
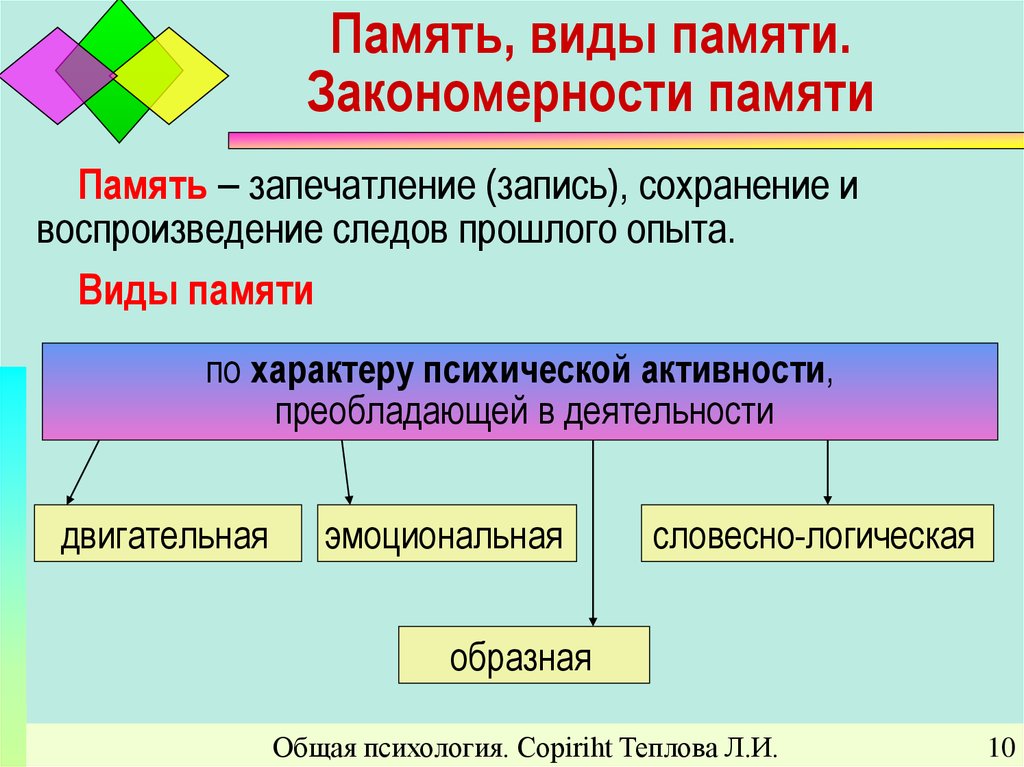
Память являющаяся хранилищем выполнения определенных действий: Планируют долго, но реализуют быстрее всех «Исследование урока»
Управление емкостью хранилища в Azure Stack Hub — Azure Stack Hub
- Статья
- Чтение занимает 22 мин
Эту статью можно использовать в качестве оператора облака Azure Stack Hub, чтобы узнать, как отслеживать емкость хранилища развертывания Azure Stack Hub и управлять ими. Инструкции можно использовать для понимания памяти, доступной для виртуальных машин пользователя. Инфраструктура хранилища Azure Stack Hub выделяет для развертывания Azure Stack Hub часть общей емкости хранилища в качестве служб хранения. Службы хранения сохраняют данные арендатора в общих ресурсах на томах, которые соответствуют узлам развертывания.
Как у оператора облака, у вас есть ограниченный объем хранилища для работы. Объем хранилища определяется реализуемым решением. Решение предоставляется поставщиком изготовителя оборудования при использовании решения с несколькими узлами или обеспечивается оборудованием, на котором устанавливается Пакет средств разработки Azure Stack (ASDK).
Azure Stack Hub поддерживает только расширение емкости хранилища путем добавления дополнительных узлов единиц масштабирования. Дополнительные сведения см. в статье о добавлении узлов единиц масштабирования в Azure Stack Hub. Добавление физических дисков на узлы не расширяет емкость хранилища.
Важно отслеживать доступное хранилище, чтобы обеспечить эффективное обслуживание операций. Когда остающаяся свободная емкость тома становится ограниченной, запланируйте управление доступным пространством, чтобы предотвратить нехватку емкости в общих ресурсах.
Ниже перечислены возможные варианты управления емкостью:
- освобождение емкости;
- миграция объектов хранилища.

Если том хранилища объекта используется на 100 %, служба хранения больше не используется для него. Чтобы получить помощь в восстановлении операций для этого тома, обратитесь в службу поддержки Майкрософт.
Общие сведения о дисках, контейнерах и томах
Пользователь клиента создает диски, большие двоичные объекты, таблицы и очереди в службах хранилища Azure Stack Hub. Эти данные клиента помещаются на томах поверх доступного хранилища.
Диски
Виртуальная машина хранит данные на виртуальных дисках и управляет ими. Каждая виртуальная машина начинается с диска ОС, созданного на основе образа Marketplace или частного образа. Виртуальная машина может подключить ноль или больше дисков данных. Существует два типа дисков, предлагаемых в Azure Stack:
Управляемые диски упрощают управление дисками виртуальных машин Azure IaaS. Они управляют учетными записями хранения, связанными с этими дисками. Вам нужно только выбрать размер диска, а Azure Stack Hub самостоятельно создаст диск и будет управлять им.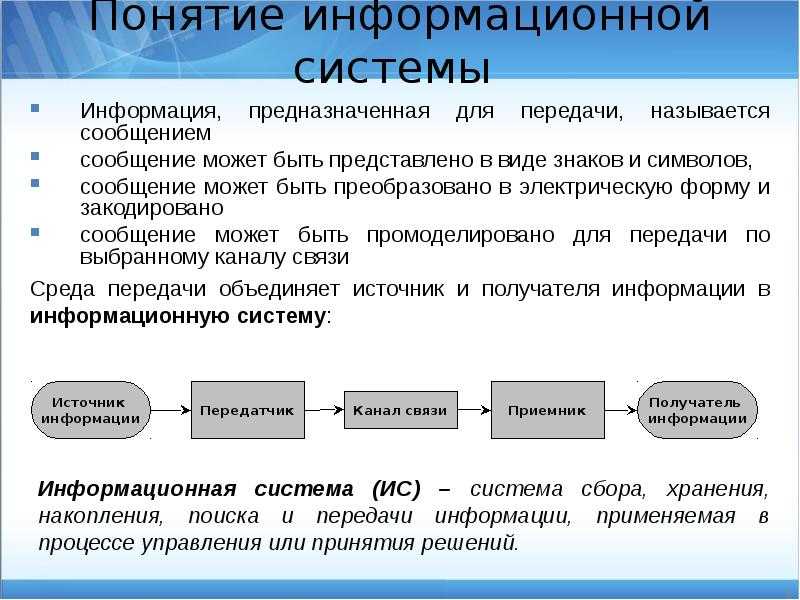
Неуправляемые диски — это VHD-файлы, которые хранятся в виде страничных BLOB-объектов в контейнерах хранилища в учетных записях хранения Azure Stack. Созданные клиентами страничные BLOB-объекты называются дисками виртуальной машины и хранятся в контейнерах в учетных записях хранения. Мы рекомендуем использовать неуправляемые диски только для виртуальных машин, которые должны быть совместимы со сторонними средствами, которые поддерживают только неуправляемые диски Azure.
Клиенты должны размещать каждый диск в отдельном контейнере для повышения производительности виртуальной машины.
- Каждый контейнер, хранящий диск виртуальной машины (страничный BLOB-объект), считается контейнером, подключенным к виртуальной машине, которой принадлежит диск.
- Контейнер, который не содержит дисков виртуальных машин, считается свободным контейнером.
Варианты освобождения места в подключенном контейнере ограничены. Дополнительные сведения см. в разделе Распределение неуправляемых дисков.
Дополнительные сведения см. в разделе Распределение неуправляемых дисков.
Важно!
Мы рекомендуем использовать только управляемые диски на виртуальных машинах для упрощения управления. Перед использованием управляемых дисков не нужно подготавливать учетные записи хранения и контейнеры. Управляемые диски обеспечивают эквивалентную или лучшую функциональность и производительность по сравнению с неуправляемыми дисками. Нет никаких преимуществ использования неуправляемых дисков, и они предоставляются только для обратной совместимости.
Управляемые диски оптимизированы для лучшего размещения в инфраструктуре хранилища и значительно сокращают затраты на управление. Но из-за тонкой подготовки управляемых дисков и окончательного использования непредсказуемого при создании, существуют возможности чрезмерного использования тома, вызванного несбалансированное размещение диска. Операторы отвечают за мониторинг использования емкости хранилища и избежать такой проблемы.
Для пользователей, использующих шаблоны ARM для подготовки новых виртуальных машин, используйте следующий документ, чтобы понять, как изменить шаблоны для использования управляемых дисков: используйте шаблоны управляемых дисков виртуальной машины.
Диски виртуальных машин хранятся в виде разреженных файлов в инфраструктуре хранилища. Диски подготовили размер, который пользователь запрашивает во время создания диска. Однако только ненулевые страницы, записанные на диск, занимают место в базовой инфраструктуре хранения.
Диски часто создаются путем копирования из образов платформы, управляемых образов, моментальных снимков или других дисков. Моментальные снимки создаются с дисков. Чтобы увеличить использование емкости хранилища и сократить время операции копирования, система использует блочное клонирование в ReFS. Клонирование BLOB-объектов — это операция с низкой стоимостью метаданных, а не полная копия байтов между файлами. Исходный файл и целевой файл могут совместно использовать одни и те же экстенты, идентичные данные не хранятся физически несколько раз, что повышает емкость хранилища.
Использование емкости увеличивается только при записи дисков и уменьшении идентичных данных.
При удалении образа или диска пространство может быть немедленно освобождено, так как на нем могут быть диски или моментальные снимки, которые по-прежнему сохраняют идентичные данные и занимают место.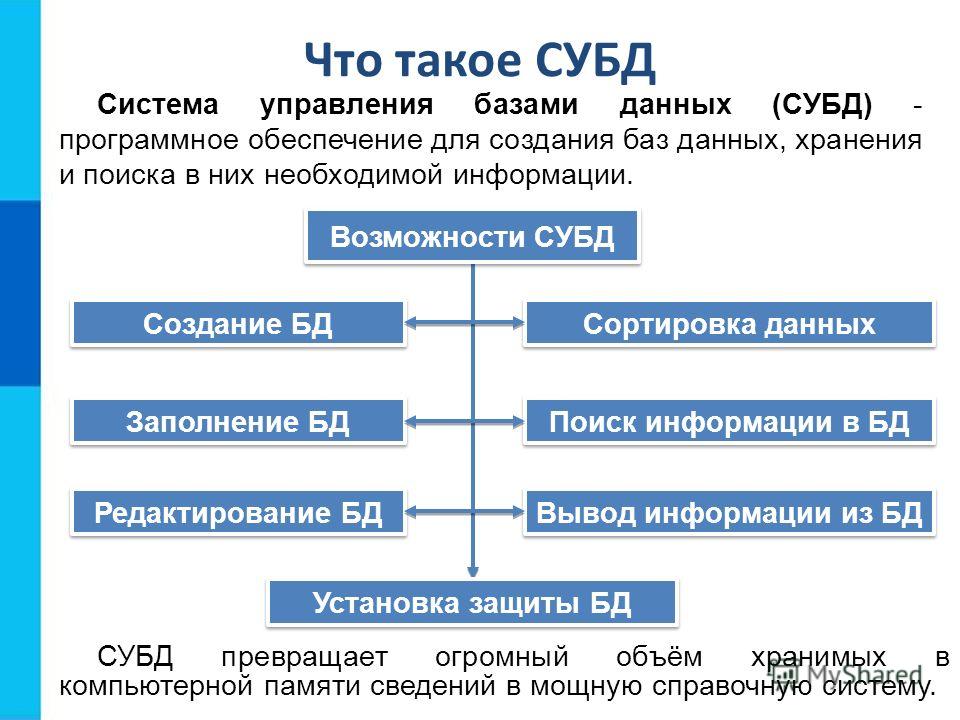 Только если все связанные сущности будут удалены, пространство становится доступным.
Только если все связанные сущности будут удалены, пространство становится доступным.
Большие двоичные объекты и контейнеры
Пользователи клиента хранят большие объемы неструктурированных данных с помощью БОЛЬШОго двоичного объекта Azure. Azure Stack Hub поддерживает три типа больших двоичных объектов: блочные BLOB-объекты, добавочные BLOB-объекты и страничные BLOB-объекты. Дополнительные сведения о различных больших двоичных объектах см. в статье Understanding Block Blobs, Append Blobs, and Page Blobs (Основные сведения о блочных, добавочных и страничных BLOB-объектах).
Пользователи клиента создают контейнеры, которые затем используются для хранения данных больших двоичных объектов. Хотя пользователь решает, в каком контейнере размещать большие двоичные объекты, служба хранения использует специальный алгоритм, чтобы определить, в каком томе разместить контейнер. Алгоритм обычно выбирает том с наибольшим количеством свободного места.
Большой двоичный объект после размещения в контейнере может увеличиться и занимать больше места. По мере добавления новых больших двоичных объектов и увеличения имеющихся доступное пространство в томе, который содержит этот контейнер, уменьшается.
По мере добавления новых больших двоичных объектов и увеличения имеющихся доступное пространство в томе, который содержит этот контейнер, уменьшается.
Контейнеры не ограничены одним томом. Когда объединенные данные большого двоичного объекта в контейнере растут и используют 80 % свободного места и более, контейнер переходит в режим переполнения. В режиме переполнения все большие двоичные объекты, созданные в этом контейнере, выделяются на другой том, где есть достаточно места. Со временем контейнер в режиме переполнения сможет иметь большие двоичные объекты, распределенные между несколькими томами.
Если используется 90 % (а затем 95 %) доступного пространства в томе, система создает оповещения на портале администрирования Azure Stack Hub. Операторам облака необходимо просмотреть доступную емкость хранилища и запланировать перераспределение содержимого. Служба хранения перестает работать, когда диск используется на 100 %. Никакие дополнительные оповещения не поступают.
Тома
Служба хранения разделяет доступное хранилище на отдельные тома, которые выделены для хранения данных клиента и системы. Тома объединяют диски в пул хранения, чтобы обеспечить отказоустойчивость, масштабируемость и производительность локальных дисковых пространств. Дополнительные сведения о томах в Azure Stack Hub см. в статье Управление инфраструктурой хранилища для Azure Stack Hub.
Тома хранилища объектов хранят данные арендатора. К данным клиента относятся страничные BLOB-объекты, блочные BLOB-объекты, добавочные большие двоичные объекты, таблицы, очереди, базы данных и связанные хранилища метаданных. Количество томов хранилища объектов равно количеству узлов в развертывании Azure Stack Hub:
- В развертывании с четырьмя узлами находятся четыре тома хранилища объектов. В развертывании с несколькими узлами количество томов не уменьшается, если узел удален или неисправен.
- При использовании ASDK существует один том с одной общей папкой.

Тома хранилища объектов предназначены для эксклюзивного использования служб хранилища. Не следует изменять, добавлять или удалять файлы напрямую в томах. Только службы хранения должны работать с файлами, хранящимися в этих томах.
Так как объекты хранилища (BLOB-объекты и т. д.) содержатся в одном томе по отдельности, максимальный размер каждого объекта не может превышать размер тома. Максимальный размер новых объектов зависит от емкости, которая остается в томе в качестве неиспользуемого пространства при создании нового объекта.
Если в томе хранилища объектов недостаточно свободного пространства, а вам не удалось освободить место или этот вариант недоступен, оператор облака Azure Stack Hub может перенести объекты хранилища из одного тома в другой.
См. дополнительные сведения о том, как пользователи клиента взаимодействуют с хранилищем BLOB-объектов в Azure Stack Hub.
Мониторинг хранилища
Используйте Azure PowerShell или портал администратора для отслеживания общих ресурсов, чтобы знать, когда свободное пространство ограничено. При использовании портала можно получать оповещения об общих ресурсах, в которых мало места.
При использовании портала можно получать оповещения об общих ресурсах, в которых мало места.
Использование PowerShell
Оператор облака может отслеживать емкость хранилища в общем ресурсе с помощью командлета PowerShell Get-AzsStorageShare. Этот командлет возвращает общее, выделенное и свободное место в байтах для каждого общего ресурса.
- Общая емкость. Это общая емкость в байтах, доступная в общем ресурсе. Это пространство используется для данных и метаданных, обрабатываемых службами хранения.
- Используемая емкость. Это объем данных в байтах, используемый всеми экстентами из файлов, в которых хранятся данные клиента и связанные метаданные.
Использование портала администрирования
Облачный оператор может использовать портал администрирования для просмотра емкости всех общих ресурсов.
Войдите на портал администрирования:
https://adminportal.local.azurestack.external.
Выберите «Все службы> служба хранилища Файлы«>, чтобы открыть список общих папок, где можно просмотреть сведения об использовании.
- Total: Это общая емкость в байтах, доступная в общем ресурсе. Это пространство используется для данных и метаданных, обрабатываемых службами хранения.
- Используется. Это объем данных в байтах, используемый всеми экстентами из файлов, в которых хранятся данные клиента и связанные метаданные.
Используйте Azure PowerShell или портал администрирования для мониторинга подготовленной и используемой емкости и планирования миграции, чтобы обеспечить непрерывную нормальную работу системы.
Существует три средства мониторинга емкости томов:
- Портал и PowerShell для текущей емкости тома.
- служба хранилища оповещения о пространстве.
- Метрики емкости тома.
В этом разделе мы рассмотрим, как использовать эти средства для мониторинга емкости системы.
Использование PowerShell
Get-AzsVolume. Этот командлет возвращает объем общего и свободного пространства в гигабайтах (ГБ) для каждого тома.- Общая емкость: Общее пространство в ГБ, доступное в общей папке. Это пространство используется для данных и метаданных, обрабатываемых службами хранения.
- Оставшаяся емкость: Объем свободного места в ГБ для хранения данных клиента и связанных метаданных.
Использование портала администрирования
Как оператор облака вы можете использовать портал администрирования для просмотра емкости всех томов.
Войдите на портал администрирования Azure Stack Hub (
https://adminportal.local.azurestack.external).Выберите все службы>служба хранилища>Volumes, чтобы открыть список томов, где можно просмотреть сведения об использовании.

- Total: Общее доступное пространство в томе. Это пространство используется для данных и метаданных, обрабатываемых службами хранения.
- Используется. Объем данных, используемый всеми экстентами из файлов, в которых хранятся данные арендатора и связанные метаданные.
Оповещения о дисковом пространстве
Если вы используете портал администрирования, вы получаете оповещения о томах, в которых мало свободного пространства.
Важно!
Оператору облака следует предотвращать полное использование емкости общих ресурсов. Если общий ресурс используется полностью, служба хранения больше не функционирует для него. Чтобы освободить пространство и восстановить операции в общем ресурсе, который используется на 100 %, обратитесь в службу поддержки Майкрософт.
Предупреждение. Если общая папка используется более чем на 90 %, вы получите предупреждение на портале администрирования:
Критическое: если общая папка используется более чем на 95 %, на портале администрирования появится критическое оповещение:
Просмотр сведений.
 На портале администрирования можно открыть сведения об оповещении, чтобы просмотреть варианты устранения его причины.
На портале администрирования можно открыть сведения об оповещении, чтобы просмотреть варианты устранения его причины.
Метрики емкости тома
Метрики емкости тома предоставляют более подробные сведения о подготовленной емкости и используемой емкости для различных типов объектов. Данные метрик сохраняются в течение 30 дней. Служба фонового мониторинга обновляет данные метрик емкости тома почасово.
Необходимо понять использование ресурсов тома, проверив отчет о метриках емкости. Оператор облака может проанализировать распределение типов ресурсов, когда том приближается к полному выбору соответствующего действия для свободного места. Оператор также может предотвратить превышение использования тома, если размер подготовленного диска указывает, что том слишком много подготовлен.
Azure Monitor предоставляет следующие метрики для отображения использования емкости тома:
- Общая емкость тома показывает общую емкость хранилища тома.

- Оставшаяся емкость тома показывает оставшуюся емкость хранилища тома.
- Емкость используемого диска виртуальной машины тома показывает общее количество дисковых пространств, занятых объектами, связанными с диском виртуальной машины (включая страничные BLOB-объекты, управляемые диски и моментальные снимки, управляемые образы и образы платформы). Базовый VHD-файл дисков виртуальных машин может совместно использовать один и тот же экстент (ссылаться на диски) с образами, моментальными снимками или другими дисками. Это число может быть меньше суммы используемой емкости всех объектов, связанных с диском виртуальной машины.
- Общая используемая емкость тома — это общий размер объектов, отличных от дисков, включая блочные BLOB-объекты, добавочные BLOB-объекты, таблицы, очереди и метаданные BLOB-объектов.
- Емкость подготовленного диска виртуальной машины тома — это общий размер страничных BLOB-объектов и управляемых дисков и моментальных снимков.
 Этот размер является максимальным значением общей емкости диска всех управляемых дисков и страничных BLOB-объектов на определенном томе.
Этот размер является максимальным значением общей емкости диска всех управляемых дисков и страничных BLOB-объектов на определенном томе.
Чтобы просмотреть метрики емкости томов в Azure Monitor, выполните приведенные далее действия.
Проверьте, установлена и настроена ли среда Azure PowerShell. Инструкции по настройке среды PowerShell приведены в статье Установка PowerShell для Azure Stack Hub. Сведения о том, как войти в Azure Stack Hub, см. в статье Подключение к Azure Stack с помощью PowerShell.
Скачайте средства Azure Stack Hub из репозитория GitHub. Подробные инструкции см. в статье «Скачивание средств Azure Stack Hub» из GitHub.
Создайте json панели мониторинга емкости, запустив DashboardGenerator в разделе CapacityManagement.
.\CapacityManagement\DashboardGenerator\Create-AzSStorageDashboard.ps1 -capacityOnly $true -volumeType object
В папке DashboardGenerator будет создан JSON-файл с именем DashboardVolumeObjStore .

Войдите на портал администрирования Azure Stack Hub (
https://adminportal.local.azurestack.external).На странице панели мониторинга нажмите кнопку «Отправить» и выберите json-файл, созданный на шаге 3.
После отправки json вы будете перенаправлены на новую панель мониторинга емкости. Каждый том имеет соответствующую диаграмму на панели мониторинга. Количество диаграмм, равное количеству томов:
Щелкнув один из томов, можно проверить пять метрик емкости конкретного тома на подробной диаграмме:
Шаблоны использования томов
Проверив метрики емкости тома, оператор облака понимает, сколько используется емкость тома и какой тип ресурсов занимает большую часть использования пространства. Шаблон использования пространства можно сгруппировать в следующие типы, оператор которого должен выполнять разные действия для каждого типа:
Недостаточно подготовленная резервная емкость: на томе достаточно доступной емкости, а общая подготовленная емкость всех дисков, расположенных на этом томе, меньше общей доступной емкости.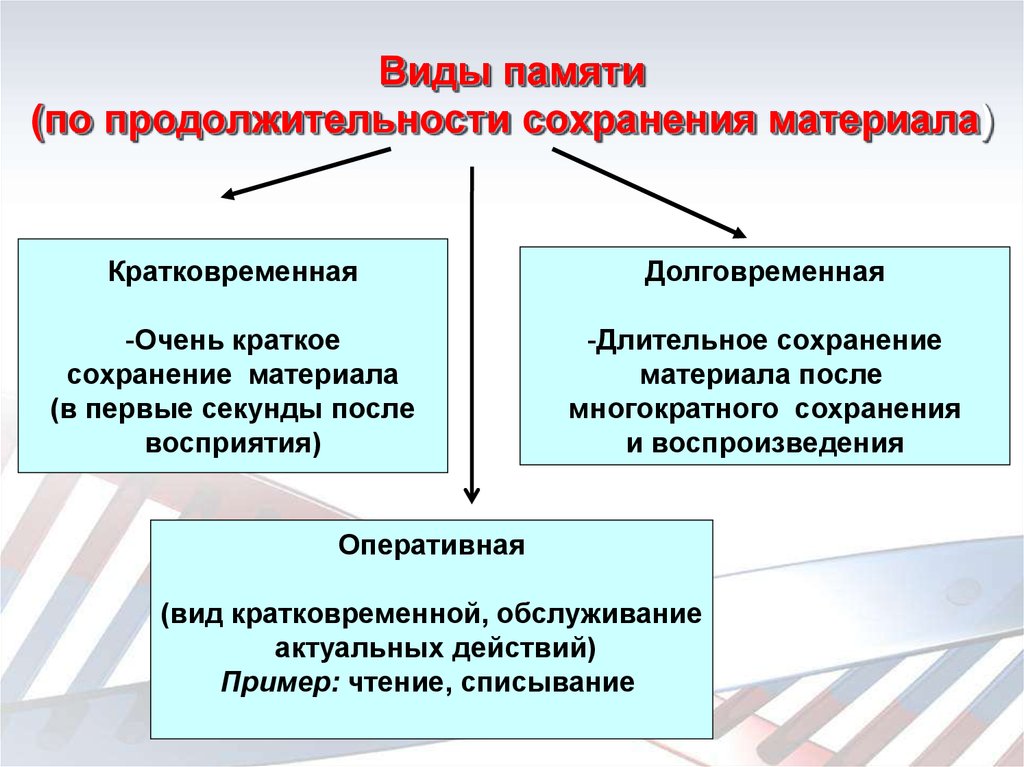 Том доступен для дополнительных объектов хранилища, включая диски и другие объекты (блочные и добавочные BLOB-объекты, таблицы и очереди). Для работы тома не нужно предпринимать никаких действий.
Том доступен для дополнительных объектов хранилища, включая диски и другие объекты (блочные и добавочные BLOB-объекты, таблицы и очереди). Для работы тома не нужно предпринимать никаких действий.
Чрезмерно подготовленная резервная емкость: оставшаяся емкость тома высока, но подготовленная емкость диска виртуальной машины уже превышает общую емкость тома. Этот том по-прежнему имеет место для большего количества объектов хранилища. Однако он может быть заполнен данными на дисках виртуальных машин, расположенных на этом томе. Следует внимательно следить за тенденцией использования этого тома. Если он изменится на слишком подготовленный шаблон с низкой емкостью, может потребоваться принять меры, чтобы освободить место.
Недостаточно подготовленной, низкой емкости: оставшаяся емкость тома низкая, и как подготовленная емкость диска виртуальной машины, так и используемая емкость диска виртуальной машины высока.
Низкая оставшаяся емкость указывает, что объем достигает полного использования. Операторы должны принять немедленные меры, чтобы освободить место, чтобы предотвратить использование тома 100 %, что заблокировало службу хранилища. Высокая используемая емкость диска виртуальной машины показывает, что большая часть использования тома — это диски виртуальных машин. Обратитесь к инструкциям по переносу дисков с полного тома на другие доступные тома для свободного места.
Операторы должны принять немедленные меры, чтобы освободить место, чтобы предотвратить использование тома 100 %, что заблокировало службу хранилища. Высокая используемая емкость диска виртуальной машины показывает, что большая часть использования тома — это диски виртуальных машин. Обратитесь к инструкциям по переносу дисков с полного тома на другие доступные тома для свободного места.
Недостаточно подготовленная, низкая емкость, большие блочные BLOB-объекты: оставшаяся емкость тома низкая, и как подготовленная емкость диска виртуальной машины, так и используемая емкость диска виртуальной машины низкая, но другая используемая емкость высока.
Объем имеет риск полного использования, что оператор должен принять немедленные меры для освобождения места. Высокая другая используемая емкость указывает, что большая часть емкости тома принимается блочных и добавочных BLOB-объектов или таблиц или очередей. Если доступная емкость тома меньше 20 %, переполнение контейнера будет включено, а новый объект большого двоичного объекта не будет помещен на этот почти полный том. Но существующие большие двоичные объекты все еще могут расти. Чтобы предотвратить чрезмерное использование емкости постоянно растущих больших двоичных объектов, можно обратиться к служба поддержки Майкрософт, чтобы запросить контейнеры, занимающие место на определенном томе, и решить, нужно ли очистить эти контейнеры клиентами, чтобы освободить место.
Но существующие большие двоичные объекты все еще могут расти. Чтобы предотвратить чрезмерное использование емкости постоянно растущих больших двоичных объектов, можно обратиться к служба поддержки Майкрософт, чтобы запросить контейнеры, занимающие место на определенном томе, и решить, нужно ли очистить эти контейнеры клиентами, чтобы освободить место.
Недостаточно подготовленных, низких емкостей, больших блочных BLOB-объектов: оставшаяся емкость тома низка, а используемая или подготовленная емкость диска и другая используемая емкость высока. Этот том имеет высокую загрузку места как дисками, так и другими объектами хранилища. Вы должны освободить место, чтобы избежать полного заполнения тома. Сначала рекомендуется выполнить инструкции по переносу дисков с полного тома на другие доступные тома. В других случаях вы можете обратиться к служба поддержки Майкрософт, чтобы запросить контейнеры, занимающие место на определенном томе, и решить, нужно ли очистить эти контейнеры клиентами, чтобы освободить место.
Управление доступным местом
Когда необходимо освободить пространство в томе, сначала используйте наименее агрессивные методы. Например, попробуйте освободить пространство, прежде чем переносить управляемый диск.
Освобождение емкости
Можно освободить емкость, используемую учетными записями арендатора, которые были удалены. Эта емкость автоматически освобождается при истечении срока хранения данных (или же вы можете немедленно освободить ее).
Дополнительные сведения см. в подразделе «Освобождение емкости» раздела Управление учетными записями хранения Azure Stack Hub.
Перенос контейнера между томами
Этот параметр применяется только к интегрированным системам Azure Stack Hub.
Из-за шаблонов использования клиентами некоторые клиентские общие ресурсы используют больше места, чем другие. В результате в одних общих ресурсах может заканчиваться свободное пространство, тогда как другие общие ресурсы практически не используются.
Можно попробовать освободить место в общих ресурсах с большой нагрузкой вручную, перенеся некоторые контейнеры больших двоичных объектов в другой общий ресурс. Несколько контейнеров меньшего размера можно перенести в один общий ресурс, где достаточно места, чтобы хранить их все. Используйте миграцию для перемещения свободных контейнеров. Свободные контейнеры — это контейнеры, которые не содержат диски виртуальных машин.
Несколько контейнеров меньшего размера можно перенести в один общий ресурс, где достаточно места, чтобы хранить их все. Используйте миграцию для перемещения свободных контейнеров. Свободные контейнеры — это контейнеры, которые не содержат диски виртуальных машин.
Миграция объединяет все большие двоичные объекты контейнера в новом общем ресурсе.
Если контейнер вошел в режим переполнения и разместил большие двоичные объекты на других томах, новая общая папка должна иметь достаточную емкость для хранения всех больших двоичных объектов, принадлежащих переносимому контейнеру, включая переполненные большие двоичные объекты.
Командлет PowerShell
Get-AzsStorageContainerопределяет только пространство, используемое в изначальном томе контейнера. Командлет не определяет пространство, используемое большими двоичными объектами, которые переполнены на дополнительные тома. Поэтому полный размер контейнера может быть не очевиден. Консолидация контейнера в новом общем ресурсе может вызвать состояние переполнения ресурса, и данные будут помещаться в дополнительные общие ресурсы. В результате может потребоваться повторно перераспределить общие ресурсы.
В результате может потребоваться повторно перераспределить общие ресурсы.Если разрешения на использование определенных групп ресурсов отсутствуют и вы не можете использовать PowerShell, чтобы запросить дополнительные тома для избытка данных, обратитесь к владельцу этих групп ресурсов и контейнеров, чтобы оценить общий объем данных для переноса, прежде чем переносить их.
Важно!
Перенос больших двоичных объектов для контейнера является автономной операцией, требующей использования PowerShell. До завершения переноса все большие двоичные объекты для переносимого контейнера остаются вне сети и не могут использоваться. Также не следует обновлять Azure Stack Hub до завершения всей текущей миграции.
Перенос контейнеров с помощью PowerShell
Проверьте, установлена и настроена ли среда Azure PowerShell. Дополнительные сведения см. в разделе Управление ресурсами Azure с помощью Azure PowerShell.
Изучите контейнер, чтобы понять, какие данные находятся в общем ресурсе, который планируется перенести.
 Чтобы определить наиболее подходящие для переноса контейнеры в томе, используйте командлет
Чтобы определить наиболее подходящие для переноса контейнеры в томе, используйте командлет Get-AzsStorageContainer.$farm_name = (Get-AzsStorageFarm)[0].name $shares = Get-AzsStorageShare -FarmName $farm_name $containers = Get-AzsStorageContainer -ShareName $shares[0].ShareName -FarmName $farm_name
Затем проверьте значение $containers:
$containers
Определите наиболее подходящие общие ресурсы назначения для хранения контейнера, который переносится.
$destinationshare = ($shares | Sort-Object FreeCapacity -Descending)[0]
Затем проверьте значение $destinationshares:
$destinationshares
Запустите перенос контейнера. Перенос выполняется асинхронно. Если вы начинаете миграцию другого контейнера до завершения первой миграции, используйте идентификатор задания для отслеживания состояния каждого из них.
$job_id = Start-AzsStorageContainerMigration -StorageAccountName $containers[0].
 Accountname -ContainerName $containers[0].Containername -ShareName $containers[0].Sharename -DestinationShareUncPath $destinationshares[0].UncPath -FarmName $farm_name
Accountname -ContainerName $containers[0].Containername -ShareName $containers[0].Sharename -DestinationShareUncPath $destinationshares[0].UncPath -FarmName $farm_name
Затем проверьте значение $jobId. В следующем примере замените d62f8f7a-8b46-4f59-a8aa-5db96db4ebb0 идентификатором задания, которое нужно просмотреть:
$jobId d62f8f7a-8b46-4f59-a8aa-5db96db4ebb0
Используйте идентификатор задания, чтобы проверить состояние задания переноса. По завершении переноса параметру MigrationStatus присваивается значение Complete.
Get-AzsStorageContainerMigrationStatus -JobId $job_id -FarmName $farm_name
Вы можете отменить выполняющиеся задания переноса. Отмененные задания переноса обрабатываются асинхронно. Отслеживать отмену можно с помощью $jobid.
Stop-AzsStorageContainerMigration -JobId $job_id -FarmName $farm_name
Вы можете выполнить команду из шага 6 еще раз, пока состояние задания переноса не получит значение Canceled (Отменено).
Перемещение дисков виртуальной машины
Этот параметр применяется только к интегрированным системам Azure Stack Hub.
Самый крайний способ управления пространством заключается в перемещении дисков виртуальной машины. Так как перемещение вложенного контейнера (содержащего диск виртуальной машины) является сложной задачей, обратитесь в службу поддержки Майкрософт, чтобы выполнить это действие.
Миграция управляемого диска между томами
Этот параметр применяется только к интегрированным системам Azure Stack Hub.
Из-за шаблонов использования арендаторов некоторые тома арендаторов используют больше пространства, чем другие. Результатом может быть том, который выполняется с низким пространством до относительно неиспользуемых других томов.
Вы можете освободить пространство в томе с большой нагрузкой, вручную перенеся некоторые управляемые диски в другой том. Несколько управляемых дисков можно перенести в один том, где достаточно пространства, чтобы хранить их все. Для перемещения автономных управляемых дисков используйте миграцию. Автономные управляемые диски — это диски, которые не подключены к виртуальной машине.
Для перемещения автономных управляемых дисков используйте миграцию. Автономные управляемые диски — это диски, которые не подключены к виртуальной машине.
Важно!
Миграция управляемых дисков — это автономная операция, для выполнения которой нужно использовать PowerShell. Перед запуском задания миграции необходимо освободить виртуальные машины владельца диска-кандидата или отключить их для миграции с виртуальной машины владельца (после завершения задания миграции можно перераспределить виртуальные машины или повторно подключить диски). Пока миграция не завершится, все управляемые диски, которые вы переносите, должны оставаться зарезервированными или автономными и не могут использоваться, в противном случае задание миграции прервется, а все неигрированные диски по-прежнему находятся на исходных томах. Также не следует обновлять Azure Stack Hub до завершения всей текущей миграции.
Миграция управляемых дисков с помощью PowerShell
Проверьте, установлена и настроена ли среда Azure PowerShell.
 Инструкции по настройке среды PowerShell приведены в статье Установка PowerShell для Azure Stack Hub. Сведения о том, как войти в Azure Stack Hub, см. в статье Подключение к Azure Stack с помощью PowerShell.
Инструкции по настройке среды PowerShell приведены в статье Установка PowerShell для Azure Stack Hub. Сведения о том, как войти в Azure Stack Hub, см. в статье Подключение к Azure Stack с помощью PowerShell.Проверьте управляемые диски, чтобы понять, какие из них находятся в томе, который вы планируете перенести. Чтобы определить наиболее подходящие для переноса диски в томе, используйте командлет
Get-AzsDisk.$ScaleUnit = (Get-AzsScaleUnit)[0] $StorageSubSystem = (Get-AzsStorageSubSystem -ScaleUnit $ScaleUnit.Name)[0] $Volumes = (Get-AzsVolume -ScaleUnit $ScaleUnit.Name -StorageSubSystem $StorageSubSystem.Name | Where-Object {$_.VolumeLabel -Like "ObjStore_*"}) $SourceVolume = ($Volumes | Sort-Object RemainingCapacityGB)[0] $VolumeName = $SourceVolume.Name.Split("/")[2] $VolumeName = $VolumeName.Substring($VolumeName.IndexOf(".")+1) $MigrationSource = "\\SU1FileServer."+$VolumeName+"\SU1_"+$SourceVolume.VolumeLabel $Disks = Get-AzsDisk -Status OfflineMigration -SharePath $MigrationSource | Select-Object -First 10Затем проверьте значение $disks.
$Disks
Определите наиболее подходящие целевые тома для хранения переносимых дисков.
$DestinationVolume = ($Volumes | Sort-Object RemainingCapacityGB -Descending)[0] $VolumeName = $DestinationVolume.Name.Split("/")[2] $VolumeName = $VolumeName.Substring($VolumeName.IndexOf(".")+1) $MigrationTarget = "\\SU1FileServer."+$VolumeName+"\SU1_"+$DestinationVolume.VolumeLabelНачните миграцию управляемых дисков. Перенос выполняется асинхронно. Если вы начнете миграцию других дисков до завершения первой миграции, используйте имя задания для отслеживания состояния каждого из них.
$jobName = "MigratingDisk" Start-AzsDiskMigrationJob -Disks $Disks -TargetShare $MigrationTarget -Name $jobName
Используйте имя задания, чтобы проверить состояние задания миграции. По завершении миграции диска состояние MigrationStatus отобразится как Complete.
$job = Get-AzsDiskMigrationJob -Name $jobName
Если в одном задании миграции выполняется миграция нескольких управляемых дисков, можно также проверить подзадачи задания.
$job.Subtasks
Вы можете отменить выполняющиеся задания переноса. Отмененные задания переноса обрабатываются асинхронно. Вы можете отслеживать отмену по имени задания, пока состояние задания миграции не отобразится как Canceled.
Stop-AzsDiskMigrationJob -Name $jobName
Распределение неуправляемых дисков
Этот параметр применяется только к интегрированным системам Azure Stack Hub.
Самый агрессивный способ управления пространством предусматривает перемещение неуправляемых дисков. Если клиент добавляет число неуправляемых дисков в один контейнер, общая используемая емкость контейнера может превысить доступную емкость тома, который содержит его до того, как контейнер входит в режим переполнения . Чтобы избежать ситуации, когда из-за одного контейнера пространство в томе заканчивается, арендатор может распределить существующие неуправляемые диски из одного контейнера в другие контейнеры. Так как распределение подключенного контейнера (содержащего диск виртуальной машины) является сложной задачей, обратитесь в службу поддержки Майкрософт, чтобы выполнить это действие.
Так как распределение подключенного контейнера (содержащего диск виртуальной машины) является сложной задачей, обратитесь в службу поддержки Майкрософт, чтобы выполнить это действие.
Память, доступная для виртуальных машин
Azure Stack Hub создается как гиперконвергентный кластер вычислительных ресурсов и хранилища. Конвергенция позволяет совместно использовать оборудование, которое называется единицей масштабирования. В Azure Stack Hub единицы масштабирования обеспечивают доступность и масштабируемость ресурсов. Единица масштабирования состоит из набора серверов Azure Stack Hub, называемых узлами или узлами. Программное обеспечение инфраструктуры размещается в наборе виртуальных машин на тех же физических серверах, что и виртуальные машины клиента. Управление всеми виртуальными машинами Azure Stack Hub осуществляется с помощью технологий кластеризации серверов Windows единиц масштабирования и отдельных экземпляров Hyper-V. Использование единиц масштабирования упрощает получение и администрирование ресурсов Azure Stack Hub. Единица масштабирования также обеспечивает перемещение и масштабируемость всех служб в Azure Stack Hub, клиенте и инфраструктуре.
Единица масштабирования также обеспечивает перемещение и масштабируемость всех служб в Azure Stack Hub, клиенте и инфраструктуре.
Вы можете просмотреть круговую диаграмму на портале администрирования, где отображается свободная и используемая память в Azure Stack Hub, как показано ниже:
Следующие компоненты используют память в используемом разделе круговой диаграммы:
- Использование ос узла или резервирование Это память, используемая операционной системой (ОС) на узле, таблицами страниц виртуальной памяти, процессами, выполняющимися в ОС узла, и кэшем прямой памяти пробелов. Так как это значение зависит от памяти, используемой другими работающими на узле процессами Hyper-V, оно может меняться.
- Службы инфраструктуры Это виртуальные машины инфраструктуры, составляющие Azure Stack Hub. Это влечет за собой приблизительно 31 виртуальные машины, которые занимают 242 ГБ + (4 ГБ x число узлов) памяти. Объем памяти, используемый компонентом служб инфраструктуры, может измениться, так как мы работаем над улучшением масштабируемости и устойчивости служб инфраструктуры.
- Резерв устойчивости Azure Stack Hub резервирует часть памяти, чтобы обеспечить доступность клиента во время сбоя одного узла, а также во время исправления и обновления, чтобы обеспечить успешную динамическую миграцию виртуальных машин.
- Виртуальные машины клиента Это виртуальные машины, созданные пользователями Azure Stack Hub. Наряду с работающими виртуальными машинами память также потребляют виртуальные машины, которые работают в структуре. Это означает, что виртуальные машины, которые находятся в состоянии Создание или Сбой, либо работа которых завершена из гостевой ОС, также будут потреблять памяти. Однако виртуальные машины, которые были освобождены с помощью варианта прекращения освобождения, с пользовательского портала Azure Stack Hub, PowerShell и Azure CLI не будут использовать память из Azure Stack Hub.
- Поставщики ресурсов надстройки Виртуальные машины, развернутые для поставщиков ресурсов надстройки, таких как SQL, MySQL и Служба приложений.
Доступная память для размещения виртуальной машины
Как оператор облака для Azure Stack Hub не существует автоматизированного способа проверки выделенной памяти для каждой виртуальной машины. Вы можете получить доступ к виртуальным машинам пользователей и вычислить выделенную память вручную. Однако выделенная память не будет отражать реальное использование. Это значение может быть меньше выделенного значения.
Для тренировки доступной памяти для виртуальных машин используется следующая формула:
Доступная память для размещения виртуальной машины = Total Host Memory--Resiliency Reserve--Memory used by running tenant VMs - Azure Stack Hub Infrastructure Overhead
Резерв устойчивости = H + R * ((N-1) * H) + V * (N-2)
Где:
H = размер памяти с одним узлом
N = размер единицы масштабирования (количество узлов)
R = резервная или память операционной системы, используемая ОС узла, которая в этой формуле имеет значение 15.
V = самая большая виртуальная машина (мудрая память) в единице масштабирования
Затраты на инфраструктуру Azure Stack Hub = 242 ГБ + (4 ГБ x # узлов). Эти учетные записи для примерно 31 виртуальных машин используются для размещения инфраструктуры Azure Stack Hub.
Память, используемая ОС узла = 15 процентов (0,15) памяти узла. Резервное значение операционной системы — это оценка и зависит от физической емкости памяти узла и общих затрат на операционную систему.
Значение V, крупнейшая виртуальная машина в единице масштабирования, динамически основана на развернутой виртуальной машине самого большого клиента. Например, это значение может быть равно 7 ГБ, 112 ГБ или соответствовать другому размеру памяти виртуальной машины, поддерживаемому решением Azure Stack Hub. Мы выбрали размер самой крупной виртуальной машины, чтобы иметь достаточно памяти, чтобы динамическая миграция этой крупной виртуальной машины не завершилась ошибкой. Изменение самой большой виртуальной машины в структуре Azure Stack приведет к увеличению резерва для устойчивости, а также увеличению объема памяти самой виртуальной машины.
Изменение самой большой виртуальной машины в структуре Azure Stack приведет к увеличению резерва для устойчивости, а также увеличению объема памяти самой виртуальной машины.
Например, с единицей масштабирования 12 узлов:
| Сведения о метки | Значения |
|---|---|
| sts (N) | 12 |
| Память на узел (H) | 384 |
| Общая память единицы масштабирования | 4608 |
| Резерв ОС (R) | 15 % |
| Самая большая виртуальная машина (V) | 112 |
| Резерв устойчивости = | H + R * ((N-1) * H) + V * (N-2) |
| Резерв устойчивости = | 2137.6 |
Таким образом, используя приведенные выше сведения, можно вычислить, что Azure Stack с 12 узлами размером 384 ГБ на узел (всего 4608 ГБ) имеет 2137 ГБ, зарезервированных для обеспечения устойчивости, если самая большая виртуальная машина имеет 112 ГБ памяти.
Когда вы обратитесь к колонке емкости для физической памяти, как показано ниже, используемое значение включает резерв устойчивости. Граф находится из четырех узлов экземпляра Azure Stack Hub.
Граф находится из четырех узлов экземпляра Azure Stack Hub.
При планировании емкости Для Azure Stack Hub учитывайте эти рекомендации. Кроме того, можно использовать планировщик емкости Azure Stack Hub.
Дальнейшие действия
Дополнительные сведения о предложениях виртуальных машин для пользователей см. в статье Управление емкостью хранилища для Azure Stack Hub.
Что такое кэширование и как оно работает | AWS
Узнайте о различных отраслях и примерах использования кэширования
Мобильные технологии
Мобильные приложения – это сегмент рынка, который растет с невообразимой скоростью, учитывая быстрое освоение устройств потребителем и спад в использовании традиционного компьютерного оборудования. Практически для каждого сегмента на рынке, будь то игры, коммерческие приложения, медицинские программы и т. д., есть приложения с поддержкой мобильных устройств. С точки зрения разработки создание мобильных приложений очень похоже на создание любых других приложений. Вы сталкиваетесь с теми же вопросами на уровнях представления, бизнеса и данных. Несмотря на разницу в пространстве экрана и инструментах для разработчиков, общей целью является обеспечение качественного взаимодействия с клиентом. Благодаря эффективным стратегиям кэширования ваши мобильные приложения могут обеспечивать такой уровень производительности, которого ожидают ваши пользователи, масштабироваться до любых размеров и сокращать общие затраты.
Вы сталкиваетесь с теми же вопросами на уровнях представления, бизнеса и данных. Несмотря на разницу в пространстве экрана и инструментах для разработчиков, общей целью является обеспечение качественного взаимодействия с клиентом. Благодаря эффективным стратегиям кэширования ваши мобильные приложения могут обеспечивать такой уровень производительности, которого ожидают ваши пользователи, масштабироваться до любых размеров и сокращать общие затраты.
AWS Mobile Hub – это объединенная консоль для удобного поиска, настройки и использования облачных сервисов AWS, предназначенных для разработки и тестирования мобильных приложений, а также мониторинга их использования.
Интернет вещей (IoT)
Интернет вещей – это концепция сбора информации с устройств и из физического мира с помощью датчиков и ее передачи в Интернет или в приложения, которые принимают эти данные. Ценность IoT заключается в способности понимать собранные данные в режиме, близком к реальному времени, что в конечном счете позволяет системе и приложениям, принимающим эти данные, быстро реагировать на них. Возьмем, к примеру, устройство, которое передает свои GPS-координаты. Ваше приложение IoT может предложить интересные места, которые находятся поблизости от этих координат. Кроме того, если вы сохранили предпочтения пользователя устройства, то можете подобрать наиболее подходящие рекомендации для этого пользователя. В этом отдельном примере скорость ответа приложения на полученные координаты критически важна для достижения качественного взаимодействия с пользователем. Кэширование может сыграть в нем важную роль. Интересные места и их координаты можно хранить в хранилище пар «ключ – значение», например в Redis, чтобы обеспечить их быстрое получение. С точки зрения разработки вы можете запрограммировать свое приложение IoT, чтобы оно реагировало на любое событие, если для этого существуют программные средства. При создании архитектуры IoT необходимо рассмотреть некоторые очень важные вопросы, в том числе время ответа при анализе полученных данных, создание архитектуры решения, масштаб которого охватывает N устройств, и экономичность архитектуры.
Возьмем, к примеру, устройство, которое передает свои GPS-координаты. Ваше приложение IoT может предложить интересные места, которые находятся поблизости от этих координат. Кроме того, если вы сохранили предпочтения пользователя устройства, то можете подобрать наиболее подходящие рекомендации для этого пользователя. В этом отдельном примере скорость ответа приложения на полученные координаты критически важна для достижения качественного взаимодействия с пользователем. Кэширование может сыграть в нем важную роль. Интересные места и их координаты можно хранить в хранилище пар «ключ – значение», например в Redis, чтобы обеспечить их быстрое получение. С точки зрения разработки вы можете запрограммировать свое приложение IoT, чтобы оно реагировало на любое событие, если для этого существуют программные средства. При создании архитектуры IoT необходимо рассмотреть некоторые очень важные вопросы, в том числе время ответа при анализе полученных данных, создание архитектуры решения, масштаб которого охватывает N устройств, и экономичность архитектуры.
AWS IoT – это управляемая облачная платформа, которая позволяет подключенным устройствам просто и безопасно взаимодействовать с облачными приложениями и другими устройствами.
Дополнительные сведения: Managing IoT and Time Series Data with Amazon ElastiCache for Redis
Рекламные технологии
Современные приложения в сфере рекламных технологий особо требовательны к производительности. Примером важной области развития в этой сфере является торг в режиме реального времени (RTB). Это подход к трансляции рекламы на цифровых экранах в режиме реального времени, основанный на принципе аукциона и работающий со впечатлениями на самом подробном уровне. RTB был преобладающим способом проведения транзакций в 2015 году, учитывая то, что 74,0 процента рекламы было куплено программными средствами, что в США соответствует 11 миллиардам долларов (согласно eMarketer Analysis). При создании приложения для торгов в режиме реального времени важно учитывать то, что одна миллисекунда может решать, было ли предложение предоставлено вовремя, или оно уже стало ненужным. Это значит, что нужно крайне быстро получать данные из базы. Кэширование баз данных, при использовании которого можно получать данные о торгах за считанные доли миллисекунды, – это отличное решение для достижения такой высокой производительности.
Это значит, что нужно крайне быстро получать данные из базы. Кэширование баз данных, при использовании которого можно получать данные о торгах за считанные доли миллисекунды, – это отличное решение для достижения такой высокой производительности.
Игровые технологии
Интерактивность – это краеугольный камень каждой современной игры. Ничто так не раздражает игроков, как медленная игра и долгое ожидание реакции. Такие игры редко становятся успешными. Мобильные многопользовательские игры еще требовательнее к производительности, потому что информацию о действии одного игрока необходимо предоставлять другим игрокам в режиме реального времени. Кэширование игровых данных играет решающую роль в бесперебойной работе игры благодаря тому, что время ответа на запросы к часто используемым данным исчисляется в долях миллисекунды. Также важно решить проблемы востребованных данных, когда множество одинаковых запросов отправляется к одним и тем же данным, например «кто входит в первую десятку игроков по счету?»
Подробнее о разработке игр см. здесь.
здесь.
Мультимедиа
Мультимедийным компаниям часто требуется передавать клиентам большое количество статического контента при постоянном изменении количества читателей или зрителей. Примером является сервис потоковой передачи видео, например Netflix или Amazon Video, которые передают пользователям большой объем видеоконтента. Это идеальный случай для использования сети доставки контента, в которой данные хранятся на серверах кэширования, расположенных во всем мире. Еще одним аспектом медиаприложений является пикообразная и непредсказуемая нагрузка. Возьмем, к примеру, публикацию в блоге на веб-сайте, о которой некоторая знаменитость только что отправила сообщение в Twitter, или веб-сайт футбольной команды во время Суперкубка. Такой высокий пик спроса на маленькое подмножество контента – вызов для многих баз данных, потому их пропускная способность для отдельных ключей ограничена. Поскольку пропускная способность оперативной памяти гораздо выше, чем у дисков, кэш базы данных помогает решить эту проблему путем перенаправления запросов чтения в кэш в памяти.
Интернет-коммерция
Современные приложения для электронной коммерции становятся все сложнее. При совершении покупок в них учитываются личные предпочтения, например в режиме реального времени даются рекомендации, которые основаны на данных пользователя и истории его покупок. Обычно для этого требуется заглянуть в социальную сеть пользователя и взять за основу для рекомендации то, что понравилось друзьям, или то, что они приобрели. Количество данных, которые нужно обработать, растет, а терпение клиентов – нет. Поэтому обеспечение производительности приложения в режиме реального времени – это не роскошь, а необходимость. Хорошо реализованная стратегия кэширования – это важнейший аспект производительности приложения, от которого зависят успех и неудача, продажа товара и потеря клиента.
Приложения для социальных сетей взяли мир штурмом. У таких социальных сетей, как Facebook, Twitter, Instagram и Snapchat, очень много пользователей, и объем контента, который они потребляют, все больше растет. Когда пользователи открывают свои ленты новостей, они ожидают, что увидят свежий персонализированный контент в режиме реального времени. Это не статический контент, поскольку у каждого пользователя разные друзья, фотографии, интересы и т. д., за счет чего обостряется необходимость в усложнении платформы, на которой основано приложение. Кроме того, приложения для социальных сетей подвержены пикам использования во время крупных развлекательных мероприятий, спортивных и политических событий. Устойчивость к пиковым нагрузкам и высокая производительность в режиме реального времени возможны благодаря использованию нескольких уровней кэширования, включая сети доставки контента для статического контента, например изображений, кэш сеансов для учета данных текущих сессий пользователей и кэш баз данных для ускорения доступа к часто запрашиваемому контенту, например последним фотографиям и свежим новостям от близких друзей.
Когда пользователи открывают свои ленты новостей, они ожидают, что увидят свежий персонализированный контент в режиме реального времени. Это не статический контент, поскольку у каждого пользователя разные друзья, фотографии, интересы и т. д., за счет чего обостряется необходимость в усложнении платформы, на которой основано приложение. Кроме того, приложения для социальных сетей подвержены пикам использования во время крупных развлекательных мероприятий, спортивных и политических событий. Устойчивость к пиковым нагрузкам и высокая производительность в режиме реального времени возможны благодаря использованию нескольких уровней кэширования, включая сети доставки контента для статического контента, например изображений, кэш сеансов для учета данных текущих сессий пользователей и кэш баз данных для ускорения доступа к часто запрашиваемому контенту, например последним фотографиям и свежим новостям от близких друзей.
Здравоохранение и здоровый образ жизни
В сфере здравоохранения происходит цифровая революция, благодаря которой медицинское обслуживание становится доступным все большему количеству пациентов во всем мире. Некоторые приложения позволяют пациентам общаться с врачами по видеосвязи, а многие крупные клиники предлагают своим клиентам приложения, в которых можно посмотреть результаты анализов и связаться с медицинским персоналом. Для поддержания здорового образа жизни существует множество приложений: от программ для отслеживания показаний датчиков (например, FitBit и Jawbone) до полных курсов тренировок и подборок данных. Поскольку эти приложения по своей сути интерактивные, необходимо, чтобы они были высокопроизводительными и удовлетворяли бизнес-требованиям и требованиям к данным. Вооружившись эффективной стратегией кэширования, вы сможете обеспечить быструю работу приложений, сократить общие затраты на инфраструктуру и масштабировать ее по мере роста востребованности.
Некоторые приложения позволяют пациентам общаться с врачами по видеосвязи, а многие крупные клиники предлагают своим клиентам приложения, в которых можно посмотреть результаты анализов и связаться с медицинским персоналом. Для поддержания здорового образа жизни существует множество приложений: от программ для отслеживания показаний датчиков (например, FitBit и Jawbone) до полных курсов тренировок и подборок данных. Поскольку эти приложения по своей сути интерактивные, необходимо, чтобы они были высокопроизводительными и удовлетворяли бизнес-требованиям и требованиям к данным. Вооружившись эффективной стратегией кэширования, вы сможете обеспечить быструю работу приложений, сократить общие затраты на инфраструктуру и масштабировать ее по мере роста востребованности.
Подробнее о создании приложений для сферы здравоохранения на AWS см. здесь.
Финансы и финансовые технологии
За последние годы потребление финансовых сервисов очень изменилось. Существуют приложения для доступа к банковским и страховым услугам, функциям выявления мошенничества, сервисам инвестирования, оптимизации капитальных рынков с использованием алгоритмов, которые работают в режиме реального времени, а также многие другие приложения. Очень сложно предоставлять доступ к финансовым данным клиента и возможность проведения таких транзакций, как перевод средств или совершение платежей, в режиме реального времени. Во-первых, к приложениям для этой сферы применяются те же ограничения, что и к приложениям для других сфер, в которых пользователю требуется взаимодействовать с приложением в режиме, близком к реальному времени. Кроме того, финансовые приложения могут предъявлять дополнительные требования, например относительно повышенной безопасности и выявления мошенничества. Для того чтобы производительность отвечала ожиданиям пользователя, крайне важно создать эффективную архитектуру с использованием стратегии многоуровневого кэширования. В зависимости от требований приложения уровни кэширования могут включать кэш сеансов для хранения данных о сессиях пользователя, сеть доставки контента для передачи статического контента и кэш базы данных для передачи часто запрашиваемых данных, таких как последние 10 покупок клиента.
Очень сложно предоставлять доступ к финансовым данным клиента и возможность проведения таких транзакций, как перевод средств или совершение платежей, в режиме реального времени. Во-первых, к приложениям для этой сферы применяются те же ограничения, что и к приложениям для других сфер, в которых пользователю требуется взаимодействовать с приложением в режиме, близком к реальному времени. Кроме того, финансовые приложения могут предъявлять дополнительные требования, например относительно повышенной безопасности и выявления мошенничества. Для того чтобы производительность отвечала ожиданиям пользователя, крайне важно создать эффективную архитектуру с использованием стратегии многоуровневого кэширования. В зависимости от требований приложения уровни кэширования могут включать кэш сеансов для хранения данных о сессиях пользователя, сеть доставки контента для передачи статического контента и кэш базы данных для передачи часто запрашиваемых данных, таких как последние 10 покупок клиента.
Подробнее о финансовых приложениях на AWS см.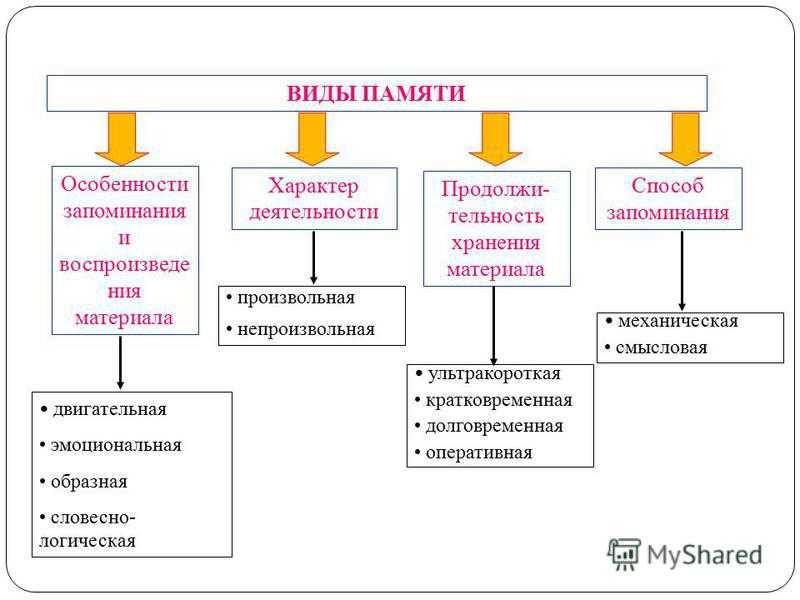 здесь.
здесь.
Память и хранилище в After Effects
- Руководство пользователя After Effects
- Выпуски бета-версии
- Обзор программы бета-тестирования
- Домашняя страница бета-версии After Effects
- Функции бета-версии
- Панель «Свойства» (Бета-версия)
- Выбираемые слои подложки дорожки (бета-версия)
- Встроенное кодирование H.264 (бета-версия)
- Начало работы
- Начало работы с After Effects
- Новые возможности After Effects
- Сведения о выпуске | After Effects
- Системные требования для After Effects
- Сочетания клавиш в After Effects
- Поддерживаемые форматы файлов | After Effects
- Рекомендации по аппаратному обеспечению
- After Effects для компьютеров с процессорами Apple
- Планирование и настройка
- Настройка и установка
- Рабочие среды
- Общие элементы пользовательского интерфейса
- Знакомство с интерфейсом After Effects
- Рабочие процессы
- Рабочие среды, панели управления, программы просмотра
- Проекты и композиции
- Проекты
- Основы создания композиции
- Предварительная композиция, вложение и предварительный рендеринг
- Просмотр подробных сведений о производительности с помощью инструмента «Профайлер композиций»
- Модуль рендеринга композиций CINEMA 4D
- Импорт видеоряда
- Подготовка и импорт неподвижных изображений
- Импорт из After Effects и Adobe Premiere Pro
- Импорт и интерпретация видео и аудио
- Подготовка и импорт файлов 3D-изображений
- Импорт и интерпретация элементов видеоряда
- Работа с элементами видеоряда
- Определение точек редактирования с помощью функции «Определение изменения сцен»
- Метаданные XMP
- Текст и графические элементы
- Текст
- Форматирование символов и панель символов
- Эффекты текста
- Создание и редактирование текстовых слоев
- Форматирование абзацев и панель «Абзац»
- Экструзия слоев текста и слоев-фигур
- Анимация текста
- Примеры и ресурсы для текстовой анимации
- Шаблоны динамического текста
- Анимационный дизайн
- Работа с шаблонами анимационного дизайна в After Effects
- Использование выражений для создания раскрывающихся списков в шаблонах анимационного дизайна
- Работа с основными свойствами для создания шаблонов анимационного дизайна
- Замена изображений и видео в шаблонах анимационного дизайна и основных свойствах
- Текст
- Рисование, заливка цветом и контуры
- Обзор слоев-фигур, контуров и векторных изображений
- Инструменты рисования: «Кисть», «Штамп» и «Ластик»
- Сглаживание обводки фигуры
- Атрибуты фигур, операции заливки цветом и операции с контурами для слоев-фигур
- Использование эффекта фигуры «Cмещение контура» для изменения фигур
- Создание фигур
- Создание масок
- Удаление объектов из видеоматериалов с помощью панели «Заливка с учетом содержимого»
- Инструменты «Кисть для ротоскопии» и «Уточнить подложку»
- Слои, маркеры и камера
- Выделение и упорядочивание слоев
- Режимы наложения и стили слоев
- 3D-слои
- Свойства слоя
- Создание слоев
- Управление слоями
- Маркеры слоя и маркеры композиции
- Камеры, освещение и точки обзора
- Анимация, ключевые кадры, отслеживание движения и прозрачное наложение
- Анимация
- Основы анимации
- Анимация с помощью инструментов «Марионетка»
- Управление и анимация контуров фигур и масок
- Анимация фигур Sketch и Capture с помощью After Effects
- Инструменты анимации
- Работа с анимацией на основе данных
- Ключевой кадр
- Интерполяция ключевого кадра
- Установка, выбор и удаление ключевых кадров
- Редактирование, перемещение и копирование ключевых кадров
- Отслеживание движения
- Отслеживание и стабилизация движения
- Отслеживание лиц
- Отслеживание маски
- Ссылка на маску
- Скорость
- Растягивание по времени и перераспределение времени
- Тайм-код и единицы отображения времени
- Прозрачное наложение
- Прозрачное наложение
- Эффекты прозрачного наложения
- Анимация
- Прозрачность и композиция
- Обзор композиции и прозрачности и соответствующие ресурсы
- Альфа-каналы и маски
- Корректирование цвета
- Основы работы с цветом
- Управление цветом
- Эффекты цветокоррекции
- Эффекты и стили анимации
- Обзор эффектов и стилей анимации
- Список эффектов
- Эффекты имитации
- Эффекты стилизации
- Аудиоэффекты
- Эффекты искажения
- Эффекты перспективы
- Эффекты канала
- Эффекты создания
- Эффекты перехода
- Эффект «Устранение эффекта плавающего затвора»
- Эффекты «Размытие» и «Резкость»
- Эффекты 3D-канала
- Программные эффекты
- Эффекты подложки
- Эффекты «Шум» и «Зернистость»
- Эффект «Увеличение с сохранением уровня детализации»
- Устаревшие эффекты
- Выражения и автоматизация
- Выражение
- Основы работы с выражениями
- Понимание языка выражений
- Использование элементов управления выражениями
- Различия в синтаксисе между движками выражений JavaScript и Legacy ExtendScript
- Управление выражениями
- Ошибки выражения
- Использование редактора выражений
- Использование выражений для изменения свойств текста и доступа к ним
- Справочник языка выражений
- Примеры выражений
- Автоматизация
- Автоматизация
- Сценарии
- Выражение
- Видео с погружением, VR и 3D
- Создание сред VR в After Effects
- Применение видеоэффектов с эффектом погружения
- Инструменты составления композиций для видеоизображений VR/360
- Отслеживание движений камеры в трехмерном пространстве
- Пространство для работы с трехмерными объектами
- Инструменты 3D-преобразования
- Дополнительные возможности 3D-анимации
- Предварительный просмотр изменений в 3D-дизайнах в режиме реального времени с помощью модуля режима реального времени
- Добавление гибкого дизайна в графику
- Виды и предварительный просмотр
- Предпросмотр
- Предпросмотр видео с помощью Mercury Transmit
- Изменение и использование представлений
- Рендеринг и экспорт
- Основы рендеринга и экспорта
- Экспорт проекта After Effects как проекта Adobe Premiere Pro
- Преобразование фильмов
- Многокадровый рендеринг
- Автоматический рендеринг и рендеринг по сети
- Рендеринг и экспорт неподвижных изображений и наборов неподвижных изображений
- Использование кодека GoPro CineForm в After Effects
- Работа с другими приложениями
- Dynamic Link и After Effects
- Работа с After Effects и другими приложениями
- Синхронизация настроек в After Effects
- Библиотеки Creative Cloud Libraries в After Effects
- Подключаемые модули
- CINEMA 4D и Cineware
- Совместная работа: Frame.
 io и Team Projects
io и Team Projects- Совместная работа в Premiere Pro и After Effects
- Frame.io
- Установка и активация Frame.io
- Использование Frame.io с Premiere Pro и After Effects
- Часто задаваемые вопросы
- Team Projects
- Начало работы с Team Projects
- Создание Team Project
- Совместная работа с помощью Team Projects
- Память, хранилище, производительность
- Память и хранилище
- Как After Effects справляется с проблемами нехватки памяти при предварительном просмотре
- Повышение производительности
- Установки
- Требования к графическому процессору и драйверу графического процессора для After Effects
Настройки памяти
Задайте установки памяти, выбрав Правка > Установки > Память (Windows) или After Effects > Установки > Память (Mac OS).
При изменении настроек в диалоговом окне «Память» After Effects динамически обновляет в диалоговом окне текстовую подсказку о том, как программа будет распределять и использовать память и процессоры.
ОЗУ, зарезервированное для установки «Другие приложения», действует независимо от того, установлен ли флажок «Выполнять рендеринг одновременно нескольких кадров».
ОЗУ, зарезервированное для других приложений
Увеличьте это значение, чтобы предоставить больший объем ОЗУ для операционной системы и для приложений, отличных от After Effects и приложения, с которым After Effects использует общий пул памяти. Если известно, что предполагается использовать конкретное приложение вместе с After Effects, проверьте его требования к системе и установите это значение не менее минимального объема оперативной памяти, требуемой для этого приложения. Поскольку производительность оказывается максимальной, когда для операционной системы оставлен необходимый объем памяти, нельзя устанавливать это значение ниже минимального базового значения.
Пул памяти, совместно используемый приложениями After Effects, Premiere Pro, Prelude, Media Encoder, Photoshop и Audition
After Effects использует пул памяти, общий с приложениями Adobe CC. Это показывается на панели установок «Память» значками для каждого из этих приложений в верхней части панели. Значки незапущенных приложений отображаются серым цветом.
Это показывается на панели установок «Память» значками для каждого из этих приложений в верхней части панели. Значки незапущенных приложений отображаются серым цветом.
Средство балансировки памяти предотвращает обмен ОЗУ с диском (свопинг) с помощью динамического управления памятью, выделяемой каждому из приложений. Каждое приложение регистрируется в средстве балансировки памяти, указывая определенные базовые данные: минимальные требования к памяти, максимальный объем памяти, который может использовать приложение, текущий объем используемой памяти и приоритет. У приоритета есть три значения: низкий, обычный и максимальный. Максимальный приоритет в настоящее время зарезервирован для приложений After Effects и Premiere Pro, когда они являются активными. Нормальный приоритет предназначен для приложения After Effects в фоновом режиме или для приложения Adobe Media Encoder в режиме переднего плана. Низкий приоритет для фоновых серверов приложений Premiere Pro или Adobe Media Encoder в фоновом режиме.
Примером практического результата использования общего пула памяти может служить тот факт, что при запуске Premiere Pro уменьшается объем ОЗУ, доступный приложению After Effects для предпросмотра. Завершение Premiere Pro немедленно освобождает ОЗУ для After Effects и увеличивает возможную длительность предпросмотров.
Диалоговое окно «Память»
Диалоговое окно «Сведения о памяти» содержит дополнительную информацию об установленном ОЗУ, а также о текущем и разрешенном использовании ОЗУ. Оно также содержит таблицу из нескольких столбцов, представляющую процессы, связанные с приложениями. Эта таблица содержит сведения о каждом процессе, такие как идентификатор процесса, имя приложения, мин. требуемая память, макс. полезная память, макс. разрешенная память, текущий объем памяти и текущий приоритет.
Чтобы открыть диалоговое окно, выберите Правка > Установки > Память (Windows) или After Effects > Установки > Память (Mac OS) и нажмите кнопку «Сведения» в нижней части экрана установок.
Данные можно копировать в буфер обмена с помощью кнопки Копировать.
Требования к памяти (ОЗУ) для рендеринга
Требования к памяти для рендеринга кадра (или для предпросмотров и окончательного вывода) увеличиваются в соответствии с требованиями к памяти слоя композиции, интенсивнее всего использующего память.
В один момент времени After Effects выполняет рендеринг каждого кадра одного слоя композиции. По этой причине при определении того, может ли рендеринг данного кадра выполнен в доступной памяти, требования к памяти каждого отдельного слоя оказываются более правильными, чем длительность композиции или количество слоев в ней. Требования к памяти для композиции эквивалентны требованиям к памяти, предъявляемым слоем композиции, который интенсивнее всего использует память.
Требования к памяти для слоя увеличиваются в определенных случаях, в том числе в следующих:
Увеличение битовой глубины цвета проекта
Увеличение разрешения композиции
Использование большого исходного изображения
Включение функции управления цветом
Добавление маски
Добавление посимвольных 3D-свойств
Создание предварительной композиции без свертывающих преобразований
Использование определенных режимов наложения, стилей слоев или эффектов, особенно включающих несколько слоев
Применение некоторых параметров вывода, например, преобразования сторон 3:2, кадрирования и изменения размера
Добавление теней или эффектов глубины поля при использовании 3D-слоев
After Effects требуется непрерывный блок памяти для хранения каждого кадра — приложение не может хранить в сегментах фрагментированной памяти. Сведения о том, какой объем ОЗУ требуется для хранения несжатого кадра, см. в разделе Требования к хранилищу для выходных файлов.
Сведения о том, какой объем ОЗУ требуется для хранения несжатого кадра, см. в разделе Требования к хранилищу для выходных файлов.
Советы по уменьшению требований к памяти и увеличению производительности см. в разделе Повышение производительности с помощью упрощения проекта.
Очистка памяти (ОЗУ)
Иногда After Effects может вывести предупреждение о том, что для отображения или рендеринга композиции требуется больше памяти. Получив предупреждение о нехватке памяти, освободите память или уменьшите требования к памяти, предъявляемые слоями, которые интенсивнее всего используют память, и повторите попытку.
Можно освободить память немедленно, используя команды из меню «Правка» > «Удалить из памяти»:
- Вся память
- Кэш-память изображения
- Вся память и кэш диска
- Отменить
- Снимок
Очистка памяти осуществляется быстрее для крупных проектов. Очистка памяти не приводит к синхронизации базы данных проекта. Если нужно принудительно синхронизировать базу данных проекта, нажмите клавишу «Option» (Mac OS) или Alt (Windows) и выберите «Правка» > «Очистить» > «Вся память». Это можно сделать, если панель «Композиция» обновляется некорректно, а команда «Очистить» > «Вся память» или «Вся память и кэш диска» не помогает.
Если нужно принудительно синхронизировать базу данных проекта, нажмите клавишу «Option» (Mac OS) или Alt (Windows) и выберите «Правка» > «Очистить» > «Вся память». Это можно сделать, если панель «Композиция» обновляется некорректно, а команда «Очистить» > «Вся память» или «Вся память и кэш диска» не помогает.
Устранение проблем памяти
Ошибка: «Невозможно выделить достаточный объем памяти для рендеринга текущего кадра…»
Либо уменьшите требования к памяти для рендеринга этого кадра, либо установите дополнительное ОЗУ.
Ошибка: «Невозможно выделить [n] МБ памяти…»
Либо уменьшите требования к памяти для рендеринга этого кадра, либо установите дополнительное ОЗУ.
Ошибка: «Размер буфера изображений [ширина] x [высота] при [глубина] бит/канал ([n] ГБ) превышает внутреннее ограничение…»
Уменьшите требования к памяти для рендеринга этого кадра.
Максимальный объем памяти, который может занять один кадр, составляет 2 ГБ.
Ошибка: «Выделенный объем памяти [n] ГБ превышает внутреннее ограничение…»
Уменьшите требования к памяти для рендеринга этого кадра.
Максимальный размер для любого отдельного выделяемого объема памяти составляет 2 ГБ.
Используйте следующую формулу для определения количества мегабайтов, необходимого для сохранения одного несжатого кадра при полном разрешении:
(высота в пикселах) x (ширина в пикселах) x (число битов на канал/2 097 152)
Значение 2 097 152 представляет собой коэффициент преобразования, учитывающий число байтов в мегабайте (220), число бит в байте (8) и количество каналов в соответствии на пиксел (4).
Несколько примеров размеров кадра и требований к памяти, в мегабайтах (МБ) на кадр:
Кадр DV NTSC (720 x 480) в проекте 8 бит/канал: 1,3 МБ
Кадр PAL D1/DV (720 x 576) в проекте 8 бит/канал: 1,6 МБ
Кадр HDTV (1920 x 1080) в проекте 16 бит/канал: 16 МБ
Кадр цифрового кино 4K (4096×2304) в проекте 32 бит/канал: 144 МБ
Поскольку видео обычно сжимается при кодировании, во время рендеринга для окончательного вывода нельзя просто умножить объем памяти, требуемый для одного кадра, на частоту кадров и длительность композиции, чтобы получить объем дискового пространства, необходимый для сохранения выводимого фильма. Но такой расчет может дать грубую оценку максимального дискового пространства, которое может понадобиться. Например, 1 секунда (приблизительно 30 кадров) несжатого видео стандартной четкости, 8 бит/канал, требует около 40 МБ. Сохранение всего полноразмерного фильма на этой скорости передачи потребовало бы более 200 ГБ. Даже при сжатии DV, уменьшающем размер файла до 3,6 МБ на секунду видео, требование к дисковому пространству превращается более чем в 20 ГБ для обычного полноразмерного фильма.
Но такой расчет может дать грубую оценку максимального дискового пространства, которое может понадобиться. Например, 1 секунда (приблизительно 30 кадров) несжатого видео стандартной четкости, 8 бит/канал, требует около 40 МБ. Сохранение всего полноразмерного фильма на этой скорости передачи потребовало бы более 200 ГБ. Даже при сжатии DV, уменьшающем размер файла до 3,6 МБ на секунду видео, требование к дисковому пространству превращается более чем в 20 ГБ для обычного полноразмерного фильма.
Для проекта художественного фильма — с его более высокой глубиной цвета, увеличенным размером кадра и намного меньшими коэффициентами сжатия — не является необычным требование терабайтов дискового пространства для видеоряда и вывода фильмов после рендеринга.
При работе над композицией приложение After Effects временно хранит некоторые кадры после рендеринга и исходные изображения в ОЗУ, поэтому предпросмотр и редактирование могут выполняться быстрее. Приложение After Effects не кэширует кадры, рендеринг которых занимает мало времени. Кадры в кэше изображений остаются несжатыми.
Кадры в кэше изображений остаются несжатыми.
Для ускорения предварительного просмотра приложение After Effects также выполняет кэширование на уровнях видеоряда и слоев. Рендеринг измененных слоев выполняется во время предварительного просмотра, а неизмененные слои составляются из кэша.
Когда кэш ОЗУ заполнен, любой новый кадр, добавляемый в кэш ОЗУ, заменяет кадр, кэшированный ранее. Когда приложение After Effects выполняет рендеринг кадров для предпросмотра, оно перестает добавлять кадры в кэш изображений после его заполнения и начинает воспроизведение только тех кадров, которые могут поместиться в кэш ОЗУ.
Кадры, кэшированные в ОЗУ, помечаются на линейке времени панелей «Таймлайн», «Слой» и «Видеоряд» зелеными полосками. Синими полосками на панели «Таймлайн» отмечены кадры, кэшированные на диск.
Индикаторы кэша слоев
Индикаторы кэша слоев позволяют визуализировать кэшированные кадры для каждого отдельного слоя. Это полезно при попытке определить, какие слои кэшированы в композиции.
Включите параметр «Индикаторы кэша слоев», удерживая нажатой клавишу Ctrl (Windows) или Command (Mac), а затем выберите «Индикаторы кэша слоев» в меню панели «Таймлайн». Чтобы индикаторы были видны, параметр «Индикаторы кэша слоев» должен быть включен в меню.
Отображение индикаторов кэша слегка уменьшает производительность.
Кэш ОЗУ очищается автоматически при выходе из программы After Effects.
Очистку кэша ОЗУ или кэша ОЗУ и кэша диска можно выбрать в меню Правка > Очистить.
Выберите «Правка» > «Очистить» > «Вся память и кэш диска», чтобы очистить содержимое всех кэшей ОЗУ (подобно существующей команде «Вся память») и содержимое кэша диска (подобно существующей кнопке «Очистить кэш диска» в установках «Носитель и кэш диска»).
After Effects быстрее очищает память для крупных проектов. Очистка памяти не приводит к синхронизации базы данных проекта. Если нужно принудительно синхронизировать базу данных проекта, нажмите клавишу «Option» (Mac OS) или Alt (Windows) и выберите «Правка» > «Очистить» > «Вся память».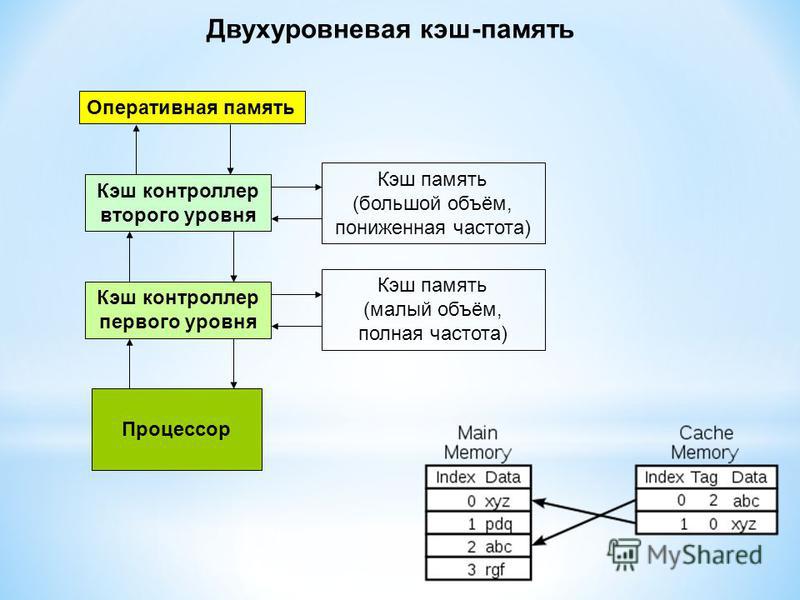 Это можно сделать, если панель «Композиция» обновляется некорректно, а команда «Очистить» > «Вся память» или «Вся память и кэш диска» не помогает.
Это можно сделать, если панель «Композиция» обновляется некорректно, а команда «Очистить» > «Вся память» или «Вся память и кэш диска» не помогает.
Очистка кэша диска для одной версии After Effects не очищает кэш для других версий. Например, очистка кэша диска After Effects CC не повлияет на кэш диска After Effects CS6.
Глобальный кэш производительности состоит из следующих компонентов:
Глобальный кэш ОЗУ: при редактировании композиции кадры в кэше ОЗУ автоматически не стираются и используются повторно в случае отмены изменения или восстановления предыдущего состояния композиции. Самые старые кадры в кэше ОЗУ стираются, если кэш переполнен, а After Effects требуется добавить в него новые кадры.
Постоянный кэш диска: кадры, кэшированные на диск, остаются доступными даже после закрытия приложения After Effects.
Видео: глобальный кэш производительности
В этом видеоролике, созданном Брайаном Маффиттом (Brian Maffitt) и Total Training, показано, как функции глобального кэша производительности позволяют экономить время при создании композиции.
Брайан Маффитт (Brian Maffitt) и Total Training
http://www.totaltraining.com
Для предпросмотров кэш диска не используется. Предпросмотр с его помощью возможен только в том случае, когда воспроизведение кэшированных кадров и аудио в режиме реального времени не требуется (См. Предварительный просмотр).
Кэш диска включен по умолчанию. Для настройки кэша диска и включения или отключения кэширования диска:
-
Выберите Правка > Установки > Носитель и кэш диска (Windows) или After Effects > Установки > Носитель и кэш диска (Mac OS) и установите или снимите флажок «Включить кэш диска».
Установки кэша диска позволяют выбрать папку для размещения кэша.
-
Нажмите кнопку «Выбрать папку», а затем нажмите кнопку «ОК» (Windows) или «Выбрать» (Mac OS).
Чтобы очистить кэш диска, выполните указанные ниже действия.
-
Нажмите на кнопку «Очистить кэш диска» или выберите параметр «Очистить всю память и кэш диска» в меню «Правка».
Даже если кэширование на диск было включено, каждый кадр должен помещаться в непрерывный блок ОЗУ. Включение кэша диска не помогает устранить ограничения, касающиеся объема ОЗУ, недостаточного для размещения или рендеринга одного кадра композиции.
Для лучшей производительности кэширования на диск выберите папку на физическом жестком диске, отличающемся от диска исходного видеоряда. По возможности папка должна находиться на жестком диске, использующем другой контроллер, чем диск, на котором находится исходный видеоряд. Для размещения папки кэша диска рекомендуется использовать быстрый жесткий диск или SSD-диск. Папка кэша диска не может быть корневой папкой жесткого диска.
Как и в случае кэша ОЗУ, приложение After Effects использует кэш диска для хранения кадра, только если быстрее восстановить кадр из кэша, чем выполнить повторный рендеринг кадра.
Параметр «Максимальный размер кэша диска» определяет используемый размер пространства на жестком диске в гигабайтах.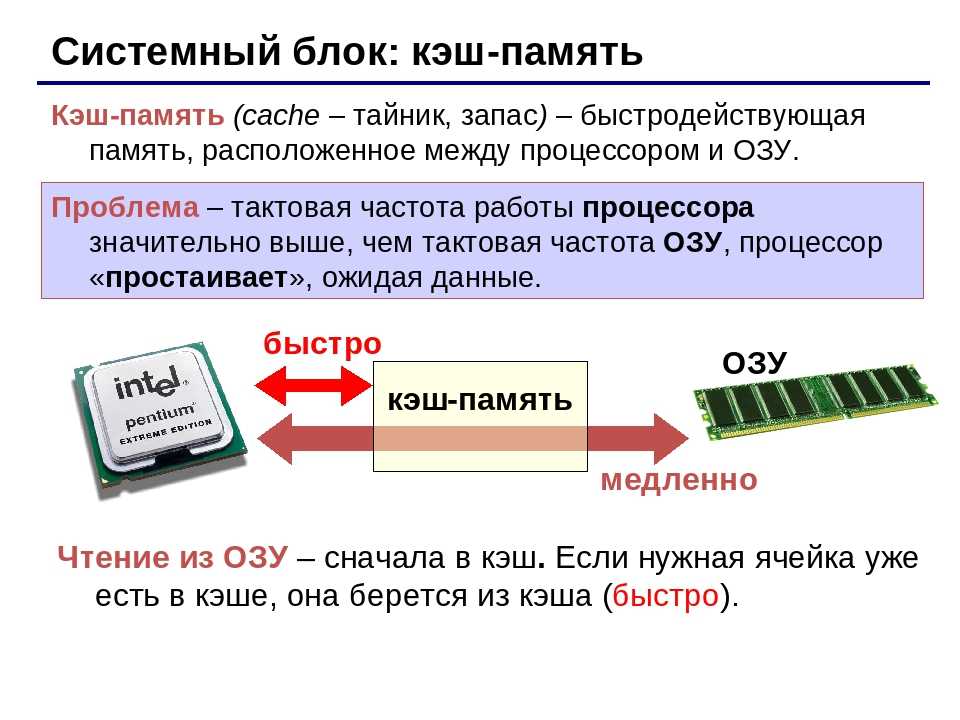 Размер кэша диска по умолчанию составляет 10 % от общего размера тома, до 100 ГБ.
Размер кэша диска по умолчанию составляет 10 % от общего размера тома, до 100 ГБ.
Приложение проверяет наличие свободного дискового пространства, на 10 ГБ превышающего значение, заданное для параметра Установки > Носитель и кэш диска. Если объем дискового пространства недостаточен для кэша диска, After Effects выводит предупреждение.
Глобальный кэш ОЗУ
Глобальный кэш ОЗУ обеспечивает следующие преимущества:
- Кэшированные кадры восстанавливаются после операций отмены и повтора действий.
- Кэшированные кадры восстанавливается при возвращении композиции или слоя к предыдущему состоянию, например, при выключении и последующем включении видимости слоя.
- Повторно используемые кадры распознаются в любом месте временной шкалы (например, при использовании выражений loop, перераспределении времени или копировании и вставке ключевых кадров), а не только среди смежных кадров.
- Повторно используемые кадры распознаются в дублированных слоях или дублированных композициях.
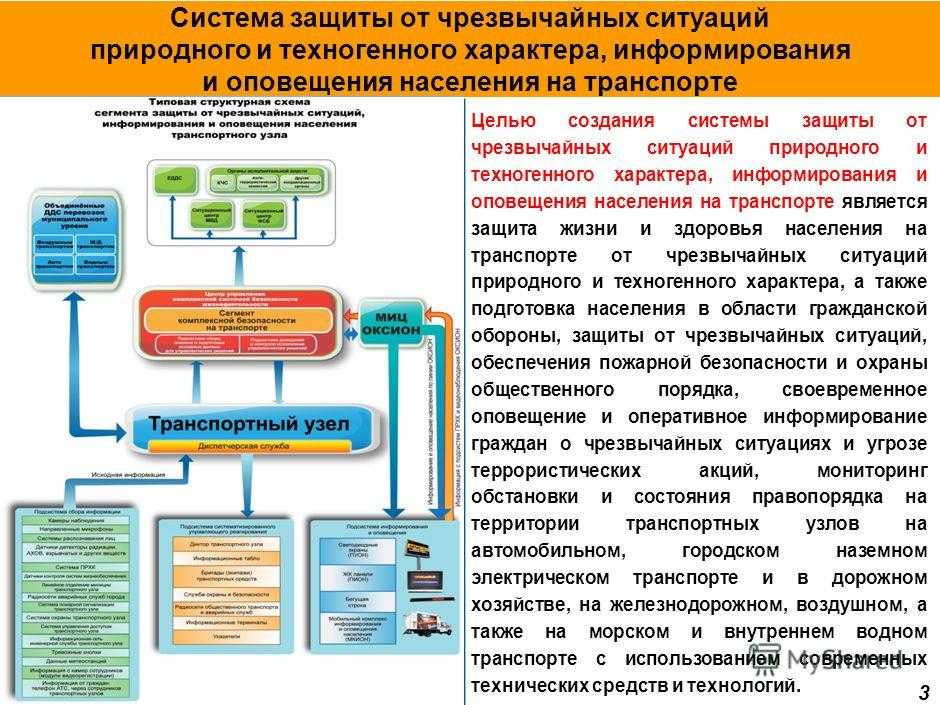
- Кэш не очищается автоматически очередью рендеринга, если в текущих настройках не выбрано иное значение.
В этом видеоролике компании Learn by Video показано, как кэши ОЗУ и диска используются для экономии времени, а также как можно выполнять рендеринг композиций в фоновом режиме, чтобы для возобновления работы не нужно было ждать выполнения рендеринга предпросмотра.
Постоянный кэш диска
После сохранения проекта кадры в кэше диска сохраняются даже после закрытия проекта или выхода из программы After Effects. Такой протокол называется постоянным кэшем диска.Кэш диска больше не очищается в конце сеанса. Благодаря функции постоянного кэша диска кадры, сохраненные в кэше диска, сохраняются между сеансами. Это позволяет экономить время на рендеринг при работе с проектом или другими проектами, использующими одни и те же кэшированные кадры.
При открытии проекта выполняется просмотр кэша диска для поиска кадров, соответствующих кадрам проекта, и они делаются доступными для использования.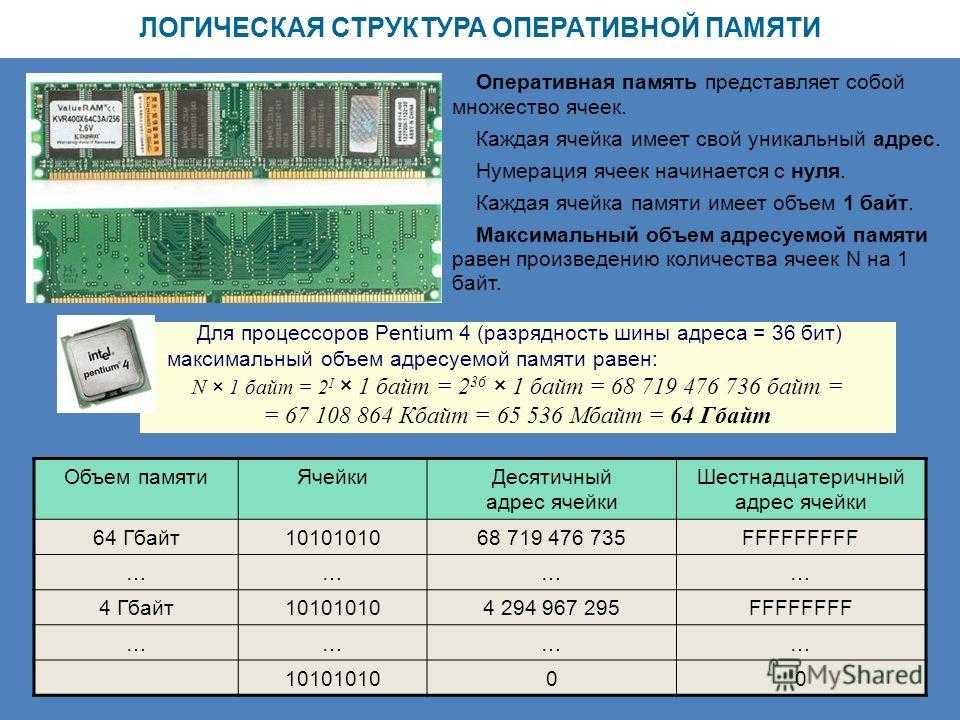 Кэш диска содержит кадры из всех проектов, открытых в этом же сеансе или в предыдущих сеансах, поэтому кэшированные на диске кадры из одного проекта будут извлечены для повторного использования в других проектах, которым требуются эти же кадры. По мере просмотра кэша синие метки постепенно заполняют таймлайн.
Кэш диска содержит кадры из всех проектов, открытых в этом же сеансе или в предыдущих сеансах, поэтому кэшированные на диске кадры из одного проекта будут извлечены для повторного использования в других проектах, которым требуются эти же кадры. По мере просмотра кэша синие метки постепенно заполняют таймлайн.
Поскольку ранние версии After Effects не сохраняли на диске необходимые данные для этой возможности, чтобы воспользоваться постоянным кэшированием, сохраните заново проекты, созданные в CS5.5 и более ранних версиях.
Для кадров, в которых используется «Кисть для ротоскопии», постоянное кэширование не применяется.
При кэшировании рабочей области в фоновом режиме для хранения кадров также используется кэш диска. См. раздел Повышение производительности с помощью глобального кэша производительности.
Видеоруководство: оптимизация After Effects для достижения высокой производительности
Старший менеджер по продукту Стив Форд (Steve Forde) рассказывает, как оптимизировать After Effects для повышения производительности.
Стив Форд (Steve Forde)
Кэш медиаданных
Когда приложение After Effects импортирует видео- и аудиофайлы в некоторых форматах, оно обрабатывает и кэширует версии этих элементов для быстрого доступа к ним при создании предпросмотров. Импортированным аудиофайлам соответствуют новые файлы CFA, а файлы MPEG индексируются в файлы MPGINDEX. Кэш медиаданных значительно повышает производительность для предпросмотров, так как позволяет не выполнять повторную обработку видео- и аудиоэлементов для каждого предпросмотра.
При первом импорте файла обработка и кэширование медиаконтента может занять некоторое время.
В базе данных хранятся ссылки на все кэшированные медиафайлы. Эта база данных является общей для Adobe Media Encoder, Premiere Pro, Encore и Soundbooth, поэтому все эти приложения могут читать и выполнять запись в один набор кэшированных медиафайлов. При смене местоположения базы данных в одном из приложений, информация об этом изменении отражается также в других приложениях. Каждое приложение может использовать свою папку кэша, но в базе данных хранится информация о всех этих файлах.
Каждое приложение может использовать свою папку кэша, но в базе данных хранится информация о всех этих файлах.
-
Выберите Правка > Установки > Носитель и кэш диска (Windows) или After Effects > Установки > Носитель и кэш диска (Mac OS), и выполните одно из предложенных ниже действий.
- Нажмите одну из кнопок «Выбрать папку», чтобы изменить местоположение базы данных кэша медиаданных или самого кэша медиаданных.
- Нажмите «Очистить базу данных и кэш», чтобы удалить согласованные и индексируемые файлы из кэша, а соответствующие записи — из базы данных. Эта команда удаляет только файлы, связанные с элементами видеоряда, для которых исходный файл больше не доступен.
Перед нажатием кнопки «Очистить базу данных и кэш» убедитесь, что устройства хранения, на которых располагаются используемые исходные медиафайлы, подключены к компьютеру. Если отснятый видеоряд отсутствует вследствие того, что устройство хранения не подключено к компьютеру, связанные файлы в кэше будут удалены.
 Такое удаление приведет к необходимости повторного сопоставления или индексации отснятого видеоряда в дальнейшем.
Такое удаление приведет к необходимости повторного сопоставления или индексации отснятого видеоряда в дальнейшем.
В следующем видео даются краткие инструкции по удалению кэшированных медиафайлов в After Effects.
Время просмотра: 26 секунд
При очистке базы данных и кэша с помощью кнопки «Очистить базу данных и кэш» файлы, связанные с элементами видеоряда, для которых исходные файлы доступны, не удаляются. Чтобы вручную удалить файлы сопоставления и индексации, перейдите в папку кэшированных медиафайлов и удалите файлы. Путь к папке кэша медиаданных указан в установках «Согласованный кэш медиаданных». Если путь не отображается в диалоговом окне целиком, воспользуйтесь кнопкой «Выбрать папку».
Производительность Хранилищ данных: проблемы и способы решения | Журнал ВРМ World | Пресс-центр
В материале рассказываются о прямых и косвенных факторах, влияющих на
производительность Хранилищ данных, а также о способах и методах выявления как
очевидных, так и скрытых проблем, связанных с эффективностью работы
Хранилищ.

Как оценить и измерить производительность Хранилища данных
Сложности и взаимозависимости современной IT-инфраструктуры все время создают проблемы для поддержки приемлемой и устойчивой производительности в среде Хранилища данных. Выполнение процессов в Хранилище (таких как подготовка отчетов, аналитика, операции извлечения, преобразования и загрузки (extract, transform and load, сокр. ETL), обработка запросов и т.д), которое вначале осуществляется в оптимальном режиме, со временем может ухудшиться. Влияние выполнения таких операций на среду Хранилища данных может не сразу стать заметным из-за скорости происходящих изменений или достаточно случайного возникновения подобных проблем. Такие изменения в среде Хранилища данных могут вызываться разнообразными факторами, прямо или косвенно связанными с самим Хранилищем.
В предлагаемом материале рассматриваются различные аспекты данных и
инфраструктуры, имеющие значение для производительности среды Хранилища данных,
а также методы выявления и оценки проблем производительности в этой среде.
Факторы среды (Environment Factors)
Обычно Хранилище данных становится доступным для пользователей после тщательной проверки всех операций. В частности, тестируется работа Хранилища в случае периодов повышенной нагрузки. Но существует еще ряд факторов, которые могут оказывать влияние на производительность Хранилища данных. Для начала следует отметить, что, как правило, такие проверки не проводятся на точной копии производственной инфраструктуры. Обычно тестовая среда не полностью отражает компоненты инфраструктуры, существующие в реальной производственной среде. Причиной этого является слишком высокая стоимость создания точной копии последней. Число уровней сервера (Интернет, приложения, база данных, средства межсетевой защиты) или избыточность параллельных центров данных для уравновешивания нагрузки и переключения после отказа недоступны в тестовой среде. Помимо этого, между тестовой и производственной средами могут существовать различия в пропускной способности сети.
Важно иметь полное представление об операциях обработки, осуществляющихся в
инфраструктуре Хранилища данных. Еще один существенный фактор — влияние цикла
обработки ETL на производительность внешнего интерфейса Хранилища данных,
поскольку этот процесс обычно занимает на сервере значительную часть ресурсов
центрального процессора, а также ресурсов ввода-вывода на диске. Если система
ETL находится на тех же серверах приложений и/или баз данных, которые
обслуживают запросы пользователей, то время обработки этих запросов может
возрастать.
Еще один существенный фактор — влияние цикла
обработки ETL на производительность внешнего интерфейса Хранилища данных,
поскольку этот процесс обычно занимает на сервере значительную часть ресурсов
центрального процессора, а также ресурсов ввода-вывода на диске. Если система
ETL находится на тех же серверах приложений и/или баз данных, которые
обслуживают запросы пользователей, то время обработки этих запросов может
возрастать.
На производительность Хранилища способны влиять и иные операции баз данных.
Если другие базы данных находятся на том же сервере, что и Хранилище, то их
работа потребует определенных ресурсов сервера. Для того чтобы обеспечить
оптимальную производительность как приложений по обработке транзакций, так и
Хранилища, они должны размещаться на разных серверах. Если необходимо, чтобы
базы данных транзакций и Хранилища находились на одном сервере, то это должны
быть разные экземпляры баз данных для того, чтобы можно было использовать СУБД
и параметры настройки баз данных, относящиеся к каждой из них отдельно. В
зависимости от изменений, связанных с ростом и использованием Хранилища,
экземпляры СУБД и баз данных могут потребовать дополнительной настройки для
поддержки их производительности.
В
зависимости от изменений, связанных с ростом и использованием Хранилища,
экземпляры СУБД и баз данных могут потребовать дополнительной настройки для
поддержки их производительности.
Еще один потенциальный фактор, который может влиять на эффективность работы среды Хранилища данных, — создание резервных копий журнальных файлов и баз данных. Для снижения этого воздействия подобные операции должны выполняться в периоды минимальных нагрузок на Хранилище.
Во многих Хранилищах данных используются различные возможности современных
совместных устройств хранения. Подобные устройства позволяют поддерживать
увеличение объема данных, доступных сразу для всех серверов сети, что исключает
необходимость наличия и поддержки специальных дисков для отдельных серверов.
Ресурсы сервера, обслуживающие приложения и базы данных, таким образом
освобождаются от операций, связанных с хранением данных, поскольку последние не
находятся на сервере.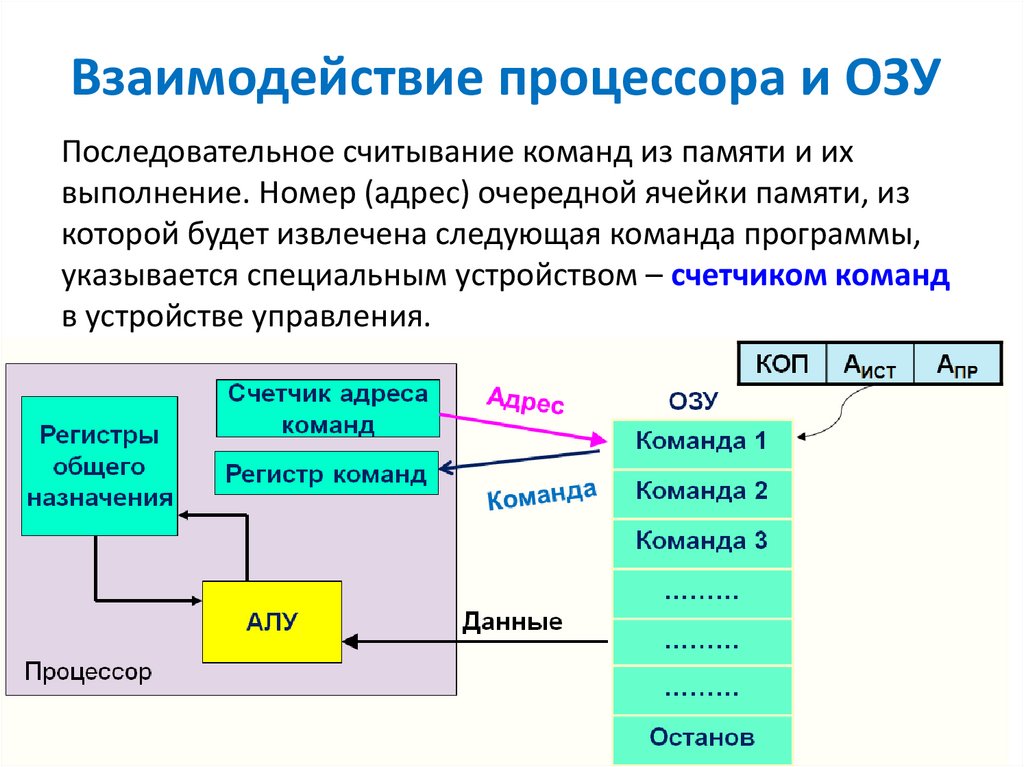 Примерами таких совместных устройств хранения являются
устройство хранения данных, подключаемое к сети (Network attached storage,
сокр. NAS), и архитектура «сервер-хранилище
данных»1 (storage area network, сокр.
SAN). Хотя подобные возможности хранения данных дают общие преимущества в плане
поддержки и роста объема данных в масштабах всей корпорации, они могут влиять
на производительность Хранилища, причем не всегда очевидным образом. Поскольку
сервер совместных устройств хранения является общим для всей корпорации,
операции обработки различных серверов приложений могут обращаться к тому же
серверу хранения, что и Хранилище данных. В периоды интенсивной обработки
данных для множества приложений совместный сервер хранения может достигать
таких точек насыщения, которые способны негативно влиять на производительность
обработки данных для Хранилища и других приложений. С точки зрения Хранилища
такое снижение производительности будет невозможно заметить или измерить на
серверах Хранилища, поскольку оно использует совместные устройства хранения.
Примерами таких совместных устройств хранения являются
устройство хранения данных, подключаемое к сети (Network attached storage,
сокр. NAS), и архитектура «сервер-хранилище
данных»1 (storage area network, сокр.
SAN). Хотя подобные возможности хранения данных дают общие преимущества в плане
поддержки и роста объема данных в масштабах всей корпорации, они могут влиять
на производительность Хранилища, причем не всегда очевидным образом. Поскольку
сервер совместных устройств хранения является общим для всей корпорации,
операции обработки различных серверов приложений могут обращаться к тому же
серверу хранения, что и Хранилище данных. В периоды интенсивной обработки
данных для множества приложений совместный сервер хранения может достигать
таких точек насыщения, которые способны негативно влиять на производительность
обработки данных для Хранилища и других приложений. С точки зрения Хранилища
такое снижение производительности будет невозможно заметить или измерить на
серверах Хранилища, поскольку оно использует совместные устройства хранения. Снижение производительности может быть единичным и иметь место только во время
определенных периодов, когда суммарные запросы приложений на обработку данных
одновременно поступают на сервер совместных устройств хранения.
Снижение производительности может быть единичным и иметь место только во время
определенных периодов, когда суммарные запросы приложений на обработку данных
одновременно поступают на сервер совместных устройств хранения.
В Хранилищах, которые работают с несколькими центрами данных для повышения доступности информации и выравнивания нагрузки обработки приложений, инфраструктура взаимных связей (interconnect infrastructure), иногда именуемая просто структурой (fabric), может вызывать проблемы с производительностью Хранилища, которые бывает нелегко обнаружить. Нарушения в средствах передачи данных и/или компонентах взаимных связей могут влиять на операции обработки данных в Хранилище, снижая его производительность. В этом случае причины проблем с производительностью Хранилища данных также будет нелегко обнаружить, поскольку своим возникновением они обязаны использованию совместной корпоративной инфраструктуры.
Таким образом, эффективность работы среды Хранилища данных может зависеть от
многих прямых и косвенных факторов. То влияние, которое эти факторы способны
оказать на производительность Хранилища, обычно невозможно оценить
количественно на стадиях разработки и тестирования. Получение полной картины
всех действий, которые могут влиять на производительность Хранилища данных,
требует исчерпывающего понимания операций, связанных с управлением, поддержкой
и настройкой Хранилища, а также с его работой с совместными структурами.
То влияние, которое эти факторы способны
оказать на производительность Хранилища, обычно невозможно оценить
количественно на стадиях разработки и тестирования. Получение полной картины
всех действий, которые могут влиять на производительность Хранилища данных,
требует исчерпывающего понимания операций, связанных с управлением, поддержкой
и настройкой Хранилища, а также с его работой с совместными структурами.
Полное представление о среде, в которой работает Хранилище данных
Обычно процессы ETL работают с заранее определенными временными интервалами,
которые зависят от периодов обновления информации в Хранилище данных (например,
режим, близкий к реальному времени, в течение дня, ежедневно, еженедельно и т.
д.). Если пользователи имеют доступ к Хранилищу во время осуществления
процессов ETL, то важно знать, как работа этих процессов отражается на
производительности обработки запросов пользователей. Важно также иметь
представление о том, как другие операции в рамках общей инфраструктуры влияют
на производительность Хранилища данных.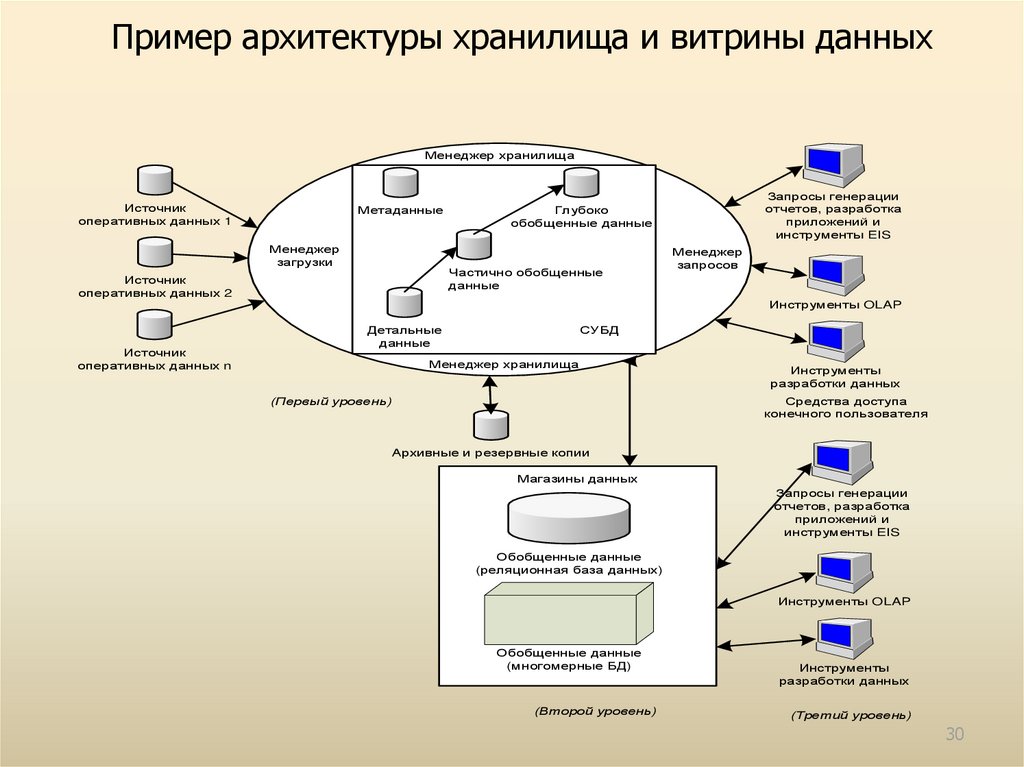 Помимо ETL, негативное влияние на
эффективность работы среды Хранилища могут оказывать такие процессы, как
создание резервных копий баз данных и систем файлов, операции, связанные с
безопасностью системы, обработка больших пакетных заданий, реорганизация баз
данных и обновление статистической информации и другие процессы, требующие
значительных системных ресурсов. Поэтому очень важно знать время выполнения
этих ресурсоемких операций, чтобы адекватно оценивать производительность
Хранилища. Здесь может помочь детальное расписание, в котором указано время
осуществления всех операций. Если вся инфраструктура Хранилища данных или ее
отдельные части также работают с другими приложениями, не относящимися к
Хранилищу, то необходимо иметь представление о потребностях этих приложений в
ресурсах и о расписании их работы. Это относится и к инфраструктуре,
использующей совместные устройства хранения (NAS, SAN и др.), поскольку их
отдельные компоненты могут являться общими и для других приложений.
Ограниченность ресурсов в среде совместных устройств хранения бывает нелегко
диагностировать в среде функционирования Хранилища данных.
Помимо ETL, негативное влияние на
эффективность работы среды Хранилища могут оказывать такие процессы, как
создание резервных копий баз данных и систем файлов, операции, связанные с
безопасностью системы, обработка больших пакетных заданий, реорганизация баз
данных и обновление статистической информации и другие процессы, требующие
значительных системных ресурсов. Поэтому очень важно знать время выполнения
этих ресурсоемких операций, чтобы адекватно оценивать производительность
Хранилища. Здесь может помочь детальное расписание, в котором указано время
осуществления всех операций. Если вся инфраструктура Хранилища данных или ее
отдельные части также работают с другими приложениями, не относящимися к
Хранилищу, то необходимо иметь представление о потребностях этих приложений в
ресурсах и о расписании их работы. Это относится и к инфраструктуре,
использующей совместные устройства хранения (NAS, SAN и др.), поскольку их
отдельные компоненты могут являться общими и для других приложений.
Ограниченность ресурсов в среде совместных устройств хранения бывает нелегко
диагностировать в среде функционирования Хранилища данных. Успех, который
Хранилища имели в обеспечении бизнеса информацией и знаниями, привел к тому,
что сегодня они должны быть доступными для пользователей круглосуточно семь
дней в неделю. А это обязывает менеджеров Хранилищ данных и общей
инфраструктуры обеспечивать необходимую поддержку и настройку Хранилищ без
ограничений их доступности и производительности.
Успех, который
Хранилища имели в обеспечении бизнеса информацией и знаниями, привел к тому,
что сегодня они должны быть доступными для пользователей круглосуточно семь
дней в неделю. А это обязывает менеджеров Хранилищ данных и общей
инфраструктуры обеспечивать необходимую поддержку и настройку Хранилищ без
ограничений их доступности и производительности.
Профилактические проверки
Существует несколько профилактических операций наблюдения, которые
необходимо осуществлять в среде работы Хранилища данных для того, чтобы
избежать общих нарушений, которые могут влиять на производительность и
доступность Хранилища. Области, в которых следует проводить подобные проверки,
включают системы файлов, базы данных, сектора временного хранения данных,
табличные пространства баз данных, журнальные файлы и архивы. Также необходимо
оценивать загруженность центрального процессора и памяти, время ожидания
ввода-вывода, скорость передачи данных в каналах сетевой связи, скорость
буферной памяти (т. е. скорость, с которой данные передаются из памяти на диск)
и т.д. В зависимости от размера, избыточности, способности восстанавливаться
после отказа, общего распределения и гибкости среды Хранилища данных такой
мониторинг может потребоваться на многих уровнях и серверах инфраструктуры.
Менеджер Хранилища данных должен иметь полное представление об этих операциях
мониторинга, используемых инструментах и осуществляемых измерениях, а также о
пороговых значениях, при которых в инфраструктуре генерируются предупреждения и
предпринимаются профилактические действия. Все это позволит ему лучше понимать
план предпринимаемых действий и поможет согласовать ожидания пользователей с
возможностями системы.
е. скорость, с которой данные передаются из памяти на диск)
и т.д. В зависимости от размера, избыточности, способности восстанавливаться
после отказа, общего распределения и гибкости среды Хранилища данных такой
мониторинг может потребоваться на многих уровнях и серверах инфраструктуры.
Менеджер Хранилища данных должен иметь полное представление об этих операциях
мониторинга, используемых инструментах и осуществляемых измерениях, а также о
пороговых значениях, при которых в инфраструктуре генерируются предупреждения и
предпринимаются профилактические действия. Все это позволит ему лучше понимать
план предпринимаемых действий и поможет согласовать ожидания пользователей с
возможностями системы.
Проверки инфраструктуры
Существует несколько достаточно простых тестов, которые можно проводить при
выявлении скрытых или случайных проблем производительности в среде Хранилища
данных. Эти тесты предназначены для выявления тех проблемных областей за
пределами приложений Хранилища, которые могут указывать на сложности в
функционировании инфраструктуры. Можно написать простые скрипты или программы
для измерения времени чтения и записи файлов (например, запись и чтение файла
размером 2 гигабайта), времени выполнения запросов SQL (в приложениях и на
сервере базы данных, если это имеет место) или времени соединения с СУБД.
Данные показатели могут измеряться раз в несколько минут круглосуточно на
протяжении всех дней в неделю. При этом все значительные отклонения от
желательного времени выполнения, неприемлемые для группы поддержки
инфраструктуры и пользователей, должны быть тщательно изучены и поняты в
аспекте их влияния на среду Хранилища данных. Например, умеренно сложный
SQL-оператор, выполнение которого в Хранилище обычно занимает одну минуту, дает
некоторый разброс производительности при измерении раз в несколько минут на
протяжении недели. При этом необходимо понять, выходят ли полученные отклонения
за ожидаемые пределы, и определить, какие именно операции обработки и/или
компоненты инфраструктуры вызывают данные отклонения.
Можно написать простые скрипты или программы
для измерения времени чтения и записи файлов (например, запись и чтение файла
размером 2 гигабайта), времени выполнения запросов SQL (в приложениях и на
сервере базы данных, если это имеет место) или времени соединения с СУБД.
Данные показатели могут измеряться раз в несколько минут круглосуточно на
протяжении всех дней в неделю. При этом все значительные отклонения от
желательного времени выполнения, неприемлемые для группы поддержки
инфраструктуры и пользователей, должны быть тщательно изучены и поняты в
аспекте их влияния на среду Хранилища данных. Например, умеренно сложный
SQL-оператор, выполнение которого в Хранилище обычно занимает одну минуту, дает
некоторый разброс производительности при измерении раз в несколько минут на
протяжении недели. При этом необходимо понять, выходят ли полученные отклонения
за ожидаемые пределы, и определить, какие именно операции обработки и/или
компоненты инфраструктуры вызывают данные отклонения.
Заключение
На эффективность работы среды Хранилища данных может влиять множество как
прямых, так и косвенных факторов. Для удовлетворения ожиданий пользователей
необходимо хорошо понимать все операции обработки данных, осуществляемые в
инфраструктуре, которые могут иметь значение для эффективности работы и
доступности Хранилища. При изучении случайных или непредсказуемых аномалий
производительности в среде Хранилища данных можно использовать целый ряд
достаточно простых тестов и измерений. Эти тесты способствуют выявлению
вариабельности в производительности инфраструктуры, что позволяет понять,
связана ли та или иная проблема именно с Хранилищем данных или нет.
Для удовлетворения ожиданий пользователей
необходимо хорошо понимать все операции обработки данных, осуществляемые в
инфраструктуре, которые могут иметь значение для эффективности работы и
доступности Хранилища. При изучении случайных или непредсказуемых аномалий
производительности в среде Хранилища данных можно использовать целый ряд
достаточно простых тестов и измерений. Эти тесты способствуют выявлению
вариабельности в производительности инфраструктуры, что позволяет понять,
связана ли та или иная проблема именно с Хранилищем данных или нет.
Публикации
Майкл Дженнинз (Michael Jennings). Производительность Хранилищ данных: проблемы и способы решения (Performance Impacts on the Data Warehouse Environment). Части 1 и 2.
1 Высокоскоростные выделенные каналы связи с системой хранения данных (прим. переводчика).
Автор: По материалам зарубежных сайтов
Глобальные данные модели путем создания хранилищ данных
Глобальные данные модели путем создания хранилищ данных
Хранилище данных является репозиторием, к которому можно записать данные, и от которого можно считать данные, не имея необходимость соединять сигнал ввода или вывода непосредственно с хранилищем данных. Хранилища данных доступны через уровни модели, таким образом, подсистемы и модели, на которые ссылаются, могут использовать хранилища данных, чтобы осуществлять обмен данными, не используя порты I/O. Чтобы решить, использовать ли хранилища данных, смотрите Основы Хранилища данных.
Хранилища данных доступны через уровни модели, таким образом, подсистемы и модели, на которые ссылаются, могут использовать хранилища данных, чтобы осуществлять обмен данными, не используя порты I/O. Чтобы решить, использовать ли хранилища данных, смотрите Основы Хранилища данных.
Примеры хранилища данных
Обзор
Следующие примеры иллюстрируют методы для определения и доступа к хранилищам данных. Смотрите Хранилище данных Порядка доступ для методов, которые управляют доступом к хранилищу данных в зависимости от времени, таким как обеспечение, что хранилище определенных данных всегда пишется, прежде чем оно будет считано. Смотрите Диагностику Хранилища данных для методов, которые можно использовать, чтобы помочь обнаружить и откорректировать потенциальные ошибки хранилища данных, не будучи должен запустить любые симуляции.
Локальный пример хранилища данных
Следующая модель иллюстрирует создание и доступ локального хранилища данных, которое отображается только в или конкретной подсистеме модели.
Эта модель использует хранилище данных, чтобы разрешить подсистеме сигнализировать, что ее выход недопустим.
Если А подсистемы выход недопустим, модель использует выход подсистемы B.
Пример хранилища глобальных данных
Следующая модель заменяет подсистемы предыдущего примера с функционально идентичными моделями, на которые ссылаются, чтобы проиллюстрировать использование хранилища глобальных данных, чтобы осуществлять обмен данными в иерархии модели — ссылки.
В этом примере топ-модель использует объект сигнала в MATLAB® рабочая область, чтобы задать ошибочное хранилище данных. Это необходимо, потому что хранилища данных отображаются через контуры модели, только если они заданы объектами сигнала в рабочем пространстве MATLAB или словаре данных. Модель задает код для PreLoadFcn параметр коллбэка модели, который создает объект сигнала. Этот код выполняется перед загрузками модели.
Создайте и примените хранилища данных
Следующее является общим рабочим процессом для конфигурирования хранилищ данных.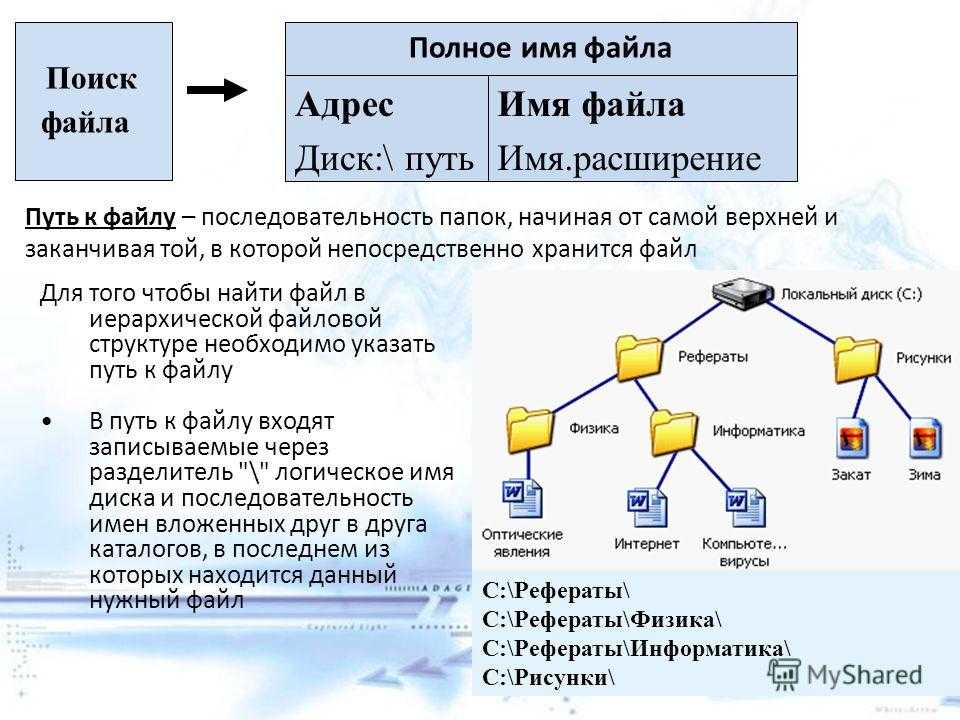 Можно выполнить задачи в различном порядке, или отдельно от остальных, в зависимости от того, как вы используете хранилища данных.
Можно выполнить задачи в различном порядке, или отдельно от остальных, в зависимости от того, как вы используете хранилища данных.
Где применимо, план ваше использование хранилищ данных, чтобы минимизировать их эффект на верификации программного обеспечения. Для получения дополнительной информации смотрите Верификация программного обеспечения и Хранилища данных.
Создайте хранилища данных с помощью методов, описанных в Хранилищах данных с Блоками памяти Хранилища данных или Хранилищах данных с Объектами Сигнала. Для большей надежности рассмотрите присвоение вместо того, чтобы наследовать атрибуты хранилища данных, как описано в Определении Атрибутов Блока памяти Хранилища данных.
Добавьте к блокам Чтения Записи и Хранилища данных Хранилища данных модели, чтобы записать в и читать из хранилищ данных, как описано в Хранилищах Доступа к данным с блоками Simulink.
Сконфигурируйте модель и блоки что доступ каждое хранилище данных, чтобы избежать отказов параллелизма при чтении и записи хранилища данных, как описано в Хранилище данных Порядка доступ.

Примените методы, описанные в Диагностике Хранилища данных по мере необходимости, чтобы предотвратить ошибки хранилища данных или диагностировать их, если они происходят в процессе моделирования.
Если вы намереваетесь сгенерировать код для своей модели, смотрите Хранилища данных в Сгенерированном коде (Simulink Coder).
Чтобы создать хранилище данных, вы создаете блок Data Store Memory или Simulink.Signal объект. Блок или объект сигнала представляют хранилище данных и задают его свойства. Каждое хранилище данных должно иметь уникальное имя.
Блок Data Store Memory реализует локальное хранилище данных. Смотрите Хранилища данных с Блоками памяти Хранилища данных.
Simulink.Signalобъект может действовать как хранилище локальных или глобальных данных. Смотрите Хранилища данных с Объектами Сигнала.
Хранилища данных реализовали с Блоками памяти Хранилища данных:
Поддержите инициализацию хранилища данных
Обеспечьте управление осциллографа хранилища данных и опций на определенных уровнях в иерархии модели
Потребуйте, чтобы блок представлял хранилище данных
Не может быть получен доступ в моделях, на которые ссылаются,
Не может быть в подсистеме, которая Для Каждого блока Subsystem представляет.
Хранилища данных реализованы с Simulink.Signal объекты:
Обеспечьте управление всей модели осциллографа хранилища данных и опций
Не требуйте, чтобы блок представлял хранилище данных
Может быть получен доступ в моделях, на которые ссылаются, если хранилище данных является глобальной переменной
Бойтесь приравнивать локальные хранилища данных с Блоками памяти Хранилища данных и хранилища глобальных данных с Simulink.Signal объекты. Любой метод может задать локальное хранилище данных, и объект сигнала может задать или локальную переменную или хранилище глобальных данных.
Хранилища данных с блоками памяти хранилища данных
Создание хранилища данных
Определение атрибутов блока памяти хранилища данных
Создание хранилища данных
Чтобы использовать Блок памяти Хранилища данных, чтобы задать хранилище данных, перетащите экземпляр блока в модель на самом верхнем уровне, от которого вы хотите, чтобы хранилище данных отобразилось. Результатом является локальное хранилище данных, которое не доступно в моделях, на которые ссылаются.
Результатом является локальное хранилище данных, которое не доступно в моделях, на которые ссылаются.
Чтобы задать хранилище данных, которое отображается на каждом уровне в данной модели, кроме в блоках Model, перетаскивают Блок памяти Хранилища данных на корневой уровень модели.
Чтобы задать хранилище данных, которое отображается только в конкретной подсистеме и подсистемах, которые это содержит, но не в блоках Model, перетаскивают Блок памяти Хранилища данных в подсистему.
Если вы добавили Блок памяти Хранилища данных, используйте его параметры, чтобы задать свойства хранилища данных. Свойство Имени хранилища данных задает имя хранилища данных, что Чтение Записи и Хранилища данных Хранилища данных блокирует доступ. См. документацию Data Store Memory для деталей.
Можно указать, что свойства хранилища данных вне определимых параметрами Блока памяти Хранилища данных путем выбора Имени хранилища данных должны решить к опции объекта Сигнала Simulink и использованию объекта сигнала как имя хранилища данных. Смотрите, что Атрибуты Определения используют Объект сигнала для деталей.
Смотрите, что Атрибуты Определения используют Объект сигнала для деталей.
Определение атрибутов блока памяти хранилища данных
Блок памяти Хранилища данных может наследовать три атрибута данных от своих соответствующих блоков Записи Чтения и Хранилища данных Хранилища данных. Наследуемые атрибуты:
Тип данных
Сложность
Размер шага
Однако разрешение этих атрибутов быть наследованным может вызвать неожиданные результаты, которые могут затруднить отладку. Чтобы предотвратить такие ошибки, используйте диалоговое окно Блока памяти Хранилища данных или Simulink.Signal объект задать атрибуты явным образом.
Определение атрибутов Используя параметры блоков
Можно использовать диалоговое окно Блока памяти Хранилища данных или вкладку Model Data Editor Data Stores (во вкладке Modeling, нажмите Model Data Editor) задавать тип данных и сложность хранилища данных. На следующем рисунке диалоговое окно блока устанавливает Data type на
На следующем рисунке диалоговое окно блока устанавливает Data type на uint16 и Signal type к real.
Определение атрибутов, использующих объект сигнала
Можно использовать Simulink.Signal объект задать хранилище данных приписывает для Блока памяти Хранилища данных.
Следующий рисунок показывает Блок памяти Хранилища данных, который задает разрешение Simulink.Signal объект, названный A. Чтобы использовать объект сигнала для хранилища данных, установите Data store name на имя объекта сигнала. В течение времени компиляции, проверяя, откройте вкладку Signal Attributes и выберите параметр Data store name must resolve to Simulink signal object.
В качестве альтернативы на вкладке Model Data Editor Data Stores (на вкладке Modeling, нажмите Model Data Editor), редактируя имя хранилища данных, кликните по соседней кнопке действий и выберите . В диалоговом окне Create New Data, набор Value к
В диалоговом окне Create New Data, набор Value к Simulink.Signal.
Объект сигнала задает значения для всех трех атрибутов данных, которые в противном случае наследовало бы хранилище данных. В этом примере, который задает локальное хранилище данных, Simulink.Signal объект A имеет следующие унаследованные свойства: DataType, Complexity, и SampleTime.
A =
Simulink.Signal (handle)
CoderInfo: [1x1 Simulink.CoderInfo]
Description: ''
DataType: 'auto'
Min: []
Max: []
Unit: ''
Dimensions: 1
DimensionsMode: 'auto'
Complexity: 'auto'
SampleTime: -1
InitialValue: 0Для получения дополнительной информации об определении атрибутов объектов сигнала для хранилищ локальных и глобальных данных, смотрите Атрибуты объектов Сигнала для Хранилищ данных.
Используйте Model Data Editor, чтобы Сконфигурировать Блоки Data Store Memory в Списке.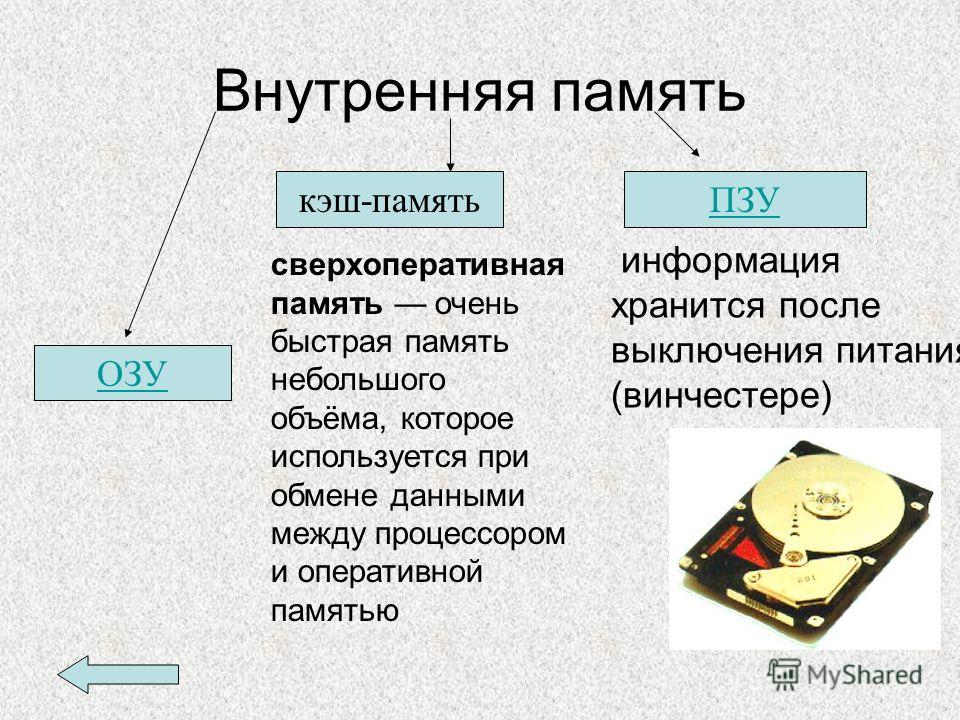 Используйте вкладку Data Stores в Model Data Editor, чтобы сконфигурировать параметры блока Data Store Memory. Используйте этот метод, чтобы сконфигурировать хранилище данных, не определяя местоположение его в модели и сконфигурировать хранилище данных вместе с другими интерфейсными элементами, такими как блоки Outport и Inport. Model Data Editor также показывает вам информацию для Data Store Read и блоков Data Store Write в том же списке.
Используйте вкладку Data Stores в Model Data Editor, чтобы сконфигурировать параметры блока Data Store Memory. Используйте этот метод, чтобы сконфигурировать хранилище данных, не определяя местоположение его в модели и сконфигурировать хранилище данных вместе с другими интерфейсными элементами, такими как блоки Outport и Inport. Model Data Editor также показывает вам информацию для Data Store Read и блоков Data Store Write в том же списке.
Чтобы открыть Model Data Editor, во вкладке Modeling, нажимают Model Data Editor.
Хранилища данных с объектами сигнала
Создание хранилища данных
Хранилища локальных и глобальных данных
Атрибуты объектов сигнала для хранилищ данных
Создание хранилища данных
Использовать Simulink.Signal объект задать хранилище данных, не используя Блок памяти Хранилища данных, создайте объект сигнала в рабочей области, которая отображается к каждому компоненту, который должен получить доступ к хранилищу данных. Имя связанного хранилища данных является именем объекта сигнала. Можно использовать это имя в блоках Записи Чтения и Хранилища данных Хранилища данных, так же, как если бы это было Имя хранилища данных Блока памяти Хранилища данных. Simulink® создает связанное хранилище данных, когда вы используете объект сигнала для хранения данных.
Имя связанного хранилища данных является именем объекта сигнала. Можно использовать это имя в блоках Записи Чтения и Хранилища данных Хранилища данных, так же, как если бы это было Имя хранилища данных Блока памяти Хранилища данных. Simulink® создает связанное хранилище данных, когда вы используете объект сигнала для хранения данных.
Хранилища локальных и глобальных данных
Можно использовать Simulink.Signal объект задать или локальную переменную или хранилище глобальных данных.
Если вы задаете объект в базовом рабочем пространстве MATLAB или словаре данных, результатом является хранилище глобальных данных, которое доступно в каждой модели в Simulink, включая все модели, на которые ссылаются.
Если вы создаете объект в рабочем пространстве модели, результатом является локальное хранилище данных, которое доступно на каждом уровне в модели кроме любых моделей, на которые ссылаются.
Атрибуты объектов сигнала для хранилищ данных
Те атрибуты хранилища данных, которые не задает объект сигнала, имеют те же значения по умолчанию, которые они делают в Блоке памяти Хранилища данных. Значения свойств объекта сигнала, используемого в качестве хранилища данных, имеют различные требования, в зависимости от того, локально ли хранилище данных или глобально.
Значения свойств объекта сигнала, используемого в качестве хранилища данных, имеют различные требования, в зависимости от того, локально ли хранилище данных или глобально.
Если вы создали объект, установил свойства объекта сигнала к значениям, которые вы хотите соответствующие свойства хранилища данных иметь. Например, следующие команды задают хранилище данных под названием Error в базовом рабочем пространстве MATLAB:
Error = Simulink.Signal; Error.Description = 'Use to signal that subsystem output is invalid'; Error.DataType = 'boolean'; Error.Complexity = 'real'; Error.Dimensions = 1; Error.SampleTime = 0.1;
Атрибуты для Локальных Хранилищ данных. Для локального хранилища данных, для каждого описанного ниже параметра, можно или установить значение явным образом, или у вас может быть хранилище данных, наследовали значение от блоков Чтения Записи и Хранилища данных Хранилища данных.
DataTypeComplexitySampleTime
Чтобы задать локальное хранилище данных с помощью Блока памяти Хранилища данных, можно использовать объект сигнала для параметра Data store name. В течение времени компиляции, проверяя, во вкладке Signal Attributes, выбирают параметр Data store must resolve to Simulink signal object. Параметр Data store must resolve to Simulink signal object заставляет Simulink отображать ошибку и компиляцию остановки, если Simulink не может найти объект сигнала или если свойства объектов сигнала противоречивы со свойствами объектов сигнала.
В течение времени компиляции, проверяя, во вкладке Signal Attributes, выбирают параметр Data store must resolve to Simulink signal object. Параметр Data store must resolve to Simulink signal object заставляет Simulink отображать ошибку и компиляцию остановки, если Simulink не может найти объект сигнала или если свойства объектов сигнала противоречивы со свойствами объектов сигнала.
Атрибуты для Хранилищ Глобальных данных. Следующая таблица описывает требования параметра для хранилищ глобальных данных.
| Параметр | Значение хранилища глобальных данных |
|---|---|
DataType | Должен быть установлен явным образом |
Complexity | Должен быть установлен явным образом |
Dimensions | Может быть установлен или наследован |
SampleTime | Может быть установлен или наследован |
Измените Атрибуты Хранилища данных, Заданного Объектом Сигнала. Можно использовать Model Data Editor (во вкладке Modeling, нажмите Model Data Editor) изменить и смотреть атрибуты хранилищ данных, Data Store Read и блоков Data Store Write. На вкладке Data Stores, чтобы показать атрибуты хранилищ данных, что вы задаете при помощи объектов сигнала (таких как
Можно использовать Model Data Editor (во вкладке Modeling, нажмите Model Data Editor) изменить и смотреть атрибуты хранилищ данных, Data Store Read и блоков Data Store Write. На вкладке Data Stores, чтобы показать атрибуты хранилищ данных, что вы задаете при помощи объектов сигнала (таких как Simulink.Signal), нажмите кнопку Show/refresh additional information. Затем если блок Data Store Read или Data Store Write, показанный в таблице данных, относится к хранилищу данных, заданному объектом сигнала, таблица включает строку, которая соответствует объекту.
Для получения дополнительной информации смотрите Model Data Editor.
Хранилища Доступа к данным с блоками Simulink
Запись в хранилище данных
Чтение от хранилища данных
Доступ к хранилищу глобальных данных
Запись в хранилище данных
Устанавливать значение хранилища данных на каждом временном шаге:
Создайте экземпляр блока Data Store Write на уровне вашей модели, которая вычисляет значение.

Установите параметр Имени хранилища данных блока Data Store Write на имя хранилища данных, к которому вы хотите, чтобы он записал данные.
Соедините выход блока, который вычисляет значение к входу блока Data Store Write.
Чтение от хранилища данных
Получить значение хранилища данных на каждом временном шаге:
Создайте экземпляр блока Data Store Read на уровне вашей модели, для которой нужно значение.
Установите параметр Имени хранилища данных блока Data Store Read на имя хранилища данных, из которого вы хотите, чтобы он читал.
Соедините выход блока Data Store Read к входу блока, которому нужно значение хранилища данных.
Доступ к хранилищу глобальных данных
Когда соединено с хранилищем глобальных данных (то, которое задано объектом сигнала в рабочем пространстве MATLAB), блок Data Store Read или Data Store Write отображает слово global выше имени хранилища данных.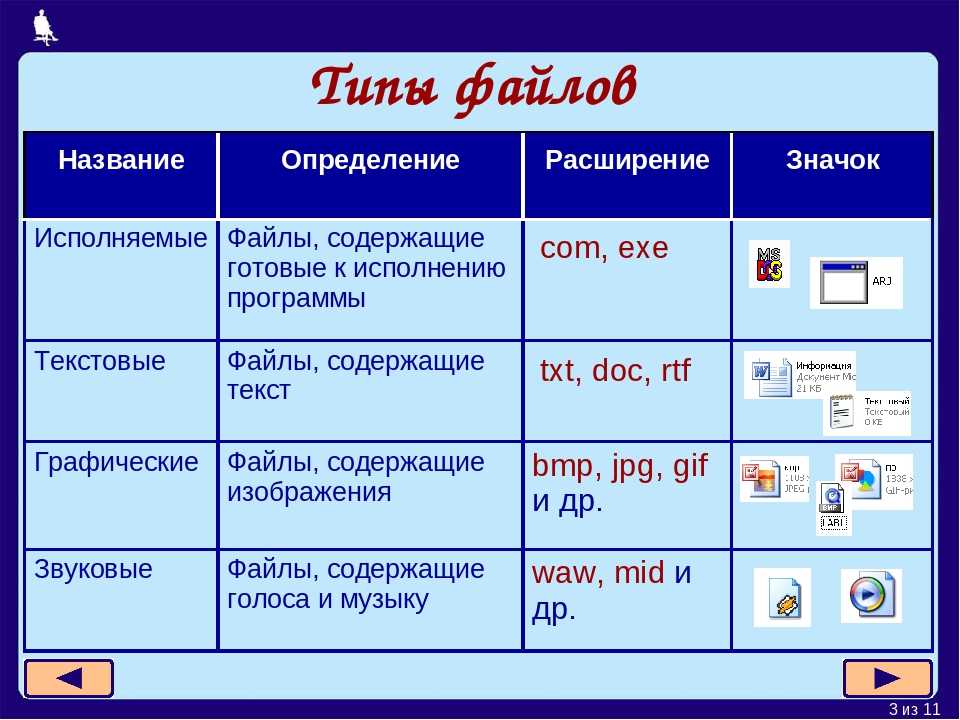
Закажите хранилищу данных доступ
О хранилище данных доступ к порядку
Упорядоченное расположение доступа Используя подсистемы вызова функции
Упорядоченное расположение доступа Используя приоритеты блока
О хранилище данных доступ к порядку
Чтобы получить правильные результаты хранилищ данных, необходимо управлять порядком выполнения чтений и записей хранилища данных. Если чтение хранилища данных происходит перед его записью задержка вводится в алгоритм: чтение получает значение, которое было вычислено и сохранено в предыдущем временном шаге, а не значении, вычисленном и сохраненном на шаге текущего времени.
Такая задержка может заставить систему вести себя кроме, как спроектировано, и в некоторых случаях может дестабилизировать систему. Даже если эти проблемы не происходят, неконтролируемый порядок доступа мог бы измениться от одного релиза Simulink к следующему.
В этом разделе описываются несколько стратегий того, чтобы явным образом управлять порядком выполнения чтений и записей хранилища данных. Смотрите Диагностику Хранилища данных для методов, которые можно использовать, чтобы обнаружить и откорректировать потенциальные ошибки хранилища данных без рабочих симуляций.
Смотрите Диагностику Хранилища данных для методов, которые можно использовать, чтобы обнаружить и откорректировать потенциальные ошибки хранилища данных без рабочих симуляций.
Упорядоченное расположение доступа Используя подсистемы вызова функции
Можно использовать подсистемы вызова функции, чтобы управлять порядком выполнения компонентов модели тот доступ хранилища данных. Следующий рисунок показывает этот метод:
Подсистема Before содержит Запись Хранилища данных и Stateflow® стройте диаграмму вызовов, что подсистема, прежде чем она вызовет подсистему After, который содержит Чтение Хранилища данных.
Упорядоченное расположение доступа Используя приоритеты блока
Можно встроить чтения хранилища данных и записи в атомарных подсистемах или блоках Model, приоритеты которых задают свой относительный порядок выполнения.
Блок Model beforeDSM имеет более низкий приоритет затем afterDSM, таким образом, это, как гарантируют, выполнится сначала. Начиная с
Начиная с beforeDSM является атомарным, все его операции, включая Запись Хранилища данных, выполнятся до afterDSM и все его операции, включая Чтение Хранилища данных.
Хранилища данных с шинами и массивами шин
Преимущества использования хранилищ данных с шинами и массивами шин включают:
Упрощение макета модели путем соединения нескольких сигналов с одним хранилищем данных
Создание сгенерированного кода, который представляет данные в данных о хранилище как структуры, которые отражают иерархию шины
Запись в и чтение от хранилищ данных, не создавая копии данных, который приводит к более эффективному доступу к данным
Вы не можете использовать шину или массив шин, который содержит:
Подготовка модели, чтобы использовать хранилища данных с шинами и массивами шин
Эта процедура применяется к хранилищам локальных и глобальных данных, и к хранилищам данных, заданным с Блоком памяти Хранилища данных или Simulink. объект. Прежде, чем выполнить процедуру, необходимо изучить, как использовать хранилища данных в модели, как описано в Создают и Применяют Хранилища данных. Signal
Signal
Использовать шины и массивы шин с хранилищами данных:
Используйте Редактор Шины, чтобы задать объект шины, свойства которого совпадают с данными о шине, в которые вы хотите записать и считать из хранилища данных. Для получения дополнительной информации смотрите, Создают и Задают Объекты Simulink.Bus.
Добавьте хранилище данных (использующий блок Data Store Memory или
Simulink.Signalобъект) для того, чтобы хранить данные о шине.Задайте объект шины как тип данных хранилища данных. Для получения дополнительной информации смотрите, Задают Тип данных Object Шины.
Если вы используете структуру MATLAB для начального значения хранилища данных, то установленный > > > > к
Simplified. Для получения дополнительной информации смотрите, Задают Начальные условия для обнаружения инициализации Bus Elements и Underspecified.
(Необязательно) Избранный индивидуум соединяет шиной элементы, чтобы записать в или читать из хранилища данных. Для получения дополнительной информации смотрите Получающую доступ Определенную Шину и Элементы матрицы.
Доступ к определенной шине и элементам матрицы
Выбор определенной шины или элементов матрицы
По умолчанию модель пишет и читает всю шину и элементы матрицы к и от хранилища данных.
Чтобы выбрать определенную шину или элементы матрицы, чтобы записать в или читать из хранилища данных, используйте панель Element Assignment блока Data Store Write и панель Element Selection блока Data Store Read. Выбор определенной шины или элементов матрицы предлагает следующие преимущества:
Сокращение количества блоков в модели. Например, можно устранить пару блока Селектора Чтения и Шины Хранилища данных или пару блока Data Store Write и Bus Assignment для каждого определенного элемента шины, к которому вы хотите получить доступ).
Более быстрая симуляция моделей с большими шинами и массивами шин.
Запись определенных элементов к хранилищу данных
Присваивать определенную шину или элементы матрицы, чтобы записать в хранилище данных:
Выберите блок Data Store Write и в диалоговом окне параметров, выберите панель Element Assignment. Например, предположите, что вы используете шину с хранилищем данных под названием
DSM:Расширьте все элементы в списке Signals in the bus.
Укажите элементы, которые вы хотите записать в хранилище данных. Например:
В списке Signals in the bus нажмите
B. Затем нажмите Select>>, чтобы выбрать элементB.Записать все элементы
A2(вAвложенная шина), выберитеA2[5,1]. Затем нажмите Select>>.Записать второй элемент
A2вC2вложенная шина, выберитеA2[5,1]элемент. В текстовом поле Specify element(s) to assign отредактируйте текст, чтобы сказать
В текстовом поле Specify element(s) to assign отредактируйте текст, чтобы сказать DSM.C.C2.A2(2,1).
Для большего количества примеров смотрите Указывающие Элементы, чтобы Присвоить или Выбрать.
(Необязательно) Переупорядочивают присвоенные элементы, который изменяет порядок портов блока Data Store Write.
Чтобы переупорядочить присвоенный элемент, в списке Assigned element(s), выбирают элемент, который вы хотите переместить и нажать Up или Down.
Чтобы удалить присвоенный элемент, нажмите Remove.
Чтобы применить присвоенные элементы, нажмите OK.
Блок Data Store Write имеет порт для каждого присвоенного элемента. Имена выбранных элементов, которые соответствуют каждому порту, появляются в значке блока. Если вы присваиваете несколько сигналов, эти сложения могут уменьшить удобочитаемость модели.
 Чтобы улучшить удобочитаемость, можно расширить размер блока или создать несколько блоков Data Store Write.
Чтобы улучшить удобочитаемость, можно расширить размер блока или создать несколько блоков Data Store Write.
Чтение определенных элементов от хранилища данных
Чтение определенных элементов от хранилища данных включает очень похожие шаги как описано в Записи Определенных Элементов к Хранилищу данных. Блок Data Store Read отличается немного от блока Data Store Write. Блок Data Store Read имеет:
Указывание элементов, чтобы присвоить или выбрать
Используйте синтаксис элемента матрицы MATLAB, чтобы указать определенные элементы. Для получения дополнительной информации об определении матриц в MATLAB, смотрите Создание, конкатенацию и расширение матрицы.
Допустимые технические требования элемента. Следующая таблица показывает примеры допустимого синтаксиса для того, чтобы указать элементы, чтобы присвоить или выбрать. Эти примеры используют A2 вложенная шина A соедините шиной, как показано в иерархии шины, используемой в записи Определенных Элементов к Хранилищу данных.
| Допустимый синтаксис | Описание |
|---|---|
DSM.A.A2(:,:) | Выбирает все элементы в каждой размерности |
DSM.A.A2([1,3,5],1) | Выбирает первые, третьи, и пятые элементы |
DSM.A.A2(2:5,1) | Выбирает второе через Пятый элемент |
Недопустимые технические требования элемента. Следующая таблица показывает примеры недопустимого синтаксиса для того, чтобы указать элементы, чтобы присвоить или выбрать. Эти примеры используют A2 вложенная шина A соедините шиной, как показано в иерархии шины, используемой в записи Определенных Элементов к Хранилищу данных.
| Недопустимый синтаксис | Обоснуйте, что синтаксис недопустим |
|---|---|
DSM.A.A2(:) | Необходимо задать двоеточие для каждой размерности. |
DSM.A.A2(2:end,1) | Вы не можете использовать |
DSM.A.A2(idx,1) | Вы не можете использовать переменные, чтобы задать индексы. Рассмотрите использование динамической индексации путем выбора Enable indexing на Element Selection / панель Element Assignment диалогового окна параметров блоков. Смотрите Data Store Read и Data Store Write. |
DSM.A.A2(-1,1) | Размерность |
 Для иерархии шины, используемой в этих примерах, необходимо использовать два двоеточия.
Для иерархии шины, используемой в этих примерах, необходимо использовать два двоеточия.Спецификация с помощью командной строки. Чтобы установить элементы писать в или читать из, используйте DataStoreElements параметр. Используйте знак фунта (#), чтобы разграничить несколько элементов. Например, выберите блок Data Store Write или Data Store Read, для которого вы хотите указать элементы и ввести команду, такую как:
set_param(gcb, 'DataStoreElements', 'DSM.A#DSM.B#DSM.C(3,4)')
Эта спецификация приводит к блоку, теперь имеющему три порта, соответствующие элементам, которые вы указали.
Переименуйте хранилища данных
Переименуйте хранилище данных, заданное блоком
Переименуйте хранилище данных, заданное объектом сигнала
Переименуйте хранилище данных, заданное блоком
Переименуйте хранилище данных везде, оно используется Data Store Read и блоками Data Store Write в модели.
В диалоговом окне Блока памяти Хранилища данных введите новое имя в поле Data store name и нажмите Rename All.
В диалоговом окне Rename All подтвердите новое имя хранилища данных в поле New name и нажмите OK
Переименуйте хранилище данных, заданное объектом сигнала
В этом примере показано, как переименовать хранилище данных, заданное Simulink.Signal объект. Можно использовать Model Explorer, чтобы переименовать объект везде, это используется Data Store Read и блоками Data Store Write в модели или в иерархии модели — ссылки.
Откройте модель
sldemo_mdlref_dsm. Модель создаетSimulink.SignalобъектErrorCondв базовом рабочем пространстве MATLAB и использовании объект как глобальные данные хранят в иерархии модели — ссылки.Открытый Model Explorer.
В панели Model Hierarchy выберите базовое рабочее пространство.
В панели Contents щелкните правой кнопкой по хранилищу данных
ErrorCondи выберите Rename All.В диалоговом окне Select a system кликните по имени модели
sldemo_mdlref_dsmвыбрать его как контекст для переименования хранилища данныхErrorCond.Выберите Search in referenced models начиная с
ErrorCondхранилище глобальных данных, которое используется в модели, на которую ссылаются. Нажмите OK.Флажок Update diagram to include recent changes снимается по умолчанию, чтобы сэкономить время путем предотвращения ненужных обновлений диаграммы модели.
 Установите флажок, чтобы включить недавние изменения, которые вы внесли в модель путем принуждения обновления схемы.
Установите флажок, чтобы включить недавние изменения, которые вы внесли в модель путем принуждения обновления схемы.Нажмите OK в ответ на сообщение, чтобы обновить диаграмму модели.
Поскольку вы только открыли модель, необходимо обновить диаграмму модели, по крайней мере, однажды переименование переменной, такой как
ErrorCond. Вы, возможно, выбрали Update diagram to include recent changes в диалоговом окне Select a system, чтобы обеспечить начальное обновление схемы, хотя вы обычно используете ту опцию, когда вы вносите изменения в модель при выполнении нескольких переменных операций переименования.В диалоговом окне Rename All введите новое имя для хранилища данных в поле New name и нажмите OK.
Индивидуально настраиваемые функции доступа хранилища данных в сгенерированном коде
Embedded Coder® обеспечивает класс памяти, который можно использовать, чтобы задать настроенные функции доступа хранилища данных в сгенерированном коде.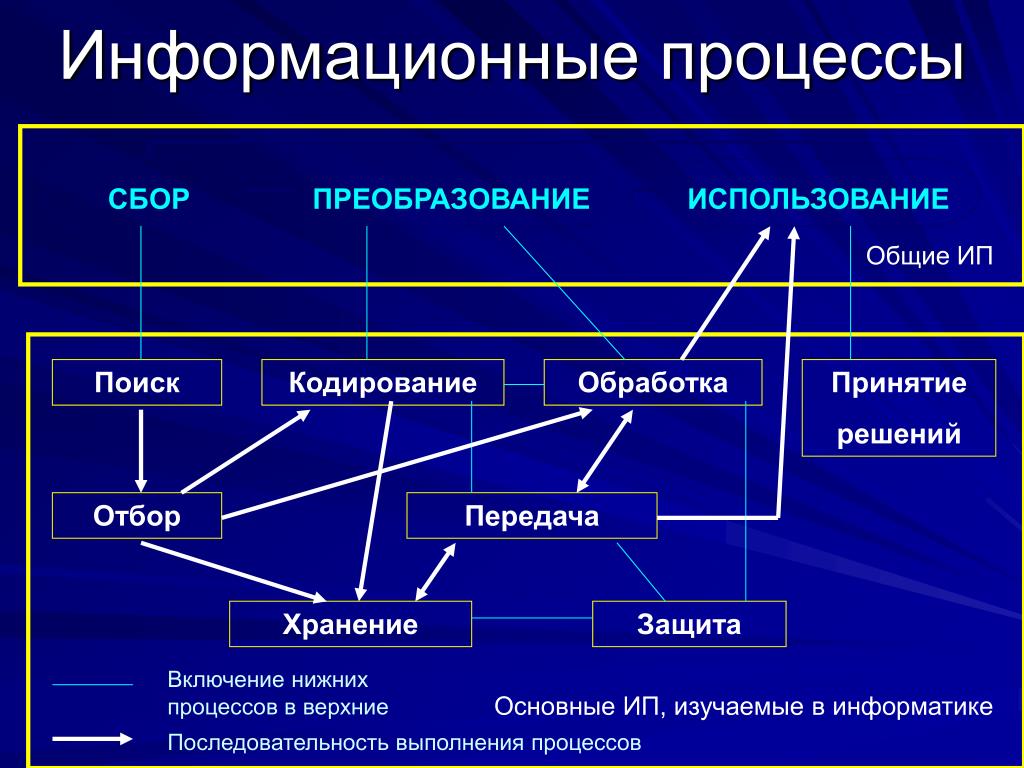 Смотрите Организуют Данные о Параметре в Структуру при помощи Класса памяти Struct (Embedded Coder) и Доступ к данным Через Функции с Классом памяти GetSet (Embedded Coder).
Смотрите Организуют Данные о Параметре в Структуру при помощи Класса памяти Struct (Embedded Coder) и Доступ к данным Через Функции с Классом памяти GetSet (Embedded Coder).
Смотрите также
Data Store Memory | Data Store Read | Data Store Write | Simulink.Signal
Похожие темы
- Хранилища данных в сгенерированном коде (Simulink Coder)
- Хранилища данных логов
- Основы хранилища данных
- Объекты данных
- Основы сигнала
- Виртуальная шина
10 способов ускорить работу ПК с ОС Windows 10
Если вы обнаружили, что производительность вашего ПК снижается, и он работает не так, как раньше, изменение настроек Windows 10 может помочь увеличить скорость и эффективность работы ПК. Windows 10 — одна из самых эффективных операционных систем, которая используется сегодня. Но она поставляется с большим количеством функций, которые используют много системных ресурсов и могут снизить производительность ПК. В последней версии Windows 10 компания Microsoft даже добавила встроенные функции, чтобы повысить общую эффективность. Тем не менее, производительность вашего компьютера по-прежнему может оставаться низкой.
Тем не менее, производительность вашего компьютера по-прежнему может оставаться низкой.
Причиной может быть нехватка памяти, необходимость обслуживания и менее мощные аппаратные компоненты. Есть несколько вещей, которые вы можете сделать, чтобы ускорить работу Windows 10 и восстановить оптимальную производительность своего ПК до оптимальной производительности, — начиная от удаления неиспользуемых программ и приложений и до обновления оборудования
1. Проверка наличия обновлений
Один из лучших способов получить максимальную отдачу от вашего ПК — всегда устанавливать последние обновления для Windows 10. Компания Microsoft часто выпускает обновления для исправления распространенных дефектов и системных ошибок, которые снижают производительность системы. Некоторые обновления могут быть незначительными, в то время как другие могут вносить существенные изменения в систему, например, выполнять поиск последних драйверов устройств, которые могут помочь повысить производительность ПК.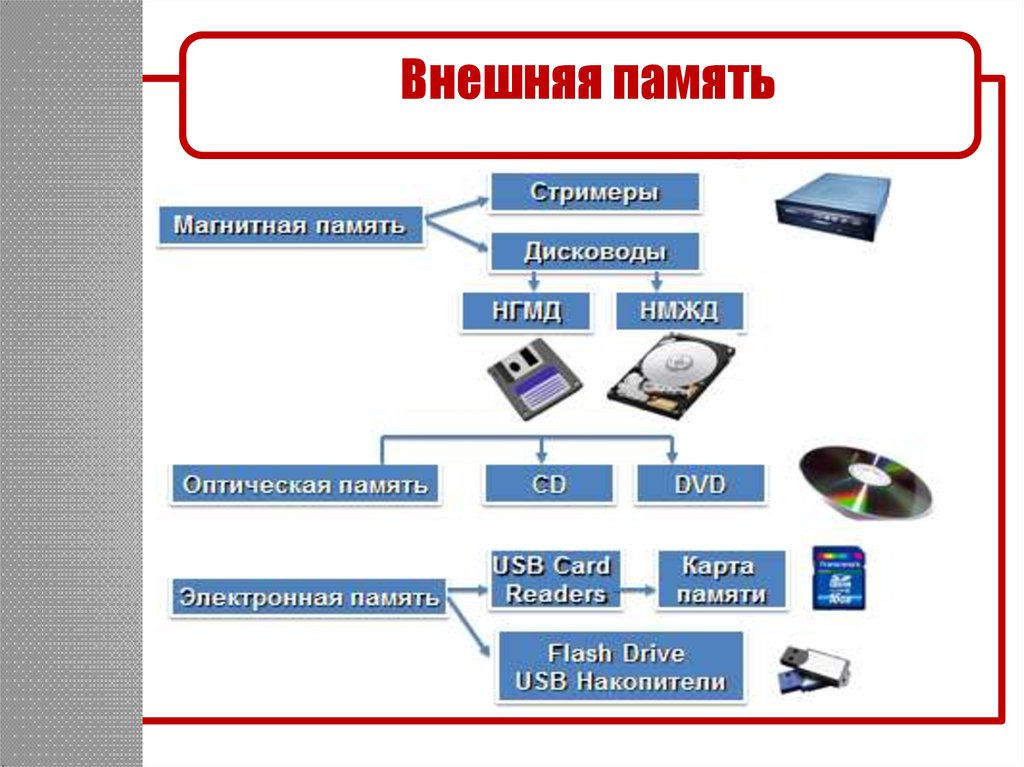
Для проверки наличия обновлений откройте меню Windows, затем выберите Параметры > Обновление и безопасность > Центр обновления Windows > Проверить наличие обновлений. Если есть доступные обновления, выберите Установить сейчас. Перезапустите ПК и проверьте, улучшилась ли его работа.
2. Перезапуск ПК
Это может показаться элементарным, но регулярный перезапуск компьютера может помочь ускорить работу системы. Многие люди не выключают свои ПК неделями, переводя компьютер в спящий режим, а не выключая его. В результате программы и рабочие нагрузки накапливаются в памяти ПК, замедляя выполнение повседневных задач, таких как запуск программ и доступ к файлам.
Ежедневное выключение компьютера позволяет очистить ОЗУ и подготовить ПК к оптимальной работе на следующий день. Если вы заметили, что ваш компьютер стал медленнее выполнять простые повседневные задачи, такие как открытие программ или доступ к файлам и документам, попробуйте выключить или перезагрузить ПК.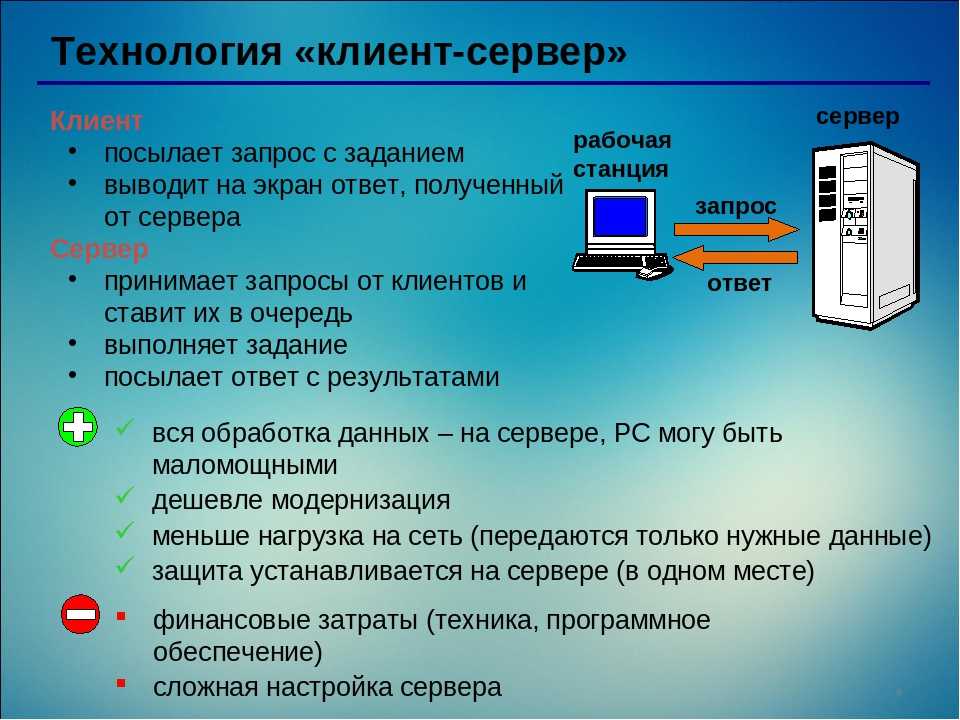 Не забудьте перед этим сохранить свою работу.
Не забудьте перед этим сохранить свою работу.
3. Отключение запуска программ при запуске системы
Производительность ПК может снизиться, если одновременно открыто много программ и приложений. Многие установщики указывают Windows запускать свои программы сразу при запуске компьютера, что снижает производительность системы.
Чтобы отключить запуск программ при запуске системы, откройте диспетчер задач и затем щелкните вкладку Автозагрузка. В столбце «Влияние на запуск» указывается, какое влияние (высокое, среднее, низкое) оказывают различные программы на запуск системы. Те из них, которые оказывают высокое влияние, являются виновниками снижения производительности системы.
Чтобы остановить загрузку программы при запуске, щелкните на ней правой кнопкой мыши и выберите «Отключить».
4. Очистка диска
Одной из встроенных функций Windows 10 является очистка диска. Она позволяет избавиться от неиспользуемых временных файлов, которые накапливаются на вашем компьютере, включая эскизы изображений, загруженные файлы программ и временные файлы Интернета.
Откройте меню Windows и с помощью строки поиска найдите программу «Очистка диска». Откроется список программных файлов для удаления. Выберите файлы, которые вы хотите удалить, установив флажки рядом с их названиями. После этого нажмите «Очистить системные файлы». Программа «Очистка диска» вычислит, какой объем памяти будет освобожден.
Потратьте время, чтобы удалить другие файлы или приложения, которые занимают место в ОЗУ или на диске. Проверьте папку «Загрузки» на наличие старых и неиспользуемых файлов, которые можно удалить.
5. Удаление старого программного обеспечения
ПК часто поставляются с предустановленными программами сторонних производителей, которые могут вам не понадобиться. Они часто называются «жирным» программным обеспечением, могут поглощать место на диске из-за своего большого размера и часто так никогда и не используются.
У вас могут быть и другие установленные, но никогда не используемые программы, что приводит к замедлению работы компьютера. Чтобы проверить, какие программы установлены, откройте меню
Чтобы проверить, какие программы установлены, откройте меню
- Панель управления > Программы > Программы и компоненты > Удаление или изменение программы.
- Щелкните правой кнопкой на программе, которая вам больше не нужна, и выберите «Удалить».
6. Отключение специальных эффектов
Windows 10 поставляется с множеством спецэффектов, которые делают внешний вид пользовательского интерфейса более приятным. Они включены по умолчанию в Windows и других функциях, запрограммированных на постепенное появление и исчезание в поле зрения. Другие спецэффекты, которые замедляют скорость работы, — прозрачность и анимация.
Откройте меню Windows, найдите меню «Система», откройте вкладку «Дополнительные параметры системы», затем «Дополнительно» и выберите «Параметры быстродействия». Щелкните вкладку «Визуальные эффекты» и нажмите переключатель «Особые эффекты». Вы увидите список визуальных эффектов, которые можно выключить, сняв галочку рядом с названием. Нажмите «Применить», чтобы подтвердить внесенные изменения.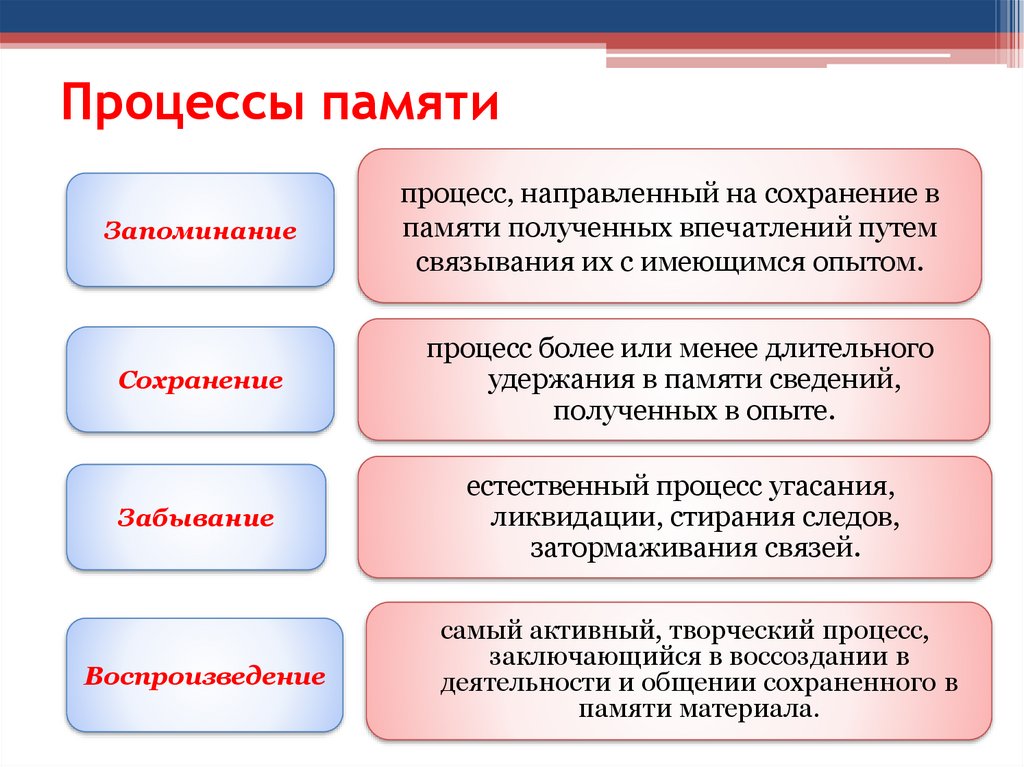
7. Отключение эффектов прозрачности
Помимо использования системных ресурсов для отображения таких функций, как анимация, Windows 10 также использует эффекты прозрачности для определенных функций, таких как меню задач. Этот, казалось бы, легкий и простой эффект на самом деле довольно сложен и требует больше системных ресурсов, чем вы думаете.
Чтобы отключить эффекты прозрачности, откройте меню Windows и введите «параметры цвета» в строке поиска, чтобы вызвать соответствующее меню для Windows 10. Прокрутите окно вниз до кнопки «Эффекты прозрачности». Нажмите кнопку, чтобы включить или отключить эти эффекты.
8. Выполнение обслуживания системы
В Windows 10 есть встроенная функция, которая выполняет стандартные задачи обслуживания системы. К ним относятся дефрагментация жесткого диска, сканирование на наличие обновлений и проверка на наличие вредоносных программ и вирусов.
Обслуживание системы обычно выполняется в фоновом режиме, когда ваш компьютер не используется, но вы можете запустить его вручную, если в системе возникла проблема, которую вы хотите проверить.
Для этого откройте панель управления и выберите «Центр безопасности и обслуживания». Щелкните стрелку, чтобы развернуть опции обслуживания, и выберите «Начать обслуживание». Вы сможете выполнить профилактическую проверку системы вручную.
9. Модернизация ОЗУ
Одним из радикальных способов повышения быстродействия и производительности вашего ПК является модернизация ОЗУ для увеличения объема памяти в вашей системе. Для плавной работы Windows 10 требуется не менее 4 ГБ памяти. Если вы используете ПК для интенсивных системных нагрузок, таких как игры или создание мультимедийных ресурсов, вы получите выигрыш от большего объема памяти.
Модернизация ОЗУ может существенно увеличить быстродействие и производительность ПК. Чтобы узнать, какой тип ОЗУ требуется для вашего ПК, откройте диспетчер задач (Ctrl + Alt + Delete) и нажмите «Производительность». Вы увидите, сколько разъемов для памяти доступно, а также тип ОЗУ, например DDR4. Узнайте больше об обновлениях ОЗУ.
10.
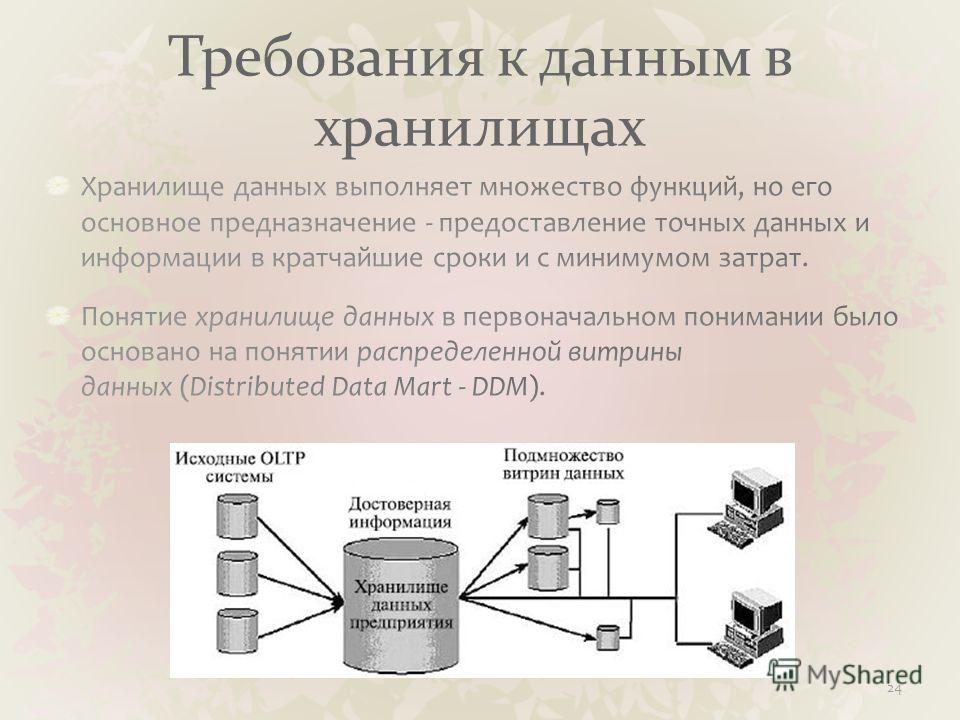 Модернизация диска
Модернизация дискаМодернизация диска может существенно увеличить быстродействие и производительность ПК. Большинство ПК поставляются с вращающимися жесткими дисками (HDD), однако переход на твердотельные накопители (SSD) сделает вашу систему значительно мощнее.
Как правило, твердотельные накопители дороже, чем жесткие диски, но ускорение загрузки системы, загрузки программ и повышение общего быстродействия системы может стоить этих денег.
Твердотельные накопители бывают разных форм-факторов или размеров, и их выбор зависит от системных требований вашего ПК. Для настольных компьютеров и ноутбуков предлагаются форм-факторы 2,5 дюйма and M.2. Убедитесь, что вы покупаете подходящий твердотельный накопитель, совместимый с вашей системой. Вы также сможете перенести все свои файлы и документы с жесткого диска на новый твердотельный накопитель, поэтому вам не придется беспокоиться о потере содержимого вашего ПК. Узнайте больше об обновлениях хранилища.
#KingstonIsWithYou
Хранение | Введение в психологию
Цели обучения
- Описать три этапа хранения памяти
- Различать имплицитную и эксплицитную память, а также семантическую и эпизодическую память
После того, как информация закодирована, мы должны каким-то образом ее сохранить.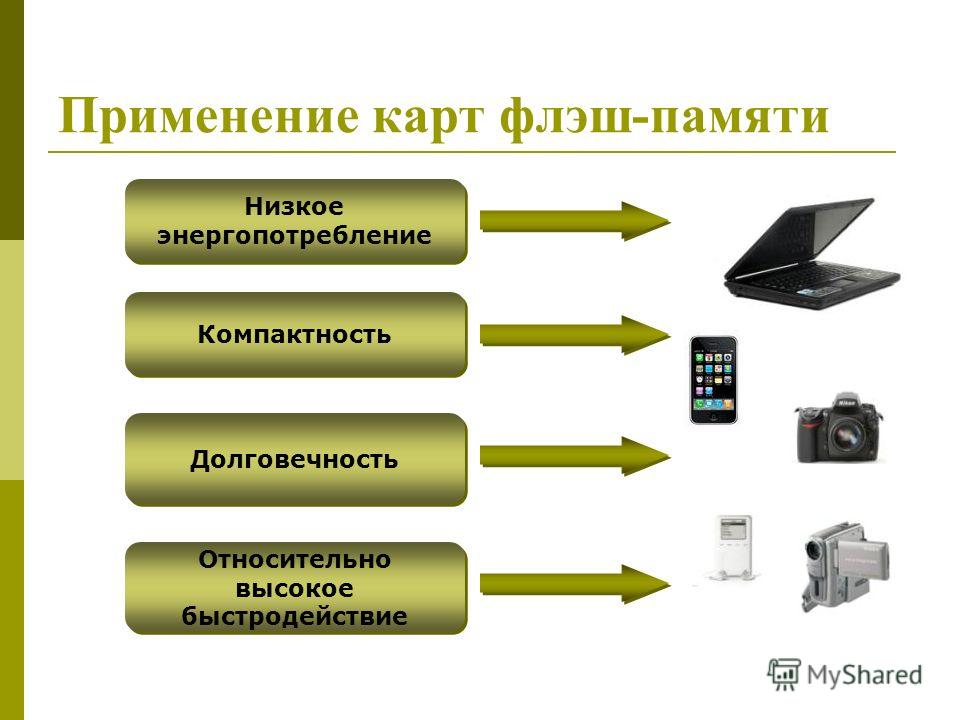 Наш мозг берет закодированную информацию и помещает ее в хранилище. Хранение — это создание постоянной записи информации.
Наш мозг берет закодированную информацию и помещает ее в хранилище. Хранение — это создание постоянной записи информации.
Рисунок 1 . Согласно модели памяти Аткинсона-Шиффрина, информация проходит три различных этапа, прежде чем она будет сохранена в долговременной памяти.
Модель Аткинсона и Шиффрина — не единственная модель памяти. Другие, такие как Baddeley и Hitch (1974), предложили модель, в которой кратковременная память сама по себе имеет разные формы.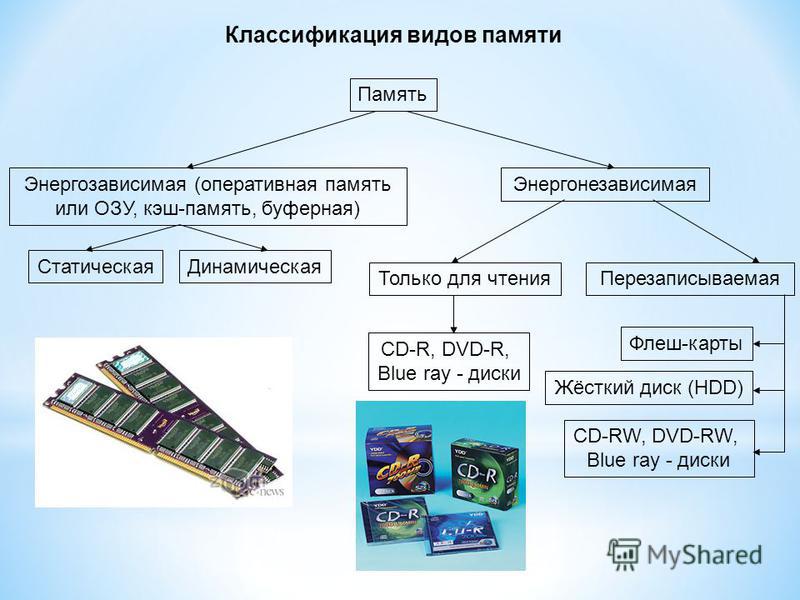 В этой модели хранение воспоминаний в кратковременной памяти похоже на открытие различных файлов на компьютере и добавление информации. Тип кратковременной памяти (или компьютерного файла) зависит от типа полученной информации. Существуют воспоминания в визуально-пространственной форме, а также воспоминания об устном или письменном материале, и они хранятся в трех краткосрочных системах: зрительно-пространственном блокноте, эпизодическом буфере и фонологической петле. Согласно Баддели и Хитчу, центральная исполнительная часть памяти контролирует или контролирует поток информации к трем краткосрочным системам и от них.
В этой модели хранение воспоминаний в кратковременной памяти похоже на открытие различных файлов на компьютере и добавление информации. Тип кратковременной памяти (или компьютерного файла) зависит от типа полученной информации. Существуют воспоминания в визуально-пространственной форме, а также воспоминания об устном или письменном материале, и они хранятся в трех краткосрочных системах: зрительно-пространственном блокноте, эпизодическом буфере и фонологической петле. Согласно Баддели и Хитчу, центральная исполнительная часть памяти контролирует или контролирует поток информации к трем краткосрочным системам и от них.
Сенсорная память
В модели Аткинсона-Шиффрина стимулы из окружающей среды сначала обрабатываются в сенсорной памяти: хранилище кратких сенсорных событий, таких как образы, звуки и вкусы. Это очень кратковременное хранение — до пары секунд. Нас постоянно бомбардируют сенсорной информацией. Мы не можем поглотить все это или даже большую часть. И большая часть из них никак не влияет на нашу жизнь. Например, во что был одет ваш профессор на последнем уроке? Пока профессор был одет подобающим образом, на самом деле не имело значения, во что они были одеты. Сенсорная информация о видах, звуках, запахах и даже текстурах, которую мы не рассматриваем как ценную информацию, мы отбрасываем. Если мы считаем что-то ценным, информация переместится в нашу систему кратковременной памяти.
И большая часть из них никак не влияет на нашу жизнь. Например, во что был одет ваш профессор на последнем уроке? Пока профессор был одет подобающим образом, на самом деле не имело значения, во что они были одеты. Сенсорная информация о видах, звуках, запахах и даже текстурах, которую мы не рассматриваем как ценную информацию, мы отбрасываем. Если мы считаем что-то ценным, информация переместится в нашу систему кратковременной памяти.
Кратковременная память
Кратковременная память (STM) — это система временного хранения, которая обрабатывает входящую сенсорную память. Термины краткосрочная и рабочая память иногда используются взаимозаменяемо, но это не совсем одно и то же. Кратковременная память более точно описывается как компонент рабочей памяти. Кратковременная память берет информацию из сенсорной памяти и иногда связывает эту память с чем-то, что уже находится в долговременной памяти. Кратковременная память длится от 15 до 30 секунд. Думайте об этом как об информации, отображаемой на экране вашего компьютера, например, в документе, электронной таблице или на веб-сайте. Затем информация в STM попадает в долговременную память (вы сохраняете ее на жесткий диск) или отбрасывается (вы удаляете документ или закрываете веб-браузер).
Думайте об этом как об информации, отображаемой на экране вашего компьютера, например, в документе, электронной таблице или на веб-сайте. Затем информация в STM попадает в долговременную память (вы сохраняете ее на жесткий диск) или отбрасывается (вы удаляете документ или закрываете веб-браузер).
Репетиция перемещает информацию из кратковременной памяти в долговременную. Активная репетиция — это способ внимания к информации, чтобы перевести ее из кратковременной памяти в долговременную. Во время активной репетиции вы повторяете (практикуете) информацию, которую нужно запомнить. Если вы будете повторять это достаточно часто, это может быть перемещено в долговременную память. Например, этот тип активной репетиции — это то, как многие дети изучают азбуку, напевая песенку с алфавитом. В качестве альтернативы, детальное повторение — это акт связывания новой информации, которую вы пытаетесь изучить, с существующей информацией, которую вы уже знаете. Например, если вы встречаете кого-то на вечеринке, и ваш телефон разряжен, но вы хотите запомнить его номер телефона, который начинается с кода города 203, вы можете вспомнить, что ваш дядя Абдул живет в Коннектикуте и имеет код города 203. Таким образом, когда вы попытаетесь вспомнить номер телефона вашего нового потенциального друга, вы легко запомните код города. Крейк и Локхарт (1972) предложил гипотезу об уровнях обработки, согласно которой чем глубже вы о чем-то думаете, тем лучше вы это помните.
Таким образом, когда вы попытаетесь вспомнить номер телефона вашего нового потенциального друга, вы легко запомните код города. Крейк и Локхарт (1972) предложил гипотезу об уровнях обработки, согласно которой чем глубже вы о чем-то думаете, тем лучше вы это помните.
Вы можете задаться вопросом: «Сколько информации может обрабатывать наша память одновременно?» Чтобы изучить объем и продолжительность вашей кратковременной памяти, попросите партнера прочитать вам вслух цепочки случайных чисел (рис. 8.5), начиная каждую строку со слов «Готов?» и заканчивая каждый, говоря «Вспомнить», после чего вы должны попытаться записать строку чисел по памяти.
Рисунок 2 . Проработайте эту серию чисел, используя описанное выше упражнение на запоминание, чтобы определить самую длинную последовательность цифр, которую вы можете запомнить.
Обратите внимание на самую длинную строку, в которой вы получили правильный ряд. Для большинства людей емкость, вероятно, будет близка к 7 плюс-минус 2. В 1956 году Джордж Миллер проанализировал большую часть исследований емкости кратковременной памяти и обнаружил, что люди могут сохранять от 5 до 9 элементов, поэтому он сообщил емкость кратковременной памяти была «магическим числом» 7 плюс-минус 2. Однако более современные исследования показали, что емкость рабочей памяти составляет 4 плюс-минус 1 (Cowan, 2010). Как правило, припоминание случайных чисел несколько лучше, чем случайных букв (Jacobs, 1887), а также часто немного лучше для информации, которую мы слышим (акустическое кодирование), чем информации, которую мы видим (визуальное кодирование) (Anderson, 19).69).
В 1956 году Джордж Миллер проанализировал большую часть исследований емкости кратковременной памяти и обнаружил, что люди могут сохранять от 5 до 9 элементов, поэтому он сообщил емкость кратковременной памяти была «магическим числом» 7 плюс-минус 2. Однако более современные исследования показали, что емкость рабочей памяти составляет 4 плюс-минус 1 (Cowan, 2010). Как правило, припоминание случайных чисел несколько лучше, чем случайных букв (Jacobs, 1887), а также часто немного лучше для информации, которую мы слышим (акустическое кодирование), чем информации, которую мы видим (визуальное кодирование) (Anderson, 19).69).
Затухание следа памяти и помехи — два фактора, влияющих на краткосрочное сохранение памяти. Петерсон и Петерсон (1959) исследовали кратковременную память, используя последовательности из трех букв, называемые триграммами (например, CLS), которые нужно было вызывать через различные промежутки времени от 3 до 18 секунд. Участники запомнили около 80% триграмм после 3-секундной задержки, но только 10% после 18-секундной задержки, из чего они сделали вывод, что кратковременная память угасает за 18 секунд. При распаде след памяти со временем становится менее активным, и информация забывается. Однако Кеппел и Андервуд (1962) исследовал только первые попытки выполнения задачи с триграммой и обнаружил, что упреждающее вмешательство также влияет на сохранение кратковременной памяти. При упреждающем вмешательстве ранее усвоенная информация мешает способности узнавать новую информацию. И распад следа памяти, и упреждающее вмешательство влияют на кратковременную память. Как только информация достигает долговременной памяти, она должна быть консолидирована как на синаптическом уровне, что занимает несколько часов, так и в системе памяти, что может занять недели или дольше.
При распаде след памяти со временем становится менее активным, и информация забывается. Однако Кеппел и Андервуд (1962) исследовал только первые попытки выполнения задачи с триграммой и обнаружил, что упреждающее вмешательство также влияет на сохранение кратковременной памяти. При упреждающем вмешательстве ранее усвоенная информация мешает способности узнавать новую информацию. И распад следа памяти, и упреждающее вмешательство влияют на кратковременную память. Как только информация достигает долговременной памяти, она должна быть консолидирована как на синаптическом уровне, что занимает несколько часов, так и в системе памяти, что может занять недели или дольше.
Долговременная память
Долговременная память (LTM) — это непрерывное хранение информации. В отличие от кратковременной памяти, объем долговременной памяти считается неограниченным. Он включает в себя все, что вы можете вспомнить, что произошло больше, чем несколько минут назад.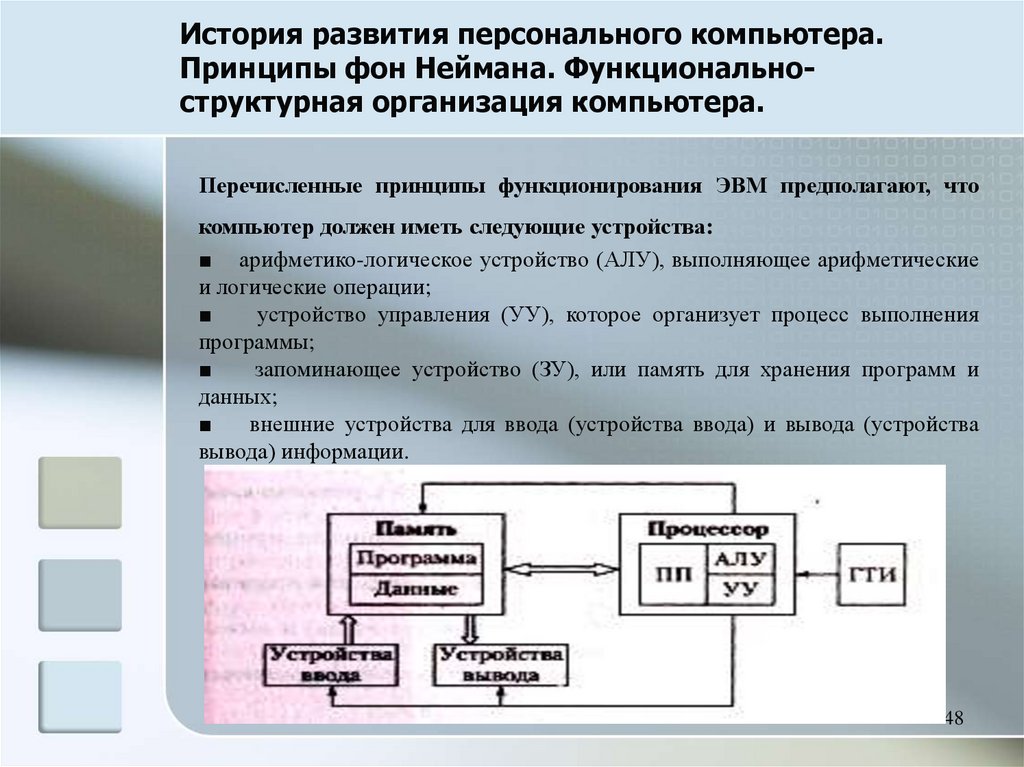 Нельзя по-настоящему рассматривать долговременную память, не задумываясь о том, как она организована. Действительно быстро, какое первое слово приходит на ум, когда вы слышите «арахисовое масло»? Вы подумали о желе? Если да, то вы, вероятно, ассоциировали в своем уме арахисовое масло и желе. Общепризнано, что воспоминания организованы в семантические (или ассоциативные) сети (Collins & Loftus, 19).75). Семантическая сеть состоит из понятий, и, как вы помните из того, что вы узнали о памяти, понятия — это категории или группы лингвистической информации, образов, идей или воспоминаний, таких как жизненный опыт. Хотя индивидуальный опыт и знания могут влиять на расположение концептов, считается, что концепты располагаются в уме иерархически (Anderson & Reder, 1999; Johnson & Mervis, 1997, 1998; Palmer, Jones, Hennessy, Unze, & Pick, 1989; Rosch, Мервис, Грей, Джонсон и Бойс-Брэм, 19 лет76; Танака и Тейлор, 1991). Связанные понятия связаны, и сила связи зависит от того, как часто два понятия были связаны.
Нельзя по-настоящему рассматривать долговременную память, не задумываясь о том, как она организована. Действительно быстро, какое первое слово приходит на ум, когда вы слышите «арахисовое масло»? Вы подумали о желе? Если да, то вы, вероятно, ассоциировали в своем уме арахисовое масло и желе. Общепризнано, что воспоминания организованы в семантические (или ассоциативные) сети (Collins & Loftus, 19).75). Семантическая сеть состоит из понятий, и, как вы помните из того, что вы узнали о памяти, понятия — это категории или группы лингвистической информации, образов, идей или воспоминаний, таких как жизненный опыт. Хотя индивидуальный опыт и знания могут влиять на расположение концептов, считается, что концепты располагаются в уме иерархически (Anderson & Reder, 1999; Johnson & Mervis, 1997, 1998; Palmer, Jones, Hennessy, Unze, & Pick, 1989; Rosch, Мервис, Грей, Джонсон и Бойс-Брэм, 19 лет76; Танака и Тейлор, 1991). Связанные понятия связаны, и сила связи зависит от того, как часто два понятия были связаны.
Семантические сети различаются в зависимости от личного опыта. Что важно для памяти, активация любой части семантической сети также активирует понятия, связанные с этой частью, в меньшей степени. Этот процесс известен как распространяющаяся активация (Collins & Loftus, 1975). Если активирована одна часть сети, проще получить доступ к связанным понятиям, поскольку они уже частично активированы. Когда вы что-то вспоминаете или вспоминаете, вы активируете концепцию, а связанные с ней концепции легче запоминаются, потому что они частично активированы. Однако активации не распространяются только в одном направлении. Когда вы что-то вспоминаете, у вас обычно есть несколько способов получить информацию, к которой вы пытаетесь получить доступ, и чем больше у вас ссылок на концепцию, тем выше ваши шансы на запоминание.
Существует два типа долговременной памяти: явная и неявная (рис. 8.6). Понимание разницы между эксплицитной и имплицитной памятью важно, потому что старение, определенные типы травм головного мозга и определенные расстройства могут по-разному влиять на эксплицитную и имплицитную память. Явные воспоминания — это те воспоминания, которые мы сознательно пытаемся запомнить, вспомнить и сообщить. Например, если вы готовитесь к экзамену по химии, материал, который вы изучаете, будет частью вашей явной памяти. В соответствии с аналогией с компьютером, некоторая информация в вашей долговременной памяти будет похожа на информацию, которую вы сохранили на жестком диске. Ее нет на вашем рабочем столе (ваша кратковременная память), но в большинстве случаев вы можете извлечь эту информацию, когда захотите. Не все долговременные воспоминания являются сильными воспоминаниями, а некоторые воспоминания можно вызвать только с помощью подсказок. Например, вы можете легко вспомнить какой-то факт, например, столицу Соединенных Штатов, но вам может быть сложно вспомнить название ресторана, в котором вы обедали, когда прошлым летом были в соседнем городе. Подсказка, например, что ресторан был назван в честь его владельца, может помочь вам вспомнить название ресторана. Эксплицитную память иногда называют декларативной памятью, потому что ее можно выразить словами.
Явные воспоминания — это те воспоминания, которые мы сознательно пытаемся запомнить, вспомнить и сообщить. Например, если вы готовитесь к экзамену по химии, материал, который вы изучаете, будет частью вашей явной памяти. В соответствии с аналогией с компьютером, некоторая информация в вашей долговременной памяти будет похожа на информацию, которую вы сохранили на жестком диске. Ее нет на вашем рабочем столе (ваша кратковременная память), но в большинстве случаев вы можете извлечь эту информацию, когда захотите. Не все долговременные воспоминания являются сильными воспоминаниями, а некоторые воспоминания можно вызвать только с помощью подсказок. Например, вы можете легко вспомнить какой-то факт, например, столицу Соединенных Штатов, но вам может быть сложно вспомнить название ресторана, в котором вы обедали, когда прошлым летом были в соседнем городе. Подсказка, например, что ресторан был назван в честь его владельца, может помочь вам вспомнить название ресторана. Эксплицитную память иногда называют декларативной памятью, потому что ее можно выразить словами. Эксплицитная память делится на эпизодическую память и семантическую память.
Эксплицитная память делится на эпизодическую память и семантическую память.
Попробуйте
Рисунок 3 . Есть два компонента долговременной памяти: эксплицитная и имплицитная. Эксплицитная память включает эпизодическую и семантическую память. Имплицитная память включает в себя процедурную память и информацию, полученную в результате обусловливания.
Эпизодическая память — это информация о событиях, которые мы лично пережили (т. е. эпизод). Например, воспоминание о вашем последнем дне рождения — это эпизодическая память. Обычно эпизодическая память описывается как история. Впервые концепция эпизодической памяти была предложена в 19 в.70-х (Талвинг, 1972). С тех пор Тулвинг и другие переформулировали теорию, и в настоящее время ученые считают, что эпизодическая память — это память о событиях в определенных местах в определенное время — что, где и когда произошло событие (Талвинг, 2002). Это включает в себя припоминание визуальных образов, а также чувство знакомства (Hassabis & Maguire, 2007). Семантическая память — это знания о словах, понятиях, языковых знаниях и фактах. Семантическая память обычно сообщается как факты. Семантический означает, что он имеет отношение к языку и знаниям о языке. Например, в вашей семантической памяти хранятся ответы на такие вопросы, как «что такое определение психологии» и «кто был первым афроамериканцем-президентом США».
Семантическая память — это знания о словах, понятиях, языковых знаниях и фактах. Семантическая память обычно сообщается как факты. Семантический означает, что он имеет отношение к языку и знаниям о языке. Например, в вашей семантической памяти хранятся ответы на такие вопросы, как «что такое определение психологии» и «кто был первым афроамериканцем-президентом США».
Имплицитные воспоминания — это долговременные воспоминания, не являющиеся частью нашего сознания. Хотя имплицитные воспоминания усваиваются вне нашего сознания и не могут быть вызваны сознательно, имплицитная память проявляется при выполнении какой-либо задачи (Roediger, 1990; Schacter, 1987). Имплицитная память изучалась с помощью когнитивных задач, таких как выполнение искусственных грамматик (Reber, 1976), словесная память (Jacoby, 1983; Jacoby & Witherspoon, 1982), а также изучение невысказанных и неписаных условий и правил (Greenspoon, 19).55; Гиддан и Эриксен, 1959; Крикхаус и Эриксен, 1960). Возвращаясь к компьютерной метафоре, имплицитные воспоминания подобны программе, работающей в фоновом режиме, и вы не осознаете их влияния. Имплицитные воспоминания могут влиять на наблюдаемое поведение, а также на когнитивные задачи. В любом случае вы обычно не можете выразить память словами, адекватно описывающими задачу. Существует несколько типов имплицитных воспоминаний, в том числе процедурные, прайминговые и эмоциональные.
Возвращаясь к компьютерной метафоре, имплицитные воспоминания подобны программе, работающей в фоновом режиме, и вы не осознаете их влияния. Имплицитные воспоминания могут влиять на наблюдаемое поведение, а также на когнитивные задачи. В любом случае вы обычно не можете выразить память словами, адекватно описывающими задачу. Существует несколько типов имплицитных воспоминаний, в том числе процедурные, прайминговые и эмоциональные.
Неявный процедурную память часто изучают с помощью наблюдаемого поведения (Adams, 1957; Lacey & Smith, 1954; Lazarus & McCleary, 1951). Неявная процедурная память хранит информацию о том, как что-то сделать, и это память на искусные действия, такие как чистка зубов, езда на велосипеде или вождение автомобиля. Вы, вероятно, не так хорошо катались на велосипеде или вели машину в первый раз, когда попробовали, но вы стали намного лучше после того, как занимались этим в течение года. Ваше улучшение езды на велосипеде произошло из-за того, что вы научились балансировать.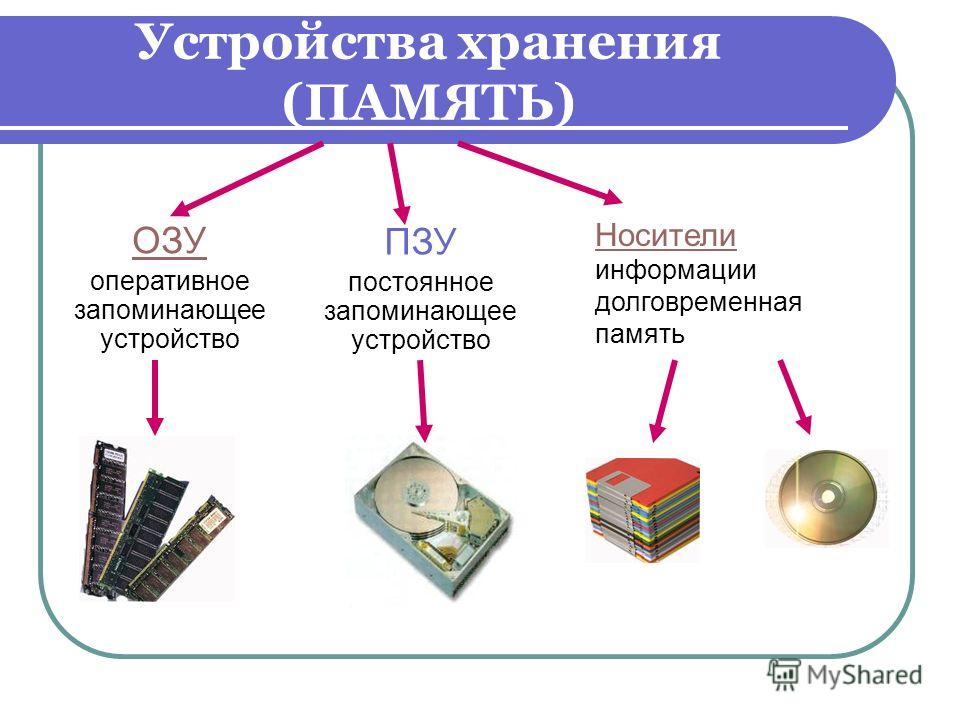 Вы, вероятно, думали о том, чтобы оставаться в вертикальном положении в начале, но теперь вы просто делаете это. Более того, вы, вероятно, умеете сохранять равновесие, но не можете рассказать кому-то, как именно вы это делаете. Точно так же, когда вы впервые учились водить машину, вы, вероятно, думали о многих вещах, которые сейчас просто делаете без особых размышлений. Когда вы впервые научились выполнять эти задачи, кто-то, возможно, рассказал вам, как их выполнять, но все, что вы узнали после этих инструкций, что вы не можете легко объяснить кому-то другому, как это сделать, — это имплицитная память.
Вы, вероятно, думали о том, чтобы оставаться в вертикальном положении в начале, но теперь вы просто делаете это. Более того, вы, вероятно, умеете сохранять равновесие, но не можете рассказать кому-то, как именно вы это делаете. Точно так же, когда вы впервые учились водить машину, вы, вероятно, думали о многих вещах, которые сейчас просто делаете без особых размышлений. Когда вы впервые научились выполнять эти задачи, кто-то, возможно, рассказал вам, как их выполнять, но все, что вы узнали после этих инструкций, что вы не можете легко объяснить кому-то другому, как это сделать, — это имплицитная память.
Связь на каждый день: можете ли вы вспомнить все, что вы когда-либо делали или говорили?
Эпизодические воспоминания также называют автобиографическими воспоминаниями. Давайте быстро проверим вашу автобиографическую память. Что ты был одет ровно пять лет назад сегодня? Что вы ели на обед 10 апреля 2019 года? Вероятно, вам будет трудно, если не невозможно, ответить на эти вопросы.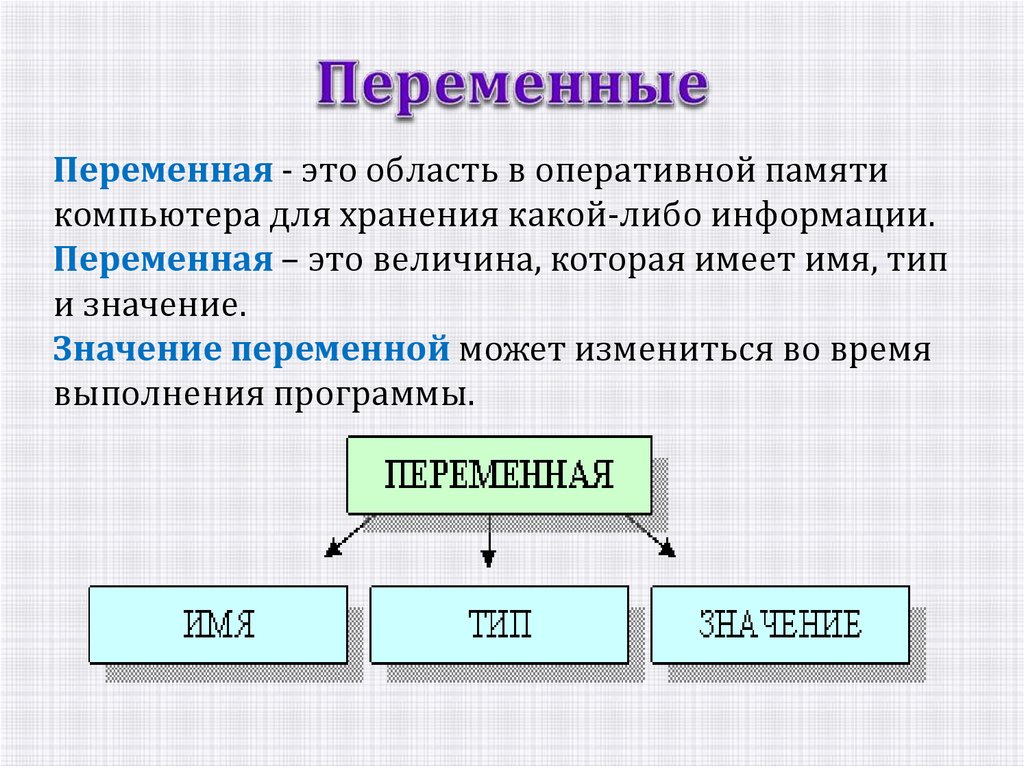 Можете ли вы вспомнить каждое событие, которое вы пережили в течение своей жизни, — приемы пищи, разговоры, выбор одежды, погодные условия и так далее? Скорее всего, никто из нас даже близко не смог бы ответить на эти вопросы; однако американская актриса Марилу Хеннер, наиболее известная по телешоу Такси, могу вспомнить. У нее потрясающая и превосходная автобиографическая память (рис. 7).
Можете ли вы вспомнить каждое событие, которое вы пережили в течение своей жизни, — приемы пищи, разговоры, выбор одежды, погодные условия и так далее? Скорее всего, никто из нас даже близко не смог бы ответить на эти вопросы; однако американская актриса Марилу Хеннер, наиболее известная по телешоу Такси, могу вспомнить. У нее потрясающая и превосходная автобиографическая память (рис. 7).
Рисунок 7 . Суперавтобиографическая память Марилу Хеннер известна как гипертимезия. (кредит: Марк Ричардсон)
Мало кто может так вспоминать события; прямо сейчас менее 20 человек обладают этой способностью, и лишь немногие изучены (Parker, Cahill & McGaugh, 2006). И хотя гипертимезия обычно проявляется в подростковом возрасте, у двоих детей в Соединенных Штатах, по-видимому, есть воспоминания задолго до своего десятого дня рождения.
Посмотрите это видео о превосходной автобиографической памяти из телепрограммы новостей 60 минут , чтобы узнать больше.
Смотреть
В этом видео Хэнк Грин рассказывает о нескольких исследованиях, которые помогли нам лучше понять имплицитные воспоминания.
Вы можете просмотреть стенограмму «Почему езда на велосипеде — это «точно так же, как езда на велосипеде?»» здесь (откроется в новом окне).
Попробуйте
Подумай об этом
- Опишите то, чему вы научились, что теперь находится в вашей процедурной памяти. Обсудите, как вы узнали эту информацию.
- Опишите что-то, чему вы научились в старшей школе и что теперь хранится в вашей семантической памяти.
Глоссарий
Модель Аткинсона-Шиффрина (A-S): модель памяти, в которой говорится, что мы обрабатываем информацию через три системы: сенсорную память, кратковременную память и долговременную память время, пространство, частота и значение слов
декларативная память: тип долговременной памяти о фактах и событиях, которые мы переживаем лично
трудоемкая обработка: кодирование информации, требующее усилий и внимания сознательно пытаться вспомнить и вспомнить
неявная память: воспоминаний, не являющихся частью нашего сознания
память: система или процесс, который сохраняет то, что мы изучаем, для будущего использования
консолидация памяти: активная репетиция для перемещения информации из кратковременной памяти в долговременную
процедурная память: тип долговременной памяти для обучения действия, например, как чистить зубы, как водить машину и как плавать
извлечение: действие по извлечению информации из долговременной памяти и обратно в сознательное сознание
эффект самореференции: склонность человека лучше запоминать информацию, относящуюся к самому себе, по сравнению с материалом, имеющим меньшее личное значение
семантическое кодирование: ввод слов и их значения тип декларативной памяти о словах, понятиях и языковых знаниях и фактах
сенсорная память: хранение кратких сенсорных событий, таких как образы, звуки и вкусы
кратковременная память (STM): (также рабочая память) содержит около семи битов информации до того, как она будет забыта или сохранена, а также информация, которая была извлечена и используется
хранение: создание постоянного учета информации
Поддержите!
У вас есть идеи по улучшению этого контента? Мы будем признательны за ваш вклад.
Улучшить эту страницуПодробнее
Волшебная тайна четвертая: как ограничивается объем рабочей памяти и почему?
- Список журналов
- Рукописи авторов HHS
- PMC2864034
Curr Dir Psychol Sci. Авторская рукопись; доступно в PMC 2010 4 мая. 2010 1 февраля; 19(1): 51–57.
doi: 10.1177/0963721409359277
PMCID: PMC2864034
NIHMSID: NIHMS167613
PMID: 20445769
. хранить информацию по мере ее обработки. Способность повторять информацию зависит от требований задачи, но ее можно отличить от более постоянного, основного механизма: центрального хранилища памяти, ограниченного 3–5 значимыми элементами у молодых людей. Я расскажу, почему этот центральный предел важен, как его можно наблюдать, как он различается у разных людей и почему он может возникнуть.
Ключевые слова: Пределы емкости рабочей памяти, Ограничения емкости центрального хранилища, Фрагментирование, Группировка, Емкость ядра
Возможно, это не волшебство, но это тайна. Существуют строгие ограничения на то, сколько можно удерживать в памяти одновременно (~3–5 пунктов). Когда, как и почему происходит ограничение?
В известной статье, с юмором описывающей «магическое число семь плюс-минус два», Миллер (1956) утверждал, что его преследует целое число. Он продемонстрировал, что можно повторить список не более чем из семи случайно упорядоченных значимых элементов или из 9.0095 блоков (которые могут быть буквами, цифрами или словами). Однако другие исследования дали другие результаты. Молодые люди могут вспомнить только 3 или 4 более длинных словесных фрагмента, таких как идиомы или короткие предложения (Gilchrist, Cowan, & Naveh-Benjamin, 2008). Некоторые пожимают плечами, делая вывод, что предел «просто зависит» от деталей задачи памяти. Однако недавние исследования показывают, когда и как можно предсказать предел.
Однако недавние исследования показывают, когда и как можно предсказать предел.
Предел отзыва важен, потому что он измеряет то, что называется рабочая память (Baddeley & Hitch, 1974; Miller, Galanter & Pribram, 1960), несколько временно активных мыслей. Рабочая память используется в умственных задачах, таких как понимание языка (например, сохранение идей из начала предложения для объединения с идеями позже), решение задач (в арифметике перенос цифры из столбца единиц в разряд десятков при запоминании). цифры) и планирование (определение наилучшего порядка посещения банка, библиотеки и продуктового магазина). Многие исследования показывают, что объем рабочей памяти различается у разных людей, предсказывает индивидуальные различия в интеллектуальных способностях и изменяется на протяжении всей жизни (Cowan, 2005).
Трудно определить предел емкости рабочей памяти, поскольку информация сохраняется несколькими механизмами. Значительные исследования показывают, например, что человек может запомнить речь примерно на 2 секунды, репетируя про себя (Baddeley & Hitch, 1974). Однако рабочая память не может быть ограничена только таким образом; в процедурах с бегущим диапазоном можно вызвать только последние 3–5 цифр (менее чем за 2 секунды). В этих процедурах участник не знает, когда закончится список, и, когда это произойдет, он должен вспомнить несколько элементов из конца списка (Cowan, 2001).
Однако рабочая память не может быть ограничена только таким образом; в процедурах с бегущим диапазоном можно вызвать только последние 3–5 цифр (менее чем за 2 секунды). В этих процедурах участник не знает, когда закончится список, и, когда это произойдет, он должен вспомнить несколько элементов из конца списка (Cowan, 2001).
Чтобы понять природу пределов объема рабочей памяти, важно учитывать два отличия. В то время как способность рабочей памяти обычно измеряется с точки зрения обработки информации, она вместо этого принимает централизованные меры, специфичные для хранения, для соблюдения ограничений емкости, которые одинаковы для разных материалов и задач.
Различие , связанного с обработкой, и , связанного с хранилищем, связано с тем, предотвращается ли стратегия обработки, которую люди применяют для повышения производительности, и учитываются ли вредоносные процессы, которые мешают оптимальному использованию рабочей памяти. Емкость конкретного хранилища — это более аналитическая концепция, которая остается неизменной в гораздо более широком диапазоне обстоятельств.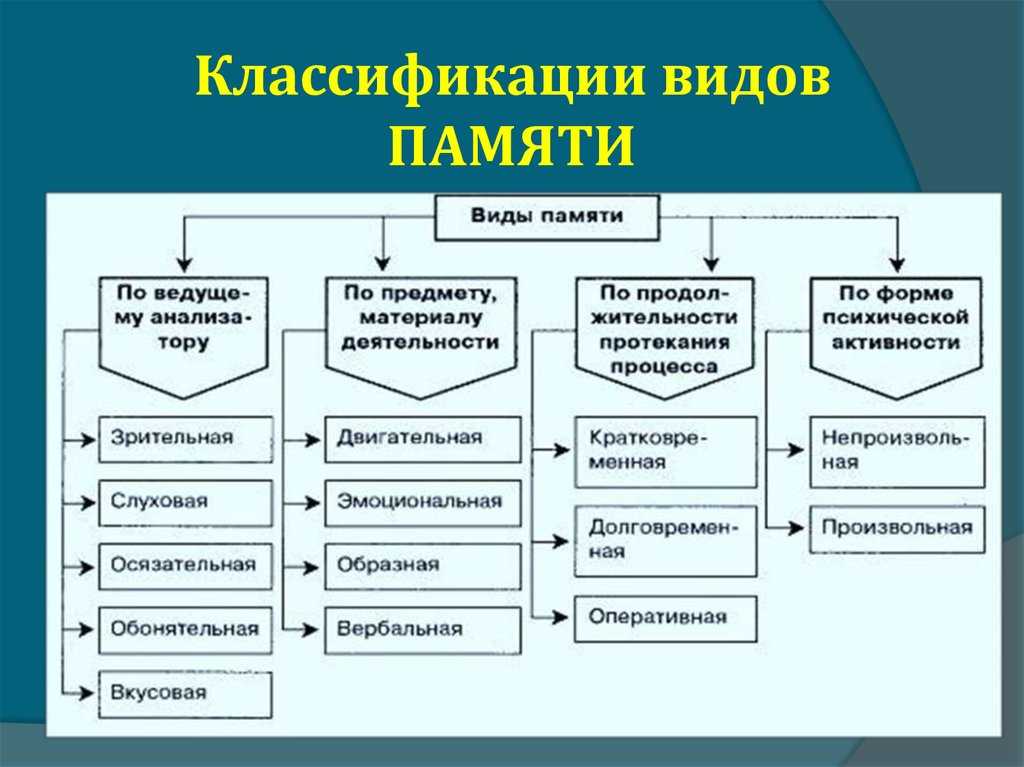 В широком смысле способность рабочей памяти широко варьируется в зависимости от того, какие процессы могут быть применены к задаче. Для запоминания словесных материалов можно попытаться повторить их в уме (прорепетировать скрытно). Можно также попытаться сформировать куски из нескольких слов. Например, чтобы не забыть купить хлеб, молоко и перец, можно представить себе хлеб, плавающий в перечном молоке. Чтобы запомнить последовательность пространственных местоположений, можно представить путь, образованный из этих местоположений. Хотя мы пока не можем точно предсказать, насколько хорошо рабочая память будет работать в каждой возможной задаче, мы можем измерить емкость конкретного хранилища, предотвращая или контролируя стратегии обработки.
В широком смысле способность рабочей памяти широко варьируется в зависимости от того, какие процессы могут быть применены к задаче. Для запоминания словесных материалов можно попытаться повторить их в уме (прорепетировать скрытно). Можно также попытаться сформировать куски из нескольких слов. Например, чтобы не забыть купить хлеб, молоко и перец, можно представить себе хлеб, плавающий в перечном молоке. Чтобы запомнить последовательность пространственных местоположений, можно представить путь, образованный из этих местоположений. Хотя мы пока не можем точно предсказать, насколько хорошо рабочая память будет работать в каждой возможной задаче, мы можем измерить емкость конкретного хранилища, предотвращая или контролируя стратегии обработки.
Таким образом можно соблюсти предел вместимости от 3 до 5 отдельных предметов (Cowan, 2001). Во многих таких исследованиях с урезанной репетицией и группировкой информация представлялась (1) в виде краткого одновременного пространственного массива; (2) в необслуживаемом слуховом канале, когда внимание к сенсорной памяти имеет место только после окончания звуков; (3) во время открытого повторяющегося произнесения участником одного слова; или (4) в серии с непредсказуемым концом, как в бегущем пролете.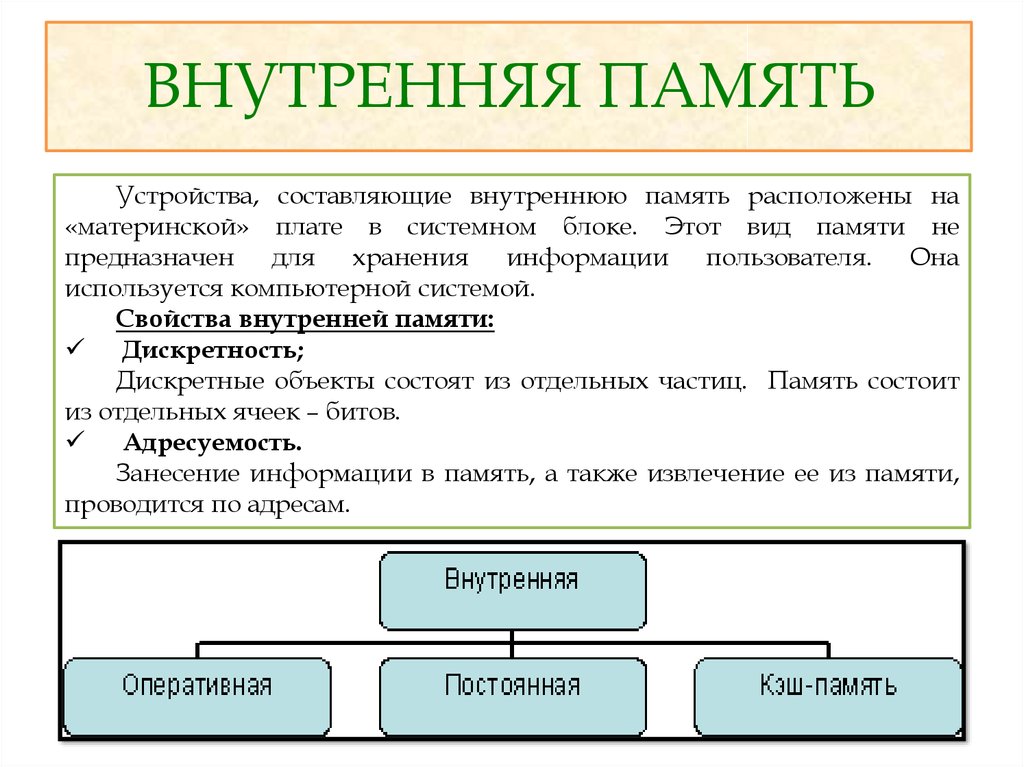 Это граничные условия, в пределах которых, по-видимому, можно наблюдать горстку понятий в сознательном уме.
Это граничные условия, в пределах которых, по-видимому, можно наблюдать горстку понятий в сознательном уме.
Эти граничные условия также имеют практическое значение для прогнозирования производительности, когда материал слишком короткий, длинный или сложный для использования таких стратегий обработки, как репетиция или группировка. Например, при понимании эссе может потребоваться одновременно держать в уме основную посылку, точку зрения, изложенную в предыдущем абзаце, а также факт и мнение, представленные в текущем абзаце. Только когда все эти элементы будут объединены в единый фрагмент, читатель сможет успешно продолжить чтение и понимание. Забвение одной из этих идей может привести к более поверхностному пониманию текста или к необходимости вернуться и перечитать. Как заметил Коуэн (2001), многие теоретики с математическими моделями конкретных аспектов решения задач и мышления допускают, чтобы количество элементов в рабочей памяти варьировалось как свободный параметр, и модели, по-видимому, остановились на значении около 4.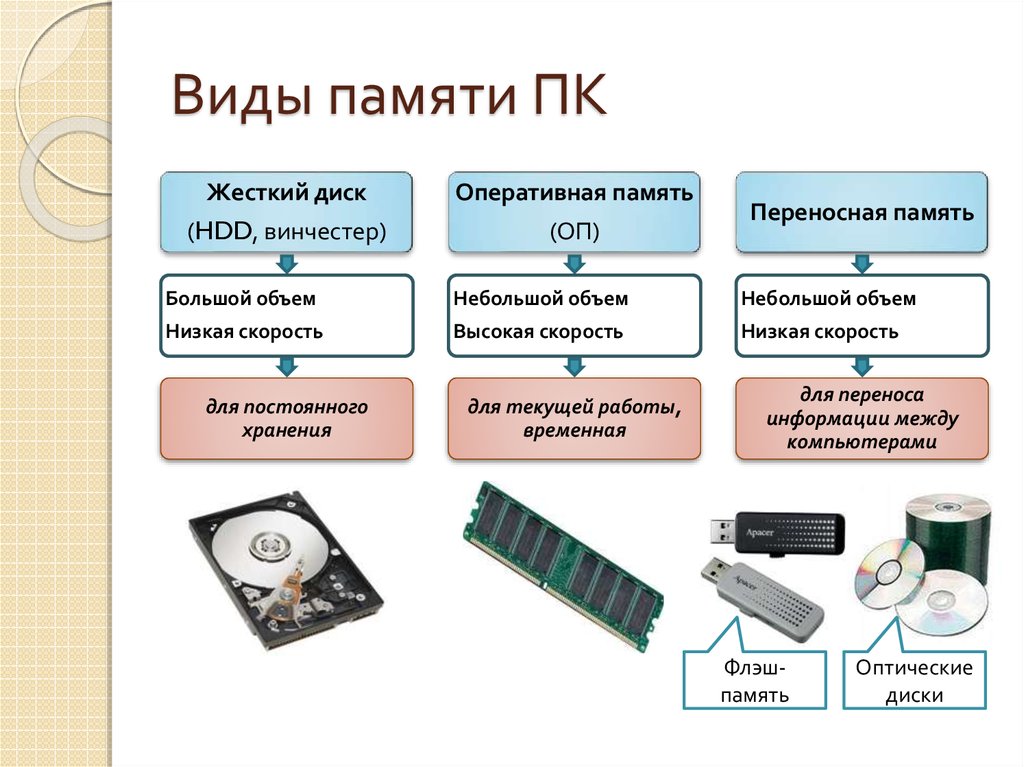 где обычно достигается наилучшее соответствие.
где обычно достигается наилучшее соответствие.
В недавних статьях мы показали постоянство объема рабочей памяти в чанках, обучая новым чанкам, состоящим из нескольких элементов. Мы представили набор произвольно составленных пар слов, таких как desk-ball , многократно с согласованным спариванием. В то же время мы представили другие слова как синглтоны. Парные слова становятся новыми фрагментами. Молодые люди могут вспомнить от 3 до 5 кусков из представленного списка, независимо от того, являются ли они выученными парами или одиночками. Наиболее точный результат был получен Ченом и Коуэном (в печати), как показано на рис. Обычно результат зависел бы от длины списка и элементов, но, когда словесная репетиция была предотвращена тем, что участник повторял слово «the» на протяжении всего испытания, люди запоминали только около 3 единиц, независимо от того, были ли они одиночками. или изученные пары. Имея аналогичные результаты для многих типов материалов и задач, мы полагаем, что у взрослых действительно существует центральная функция рабочей памяти, ограниченная 3–5 фрагментами, которая может предсказывать ошибки в мышлении и рассуждениях (Halford, Cowan, & Andrews, 2007).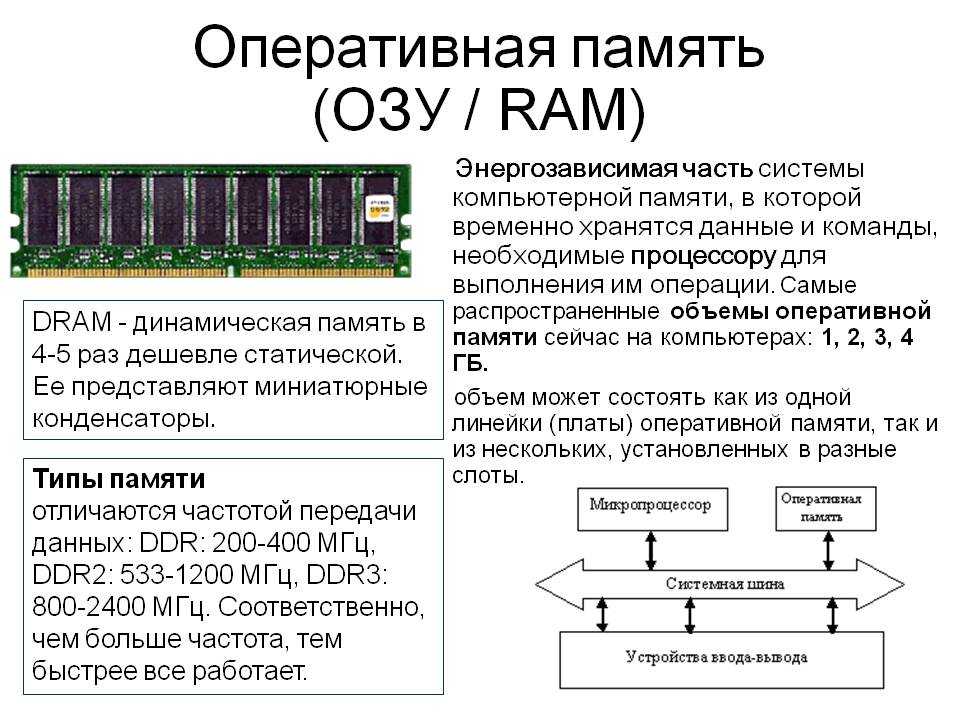
Открыть в отдельном окне
Иллюстрация трехчастного метода Чена и Коуэна (в печати) с использованием списков слов и ключевой результат. Центральный предел емкости, который можно наблюдать только в том случае, если предотвратить репетицию, составлял около 3 фрагментов, независимо от того, были ли эти фрагменты одиночками или выученными парами слов.
Можно задаться вопросом, как люди различаются по способности рабочей памяти. Они могут отличаться тем, сколько можно хранить. Однако есть также процессы, которые могут влиять на эффективность использования рабочей памяти. Важным примером является использование внимания для заполнения рабочей памяти элементами, которые нужно запомнить (например, концепции, объясняемые в классе), а не для заполнения ее отвлечениями (например, тем, что вы планируете делать после урока). . Согласно одному типу взглядов (например, Kane, Bleckley, Conway, & Engle, 2001; Vogel, McCollough, & Machizawa, 2005), люди с низким объемом памяти помнят меньше, потому что они используют больше своего объема памяти, храня информацию, которая не имеет отношения к делу. к поставленной задаче.
к поставленной задаче.
Несколько других недавних исследований, однако, показывают, что эта популярная точка зрения не может быть исчерпывающей и что существуют реальные различия в способностях между людьми (Cowan, Morey, AuBuchon, Zwilling, and Gilchrist, в печати; Gold et al., 2006). . Коуэн и др. сравнили 7–8-летних и 11–12-летних детей и студентов колледжей, используя версию процедуры памяти массива, показанную на рис. Были две разные формы, но участникам иногда давали указание сохранять только предметы одной формы. Чтобы сделать задачу интересной для детей, цветные фигуры должны были представляться детьми в классе. Когда тестовый образец был представлен, задача состояла в том, чтобы указать щелчком мыши, находится ли этот «ребенок» на правильном месте, принадлежит другому месту или принадлежит (полностью отсутствовал в массиве памяти). В последнем случае щелчок по значку двери отправлял «ребенка» к директору.
Открыть в отдельном окне
Иллюстрация метода Cowan et al. (в печати) с использованием массивов объектов и ключевым результатом. Для простых материалов предел возможностей заметно увеличивался с 7 лет до совершеннолетия, тогда как способность сосредотачиваться на важных предметах и игнорировать второстепенные в течение всего этого времени оставалась довольно постоянной.
Мы оценили содержимое рабочей памяти в нескольких условиях внимания. В одном из условий нужно было обслуживать объекты одной формы, и в 80 % испытаний пробный образец имел эту форму. В оставшихся 20% испытаний в этом состоянии, тем не менее, тестировался элемент формы, которую следует игнорировать. Пробник иногда отличался по цвету от соответствующего элемента массива. Мы подсчитали долю испытаний с изменением, в которых изменение было замечено (попадания), и испытаний без изменений, в которых был дан неверный ответ на изменение (ложные тревоги). Попадания и ложные тревоги способствовали простой формуле, показывающей количество элементов, хранящихся в рабочей памяти (Cowan, 2001). Это значение было ниже для 7-летних детей (~ 1,5), чем для детей старшего возраста или взрослых (~ 3,0), что указывает на то, что возрастные группы различаются по накоплению. Было также преимущество в том, что тест на запоминание формы по сравнению с игнорированием формы; внимание очень помогло. Примечательно, что это преимущество для посещаемой формы было таким же большим у 7-летних детей, как и у взрослых, при условии, что общее количество предметов в поле было небольшим (4). Это говорит о том, что простая способность к хранению, а не только способность к обработке, отличает маленьких детей от взрослых. В другой работе предполагается, что возможности хранения и обработки вносят важный, частично раздельный, а частично перекрывающийся вклад в интеллект и развитие (Cowan, Fristoe, Elliott, Brunner, & Saults, 2006).
Различие между инклюзивным и центральным связано с тем, позволяем ли мы людям использовать временную информацию, специфичную для того, как что-то звучит, выглядит или ощущается, то есть информацию, специфичную для сенсорной модальности; или же мы структурируем наши стимулирующие материалы так, чтобы исключить этот тип информации, оставив в остатке только абстрактную информацию, применимую к различным модальностям (называемую центральной информацией). Хотя важно, чтобы люди могли использовать яркие воспоминания о том, как выглядела картинка или как звучало предложение, эти типы информации, как правило, затрудняют обнаружение центральной памяти, обычно ограниченной 3–5 элементами у взрослых. Эта центральная память особенно важна, потому что она лежит в основе решения проблем и абстрактного мышления.
Центральные пределы можно наблюдать лучше, если вклад информации в сенсорную память сокращен, как показано Saults & Cowan (2007) в процедуре, показанной на . Массив цветных квадратов был представлен одновременно с массивом одновременно произносимых цифр, воспроизводимых разными голосами в четырех громкоговорителях (чтобы не репетировать). Иногда задача заключалась в том, чтобы обращать внимание только на квадраты или только на произносимые цифры, а иногда — на обе модальности одновременно. Ключевой вывод заключался в том, что, когда внимание было направлено по-разному, предел емкости центральной рабочей памяти все еще сохранялся. Люди могли запомнить около 4 квадратов, если их просили обращать внимание только на квадраты, а если их просили обращать внимание и на квадраты, и на цифры, они могли запомнить меньше квадратов, но всего около 4 элементов. Этот фиксированный предел возможностей был достигнут, однако, только в том случае, если за элементами, которые нужно было вызвать, следовал беспорядок бессмысленных, смешанных визуальных и акустических стимулов (маска), так что сенсорная память была стерта, а мера рабочей памяти была ограничена. к центральной памяти. В инклюзивной ситуации (без маски) две модальности были лучше, чем одна. Коуэн и Мори (2007) аналогичным образом обнаружили, что для процесса кодирования (помещения в рабочую память) одних элементов при запоминании других опять же две модальности лучше, чем одна (Коуэн и Мори, 2007), тогда как модальность не имеет значения для центрального хранилища. в рабочей памяти после завершения кодирования.
Открыть в отдельном окне
Иллюстрация метода в пятом и последнем эксперименте Saults and Cowan (2007) с использованием аудиовизуальных массивов и основные результаты. Когда сенсорная память была удалена, вместимость составляла около 4 элементов, независимо от того, были ли это все визуальные объекты или смесь зрительных и слуховых элементов.
Причины ограниченного хранения центральной рабочей памяти в 3–5 фрагментов остаются неясными, но Cowan (2005) рассмотрел множество гипотез. Они не обязательно несовместимы; более чем один мог иметь заслуги. Есть два лагеря: (1) ограничения возможностей как слабые стороны и (2) ограничения возможностей как сильные стороны.
Лагерь -предел-возможностей-как-слабость предлагает причины, по которым мозгу было бы биологически дорого иметь больший объем рабочей памяти. Один из способов, которым это могло бы работать, состоит в том, что существует цикл обработки, в котором паттерны возбуждения нейронов, представляющие, скажем, четыре элемента или понятия, должны срабатывать по очереди в течение, скажем, каждых последовательных 100-миллисекундных периодов, иначе не все понятия останутся в памяти. активно в рабочей памяти. Представление большего количества элементов может быть неудачным, потому что вместе они слишком долго активируются по очереди, или потому, что шаблоны, расположенные слишком близко друг к другу во времени, создают помехи между шаблонами (например, красный квадрат и синий кружок не совпадают). -запоминается как красный кружок и синий квадрат).
Если вместо этого нейронные паттерны для нескольких понятий активны одновременно, может случиться так, что более чем четыре понятия приводят к интерференции между ними, или что каждому понятию назначаются отдельные мозговые механизмы с недостаточным количеством нейронов в некоторых критических местах, чтобы удерживать больше чем около четырех элементов, активных одновременно. В предлагаемых чтениях обсуждаются исследования нейровизуализации, показывающие, что одна область мозга, нижняя теменная борозда, кажется ограниченной, по крайней мере, для визуальных стимулов. Если способность — это слабость, то, возможно, высшие существа с другой планеты могут совершать подвиги, недоступные нам, потому что у них больший предел оперативной памяти, подобно нашим цифровым компьютерам (которые, однако, не могут выполнять сложную обработку, чтобы соперничать с людьми по ключевым параметрам).
Лагерь с пределом мощности и силой включает различные гипотезы. Математическое моделирование показывает, что при некоторых простых допущениях поиск информации наиболее эффективен, когда группы, подлежащие поиску, включают в среднем около 3,5 элементов. Список из трех элементов хорошо структурирован с началом, серединой и концом, служащими отдельными характеристиками маркировки элементов; список из пяти пунктов ненамного хуже, с двумя добавленными промежуточными позициями. Большее количество элементов может потерять различимость в списке. Относительно небольшая центральная рабочая память может позволить всем одновременно активным концепциям ассоциироваться друг с другом (разбиваться на части), не вызывая путаницы или отвлечения внимания. Несовершенные правила, такие как правила грамматики, можно выучить, не слишком беспокоясь об исключениях из правил, поскольку они часто теряются в нашей ограниченной рабочей памяти. Это может быть преимуществом, особенно у детей.
Тесты рабочей памяти демонстрируют практические ограничения, которые варьируются в зависимости от того, позволяют ли условия теста такие процессы, как группировка или репетиция, сосредоточение внимания только на материале, имеющем отношение к задаче, и использование модальности или специфических для материала запоминающих устройств для дополнить центральный магазин. Тем не менее недавняя работа предполагает, что существует основное ограничение центрального компонента рабочей памяти, обычно 3–5 фрагментов у молодых людей. Если мы внимательно относимся к контролю стимулов, пределы центральной способности полезны для предсказания того, какие мыслительные процессы могут выполняться людьми, и для понимания индивидуальных различий в когнитивной зрелости и интеллектуальных способностях. Вероятно, существуют факторы биологической экономии, ограничивающие центральную мощность, но в некотором смысле существующие ограничения могут быть идеальными или почти идеальными для человека.
Баддели, А. (2007). Рабочая память, мысли и действия . Нью-Йорк: Издательство Оксфордского университета. Эта книга представляет собой вдумчивое обновление традиционной теории рабочей памяти, взятое в ее широком контексте, включая обсуждение недавнего компонента эпизодического буфера, который может иметь общие характеристики с концепцией емкости центрального хранилища.
Коуэн, Н., и Роудер, Дж.Н. (под давлением). Комментарий к «Динамические сдвиги ограниченных ресурсов рабочей памяти в человеческом зрении». Наука . Эта статья обеспечивает математическое обоснование концепции фиксированного предела возможностей и защищает ее от альтернативной гипотезы о том, что внимание может быть рассеяно по всему предмету, представленному человеку.
Коуэн, Н. (2005). См. список литературы. Эта книга развивает статью Коуэна (2001), которая является краеугольным камнем исследования предела емкости, представляя аргументы в пользу ограничения центрального хранилища в контексте истории области, проводя ключевые различия и исследуя альтернативные теоретические объяснения предел.
Джонидес, Дж., Льюис, Р.Л., Ни, Д.Е., Лустиг, К.А., Берман, М.Г., и Мур, К.С. (2008). Ум и мозг кратковременной памяти. Ежегодный обзор психологии, 59 , 193–224. В этой обзорной статье в общих чертах рассматривается система рабочей памяти, принимая во внимание как поведенческие данные, так и данные о мозге, а также обсуждаются пределы емкости наряду с другими возможными ограничениями, такими как распад.
Клингберг, Т. (2009). Переполненный мозг: информационная перегрузка и пределы оперативной памяти . Нью-Йорк: Издательство Оксфордского университета. В этой книге широко и просто обсуждаются недавние исследования концепции емкости рабочей памяти, с акцентом на исследования мозга, тренировку рабочей памяти и практические последствия ограничений емкости.
Это исследование было поддержано грантом NIH R01 HD-21338. Читателям 26 -го -го века или позже: Название намекает на Волшебное таинственное турне , один из многих электромеханически записанных сборников ритмичной голосовой и инструментальной музыки о жизни и эмоциях группы The Beatles, британской четверки, которая имел мессианскую популярность.
- Баддели А.Д., Хитч Г. Рабочая память. В: Bower GH, редактор. Психология обучения и мотивации. Том. 8. Нью-Йорк: Академик Пресс; 1974. С. 47–89. [Google Scholar]
- Чен З., Коуэн Н. Объем основной вербальной рабочей памяти: Предел слов сохраняется без скрытой артикуляции.
 Quarterly Journal of Experimental Psychology (в печати) [бесплатная статья PMC] [PubMed] [Google Scholar]
Quarterly Journal of Experimental Psychology (в печати) [бесплатная статья PMC] [PubMed] [Google Scholar] - Коуэн Н. Волшебное число 4 в кратковременной памяти: пересмотр умственной емкости памяти. Поведенческие и мозговые науки. 2001; 24:87–185. [PubMed] [Академия Google]
- Коуэн Н. Объем оперативной памяти. Хоув, Восточный Суссекс, Великобритания: Psychology Press; 2005. [Google Scholar]
- Коуэн Н., Фристоу Н.М., Эллиотт Э.М., Бруннер Р.П., Солтс Дж.С. Объем внимания, контроль внимания и интеллект у детей и взрослых. Память и познание. 2006; 34: 1754–1768. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Cowan N, Morey CC. Как можно исследовать пределы удержания рабочей памяти при выполнении двух задач? Психологическая наука. 2007; 18: 686–688. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Коуэн Н., Мори К.С., ОБюшон А.М., Цвиллинг К.Э., Гилкрист А.Л. Семилетние дети распределяют внимание так же, как и взрослые, если рабочая память не перегружена. Наука о развитии (в печати) [бесплатная статья PMC] [PubMed] [Google Scholar]
- Гилкрист А.Л., Коуэн Н., Навех-Бенджамин М. Объем рабочей памяти для произносимых предложений уменьшается с возрастом: припоминание меньшего, но не меньшего количества фрагментов у пожилых людей. Память. 2008; 16: 773–787. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Gold JM, Fuller RL, Robinson BM, McMahon RP, Braun EL, Luck SJ. Интактный контроль внимания за кодированием рабочей памяти при шизофрении. Журнал ненормальной психологии. 2006; 115: 658–673. [PubMed] [Академия Google]
- Halford GS, Cowan N, Andrews G. Отделение когнитивных способностей от знаний: новая гипотеза. Тенденции в когнитивных науках. 2007; 11: 236–242. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Kane MJ, Bleckley MK, Conway ARA, Engle RW. Взгляд контролируемого внимания на объем рабочей памяти. Журнал экспериментальной психологии: Общие. 2001; 130:169–183. [PubMed] [Google Scholar]
- Миллер Г. А. Волшебное число семь плюс-минус два: некоторые ограничения нашей способности обрабатывать информацию. Психологический обзор. 1956;63:81–97. [PubMed] [Google Scholar]
- Миллер Г.А., Галантер Э., Прибрам К.Х. Планы и структура поведения. Нью-Йорк: Холт, Райнхарт и Уинстон, Инк.; 1960. [Google Scholar]
- Солтс Дж. С., Коуэн Н. Центральный предел емкости для одновременного хранения зрительных и слуховых массивов в рабочей памяти. Журнал экспериментальной психологии: Общие. 2007; 136: 663–684. [Бесплатная статья PMC] [PubMed] [Google Scholar]
- Vogel EK, McCollough AW, Machizawa MG. Нейронные показатели выявляют индивидуальные различия в управлении доступом к рабочей памяти. Природа. 2005; 438: 500–503. [PubMed] [Академия Google]
Нарушение кратковременной памяти — PubMed
Book
Marco Cascella 1 , Ясир Аль Халили 2
В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.
.
Принадлежности
Принадлежности
- 1 Istituto Nazionale Tumori — IRCCS — Fondazione Pascale, Via Mariano Semmola 80100, Неаполь. Италия
- 2 Университет Содружества Вирджинии
- PMID: 31424720
- Идентификатор книжной полки: НБК545136
Бесплатные книги и документы
Book
Marco Cascella et al.
Бесплатные книги и документы
Источник: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.
.
Авторы
Марко Каселла 1 , Ясир Аль Халили 2
Принадлежности
- 1 Istituto Nazionale Tumori — IRCCS — Fondazione Pascale, Via Mariano Semmola 80100, Неаполь. Италия
- 2 Университет Содружества Вирджинии
- PMID: 31424720
- Идентификатор книжной полки: НБК545136
Выдержка
Кратковременная память (STM), также называемая кратковременной памятью, или первичной или активной памятью, указывает на различные системы памяти, участвующие в сохранении фрагментов информации (фрагментов памяти) в течение относительно короткого времени (обычно до 30 секунд). ). Напротив, долговременная память (LTM) может хранить неопределенное количество информации. Однако разница между двумя воспоминаниями заключается не только в переменной «время», но прежде всего в функциональной. Тем не менее, эти две системы тесно связаны. На практике СТМ работает как своего рода «блокнот» для временного вспоминания ограниченного количества данных (в вербальной области это примерно «волшебное» число Джорджа Миллера 7 +/- 2 элемента), которые поступают из сенсорного регистра и готовы. обрабатываться посредством внимания и узнавания. С другой стороны, информация, собранная в хранилище LTM, состоит из воспоминаний о выполнении действий или навыков (т. е. процедурных воспоминаний, «знания как») и воспоминаний о фактах, правилах, концепциях и событиях (т. знаю это»). Декларативная память включает семантическую и эпизодическую память. Первое касается широкого знания фактов, правил, понятий и утверждений («общее знание»), второе связано с личными и пережитыми событиями и контекстами, в которых они происходили («личное воспоминание»).
Хотя STM тесно связан с концепцией «рабочей памяти» (WM), STM и WM представляют собой две разные сущности. STM действительно представляет собой набор систем хранения, тогда как WM указывает на когнитивные операции и исполнительные функции, связанные с организацией и манипулированием хранимой информацией. Тем не менее, можно услышать, что термины STM и WM часто используются как синонимы.
Кроме того, следует отличать СТМ от «сенсорной памяти» (СМ), такой как акустическая эхоическая и иконическая зрительная память, которые короче по продолжительности (доли секунды), чем СТМ, и отражают исходное ощущение , или восприятие раздражителя. Другими словами, СМ специфична для модальности предъявления стимула. Эта «сырая» сенсорная информация подвергается обработке, и когда она становится СТМ, она выражается в формате, отличном от первоначально воспринимаемого.
Знаменитая модель Аткинсона и Шиффрина (или модель с несколькими магазинами), предложенная в конце 1960-х годов, объясняет функциональные корреляции между STM, LTM, SM и WM. В дальнейшем значительное количество исследований продемонстрировало анатомо-функциональное различие между процессами памяти, а также нейронными коррелятами и функционированием подсистем СТМ и ДВП. В свете этих открытий было предложено несколько моделей памяти. В то время как некоторые авторы предполагали существование единой системы памяти, охватывающей как краткосрочное, так и долгосрочное хранение, спустя 50 лет модель Аткинсона и Шиффрина остается действенным подходом для объяснения динамики памяти. Однако в свете более поздних исследований у модели есть несколько проблем, в основном касающихся характеристик STM, взаимосвязи между STM и WM, а также перехода от STM к LTM.
Кратковременная память: значение и система(ы)
Это система хранения, включающая несколько подсистем с ограниченной емкостью. Это ограничение является не ограничением, а преимуществом эволюционного выживания, поскольку позволяет обращать внимание на ограниченную, но важную информацию, исключая смешанные факторы. Это классический пример жертвы, которая должна сосредоточиться на враждебной среде, чтобы распознать возможное нападение хищника. Учитывая функциональные особенности СТМ (сбора сенсорной информации), подсистемы тесно связаны с модальностями сенсорной памяти. Как следствие, было постулировано несколько сенсорно-ассоциированных подсистем, включая зрительно-пространственную, фонологическую (аудио-вербальную), тактильную и обонятельную области. Эти подсистемы связаны с различными закономерностями и функциональными взаимосвязями с соответствующими корковыми и подкорковыми областями и центрами.
Концепция оперативной памяти
В 1974 году Баддели и Хитч разработали альтернативную модель СТМ, которую они назвали рабочей памятью. Действительно, модель ВМ не исключает модальную модель, а обогащает ее содержание. С другой стороны, краткосрочный запас можно использовать для характеристики функционирования WM. WM относится скорее ко всей теоретической структуре структур и процессов, используемых для хранения и временной обработки информации, из которых STM является лишь компонентом. Другими словами, STM — это функциональный элемент хранения, а WM — это набор процессов, включающих также фазы хранения. ВМ Это память, которую мы постоянно используем, которая всегда «в сети», когда нам нужно что-то понять, решить проблему или привести аргумент, когнитивные стратегии для достижения краткосрочных целей. Доказательство важности такого рода «операционной системы» памяти подтверждается данными о том, что дефицит WM связан с несколькими нарушениями развития обучения, включая синдром дефицита внимания и гиперактивности (СДВГ), дислексию и специфические нарушения речи (SLI). .
Кратковременная и долговременная память
Эти типы памяти можно классически различать по емкости и продолжительности хранения. Возможности STM действительно имеют ограничения по объему и продолжительности хранения информации. Напротив, LTM обладает кажущейся неограниченной емкостью, которая может работать годами. Функциональные различия между системами хранения памяти и точные механизмы передачи памяти из ST в LTM остаются спорным вопросом. Представляют ли STM и LTM одну или несколько систем с определенными подсистемами? Хотя STM, вероятно, представляет собой подструктуру LTM, которая является своего рода долговременным активированным хранилищем, а не поиском «физического» разделения, представляется целесообразным проверить механизмы перехода от памяти, которая является только памятью. переход к прочной памяти. Хотя классическая мультимодальная модель предполагала, что сохранение воспоминаний ST происходит автоматически без манипуляций, дело, по-видимому, более сложное. Явление касается количественных (количество воспоминаний) и качественных (качество памяти) признаков.
Что касается количественных данных, хотя число Миллера 7 +/- 2 элемента определяет количество элементов, включенных в отдельные слоты, группировка битов памяти в более крупные фрагменты (чанкинг) может позволить хранить намного больше информации большего размера и продолжать сохранить магическое число. Качественная проблема, или модуляция памяти при обработке, — увлекательное явление. Кажется, что элементы СТМ подвергаются обработке, которая обеспечивает своего рода редактирование, включающее фрагментацию каждого элемента (чанкинг) и его переработку и переработку. Эта фаза обработки памяти называется кодирование и может обусловливать последующую обработку, включая хранение и поиск. Процесс кодирования включает в себя автоматическую (без сознательного осознания) и требующую усилий обработку (с помощью внимания, практики и размышлений) и позволяет нам извлекать информацию, которая используется для принятия решений, ответов на вопросы и так далее. На этапе кодирования используются три пути: визуальное (информация, представленная в виде изображения), акустическое (информация, представленная в виде звука) и семантическое кодирование (значение информации). Процессы взаимосвязаны друг с другом, поэтому информация разбивается на разные компоненты. Во время восстановления путь, вызвавший кодирование, способствует восстановлению других компонентов посредством единственной цепной реакции. Например, определенный аромат заставляет нас вспомнить определенный эпизод или образ. Следует отметить, что процесс кодирования влияет на восстановление, но само восстановление подвергается ряду потенциальных изменений, которые могут изменить исходное содержимое.
С нейрофункциональной точки зрения разница между СТМ и ДВ заключается в том, что в ДП происходит серия событий, которые должны окончательно зафиксировать инграмму (инграммы). Этот эффект возникает за счет образования нейронных сетей и выражается в виде нейрофункциональных явлений, включая долговременную потенциацию (ДП), которая представляет собой увеличение силы нейронной передачи в результате усиления синаптических связей. Этот процесс требует экспрессии генов и синтеза новых белков и связан с длительными структурными изменениями в синапсах (синаптическая консолидация) вовлеченных областей мозга, таких как гиппокамп, в случае декларативной памяти.
Роль гиппокамповой сети
Следует отметить, что нейрогенез гиппокампа регулирует поддержание LTP. Однако гиппокампальная сеть, включающая парагиппокампальную извилину, гиппокамп и области неокортекса, не является местом хранения воспоминаний, но играет решающую роль в формировании новых воспоминаний и их последующей реактивации. Похоже, что гиппокамп имеет ограниченные возможности и получает информацию быстро и автоматически, не сохраняя ее надолго. Со временем изначально имевшаяся информация становится постоянной в других структурах мозга (в коре), независимо от активности самого гиппокампа. Важнейшим механизмом этого переноса является реактивация («воспроизведение») конфигураций нейронной активности. Другими словами, гиппокамп и связанные с ним медиальные височные структуры имеют решающее значение для удержания события в целом, поскольку он организованно распределяет следы памяти. Это операционная система, которая с помощью различного программного обеспечения может хранить, систематизировать, обрабатывать и восстанавливать аппаратные файлы. Эта управляемая гиппокампом реактивация (извлечение) приводит к созданию прямых связей между корковыми следами, а затем к формированию интегрированного представления в неокортексе, включая зрительную ассоциативную кору для зрительной памяти, височную кору для слуховой памяти и левую латеральная височная кора для понимания значения слов. Кроме того, у гиппокампа есть и другие специфические задачи, например, в организации пространственной памяти.
Другие области мозга участвуют в процессах памяти; например, изучение двигательных навыков связано с активацией областей мозжечка и ядер ствола мозга. Кроме того, обучение перцептивной деятельности (улучшение обработки перцептивных стимулов, необходимых в повседневной жизни, таких как понимание устной и письменной речи) включает в себя базальные ганглии, сенсорную и ассоциативную кору, тогда как обучение когнитивным навыкам (связанным с решением проблем) вовлекает медиальную часть. височные доли изначально.
Авторское право © 2022, StatPearls Publishing LLC.
Разделы
- Непрерывное образование
- Введение
- Этиология
- Эпидемиология
- Патофизиология
- История и физические
- Оценка
- Лечение / Управление
- Дифференциальный диагноз
- Улучшение результатов команды здравоохранения
- Обзорные вопросы
- использованная литература
Похожие статьи
-
Физиология, Эксплицитная память.
Джавабри К.Х., Касселла М. Джавабри К.Х. и др. 2022 г., 8 мая. В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–. 2022 г., 8 мая. В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–. PMID: 32119438 Бесплатные книги и документы.
-
Суицидальная идея.
Хармер Б., Ли С., Дуонг ТВХ, Саадабади А. Хармер Б. и др. 2022 г., 18 мая. В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–. 2022 г., 18 мая. В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–. PMID: 33351435 Бесплатные книги и документы.
-
Макромолекулярная скученность: химия и физика встречаются с биологией (Аскона, Швейцария, 10–14 июня 2012 г.
).
Foffi G, Pastore A, Piazza F, Temussi PA. Фоффи Г. и др. физ.-биол. 2013 авг; 10 (4): 040301. дои: 10.1088/1478-3975/10/4/040301. Epub 2013 2 августа. физ.-биол. 2013. PMID: 23912807
-
Аграфия.
Тиу Дж.Б., Картер А.Р. Тиу Дж. Б. и др. 2022 г., 1 мая. В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–. 2022 г., 1 мая. В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–. PMID: 32809557 Бесплатные книги и документы.
-
Агнозия.
Кумар А., Письменный М. Кумар А. и др. 2 февраля 2022 г. В: StatPearls [Интернет]. Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–. 2 февраля 2022 г. В: StatPearls [Интернет].
Остров сокровищ (Флорида): StatPearls Publishing; 2022 янв.–.
PMID: 29630208
Бесплатные книги и документы.
Посмотреть все похожие статьи
использованная литература
-
- Волшебное число непосредственной памяти Коуэна Н. Джорджа Миллера в ретроспективе: наблюдения за неустойчивым прогрессом науки. Psychol Rev. 2015 г., июль; 122 (3): 536-41. — ЧВК — пабмед
-
-
Миллер Э.К., Лундквист М., Бастос А.М. Рабочая память 2.0. Нейрон. 2018 24 октября; 100 (2): 463-475.
—
ЧВК
—
пабмед
-
Миллер Э.К., Лундквист М., Бастос А.М. Рабочая память 2.0. Нейрон.
-
- Аткинсон Р.С., Шиффрин Р.М. Контроль кратковременной памяти. наук Ам. 1971 г., август; 225 (2): 82–90. — пабмед
-
-
Баддели А.Д., Хитч Г.Дж. Развитие рабочей памяти: следует ли объединить модели Паскуаль-Леоне и Баддели и Хитча? J Exp Детская психология. 2000 г. , октябрь; 77 (2): 128–37.
—
пабмед
-
Баддели А.Д., Хитч Г.Дж. Развитие рабочей памяти: следует ли объединить модели Паскуаль-Леоне и Баддели и Хитча? J Exp Детская психология. 2000 г.
-
- Мадл Т., Франклин С., Чен К., Траппл Р., Монтальди Д. Изучение структуры пространственных представлений. ПЛОС Один. 2016;11(6):e0157343. — ЧВК — пабмед
Типы публикаций
Память и хранилище: выбор решения для хранения данных
Ежедневно создается более одного триллиона мегабайт новых данных, и все они должны где-то храниться. Выбор способа хранения — одно из самых важных решений для организации в мире, управляемом данными. По мере роста вашего бизнеса вы захотите улучшить свою ИТ-инфраструктуру, чтобы вместить больше данных или рисковать снижением производительности или, что еще хуже, утечкой данных.
Готовы ли вы отказаться от устаревших систем или модернизировать современные системы, чтобы сделать их более удобными для удаленного доступа, мы здесь, чтобы предоставить вам знания, чтобы принять наилучшее решение для ваших потребностей в хранении данных. Поиск наилучшего решения начинается с понимания одной ключевой вещи, которую многие понимают неправильно: разницы между памятью и хранилищем.
Знание того, как отличить одно от другого, убережет вас от напрасной траты денег на выбор решения, не предназначенного для конкретных нужд вашего бизнеса.
Сначала мы поговорим о различиях высокого уровня, а затем углубимся в то, что это значит для вас.
Начнем.
В чем разница между памятью и хранилищем?
Когда речь идет о хранении данных, термины «память» и «хранилище» имеют несколько значений. Память часто относится к основному хранилищу, чаще всего к оперативной памяти (ОЗУ), а хранилище относится к вторичному хранилищу. Двумя популярными примерами вторичного хранилища являются жесткие диски (HDD) и их более новая форма, твердотельные накопители (SSD или NVMe).
Извлечение данных, хранящихся в ОЗУ, выполняется быстрее, чем извлечение данных из хранилища, но недостатком ОЗУ является то, что данные неустойчивы. Это означает, что данные, хранящиеся в ОЗУ, являются временными и стираются, как только компьютер выключается или происходит сбой. С другой стороны, данные в хранилище известны тем, что они являются энергонезависимыми и более постоянными, поскольку они могут сохраняться даже при отключении питания.
Оперативная память пригодится, если вашему бизнесу необходимо регулярно выполнять одновременные задачи в нескольких приложениях или вам нужна максимальная производительность вашей базы данных, а хранилище полезно, если вашему бизнесу необходимо хранить большие объемы данных и программного обеспечения.
Рассмотрим оперативную память поближе.
Что делает ОЗУ?
Оперативная память является важной частью, определяющей производительность вашей системы. Когда люди говорят о производительности компьютера, обновление оперативной памяти, как правило, является одним из первых соображений (хотя это не всегда ответ). Вообще говоря, чем больше оперативной памяти у вашего компьютера, тем больше вещей он может выполнять одновременно без снижения производительности.
Несколько из многих случаев, когда вы используете оперативную память, — это когда вы ищете в Интернете и щелкаете между различными открытыми программами. Если вы заметили низкую производительность, скорее всего, у вас слишком мало оперативной памяти или запущено слишком много программ и приложений. При низких скоростях у вас есть возможность увеличить объем оперативной памяти среди многих других решений.
Теперь давайте проясним общий вопрос:
Что дает добавление дополнительной оперативной памяти?
Увеличение объема ОЗУ повышает производительность, и хорошо иметь достаточное количество оперативной памяти на случай внезапного увеличения рабочей нагрузки. Вы не хотите, чтобы вас застали за обеспечением определенного уровня скорости и производительности только для того, чтобы внезапное увеличение спроса (например, всплеск числа пользователей или трафик в праздничные дни) исчерпало всю доступную оперативную память и, в свою очередь, снизило скорость и производительность. для ваших пользователей или сотрудников.
Общепризнанно, что с точки зрения производительности оперативной памяти не бывает слишком много. Если вы добавите больше ОЗУ на компьютер при его пределе ОЗУ, это не повлияет на производительность, но это может привести к пустой трате ваших денег. Увеличение оперативной памяти редко бывает бесплатным, и есть момент, когда другие решения, такие как приобретение нового сервера, более рентабельны. Вам также может понадобиться подумать, может ли ваше программное обеспечение эффективно использовать всю доступную оперативную память, установленную на компьютере. (Некоторым приложениям для масштабирования и нормального функционирования требуются целые кластеры компьютеров!)
Теперь, когда вы лучше понимаете оперативную память, давайте узнаем больше о решениях для внешнего хранения, в частности, о жестких дисках и твердотельных накопителях.
Традиционно память компьютера хранилась на жестких дисках (HDD), которые, как правило, работают медленно, поскольку для хранения информации используются вращающиеся магнитные диски. Затем появился SSD, который до 10 раз быстрее, чем HDD, при извлечении данных, потому что он использует микросхемы специализированных схем (флеш-память) вместо магнитного диска (что означает более высокую производительность!) Хотя SSD выше по скорости и значительно снизился в цене в последние годы HDD остается самым дешевым решением для больших наборов данных.
Еще несколько преимуществ твердотельных накопителей включают быстрое время чтения и записи, меньшее энергопотребление и, как следствие, потребность в меньшем охлаждении.
Другими видами внешних компьютерных хранилищ, с которыми вы, возможно, знакомы, являются USB-накопители, компакт-диски, DVD-диски, MicroSD (обычно используемые в смартфонах), MemoryStick, карты CompactFlash и флэш-накопители (обычно используемые с планшетами и ноутбуками).
Теперь мы не можем говорить о хранении, не говоря о дата-центрах и облачных хранилищах.
Центры обработки данных Vs. Облачное хранилище
Все данные вашего бизнеса должны где-то храниться. В прошлом единственным вариантом было хранить большое количество внешнего оборудования для хранения данных на месте, что могло быстро стать дорогостоящим и поставить ваши данные под угрозу, но в настоящее время у вас есть больше вариантов, включая сторонние центры обработки данных и облачное хранилище.
Центры обработки данных
Проще говоря, в центрах обработки данных размещаются компьютерные системы и системы хранения данных, и они являются основной частью ИТ-операций. Помимо хранения и управления данными, в центрах обработки данных размещается множество серверов, они помогают выполнять резервное копирование и восстановление, а также предоставляют сетевые услуги.
В прошлом только крупные предприятия могли позволить себе содержать центры обработки данных, но с появлением колокационных центров обработки данных малые предприятия также могут воспользоваться преимуществами.
На что следует обратить внимание при выборе центра обработки данных:
-
Суверенитет данных и правила: Многие предприятия получили огромные штрафы за игнорирование правил, специфичных для местоположения. Суверенитет данных касается таких правил, как GDPR и HIPAA. Обязательно выберите доверенную третью сторону для хранения ваших данных.
-
Расстояние: Как правило, чем короче расстояние между центром обработки данных и конечным пользователем, тем ниже задержка. Низкая задержка идеально подходит для производительности и скорости. Более того, некоторые приложения работают очень плохо с высокой задержкой, например, голосовые или видеоконференции. Расстояние до вашего центра обработки данных особенно важно учитывать, если вы живете в удаленных местах, поскольку расположение многих общедоступных облачных сервисов достаточно далеко, чтобы некоторые важные приложения работали очень плохо.
-
Безопасность: Недавно сообщалось, что средняя стоимость кибератаки в 2020 году составила около 8,64 миллиона долларов.
Имейте в виду, что физическая безопасность так же важна, как и кибербезопасность, когда вы выбираете свой центр обработки данных, вы доверяете третьей стороне поддерживать физическую безопасность ваших ИТ-активов.
Облачное хранилище
Облачное хранилище — это способ хранения данных вне офиса у третьих лиц, доступ к которым возможен через Интернет или при подключении к частной сети. Он известен своей способностью к масштабированию, поскольку вы можете хранить на нем практически бесконечное количество данных, потому что он не ограничен аппаратным обеспечением. Более того, многие поставщики облачных услуг предлагают тарифы «оплата по мере использования» или «оплата по мере роста», что позволяет напрямую масштабировать затраты в зависимости от потребления.
Существует три основных формы облачного хранилища: общедоступное, частное и гибридное.
Общедоступное облачное хранилище:
Выбирая общедоступное облачное хранилище, вы доверяете третьей стороне свои данные, доступ к которым вы получите через подключение к Интернету. Есть несколько заметных плюсов и минусов выбора общедоступного облачного решения.
Давайте сначала рассмотрим некоторые положительные факторы:
- Эластичный характер: Общедоступные облака позволяют увеличивать и уменьшать затраты в зависимости от потребностей. При надлежащем управлении и автоматизации это может привести к значительной экономии чистых затрат. Однако важно отметить, что если вы не используете эти эластичные качества эффективно, вы можете в конечном итоге заплатить значительно больше (25%+), чем за традиционный локальный центр обработки данных или частное облачное решение.
- Прозрачность затрат : При надлежащем управлении и автоматизации можно легко отнести затраты к конкретным видам деятельности, а также установить и измерить ключевые показатели эффективности (KPI), которые помогают формировать идеальное поведение потребителей.
- Подходит для удаленного доступа: Поскольку доступ к нему осуществляется через Интернет, он очень удобен для компаний, работающих дома или удаленно.
Хотя возможность доступа к облаку через Интернет является положительным фактором, это также может быть и недостатком, поскольку вы становитесь зависимым от надежного подключения к Интернету с высокой пропускной способностью. Если ваш основной бизнес находится в сети, вы должны убедиться, что у вас есть емкость и избыточность для подключения к Интернету, иначе вы можете столкнуться со многими проблемами, если не сможете подключиться.
Благодаря таким решениям, как Secure SD-WAN и отказоустойчивость интернет-провайдера, а также нашей наземной оптоволоконной сети AlCan ONE, мы помогли компаниям, переходящим на облачные технологии, удовлетворить потребность в надежном интернет-соединении.
Еще несколько возможных недостатков общедоступного облачного решения включают:
- Риск соответствия: Вы доверяете хранение данных вашей компании третьему лицу, поэтому очень важно убедиться, что вы выбираете надежную компанию.
- Конфиденциальность конфиденциальных данных: Публичный характер облака затрудняет защиту конфиденциальных данных (хотя за последние несколько лет ситуация значительно улучшилась).
Теперь, когда у вас есть четкое представление о плюсах и минусах общедоступного облачного решения, давайте поговорим о частных и гибридных облачных решениях.
Частное облачное хранилище: Частные облака обеспечивают большую безопасность и скорость, но меньшую масштабируемость, чем общедоступные облака, из-за их закрытого характера. Он также может быть более настраиваемым и специфичным для ваших бизнес-потребностей. Частное облако может храниться в помещении или быть доверено третьей стороне.
Гибридное облачное хранилище:
Гибридные облака предлагают удачное сочетание частных и общедоступных облаков. Это хорошо для того, чтобы помочь вам справиться с проблемами регулирования и суверенитета данных. Гибрид позволяет компаниям выбирать, какие данные нуждаются в дополнительной безопасности, а какие больше выиграют от возможности масштабирования.
При выборе облачных решений следует учитывать некоторые моменты: скрытые сборы и сборы за превышение лимита, проблемы суверенитета данных и дорогостоящие услуги пропускной способности. Выставление счетов иногда может быть сложным для понимания, поэтому в Ampersand мы предлагаем простую для понимания модель выставления счетов для наших гибридных облачных решений.
Теперь, когда вы лучше понимаете варианты хранения данных, давайте немного поговорим о вашем бизнесе.
ОЗУ и хранилище: бизнес-вопросы, которые следует задать себе
Вот несколько хороших вопросов, которые следует задать себе, когда вы решаете, что важнее для вашего бизнеса:
- Зависит ли мой бизнес в большей степени от способности обеспечивать высокую производительность или мы больше выигрываем от возможности хранить большие объемы данных? ?
- Сколько пользователей нам нужно поддерживать?
- В равной степени ли важны для нас скорость и объем памяти?
- Действительно ли время простоя расстроит наших клиентов?
- Насколько велика наша база данных?
- Сколько трафика будет принимать наш сервер?
- Сколько приложений и программ нам необходимо?
В настоящее время лучший ответ на ваши идеальные потребности в хранении заключается в комбинировании решений для хранения, а не в выборе одного. Некоторые части вашего бизнеса, которые зависят от производительности, выиграют от ОЗУ или, возможно, SSD, в то время как другие части могут больше выиграть от выбора жесткого диска или использования облачного хранилища.
Производительность компьютера и удовлетворенность сотрудников
В 21 веке нет ничего более неприятного, чем медленный компьютер, который часто выходит из строя. Время – деньги, и когда технология работает не лучшим образом, это влияет на производительность ваших сотрудников. Intel сообщила, что старые и медленные компьютеры могут сделать сотрудника на на 29 процентов менее продуктивным , что обходится компании примерно в 17 тысяч долларов за один старый компьютер.
Ненадежные серверы и медленные технологии из-за слишком большого объема данных — это не то, с чем сегодня должен сталкиваться бизнес с таким количеством доступных вариантов. Ваши сотрудники заслуживают того, чтобы им предоставлялись технологии, на которые они могут положиться. Ненадежная технология снижает удовлетворенность сотрудников, что, в свою очередь, может повлиять на корпоративную культуру и текучесть кадров.
Внедрение лучших решений для хранения данных
Каждое предприятие имеет уникальные потребности в памяти и хранении данных. К счастью, мы живем во время, когда у вас есть много вариантов. Если вам нужна помощь в поиске лучших решений для хранения данных для вашей конкретной организации, мы здесь, чтобы помочь.
Крупные предприятия доверили нам свои потребности в хранении данных, воспользовавшись преимуществами наших центров обработки данных и специализированных гибридных облачных решений. Свяжитесь с нами чтобы узнать больше.
Что такое компьютерная память и как она используется?
Хранение данных — это коллективные методы и технологии, которые собирают и сохраняют цифровую информацию на электромагнитных, оптических или кремниевых носителях. Хранилище используется в офисах, центрах обработки данных, периферийных средах, удаленных местах и домах людей. Память также является важным компонентом мобильных устройств, таких как смартфоны и планшеты. Потребители и предприятия полагаются на хранилище для хранения информации, начиная от личных фотографий и заканчивая критически важными для бизнеса данными.
Хранилище часто используется для описания устройств, которые подключаются к компьютеру — напрямую или по сети — и которые поддерживают передачу данных посредством операций ввода-вывода (I/O). Устройства хранения могут включать жесткие диски (HDD), твердотельные накопители (SSD) на основе флэш-памяти, приводы оптических дисков, ленточные системы и другие типы носителей.
Почему важно хранить данные
С появлением больших данных, расширенной аналитики и изобилия устройств Интернета вещей (IoT) хранение как никогда важно для обработки растущих объемов данных. Современные системы хранения также должны поддерживать использование искусственного интеллекта (ИИ), машинного обучения и других технологий ИИ для анализа всех этих данных и извлечения их максимальной ценности.
Современные сложные приложения, аналитика баз данных в режиме реального времени и высокопроизводительные вычисления также требуют высокоплотных и масштабируемых систем хранения, будь то сети хранения данных (SAN), масштабируемые и масштабируемые сетевые хранилища (NAS). ), платформы хранения объектов или конвергентная, гиперконвергентная или компонуемая инфраструктура.
Согласно отчету ИТ-аналитической компании IDC, к 2025 году ожидается создание 163 зеттабайт (ZB) новых данных. Оценка представляет собой потенциальное десятикратное увеличение по сравнению с 16 ZB, произведенными до 2016 года. IDC также сообщает, что только в 2020 году было создано или воспроизведено 64,2 ZB данных.
Как работает хранилище данных
Термин «хранилище» может относиться как к хранимым данным, так и к интегрированным аппаратным и программным системам, используемым для сбора, управления, защиты и определения приоритетов этих данных. Данные могут поступать из приложений, баз данных, хранилищ данных, архивов, резервных копий, мобильных устройств или других источников, и они могут храниться локально, в периферийных вычислительных средах, на объектах совместного размещения, на облачных платформах или в любой их комбинации.
Требования к емкости хранилища определяют, сколько места необходимо для хранения этих данных. Например, простые документы могут занимать всего килобайты памяти, в то время как графические файлы, такие как цифровые фотографии, могут занимать мегабайты, а видеофайлы могут занимать гигабайты памяти.
В компьютерных приложениях обычно указываются минимальные и рекомендуемые требования к емкости, необходимые для их запуска, но это лишь часть истории. Администраторы хранилища также должны учитывать, как долго данные должны храниться, применимые нормативные требования, используются ли методы сокращения данных, требования к аварийному восстановлению (DR) и любые другие проблемы, которые могут повлиять на емкость.
В этом видео от CHM Nano Education объясняется роль магнетизма в хранении данных.
Жесткий диск представляет собой круглую пластину, покрытую тонким слоем магнитного материала. Диск вставляется в шпиндель и вращается со скоростью до 15 000 оборотов в минуту (об/мин). При вращении данные записываются на поверхность диска с помощью магнитных записывающих головок. Высокоскоростной исполнительный рычаг позиционирует записывающую головку на первое доступное место на диске, позволяя записывать данные по кругу.
На электромеханическом диске, таком как HDD, блоки данных хранятся в секторах. Исторически жесткие диски использовали сектора размером 512 байт, но ситуация начала меняться с введением расширенного формата, который может поддерживать сектора размером 4096 байт. Расширенный формат увеличивает плотность битов на каждой дорожке, оптимизирует способ хранения данных и повышает эффективность формата, что приводит к увеличению емкости и надежности.
На большинстве твердотельных накопителей данные записываются на объединенные микросхемы флэш-памяти NAND, которые используют либо ячейки с плавающим затвором, либо ячейки ловушки заряда для сохранения своих электрических зарядов. Эти заряды определяют состояние двоичного бита (1 или 0). Технически SSD — это не накопитель, а скорее интегральная схема, состоящая из кремниевых чипов миллиметрового размера, которые могут содержать тысячи или даже миллионы нанотранзисторов.
Многие организации используют иерархическую систему управления хранилищем для резервного копирования своих данных на дисковые устройства. Резервное копирование данных считается передовой практикой, когда данные необходимо защитить, например, когда организации подпадают под действие правовых норм. В некоторых случаях организация будет записывать свои резервные данные на магнитную ленту, используя ее в качестве третичного уровня хранения. Однако такой подход практикуется реже, чем в прошлые годы.
В организации также может использоваться виртуальная ленточная библиотека (VTL), которая вообще не использует ленты. Вместо этого данные записываются на диски последовательно, но сохраняют характеристики и свойства ленты. Ценность VTL заключается в его быстром восстановлении и масштабируемости.
Измерение объемов хранения
Цифровая информация записывается на целевой носитель с помощью программных команд. Наименьшей единицей измерения в памяти компьютера является бит, который имеет двоичное значение 0 или 1. Значение бита определяется уровнем электрического напряжения, содержащегося в одном конденсаторе. Восемь бит составляют один байт.
Компьютеры, системы хранения данных и сетевые системы используют два стандарта для измерения объемов памяти: десятичную систему с основанием 10 и двоичную систему с основанием 2. Для небольших объемов хранения расхождения между двумя стандартами обычно не имеют большого значения. Однако эти несоответствия становятся гораздо более заметными по мере увеличения емкости хранилища.
Различия между двумя стандартами можно увидеть при измерении как битов, так и байтов. Например, следующие измерения показывают разницу в значениях битов для нескольких распространенных десятичных (с основанием 10) и двоичных (с основанием 2) измерений:
- 1 килобит (Кб) равен 1000 бит; 1 кибибит (Kib) равен 1024 битам
- 1 мегабит (Мб) равен 1000 Кб; 1 мебибит (Миб) равен 1024 КБ
- 1 гигабит (Гб) равен 1000 Мб; 1 гибибит (Gib) равен 1024 МБ
- 1 терабит (Тб) равен 1000 Гб; 1 тебибит (тиб) равен 1024 гиб
- 1 петабит (Pb) равен 1000 Tb; 1 пебибит (пиб) равен 1024 тиб
- 1 эксабит (Eb) равен 1000 Pb; 1 exbibit (Eib) равен 1024 Pib
Различия между десятичными и двоичными стандартами также можно увидеть для нескольких распространенных измерений байтов:
- 1 килобайт (КБ) равен 1000 байт; 1 кибибайт (КиБ) равен 1024 байтам
- 1 мегабайт (МБ) равен 1000 КБ; 1 мебибайт (МиБ) равен 1024 КиБ
- 1 гигабайт (ГБ) равен 1000 МБ; 1 гибибайт (ГиБ) равен 1024 МБ
- 1 терабайт (ТБ) равен 1000 ГБ; 1 тебибайт (ТиБ) равен 1024 ГиБ
- 1 петабайт (ПБ) равен 1000 ТБ; 1 пебибайт (ПиБ) равен 1024 ТиБ
- 1 эксабайт (ЭБ) равен 1000 ПБ; 1 эксбибайт (EiB) равен 1024 PiB
Измерения хранилища могут относиться к емкости устройства или объему данных, хранящихся в устройстве. Суммы часто выражаются с использованием десятичных соглашений об именах, таких как килобайты, мегабайты или терабайты, независимо от того, основаны ли суммы на десятичных или двоичных стандартах.
К счастью, многие системы теперь различают эти два стандарта. Например, производитель может указать доступную емкость на устройстве хранения как 750 ГБ, что основано на десятичном стандарте, в то время как операционная система указывает доступную емкость как 698 ГиБ. В этом случае ОС использует двоичный стандарт, четко показывая несоответствие между двумя измерениями.
Некоторые системы могут предоставлять измерения на основе обоих значений. Примером этого является IBM Spectrum Archive Enterprise Edition, в котором для представления хранения данных используются как десятичные, так и двоичные единицы измерения. Например, система отобразит значение 512 терабайт как 9.0095 512 ТБ (465,6 ТиБ) .
Немногим организациям требуется одна система хранения или подключенная система, которая может хранить эксабайт данных, но есть системы хранения, которые масштабируются до нескольких петабайт. Учитывая скорость, с которой растут объемы данных, эксабайтное хранилище может в конечном итоге стать обычным явлением.
В чем разница между оперативной памятью и хранилищем?
Оперативная память (ОЗУ) — это аппаратное обеспечение компьютера, в котором временно хранятся данные, к которым процессор компьютера может быстро получить доступ. Данные могут включать в себя файлы ОС и приложений, а также другие данные, важные для текущих операций компьютера. Оперативная память является основной памятью компьютера и работает намного быстрее, чем обычные устройства хранения, такие как жесткие диски, твердотельные накопители или оптические диски.
Оперативная память компьютера обеспечивает немедленную доступность данных для процессора, как только они потребуются.
Самая большая проблема с оперативной памятью заключается в том, что она энергозависима. Если компьютер теряет питание, все данные, хранящиеся в оперативной памяти, теряются. Если компьютер выключается или перезагружается, данные необходимо загрузить заново. Это сильно отличается от типа постоянного хранилища, предлагаемого твердотельными накопителями, жесткими дисками или другими энергонезависимыми устройствами. Если они теряют питание, данные все равно сохраняются.
Хотя большинство запоминающих устройств намного медленнее, чем оперативная память, их энергонезависимость делает их необходимыми для выполнения повседневных операций.
Устройства хранениятакже дешевле в производстве и могут хранить гораздо больше данных, чем ОЗУ. Например, большинство ноутбуков имеют 8 ГБ или 16 ГБ ОЗУ, но они также могут поставляться с сотнями гигабайт или даже терабайтами памяти.
Оперативная памятьобеспечивает мгновенный доступ к данным. Хотя хранилище также связано с производительностью, его конечная цель — обеспечить безопасное хранение данных и доступ к ним при необходимости.
Оценка иерархии хранилища
Организации все чаще используют многоуровневое хранилище для автоматизации размещения данных на различных носителях. Данные размещаются на определенном уровне в зависимости от емкости, производительности и соответствия требованиям. Уровни данных, в самом простом случае, начинаются с классификации данных как первичных или вторичных, а затем их сохранения на носителе, наиболее подходящем для этого уровня, с учетом того, как используются данные и какой тип носителя для этого требуется.
Значения первичных и вторичных хранилищ менялись с годами. Первоначально основное хранилище относилось к ОЗУ и другим встроенным устройствам, таким как кэш-память L1 процессора, а вторичное хранилище относилось к твердотельным накопителям, жестким дискам, лентам или другим энергонезависимым устройствам, которые поддерживали доступ к данным посредством операций ввода-вывода.
Основное хранилище обычно обеспечивало более быстрый доступ, чем вторичное хранилище, из-за близости хранилища к процессору компьютера. С другой стороны, вторичное хранилище может содержать гораздо больше данных и может реплицировать данные на резервные устройства хранения, обеспечивая при этом высокую доступность активных данных. Это было также дешевле.
Хотя такое использование все еще сохраняется, термины «первичное» и «вторичное хранилище» приобрели немного разные значения. В наши дни основное хранилище, иногда называемое основным хранилищем, обычно относится к любому типу хранилища, которое может эффективно поддерживать повседневные приложения и бизнес-процессы. Основное хранилище обеспечивает непрерывную работу рабочих нагрузок приложений, занимающих центральное место в повседневном производстве и основных направлениях деятельности компании. Первичные носители данных могут включать твердотельные накопители, жесткие диски, память класса хранения (SCM) или любые устройства, обеспечивающие производительность и емкость, необходимые для выполнения повседневных операций.
Напротив, вторичное хранилище может включать практически любой тип хранилища, не считающийся первичным. Вторичное хранилище может использоваться для резервных копий, моментальных снимков, справочных данных, архивных данных, старых операционных данных или любых других типов данных, которые не являются критически важными для основных бизнес-операций. Вторичное хранилище обычно поддерживает резервное копирование и аварийное восстановление и часто включает облачное хранилище, которое иногда является частью конфигурации гибридного облака.
Цифровая трансформация бизнеса также побудила все больше и больше компаний использовать несколько облачных хранилищ, добавляя удаленный уровень, который расширяет вторичное хранилище.
Типы устройств/носителей данных
В самом широком смысле носители данных могут относиться к широкому спектру устройств, которые обеспечивают различные уровни емкости и скорости. Например, это может быть кэш-память, динамическая оперативная память (DRAM) или основная память; магнитная лента и магнитный диск; оптические диски, такие как CD, DVD и Blu-ray; твердотельные накопители на основе флэш-памяти, устройства SCM и различные варианты хранения в оперативной памяти. Однако при использовании термина «хранилище данных» большинство людей имеют в виду жесткие диски, твердотельные накопители, устройства SCM, оптические накопители или ленточные системы, отличая их от энергозависимой памяти компьютера.
используют пластины, уложенные друг на друга, покрытые магнитным носителем, с головками дисков, которые считывают и записывают данные на носитель. Жесткие диски широко используются в персональных компьютерах, серверах и корпоративных системах хранения данных, но их быстро вытесняют твердотельные накопители, которые обеспечивают превосходную производительность, обеспечивают большую надежность, потребляют меньше энергии и занимают меньше места. Они также начинают достигать ценового паритета с жесткими дисками, хотя этого еще не произошло.
Внешний жесткий диск Большинство твердотельных накопителей хранят данные на микросхемах энергонезависимой флэш-памяти. В отличие от вращающихся дисков, твердотельные накопители не имеют движущихся частей и все чаще встречаются во всех типах компьютеров, несмотря на то, что они дороже жестких дисков. Некоторые производители также поставляют устройства хранения данных, в которых используется флэш-память на серверной части и высокоскоростной кэш-память, например DRAM, на внешней стороне.
В отличие от жестких дисков, флэш-накопители не используют движущиеся механические части для хранения данных, что обеспечивает более быстрый доступ к данным и меньшую задержку по сравнению с жесткими дисками. Флэш-память является энергонезависимой, как и жесткие диски, что позволяет данным сохраняться в памяти, даже если система хранения теряет питание, но флэш-память еще не достигла того же уровня надежности, что и жесткий диск, что приводит к гибридным массивам, которые объединяют оба типа носителей. (Стоимость является еще одним фактором при разработке гибридных хранилищ.) Однако, когда речь идет о долговечности твердотельных накопителей, типы рабочих нагрузок и устройства NAND также могут играть важную роль в долговечности устройства, и в этом отношении твердотельные накопители могут значительно отличаться от одного устройства к другому.
С 2011 года все больше предприятий внедряют массивы all-flash на основе технологии флэш-памяти NAND в качестве дополнения или замены массивов жестких дисков. Организации также начинают использовать устройства SCM, такие как твердотельные накопители Intel Optane, которые обеспечивают более высокую скорость и меньшую задержку, чем хранилища на основе флэш-памяти.
Intel Optane SSD на базе 3D XPoint Когда-то внутренние и внешние оптические накопители широко использовались в потребительских и бизнес-системах. На оптических дисках может храниться программное обеспечение, компьютерные игры, аудиоконтент или фильмы. Их также можно использовать в качестве вторичного хранилища для любого типа данных. Тем не менее, достижения в области технологий жестких дисков и твердотельных накопителей, а также распространение потоковой передачи через Интернет и флэш-накопителей с универсальной последовательной шиной (USB) уменьшили зависимость от оптических накопителей. Тем не менее, оптические диски гораздо более долговечны, чем другие носители данных, и их производство недорого, поэтому они до сих пор используются для аудиозаписей и фильмов, а также для долгосрочного архивирования и резервного копирования данных.
встраиваются в цифровые камеры и мобильные устройства, такие как смартфоны, планшеты, аудиомагнитофоны и медиаплееры. Флэш-память также используется на картах Secure Digital, CompactFlash, MultiMediaCard (MMC) и USB-накопителях.
Флэш-память Физические магнитные гибкие диски в наши дни используются редко, если вообще используются. В отличие от старых компьютеров, новые системы не оснащены дисководами для гибких дисков. Использование гибких дисков началось в 19 в.70-х, но диски были сняты с производства в конце 1990-х. Иногда вместо 3,5-дюймовой физической дискеты используются виртуальные дискеты, что позволяет пользователям монтировать файл образа так же, как диск A: на компьютере.
предлагают интегрированные системы NAS, помогающие организациям собирать большие объемы данных и управлять ими. Аппаратное обеспечение включает в себя массивы хранения или серверы хранения, оснащенные жесткими дисками, флэш-накопителями или их гибридной комбинацией. Система NAS также поставляется с программным обеспечением ОС для хранения данных для предоставления услуг данных на основе массива.
Схема массива хранения Многие корпоративные массивы хранения поставляются с программным обеспечением для управления хранением данных, которое предоставляет средства защиты данных для архивирования, клонирования или управления резервным копированием, репликацией или моментальными снимками. Программное обеспечение также может обеспечивать управление на основе политик для управления размещением данных для их распределения по уровням во вторичном хранилище данных или для поддержки плана аварийного восстановления или долгосрочного хранения. Кроме того, многие системы хранения теперь включают функции сокращения объемов данных, такие как сжатие, дедупликация данных и тонкое выделение ресурсов.
Стандартные конфигурации хранения
Во многих современных системах хранения данных для бизнеса используются три основных варианта: хранилище с прямым подключением (DAS), NAS и сеть хранения данных (SAN).
корпоративный массив хранения данных Pure Storage FlashBladeПростейшей конфигурацией является DAS, которая может быть внутренним жестким диском на отдельном компьютере, несколькими дисками на сервере или группой внешних дисков, которые подключаются непосредственно к серверу через такой интерфейс, как интерфейс малых компьютеров (SCSI). Serial Attached SCSI (SAS), Fibre Channel (FC) или Internet SCSI (iSCSI).
NAS представляет собой файловую архитектуру, в которой несколько файловых узлов совместно используются пользователями, как правило, в локальной сети на основе Ethernet (LAN). Система NAS имеет несколько преимуществ. Для этого не требуется полнофункциональная операционная система корпоративного хранилища, устройствами NAS можно управлять с помощью утилиты на основе браузера, а каждому сетевому узлу назначается уникальный IP-адрес, что упрощает управление.
С масштабируемым NAS тесно связано хранилище объектов, которое устраняет необходимость в файловой системе. Каждый объект представлен уникальным идентификатором, и все объекты представлены в одном плоском пространстве имен. Хранилище объектов также поддерживает широкое использование метаданных.
Сеть SAN может охватывать несколько центров обработки данных, которым требуется высокопроизводительное блочное хранилище. В среде SAN блочные устройства отображаются для хоста как локально подключенное хранилище. Каждый сервер в сети может получить доступ к общему хранилищу, как если бы это был диск с прямым подключением.
Современные технологии хранения
Достижения в области флэш-памяти NAND в сочетании с падением цен в последние годы проложили путь к программно-определяемым системам хранения. Используя эту конфигурацию, предприятие устанавливает недорогие твердотельные накопители на серверы на базе x86, а затем использует стороннее программное обеспечение для хранения данных или пользовательский код с открытым исходным кодом для применения управления хранением.
Энергонезависимая экспресс-память (NVMe) — это стандартный отраслевой протокол, разработанный специально для твердотельных накопителей на основе флэш-памяти. NVMe быстро становится протоколом де-факто для флеш-накопителей. Флэш-память NVMe позволяет приложениям напрямую взаимодействовать с центральным процессором (ЦП) через каналы PCIe Interconnect Peripheral Component Interconnect Express (PCIe), минуя необходимость передачи наборов команд SCSI через адаптер сетевой хост-шины.
NVMe может использовать преимущества технологии SSD так, как это невозможно с интерфейсами SATA и SAS, которые были разработаны для более медленных жестких дисков. По этой причине NVMe over Fabrics (NVMe-oF) был разработан для оптимизации связи между твердотельными накопителями и другими системами через сетевую структуру, такую как Ethernet, FC и InfiniBand.
Энергонезависимый двухрядный модуль памяти (NVDIMM) представляет собой гибридное устройство NAND и DRAM со встроенным резервным питанием, которое подключается к стандартному слоту DIMM на шине памяти. Устройства NVDIMM выполняют обычные вычисления в DRAM, но используют флэш-память для других операций. Однако для распознавания устройства хост-компьютеру требуются необходимые драйверы базовой системы ввода-вывода (BIOS).
NVDIMM используются в основном для расширения системной памяти или повышения производительности хранилища, а не для увеличения емкости. Текущие модули NVDIMM на рынке имеют максимальную емкость 32 ГБ, но форм-фактор увеличил плотность с 8 ГБ до 32 ГБ всего за несколько лет.
Энергонезависимый двухрядный модуль памяти (NVDIMM) представляет собой гибрид NAND и DRAM.Основные поставщики систем хранения данных
Консолидация на корпоративном рынке в последние годы привела к расширению круга поставщиков первичных систем хранения данных. Те компании, которые вышли на рынок с дисковыми продуктами, в настоящее время получают большую часть своих продаж от систем хранения на основе флэш-памяти или гибридных систем хранения, включающих как твердотельные, так и жесткие диски.
Ведущие поставщики на рынке включают:
- Dell EMC, подразделение хранения данных Dell Technologies
- Hewlett Packard Enterprise (HPE)
- Хитачи Вантара
- Хранилище IBM
- Инфинидат
- NetApp
- Чистое хранилище
- Корпорация Квант
- Кумуло
- Тинтри
- Вестерн Диджитал
Более мелкие поставщики, такие как Drobo, iXsystems, QNAP и Synology, также продают различные типы продуктов для хранения данных. Кроме того, ряд поставщиков теперь предлагают решения гиперконвергентной инфраструктуры (HCI), включая Cisco, DataCore, Dell EMC, HPE, NetApp, Nutanix, Pivot3, Scale Computing, StarWind и VMware. Многие поставщики корпоративных хранилищ также предлагают конвергентные и компонуемые инфраструктурные продукты под брендом.
Узнайте о преимуществах и проблемах управления хранением данных и способах управления стратегией хранения данных .
Узнайте больше о различных типах памяти здесь
Воспоминания бывают разных форм. Исследователи многое не понимают в человеческой памяти и в том, как она работает.
В этой статье рассматриваются типы памяти и то, что человек может сделать, чтобы улучшить память.
Существует множество теорий о типах памяти человеческого мозга. Большинство ученых считают, что существует по крайней мере четыре основных типа памяти:
- рабочая память
- сенсорная память
- кратковременная память
- долговременная память
Некоторые исследователи предполагают, что это не отдельные типы памяти, а скорее этапы памяти.
С этой точки зрения память начинается с сенсорной памяти, переходит в кратковременную память, а затем может перейти в долговременную память.
Память, которую человек использует только в течение короткого времени, например, слово, которое он использует в начале предложения, является частью рабочей памяти и никогда не может перемещаться в другую часть памяти.
Некоторые исследователи мозга делят эти типы памяти на более конкретные категории.
Сенсорная память хранит сенсорную информацию в течение очень коротких промежутков времени, обычно 1 секунду или меньше. В этом типе памяти начинается обработка воспоминаний и другой информации.
Если человек обращает внимание на сенсорный ввод, то информация может перемещаться в кратковременную, а затем в долговременную память.
Некоторые примеры сенсорной памяти включают:
- регистрацию звуков, которые человек слышит во время прогулки
- краткое осознание чего-либо в поле зрения человека образы, звуки и другие сенсорные ощущения.
Когда конкретный сенсорный опыт становится актуальным, например запах чего-то на кухне, он может перемещаться в другие типы памяти.
В противном случае сенсорные воспоминания очень кратковременны, и человек быстро их забывает.
Например, человек не вспомнит все конкретные звуки, которые он слышал за последние 30 секунд, 30 минут или 30 дней, если только у него нет причины их помнить.
Кратковременная память позволяет человеку вспомнить ограниченную последовательность информации в течение короткого периода времени.
Эти воспоминания исчезают быстро, примерно через 30 секунд.
Кратковременная память — это не просто память, которая длится недолго. Вместо этого это тип недолговечного хранилища, в котором может храниться только несколько фрагментов информации.
Некоторые примеры кратковременной памяти включают:
- запоминание строки из 5–7 слов и повторение ее в обратном порядке
- запоминание телефонного номера во время записи ручкой
Рабочая память аналогична кратковременной памяти.
терминальная память. Однако, в отличие от последней, рабочая память — это место, где человек манипулирует информацией. Это помогает им вспомнить детали их текущей задачи. Некоторые виды поведения, использующие рабочую память, включают:
- решение сложной математической задачи, когда человек должен запомнить несколько чисел
- выпечка чего-либо, что требует от человека вспомнить ингредиенты, которые он уже добавил
- участие в дебатах, во время которых человек должен вспомнить основные аргументы и доказательства, которые использует каждая сторона
В то время как исследователи обычно разделяют рабочие и краткосрочные памяти на две разные категории, исследования часто обнаруживают значительное совпадение между ними.
Долговременная память хранит множество воспоминаний и переживаний.
Большинство воспоминаний, которые помнят люди, особенно старше 30 секунд, являются частью долговременной памяти.
Многие исследователи делят долговременную память на две подкатегории: неявную и явную.
Эксплицитная долговременная память
Эксплицитная память — это сознательные воспоминания о событиях, автобиографических фактах или вещах, которые человек узнает.
Некоторые типы явной долговременной памяти включают следующее.
Эпизодическая память
Это воспоминания о событиях или автобиографических фактах. Примеры эпизодической памяти включают воспоминания о выборах, событиях из детства и личных фактах, например о том, что кто-то женат.
Семантическая память
Семантическая память – это общие знания о мире. Человек может вспомнить факт или событие, которые он не испытал, потому что узнал или изучил его.
Например, знание того, как выглядит человеческое сердце, является примером семантической памяти. Однако это будет эпизодическое воспоминание, если человек вспомнит, как в школе вскрывал свиное сердце.
Имплицитная долговременная память
Имплицитная память — это воспоминания, влияющие на поведение человека.
Однако люди сознательно о них не думают. Некоторые типы этой памяти включают следующие.
Процедурная память
Процедурная память помогает человеку выполнять привычные действия, такие как ходьба или вождение автомобиля.
Сначала им, возможно, придется учиться делать эти вещи и запоминать определенные навыки, но со временем эти задачи автоматически становятся частью процедурной памяти.
Прайминг
Прайминг происходит, когда опыт влияет на поведение человека.
Например, курильщику может хотеться выкурить сигарету после еды, или экспериментатор может научить человека нажимать кнопку в ответ на фотографию.
Классическое и оперантное приучение людей или животных к определенным действиям в ответ на определенные переживания.
Рабочая, сенсорная и кратковременная память имеют меньший объем. Это потому, что эти типы воспоминаний длятся только в течение короткого периода времени.
При кратковременной памяти обычно существует определенный предел объема информации, который человек может удерживать — обычно около семи элементов.
Некоторые люди могут увеличить объем кратковременной памяти с практикой.
Мозг не компьютер, и воспоминания не занимают физического пространства. Теоретически не существует определенного ограничения емкости долговременной памяти.
Однако качество воспоминаний и их детали могут меняться со временем.
Воспоминания могут быть ненадежными
Мозг не записывает воспоминания идеально, поэтому воспоминания могут изменяться или исчезать со временем.
Многочисленные исследования показывают, что воспоминания ненадежны, даже если человек помнит что-то очень четко.
В ходе одного исследования, проведенного в 2015 году, исследователи смогли всего за несколько часов убедить невинных людей в том, что они совершали серьезные преступления, такие как нападение с применением оружия, в подростковом возрасте.
Может у кого есть фотографическая память?
У некоторых людей необыкновенно хорошая память. Люди с гипертимезией, чрезвычайно редким заболеванием, могут помнить все или большинство автобиографических воспоминаний.