где «школа» является справочной категорией.
контрасты(удовлетворенность работой$education_level)
## колледж университет
## школа 0 0
## колледж 1 0
## University 0 1
Предположим, мы хотим запустить линейную модель, в которой удовлетворенность работой предсказывается или объясняется полом и уровнем образования. Что касается гендерного эффекта, мы довольствуемся тем, что мужчины составляют референтную группу, поэтому мы сохраняем кодирование лечения. Мы также довольствуемся фиктивным кодированием для education_level , где «школа» является справочной категорией.
# запустить линейную модель с полом и уровнем образования
out1 <- удовлетворенность работой %>%
lm(оценка ~ пол + образование_уровень,
данные = . )
out1 %>% tidy() ## # Набор символов: 4 × 5
## оценка срока std.error statistic p.value
##
## 1 (Перехват) 5,66 0,164 34,6 1,66e-38
## 2 полженский -0,125 0,161 -0,777 4,41e- 1
## 3 education_levelcollege 0,757 0,198 3,82 3,47д- 4
## 4 education_leveluniversity 3.25 0.196 16.6 7.01e-23
В выходных данных мы видим, что оценки удовлетворенности работой в среднем на 0,125 балла ниже у женщин, чем у мужчин. Кроме того, мы видим, что контраст между колледжем и школой ( education_levelcollege ) равен 0,757. Это означает, что степень удовлетворенности работой у мужчин с высшим образованием на 0,757 выше, чем у мужчин, окончивших только среднюю школу. Контраст между университетом и школой ( education_leveluniversity ) показывает, что выпускники университетов оценивают удовлетворенность работой на 3,25 балла выше, чем выпускники школ. Перехват равен 5,66, что означает, что люди, входящие в референтную группу учащихся мужского пола, окончивших школу, набирают в среднем 5,66.
Чтобы проверить правильность наших интерпретаций, мы можем проверить групповые средние.
удовлетворенность работой %>%
group_by (уровень_образования, пол) %>%
суммировать (среднее = среднее (оценка))
## `summarise()` сгруппировал вывод по 'education_level'. Вы можете переопределить, используя
## аргумент `.groups`.
## # Тиббл: 6 × 3
## # Группы: education_level [3]
## education_level пол среднее значение
## <фкт> <фкт>
## 1 школьный мальчик 5,43
## 2 школьница 5,74
## 3 студент мужского пола 6.22
## 4 девушки из колледжа 6,46
## 5 университет мужской 9.29
## 6 университет женский 8.41
Чтобы проверить интерпретацию перехвата, делаем
удовлетворенность работой %>%
filter((gender == "мужской") & (education_level == "school")) %>% # только мужчины со школой
summarise(mean = mean(score)) # вычислить среднее значение
## # tibble: 1 × 1
## иметь в виду
## <дбл>
## 1 5.43
Мы видим небольшое несоответствие: наблюдаемое среднее не соответствует предсказанию линейной модели!
Интерпретация результатов, которую мы только что обсудили, и сделанные прогнозы действительны только в том случае, если модель хорошо отражает реальную ситуацию в популяции. На самом деле их может быть модерация : влияние пола может быть смягчено уровнем образования. То есть разница между самками и самцами может быть разной, в зависимости от уровня образования. Модель только с двумя основными эффектами предполагает, что различия между женщинами и мужчинами составляют -0,125, независимо от образования. Если мы хотим знать, смягчается ли эта гендерная разница образованием, нам нужно искать эффекты взаимодействия. Для этого нам нужно включить в модель термин взаимодействия. Мы сохраняем кодирование обработки по умолчанию (фиктивное кодирование).
out2 <- удовлетворенность работой %>%
lm(оценка ~ пол + уровень_образования + пол:уровень_образования, данные = .)
out2 %>% tidy(conf.int = TRUE)
## # tibble: 6 × 7
## оценка срока std.error statistic p.value conf.low conf.high
##
## 1 (Перехват) 5,43 0,183 29,6 3,26e-34 5,06 5,79
## 2 полженский 0,314 0,253 1,24 2,19е- 1 -0,193 0,821
## 3 education_levelcolle… 0,797 0,259 3,07 3,37e- 3 0,276 1,32
## 4 education_levelunive… 3,87 0,253 15,3 6,87e-21 3,36 4,37
## 5 полженщина:образование… -0,0747 0,357 -0,209 8,35e- 1 -0,792 0,643
## 6 genderfemale:educati… -1,20 0,353 -3,40 1,29e- 3 -1,91 -0,493
Теперь нас интересует только, отличается ли член взаимодействия от 0. Если мы посмотрим на вывод out2 , мы увидим два условия взаимодействия: один для дополнительного гендерного эффекта у студентов колледжей (по сравнению с выпускниками средней школы) и один для дополнительного гендерного эффекта у выпускников университетов. В главе 9мы узнали, что если мы хотим знать, является ли общее замедление значительным, мы должны выполнить дисперсионный анализ.
anova(out2)
## Таблица дисперсионного анализа
##
## Ответ: оценка
## Df Сумма Sq Среднее значение Sq F Pr(>F)
## пол 1 0,541 0,541 1,7872 0,187090
## education_level 2 113,684 56,842 187,8921 < 0,00000000000000022 ***
## пол:образование_уровень 2 4,440 2,220 7,33790,001559 **
## Остаток 52 15,731 0,303
## ---
## Значение. коды: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1
Мы сравниваем гендерный эффект для трех различных уровней образования, поэтому мы должны увидеть две степени свободы для члена взаимодействия. Значение \(F\) больше 1 и оказывается значимым на уровне 0,05, \(F(2, 52) = 7,338, p = 0,002\). Таким образом, мы можем сделать вывод, что гендерный эффект различен в зависимости от уровня образования.
Теперь эти выходные данные anova() и выходные данные lm() говорят нам только о том, что гендерный эффект различен для разных уровней образования: гендерный эффект на -0,07 больше у выпускников колледжей, чем у выпускников школ, и - В 1,20 раза больше у выпускников вузов, чем у выпускников школ. Однако что, если одним из вопросов исследования будет оценка гендерного эффекта для различных уровней образования? То есть, насколько велико влияние пола на выпускников школ, насколько велико влияние пола на выпускников колледжей и насколько велико влияние пола на выпускников университетов?
Мы должны быть в состоянии получить оценки этих величин, работая с различными параметрами в результатах анализа lm() . Например, гендерный эффект у выпускников школ должен быть равен параметру 2 («genderfemale»). Поскольку референтной группой являются выпускники школ мужского пола, параметр «пол женщины» дает разницу с выпускниками школ женского пола. Этот параметр имеет стандартную ошибку, и мы можем запросить доверительный интервал. Но все сложнее, когда мы хотим оценить гендерный эффект у выпускников колледжей и университетов. На основе параметров в выходных данных модели мы могли бы определить ожидаемые гендерные эффекты в этих группах, но у нас не было бы информации о стандартных ошибках и, следовательно, доверительных интервалах.
Математически стандартная ошибка линейной комбинации параметров зависит от стандартных ошибок исходных параметров и степени, в которой оценки связаны друг с другом (коррелированы). Но поскольку большинство из нас не математики, мы не хотим об этом беспокоиться. Мы просто просим R сделать необходимые вычисления для нас. Теперь мы покажем вам, как получить стандартные ошибки и доверительные интервалы для влияния одной категориальной переменной, учитывая уровень другого категориального уровня.
Мы используем пакет reghelper (сначала установите его). Сначала мы запускаем модель с включенными эффектами взаимодействия, а затем используем функцию simple_slopes() на выходе модели.
# с использованием пакета reghelper
библиотека (reghelper)
удовлетворенность работой %>%
lm(оценка ~ пол + уровень_образования + пол:уровень_образования, данные = .) %>%
simple_slopes(confint = TRUE,
ci.width = 0,95) ## гендерное образование_уровень Тест Оценка Стд. Ошибка 2,5% 97,5% т значение
## 1 юноша сстест (колледж) 0,7967 0,2593 0,2764 1,3170 3,0726
## 2 мужской сстест (университет) 3,8653 0,2527 3,3582 4,3724 15,2950
## 3 жен сстест (колледж) 0,7220 0,2460 0,2284 1,2156 2,9352
## 4 жен сстест (университет) 2,6650 0,2460 2,1714 3,1586 10,8343
## 5 sstest школа 0,3143 0,2527 -0,1928 0,8214 1,2438
## 6 sstest колледж 0,2397 0,2527 -0,2674 0,7468 0,9484
## 7 sstest университет -0,8860 0,2460 -1,3796 -0,3924 -3,6020
## df Pr(>|t|) Sig.
## 1 52 0,0033741 **
## 2 52 < 0,00000000000000022 ***
## 3 52 0,0049525 **
## 4 52 0.000000000000006074 ***
## 5 52 0,21
## 6 52 0,3473349
## 7 52 0.0007058 ***
В выводе вы видите семь строк. В первом ряду вы видите эффект выпускника колледжа (референтная группа — «школа»), учитывая, что это мужчина. Другими словами, у мужчин мы видим, что разница между выпускниками колледжей и выпускниками школ составляет 0,79.67, со стандартной ошибкой 0,2593 и доверительным интервалом 95%, и проверкой нулевой гипотезы.
Мы игнорируем первые четыре строки, потому что они о влиянии education_level при заданном значении пола (мужской или женский). Поскольку нас интересует влияние пола при определенном уровне образования, мы проверяем только последние три строки. В строках 5, 6 и 7 мы видим, что влияние пола равно 0,31 для выпускников школ, 0,24 для выпускников колледжей и -0,89.для выпускников вузов. Также приведены соответствующие стандартные ошибки, доверительные интервалы и тесты нулевой гипотезы. Поэтому мы можем сообщить:
«В наборе данных об удовлетворенности работой мы оценили гендерный эффект (женщин по отношению к мужчинам) на трех уровнях образования: выпускники школы, колледжа и университета. Результаты показали, что среди выпускников школ гендерная разница составила 0,314 (SE = 0,253). , 95% ДИ: -0,193, 0,821), у выпускников колледжей разница составила 0,240 (SE = 0,253, 95% ДИ: -0,267, 0,747), а у выпускников университетов разница составила -0,886 (SE = 0,246, 95% ДИ: -1,380, -0,392)"
Обратите внимание, что общий термин «простые наклоны» относится к влиянию одной независимой переменной на зависимую переменную при заданном значении другой независимой переменной. Другой термин для этого — «простые эффекты». Такие простые эффекты можно изучать, когда у вас есть две категориальные независимые переменные, а также в ситуациях с числовыми независимыми переменными, как мы увидим в следующем разделе.
10.11 Контрасты в случае одной категориальной переменной и одной числовой переменной
Вернемся к примеру в главе 9, где мы анализировали словарь как функцию возраста и социально-экономического статуса (СЭС). Зависимой переменной было количество слов, которые человек знает. Искали модерацию эффекта возраста (числового), СЭС (категориального). Другими словами, мы смоделировали другую линейную зависимость между возрастом и словарным запасом 9.0028, в зависимости от СЭС . В этой главе мы немного расширим этот пример, введя три уровня SES: низкий, средний и высокий.
Предположим, мы хотим знать, каковы наклоны для каждого из уровней SES. Данные имеют структуру, как в таблице 10.10. В общей сложности данные поступили от 100 детей, по одному измерению на ребенка.
Таблица 10.10: Пример набора данных о словарном запасе детей из страны X.
идентификатор ребенка
СЭС
возраст
слова
1
средний
4
111
2
низкий
1
94
3
средний
4
116
4
средний
1
82
5
высокая
1
103
6
низкий
4
124
Как и в предыдущем разделе, мы спрашиваем, как влияет одна переменная при определенном уровне второй переменной. Единственное отличие теперь состоит в том, что первая переменная является числовой, а не категориальной. Таким образом, аналогично предыдущему разделу, мы можем решить задачу следующим образом.
Мы запускаем стандартный анализ, используя фиктивное кодирование, смотрим на вывод и убеждаемся, что правильно понимаем значения в выводе. Для этого нам нужно знать порядок уровней и схему кодирования.
level(data_words$SES) # проверить порядок уровней
## NULL
data_words <- data_words %>%
mutate(SES = factor(SES)) # превращаем SES в факторную переменную
level(data_words$SES)
## [1] "средний" "высокий" "низкий"
контрасты(data_words$SES) # проверка фиктивного кодирования
## высокий низкий
## среднее 0 0
## высокий 1 0
## низкий 0 1
out_words <- data_words %>%
lm(words ~ age + SES + age:SES, data = .) # запустить модель с фиктивным кодированием
out_words %>% аккуратно()
## # Тиббл: 6 × 5
## оценка срока std. error statistic p.value
##
## 1 (Перехват) 87,0 4,95 17,6 1,90e-31
## 2 возраст 3,70 1,53 2,42 1,76е- 2
## 3 SESвысокий 12,5 6,66 1,87 6,43e- 2
## 4 SESlow 8.81 7.12 1.24 2.19e- 1
## 5 возраст:СЭвысокий -4,04 2,04 -1,98 5,06д- 2
## 6 возраст:SESlow -1,85 2,19 -0,844 4,01e- 1
В главе 9 мы научились читать этот вывод. Мы видим, что «средняя» группа СЭС является референтной. Эффект возраста для этой группы равен 3,70 (наклон).
Теперь давайте снова воспользуемся функцией simple_slopes() , чтобы также увидеть влияние возраста для других групп SES.
библиотека (reghelper)
слова_данных %>%
lm(слова ~ возраст + SES + возраст:SES, данные = .) %>%
simple_slopes(confint = TRUE,
ci.width = 0,95) ## age SES Test Estimate Std. Ошибка 2,5% 97,5% t значение df
## 1 1,803566 ssтест (высокий) 5,1778 3,5549 -1,8805 12,2360 1,4565 94
## 2 1,803566 ssтест (низкий) 5,4767 3,7220 -1,9134 12,8669 1,4714 94
## 3 3,03 ssтест (высокий) 0,2204 2,5593 -4,8612 5,3020 0,0861 94
## 4 3,03 ssтест (низкий) 3,2097 2,5773 -1,9076 8,3271 1,2454 94
## 5 4,256434 ssтест (высокий) -4,7369 3,6048 -11,8942 2,4204 -1,3141 94
## 6 4,256434 sтест (низкий) 0,9427 3,7217 -6,4468 8,3322 0,2533 94
## 7 sstest среднее 3,6957 1,5297 0,6583 6,7330 2,4159 94
## 8 sstest high -0,3464 1,3511 -3,0290 2,3362 -0,2564 94
## 9 sstest low 1,8472 1,5662 -1,2626 4,9570 1,1794 94
## Pr(>|t|) Знак.
## 1 0,14858
## 2 0,14451
## 3 0,
## 4 0,21610
## 5 0,19202
## 6 0,80059
## 7 0,01763 *
## 8 0,79820
## 9 0,24122 В последних трех строках мы видим эффекты (наклоны) возраста при среднем, высоком или низком СЭС. Следовательно, мы можем сообщить:
«В наборе данных о размере словарного запаса 100 детей разного возраста мы оценили коэффициент наклона регрессии количества слов в зависимости от возраста в годах на трех уровнях СЭС: низком, среднем и высоком. Результаты показали, что при низком У детей со СЭС наклон составил 1,85 (СО = 1,57, 95% ДИ: -1,26, 4,96), у детей со средним СЭС наклон составил 3,70 (СО = 1,53, 95% ДИ: 0,66, 6,73), а у детей с высоким СЭС - наклон был -0,35 (SE = 1,35, 95% ДИ: -3,03, 2,34)».
Теперь, когда мы получили ответы на вопросы нашего исследования, вы можете задаться вопросом, как интерпретировать остальные шесть строк в выходных данных простых наклонов. Например, в первой строке мы видим эффект высокого SES (относительно «среднего») при определенном значении возраста, а именно 1,803566 лет. Другими словами, для детей в возрасте 1,80 лет (почти двух лет) мы видим, что дети с высоким SES набирают на 5,1778 баллов больше по словарному запасу, чем дети со средним SES.
Во второй строке мы видим, что у детей в возрасте 1,80 года дети с низким СЭС набирают на 5,4767 балла больше, чем дети со средним СЭС.
В следующих двух строках (строки 3 и 4) мы видим другие оценки для детей в возрасте 3,03 года, а в строках 5 и 6 мы видим влияние СЭС на детей в возрасте 4,26 лет.
Эти три значения возраста (1,80, 3,03 и 4,26) выбираются функцией simple_slopes() путем вычисления среднего значения (3.03), вычитания стандартного отклонения переменной возраста из среднего (\(3,03 - 1,23 = 1,80\)), и прибавив стандартное отклонение к среднему (\(3,03 + 1,23= 4,26\), при округлении до двух знаков после запятой). Это можно проверить, получив некоторую описательную статистику для возраст переменная.
data_words %>% суммировать (среднее = среднее (возраст),
sd = sd(возраст)) ## # Тиббл: 1 × 2
## среднее SD
##
## 1 3. 03 1.23
Поскольку с числовой переменной у вас не категории, а бесконечное число возможных значений, нам просто нужно выбрать пару значений, для которых мы изучаем эффект SES. Можно сказать, что мы смотрим на влияние СЭС, учитывая три значения возраста: «относительно молодой» (1,80 года), «средний» (3,03 года) и «относительно старый» (4,26).
10.12 Почему бы просто не разделить данные на подмножества?
Вы можете задаться вопросом, а не проще ли было бы разделить данные на три части? Например, в предыдущем разделе мы могли бы разделить данные на детей с низким, средним и высоким SES, а затем смоделировать влияние возраста на слова для каждой отдельной группы? Или в предыдущем разделе: разделить данные на три набора данных, по одному для каждого уровня образования, а затем искать разницу между женщинами и мужчинами для каждого набора данных отдельно?
Что ж, возможно, вы правы в том, что это может быть проще, но приведет к немного другим результатам. Если бы мы разделили данные на три части и провели три отдельных анализа, у нас было бы меньше точек данных, на которых можно основывать наши выводы. В каждом отдельном анализе у нас будет три параметра модели: один для точки пересечения, один для наклона, а также один для дисперсии остатков. Эта остаточная дисперсия используется для вычисления стандартной ошибки параметров пересечения и наклона. Поэтому, если вы разделите данные и проведете анализ каждой части отдельно, вы получите три разных значения этой остаточной дисперсии. С другой стороны, если вы выполняете анализ один раз, используя все данные и вычисляя контрасты, имеется только одна оценка остаточной дисперсии. И не только это: еще и степеней свободы больше. Это общий размер выборки минус количество параметров в таблице регрессии. Вместе с рассчитанной одиночной остаточной дисперсией это влияет на размер стандартных ошибок, а также на критическое значение \(t\) для доверительных интервалов. В целом можно ожидать большей статистической мощности при одновременном использовании всех данных, чем при проведении отдельных анализов.
Как правило, лучше провести один анализ ваших данных и ответить на вопросы исследования, используя результаты этого единственного анализа, чем разделять данные и проводить отдельные анализы. Если у вас нет сомнений в том, что остаточная дисперсия одинакова для разных групп (гомоскедастичность, см. главу 7), вам следует использовать только одну линейную модель.
10.13 Выводы
-
При анализе категориальных переменных в линейной модели категориальная переменная представлена новым набором числовых переменных.
-
Эти новые переменные могут быть фиктивными переменными (по умолчанию), но также могут быть числовыми переменными других типов.
-
Отношение этих числовых переменных к исходной категориальной переменной обобщается в матрице кодирования \(\mathbf{S}\).
-
Матрица кодирования \(\mathbf{S}\) определяет, какие значения печатаются в таблице регрессии. Эти значения на самом деле являются контрастами.
-
Контрасты представляют собой взвешенные суммы групповых средних. Контрасты представлены в матрице контрастов \(\mathbf{L}\).
-
Контрасты предназначены для решения конкретных исследовательских вопросов.
-
Матрица \(\mathbf{L}\) является обратной к \(\mathbf{S}\), а \(\mathbf{S}\) является обратной к \(\mathbf{L}\).
-
Если ваша модель предполагает модерацию, вы можете рассчитать «простые эффекты» (или «простые наклоны»): эффекты одной независимой переменной при определенных значениях второй независимой переменной.
Ключевые концепции
- Контрасты
- Взвешенная сумма
- Линейная комбинация
- Матрица контраста \(\mathbf{L}\)
- Матрица схемы кодирования \(\mathbf{S}\)
- Фиктивное кодирование/кодирование обработки
- Кодирование эффекта
- Helmert контрастирует с
- Контрастное кодирование последовательных различий
- Простые эффекты (простые наклоны)
Ссылка Определение и значение | Dictionary.com
- Основные определения
- Синонимы
- Викторина
- Связанный контент
- Примеры
- Британские
- ИДИОМЫ И ФРАЗА
[ref-er-uhns, ref-ruhns]
/ ˈrɛf əns, ruhns].
См. синонимы для: ссылка / ссылка / ссылки / ссылка на Thesaurus.com
существительное
действие или пример ссылки.
упоминание; намек.
то, что означает имя или обозначение; обозначение.
указание в книге или письмо к какой-либо другой книге, отрывок и т. д.
книга, отрывок и т. д., на которые направлено.
контрольная метка (по умолчанию 2).
материал, содержащийся в сноске или библиографии, или указанный ссылочным знаком.
использование или обращение в информационных целях: библиотека для всеобщего ознакомления.
книга или другой источник полезных фактов или информации, такой как энциклопедия, словарь и т. д.
лицо, к которому обращаются за свидетельством о своем характере, способностях и т. д.
обычно письменное заявление о характере, способностях и т. д.
отношение, отношение или уважение: все лица, независимо от возраста.
глагол (используется с дополнением), на который ссылаются, ссылаются.
снабдить (книгу, диссертацию и т. д.) ссылками: Каждый новый том тщательно снабжается ссылками.
упорядочить (примечания, данные и т. д.) для удобства поиска: Статистические данные указаны в глоссарии.
для ссылки: для ссылки на файл.
ДРУГИЕ СЛОВА ДЛЯ ссылки
4 примечание, цитата.
11 индоссамент.
12 рассмотрение, озабоченность.
См. синонимы для справки на Thesaurus.com
ВИКТОРИНА
Сыграем ли мы «ДОЛЖЕН» ПРОТИВ. "ДОЛЖЕН" ВЫЗОВ?
Следует ли вам пройти этот тест на «должен» или «должен»? Это должно оказаться быстрым вызовом!
Вопрос 1 из 6
Какая форма используется для указания обязательства или обязанности кого-либо?
Происхождение ссылки
Впервые записано в 1580–1590 гг.; refer + -ence
ДРУГИЕ СЛОВА ИЗ reference
mis·reference, существительноеnon·reference, существительноеpre·reference, существительноеsub·re·er·ence, существительное
un·ref ·начало, прилагательное
СЛОВА, КОТОРЫЕ МОЖНО СПУТАТЬ СО ссылкой
1. намек, ссылка 2. ссылка , ссылка Dictionary.com Unabridged
На основе Random House Unabridged Dictionary, © Random House, Inc., 2022
Слова, относящиеся к ссылке
аллюзия, намек, инсинуация, упоминание, примечание, цитата, характер, одобрение, рекомендация, дань уважения, свидетельство, письмо, реклама, ассоциация, приписывание, связь, подтекст, указание, инсинуация, вставка
Как использовать ссылку в предложении
-
Было много положительных отзывов от людей, интересующихся небинарными людьми.
Grindr’s Trans Dating Problem|Дэвид Левесли|9 января 2015|DAILY BEAST
-
В 2011 году ЛГБТ-СМИ Queerty привлекло приложение к ответственности за якобы удаление учетных записей, которые упоминали о трансгендерности.
Проблема транс-свиданий Гриндра|Дэвид Левсли|9 января 2015 г.|DAILY BEAST
-
Затем он дает некоторое представление о своей психике - в комплекте со ссылкой на Дом животных.
Huckabee 2016: Нагнись и возьми как узник!|Оливия Нуцци|8 января 2015|DAILY BEAST
-
Примерно через неделю она бросила JSwipe и нашла своего нынешнего бойфренда, нееврея, на OkCupid.
Моя неделя в еврейском Tinder|Эмили Шайр|5 января 2015 г.|DAILY BEAST
-
Атеист советует своим собратьям-неверующим, как не разговаривать с верующими.
Дело против неприкрытого атеизма|Стив Нойманн|4 января 2015 г.|DAILY BEAST
-
Экспатриированные бывшие повстанцы встревожились из-за неполучения возмещения ущерба и новостей из своих домов.
Филиппинские острова|Джон Форман
-
Он также заявляет, что Audiencia практически не существует, и поэтому нет высшего суда, в котором можно добиваться справедливости.
Филиппинские острова, 1493-1898, том XX, 1621-1624|Разное
-
Эти эскимосы очень любили запускать воздушных змеев, ради них самих, не говоря уже о полезности!
Великан Севера|Р.М. Ballantyne
-
De moi, je ne say qu'en dire, d'autant que je ne veux asserter ny le si ny le non en ce dont je n'ay vidence.
Отношения иезуитов и союзнические документы, Vol. II: Acadia, 1612-1614|Разное
-
Certes le capitaine Merveilles et ses monstrerent leur pit non vulgaire.
Отношения иезуитов и союзнические документы, Vol. II: Acadia, 1612-1614 | Различные
Британские определения словаря для справки
Ссылка
/ (ˈrɛfərəns, ˈrɛfrəns) /
существительное
. представленный судье
направление внимания на отрывок в другом месте или на другую книгу, документ и т. д.
книга или отрывок, на который ссылаются
упоминание или аллюзия в этой книге есть несколько ссылок на Гражданскую войну
философия
- связь между словом, фразой или символом и объектом или идеей, к которым они относятся
- объект, указанный выражениемСравнить смысл ( по определению 12)
- источник информации или фактов
- (как модификатор) справочник; справочная библиотека
письменное свидетельство о характере или способностях
лицо, указанное для такого свидетельства
- (вслед за) связь или разграничение, особенно принадлежность к определенному классу или группе или по принадлежности к ней; уважать или относиться ко всем людям без привязки к полу или возрасту
- (в качестве модификатора)референтная группа
точка отсчета факт, лежащий в основе оценки или оценки; критерий
круг ведения конкретные пределы ответственности, определяющие деятельность органа, проводящего расследование, и т. д.
глагол (tr)
предоставить или составить список литературы для (академической диссертации, публикации и т. д.)
сделать ссылку на; См. TOHE, ссылаясь на Хомский, 1956
Предлог
Коммерция со ссылкой на вершину. Ваша буква 9 -й Аббревиации: Re
, полученные формы ссылки
Референс, Unounreferential (ˌrɛfəˈrɛnʃəl), Adjective Collins (ˌrɛfəˈrɛnʃəl), Adjective
. Цифровое издание
© William Collins Sons & Co. Ltd. 1979, 1986 © HarperCollins
Publishers 1998, 2000, 2003, 2005, 2006, 2007, 2009, 2012
Другие идиомы и фразы со ссылкой
ссылка
см. в отношении (ссылка) на.
Словарь идиом американского наследия®
Авторские права © 2002, 2001, 1995, издательство Houghton Mifflin Harcourt Publishing Company. Опубликовано издательством Houghton Mifflin Harcourt Publishing Company.
Типы социальных групп | Безграничная социология |
Природа групп
Социальная группа — это два или более человека, которые взаимодействуют друг с другом, имеют схожие характеристики и коллективно имеют чувство единства.
Цели обучения
Сравните концепцию социальной группы, основанную на социальной сплоченности, с концепцией социальной идентичности
Ключевые выводы
Ключевые моменты
- Социальная группа демонстрирует некоторую степень социальной сплоченности и представляет собой нечто большее, чем просто собрание или совокупность индивидуумов.
- Социальная сплоченность может быть сформирована через общие интересы, ценности, представления, этническое или социальное происхождение и родственные связи, среди прочих факторов.
- Подход социальной идентичности постулирует, что необходимым и достаточным условием формирования социальных групп является осознание того, что индивид принадлежит и признается членом группы.
- Подход социальной идентичности постулирует, что необходимым и достаточным условием формирования социальных групп является осознание того, что индивид принадлежит и признается членом группы.
Ключевые термины
- социальная группа : Совокупность людей или животных, которые имеют определенные характеристики, взаимодействуют друг с другом, принимают ожидания и обязательства в качестве членов группы и имеют общую идентичность.
- Подход социальной идентичности : Полагает, что необходимым и достаточным условием для формирования социальных групп является осознание принадлежности к общей категории.
- Подход к социальной сплоченности : Больше, чем просто набор или совокупность отдельных лиц, таких как люди, ожидающие на автобусной остановке, или люди, стоящие в очереди.
В социальных науках социальная группа — это два или более человека, которые взаимодействуют друг с другом, имеют схожие характеристики и имеют коллективное чувство единства. Это очень широкое определение, так как оно включает в себя группы всех размеров, от диад до целых обществ. Общество можно рассматривать как большую группу, хотя большинство социальных групп значительно меньше. Общество также можно рассматривать как людей, которые взаимодействуют друг с другом, имея общие черты в отношении культуры и территориальных границ.
Социальная группа демонстрирует некоторую степень социальной сплоченности и представляет собой нечто большее, чем просто собрание или совокупность индивидуумов, таких как люди, ожидающие на автобусной остановке, или люди, стоящие в очереди. Характеристики, общие для членов группы, могут включать интересы, ценности, представления, этническое или социальное происхождение и родственные связи. Один из способов определить, можно ли считать совокупность людей группой, состоит в том, если лица, принадлежащие к этой совокупности, используют самореферентное местоимение «мы»; использование «мы» для обозначения группы людей часто подразумевает, что эта коллекция думает о себе как о группе. Примеры групп включают: семьи, компании, круги друзей, клубы, местные отделения братств и женских клубов, а также местные религиозные общины.
Известный социальный психолог Музафер Шериф сформулировал техническое определение социальной группы. Это социальная единица, состоящая из ряда индивидуумов, взаимодействующих друг с другом по поводу:
- общих мотивов и целей;
- принятое разделение труда;
- установленные статусные отношения;
- принятых норм и ценностей в отношении вопросов, имеющих отношение к группе; и
- развитие принятых санкций, таких как повышение и наказание, когда нормы соблюдались или нарушались.
Определению социальных групп, основанному на социальной сплоченности, явно противопоставлена перспектива социальной идентичности, основанная на выводах, сделанных в теории социальной идентичности. Подход социальной идентичности постулирует, что необходимыми и достаточными условиями для формирования социальных групп является «осознание принадлежности к общей категории» и что социальная группа может быть «полезно осмыслена как ряд индивидуумов, которые усвоили принадлежность к той же социальной категории, что и компонент их Я-концепции». Другими словами, в то время как подход социальной сплоченности предполагает, что члены группы будут спрашивать: «Кто меня привлекает?», подход социальной идентичности предполагает, что члены группы просто спросят: «Кто я?»
Подход к социальной идентичности : Объяснительные профили теории социальной идентичности и самокатегоризации.
Должностные лица правоохранительных органов : Сотрудник правоохранительных органов является социальной категорией, а не группой. Однако сотрудники правоохранительных органов, которые все работают в одном участке и регулярно встречаются, чтобы планировать свой день и работать вместе, будут считаться частью группы.
Основные группы
Первичная группа обычно представляет собой небольшую социальную группу, члены которой связаны близкими, личными и прочными отношениями.
Цели обучения
Перечислите не менее трех определяющих характеристик основной группы
Основные выводы
Ключевые моменты
- Основные группы характеризуются заботой друг о друге, общими занятиями и культурой, а также длительными периодами времени, проведенными вместе. Они психологически утешительны и весьма влиятельны в развитии личности.
- Семьи и близкие друзья являются примерами первичных групп.
- Целью первичных групп на самом деле являются сами отношения, а не достижение какой-либо другой цели.
- Понятие первичной группы было введено Чарльзом Кули в его книге Социальная Организация : Исследование более широкого разума .
Ключевые термины
- Близкие друзья : Это примеры первичных групп.
- группа : Ряд вещей или лиц, находящихся в некотором отношении друг к другу.
- связь : Связь или ассоциация; состояние родства.
Социологи различают два типа групп на основе их характеристик. Первичная группа обычно представляет собой небольшую социальную группу, члены которой связаны близкими, личными и прочными отношениями. Эти группы отмечены заботой друг о друге, общими занятиями и культурой, а также длительными периодами времени, проведенными вместе. Целью первичных групп на самом деле являются сами отношения, а не достижение какой-либо другой цели. Семьи и близкие друзья являются примерами первичных групп.
Чарльз Кули
Понятие первичной группы было введено Чарльзом Кули, социологом Чикагской школы социологии, в его книге «Социальная организация: исследование более широкого разума » (1909). Первичные группы играют важную роль в развитии личности. Кули утверждал, что влияние первичной группы настолько велико, что люди цепляются за первичные идеалы в более сложных ассоциациях и даже создают новые первичные группы внутри формальных организаций. В этом отношении он рассматривал общество как постоянный эксперимент по расширению социального опыта и координации разнообразия. Поэтому он проанализировал действие таких сложных социальных форм, как формальные институты и системы социальных классов, а также тонкий контроль над общественным мнением.
Функции основных групп
Первичная группа — это группа, в которой человек обменивается неявными элементами, такими как любовь, забота, забота, поддержка и т. д. Примерами этого могут быть семейные группы, любовные отношения, группы поддержки в кризисных ситуациях и церковные группы. Отношения, формирующиеся в первичных группах, часто бывают длительными и самоцелью. Они также часто психологически утешают вовлеченных лиц и служат источником поддержки и поощрения.
Чарльз Кули : Понятие первичной группы было введено Чарльзом Кули, социологом Чикагской школы социологии, в его книге «Социальная организация: исследование более широкого разума» (1909).
Семьи как социальные группы : Эта семья 1970-х годов может быть примером первичной группы.
Второстепенные группы
Вторичные группы — это большие группы, отношения которых безличны и ориентированы на достижение цели; их отношения временны.
Цели обучения
Опишите основные различия между первичными и вторичными группами
Ключевые выводы
Ключевые моменты
- Различие между первичными и вторичными группами было первоначально предложено Чарльзом Кули. Он назвал их «вторичными», потому что они обычно развиваются в более позднем возрасте и с гораздо меньшей вероятностью будут влиять на личность человека, чем первичные группы.
- Вторичные отношения предполагают слабые эмоциональные связи и мало личных знаний друг о друге. В отличие от первичных групп, вторичные группы не имеют цели поддерживать и развивать отношения самостоятельно.
- Вторичные группы включают в себя группы, в которых обмениваются явные товары, такие как труд на заработную плату, услуги на платежи и тому подобное. К ним также относятся университетские классы, спортивные команды и группы сотрудников.
Ключевые термины
- первичная группа : Обычно это небольшая социальная группа, члены которой связаны близкими, личными, продолжительными отношениями. Эти группы отмечены заботой друг о друге, общими занятиями и культурой, а также длительными периодами времени, проведенными вместе.
- группа : Ряд вещей или лиц, находящихся в некотором отношении друг к другу.
- Второстепенные группы : Это большие группы, отношения между которыми безличные и целеустремленные.
В отличие от первых групп, вторичные группы представляют собой большие группы, отношения между которыми безличны и ориентированы на достижение цели. Люди во вторичной группе взаимодействуют на менее личном уровне, чем в первичной группе, и их отношения обычно носят временный, а не длительный характер. Некоторые вторичные группы могут существовать в течение многих лет, хотя большинство из них краткосрочны. Такие группы также начинаются и заканчиваются с очень небольшим значением в жизни вовлеченных людей.
Вторичные отношения связаны со слабыми эмоциональными связями и небольшим личным знанием друг друга. В отличие от первичных групп, вторичные группы не имеют цели поддерживать и развивать отношения самостоятельно.
Чарльз Кули
Различие между первичными и вторичными группами было первоначально предложено Чарльзом Кули. Он назвал группы «первичными», потому что люди часто сталкиваются с такими группами в начале своей жизни, и такие группы играют важную роль в развитии личной идентичности. Вторичные группы обычно развиваются в более позднем возрасте и с гораздо меньшей вероятностью будут влиять на чью-либо идентичность.
Функции
Поскольку вторичные группы создаются для выполнения функций, роли людей более взаимозаменяемы. Вторичная группа — это та, частью которой вы решили стать. Они основаны на интересах и деятельности. Это место, где многие люди могут встретить близких друзей или людей, которых они просто назвали бы знакомыми. Вторичные группы — это также группы, в которых обмениваются явные товары, такие как труд на заработную плату, услуги на платежи и т. д. Примерами этого могут быть занятость, отношения между продавцом и клиентом, врач, механик, бухгалтер и т. д. Университетский класс, спортивная команда и рабочие в офисе — все это, вероятно, образует вторичные группы. Первичные группы могут формироваться внутри вторичных групп по мере того, как отношения становятся более личными и близкими.
Одноклассники как второстепенная группа : Класс учащихся обычно считается вторичной группой.
Врачи как вторичные группы : Отношения между врачом и пациентом являются еще одним примером вторичных групп.
Входящие и чужие группы
Ингруппы — это социальные группы, к которым человек чувствует свою принадлежность, в то время как индивид не идентифицирует себя с чужой группой.
Цели обучения
Вспомните две ключевые особенности внутригрупповых предубеждений по отношению к чужим группам
Key Takeaways
Key Points
- Ингрупповой фаворитизм относится к предпочтению и привязанности к своей группе по сравнению с чужой группой или кем-либо, кого считают за пределами своей группы.
- Одним из ключевых факторов, определяющих групповые предубеждения, является необходимость повышения самооценки. То есть люди найдут причину, какой бы незначительной она ни была, чтобы доказать себе, почему их группа лучше.
- Межгрупповая агрессия — это любое поведение, направленное на причинение вреда другому человеку, потому что он или она является членом чужой группы, причем такое поведение рассматривается ее объектами как нежелательное.
- Эффект однородности чужой группы заключается в том, что человек воспринимает членов чужой группы как более похожих друг на друга, чем члены своей группы (например, «они похожи; мы разные»).
- Предубеждение — это враждебное или негативное отношение к людям в отдельной группе, основанное исключительно на их принадлежности к этой группе.
- Стереотип — это обобщение о группе людей, в которой идентичные характеристики приписываются практически всем членам группы, независимо от фактических различий между членами.
Ключевые термины
- предвзятость внутри группы : Это относится к предпочтению и близости к своей группе по сравнению с чужой группой или кем-либо, кого считают не принадлежащим к своей группе.
- Межгрупповая агрессия : Это любое поведение, направленное на причинение вреда другому человеку, потому что он или она является членом чужой группы, поведение, рассматриваемое его целями как нежелательное.
- Внутригрупповой фаворитизм : Это относится к предпочтению и близости к своей группе по сравнению с чужой группой или кем-либо, кого считают не принадлежащим к своей группе. Это может выражаться в оценке других, связывании, распределении ресурсов и многими другими способами.
В социологии и социальной психологии «свои» и «чужие» группы — это социальные группы, к которым индивидуум чувствует, что он или она принадлежит в качестве члена, или по отношению к которым он испытывает презрение, оппозицию или желание конкурировать соответственно. Люди, как правило, положительно относятся к членам своих групп — явление, известное как внутригрупповая предвзятость. Термин происходит из теории социальной идентичности, которая выросла из работ социальных психологов Анри Тайфеля и Джона Тернера.
Анри Тайфел : Понятия «своя» и «чужая» группы происходят из теории социальной идентичности, которая выросла из работ социальных психологов Анри Тайфеля и Джона Тернера.
Внутригрупповой фаворитизм относится к предпочтению и близости к своей группе по сравнению с чужой группой или кем-либо, кого считают за пределами своей группы. Это может выражаться в оценке других, связывании, распределении ресурсов и многих других способах. Ключевым моментом в понимании предубеждений внутри группы/вне группы является определение психологического механизма, который управляет предубеждением. Одним из ключевых факторов, определяющих групповые предубеждения, является необходимость повышения самооценки. То есть люди найдут причину, какой бы незначительной она ни была, чтобы доказать себе, почему их группа лучше.
Межгрупповая агрессия – это любое поведение, направленное на причинение вреда другому человеку, потому что он или она является членом чужой группы. Межгрупповая агрессия является побочным продуктом внутригрупповой предвзятости, поскольку, если убеждения своей группы оспариваются или если наша группа чувствует угрозу, они будут выражать агрессию по отношению к чужой группе. Основным мотивом межгрупповой агрессии является восприятие конфликта интересов между своей и чужой группой. Агрессия оправдывается через дегуманизацию чужой группы, потому что чем больше чужая группа дегуманизируется, тем «менее они заслуживают гуманного обращения, предписываемого универсальными нормами» 9.0003
French Стереотипы : Предубеждение похоже на стереотип в том, что стереотип представляет собой обобщение о группе людей, в которой практически всем членам группы приписываются одинаковые характеристики, независимо от фактических различий между членами.
Эффект однородности вне группы - это восприятие членов вне группы как более похожих друг на друга, чем члены своей группы, например. «Они похожи, мы разные». Эффект однородности вне группы был обнаружен при использовании самых разных социальных групп, от политических и расовых групп до возрастных и гендерных групп. Воспринимающие, как правило, имеют впечатление о разнообразии или изменчивости членов группы вокруг этих центральных тенденций или типичных атрибутов этих членов группы. Таким образом, суждения о стереотипах чужой группы переоцениваются, что подтверждает мнение о том, что стереотипы чужой группы являются чрезмерными обобщениями. В эксперименте по проверке однородности чужой группы исследователи обнаружили, что люди других рас воспринимаются более похожими, чем представители своей собственной расы. . Когда белым студентам показывали лица нескольких белых и нескольких черных людей, они позже более точно узнавали белые лица, которых они видели, и часто ошибочно узнавали черные лица, которых раньше не видели. Противоположные результаты были получены, когда испытуемые состояли из чернокожих.
Предубеждение — это враждебное или негативное отношение к людям в отдельной группе, основанное исключительно на их принадлежности к этой группе. Есть три компонента. Первым является аффективный компонент, представляющий как тип эмоции, связанный с отношением, так и серьезность отношения. Второй — когнитивный компонент, включающий убеждения и мысли, составляющие установку. Третий – поведенческий компонент, относящийся к своим действиям – люди не просто придерживаются установок, но и воздействуют на них. Предубеждение в первую очередь относится к отрицательному отношению к другим, хотя можно иметь и положительное предубеждение в пользу чего-либо. Предубеждение похоже на стереотип в том, что стереотип — это обобщение о группе людей, в которой идентичные характеристики приписываются практически всем членам группы, независимо от фактических различий между членами.
Справочные группы
Социологи называют референтной группой любую группу, которую люди используют в качестве эталона для оценки себя и своего поведения.
Цели обучения
Объясните цель референтной группы
Основные выводы
Ключевые моменты
- Теория социального сравнения утверждает, что люди используют сравнения с другими, чтобы получить точную самооценку и научиться определять себя. Референтная группа — это понятие, относящееся к группе, с которой сравнивают человека или другую группу.
- Референтные группы обеспечивают ориентиры и контрасты, необходимые для сравнения и оценки групповых и личных характеристик.
- Роберт К. Мертон выдвинул гипотезу о том, что люди сравнивают себя с референтными группами людей, занимающих социальную роль, к которой стремится индивид.
Ключевые термины
- самоидентификация : многомерная конструкция, относящаяся к восприятию человеком «я» по отношению к любому количеству характеристик, таких как академические и неакадемические, гендерные роли и сексуальность, расовая идентичность ,и многие другие.
- социальная роль : это набор связанного поведения, прав и обязанностей, концептуализированных акторами в социальной ситуации.
- референтная группа : это понятие, относящееся к группе, с которой сравнивают человека или другую группу.
Теория социального сравнения основана на вере в то, что у людей есть стремление получить точную самооценку. Люди оценивают свои собственные мнения и определяют себя, сравнивая себя с другими. Одним из важных понятий в этой теории является референтная группа. Референтная группа относится к группе, с которой сравнивают человека или другую группу. Социологи называют референтной группой любую группу, которую люди используют в качестве эталона для оценки себя и своего поведения.
Референтные группы используются для оценки и определения характера данного индивидуума или других групповых характеристик и социологических атрибутов. Это группа, к которой индивид относится или стремится относиться психологически. Референтные группы становятся системой отсчета человека и источником для упорядочения его или ее переживаний, восприятий, познания и представлений о себе. Это важно для определения самоидентификации человека, его установок и социальных связей. Эти группы становятся основой для сравнения или противопоставления, а также для оценки внешнего вида и производительности.
Роберт К. Мертон выдвинул гипотезу о том, что люди сравнивают себя с референтными группами людей, которые занимают социальную роль, к которой стремится индивид. Референтные группы выступают в качестве системы отсчета, к которой люди всегда обращаются, чтобы оценить свои достижения, свою роль, стремления и амбиции. Референтная группа может быть либо из группы членов, либо из группы, не состоящей в членстве.
Примером референтной группы является группа людей, имеющих определенный уровень достатка. Например, человек в США с годовым доходом в 80 000 долларов может считать себя богатым, если сравнивать себя с людьми из среднего слоя доходов, которые зарабатывают примерно 32 000 долларов в год. Если, однако, тот же человек считает релевантной референтной группой те, кто входит в 0,1% самых богатых домохозяйств в США, те, кто зарабатывает 1,6 миллиона долларов или более, то доход человека в 80 000 долларов заставит его или ее казаться довольно бедным.
Референтная группа : Референтные группы обеспечивают ориентиры и контрасты, необходимые для сравнения и оценки групповых и личных характеристик.
Референтная группа : Референтные группы становятся точкой отсчета человека и источником для упорядочения его или ее переживаний, восприятий, познания и представлений о себе.
Социальные сети
Социальная сеть — это социальная структура между акторами, соединяющая их через различные социальные знакомства.
Цели обучения
Схема, в миниатюре, ваших социальных сетей с использованием узлов и связей
Ключевые выводы
Ключевые точки
- Изучение социальных сетей называется как «анализом социальных сетей», так и «теорией социальных сетей».
- Теория социальных сетей рассматривает социальные отношения с точки зрения узлов и связей. Узлы — это отдельные действующие лица в сетях, а связи — это отношения между действующими лицами.
- В социологии социальный капитал — это ожидаемые коллективные или экономические выгоды, получаемые в результате преимущественного обращения и сотрудничества между отдельными лицами и группами.
- Правило 150 гласит, что размер настоящей социальной сети ограничен примерно 150 участниками.
- Феномен маленького мира — это гипотеза о том, что цепочка социальных знакомств, необходимая для связи одного произвольного человека с другим произвольным человеком в любой точке мира, обычно коротка.
- Милграм также определил концепцию знакомого незнакомца или человека, которого узнают по обычной деятельности, но с которым никто не взаимодействует.
- Милгрэм также определил концепцию знакомого незнакомца или человека, которого узнают по обычной деятельности, но с которым никто не взаимодействует.
Ключевые термины
- узел : Это отдельные действующие лица в сетях, а связи — это отношения между действующими лицами.
- социальный капитал : добрая воля, симпатия и связи, созданные социальным взаимодействием внутри и между социальными сетями.
Социальная сеть — это социальная структура между акторами, отдельными лицами или организациями. Это указывает на способы, которыми они связаны через различные социальные знакомства, начиная от случайного знакомства и заканчивая тесными семейными узами. Изучение социальных сетей называют как «анализом социальных сетей», так и «теорией социальных сетей». Исследования в ряде академических областей показали, что социальные сети действуют на многих уровнях, от семей до уровня наций, и играют решающую роль. роль в определении того, как решаются проблемы, управляются организации и в какой степени люди преуспевают в достижении своих целей. Социологи интересуются социальными сетями из-за их влияния и важности для человека. Социальные сети — это основные инструменты, используемые людьми для знакомства с другими людьми, отдыха и поиска социальной поддержки.
Иллюстрация социальной сети : Пример схемы социальной сети
Теория социальных сетей рассматривает социальные отношения с точки зрения узлов и связей. Узлы — это отдельные действующие лица в сетях, а связи — это отношения между действующими лицами. Между узлами может быть много видов связей. В самом простом виде социальная сеть представляет собой карту всех соответствующих связей между изучаемыми узлами. Сеть также может быть использована для определения социального капитала отдельных участников. В социологии социальный капитал — это ожидаемые коллективные или экономические выгоды, получаемые в результате преимущественного обращения и сотрудничества между отдельными лицами и группами.
Правило 150 гласит, что размер настоящей социальной сети ограничен примерно 150 участниками. Правило вытекает из кросс-культурных исследований в социологии и особенно антропологии максимального размера деревни. Феномен маленького мира - это гипотеза о том, что цепочка социальных знакомств, необходимая для связи одного произвольного человека с другим произвольным человеком в любой точке мира, обычно коротка. Эта концепция породила знаменитую фразу «шесть степеней разделения» после 19Психолог Стэнли Милгрэм провел 67 экспериментов с маленьким миром, который обнаружил, что двух случайных граждан США связывало в среднем шесть знакомых. Милгрэм также определил концепцию знакомого незнакомца или человека, которого узнают по обычной деятельности, но с которым никто не взаимодействует. Тот, кого ежедневно видят в поезде или в спортзале, но с которым иначе не общаются, является примером знакомого незнакомца. Если такие люди встречаются в незнакомой обстановке, например, во время путешествия, они с большей вероятностью представятся, чем совершенно незнакомые люди, поскольку у них есть общий опыт.
Учеба
Недавние исследования показывают, что социальные сети американцев сужаются, и все больше и больше людей не имеют близких доверенных лиц или людей, с которыми они могли бы поделиться своими самыми сокровенными мыслями. В 1985 году средний размер сети физических лиц в Соединенных Штатах составлял 2,94 человека. Сети сократились почти на целое доверенное лицо к 2004 году, до 2,08 человека. Почти половина, 46,3% американцев, говорят, что у них есть только одно доверенное лицо или нет доверенных лиц, с которыми они могут обсудить важные вопросы. Наиболее часто встречающийся ответ на вопрос, сколько у человека доверенных лиц, в 2004 г. был равен нулю9.0003
Интернет-сообщества
В Интернете социальные взаимодействия могут происходить в онлайн-сообществах, что исключает необходимость общения лицом к лицу.
Цели обучения
Обсудите не менее трех основных характеристик сетевых сообществ.
Основные выводы
Ключевые моменты
- Интернет-сообщество — это виртуальное сообщество, существующее в сети, члены которого поддерживают свое существование, участвуя в членских ритуалах.
- Интернет-сообщество может принимать форму информационной системы, в которой каждый может публиковать контент, например, доску объявлений или систему, в которой только ограниченное число людей может инициировать публикации, например, веб-блоги.
- Стоимость играет роль во всех аспектах и этапах для онлайн-сообществ. Довольно дешевые и легкодоступные технологии и программы также повлияли на увеличение числа онлайн-сообществ.
Ключевые термины
- информационная система : Любая система обработки данных, ручная или компьютеризированная
- Интернет-сообщества : Это виртуальное сообщество, которое существует в Интернете и члены которого поддерживают его существование, участвуя в ритуале членства.
- веб-журнал : веб-сайт в форме постоянного журнала; блог.
Интернет-сообщество — это виртуальное сообщество, которое существует в Интернете и члены которого обеспечивают его существование, принимая участие в ритуалах членства. Интернет-сообщество может принимать форму информационной системы, в которой любой может публиковать контент, например, доску объявлений или систему, в которой только ограниченное число людей может инициировать публикации, например, веб-блоги. Интернет-сообщества также стали дополнительной формой общения между людьми, которые знают друг друга преимущественно в реальной жизни. Многие средства используются в социальном программном обеспечении по отдельности или в комбинации, включая текстовые чаты и форумы, использующие голос, видеотекст или аватары.
Развитие интернет-сообществ
Идея сообщества не является новой концепцией. Однако новым является перенос его в онлайн-мир. Сообщество ранее определялось как группа из одного места. Если вы жили в обозначенном районе, вы становились частью этого сообщества. Взаимодействие между членами сообщества осуществлялось в основном лицом к лицу и в социальной среде. Это определение для сообщества больше не применяется. В онлайн-мире социальные взаимодействия больше не должны происходить лицом к лицу или основываться на близости. Вместо этого они могут быть буквально с кем угодно и где угодно. Существует набор ценностей, которые следует учитывать при разработке онлайн-сообщества. Некоторые из этих ценностей включают: возможности, образование, культуру, демократию, социальные услуги, равенство в экономике, информацию, устойчивость и общение.
Стоимость играет роль во всех аспектах и этапах для онлайн-сообществ. Довольно дешевые и легкодоступные технологии и программы также повлияли на увеличение числа онлайн-сообществ. В то время как для участия в некоторых онлайн-сообществах, таких как определенные веб-сайты знакомств или для ежемесячной подписки на игры, необходима оплата, многие другие сайты бесплатны для пользователей, таких как социальные сети Facebook и Twitter. Из-за дерегулирования и расширения доступа в Интернет популярность онлайн-сообществ возросла. Интернет-сообщества обеспечивают мгновенное удовлетворение, развлечение и обучение.
Создание интернет-сообществ
В каждом онлайн-сообществе есть определенный набор участников, которые участвуют по-разному. Скрытень наблюдает за сообществом и просматривает контент, но не добавляет к контенту или обсуждению сообщества. Новичок вовлекает сообщество, начинает предоставлять контент и предварительно участвует в нескольких дискуссиях. Постоянный постоянно добавляет в обсуждение и контент сообщества и взаимодействует с другими пользователями. Лидер признается ветераном-участником, который объединяется с постоянными игроками для создания более высоких концепций и идей. Наконец, старейшина покидает общину по разным причинам. Например, у пожилого человека могут измениться интересы или у него может не хватить времени, чтобы оставаться на связи.
Учеба
В 2001 году консультанты McKinsey & Company провели исследование, в ходе которого обнаружили, что только 2% клиентов, совершающих сделки, возвращаются после первой покупки. Напротив, 60% новых пользователей онлайн-сообществ начали использовать и регулярно посещать сайты после первого знакомства с ними. Интернет-сообщества изменили правила игры для розничных фирм, поскольку заставили их изменить свои бизнес-стратегии.
Facebook : Хотя для участия в некоторых онлайн-сообществах, таких как определенные сайты знакомств или для ежемесячной подписки на игры, необходима оплата, многие другие сайты, такие как социальные сети Facebook и Twitter, бесплатны для пользователей.
Лицензии и атрибуции
Контент под лицензией CC, совместно используемый ранее
- Курирование и пересмотр. Предоставлено : Boundless.com. Лицензия : CC BY-SA: Attribution-ShareAlike
Лицензионный контент CC, конкретная атрибуция
- социальная группа. Предоставлено : Викисловарь. Расположен по адресу : https://en.wiktionary.org/wiki/social_group. Лицензия : CC BY-SA: Attribution-ShareAlike
- Введение в социологию/группы. Предоставлено : Wikibooks. Лицензия : CC BY-SA: Attribution-ShareAlike
- Социальная сплоченность. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Подход к социальной идентификации. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Социальная группа. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничная. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- Офицеры секретной службы США. Предоставлено : Wikimedia. Лицензия : Общественное достояние: Нет данных Copyright
- Сидячий подход. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- группа. Предоставлено : Викисловарь. Лицензия : CC BY-SA: Attribution-ShareAlike
- Социальная группа. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Колледж OpenStax, социология. 17 сентября 2013 г. Предоставлено : OpenStax CNX. Расположен по адресу : https://openstax.org/books/introduction-sociology/pages/1-introduction-to-sociology. Лицензия : CC BY-SA: Attribution-ShareAlike
- Чарльз Кули. Предоставлено : Википедия. Расположен по адресу : https://en.wikipedia.org/wiki/Charles_Cooley. Лицензия : CC BY-SA: Attribution-ShareAlike
- Введение в социологию/группы. Предоставлено : Wikibooks. Лицензия : CC BY-SA: Attribution-ShareAlike
- связь. Предоставлено : Викисловарь. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- Офицеры секретной службы США. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Подход SIT. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- 1975family. Предоставлено : Wikimedia. Лицензия : CC BY: Attribution
- Чарльз Кули. Предоставлено : Википедия. Лицензия : Общедоступное достояние: Нет данных Copyright
- Социальная группа. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Введение в социологию/группы. Предоставлено : Wikibooks. Лицензия : CC BY-SA: Attribution-ShareAlike
- Первичная и вторичная группы. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- основная группа. Предоставлено : Википедия. Лицензия : CC BY-SA: Группа Attribution-ShareAlike
- . Предоставлено : Викисловарь. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- Офицеры секретной службы США. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Подход SIT. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- 1975family. Предоставлено : Wikimedia. Лицензия : CC BY: Attribution
- Чарльз Кули. Предоставлено : Википедия. Лицензия : Общественное достояние: неизвестно Авторские права
- Доктор использует стетоскоп для осмотра молодого пациента. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Ian Mackenzie High School Class. Предоставлено : Wikimedia. Расположен по адресу : https://commons.wikimedia.org/wiki/File:Ian_Mackenzie_High_School_Classroom.jpg. Лицензия : Общественное достояние: Неизвестно Copyright
- Парадигма минимальной группы. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Предубеждение. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Теория социальной идентичности. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Смещение однородности за пределами группы. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Группа. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Предвзятость внутри группы и вне группы. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Колледж OpenStax, социология. 17 сентября 2013 г. Предоставлено : OpenStax CNX. Расположен по адресу : https://openstax.org/books/introduction-sociology/pages/1-introduction-to-sociology. Лицензия : CC BY-SA: Attribution-ShareAlike
- Стереотипы. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- предвзятость внутри группы. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Офицеры секретной службы США. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Подход SIT. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- 1975family. Предоставлено : Wikimedia. Лицензия : CC BY: Attribution
- Чарльз Кули. Предоставлено : Википедия. Лицензия : Общественное достояние: неизвестно Авторские права
- Доктор использует стетоскоп для осмотра молодого пациента. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Ian Mackenzie High School Class. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Copyright
- Tajfel. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- Stu00e9ru00e9otypes Franu00e7ais. Предоставлено : Wikimedia. Лицензия : CC BY-SA: Attribution-ShareAlike
- Теория социального сравнения. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Колледж OpenStax, социология. 17 сентября 2013 г. Предоставлено : OpenStax CNX. Расположен по адресу : https://openstax.org/books/introduction-sociology/pages/1-introduction-to-sociology. Лицензия : CC BY-SA: Attribution-ShareAlike
- собственная личность. Предоставлено : Википедия. Расположен по адресу : https://en.wikipedia.org/wiki/Самоидентификация. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- социальная роль. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Офицеры секретной службы США. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Подход SIT. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- 1975family. Предоставлено : Викимедиа. Лицензия : CC BY: Attribution
- Чарльз Кули. Предоставлено : Википедия. Лицензия : Общественное достояние: неизвестно Авторские права
- Доктор использует стетоскоп для осмотра молодого пациента. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Ian Mackenzie High School Class. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно. Copyright
- Tajfel. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- Stu00e9ru00e9otypes Franu00e7ais. Предоставлено : Wikimedia. Лицензия : CC BY-SA: Attribution-ShareAlike
- ВПЧ-гонка. Предоставлено : Wikimedia. Лицензия : Общедоступное достояние: Неизвестно Авторские права
- Одна из сидячих групп, Open Space, Trusted Advisors, ACMP 2012 | Flickr - Обмен фотографиями!. Предоставлено : Flickr. Расположен по адресу : https://www.flickr.com/photos/stella12/7045899425/. Лицензия : CC BY: Attribution
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- социальный капитал. Предоставлено : Викисловарь. Расположен по адресу : https://en.wiktionary.org/wiki/social_capital. Лицензия : CC BY-SA: Attribution-ShareAlike
- Знакомый незнакомец. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Введение в социологию/группы. Предоставлено : Wikibooks. Лицензия : CC BY-SA: Attribution-ShareAlike
- Социальный капитал. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Социальная сеть. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- Офицеры секретной службы США. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Подход SIT. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- 1975family. Предоставлено : Wikimedia. Лицензия : CC BY: Attribution
- Чарльз Кули. Предоставлено : Википедия. Лицензия : Общественное достояние: неизвестно Авторские права
- Доктор использует стетоскоп для осмотра молодого пациента. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Ian Mackenzie High School Class. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Тайфел. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- Stu00e9ru00e9otypes Franu00e7ais. Предоставлено : Wikimedia. Лицензия : CC BY-SA: Attribution-ShareAlike
- ВПЧ-гонка. Предоставлено : Wikimedia. Лицензия : Общедоступное достояние: Неизвестно Авторские права
- Одна из сидячих групп, Open Space, Trusted Advisors, ACMP 2012 | Flickr - Обмен фотографиями!. Предоставлено : Flickr. Расположен по адресу : https://www.flickr.com/photos/stella12/7045899425/. Лицензия : CC BY: Attribution
- Социальная сеть. Предоставлено : Википедия. Лицензия : Общедоступное достояние: Нет данных Copyright
- Интернет-сообщество. Предоставлено : Википедия. Лицензия : CC BY-SA: Attribution-ShareAlike
- блог. Предоставлено : Викисловарь. Лицензия : CC BY-SA: Attribution-ShareAlike
- Безграничный. Предоставлено : Безграничное обучение. Лицензия : CC BY-SA: Attribution-ShareAlike
- информационная система. Предоставлено : Викисловарь. Расположен по адресу : https://en.wiktionary.org/wiki/information_system. Лицензия : CC BY-SA: Attribution-ShareAlike
- Офицеры секретной службы США. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Подход SIT. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- 1975family. Предоставлено : Wikimedia. Лицензия : CC BY: Attribution
- Чарльз Кули. Предоставлено : Википедия. Лицензия : Общественное достояние: неизвестно Авторские права
- Доктор использует стетоскоп для осмотра молодого пациента. Предоставлено : Wikimedia. Лицензия : Общественное достояние: Авторские права неизвестны
- Класс средней школы Иэна Маккензи. Предоставлено : Wikimedia. Лицензия : Общественное достояние: неизвестно Авторское право
- Тайфел. Предоставлено : Википедия. Лицензия : CC BY: Attribution
- Stu00e9ru00e9otypes Franu00e7ais. Предоставлено : Wikimedia. Лицензия : CC BY-SA: Attribution-ShareAlike
- ВПЧ-гонка. Предоставлено : Wikimedia. Расположен по адресу : https://commons.wikimedia.org/wiki/File:Hpv-race.jpg. Лицензия : Общедоступное достояние: Неизвестно Авторские права
- Одна из сидячих групп, Open Space, Trusted Advisors, ACMP 2012 | Flickr - Обмен фотографиями!. Предоставлено : Flickr. Расположен по адресу : https://www.flickr.com/photos/stella12/7045899425/. Лицензия : CC BY: Attribution
- Социальная сеть. Предоставлено : Википедия. Лицензия : Общественное достояние: неизвестно Copyright
- Значок Facebook. Предоставлено : Wikimedia. Лицензия : Общедоступное достояние: Не известно Авторское право
В чем разница? Тесты, основанные на критериях, и тесты, основанные на нормах
Вас когда-нибудь озадачивала подобная ситуация?
Осенью учащийся по имени Бруно хорошо сдал школьную аттестацию. Он набрал 55 баллов из 100, что округ считает «высоким» для его уровня. Его процентильный ранг был 88, что ставит его выше своих сверстников.
Позднее в том же учебном году, весной, Бруно снова сдал ту же самую оценку. На этот раз он набрал 60 баллов, все еще «отлично» для своей оценки, но внезапно его процентиль упал до 38.
Что случилось? Весенняя оценка Бруно, равная 60, выше, чем его осенняя оценка, равная 55, но его процентильный ранг ниже: с 88 осенью до 38 весной. Как это вообще возможно?
Тесты, основанные на критериях, и тесты, основанные на нормах
Чтобы понять, что произошло, нам нужно понять разницу между тестами, основанными на критериях, и тестами, основанными на нормах.
Первое, что нужно понять, это то, что даже эксперт по оценке не может отличить тест, основанный на критериях, и тест, основанный на нормах, просто взглянув на них. Разница на самом деле заключается в баллах — и некоторые тесты могут дать и результатов по критерию, и результатов по норме!
Как интерпретировать тесты на основе критериев
Тесты на основе критериев сравнивают знания или навыки человека с заранее определенным стандартом, целью обучения, уровнем успеваемости или другим критерием. В тестах, основанных на критериях, результаты каждого человека сравниваются непосредственно со стандартом, без учета того, как другие учащиеся справляются с тестом. В тестах, основанных на критериях, часто используются «сокращенные баллы», чтобы распределить учащихся по таким категориям, как «базовый», «продвинутый» и «продвинутый».
Если вы когда-нибудь были на карнавале или в парке развлечений, вспомните таблички с надписью «Вы должны быть такого высокого роста, чтобы кататься на этом аттракционе!» со стрелкой, указывающей на определенную строку на диаграмме роста. Линия, указанная стрелкой, выполняет функцию критерия; оператор аттракциона сравнивает рост каждого человека с ним, прежде чем разрешить им сесть на аттракцион.
Обратите внимание, что не имеет значения, сколько других людей в очереди или насколько они высоки или низкорослы; то, разрешено ли вам садиться на аттракцион, определяется исключительно вашим ростом. Даже если вы самый высокий человек в очереди, если ваша макушка не достигает линии на таблице роста, вы не сможете ездить верхом.
Оценки на основе критериев работают аналогичным образом: индивидуальный балл и то, как этот балл классифицируется, не зависят от успеваемости других учащихся. В приведенных ниже диаграммах вы можете видеть, что оценка и категория успеваемости учащегося («ниже уровня знаний») изменяются на , а не на , независимо от того, является ли он учащимся с самой высокой успеваемостью, средней или низкой успеваемостью.
Это означает, что знание оценки учащегося по тесту, основанному на критериях, скажет вам только о том, как этот конкретный учащийся сравнивается с критерием, но не о том, были ли его результаты ниже среднего, выше среднего или среднего по сравнению со своими сверстниками.
Как интерпретировать тесты, основанные на нормах
Меры, основанные на нормах, сравнивают знания или навыки человека со знаниями или навыками группы норм. Состав группы нормы зависит от оценки. Для оценок учащихся нормальная группа часто представляет собой национально репрезентативную выборку из нескольких тысяч учащихся одного класса (а иногда и в один и тот же период учебного года). Нормированные группы также могут быть дополнительно сужены по возрасту, статусу изучающих английский язык (ELL), социально-экономическому уровню, расе/этнической принадлежности или многим другим характеристикам.
Одним из стандартных показателей, с которым знакомы многие семьи, являются диаграммы роста веса ребенка в кабинете педиатра, которые показывают, к какому процентилю относится вес ребенка. Ребенок в 50-м процентиле имеет средний вес; ребенок в 75-м процентиле весит на больше, чем на , чем 75% детей в группе нормы, и на столько же или меньше, чем на , чем самые тяжелые 25% детей в группе нормы; а ребенок в 25-м процентиле весит на больше , чем 25% детей в группе нормы и такие же или менее , чем 75% из них. Важно отметить, что эти показатели, основанные на норме, не говорят о том, является ли вес ребенка при рождении «здоровым» или «нездоровым», а только о том, как он соотносится с группой нормы.
Например, ребенок, весивший при рождении 2600 граммов, относится к 7-му процентилю, то есть весит столько же или меньше, чем 93% детей в группе нормы. Однако, несмотря на очень низкий процентиль, 2600 грамм классифицируется как нормальный или здоровый вес для детей, рожденных в Соединенных Штатах. рискованно. (Для любопытных: 2600 граммов — это примерно 5 фунтов и 12 унций.) Таким образом, знание процентиля веса ребенка может сказать вам, как он сравнивается со своими сверстниками, но не является ли вес ребенка «здоровым» или «нездоровым».
Оценки, основанные на нормах, работают аналогичным образом: процентильный ранг отдельного учащегося описывает его успеваемость по сравнению с успеваемостью учащихся в группе нормы, но не указывает, соответствуют ли они определенному стандарту или критерию или нет.
В приведенных ниже диаграммах видно, что хотя баллы учащегося не меняются, их процентиль меняется на в зависимости от того, насколько хорошо учащиеся в стандартной группе выступили. Когда человек является лучшим учеником, он имеет высокий процентильный ранг; когда они плохо успевают, у них низкий процентильный ранг. Чего мы не можем сказать по этим диаграммам, так это того, следует ли учащегося классифицировать как владеющего или ниже владеющего.
Это означает, что знание процентного ранга учащегося в стандартном тесте скажет вам, насколько хорошо этот конкретный учащийся выполнил задание по сравнению с показателями стандартной группы, но не скажет вам, достиг ли учащийся уровня владения языком, превысил его или не достиг или любой другой критерий.
Сравнение оценок, основанных на критериях и нормах
Некоторые оценки дают результаты, основанные как на критериях, так и на нормах, что часто может быть источником путаницы. Например, у вас может быть учащийся с высоким процентильным рейтингом, но не отвечающий критерию владения языком. Хорошо ли учится этот ученик, потому что он превосходит своих сверстников, или плохо, потому что он не достиг мастерства?
Возможно и обратное. Учащийся может иметь очень низкий процентильный ранг, но все же соответствовать критерию владения языком. Этот ученик учится плохо, потому что он не так хорош, как его сверстники, или у него все хорошо, потому что он достиг мастерства?
Однако это довольно крайние и маловероятные случаи. Возможно, более распространенным является «типичный» или «средний» учащийся, который не достигает мастерства, потому что большинство студентов не достигают мастерства. На самом деле, это модель, которую мы наблюдаем в результатах Национальной оценки успеваемости (NAEP), где «типичный» учащийся четвертого класса (50-й процентиль) имеет 226 баллов, а «средний» учащийся четвертого класса (средний все баллы учащихся) имеет 222 балла, но для владения языком требуется балл 238 или выше.
Во всех этих случаях преподаватели должны использовать свое профессиональное суждение, знание учащегося, знакомство со стандартами и ожиданиями, понимание доступных ресурсов и опыт в предметной области, чтобы определить наилучший план действий для каждого отдельного учащегося. Оценки и данные, которые они производят, просто предоставляют информацию, которую педагог может использовать для принятия обоснованных решений.
Что случилось с Бруно?
Так что же случилось с Бруно в сценарии, описанном в начале этого поста?
Осенью Бруно набрал 55 баллов из 100 по оценке своего округа. Округ установил 50 баллов за мастерство, что означает, что Бруно считается «опытным». Окружной оценщик сравнил 55 баллов Бруно с баллами падения их нормальной группы и обнаружил, что Бруно набрал более 88% процентов своих сверстников в нормальной группе. Это дает ему процентильный ранг 88.
Весной Бруно снова проходит тот же тест. На этот раз он набирает 60 баллов, что выше, чем этот осенний балл. Поскольку критерий округа для владения языком не изменился, он по-прежнему относится к категории опытных.
Как и Бруно, учащиеся нормальной группы сдавали экзамен дважды — один раз осенью и один раз весной. На этот раз окружной оценщик сравнивает весенний балл Бруно с весенними баллами нормальной группы. В этом случае учащиеся в группе нормы добились заметных успехов и набрали гораздо больше баллов весной, чем осенью. Поскольку учащиеся из нормальной группы, как правило, имели гораздо больший прирост с осени к весне, чем Бруно, весенний балл Бруно теперь ставит его на 38-й процентиль.
Для учителя Бруно это признак беспокойства. Хотя Бруно по-прежнему считается опытным, он не отстает от своих сверстников и рискует отстать в будущем. Кроме того, если округ или штат повысят критерий профессионального уровня — что может произойти при изменении стандартов или оценок — он может не соответствовать этому новому критерию и будет бороться за то, чтобы за год добиться достаточного прогресса, чтобы соответствовать более строгим ожиданиям.
Это одна из причин, по которой преподавателям важно контролировать рост плюс рост .
Важность процентилей роста учащихся (SGP)
Успеваемость рассчитывается путем взятия текущего балла учащегося и простого вычитания его предыдущего балла. Успехи показывают, повысил ли учащийся уровень своих знаний или навыков, но не указывают, идет ли учащийся в ногу со своими сверстниками, опережает или отстает. Для этого нужна мера роста.
Рост — в частности, Процентиль роста учащегося или SGP — это нормативная мера, которая сравнивает успехи учащегося за один период за другим с успехами их академических сверстников по всей стране за аналогичный период времени. Сверстники в учебе определяются как учащиеся одного класса с похожей историей оценок, что означает, что учащиеся с низкой успеваемостью сравниваются с другими учащимися с низкой успеваемостью, а учащиеся с высокой успеваемостью сравниваются с другими учащимися с высокой успеваемостью.
В результате SGP помогает преподавателям быстро увидеть, показывает ли учащийся типичный рост, или он растет намного быстрее или намного медленнее, чем его сверстники. SGP также позволяет учителям увидеть, действительно ли два ученика с одинаковым баллом академически схожи или у них действительно очень разные потребности в обучении.
В случае Бруно знание его SGP осенью* позволило бы его учителю увидеть, что его рост медленнее, чем ожидалось. В этот момент она могла бы активно работать, чтобы ускорить его рост, возможно, предоставив ему дополнительные возможности для практики, назначив его в другую учебную группу, предоставив более целенаправленную поддержку или помощь во время уроков, или объединив его с более успевающим учеником для сверстников. репетиторство. Она могла бы также решить оценивать его чаще, возможно, каждые два или три месяца в течение учебного года, чтобы более внимательно следить за его успехами и ростом.
Возможно, эти усилия помогли Бруно закончить учебный год так же, как он его начал, — отличником — и лучше подготовиться к испытаниям в следующем классе.
*SGP доступен только после того, как учащийся сдал экзамен как минимум в двух разных окнах тестирования. Чтобы получить SGP осенью, учащийся должен пройти оценку в предыдущем учебном году. Кроме того, SGP, сообщаемый с оценкой учащегося при осенней оценке, будет показывать рост с весны на осень, с зимы на осень или с осени на осень с прошлого учебного года до текущего учебного года, в зависимости от того, когда учащийся был последняя оценка.