
Число миллера: ЧИСЛО МИЛЛЕРА — это… Что такое ЧИСЛО МИЛЛЕРА?
ЧИСЛО МИЛЛЕРА — это… Что такое ЧИСЛО МИЛЛЕРА?
- ЧИСЛО МИЛЛЕРА
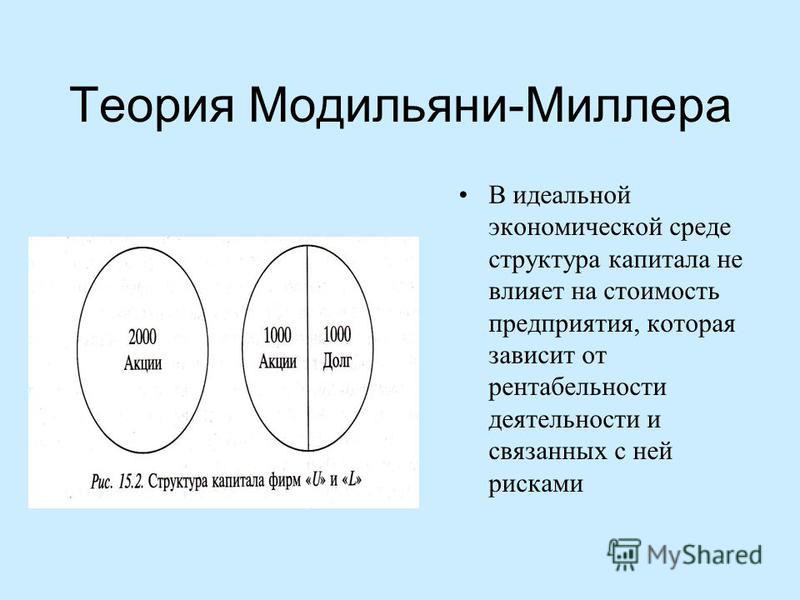
ЧИСЛО МИЛЛЕРА.
Понятие и термин психолингвистики. Дж. Миллер (США) в 1956 г. обобщил имевшиеся данные об объеме внимания и, связав их со сведениями об объеме кратковременной памяти, показал, что максимальный объем удерживаемого в памяти нового сообщения определяется не числом слов в предложении, а числом единиц информации и даже сем (единиц смысла), равным 7 ± 2. Используется в методике при определении объема информации, вводимой на занятиях по языку.
Новый словарь методических терминов и понятий (теория и практика обучения языкам). — М.: Издательство ИКАР. Э. Г. Азимов, А. Н. Щукин. 2009.
- ЧАТ
- ЧИСТОТА РЕЧИ
Смотреть что такое «ЧИСЛО МИЛЛЕРА» в других словарях:
МИЛЛЕРА ЧИСЛО
 См. число Миллера … Новый словарь методических терминов и понятий (теория и практика обучения языкам)
См. число Миллера … Новый словарь методических терминов и понятий (теория и практика обучения языкам)Тест Миллера — Рабина вероятностный полиномиальный тест простоты. Тест Миллера Рабина позволяет эффективно определять, является ли данное число составным. Однако, с его помощью нельзя строго доказать простоту числа. Тем не менее тест Миллера Рабина часто… … Википедия
Тест Миллера — Рабина — вероятностный полиномиальный тест простоты. Тест Миллера Рабина позволяет эффективно определять, является ли данное число составным. Однако, с его помощью нельзя строго доказать простоту числа. Тем не менее тест Миллера Рабина часто… … Википедия
Тест Миллера (право) — У этого термина существуют и другие значения, см. Тест Миллера. Тест Миллера (англ. Miller test; также называется Трёхсторонний тест, англ. Three Prong Obscenity Test[1]) тест, применяемый в Верховном суде Соединённых Штатов… … Википедия
Магическое число семь (magical number seven) — Словосочетание М.
 ч.с. стало частью языка психологии благодаря важной статье под названием «Магическое число семь, плюс минус два: некоторые пределы нашей способности обрабатывать информацию» (The magical number seven, plus or minus two: Some… … Психологическая энциклопедия
ч.с. стало частью языка психологии благодаря важной статье под названием «Магическое число семь, плюс минус два: некоторые пределы нашей способности обрабатывать информацию» (The magical number seven, plus or minus two: Some… … Психологическая энциклопедияТест Миллера (теория чисел) — У этого термина существуют и другие значения, см. Тест Миллера. Не следует путать с «Тестом Миллера Рабина» вероятностным полиномиальным тестом простоты. Тест Миллера детерминированный полиномиальный тест простоты. В 1976 году Миллер… … Википедия
Простое число — Простое число это натуральное число, имеющее ровно два различных натуральных делителя: единицу и само себя. Все остальные натуральные числа, кроме единицы, называются составными. Таким образом, все натуральные числа больше единицы… … Википедия
Псевдопростое число — Натуральное число называется псевдопростым, если оно обладает некоторыми свойствами простых чисел, являясь тем не менее составным числом.
 В зависимости от рассматриваемых свойств существует несколько различных типов псевдопростых чисел.… … Википедия
В зависимости от рассматриваемых свойств существует несколько различных типов псевдопростых чисел.… … ВикипедияСлучайное простое число — В криптографии под случайным простым числом понимается простое число, содержащее в двоичной записи заданное количество битов , на алгоритм генерации которого накладываются определенные ограничения. Получение случайных простых чисел является… … Википедия
Кошелек Миллера — «Магическое число семь плюс минус два» закономерность (также известная как «кошелёк Миллера»), обнаруженная американским учёным психологом Джорджем Миллером, суть которой состоит в том, что кратковременная человеческая память может запомнить и… … Википедия
Важнейшее правило UX дизайна, которое все нарушают | by Nancy Pong | Начинающему UX-дизайнеру
Закон Миллера можно применить в любой ситуации, когда требуется выполнить задачу средней сложности. Достаточно просто уменьшить количество элементов, которые попадают в рабочую память — и собрать их в порции по 5–9 элементов. Так мозгу будет проще запомнить, что и где находится, чтобы при случае быстро найти нужные элементы. Когда список слишком большой, нам сложнее визуализировать его в своей голове — на это уходит дополнительный ресурс мозга.
Так мозгу будет проще запомнить, что и где находится, чтобы при случае быстро найти нужные элементы. Когда список слишком большой, нам сложнее визуализировать его в своей голове — на это уходит дополнительный ресурс мозга.
Особенно важно соблюдать закон Миллера в контексте применения lean-методологии и других современных трендов в области технологий и UX. Прежде чем купить продукт, пользователи скачивают пробную версию. Если они не почувствуют ценности решения с первого же дня — они не купят ваш продукт. У пользователей нет времени изучать, где у вас что находится — информационный дизайн должен быть четко спланирован и продуман еще на этапе проектирования.
В наше время объемы информации растут в геометрической прогрессии. Мы должны серьезно относиться к организации информации — или хотя бы безжалостно уничтожать лишнее — иначе мы потеряем способность принимать важные решения, которые напрямую связаны с вопросом выживания (я говорю, к примеру, о навигации и зарабатывании средств к существованию).
Именно поэтому сейчас особенно актуален вопрос отказа от всего лишнего: вещей, продуктов, услуг, которые не дают качественной отдачи. Тут вступает в игру принцип Парето — что 20% вложений обеспечивают 80% результата. Вы пытаетесь быть эффективным, прыгая между кучей разных задач? У вашей команды слишком много инструментов для совместной работы? В команде слишком много человек? Возможно, вы перегружаете новичков информацией?
Закон Миллера учит нас, что человек может воспринять ограниченный объем информации за раз, а информационная перегрузка снижает эффективность работы. Важная задача компаний состоит в том, чтобы правильно организовать информацию и дозированно выдавать ее клиентам и работникам.
Для этого нужно избавиться от инструментов и приложений, которые создают когнитивную перегрузку, сократить количество человек в команде, возможно даже реорганизовать отделы и команды с учетом наших знаний о рабочей памяти человека.
Закон Миллера также можно упомянуть в контексте концепции “потока”, которую сформулировал известный психолог Михай Чиксентмихайи. Поток — это состояние концентрации и вовлеченности в решение задачи, которое доставляет человеку чувство удовольствия и уверенности в себе. Ученый называет потокоптимальным состоянием, в котором мы работаем на максимальной мощности и действительно “живем в моменте”.
Поток — это состояние концентрации и вовлеченности в решение задачи, которое доставляет человеку чувство удовольствия и уверенности в себе. Ученый называет потокоптимальным состоянием, в котором мы работаем на максимальной мощности и действительно “живем в моменте”.
А вот различные отвлекающие факторы нарушают состояние потока. Поэтому, прежде чем предлагать своим сотрудникам очередной инструмент, трижды подумайте: а как он повлияет на эффективность их работы? Если верить закону Миллера, все лишнее нам мешает. Когда дело касается решения задач, чем меньше — тем лучше.
Практические советы
Выключите уведомления в slack. Выкиньте все, чем давно не пользуетесь. Хватит проверять свои многочисленные почтовые ящики. Освойте в совершенстве один инструмент — не нужно распыляться на много разных. А теперь сконцентрируйтесь.
Восемь именных законов в UX дизайне (часть 2) / Хабр
Эта статья является продолжением опубликованной ранее первой части. Если вы еще не успели ознакомиться с ней, рекомендую начать именно с нее.
Закон Миллера
«Магическое число семь плюс-минус два» («кошелёк Миллера», «закон Миллера») — закономерность, обнаруженная американским учёным-психологом Джорджем Миллером, согласно которой кратковременная человеческая память, как правило, не может запомнить и повторить более 7 ± 2 элементов.
В 1956 году Джордж Миллер, американский психолог, опубликовал статью под названием «Магическое число семь плюс-минус два: некоторые ограничения в нашей возможности обработки информации».
Проведя серию экспериментов, в ходе которых людям необходимо было различать звуковые сигналы с разной частотой, психолог выявил, что если количество сигналов 2 или 3, то у испытуемых не возникает сложностей в их определении. Начиная с 4-го сигнала появляются незначительные проблемы. А на 5-м и более звуках испытуемые ошибаются все чаще. Помимо экспериментов со звуком также проводились эксперименты со вкусом, с визуальным восприятием и другие.
Миллер обобщил показатели всех экспериментов и получил то самое число 7±2. Именно такое количество элементов способна хранить кратковременная память среднестатистического человека.
Именно такое количество элементов способна хранить кратковременная память среднестатистического человека.
Несмотря на то, что закон Миллера является одним из наиболее популярных и цитируемых в среде UX дизайна, он не имеет почти никакого отношения к пользовательскому опыту и интерфейсам.
Этот закон – миф, как и многие вытекающие из него убеждения о том, что количество элементов меню или количество элементов списка не должно превышать отметку в
семьединиц.
Начнем с того, что пользователю просто незачем запоминать информацию, она и так представлена в полном объеме у него на экране, поэтому он легко может оперировать большим количеством элементов. И незачем искусственно ограничивать это количество семью.
Human Factors International (HFI), одна из крупнейших компаний, специализирующихся на проектировании пользовательского опыта провела исследования, в результате которого выяснилось, что объемные, но неглубокие меню могут работать лучше, чем те, которые имеют большое количество вложенностей.
Разделы на сайте Amazon
Даже сам Джордж Миллер был потрясен тем, насколько его статья была неверно истолкована, заявив, что исследования проводились для одномерных стимулов (звук, яркость и т. д.), и не имеет никакого отношения к способностям человека понимать печатный текст.
Тем не менее, основной вывод исследований Миллера для UX специалистов должен заключаться в следующем: кратковременная память человека ограничена, поэтому, если вы хотите, чтобы ваши пользователи работали с бОльшим объемом информации и запоминали ее, разделяйте информацию на порции. Не просите пользователей одновременно хранить в своей краткосрочной памяти сразу много фрагментов информации. И не зацикливайтесь на цифре семь.
Закон Теслера
Закон Теслера, или закон сохранения сложности, утверждает, что для любой системы существует определенный уровень сложности, который нельзя сократить.
Ларри Теслер — информатик, специалист в области взаимодействия человека и компьютера. Он работал в таких компаниях как Xerox PARC, Apple, Amazon и Yahoo. Фактически именно он ввел в оборот комбинацию клавиш Ctrl+C, Ctrl+V.
Он работал в таких компаниях как Xerox PARC, Apple, Amazon и Yahoo. Фактически именно он ввел в оборот комбинацию клавиш Ctrl+C, Ctrl+V.
Он утверждал, что каждое приложение имеет определенную степень сложности. Единственный вопрос: кто будет иметь с этим дело? Пользователь, разработчик приложения или разработчик платформы?
Требуется довольно много работы, чтобы сделать что-то «простое». Уменьшая сложность для пользователя, мы переносим сложность на дизайнеров, разработчиков.
Давайте разберем простой пример — выбор типа платежной системы.
Тип платежной системы выбирает пользователь
Тип платежной системы подставляется автоматически
В первом случае выбор ложится на плечи пользователя, тем самым усложняя для него систему, но упрощая разработку. Во втором — тип платежной системы подставляется автоматически, когда пользователь начинает вводить номер карты. Это упрощает работу для пользователя, так как сложность задачи уменьшается на один шаг. Но разработка при этом становится сложнее.
Но разработка при этом становится сложнее.
Распространенная ошибка многих продуктовых команд — отдать как можно больше контролов для выбора пользователю, как будто он лучше знает, что с этим делать. Дизайнер рисует очередную пачку чекбоксов, говоря прямым текстом пользователю: «Парень, теперь это твоя проблема».
Вместо этого, команде следует собрать больше информации о пользователях, проанализировать ее и сделать этот выбор за пользователя.
Модель Кано
«Модель Кано» — методика, которая используется для оценки эмоциональной реакции потребителя на отдельные характеристики продукта. Она позволяет управлять удовлетворенностью и лояльностью потребителей, упрощает и оптимизирует процесс потребления.
Модель Кано разработана в 1984 году доктором Нориаки Кано.
Модель Кано позволяет проектировщикам гораздо лучше понять желания потребителей и избавиться от ненужных фич в продукте. С его помощью компании вырабатывают стратегии и решают задачи по обеспечению удовлетворенности и лояльности пользователей.
Модель Кано
Кано разделяет все свойства продуктов на 5 категорий:
- Обязательные характеристики
- Линейные характеристики
- Привлекательные характеристики
- Безразличные характеристики
- Обратные характеристики
Давайте разберем каждую из них более подробно:
Обязательные характеристики
Как и следует из названия, к обязательным характеристикам продукта относятся те, без которых продукт не будет работать надлежащим образом. Например, автомобиль без руля, смартфон без возможности совершать звонки и так далее.
Обязательные атрибуты должны присутствовать, ведь без них продукт не будет иметь ценность для потребителя.
Однако, как следует из графика ниже, уровень выполнения обязательных характеристики продукта не влияет на удовлетворенность потребителей напрямую.
Обязательные характеристики
Само наличие таких атрибутов в продукте не вызывает у них больших эмоций, поскольку они считают, что эти атрибуты должны присутствовать в продукте по умолчанию.
Линейные Характеристики
К линейным или одномерным характеристикам относят характеристики из разряда «чем больше, тем лучше». Например, объем памяти, расход топлива, емкость аккумулятора и прочие. Чем лучше значения этих показателей, тем выше удовлетворенность клиента.
Линейные характеристики
Как показывает график, уровень удовлетворенности линейными характеристиками находится в прямой зависимости с уровнем функциональности указанного атрибута.
Привлекательные характеристики
Привлекательные или восхищающие характеристики продукта — это киллер фичи вашего продукта. К таким характеристикам в свое время относилась функция iPhone Touch ID, а теперь и Face ID. Автоматическая разблокировка MacBook часами Apple Watch, беспроводная зарядка смартфонов и многие другие.
Привлекательные характеристики
Уровень выполнения привлекательных свойств не влияет на удовлетворенность потребителей напрямую. Если восхищающее свойство отсутствует, потребители не будут разочарованы, так как у них не было никаких ожиданий относительно такого свойства. Но зато если восхищающее свойство обнаружено потребителями, то благодаря эффекту неожиданности они будут настолько впечатлены, что просто не смогут удержаться и не поделиться своим открытием с другими.
Если восхищающее свойство отсутствует, потребители не будут разочарованы, так как у них не было никаких ожиданий относительно такого свойства. Но зато если восхищающее свойство обнаружено потребителями, то благодаря эффекту неожиданности они будут настолько впечатлены, что просто не смогут удержаться и не поделиться своим открытием с другими.
Со временем многие привлекательные характеристики переходят в разряд обязательных.
Безразличные характеристики
Это те функции и атрибуты продукта, которые потребителя мало интересуют или не интересуют вовсе; функционал, который никак не влияет на уровень удовлетворенности клиента продуктом.
Безразличные характеристики
В качестве примера таких свойств можно привести шифрование фотографий в Google Photos, сторона расположения бензобака на автомобиле и другие.
Обратные характеристики
Обратные или нежелательные характеристики — это те свойства продукта, которые по мере роста своего количества уменьшают удовлетворенность пользователя продуктом.
Обратные характеристики
В качестве примера таких характеристик можно привести огромное количество кнопок на руле автомобиля, которые отвлекают водителя, или автомобильная парковка с большим количеством мест, но места в которой настолько узкие, что трудно открыть дверь автомобиля.
Как использовать Модель Кано?
Для того, чтобы использовать Модель Кано, вам потребуется провести исследование целевой аудитории, выявить их видение характеристик вашего продукта.
Составьте список фич вашего продукта для каждого типа персон. Ведь один сегмент ваших потребителей будет видеть доминирующую ценность продукта в одних характеристиках, а другие – в других. Учитывайте этот факт при опросе.
Далее перейдем к самому опросу. Он состоит всего из двух вопросов, каждый из которых задается один раз для каждого атрибута:
- как бы вы себя чувствовали, если бы продукт имел следующую характеристику?
- как бы вы себя чувствовали, если бы продукт не имел следующей характеристики?
В качестве ответа опрашиваемым необходимо выбрать один из нескольких вариантов ответа:
- Мне бы понравилось
- Я ожидаю это
- Мне все равно
- Я могу с этим жить
- Я бы не использовал продукт из-за этого
Обратите внимание на таблицу ниже:
Источник: https://uxdesign. cc
cc
Она состоит из нескольких категорий, отмеченных буквами:
A — Attractive — Привлекательные
O — One dimensional — Линейные
M — Must-be — Обязательные
I — Indifferent — Безразличные
R — Reverse — Обратные
Q — Questionable — Под вопросом (Отражает неясные результаты, которые не могут быть оценены)
Таким образом, каждая пара ответов на пересечении строк и столбцов показывает тип категории для данной функции.
К примеру, если пользователь отвечает «1. Мне бы понравилось» на функциональный (положительный) вопрос и «2. Я ожидаю это» на нефункциональный (отрицательный) вопрос, то тестируемая функция попадает в категорию «А», т.е. привлекательная.
Обратите внимание также, что там, где вы получили R — людям не интересен ваш продукт, это не ваша целевая аудитория, а там, где вы получили Q, люди скорее всего не поняли вопрос.
Таким образом, Модель Кано может помочь выяснить требования клиентов к данному продукту и помогает в создании продуктов, которые приводят к высокой удовлетворенности клиентов.
Закон Парето
Закон Парето (принцип Парето, принцип 80/20) — эмпирическое правило в наиболее общем виде формулируется как «20 % усилий дают 80 % результата, а остальные 80 % усилий — лишь 20 % результата».
Принцип Парето
Этот принцип был предложен консультантом по управлению Джозефом Джураном в 1951 году, который сослался на частную закономерность, выявленную итальянским экономистом и социологом Вильфредо Парето в 1897 году.
Закон Парето полезен, потому что он позволяет нам сосредоточить наши усилия на областях, которые приносят наибольшую пользу. Он используется практически в каждой бизнес-дисциплине.
Неважно, разрабатываете ли вы небольшой веб-сайт или большое и сложное приложение, как только вы углубитесь в пользовательскую аналитику, вы увидите, что бОльшую часть времени пользователи работают лишь с ограниченной частью функционала. Конечно это не означает, что остальные функциональные возможности или контент не имеют никакой ценности, но это говорит о том, что некоторые функциональные возможности и контент более важны для ваших пользователей, чем для остальных.
Это важно, потому что это позволяет вам сосредоточить свои исследования на наиболее важных вещах и обеспечить сохранность этих вещей, когда вы приступаете к пересмотру пользовательского опыта. Если вы не будете учитывать это, то вы потеряете пользователей. И наоборот, если вы сможете улучшить взаимодействие с пользователем этих ключевых атрибутов вашего продукта, вы с большей вероятностью сможете завоевать новых пользователей и поощрить лояльность текущих.
Но не все так просто, предположим, что вы получили в службу поддержки 300 обращений, 200 из которых относятся к проблеме A, 80 относятся к проблеме B, и только 20 относятся к C. На этом этапе нетрудно сосредоточиться на решении проблемы A. Но если все запросы, относящиеся к B или C, поступают от пользователей с платной или премиальной подпиской, а вызовы, относящиеся к функции A — нет, то вы все же можете сначала сосредоточить свои усилия на исправлении B или C.
Закон Парето предлагает способ сосредоточить свою энергию и усилия на создании пользовательского опыта. Он поможет вам получить четкое представление о том, что имеет отношение к вашим пользователям и бизнесу, чтобы вы могли устанавливать приоритеты и решать правильные дизайн задачи.
Все написанное выше не является аксиомой, скорее это набор несложных принципов и рекомендаций, пользуясь которыми, можно ощутимо улучшить пользовательский опыт и избежать типичных проблем юзабилити продукта.
Спасибо, что потратили время на чтение этой статьи, надеюсь, она была для вас полезной.
Число выявленных заражений COVID-19 в мире превысило 244,9 млн От IFX
© Reuters Число выявленных заражений COVID-19 в мире превысило 244,9 млнЧисло зарегистрированных случаев заражения коронавирусом COVID-19 в мире на утро четверга возросло до 244 млн 996 тыс. 373, свидетельствуют данные американского университета Джонса Хопкинса. С начала распространения вируса в мире после заражения COVID-19 скончались 4 млн 971 тыс. 538 человек.
538 человек.
В число стран с более чем 20 млн случаев заражения COVID-19 входят США, Индия и Бразилия.
Лидерство по числу заразившихся и скончавшихся сохраняют США, где выявлено 45 млн 703 тыс. 960 инфицированных COVID-19. Количество летальных исходов составило 741 тыс. 231.
Второе место по числу заразившихся занимает Индия, где количество подтвержденных случаев COVID-19 достигло 34 млн 215 тыс. 653. Число умерших от последствий заражения вирусом в стране выросло до 455 тыс. 653 человек.
На третьем месте в мире по распространению коронавируса находится Бразилия, где за время пандемии зарегистрировано 21 млн 766 тыс. 168 заболевших, из них умерли 606 тыс. 679 человек.
За время пандемии в мире было распределено 6 млрд 885 млн 663 тыс. 825 доз вакцины против коронавируса.
По данным портала Worldometers, который специализируется на статистике по важнейшим мировым событиям, коэффициент смертности на 1 млн населения планеты составил на утро четверга 639,9. В США на 1 млн жителей скончались 2 тыс. 284 человека, в Индии — 327, в Бразилии — 2 тыс. 828.
В США на 1 млн жителей скончались 2 тыс. 284 человека, в Индии — 327, в Бразилии — 2 тыс. 828.
Fusion Media or anyone involved with Fusion Media will not accept any liability for loss or damage as a result of reliance on the information including data, quotes, charts and buy/sell signals contained within this website. Please be fully informed regarding the risks and costs associated with trading the financial markets, it is one of the riskiest investment forms possible.
Коктейль Миллера – Газета Коммерсантъ № 1 (3332) от 10.01.2006
газовая война
Такого завершения газовой войны между Россией и Украиной не ожидал решительно никто. Вместо замерзающих украинских сел и остановившихся немецких заводов итогом самого острого экономического конфликта 2005 года станет выход на европейский газовый рынок газового трейдера RosUkrEnergo с оборотами в миллиарды долларов — с соответствующими прибылями его неизвестных совладельцев.
После переговоров министра энергетики Украины Ивана Плачкова с Владимиром Путиным 29 декабря, на которых президент России недвусмысленно поместил Украину в число стран, не входящих в число «ближайших друзей и соседей», предполагать, что уже 4 января собеседник господина Плачкова торжественно заявит на совещании в Ново-Огареве о «качественно новом уровне отношений» двух стран, было невозможно. На смену курса в отношении Украины от энергоблокады до тесного партнерства потребовалось пять дней.
Напомним, накануне нового года «Газпром» был твердо намерен продавать Украине газ по цене $230 за 1 тыс. куб. м, Украина — покупать газ не дороже $70-80. 1 января 2006 года в 10.00 «Газпром» прекратил поставки газа в адрес украинских потребителей, в том числе туркменского, снизив давление в системе трубопроводов «Союз» на украинскую квоту.
куб. м, Украина — покупать газ не дороже $70-80. 1 января 2006 года в 10.00 «Газпром» прекратил поставки газа в адрес украинских потребителей, в том числе туркменского, снизив давление в системе трубопроводов «Союз» на украинскую квоту.
А уже в 10.00 4 января было объявлено об урегулировании всех споров между «Газпромом» и «Нафтогазом Украины». Виктор Ющенко объявил о закупках газа Украиной на границе с Россией по цене $95 за 1 тыс. куб. м (в 2005 году цена составляла $50) и росте ставок транзита для «Газпрома» с $1,09 за 1 тыс. куб. м на 100 км до $1,6. Через час председатель правления «Газпрома» Алексей Миллер сообщил, что Россия будет поставлять собственный газ на Украину по цене $230 за 1 тыс. куб. м через швейцарскую компанию RosUkrEnergo (RUE), ранее поставлявшую туда туркменский газ по украинско-туркменскому соглашению. Никаких внятных объяснений о том, как RUE, в которой «Газпрому» через Газпромбанк принадлежит 50% акций, сможет закупать газ в России по $230, продавать на Украине по $95 и немедля не разориться, не последовало.
По данным Ъ, соглашение между НАК «Нафтогаз Украины», «Газпромом» и RUE было подписано в офисе «Газпрома» 3 января в 2.30, а окончательное решение было принято ближе к полуночи в гостинице «Украина» на переговорах, в которых принимало участие руководство всех заинтересованных сторон, по неофициальным сведениям, не исключая и бизнесмена Семена Могилевича, стоявшего у истоков создания RUE в 2004 году. Акционеры именно этой офшорной компании, зарегистрированной в швейцарском кантоне Цуг, и соберут в 2006 году первые трофеи.
Как следует из опубликованного главой избирательного блока БЮТ Юлией Тимошенко на пресс-конференции в Киеве договора (его подлинность не опровергают ни в «Газпроме», ни в «Нафтогазе Украины»), схема «газового компромисса» выглядит так. ООО «Газэкспорт», экспортирующая газ «дочка» «Газпрома», и «Нафтогаз Украины» продают RUE на границе Туркмении и Узбекистана весь газ, который Туркмения способна экспортировать в 2006 году,— 41 млрд куб. м. На границе Узбекистана и Казахстана RUE покупает у «Газэкспорта» еще до 8 млрд куб. м узбекского газа, а на границе Казахстана и России — еще до 7 млрд куб. м казахского. Точные объемы закупок зависят от пропускной способности газотранспортной системы Средняя Азия—Центр, цены закупок пока неизвестны.
м узбекского газа, а на границе Казахстана и России — еще до 7 млрд куб. м казахского. Точные объемы закупок зависят от пропускной способности газотранспортной системы Средняя Азия—Центр, цены закупок пока неизвестны.
Весь этот объем — 56 млрд куб. м — RUE по договору транзита с «Газпромом» поставляет на границу РФ и Украины — по данным Ъ, себестоимость среднеазиатской газовой смеси для RUE с учетом цены транзита составит порядка $85-90 за 1 тыс. куб. м. После чего RUE продает газ своей совместной компании с «Нафтогазом Украины», зарегистрированной на Украине (она по договору будет создана до 1 февраля и, по данным Ъ, будет называться «Росукрэнерго»). СП будет продавать газ на Украине без права реэкспорта.
В первом полугодии 2006 года RUE обязалась поставить своему СП 34 млрд куб. м газа. Кроме этого RUE обязалась закупить у «Газпрома» на границе РФ и Украины до 17 млрд куб. м. по цене $230 за тысячу кубометров — именно об этом, собственно, и говорил Алексей Миллер. Цены поставок 34 млрд куб. м газа RUE «Росукрэнерго» фиксированы на уровне $95 за тысячу кубометров — это, в свою очередь, и объявлял Виктор Ющенко. То, что не объявлялось и что следует из договора 4 января (все протоколы к нему, кстати, подписаны задним числом, поэтому все обвинения «Газпрома» в адрес Украины сняты),— оставшиеся после исполнения этих обязательств у RUE 39 млрд куб. м газа она вправе экспортировать куда угодно и по каким угодно ценам: на Украину, которой во второй половине 2006 года не будет хватать в газовом балансе около 22 млрд куб. м, или в СНГ и Европу, где этот газ будет стоить $180-270 за тысячу кубометров. При средней цене реализации газа $250 доходы RUE от экспорта этого газа могут составить порядка $2,7 млрд.
Цены поставок 34 млрд куб. м газа RUE «Росукрэнерго» фиксированы на уровне $95 за тысячу кубометров — это, в свою очередь, и объявлял Виктор Ющенко. То, что не объявлялось и что следует из договора 4 января (все протоколы к нему, кстати, подписаны задним числом, поэтому все обвинения «Газпрома» в адрес Украины сняты),— оставшиеся после исполнения этих обязательств у RUE 39 млрд куб. м газа она вправе экспортировать куда угодно и по каким угодно ценам: на Украину, которой во второй половине 2006 года не будет хватать в газовом балансе около 22 млрд куб. м, или в СНГ и Европу, где этот газ будет стоить $180-270 за тысячу кубометров. При средней цене реализации газа $250 доходы RUE от экспорта этого газа могут составить порядка $2,7 млрд.
С 2007 года RUE обязуется ежегодно поставлять на Украину по фиксированным ценам (которые пока не определены) до 58 млрд куб. м газа, при этом профицит только неукраинских операций компании составит не менее 15 млрд куб. м газа. Глава RUE Вольфганг Пучек в конце прошлой недели выразил удовлетворение договоренностью РФ и Украины по газовым вопросам, официально заявил о намерении компании увеличить оборот в 2006 году на 30-40%, войти в число ведущих торговцев газом в Евросоюзе и начать подготовку к IPO.
Формально проигравших в «газовой войне» России и Украины нет. С точки зрения Украины, ее правительство обеспечило себе поставки газа в самое тяжелое (к тому же — приходящееся на парламентские выборы) первое полугодие 2006 года по $95 за тысячу кубометров. Кроме того, вряд ли RUE откажется от поставок газа во втором полугодии 2006 года в адрес своей «дочки» «Росукрэнерго» по цене в диапазоне $95-160 за тысячу кубометров — относительное спокойствие на Украине является залогом того, что цены транзита в $1,6 не будут пересмотрены ни для нее, ни для «Газпрома». «Газпром», обеспечив сбыт 17 млрд куб. м по $230 за тысячу кубометров российского газа RUE вместо Украины, формально ничего не теряет. Не теряет на этой операции и RUE — среднеазиатского газа с лихвой хватает, чтобы обеспечить рентабельность поставок.
Проблема лишь в том, что «Газпром» был вынужден передать RUE абсолютно все, что он заработал с 2001 года, скупая среднеазиатский газ. По сути, 4 января Туркмения, Узбекистан и Казахстан решили задачу по независимому напрямую от «Газпрома» экспорту российского газа в страны ЕС. Если ранее «Газпром» мог претендовать на 100% прибылей от экспорта среднеазиатского газа в Европу, то теперь он получит от него не более 50% — вторая половина будет распределена среди других акционеров RUE (см. схему). RUE увеличивает свою долю на рынке стран СНГ и Европы с нынешних 3-4% до 11-12%.
Если ранее «Газпром» мог претендовать на 100% прибылей от экспорта среднеазиатского газа в Европу, то теперь он получит от него не более 50% — вторая половина будет распределена среди других акционеров RUE (см. схему). RUE увеличивает свою долю на рынке стран СНГ и Европы с нынешних 3-4% до 11-12%.
По какой же причине «Газпром» добровольно отдал свои позиции офшорной компании, существующей два года? По заявлению Вольфганга Пучека агентству Reuters, за компанией Raiffeisen Invest AG (RAIG) стоит «группа международных инвесторов, пока не предполагающих раскрывать свои имена». Все это крайне напоминает заявление Владимира Путина годичной давности о группе «опытных энергетиков», стоящих за компанией «Байкал Финанс Групп», купившей на аукционе РФФИ «Юганскнефтегаз».
ДМИТРИЙ Ъ-БУТРИН
Число миллера в психологии. Отрывок, характеризующий Магическое число семь плюс-минус два
Число зверя – 666
Чтобы пояснить это число, приведу главу из моей книги «Дорога Домой». Сначала я, как все люди, не мог понять, что означает число зверя, а слепо верить религиозным мифам не позволяло образование. Потом, когда открыл, какие циклы правят умом, а следовательно
Сначала я, как все люди, не мог понять, что означает число зверя, а слепо верить религиозным мифам не позволяло образование. Потом, когда открыл, какие циклы правят умом, а следовательно
Идеальное число членов мозгового центра В идеале их должно быть 5–6 человек. Если меньше – коллектив утрачивает движущую силу, если больше – становится «неповоротливым»: встречи затягиваются, потребности некоторых участников остаются без внимания, а межличностное
Как всегда угадывать загаданное число Дайте выбранной зрительнице большой лист бумаги формата А4 и фломастер. Попросите ее написать любое число между 100 и 999. Скажите, что ей придется еще писать числа выше или ниже первого и для них надо будет оставить место. Затем
автора Минделл АрнольдМагическое число семь плюс-минус два Объем памяти В 1956 году когнитивный психолог Джордж Миллер опубликовал ставшую сегодня знаменитой работу под названием «Магическое число семь плюс-минус два: границы способности к обработке информации», в которой ученый высказал
Из книги Руководство по выращиванию капитала от Джозефа Мэрфи, Дейла Карнеги, Экхарта Толле, Дипака Чопры, Барбары Шер, Нила Уолша автора Штерн Валентин1. Тяга к учению слишком часто ослабевает по мере того, как растет число побед
Несколько лет назад за обедом в Одессе (штат Техас) я разговорился с Джимом Коллинзом, автором книги «Способность к величию» («Good to Great»). Джим – здравомыслящий человек, и мне доставляет
Тяга к учению слишком часто ослабевает по мере того, как растет число побед
Несколько лет назад за обедом в Одессе (штат Техас) я разговорился с Джимом Коллинзом, автором книги «Способность к величию» («Good to Great»). Джим – здравомыслящий человек, и мне доставляет
Включите себя в число тех, кого вы любите Если вам кажется, что стать достойным счастья и благополучия очень трудно – то вы ошибаетесь. Дело в том, что вы уже достойны счастья и благополучия. Как и все люди. Но, может быть, вы не знаете об этом, забыли об этом и не чувствуете
Описание принципа
Применение
Данный принцип используется, например, в построении интерфейсов программ. Если количество элементов (пунктов меню, кнопок, закладок) меню больше семи, или в крайнем случае девяти, то эти элементы стараются сгруппировать.
Ссылки
- George A. Miller. The Magical Number Seven, Plus or Minus Two . // The Psychological Review, 1956, vol.
 63, pp. 81-97.
63, pp. 81-97. - DDR для головы, или как работает наша память — Статья на Хабрахабре
Примечания
Wikimedia Foundation . 2010 .
Смотреть что такое «Семь плюс минус два» в других словарях:
Семь плюс/минус два (7 +/_2) — – «магическое число» Д.А. Миллера (на самом деле эта характеристика объёма кратковременной памяти впервые и ранее установлена Д. Якобсом в опытах по запоминанию цифр). Имеется в виду, что объём или вместимость кратковременной памяти касается не… … Энциклопедический словарь по психологии и педагогике
СЕМЬ ПЛЮС»МИНУС СЕМЬ ПЛЮС»МИНУС ДВА (7±2) — Магическое число Джорджа А. Миллера. Этот термин означает приблизительное число дискретных фрагментов информации, которое может одновременно сохраняться в кратковременной памяти. Обратите внимание, что это ограничение основывается на понимании… … Толковый словарь по психологии
— «Магическое число семь плюс минус два» («кошелёк Миллера») закономерность, обнаруженная американским учёным психологом Джорджем Миллером, согласно которой кратковременная человеческая память, как правило, не может запомнить и повторить более 7 ±… … Википедия
— () знак вычитания в арифметике. Словарь иностранных слов, вошедших в состав русского языка. Павленков Ф., 1907. МИНУС (лат. minus меньший). 1) в арифметике знак вычитания. 2) обозначение, когда чего либо недостает. 3) Знак отрицательной величины … Словарь иностранных слов русского языка
— «Магическое число семь плюс минус два» закономерность (также известная как «кошелёк Миллера»), обнаруженная американским учёным психологом Джорджем Миллером, суть которой состоит в том, что кратковременная человеческая память может запомнить и… … Википедия
Словарь иностранных слов, вошедших в состав русского языка. Павленков Ф., 1907. МИНУС (лат. minus меньший). 1) в арифметике знак вычитания. 2) обозначение, когда чего либо недостает. 3) Знак отрицательной величины … Словарь иностранных слов русского языка
— «Магическое число семь плюс минус два» закономерность (также известная как «кошелёк Миллера»), обнаруженная американским учёным психологом Джорджем Миллером, суть которой состоит в том, что кратковременная человеческая память может запомнить и… … Википедия
— «Магическое число семь плюс минус два» закономерность (также известная как «кошелёк Миллера»), обнаруженная американским учёным психологом Джорджем Миллером, суть которой состоит в том, что кратковременная человеческая память может запомнить и… … Википедия
О некоторых пределах нашей способности перерабатывать информацию
Повсюду меня преследует один знак. В течение семи лет это число буквально следует за мною по пятам, я непрерывно сталкиваюсь с ним в своих частных делах, оно встает передо мной со страниц са-мых распространенных наших журналов. Это число принимает множество обличий, иногда оно не-сколько больше, а иногда – несколько меньше, чем бывает обычно, но никогда не изменяется настолько, чтобы его нельзя было узнать. Та настойчивость, с которой это число преследует меня, объясняется чем-то большим, нежели простым совпадением. Здесь чувствуется какая-то преднамеренность, все это подчинено какой-то определенной закономерности. Или в этом числе действительно есть что-то не-обычное, или я страдаю манией преследования.
Это число принимает множество обличий, иногда оно не-сколько больше, а иногда – несколько меньше, чем бывает обычно, но никогда не изменяется настолько, чтобы его нельзя было узнать. Та настойчивость, с которой это число преследует меня, объясняется чем-то большим, нежели простым совпадением. Здесь чувствуется какая-то преднамеренность, все это подчинено какой-то определенной закономерности. Или в этом числе действительно есть что-то не-обычное, или я страдаю манией преследования.
Я начну свой рассказ с того, что опишу вам некоторые эксперименты, в которых проверялось, с какой точностью люди могут обозначать числами величины различных параметров стимулов. Выража-ясь традиционным языком психологии, эти эксперименты следовало бы назвать экспериментами по абсолютной оценке. Однако в силу исторической случайности им присвоили другое название, и теперь мы называем их экспериментами по определению способности людей передавать информацию. Поскольку эти эксперименты никогда не были бы поставлены, не появись на психологической арене теория информации, и поскольку для анализа результатов экспериментов привлекают понятия теории информации, мне придется, прежде чем я приступлю к обсуждению темы, сделать несколько замечаний, касающихся этой теории.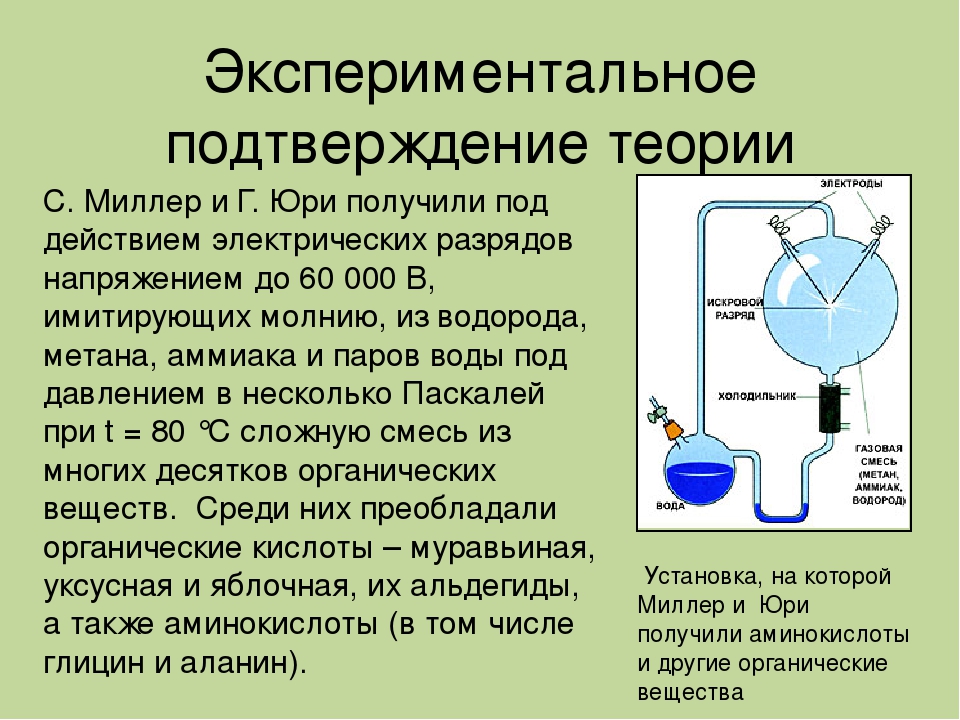
Измерение информации
Термин «количество информации» обозначает то же самое понятие, которое мы имели в виду, употребляя в течение многих лет термин «изменение» (variance). Эти выражения неодинаковы, но если твердо придерживаться той идеи, что всякое увеличение изменений влечет за собой увеличение количества информации, то мы не сильно погрешим против истины.
Преимущества этого нового подхода к трактовке изменений вполне очевидны. Изменения всегда выражаются различными единицами измерений – метрами, килограммами, вольтами и т. д., – в то время как количество информации есть безразмерная величина. Поскольку информация в дискретном стати-стическом распределении не зависит от единицы измерения, мы можем распространить эту концепцию на те ситуации, где мы можем установить метрики и где мы обычно и не подумали бы об использова-нии понятия изменения. Кроме того, такой подход дает нам возможность сравнивать результаты, полу-чаемые в совершенно различных экспериментальных условиях, когда было бы трудно сравнивать изме-нения, выраженные в различных единицах измерения. Таким образом, весьма убедительные причины заставляют нас принять эту более новую концепцию.
Таким образом, весьма убедительные причины заставляют нас принять эту более новую концепцию.
Сходство между изменением и количеством информации можно объяснить следующим образом: когда мы сталкиваемся со значительным изменением, мы почти ничего не знаем о том, что должно про-изойти в дальнейшем; если мы в таком случае (когда нам мало что известно) проводим наблюдение, то оно дает нам огромное количество информации. С другой стороны, если изменение очень невелико, то мы заранее знаем, что мам даст наше наблюдение, поэтому мы получим в результате нашего наблюде-ния очень мало информации.
Если представить себе систему связи, то легко понять, что для нее характерна большая изменчи-вость как того, что поступает в систему, так и того, что из нее выходит. Следовательно, вход и выход системы можно описать посредством их изменений (или их информации). В хорошей системе связи должна существовать определенная систематическая зависимость между тем, что поступает на вход си-стемы, и тем, что получается на ее выходе. Иначе говоря, выход системы зависит от входа или соответ-ствует ему. Если мы найдем эту зависимость, то сможем определить, какая часть выходных изменений определяется входом и какая часть возникает из-за случайных флуктуации или «шума», вносимого си-стемой при передаче. Таким образом, мы видим, что мера передаваемой информации есть просто мера связи между входом и выходом.
Иначе говоря, выход системы зависит от входа или соответ-ствует ему. Если мы найдем эту зависимость, то сможем определить, какая часть выходных изменений определяется входом и какая часть возникает из-за случайных флуктуации или «шума», вносимого си-стемой при передаче. Таким образом, мы видим, что мера передаваемой информации есть просто мера связи между входом и выходом.
Надо следовать в дальнейшем двум простым правилам: когда бы я ни упомянул о «количестве ин-формации», вы должны понимать под этим «изменение»; когда я буду говорить о «количестве передан-ной информации», вы должны будете понимать под этим «совместное изменение», или «взаимозависи-мость».
Эту ситуацию можно отобразить графически посредством двух частично перекрывающихся окружностей. Тогда левая окружность может представлять собой изменение на входе, правая окруж-ность – изменение на выходе, а перекрывающаяся часть – взаимозависимые изменения входа и выхода. Под левой окружностью следует иметь в виду количество информации на входе, под правой – количе-ство информации на выходе, а перекрывающаяся часть есть количество переданной информации.
В экспериментах по абсолютной оценке испытуемый рассматривается как канал связи. Тогда на нашем графике левая окружность будет представлять собой количество информации, заключенной в стимулах, правая окружность – количество информации, заключенное в ответных реакциях испытуемо-го, а перекрывающаяся часть – взаимоотношение между стимулами и ответными реакциями, измерен-ное количеством переданной информации. Задача эксперимента состоит в том, чтобы, увеличивая количество информации на входе, измерить количество переданной информации. Если абсолютные суждения испытуемого при этих условиях совершенно точны, то будет передана почти вся входная информация и она может быть затем восстановлена из ответных реакций испытуемого. Если же он делает ошибки, то количество переданной информации будет значительно меньше входной. Можно ожидать, что по мере увеличения количества входной информации на входе испытуемый будет допус-кать все больше и больше ошибок, в таком случае мы можем попытаться выявить пределы точности его абсолютных оценок.
Если человек-наблюдатель представляет собой разумно устроенную систему связи, то по мере ро-ста количества информации, поступающей на вход, количество передаваемой информации вначале бу-дет возрастать и с дальнейшим ростом входной информации асимптотически приближаться к некото-рой предельной величине. Это асимптотическое значение мы примем за пропускную способность (channel capacity) наблюдателя, она представляет собой максимальное количество информации, которое может дать нам наблюдатель относительно стимулов посредством абсолютных оценок. Пропускная способность есть верхняя граница области, в пределах которой наблюдатель может согласовывать свои реакции с предъявляемыми ему стимулами.
Теперь осталось сказать всего несколько слов о двоичной единице (bit), и мы перейдем затем к анализу некоторых данных. Одна двоичная единица информации есть то количество информации, которое необходимо нам для принятия решения при выборе из двух одинаково вероятных возмож-ностей. Если мы должны решить, превышает ли рост данного человека шесть футов или нет, и если мы знаем, что обе эти возможности равновероятны, т. е. шансы между ними распределены поровну, то в таком случае нам необходима одна двоичная единица информации. Заметьте, что эта единица ин-формации, использованная нами, никак не связана с мерами длины — футами, дюймами или сантимет-рами. Как бы вы ни измеряли рост человека, вам все равно (при данной задаче) будет нужна точно одна двоичная единица информации.
е. шансы между ними распределены поровну, то в таком случае нам необходима одна двоичная единица информации. Заметьте, что эта единица ин-формации, использованная нами, никак не связана с мерами длины — футами, дюймами или сантимет-рами. Как бы вы ни измеряли рост человека, вам все равно (при данной задаче) будет нужна точно одна двоичная единица информации.
2 дв. ед. информации позволяют нам произвести выбор из четырех равновероятных возможно-стей, 3 дв, ед. информации – из восьми равновероятных возможностей, 4 дв. ед. – из 16, 5 – из 32 и т. д. Иначе говоря, если заданы 32 равновероятные возможности, то, прежде чем узнать, какая из них является правильной, мы должны осуществить пять последовательных бинарных решений, каждое из которых связано с 1 дв. ед. Итак, существует довольно простое правило: каждый раз, когда число возможностей для выбора увеличивается в два раза, прибавляется 1 дв. ед. информации.
Существует два способа увеличения количества входной информации. Мы могли бы увеличить скорость, с которой мы предъявляем информацию наблюдателю; при этом будет возрастать количество информации, приходящейся на единицу времени. В другом случае мы могли бы полностью игнориро-вать временную переменную и увеличить количество входной информации, увеличив число альтерна-тивных стимулов. В экспериментах по абсолютным оценкам мы интересуемся именно вторым спосо-бом. Мы предоставляем наблюдателю столько времени, сколько ему требуется для того, чтобы дать от-вет, при этом мы просто увеличиваем число альтернативных стимулов, среди которых он должен про-извести свой выбор, и следим за тем, когда появятся ошибки. Ошибки начинают появляться при дости-жении того уровня, который мы называем «пропускной способностью».
Абсолютные оценки одномерных стимулов
Посмотрим теперь, что получается при выработке абсолютных суждений о звуковых тонах. Пол-лак давал испытуемым задание опознавать тона, причем каждому тону они должны были по-ставить в соответствие определенное число. Тона различались по частотам и выбирались в диапазоне от 100 до 8000 Гц через равные логарифмические интервалы. После того как прозвучит определенный тон, испытуемый должен был назвать соответствующее ему число. После ответа испытуемому сообщали, правильно он произвел идентификацию тона или нет.
Рис. 1. Данные, приводимые Поллаком и относящиеся к количеству информации, которое передается слушателем, выносящим абсолютную оценку о высоте тона. В то время как количество входной информации возрастает с увеличением числа различимых тонов (от 2 до 14), которые нужно оценить, количество переданной информации увеличивается и достигает верхнего предела пропускной способности, равного примерно 2,5 дв. ед. на одну оценку. В том случае, когда использовались только 2 или 3 тона, испытуемые никогда не смешивали их. При 4 различных толах ошибки были чрезвычайно редки, а при 5 и более тонах ошибки отмечались довольно часто. При 14 тонах испытуемые допускали очень много ошибок.
На рис. 1 представлены данные эксперимента. По оси абсцисс отложено количество информации в двоичных единицах на стимул. По мере увеличения числа альтернативных тонов от 2 до 14 входная информация увеличивалась от 1 до 3,8 дв. ед. По оси ординат отложено количество переданной информации. Как и следовало ожидать, полученная зависимость переданной информации от входной информации в данном случае имеет такой же характер, как и для канала связи: передаваемая информация вначале линейно растет примерно до 2 дв. ед.; затем ее рост замедляется и она стремится к асимптотическому значению, равному примерно 2,5 дв. ед. Это значение 2,5 дв. ед. и есть то, что мы называем пропускной способностью слушателя, выносящего абсолютные оценки высоты тонов.
Итак, мы получили число, равное 2,5 дв. ед. Что же оно означает? Прежде всего заметьте, что 2,5 дв, ед. примерно соответствуют 6 равновероятным возможностям. Полученный результат означает, что нельзя выбирать более 6 тонов, если мы хотим, чтобы испытуемый никогда не ошибался. И, выражаясь несколько иначе, как бы много альтернативных тонов мы ни предъявили испытуемому, самое большее, что мы можем ожидать от него, это то, что он безошибочно отнесет их к 6 различным классам.
Многие, вероятно, будут удивлены, узнав, что это число столь мало – только 6. Конечно, известно, что музыкально одаренный человек способен различать по абсолютной высоте от 50 до 60 тонов. К сча-стью, у меня нет времени для обсуждения этого удивительного исключения. Я говорю «к счастью», по-тому что не знаю, чем объяснить это достижение ими таких высоких характеристик. Поэтому будем иметь дело с более обыкновенными фактами, которые говорят, что каждый из нас способен различить любой из 5 или 6 тонов, а затем начинает делать ошибки.
Здесь уместно напомнить, что психологи уже давно пользуются семизначной оценочной шкалой по той интуитивно осознанной причине, что бесполезно пытаться разделить шкалу на более мелкие ка-тегории просто потому, что это ничего не прибавит к окончательной оценке. Полученные Поллаком результаты, по крайней мере для экспериментов с высотой тона, хорошо подтверждают эту ин-туитивную позицию.
Возникает вопрос о том, насколько широко может быть распространен этот результат? Зависит ли он только от разнесения тонов или еще и от иных условий эксперимента? Поллак изменял эти условия различным образом. Диапазон частот изменялся примерно в 20 раз, но при этом количество передавае-мой информации изменялось не более чем на несколько процентов. Различия перегруппировки тонов уменьшали информацию, но потеря была совсем небольшая. Например, если испытуемые могут разли-чить 5 высоких тонов в одной группе и 5 низких тонов в другой группе, то следовало бы ожидать, что при объединении всех 10 тонов в одну группу испытуемые продолжали бы безошибочно различать эти тона. Тем не менее им это не удается сделать. Оказывается, что пропускная способность при различе-нии тонов по высоте равна примерно 6 и это лучшее, чего удается достичь.
Рис. 2. Данные Гарнера о пропускной способности при абсолютных оценках уровней громко-сти стимулов.
Перейдем теперь к работе Гарнера , в которой исследовалось различение тонов по громкости. На рис. 2 представлены полученные Гарнером результаты. Гарнер затратил немало усилий для наилуч-шего возможного размещения тонов в диапазоне интенсивностей от 15 до 110 Дб. Он использовал 4, 5, 6, 7, 10 и 20 различных по интенсивности тонов. Представленная на рис. 2 зависимость построена с учетом различий между испытуемыми и влияния на данную оценку непосредственно предшествовавшей оценки. И в данном случае мы снова обнаруживаем наличие определенного предела. Пропускная способность при выработке абсолютных оценок относительно высоты тонов равна 2,3 дв.ед., или примерно 5 отчетливо различаемым альтернативам.
Поскольку эти два исследования были проведены в разных лабораториях с совершенно различны-ми оборудованием и методами анализа, мы не можем с полной достоверностью сказать, являются ли полученные результаты – 5 допустимых уровней громкости и 6 различных тонов – существенно различ-ными. По-видимому, это различие все же отражает действительное положение вещей, и абсолютные оценки высоты тонов просто несколько более точны, чем суждения об уровнях громкости. Важно, од-нако, что оба ответа представляют собой величины одного порядка.
Рис. 3. Данные Биб-Сеятера, Роджерса и О’Коннели о пропускной способности при абсолют-ных оценках степени солености растворов.
Были проведены также эксперименты со вкусовыми раздражителями. На рис. 3 представлены по-лученные Биб-Сентером, Роджерсом и О’Коннели результаты экспериментов по абсолютным оцен-кам концентраций солевых растворов. Концентрации брались в пределах от 0,3 до 34,7 г поваренной соли на 100 см3 питьевой воды, причем значения концентрации выбирались через равные субъективно интервалы. Пропускная способность оказалась равной 1,9 дв. ед., что соответствует примерло четырем различимым концентрациям. Таким образом, кажется, что вкусовые концентрации различаются в не-сколько меньшей степени, чем звуковые стимулы, но величины снова получились примерно те же.
С другой стороны, пропускная способность в случае оценок положений в пространстве зритель-ных стимулов оказывается значительно большей. Хейк и Гарнер проводили эксперименты, в кото-рых наблюдатели должны были интерполировать положение указателя между двумя отметками шкалы. Результаты экспериментов представлены на рис. 4. Эксперименты велись в двух направлениях. В пер-вом варианте наблюдатели могли использовать любое число от 0 до 100, чтобы описать положение. Во втором испытуемые были ограничены в своих ответах только теми значениями, которые были возмож-ны. Но результаты настолько сходны, что мы вправе заключить, что число доступных испытуемому ответов никак не сказывается на пропускной способности, которая в данном случае равна 3,25 дв. ед.
Рис. 4
Коонэн и Клеммер повторили эксперимент Хейка и Гарнера. И хотя они еще не опубликовали своих результатов, я получил разрешение заявить, что достигнутая в их опытах пропускная способность лежит в пределах от 3,2 дв. ед. для очень коротких периодов предъявления позиции указателя на шкале и до 3,9 дв. ед, для более длительных предъявлений. Эти оценки несколько выше полученных Хейком и Гарнером, и поэтому мы должны сделать вывод о том, что на линейном интервале можно отчетливо различить от 10 до 15 позиций. Это самое большое значение пропускной способности для любой из одномерных переменных величин.
В настоящее время эти четыре эксперимента по абсолютным оценкам простых одномерных сти-мулов представляют собой все, что появилось в психологических журналах по данному вопросу. Одна-ко большое количество работ, в которых исследовались другие стимульные переменные, еще не опуб-ликовано. Например, Эриксен и Хейк определили, что пропускная способность, связанная с оценка-ми размеров квадратов, составляет 2.2 дв. ед., или около 5 категорий, при широком разнообразии экспериментальных условий. В своем отдельном эксперименте Эриксен получил следующие данные: 2,8 дв. ед. для размеров, 3,1 дв. ед. для оттенков и 2.3 дв. ед, для яркости. Гелдард измерил пропускную способность тактильного анализатора, прикладывая вибраторы к грудной области. Хороший испытуемый мог различить примерно 4 степени интенсивности, 5 длительностей колебаний и около 7 местоположений.
Одной из. наиболее активных групп, работающих в этой области, является Лаборатория операци-онных исследований военно-воздушных сил. Поллак был настолько любезен, что предложил мне в полное распоряжение результаты измерений, касающихся пропускной способности оператора при работе за устройствами отображения зрительной информации. Эта группа произвела измерения пропускной способности при восприятии площадей, кривизны, длин линий и их направлений. В одной серии экспериментов они прибегали к очень короткой экспозиции стимулов-1/40 се/с, а затем повторили измерения при 5-секундной экспозиции. При короткой экспозиции они получили величину пропускной способности для площадей 2,6 дв. ед., а при длительной экспозиции — 2,7 дв. ед, Для длины линий они получили около 2,6 дв. ед. при короткой экспозиции и 3,0 дв. ед. при длительной экспозиции. Пропускная способность при оценке направлений или углов наклона оказалась равной 2,8 дв. ед. для короткой и 3,3 дв. ед. для длительной экспозиции. Оказалось, что оценка кривизны сопряжена со значительными трудностями. Результаты при постоянной длине дуги и при короткой экспозиции равны 2,2 дв. ед; если же оценивалась длина хорды, то результаты равнялись всего 1,6 дв. ед. Эта последняя величина является самой низкой из всех измеренных кем бы то ни было. Я должен добавить, однако, что полученные результаты слишком занижены, потому-что, прежде чем вычислить количество переданной информации, они объединяли данные всех испытуемых.
Разберемся теперь в достигнутых результатах. Во-первых; кажется, что пропускная способность является вполне закономерным понятием для описания поведения человека-наблюдателя. Во-вторых, значения пропускных способностей, измеренные для одномерных стимульных переменных, заключены в пределах от 1,6 до 3,9 дв. ед. для определения позиций точки на интервале. Хотя здесь не ставится вопрос о том, какие различия переменных являются подлинными и значимыми, мне кажется более важ-ным то обстоятельство, что они обнаруживают значительное сходство. Если взять верхние значения оценок, полученных во всех упомянутых экспериментах, то среднее значение по всем стимулы-гым переменным будет равно 2,6 дв. ед., причем стандартное отклонение составит только 0,6 дв. ед. Если выражать эти данные посредством различимых альтернатив, то это среднее значение пропускной способности соответствует примерно 6,5 категориям, стандартное отклонение включает от 4 до 10 категорий, а общий диапазон изменений простирается от 3 до 15 категорий. Если иметь в виду Широкое разнообразие различных переменных величин, которые мы исследовали, то этот общий диапазон изменений окажется поразительно узким.
По-видимому, наш организм имеет какой-то предел, ограничивающий наши способности и обу-словленный в свою очередь либо процессом научения, либо самим строением нашей нервной системы. Исходя из рассмотренных результатов, можно, вероятно, сделать достоверный вывод о том, что мы об-ладаем конечной и скорее малой способностью выносить такие одноразмерные оценки и что эта спо-собность изменяется незначительно при переходе от одного простого сенсорного качества к другому.
Абсолютные оценки многомерных стимулов
Читатель, вероятно, заметил, что до сих пор я был достаточно осторожен, когда говорил, что это магическое число 7 относится к одномерным стимулам. Повседневный опыт свидетельствует о том, что мы можем точно идентифицировать любое лицо из нескольких сот лиц, любое слово из нескольких тысяч слов, любой из нескольких тысяч объектов и т. д. Наш рассказ, конечно, не был бы полон, если бы мы остановились в этом месте. Нам следует как-то попытаться понять, почему оценки одномерных стимулов дают в наших лабораториях результаты, так сильно отличающиеся от того, что мы постоянно наблюдаем вне лабораторий.
Возможное объяснение заключено в существовании целого ряда независимых переменных пара-метров стимулов, на основе которых производится оценка. Предметы, лица, слова и им подобное отли-чаются друг от друга многими признаками, в то время как простые стимулы, о которых мы говорили до сих пор, отличаются друг от друга только в одном отношении.
К счастью, мы располагаем некоторыми данными относительно абсолютных оценок стимулов, отличающихся друг от друга несколькими признаками. Прежде всего рассмотрим полученные Клеммером и Фриком результаты об абсолютных оценках положения точки в квадрате. Эти результаты можно видеть на рис. 5. Как видно из рис. 5, где представлены полученные ими результаты, значение пропускной способности возросло до 4,6 дв. ед., это означает, что человек способен точно указать любое из 24 положений точки внутри квадрата.
Рис. 5. Данные Клеммера и Фрика о пропускной способности при абсолютных оценках положения точки в квадрате.
Определение положения точки в квадрате является задачей восприятия в двухмерном простран-стве. Для ее решения требуется определить положение как по горизонтали, так и по вертикали. Вполне естественно сравнить значение пропускной способности для случая оценки положения точки в квадрате (4,6 дв. ед.) со значением пропускной способности для случая оценки положения точки на линейном интервале (3,25 дв.ед.). Для определения положения точки внутри квадрата требуется произвести две оценки того же типа, что и при определении положения точки па интервале. Пропускная способность при оценке интервалов равнялась 3,25 дв. ед. Для двух таких оценок мы получили бы при определении точки в квадрате величину 6,5 дв. ед. На самом же таеле добавление второй переменной привело к увеличению значения от 3,25 только до 4,6 дв. ед.
Другой пример дает нам работа Биб-Сентера, Роджерса и О’Коннели. Когда перед испытуемыми ставилась задача различать растворы, содержащие неодинаковые концентрации сахара и соли, как по степени сладости, так и по степени солености, то оказалось, что пропускная способность в данном слу-чае равна только 2,3 дв. ед. Так как при определении солености это значение равно 1,9 дв. ед., в данном случае, когда оценки выносятся в двух признаках сложного стимула, можно было бы ожидать величи-ны пропускной способности около 3,8 дв, ед. Как и при определении пространственного положения стимула, в данной задаче второе измерение лишь незначительно увеличило пропускную способность. В экспериментах Поллака испытуемые должны были определять громкость и высоту чистых тонов. Так как высота тона дает 2,5 дв. ед. и громкость дает 2,3 дв. ед., при сочетании оценок о высоте и уровне громкости можно было бы рассчитывать получить 4,8 дв. ед. Поллак же получил 3,1 дв. ед., что опять-таки указывает на то, что добавление второго измерения увеличивает значение пропускной способности лишь незначительно.
Четвертый пример можно взять из работы Халси и Чапаниса , в которой исследовалось смеше-ние цветов одинаковой освещенности. Хотя полученные ими результаты не анализировались в теоретико-информационных понятиях, они считают, что существует примерно от 11 до 15 цветов, что соответствует в нашей терминологии примерно 3,6 дв. ед. Поскольку цвета изменялись как по оттенкам, так и по насыщенности, вероятно, вполне правильно будет рассматривать эти стимулы как двухмерные. Если мы сравним полученный результат с данными Эриксена – 3,1 дв. ед. для оттенков (оставляя в стороне вопрос о допустимости такого сравнения), мы снова получим число – немного меньше простой арифметической суммы, которую мы ожидали бы получить при добавлении второго измерения.
Однако примеры с двухмерными стимулами далеки от случая различения таких многомерных стимулов, как лица, слова и т. д. У нас есть только данные одного эксперимента со звуковыми стимула-ми, проведенного Поллаком и Фиксом . Они выбрали 6 различных акустических переменных, зна-чения которых можно было изменять в широких пределах: по частоте, интенсивности, скорости преры-вания, отношению интервалов звучания и прерывания, общей продолжительности и пространственному расположению. Как предполагалось, каждая из шести переменных могла принимать любое из 5 различных значений. В результате было получено 56, или 15625, различающихся друг от друга тонов, которые можно было бы предъявить испытуемым. Слушатели производили раздельную оценку по каждому из 6 измерений. При данных условиях количество переданной информации составило 7,2 дв. ед., что соответствует примерно 150 различным категориям, которые можно было бы абсолютно и безошибочно идентифицировать. Здесь мы только начинаем приближаться к тому диапазону изменчивости, с которым постоянно сталкиваемся в повседневной практике.
Представим себе, что мы нанесли все эти данные на график, и попытаемся теперь понять, как с изменением размерности стимула изменяется пропускная способность. В этом нам поможет рис. 6. Я даже нанес на график пунктирную линию, которая в схематическом виде отображает проявляемую эти-ми данными общую тенденцию.
Рис. 6. Общий характер зависимости между пропускной способностью и числом независимых пе-ременных признаков стимула.
Ясно, что добавление к стимулу независимого переменного признака увеличивает пропускную способность, но это увеличение по мере добавления новых признаков происходит во все уменьшаю-щейся пропорции. Интересно отметить, что пропускная способность увеличивается даже в том случае, когда эти переменные не являются независимыми. Эриксен отмечает, что в том случае, когда разме-ры, яркости и оттенки стимулов изменяются в строгой связи друг с другом, передаваемая информация равна 4,1 дв. ед. по. сравнению со своим средним значением в 2,7 дв. ед.,- которое достигается в том случае, когда каждый признак изменяется в отдельности по одному за один раз. Соединив три признака, Эриксен увеличил размерность входа, но при этом количество входной информации не увеличилось (так как изменение значений признаков происходит взаимозависимо). В результате этого пропускная способность увеличилась примерно в такой степени, как это можно было ожидать, судя по пунктирной кривой рис. 6.
Дело, как кажется, обстоит таким образом, что при добавлении новых переменных в изображение пропускная способность увеличивается, но при этом падает точность различения любой отдельной пе-ременной. Другими словами, относительно нескольких предметов одновременно мы можем делать только довольно приблизительные суждения.
Можно утверждать, что в ходе эволюционного процесса выживали лишь те организмы, которые с наибольшим успехом могли реагировать на самый широкий набор стимулов, поступавших из окружа-ющей среды. Для того чтобы выжить в постоянно изменяющемся мире, гораздо лучше иметь небольшое количество информации о многих вещах, чем обладать огромной информацией относительно малой части окружающей среды. Тот компромисс, который был достигнут в результате эволюции, и является наиболее подходящим.
Результаты, полученные Поллаком и Фиксом, очень хорошо согласуются с выдвигаемым в по-следнее время лингвистами и фонетистами аргументом . Согласно лингвистическому анализу зву-ков человеческой речи, существует от 8 до 10 мер — лингвисты называют их отличительными призна-ками, — посредством которых одна фонема отличается от другой. По своей природе эти отличительные признаки обычно являются двоичными или в крайнем случае троичными. Например, бинарный различительный признак лежит в основе отделения гласных от согласных, для различения ротовых согласных от носовых требуется принять также бинарное решение, а для различения переднеязычных, среднеязычных и заднеязычных фонем нужно принять троичное решение и т. д. Такой подход к распознаванию фонем дает нам совершенно иную картину восприятия речи и позволяет иначе подойти к анализу способности человеческого уха определять относительные различия чистых тонов. Лично я очень заинтересовался новым подходом и мне остается только выразить сожаление, что в данной работе я не могу остановиться на этом более подробно.
Вероятно, Поллак и Фикс решили провести свои эксперименты над рядом тональных стимулов именно под воздействием лингвистической теории. Они изменяли стимулы по 8 измерениям, но по каждому измерению требовалось принять только бинарное решение. В результате измерения передава-емой информации они получили 6,9 дв. ед., или 120 различимых типов звуков. В этой связи встает ин-тересный и до сих пор пока еще не решенный вопрос: можно ли таким способом неограниченно, добавлять новые измерения?
В человеческой речи обнаруживается четко выраженный предел для ряда используемых нами из-мерений. Но в таком случае, однако, не известно, возникает ли этот предел из-за самой природы пер-цептивного механизма, предназначенного для различения звуков, или из-за особенностей речевого ме-ханизма, который производит эти звуки. Видимо, для выяснения этого следует проделать специальные эксперименты. Однако в каждом языке существует хорошо изученный предел, равный 8 или 9 различи-тельным признакам. Следовательно, когда мы говорим, мы прибегаем еще к одному тонкому приему для увеличения нашей пропускной способности. В нашем языке используются целые последовательно-сти фонем. Таким образом при слушании слов и предложений мы выносим последовательно несколько оценок. Иначе говоря, мы прибегаем как к последовательным, так и к одновременным способам разли-чения звуков для того, чтобы расширить довольно жесткие пределы, обусловленные неточностью наших абсолютных оценок простых величин.
Эти многомерные оценки очень напоминают эксперименты по абстрагированию Кюльпе . Как известно, он показал, что установка испытуемых на определенные признаки стимулов приводила к тому, что испытуемые сообщали более точно именно об этих признаках, чем о признаках, не вошедших в их число. Например, Чепмэн использовал 3 различных признака и сравнивал результаты двух серий экспериментов. В первой серии перед тахистоскопическим предъявлением стимулов испытуемые получали определенные инструкции относительно признаков, во второй серии испы-туемым не сообщалось, на какой из признаков им следует обратить внимание. Оказалось, что суждения были более точны а том случае, когда испытуемым заранее давалась инструкция. Когда же инструкция давалась после предъявления стимулов, тогда испытуемые, по-видимому, должны были до оценки од-ного из трех признаков составить предварительно оценки всех признаков, что, конечно, снижало точ-ность ответов. Эти данные полностью соответствуют только что рассмотренным результатам, согласно которым точность суждения относительно каждого признака уменьшается при увеличении числа изме-рений. Суть дела, конечно, ясна, но мне хотелось бы подчеркнуть, что эксперименты по абстрагированию не подтвердили того положения, что человек за один раз может судить только об одном признаке. Они показали только то, что человек бывает менее точен в своих суждениях в том случае, когда ему приходится выносить их более чем об одном признаке одновременно.
Симультанное восприятие
Я не могу закончить этот обзор, ничего не сказав хотя бы вкратце об экспериментах над различе-нием чисел, проведенных в Маунт-Хоулиоукском колледже Кауфманом, Лордом, Ризом и Фолькманом. Они предъявляли испытуемым на экране беспорядочно составленные из точек изображения на время 5 сек. В любом предъявлении могло появиться от 1 до 200 точек. Задача испытуемых состояла в том, чтобы сообщить, сколько точек содержит изображение.
Прежде всего надо заметить, что, когда изображение содержало до пяти или шести точек, испыту-емые просто не делали ошибок. Результаты действий с этими небольшими количествами точек были настолько отличны от результатов действий с большим числом точек, что этим действиям следует дать специальное наименование. Когда число точек не превышает 7, говорят о «мгновенном схватывании» (subitise) , при большем числе говорят об оценке (estimate). Как вы заметили, это именно то, что мы од-нажды метафорически назвали «объемом внимания».
Такое резкое прерывание на числе 7 является, конечно, предположительным. Наблюдаем ли мы и здесь тот же самый процесс, который ограничивает нашу способность к одномерным оценкам примерно семью категориями?
По моему мнению, это обобщение заманчиво, но безосновательно. Эти данные по оценке чисел не были проанализированы посредством теоретико-информационных понятий, но, основываясь на опубликованных результатах, я предполагаю, что испытуемые передавали не многим более 4 дв. ед. информации относительно числа точек. Прибегая к тем же самым аргументам, что и раньше, мы могли бы заключить, что существует всего около 20 или 30 различаемых численных категорий. Это значительно превосходит то количество информации, которое можно было бы ожидать от одноразмерного изображения. На самом же деле все это очень похоже на двухмерное изображение. И хотя еще не ясно, как определять размерность изображения, составленного из случайно сгруппированных точек, эти результаты приближаются к данным Клеммера и Фрика для двухмерного стимула при нахождении положения точки в квадрате. Вероятно, при оценке числа точек такими двумя измерениями являются занимаемая точками площадь и их плотность. В том случае, когда испытуемый может симультанно воспринимать, площадь и плотность изображения не являются значимыми переменными, но, когда испытуемый должен оценивать, эти параметры, вероятно, оказываются значимыми. Во всяком случае, это не настолько простое дело, как могло показаться на первый взгляд.
Это одна из тех областей, в которых меня преследует магическое число 7. Здесь мы сталкиваемся с двумя тесно связанными типами экспериментов, каждый из которых указывает на значение числа 7 как предела наших способностей. И все же при более углубленном изучении проблемы остается, как кажется, вполне оправданное подозрение, что все это можно объяснить простым совпадением.
Объем непосредственной памяти
Позвольте мне подвести итог сказанному таким образом: существует определенный четко выра-женный предел той точности, с которой мы можем абсолютно (т. е. не прибегая к сравнению с этало-ном) различать величину одномерной стимульной переменной. Я предложил бы называть этот предел объемом абсолютной оценки, и я утверждаю, что для одномерных оценок этот объем лежит где-то по-близости от числа 7. Наши способности, однако, не находятся в полной зависимости от этого ограни-ченного объема, потому что мы обладаем множеством способов выйти за его пределы и увеличить точ-ность наших суждений. Вот три наиболее важные из них: (а) надо прибегнуть к относительным, а не к абсолютным суждениям, и если это невозможно, то (б) следует увеличить число измерений, по которым могли бы различаться стимулы, или (в) перестроить задачу таким образом, чтобы можно было составить ряд из нескольких последовательных оценок.
Исследование относительных оценок является одной из самых старых проблем эксперименталь-ной психологии, и я не собираюсь здесь приводить обзор этих исследований. Второй способ, заключа-ющийся в увеличении размерности стимулов, мы только что подробно рассматривали. Кажется, что, добавляя новые измерения и требуя только грубых, бинарных оценок типа «да» – «нет» по каждому из признаков, мы сможем расширить объем абсолютных оценок от 7 по крайней мере до 150. Если исхо-дить из нашего повседневного опыта, то, вероятно, этот предел лежит где-то около нескольких тысяч, если он в действительности существует. По моему мнению, нельзя беспредельно объединять изме-рения. Я предполагаю, что существует также объем перцептивной размерности и что численное значение этого объема лежит где-то около десяти, но я должен сразу же добавить, что для доказательства этого предположения у меня нет никаких объективных данных. Этот вопрос также нуждается в экспериментальном исследовании.
Что же касается третьего приема – использования последовательных оценок, то на нем мне хоте-лось остановиться несколько более подробно, потому что здесь прибегают к интересному приему, когда память ставится на службу процесса различения. И поскольку мнемонические процессы не менее сложны, чем перцептивные, можно думать, что разобраться в их взаимодействии будет не так-то легко.
Предположим, что мы начнем просто с небольшого развития той экспериментальной методики, которой мы уже пользовались. До сих пор мы предъявляли наблюдателю один стимул и просили назвать его немедленно после предъявления. Мы можем развить эту методику, если потребуем от испы-туемого не спешить с ответом, пока ему не будет предъявлена последовательность нескольких стиму-лов. Он должен давать ответ в конце последовательности стимулов. Наша экспериментальная ситуация оказывается тон же самой, что и при измерениях передаваемой информации. Но теперь мы перешли от экспериментов по выработке абсолютных суждений к тому, что по традиции называется эксперимента-ми по исследованию непосредственной памяти.
Прежде чем мы начнем рассматривать относящиеся к этому вопросу данные, мне хотелось бы сделать предостережение, чтобы помочь вам избежать некоторых очевидных ассоциаций, которые мо-гут ввести в заблуждение. Всем известно, что существует конечный объем непосредственной памяти и что для большинства типов тестового материала этот объем не превышает 7 единиц. Я только что гово-рил об объеме абсолютных оценок, который соответствует примерно 7 различимым категориям, и об объеме внимания, составляющем примерно 6 предметов, которые можно увидеть одновременно. Что может быть более естественнее предположения о том, что все эти явления есть различные аспекты еди-ного процесса, лежащего в их основе? И именно в этом предположении кроется коренная ошибка. Эта навязчивая вредная идея преследовала меня столь же упорно, что и магическое число 7.
Моя ошибка вела примерно к следующему. Мы уже видели, что количество информации, которое наблюдав тель может передать, является инвариантным свойством объема абсолютных суждений. Между экспериментами по абсолютным оценкам и экспериментами по изучению непосредственной памяти существует большое операционное сходство. Если явления, связанные с непосредственным запоминанием, в чем-то сходны с абсолютными оценками, то отсюда следует, что количество информации, которое может запомнить наблюдатель, также является инвариантным свойством объема непосредственной памяти. Если количество информации в объеме непосредственной памяти является постоянной величиной, то тогда этот объем должен быть малым в том случае, когда запоминаемые отдельные единицы содержат много информации, и большим в том случае, когда они несут мало информации. Например, каждая десятичная цифра несет 3,3 дв. ед. информации, мы обладаем способностью сохранять в памяти примерно семь десятичных цифр, что дает в сумме 23 дв. ед. информации. Изолированное слово английского языка несет примерно 10 дв. ед. каждое. Если общее количество информации остается постоянным и равным 23 дв. ед., то в таком случае мы должны были бы помнить только два или три выбранных наугад слова. Таким путем я пришел к гипотезе, согласно которой объем непосредственной памяти меняется в зависимости от количества информации, приходящейся на единицу тестового материала.
Измерения объема памяти, сведения о которых имеются в литературе, проводились с учетом, но недостаточно определенным, этой зависимости. Поэтому необходимо было поставить дополнительные опыты. Хейес попытался это сделать, используя в своих экспериментах пять различных типов те-стовых материалов: бинарные цифры, десятичные цифры, буквы латинского алфавита, эти же буквы плюс десятичные цифры и, кроме того, 1000 односложных слов. Списки символов читались вслух со скоростью один символ в секунду, и испытуемым предоставлялось столько времени на ответные реак-ции, сколько им было необходимо. Для подсчета реакций использовалась методика, предложенная Ву-двортсом .
Полученные результаты представлены на рис. 7 черными кружками. Пунктирная линия на этом же рисунке показывает, каким должен был бы быть объем непосредственной памяти в том случае, если бы количество информации оставалось постоянным. Сплошными линиями показаны данные, полученные на самом деле.
Рис. 7. Данные Хейеса , показывающие зависимость объема непосредственной памяти от приходящегося на единицу тестового материала количества информации.
Хейес повторил свой эксперимент, используя различные по объему тестовые словари, содержащие только английские односложные слова. Этот более однородный тестовый материал не изменил значительным образом окончательные результаты. При бинарных символах объем непосредственной памяти равен 9 единицам, и, хотя он и снижается до 5 единиц при односложных английских словах, получаемая разница оказывается гораздо меньшей, чем это можно было бы предположить на основании гипотезы постоянства количества информации в объеме непосредственной памяти.
Не следует думать, что в экспериментах Хейеса могла быть допущена какая-либо ошибка, по-скольку Поллак повторил их довольно тщательно и получил те же результаты. Поллак обратил при этом особое внимание на измерение количества передаваемой информации, не надеясь на традицион-ную методику подсчетов ответных реакций. Полученные им результаты представлены на рис. 8. Из ри-сунка видно, что количество переданной информации не является постоянной величиной, оно почти линейно возрастает с увеличением количества входной информации, приходящейся на один символ.
Рис. 8. Данные Поллака (16], показывающие зависимость остающегося после одного предъявления количества информации от приходящегося на единицу тестового материала количества информации.
Итак, окончательный результат совершенно ясен. Несмотря на то, что магическое число 7 в силу случайного совпадения появляется в обоих случаях, объем абсолютных оценок и объем непосредствен-ной памяти характеризуют два совершенно различных типа ограничений, накладываемых на наши воз-можности по переработке информации. Абсолютные оценки связаны с ограниченным количеством ин-формации, а непосредственная память ограничена числом запоминаемых единиц. Для того чтобы выра-зить это различие в наглядной форме, я предлагаю проводить различие между дв. ед. информации, с одной стороны, и отрезком информации (chunks) – с другой. В таком случае можно будет говорить, что число двоичных единиц информации постоянно для абсолютной оценки и что число отрезков информации постоянно для непосредственной памяти. Кажется, что объем непосредственной памяти почти не зависит от числа двоичных единиц, приходящихся на отрезке информации, по крайней мере в тех пределах, которые были исследованы к настоящему времени.
Противопоставление терминов дв.ед. и отрезок информации проливает также свет и на то обстоя-тельство, что мы не очень точно определяем, из чего именно образуется этот отрезок информации. Например, полученный Хейесом объем непосредственной памяти в 5 выбранных наугад из 1000 ан-глийских односложных слов может быть назван объемом памяти в 15 фонем, поскольку каждое слово образовано примерно тремя фонемами, а логическое различие между ними не так уж очевидно. Мы имеет здесь дело с процессом организации или группировки входных стимулов в знакомые единицы или отрезки информации, и значительная часть усилий при обучении должна быть направлена на обра-зование таких знакомых единиц.
Перекодирование
Следовательно, для того чтобы выражаться более точно, мы должны признать важность процессов группирования или организации входных последовательностей в единицы или отрезки информации. Поскольку объем памяти равен ограниченному числу отрезков информации, мы можем увеличить число двоичных единиц, приходящихся на один отрезок информации, путем построения все больших и больших отрезков, причем так, чтобы каждый отрезок содержал больше информации, чем раньше.
Человек, только начинающий изучать радиотелеграфный код, воспринимает на слух каждую точку и тире раздельно, как отдельный отрезок информации. Но вскоре он обретает способность организовывать эти звуки в буквы, и теперь он уже обращается с буквами как с отрезками информации. Затем буквы организуются в слова, которые в свою очередь становятся еще большими отрезками информации, и оператор начинает целиком воспринимать целые фразы. Я не имею в виду, что каждый описанный шаг есть дискретный процесс или что на кривой обучения должны появляться Ровные участки (плато), потому что, конечно, различным уровням организации соответствуют различные скорости работы и эти уровни перекрывают друг друга в процессе обучения. Я просто указываю на тот очевидный факт, что в ходе обучения точки и тире организуются в слуховые образы и что по мере образования все больших отрезков информации в соответствующей степени возрастает количество сообщений, которые способен запомнить оператор. Пользуясь предлагаемыми мною терминами, можно сказать, что оператор учится увеличивать число двоичных единиц, приходящихся на отрезок информации.
В теории связи такой процесс называется перекодированием. Входные сообщения представляют собой код, который содержит много отрезков информации при небольшом числе двоичных единиц, приходящихся на отрезок. Оператор перекодирует входные сообщения в новый код, который содержит меньше отрезков информации, но при большем числе двоичных единиц, приходящихся на отрезок. Су-ществует много способов выполнить эти операции перекодирования, но, вероятно, наиболее простая заключается в образовании группы входных символов, присвоении нового обозначения группе и запо-минании этого нового названия вместо запоминания исходных входных символов.
Поскольку я убежден в том, что этот процесс является очень общим и важным для психологии процессом, я хочу рассказать вам о демонстрационном эксперименте, который с полной ясностью про-иллюстрирует все, что я говорил. Этот эксперимент был проведен С. Смитом в 1954 году.
Начнем с того уже отмеченного факта, что человек способен воспроизвести по памяти восемь де-сятичных цифр и только девять двоичных цифр. Поскольку в данном случае наблюдается такое расхож-дение в количестве информации, воспроизводимой в этих двух ответах, мы тотчас же предполагаем, что для увеличения объема непосредственной памяти на двоичные цифры необходимо было бы применить методику перекодирования. В таблице приведен метод, предназначенный для группирования и переименования. В верхней графе представлена последовательность из 18 двоичных цифр, которая гораздо больше, чем может воспроизвести по памяти испытуемый после однократного предъявления. В следующей строке эти же самые двоичные цифры сгруппированы в пары. Здесь могут образоваться следующие четыре пары: 00 переименовывается в 0, 01 переименовывается в 1, 10 — в 2 и 11- в 3. Иначе говоря, мы перешли от двоичной арифметики к четверичной арифметике. В перекодированной последовательности теперь имеется I только 9 цифр, которые надо запомнить, и это количество почти не превышает объема непосредственной памяти. . В следующей строке таблицы исходная последовательность двоичных цифр перекодирована в отрезки информации по 3 символа в каждом. Имеется всего 8 возможных сочетаний из 3 символов. Мы даем, таким образом, каждому сочетанию новое обозначение от 0 до 7. Теперь s мы перешли от последовательности 18 двоичных цифр к последовательности б восьмеричных, цифр, и это число вполне укладывается в объем непосредственной памяти. В последних двух строках двоичные цифры сгруппированы по 4 и 5, и им присвоены двоичнодесятичные обозначения от 0 до 15 и от 0 до 31.
Вполне очевидно, что этот способ перекодирования приводит к увеличению числа двоичных еди-ниц, приходящихся на отрезок информации, он позволяет также преобразовать двоичную последова-тельность в форму, которая легко может быть удержана в непосредственной памяти.
Смит привлек к опытам 20 испытуемых и измерил объем их непосредственной памяти на двоич-ные и восьмеричные цифры. Оказалось, что объем непосредственной памяти равен 9 для двоичных и 7 для восьмеричных цифр. Затем каждая из приведенных в таблице схем кодирования была дана 5 испы-туемым. Они изучали процесс перекодирования до тех пор, пока не сообщили, что он им понятен, это продолжалось от 5 до 10 мин. Затем он снова проверял объем их памяти на двоичные цифры, в то время как они пытались применить изученные ими схемы перекодирования.
В каждом случае применение схем перекодирования увеличивало объем их непосредственной па-мяти на двоичные цифры. Но это увеличение не было настолько большим, как следовало бы ожидать исходя из значений объема для восьмеричных цифр. Поскольку отмеченное различие увеличивалось с ростом коэффициента перекодирования, мы можем заключить, что нескольких минут, отведенных на ознакомление со схемами перекодирования, явно недостаточно. Очевидно, перевод из одного кода в другой должен происходить почти автоматически, иначе испытуемый потеряет часть следующей груп-пы, в то время как он будет пытаться вспомнить перевод последней группы.
Поскольку случаи с коэффициентами 4:1 и 5:1 нуждаются в расширенном изучении, Смит решил последовать примеру Эббингхауза и провести эксперименты на самом себе. С чисто немецкой терпели-востью он тщательно изучил последовательно все схемы перекодировки и получил результаты, пред-ставленные на рис. 9. Теперь результаты очень близки к тем, которых можно было бы ожидать исходя из значения объема памяти на восьмеричные цифры. Он смог запомнить 12 восьмеричных единиц. При перекодировке с коэффициентом 2:1 эти 12 отрезков информации соответствуют 24 дв. ед. При коэф-фициенте перекодирования 3:1 12 отрезков составляют 36 дв. ед., а при коэффициентах 4:1 и 5:1 они составляют почти 40 двоичных цифр.
Когда человек воспринимает 40 двоичных цифр и затем безошибочно их воспроизводит, это про-изводит удивительное впечатление. Однако если вы думаете, что все это можно рассматривать просто как мнемонический прием для расширения объема памяти, то вы упускаете при этом гораздо более важное обстоятельство, которое следует почти из всех таких мнемонических схем. Оно заключается в том, что перекодирование оказывается исключительно мощным инструментом для увеличения количе-ства информации, которое мы можем обработать. В нашей повседневной практике мы постоянно в той или иной форме прибегаем к процессам перекодирования.
Рис. 9. Зависимость объема непосредственной памяти на двоичные цифры от использованной методики перекодирования. Предсказанная функция получена путем перемножения объема непосред-ственной памяти на восьмеричные цифры на 2,3 и 3,3 при перекодировавши по основаниям 4,8 и 10 со-ответственно.
По моему мнению, самым привычным типом перекодирования, к которому мы все время прибегаем, является перевод на словесный код. Когда мы хотим вспомнить какую-либо историю, или довод, или идею, мы обычно стараемся пересказать ее своими словами. Когда мы хотим запомнить какое-либо событие, свидетелями которого мы стали, то обычно делаем вербальное описание этого события и затем вспоминаем именно это вербальное описание. Воспроизводя что-либо по памяти, мы восстанавливаем путем вторичной переработки Детали, которые кажутся совместимыми с тем частным вербальным перекодированием, которое было сделано нами. Существование этого процесса было подтверждено известным экспериментом Кармайкла, Хогэна и Вальтера , где исследовалось влияние названий на воспроизведение по памяти визуальных изображений.
В судебной психологии хорошо известны расхождения в показаниях очевидцев, но подобные рас-хождения и искажения не бывают произвольными – они проистекают из того обстоятельства, что каж-дый свидетель пользовался своей системой перекодирования, которая зависела от всего его жизненного опыта. Наш язык исключительно приспособлен для перераспределения данных в немногие богатые информацией отрезки. Я предполагаю, что и воображение также является одной из форм кодирования, но получить представления операционным путем и затем изучить их экспериментально – это гораздо более трудная задача, чем исследование связанных с символами форм перекодирования.
Исследование процесса запоминания событий изложенным способом кажется вполне возможным. Процесс запоминания можно рассматривать как процесс формирования отрезков информации или групп из объединяемых совместно символов до тех пор, пока не образуется достаточно малое число единиц, которое мы сможем в дальнейшем воспроизвести полностью по памяти. Особый интерес в этом отношении представляет работа Боусфилда и Коена по образованию группировок слов при воспроизведении их по памяти.
Краткие выводы
Мне хотелось бы, подойдя к концу изложения своего материала, сделать краткие заключительные замечания.
Во-первых, количество информации, которую мы можем получить, переработать и запомнить, ограничено в некоторых отношениях объемом абсолютных оценок и объемом непосредственной памя-ти. Путем симультанной организации входных стимулов по нескольким измерениям и последователь-ного упорядочения их в ряд отрезков информации нам удается устранить или по крайней мере значи-тельно ослабить эту ограниченность наших процессов переработки информации.
Во-вторых, процесс перекодирования является очень важным психологическим процессом и за-служивает гораздо большего внимания, чем ему до сих пор уделялось. В частности, тот вид лингвисти-ческого перекодирования, которым поминутно пользуются люди, представляется мне жизненной осно-вой мыслительных процессов. Клиницисты, социальные психологи, лингвисты и антропологи постоянно сталкиваются с процессами перекодирования, но тем не менее, вероятно, из-за того, что перекодирование менее доступно экспериментальному исследованию, чем, например, работа с бессмысленными слогами или Т-образными лабиринтами, традиционная экспериментальная психология очень мало или почти ничего не внесла в анализ этой проблемы. Тем не менее и здесь можно разработать экспериментальные методики, найти способы перекодирования и индикаторы поведения. И я надеюсь, что нам удастся обнаружить очень стройную систему отношений, описывающих то, что теперь кажется лишь разрозненным набором не слишком связанных между собой фактов.
В-третьих, предлагаемые теорией информации методики и меры дают возможность количествен-ного подхода к решению некоторых из этих задач. Теория информации дает нам единицу измерения для калибровки стимульного материала и для измерения характеристик испытуемых. Стремясь к ясности изложения, я опускал некоторые технические детали, касающиеся способов измерения информации, и старался выражать свои мысли наиболее простым образом. Надеюсь, что это не заставит вас думать, будто бы они совсем бесполезны в исследовании, теоретико-информационные понятия уже оказались весьма полезными при изучении процессов распознавания и лингвистических проблем, они обещают быть также полезными при исследовании процессов обучения и связанных с памятью явлений, кроме того, предполагалось, что они смогут найти применение при изучении образования понятий. Теперь могут показаться важными многие казавшиеся бесполезными лет двадцать или тридцать назад вопросы. В самом деле, я чувствую, что должен здесь закончить свой рассказ как раз тогда, когда он действительно становится очень интересным.
И наконец; как же обстоит дело с магическим числом 7? Что можно сказать о 7 чудесах света, о 7 морях, о 7 смертных грехах, о 7 дочерях Атланта — Плеядах, о 7 возрастах человека, 7 уровнях ада, 7 основных цветах, 7 тонах музыкальной шкалы или о 7 днях недели? Что можно сказать о семизначной оценочной шкале, о 7 категориях абсолютной оценки, о 7 объектах в объеме внимания и о 7 единицах в объеме непосредственной памяти? В настоящее время я пока предпочитаю воздержаться от суждения. Вероятно, за всеми этими семерками скрывается нечто очень важное и глубокое, призывающее нас от-крыть его тайну. Но я подозреваю, что это только злое пифагорейское совпадение.
Литература
(1) Beebe-Center, J. G., Rogers, M. S., & O’Connell, D. N. Transmission of information about sucrose and saline solutions through the sense of taste. J. Psychol., 1955, 39, 157-160.
(2) Bousfield, W. A., & Cohen, B. H. The occurrence of clustering in the recall of randomly arranged words of different frequencies-of-usage. J. gen. Psychol., 1955, 52, 83-95.
(3) Carmichael, L., Hogan, H. P., & Walter, A. A. An experimental study of the effect of language on the reproduction of visually perceived form. J. exp. Psychol., 1932, 15, 73-86.
(4) Chapman, D. W. Relative effects of determinate and indeterminate Aufgaben. Amer. J. Psychol., 1932, 44, 163-174.
(5) Eriksen, C. W. Multidimensional stimulus differences and accuracy of discrimination. USAF, WADC Tech. Rep., 1954, No. 54-165.
4. Закон Миллера — Законы UX [Книга]
Самый простой пример разбиения на части можно найти в том, как мы форматируем телефонные номера. Без разбиения телефонный номер представлял бы собой длинную цепочку цифр — значительно больше семи, что затрудняло бы обработку и запоминание. Отформатированный (разбитый по частям) номер телефона намного проще обрабатывать и запоминать (рис. 4-1).
Рисунок 4-1. Телефонный номер (США) с разбивкой на части и без нее
Давайте перейдем к более сложному примеру.При просмотре веб-страниц вы неизбежно столкнетесь со страшной «стеной текста» (рис. 4-2) — контентом, который характеризуется отсутствием иерархии или форматирования и превышает соответствующую длину строки. Его можно сравнить с только что приведенным примером неформатированного телефонного номера, но в большем масштабе. Этот контент сложнее сканировать и обрабатывать, что увеличивает когнитивную нагрузку на пользователей.
Рисунок 4-2. Пример «стены текста» (источник: Wikipedia, 2019)
Когда мы сравниваем этот пример с контентом, к которому применены форматирование, иерархия и соответствующая длина строки, контраст становится значительным.Рисунок 4-3 — это улучшенная версия того же содержимого. Заголовки и подзаголовки были добавлены для обеспечения иерархии, пробелы были использованы для разделения содержимого на различимые разделы, длина строки была уменьшена для улучшения читаемости, текстовые ссылки были подчеркнуты, а ключевые слова были выделены для контраста с окружающим текстом. .
Рисунок 4-3. «Стена текста» улучшена с помощью иерархии, форматирования и соответствующей длины строк (источник: Википедия, 2019)
Теперь давайте посмотрим, как разбиение на части применяется в более широком контексте.Разделение на части можно использовать, чтобы помочь пользователям понять лежащие в основе отношения, группируя контент в отдельные модули, применяя правила для разделения контента и обеспечивая иерархию (рисунок 4-4). Разделение на части можно использовать для структурирования контента, особенно в насыщенных информацией случаях. Результат не только визуально приятнее, но и удобнее для сканирования. Пользователи, просматривающие последние заголовки, чтобы определить, что заслуживает их внимания, могут быстро просмотреть страницу и принять решение.
Рисунок 4-4. Пример разбиения на фрагменты, применяемый к плотной информации (источник: Bloomberg, 2018)
Хотя разбиение на части невероятно полезно для наведения порядка в насыщенном информацией опыте, его можно найти и во многих других местах. Возьмем, к примеру, сайты электронной коммерции, такие как Nike.com (рис. 4-5), где для группировки информации, относящейся к каждому продукту, используются фрагменты. Хотя отдельные элементы могут не иметь общего фона или окружающей границы, они визуально разбиты по своей близости друг к другу (изображение продукта, название, цена, тип продукта и, наконец, общее количество доступных цветов).Кроме того, Nike.com использует фрагменты для группирования связанных фильтров на левой боковой панели.
Рисунок 4-5. Разделение на части обычно используется для группировки продуктов и фильтров на веб-сайтах электронной коммерции (источник: Nike.com, 2019)
Эти примеры демонстрируют, как разбиение на части можно использовать для визуальной организации любого контента для облегчения понимания. Это помогает тем, кто потребляет контент, понять лежащие в основе отношения и информационную иерархию. Чего не делает разбиение на части, так это установления определенного ограничения на количество элементов, которые могут быть показаны в данный момент времени или в группе.Скорее, это просто метод организации контента, который упрощает быстрое определение важной информации.
Волшебное число 7 +/- 2: как привлечь внимание? | автор: Stylumia | Stylumia
Представьте себе модный магазин, в который вы входите, и если вы видите, что происходит слишком много вещей, что вы ответите? Разве вы не запутались и не стали отталкивать?
Это происходит благодаря когнитивной науке. Это редактирование проверяет, есть ли ограничение на наше внимание?
Мы все время говорим о прилипчивости клиентов.Все начинается с внимания. Внимание начинается с нашей способности сохранять наблюдения в человеческой памяти. Представьте, что это Human RAM .
Эксперимент «Магическое число семь» утверждает, что количество объектов, которые средний человек может удерживать в рабочей памяти, составляет 7 ± 2 . Это означает, что объем человеческой памяти обычно включает строки слов или понятий в диапазоне от 5 до 9. Эта информация о пределах способности обрабатывать информацию стала одной из самых цитируемых статей в психологии.
Эксперимент «Магическое число семь» был опубликован в 1956 году когнитивным психологом Джорджем А. Миллером с факультета психологии в Psychological Review Принстонского университета. В статье Миллер обсуждал совпадение пределов одномерного абсолютного суждения и пределов кратковременной памяти. В одномерной задаче абсолютного суждения человеку предъявляют ряд стимулов, которые различаются в одном измерении (, например, 10 различных тонов, различающихся только высотой звука ), и он отвечает на каждый стимул соответствующей реакцией ( выучено ранее). ).Эффективность почти идеальна при использовании пяти или шести различных стимулов, но снижается по мере увеличения количества различных стимулов.
Мы живем в мире с экспоненциально увеличивающимся объемом информации. Не организовав должным образом , или полностью исключив некоторые из них, он в конечном итоге ухудшает нашу способность выполнять критические задачи в целях выживания (навигация / получение дохода). Вот почему так полезно исключать из своей жизни предметы, товары и услуги, которые не дают качественной окупаемости инвестиций.Это соответствует принципу Парето , идее о том, что 80% ваших результатов приходят из 20% ваших инвестиций. Вы выполняете слишком много задач в день, чтобы быть эффективным? Ваша команда использует слишком много инструментов для совместной работы? В вашей команде слишком много участников? Вы перегружаете своих новых сотрудников информацией, что приводит к путанице?
Закон Миллера учит нас, что люди имеют ограниченный объем информации, которую они могут обработать, и что информационная перегрузка приведет к отвлечению внимания, что отрицательно скажется на производительности.Компаниям следует искать способы организовать информацию таким образом, чтобы ее клиенты и сотрудники могли легче усваивать. Это может быть путем устранения инструментов или приложений, вызывающих когнитивную перегрузку, уменьшения количества членов в команде или даже организации ваших отделов на основе наших знаний о рабочей памяти.
Потребители — это люди, и мы ясно видим применение закона Миллера в розничной торговле в различных областях, кроме общих, выше
1. Количество цветов в диапазоне
2.Количество групп товаров в коллекции
3. Визуальная демонстрация в магазинах
4. Визуальные темы в коммуникациях и т. Д.
Неправда, что все мы склонны помнить простые, такие как Apple Store, где беспорядок меньше всего. ?
Надеюсь, эта редакция дала вам человеческий взгляд на дизайн вещей, которые помогут вам привлечь внимание потребителей.
В Stylumia мы стремимся сделать наш пользовательский интерфейс максимально простым с меньшей когнитивной нагрузкой. Это одна из причин, по которой мы выбрали визуальный подход к бизнес-аналитике.Нам предстоит пройти долгий путь, и мы можем с уверенностью поделиться с вами, что многое происходит в этом направлении, чтобы наши пользователи могли получать действенные идеи с меньшей когнитивной нагрузкой.
Почему магическое число семь плюс-минус два
https://doi.org/10.1016/S0895-7177(03)-5Получение прав и контента
Аннотация
В 1956 году Миллер [1] предположил, что существует верхний предел нашей способности обрабатывать информацию об одновременно взаимодействующих элементах с надежной точностью и достоверностью.Это ограничение составляет семь плюс-минус два элемента. Он отметил, что число 7 встречается во многих аспектах жизни, от семи чудес света до семи морей и семи смертных грехов. В этой статье мы демонстрируем, что при вынесении суждений о предпочтениях по парам элементов в группе, как мы это делаем в процессе аналитической иерархии (AHP), количество элементов в группе не должно быть больше семи. Причина кроется в последовательности информации, полученной из отношений между элементами. Когда число элементов превышает семь, результирующее увеличение несогласованности слишком мало для разума, чтобы выделить элемент, вызывающий наибольшую несогласованность, для тщательного изучения и исправления его отношения к другим элементам, и в результате возникает путаница в уме из-за существующая информация.AHP как теория измерения имеет основной способ получить меру несогласованности для любого такого набора парных суждений. Когда количество элементов равно семи или меньше, показатель несогласованности относительно велик по отношению к количеству задействованных элементов; когда число больше, оно относительно невелико. Наиболее противоречивое суждение легко определяется в первом случае, и человек, выносящий суждения, может изменить его, чтобы улучшить общую непоследовательность. Во втором случае, поскольку измерение несогласованности относительно невелико, для улучшения несогласованности требуются лишь небольшие возмущения, и судье будет сложно определить, каким должно быть это изменение и как такое небольшое изменение может быть оправдано для повышения достоверности результата. .Ум достаточно чувствителен, чтобы исправлять большие несоответствия, но не мелкие. Из этого следует, что количество элементов в наборе должно быть ограничено семью плюс-минус два.
Ключевые слова
Парные сравнения
Согласованность
Принятие решений
Процесс аналитической иерархии
Обработка информации
Ментальные ограничения
Рекомендуемые статьи Цитирующие статьи (0)
Авторские права © 2003 Опубликовано Elsevier Ltd.
Рекомендуемые статьи
Ссылки на статьи
Miller Industries | Тяжелая буксировка, вредители, перевозчики
Miller Industries на протяжении многих лет выбирает буксировочное оборудование по многим причинам. Их преданность своей продукции и изменения, которые они вносят для улучшения своей продукции, не имеют себе равных. Боковая лебедка Miller Industries на их держателях — это наш инструмент для безопасной погрузки самых разных транспортных средств. Благодарим Miller Industries за поставку отличного продукта и разработку новых продуктов для буксировки будущего.
Наша компания всегда могла рассчитывать на грузовики Miller Industries. От серии Vulcan Wrecker до серии Century Flat Bed качество производства и огромный объем функций, включенных в каждую покупку, помогли превратить сложную работу в более управляемую. Спасибо Miller Industries за разработку, создание и поддержку оборудования, которое составляет основу нашей отрасли.
Мы стремимся предоставить услуги высочайшего качества по возврату прав собственности в автомобильную финансовую отрасль. Для достижения этой цели крайне важно, чтобы мы работали с наиболее надежным, безопасным и превосходным доступным оборудованием. Наш успех напрямую связан с выбором партнерства с Miller Industries. Они зарекомендовали себя как ведущий производитель оборудования для автопогрузчиков и стремятся обеспечить исключительное обслуживание клиентов.Спасибо, Miller Industries, за вклад в достижения нашей компании, и мы надеемся на наше дальнейшее сотрудничество.
Сердце нашего предприятия с 14 грузовиками — перевозчики. Наш флот включает два промышленных перевозчика и четыре авианосца Century Right Approach ™. Перевозчики Right Approach ™ действительно являются одним из лучших дополнений к нашему флоту. Конструкция позволяет производить погрузку и разгрузку эффективно и без повреждений.Спасибо Miller Industries за отличный продукт.
Магическое число Миллера
|
|
Мы знаем, что обучение лексике является важной частью ЧТО преподавать на этапе Giving It B-SLIM. Что может быть не так просто, так это HOW для обучения лексике. Одна вещь, которую следует учитывать при обучении словарному запасу, — это ограничить количество изучаемых слов и разбить эти слова на значимые фрагменты.Если мы посмотрим на пример Джина, он не осознает, что предоставление студентам 30 слов для изучения за один раз может вызвать трудности. Если бы он принял во внимание магическое число Миллера (+/- 7), он мог бы добиться большего успеха в обучении словарному запасу. В этом разделе мы обсудим магическое число Миллера и его применимость ко всем аспектам обучения второму языку. |
вернуться к …Пример из практики Джина |
Что такое магическое число Миллера?
У людей есть только ограниченное количество информации, которую они могут обработать и запомнить одновременно.Миллер обнаружил в 1956 году, что число 7 ± 2, по-видимому, представляет собой количество элементов (цифр, букв, слов или других единиц), которые может обрабатывать рабочая память. Хотя это число может показаться ограниченным, его можно увеличить, разбив информацию на соответствующие и связанные группы; один блок может функционировать как один элемент, что позволяет обрабатывать больший объем информации.
Какие факторы могут повлиять на магическое число?
При разбиении информации на части количество информации, которая может быть сгруппирована вместе, зависит от группируемого элемента; например, исследование показало, что в блоки можно поместить больше цифр, чем в слова, и слова большей длины можно поместить в блоки, чем слова большей длины.Знакомство учащихся со словами и идеями также может повлиять на то, смогут ли они обработать больше или меньше информации.
Как магическое число Миллера связано с обучением?
Учителя должны знать магическое число Миллера при планировании уроков, чтобы они могли наилучшим образом оценить, сколько информации ученики могут обработать в своей рабочей памяти. Осведомленность об этом означает, что у учителей меньше шансов перегружать учеников информацией; это также напоминает учителям, что они должны систематизировать свой материал по соответствующим категориям.Предоставление студентам организованной информации позволяет студентам обрабатывать больше информации с меньшими затратами.
к началу
Опрос удовлетворенности клиентов Miller’s Ale House
Добро пожаловать в опрос удовлетворенности клиентов Miller’s Ale House. Мы ценим ваши откровенные отзывы и благодарим вас за то, что вы нашли время заполнить наш опрос.
Загрузить версию для обеспечения доступности
Введите следующую информацию из квитанции.
3-значный номер хранилища:
Контрольный номер:
Дата: — 010203040506070809101112 / — 01020304050607080910111213141516171819202122232425262728293031 / — 2021 г.
Время: — 010203040506070809101112 : — 000102030405060708091011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859 — ДО ПОЛУДНЯ ПОСЛЕ ПОЛУДНЯ
Гости Miller’s Ale House могут заполнять этот опрос только раз в 30 дней.Гости получат электронное письмо со специальным предложением о скидке 5 долларов на любую покупку ужина на 20 долларов. Это предложение не распространяется на специальные предложения, подарочные карты, алкоголь, налоги или чаевые. Это предложение нельзя комбинировать с другими предложениями, скидками или купонами. Надеемся вскоре вас увидеть.
Заявление о доступности ADA
Наш партнер по исследованиям, Service Management Group (SMG), стремится поддерживать удобный продукт, доступный для всех посетителей. В соответствии с этим обязательством SMG находится в процессе включения Руководства по доступности веб-контента (WCAG) в свой дизайн, где это возможно.Дополнительная информация о WCAG доступна по адресу: https://www.w3.org/TR/WCAG20/.
Наша цель — создать доступный опыт; Однако, это не всегда возможно. В некоторых ситуациях продукты SMG могут быть несовместимы с некоторыми адаптивными технологиями.
Хотя SMG стремится поддерживать доступность, проводя периодические обзоры своих продуктов, мы всегда открыты для пользовательского ввода. Если вы столкнетесь с проблемой доступности на одной из наших страниц, свяжитесь с нами по адресу ADAaccessibility @ smg.com. В своем сообщении, пожалуйста, укажите как можно больше подробностей, включая тип адаптивной технологии, которую вы используете, и конкретный аспект нашего сайта, который не работает.
Michigan Millers Insurance — определена как ваша любимая страховая компания
Филиал Michigan Millers, Western National, объявляет о предстоящем выходе на пенсию Стю Хендерсона, правопреемника Рика Лонга на посту генерального директора
Совет директоров Western National Mutual Insurance Company сегодня подтвердил предстоящий выход на пенсию Стю Хендерсон в качестве главного исполнительного директора, а также полный преемник нынешнего президента Ричарда (Рика) Лонга на должность президента и главного исполнительного директора для всех компаний Группы со 2 апреля 2021 г.Эти изменения завершат годичную смену руководства, начавшуюся в марте 2020 года.
Стю присоединился к Western National в 2001 году, когда собственный капитал компании упал до 60,3 миллиона долларов и его A.M. Рейтинг «Лучшая финансовая устойчивость» понижен до B +. Хендерсон организовал быстрый поворот, возобновляя приверженность компании системе Независимых агентств, широко диверсифицируя свои риски, и восстановление своей справедливости.За 20 лет работы в компании руководство Хендерсона в конечном итоге превратила Western National в надрегиональную группу из восьми действующих компаний по страхованию имущества и от несчастных случаев. выписывать более 800 миллионов долларов в год в виде личных и коммерческих премий, при этом профицит страхователей превышает 610 миллионов долларов и общие активы более 1,59 миллиарда долларов. После выхода на пенсию Хендерсон останется членом Совет директоров Western National.
Рик Лонг стал президентом Western National прошлой весной, когда в США появился COVID-19, и он постоянно и успешно провел компанию в неспокойном во всем мире 2020 году, который включал в себя широкомасштабную удаленную работу, премиум и другие программы помощи COVID и значительный сбой в работе наших систем. Рик впервые присоединился к Western National в 2010 году. в качестве старшего вице-президента по претензиям, а затем в 2017 году стал президентом Michigan Millers Insurance Company.Он входил в советы директоров всех 100% акций Western National, а также в Совет Исследовательского бюро по имущественным потерям и Ассоциации страховых гарантий Миннесоты. До прихода в Western National Рик занимал должность старшего вице-президента по претензиям в компании по страхованию от несчастных случаев на фермах. дойдя до этой должности с должности оценщика претензий на местах в 1984 году.У него есть степень бакалавра наук. в области делового администрирования от SUNY в Бингемтоне, штат Нью-Йорк, и получил обозначения AIC, CPCU и ARe. Переехав в Маунд, штат Миннесота, из Десять лет назад в Нью-Йорке Рик, наконец, привык к экстремальным погодным условиям Среднего Запада и полюбил жизнь на озере. его жена Лоис и их две собаки.
Мы поздравляем Стю с его предстоящим выходом на пенсию, и мы с нетерпением ждем лидерства Рика в роли генерального директора.