
Равен тест: Тест на IQ | Бесплатный современный аналог прогрессивных матриц Равена онлайн
Матрицы Равена: уникальный тест на определение уровня интеллекта
Д. Равен вместе с Л. Пенроузом создали в 1936 году уникальные матрицы Равена. Прогрессивная методика была разработана для определения умственного уровня и оценки способностей к систематизации, методологии, логическому мышлению. Джон Равен придумал универсальный тест, результат которого почти не зависит от знаний, уровня жизни и опыта испытуемых. Стандартные матрицы предназначены как для тестирования взрослых людей, так и для детей.
Как проводится тестирование?
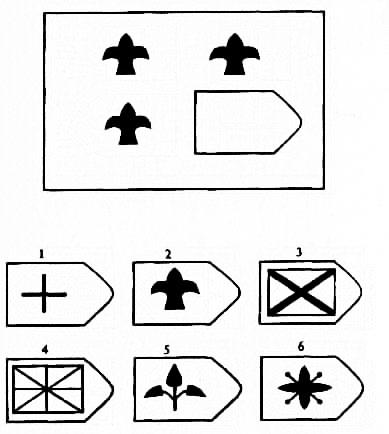
В матрицы входят 60 графических рисунков. В рисунке недостает простой фигуры, например, прямоугольника. Под рисунком размещены 6 или 8 фрагментов, которые почти подходят по размеру к недостающей фигуре. Основной задачей является обработка и поиск фрагментов той фигуры, которая точно подходила бы в пустое место. Суть проективного метода заключается в том, чтобы логически определить по какому принципу составлен графический рисунок, к которому необходимо подобрать недостающую фигуру. То есть необходимо понять закономерность, по которой связаны фигуры на изображение. На выполнение 60 заданий дается всего 20 минут. В первой группе рисунки простые, затем с каждой серией сложность прогрессирует.
Матрицы Равена поделены на 5 групп, в каждой из которой 15 рисунков. Серии рисунков разделены по определенным принципам и типам сложности. В каждой группе содержатся задания разного уровня:
Первая серия А разработана по принципу определения структуры рисунка и ее взаимосвязи. Необходимо найти одну из частей рисунка, которая точно подойдет к недостающей части основного рисунка. Задание направлено на детальную оценку составляющих изображения и поиск таких же деталей в одном из предложенных фрагментов.
Серия В содержит принцип поиска аналогии между несколькими фигурами. Человеку необходимо понять закономерность, по которой создана каждая фигура и, ориентируясь на это, определить отсутствующую часть рисунка. Нужно отыскать осевую симметрию, размещенную в фигуре.
Серия С разработана по принципу усовершенствования и усложнения фигур. С каждой серией фигуры видоизменяются, то есть происходит постепенное непрерывное развитие. Фигуры заполняются новыми частями по определенному принципу, по которому можно найти в последующих рисунках отсутствующие фигуры.
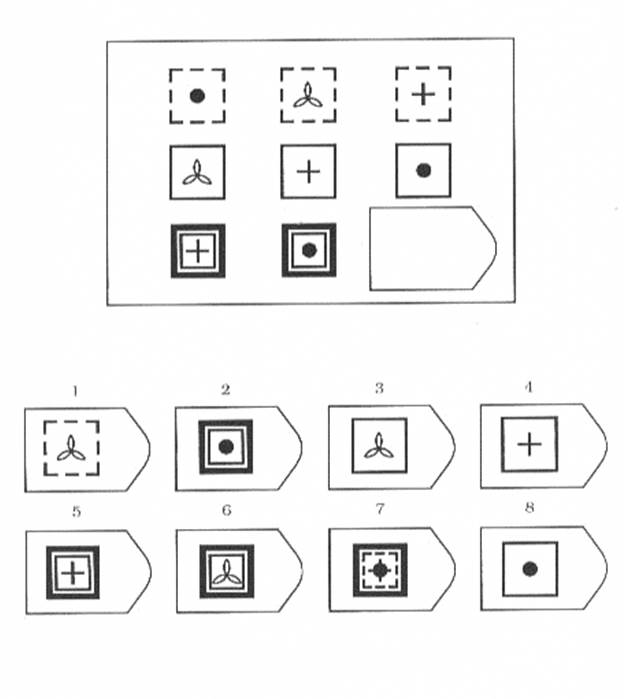
Серия D содержит принцип перестановки основных фигур. Человеку необходимо определить в разных плоскостях (горизонтальном и вертикальном) перегруппировку.
Серия Е составлена по принципу разделения основных фигур на части. Подходящие фигуры нужно собрать, определив закономерность составления фигур.
Пройдите онлайн-курсы бесплатно и откройте для себя новые возможности Начать изучениеГде используются продвинутые матрицы Равена?
- В научной сфере для изучения умственных способностей людей из других этнических и культурных групп, исследования генетических и образовательных различий интеллектуальных процессов.
- В профессиональной сфере, где необходимо определить сильные стороны работников, например, эффективных администраторов или менеджеров, кураторов или маркетологов.
- В образование деятельности, где есть потребность в прогнозе будущих результатов учащихся, независимо от уровня их жизни и опыта .
- В медицинской сфере для определения нейропсихологических проблем, для подтверждения результатов, которые были получены другими методами при измерение интеллектуальной способности.
Тестирование людей на определение уровня интеллекта является востребованным почти в любой сфере деятельности. Важно постоянно прокачивать свой мозг, продвигать себя, как специалиста, развивать компетенции и узнавать что-то новое. На платформе «Россия — страна возможностей» размещены бесплатные онлайн-курсы по маркетингу, личностному росту, финансам, менеджменту и другие. Пройдите курс «Личная ответственность за результат: результат-ориентированное мышление» и повысьте свой уровень интеллекта в моменте. Результат-ориентированное мышление помогает быстрее добиваться целей, осознанно принимать решения и грамотно использовать имеющиеся ресурсы.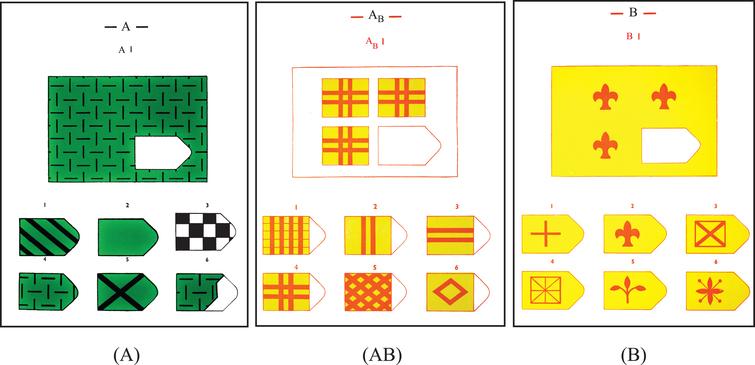
База знаний: Категория соответствия (Психологический тест: краткий отчет)
Как выставляется категория пригодности?Первая категория – Рекомендуется в первую очередь выставляется в случае, если выполнено каждое из условий:
1. Критерий «Достоверность тестирования» больше или равен 7 баллов
2. Критерий «Психическая склонность к профессии» больше или равен 8 баллов
3. Критерий «Психологическое состояние» больше или равен 9 баллов
4. Критерий «Интеллектуальные способности» (при условии, что этот критерий присутствует) больше или равен требуемого в данной профессии уровня интеллекта
5. Критерий «Вывод эксперта» (при условии, что этот критерий присутствует) больше или равен 9 баллов
Вторая категория – Рекомендуется выставляется в случае, если выполнено каждое из условий:
1. Условия первой категории не выполнены
2. Критерий «Достоверность тестирования» больше или равен 5 баллов
3. Критерий «Психическая склонность к профессии» больше или равен 6 баллов
4. Критерий «Психологическое состояние» больше или равен 7 баллов
5. Критерий «Интеллектуальные способности» (при условии, что этот критерий присутствует) больше или равен уровня, который меньше на 1 требуемого уровня интеллекта в данной профессии
6. Критерий «Вывод эксперта» (при условии, что этот критерий присутствует) больше или равен 7 баллов
Третья категория – Рекомендуется при отсутствии конкурса выставляется в случае, если выполнено каждое из условий:
1. Условия первой и второй категории не выполнены
2. Критерий «Достоверность тестирования» больше или равен 3 баллов
3. Критерий «Психическая склонность к профессии» больше или равен 4 баллов
Критерий «Психическая склонность к профессии» больше или равен 4 баллов
4. Критерий «Психологическое состояние» больше или равен 4 баллов
5. Критерий «Интеллектуальные способности» (при условии, что этот критерий присутствует) больше или равен уровня, который меньше на 2 требуемого уровня интеллекта в данной профессии
6. Критерий «Вывод эксперта» (при условии, что этот критерий присутствует) больше или равен 4 баллов
Четвертая категория – Не рекомендуется выставляется в случае, если не выполнены условия первой, второй и третьей категории.
Три простых правила относительно квадратного корня. Часть 3
GRE Mathematics
уделяет особое внимание заданиям на квадратный корень. В двух предыдущих частях статьи, мы рассматривали, что делать, если все числа в задании положительные. Если же это не так, то следует применять ещё 2 правила GRE Maths.
Правило №2: если x2 = 9, то x = 3, x = -3
Эта ситуация отлична от описанных ранее . Мы больше не имеем знака квадратного корня, зато здесь есть показатель степени. Если 3 возвести в квадрат, то мы получим 9. Если мы возведем -3 в квадрат – мы также получим 9. Следовательно, оба числа являются возможным значением x, потому что оба делают равенство верным.
С математической точки зрения, мы бы сказали, что x = 3 или x = -3. Если вы выполняете задание в разделе Quantitative Comparison, подумайте об этом следующим образом: если одно из них является возможным значением x, то оба варианта должны быть рассмотрены возможными значениями при сравнении Величины А и Величины В.
Правило №3: √(x)2 = 3, если x = 3, x = -3
Итак, вернемся к знаку квадратного корня, но теперь у нас есть и показатель степени! Что дальше? Указывать только положительное число, потому что мы имеем знак корня? Или указывать оба значения, потому что есть показатель степени?
Сначала вычислите значение x: возведите в степень оба значения √(x)2 = 3, чтобы получить x
2 = 9.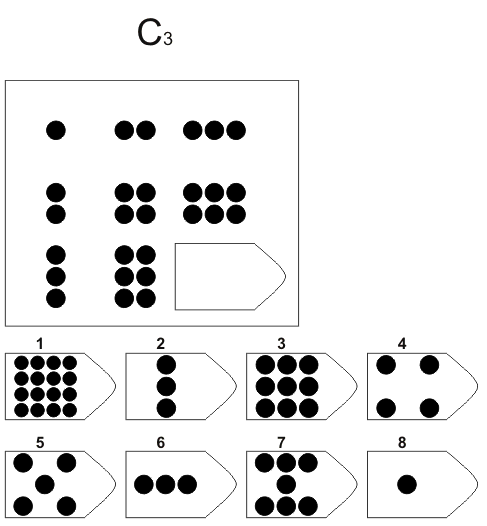 Вычислите квадратный корень, чтобы получить x = 3, x = -3 (как в правиле №2).
Вычислите квадратный корень, чтобы получить x = 3, x = -3 (как в правиле №2).
Подставьте оба числа в данное равенство, √x2 = 3, и посмотрите, делают ли они равенство верным. Если мы подставим 3 в равенство √x2 = 3, мы получим: √(3)2 = 3. Верно ли это? Да: √(3)2 = √9 и это действительно равняется 3.
Теперь подставьте в равенство -3: √(-3)2= 3. Под корнем у нас стоит отрицательное число, но также в скобках у нас есть квадратная степень. Следуйте установленному порядку действий: возведите число в квадрат, чтобы получить √9. Больше нет никаких отрицательных чисел под знаком корня! Заканчивая решение задачи, мы получаем √9, и снова это должно равняться 3, поэтому -3 тоже является возможным значением x. X может быть равен как 3, так и -3.
GRE Math Practice: Как это все не забыть?
Запомните: в первом примере представлено либо действительное число, либо очевидная переменная (не возведение в степень!) под знаком квадратного корня. В обоих случаях мы должны получить решение с положительными значениями корня, но не отрицательными.
Второй и третий примеры имеют квадратную степень. Во втором правиле нет знака квадратного корня – в этом случае мы можем получить и положительный, и отрицательный ответ. В нашем третьем правиле есть и знак квадратного корня, и степень в квадрате. В этой ситуации мы должны произвести расчеты, как показано в примере. Сначала мы решаем оба варианта, а затем подставляем их в исходное равенство. Если эти варианты делают равенство верным, то это и есть правильный ответ.
Подготовка к GRE Test включает в себя штудирование не только официальных учебников, но также изучение советов и подсказок, которые представлены здесь. Возможно, на самом тесте вам пригодятся именно они! Успехов!
Пример несложного задания на квадратные корни в тесте GRE:
По материалам сайта: www.manhattanprep.com
Применение теста Стандартные прогрессивные матрицы Равена в режиме ограничения времени
9
Индивидуальный темп работы, таким образом, не оказался однозначным
предиктором результативности SPM.
Средние значения тестовых баллов SPM в режиме 20 мин. ограничения
(см. таб. 1) для испытуемых моложе 30 лет оказались ниже, опубликованных
данных для безлимитной по времени версии теста (Равен и др., 2012, с. 39).
Существенных гендерных различий в показателях SPM нет, за исключением
возрастной группы 10-12 лет (в этой группе значимость различий
подтверждается критерием U-Манна-Уитни, p=0,008). Это совпадает с
данными британской стандартизации SPM 1979 года, показавшей отсутствие
половых различий во всех возрастных группах, за исключением возраста 11
лет 6 месяцев (Равен и др., 2012, с. 19).
Таблица 1
Показатели распределения средних значений SPM в режиме 20
минутного ограничения времени по половым и возрастным группам
Возраст
(лет)
мужчины женщины мужчины и женщины
Nсредне
е
станд.
откл. Nсредне
е
станд.
откл. Nсредне
е
станд.
откл.
10 — 12 80 34,60 10,02 80 38,86 8,24 160 36,73 9,39
13 — 15 162 38,96 8,58 146 38,56 9,49 308 38,77 9,01
16 — 18 216 41,10 9,49 243 42,32 8,13 459 41,75 8,81
19 — 21 387 42,36 9,73 502 42,48 9,14 889 42,43 9,39
22 — 24 287 43,33 9,43 285 43,71 8,93 572 43,52 9,18
25 — 27 158 41,50 10,43 180 42,57 9,40 338 42,07 9,90
28 — 30 169 42,75 9,68 193 43,30 9,28 362 43,04 9,46
31 — 33 123 41,64 9,79 177 42,95 10,07 300 42,41 9,96
34 — 36 109 40,84 11,24 160 42,05 9,75 269 41,56 10,38
37 — 39 118 41,70 11,63 185 40,83 10,99 303 41,17 11,23
40 — 42 194 40,76 10,60 229 41,62 10,09 423 41,22 10,32
43 — 45 183 41,22 9,53 251 40,56 10,14 434 40,84 9,88
46 — 48 147 42,20 9,45 202 41,27 10,60 349 41,66 10,13
49 — 51 119 40,13 10,08 168 40,13 9,68 287 40,13 9,83
52 — 55 128 38,20 10,70 188 38,14 11,18 316 38,17 10,97
56 — 60 74 38,78 9,18 107 38,76 9,34 181 38,77 9,25
61 — 65 45 34,53 8,70 44 36,25 10,37 89 35,38 9,55
Всего 2699 41,05 10,06 3340 41,44 9,80 6039 41,27 9,92
Тест карантину не товарищ – Газета Коммерсантъ № 102 (6823) от 10.
 06.2020
06.2020
Как выяснил “Ъ”, после начала тестирования москвичей на антитела департамент здравоохранения Москвы был вынужден пересмотреть ряд критериев, по которым людям рекомендуют соблюдать двухнедельную самоизоляцию. Так, с 15 мая опасным показателем носительства вируса считался уровень иммуноглобулина М (IgM) более единицы: людей с таким результатом рекомендовалось отправлять на карантин. На практике выяснилось, что у уже переболевших людей этот показатель может оставаться выше единицы на фоне высокого показателя иммунитета (IgG). В таких случаях, отмечают ученые, иммунитет уже сформирован, и показатель IgM можно не учитывать.
Семья жителей района Проспект Вернадского, которые в конце апреля переболели COVID-19 и были выписаны в начале мая, сдали в июне тест на антитела к коронавирусной инфекции и спустя несколько дней узнали, что «снова оказались на двухнедельном карантине». Напомним, о начале исследования популяционного иммунитета (выявления числа переболевших москвичей со сформированным иммунитетом к COVID-19) московские власти заявили 14 мая.
Как ранее сообщал “Ъ”, клинический комитет по борьбе с коронавирусной инфекцией при департаменте здравоохранения Москвы сформулировал рекомендации по действиям поликлиник в зависимости от результатов тестирования. Так, показатель иммуноглобулина М (IgM, свидетельствует о носительстве вируса) больше единицы, по мнению членов комитета, говорит о «стадии иммунологического ответа на вирус SARS-CoV-2». Таким пациентам рекомендуется «соблюдать самоизоляцию две недели, с учетом особенности процесса до трех недель». Если же показатель IgM меньше единицы, а показатель иммуноглобулина G (IgG, показатель иммунитета к вирусу после перенесенной болезни) больше или равен 10, также рекомендовалась «самоизоляция на две недели, если нет информации о ранее перенесенной новой коронавирусной инфекции». Позже в департаменте здравоохранения Москвы заявили, что для людей с высоким показателем IgG решение о двухнедельной самоизоляции является добровольным.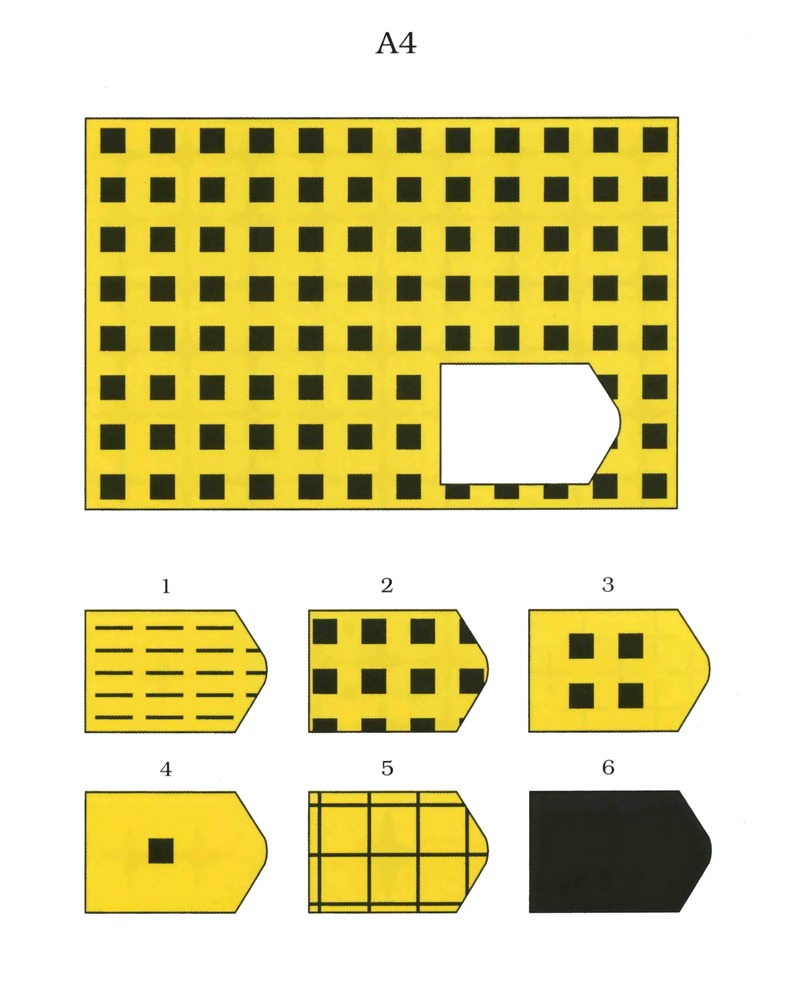
Однако как рассказала “Ъ” получившая результаты теста женщина на условиях анонимности, соблюдать карантин ей и членам ее семьи было рекомендовано не из-за высокого показателя IgG (у четырех членов ее семьи он составляет от 50 до 80), а из-за показателя носительства вируса IgM — он превышал единицу, составляя от 1,24 до 1,7:
«Нам позвонили и сказали, что мы попали в базу Роспотребнадзора автоматически из-за IgM и теперь должны опять самоизолироваться. Несмотря на то что мы переболели еще в апреле и с 9 по 12 мая все были выписаны. Позвонивший нам врач из поликлиники объяснил, что такая ситуация сейчас у многих людей, сдавших тесты на антитела».
В распоряжении “Ъ” также есть запись нескольких разговоров пациентов с представителями той же поликлиники — им подтверждают, что они «попали в систему», из которой их «смогут убрать» только 16 июня. Один из дежурных администраторов поликлиники рассказал пациентам, что несколько дней назад «спустили указание о том, что на самоизоляцию теперь будут отправлять только с показателем IgM больше 2».
В Роспотребнадзоре объяснили “Ъ”, что база, о которой говорили пациентам, ведомством «никогда не велась»: «Обследование москвичей на наличие антител к COVID-19 в рамках оценки популяционного иммунитета организовано департаментом здравоохранения Москвы». В департаменте на запрос “Ъ” ответили, что программа по мониторингу популяционного иммунитета «соответствует подходам, разработанным специалистами института имени Габричевского Роспотребнадзора». Прямого ответа на вопрос “Ъ”, действительно ли изменен показатель IgM, при котором будут направлять людей на карантин, в департаменте не дали, но представили другие «критерии интерпретации результатам тестирования». «Если у человека IgM больше или равен двум, а IgG больше или равен 10, то у пациента имеются антитела к вирусу. При этом наличие IgM говорит о том, что вирус все еще может находиться в организме, и человек может переносить инфекцию в скрытой, бессимптомной форме.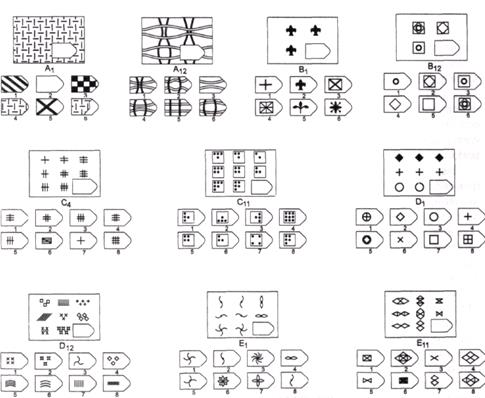 Данное заболевание еще не до конца изучено, поэтому в качестве профилактической меры рекомендуется сократить контакты с близкими людьми в течение семи дней, а через неделю повторно сдать кровь из вены»,— отметили в департаменте.
Данное заболевание еще не до конца изучено, поэтому в качестве профилактической меры рекомендуется сократить контакты с близкими людьми в течение семи дней, а через неделю повторно сдать кровь из вены»,— отметили в департаменте.
Как выяснил “Ъ”, в инструкции тестов, которые используются для обследования москвичей, говорится, что результаты IgM «в диапазоне 1–2… могут принадлежать пациентам без симптомов или недавно заболевшим пациентам, которые не успели выработать антитела в достаточном количестве».
Как полагает молекулярный биолог Ирина Якутенко, такая трактовка может быть верна только в случае, если показатели IgG отрицательны: «Когда мы видим высокий титр IgG, уже не важно, какой титр IgM». «В Nature Medicine недавно было опубликовано исследование о том, что у IgM и IgG нет принципиальной разницы во времени появления и показатель IgM держится достаточно долго,— рассказала эксперт.— Если мы видим существенные титры антител IgG, то человек уже не заразен. Уже несколько исследований показали, что основной пик заразности наступает до начала симптомов. Есть работы, которые показывают, что через четыре дня после начала симптомов люди уже не заразны — болезнь может развиваться, но люди уже не являются распространителями вируса». Случившееся с московской семьей она назвала «плохой историей»: «Теперь люди будут всеми силами избегать тестирования». Госпожа Якутенко называет консервативным и подход чиновников к срокам карантина: «Назначаемый период в две недели избыточен. Сейчас в мире уже 7 млн заболевших, и по ним есть данные. Мы знаем, что инкубационный период гораздо короче и составляет 5–7 дней максимум».
После выхода материала в Московском научно-исследовательском институте эпидемиологии и микробиологии имени Габричевского Роспотребнадзора заявили, что не сотрудничали с департаментом здравоохранения Москвы в рамках подготовки программы тестирования на антитела к коронавирусной инфекции. «ФБУН МНИИЭМ им.Г.Н.Габричевского Роспотребнадзора не разрабатывал подходы и программу по оценке популяционного иммунитета в городе Москве к возбудителю COVID-19 и с департаментом здравоохранения Москвы по этому вопросу не контактировал»,— сообщили “Ъ” в институте.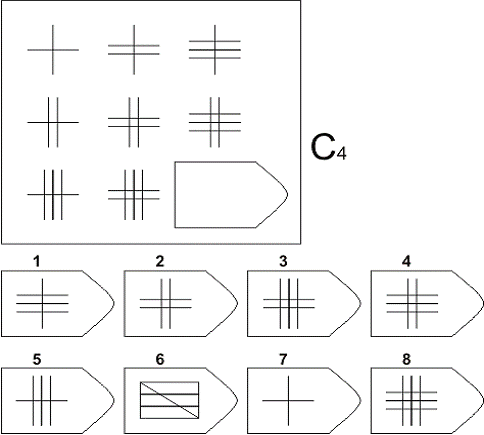
Валерия Мишина
сдать анализ в Москве, цены и адреса клиник АО Семейный доктор
Когда нужен анализ на антитела к SARS-CoV-2 (коронавирусу COVID-19)
Анализ на на антитела позволяет узнать, был ли у вас контакт с возбудителем заболевания, а если был, то как давно. С помощью данного анализа можно уточнить стадию заболевания, а также определить, сформировался ли иммунитет (как при естественном контакте с возбудителем, так и в случае вакцинации).
Анализ на антитела обычно проводится как дополнительное исследование. Если есть подозрение на COVID-19 или вам нужен официальный документ об отсутствии заболевания (для выезда за рубеж, либо по возвращению из-за границы, либо для плановой госпитализации или в иных целях), то в этом случае необходимо сделать анализ методом ПЦР.
Что такое антитела и какими они бывают
Антитела — это белки, вырабатываемые иммунной системой в ответ на проникновение возбудителя. Именно по ним определяют стадию развития инфекции. Также по ним контролируют течение заболевания. Антитела разделяются на классы:
Антитела IgA. Образуются на ранней стадии заболевания в слизистых оболочках в ответ на местное воздействие инфекции. Они не формируют клеточную память, поэтому в формировании устойчивого иммунитета не участвуют.
Антитела IgM. Иммуноглобулины этого класса первыми появляются в крови в ответ на внедрение чужеродного антигена в организм. Они тоже не формируют длительного иммунитета. Зато по наличию антител IgA и IgM можно определить. что заболевание находится в активной фазе (даже если внешние симптомы отсутствуют).
Антитела IgG. Отвечают за длительную защиту организма после перенесенных инфекционных заболеваний и обеспечивают основной иммунный ответ. Уровень антител IgG повышается медленнее и достигает стабильного уровня в среднем через 15-20 дней после начала заболевания.
Чтобы понять, на какой стадии находится инфекционное заболевание, учитывая специфику коронавирусной инфекции, нужно сдавать анализы двух типов: на определение антител IgА (или IgM) и IgG одновременно.
В случае положительного результата по антителам IgG необходимо провести повторный анализ. Сделать его рекомендуется через 14 дней после первого, чтобы определить увеличение или снижение концентрации IgG. В случае, если при повторном анализе уровень антител повысится или снизится, говорить о формировании иммунитета нельзя.
Если у пациента при первой сдаче анализов не было выявлено антител IgM, а значение IgG равно 10 и больше, а при повторной диагностике значение IgG не увеличилось, можно говорить о том, что человек переболел как минимум месяц назад и с большой вероятностью имеет иммунитет к коронавирусу.
Впрочем, положительный результат на антитела к COVID-19 пока не может считаться стопроцентной гарантией неподверженности вирусу. Ученые еще не собрали достаточно данных, чтобы дать окончательный ответ, насколько долго сохраняется иммунитет.
Важный момент: особенностью иммунного ответа к новой коронавирусной инфекции является практически одновременное появление антител как класса IgM, так класса IgA. Однако антитела класса А сохраняются дольше и поэтому в совокупности с IgG имеют большее диагностическое значение.
Тестирование на антитела к вирусу SARS-CoV-2 (COVID-19) в Семейном докторе
Мы предлагаем воспользоваться высокоточной тест-системой от проверенного производителя (страна происхождения — Германия). Метод диагностики — ИФА. Система зарегистрирована в Роспотребнадзоре и одобрена FDA США. Состоит из тестов на выявление IgA и IgG. Рекомендуем сделать сразу оба теста. Специфичность тестов — 100%, чувствительность для IgG — 99%. Готовность результатов — 2 суток. Результаты будут доступны в вашем Личном кабинете на сайте или мобильном приложении.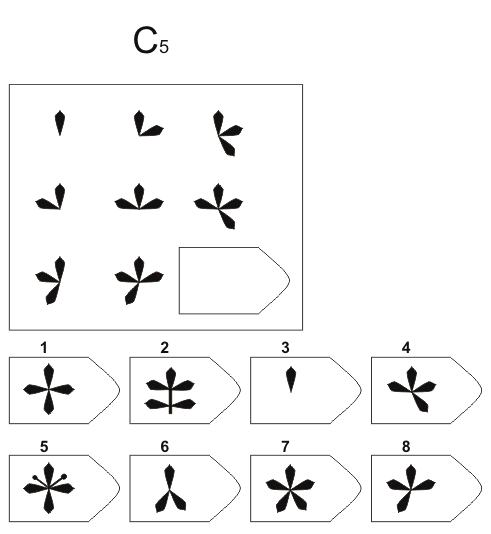
Вы также можете воспользоваться комплексным анализом (профилем), позволяющим получить количественную оценку антител IgM и IgG.
Если вам необходимо получить результат максимально быстро, вы можете выбрать экспресс-тест с готовностью результатов в течение 15-20 минут. Одновременно выявляются иммуноглобулины IgM и IgG. Методика качественная (т.е. выявляется только факт наличия антител, без количественной оценки). Чувствительность составляет 87%.
Также возможен выбор других тест-систем.
Подготовка к анализу
-
Перед анализом методом ИФА в течение 3-4 часов нельзя есть. Из питья допускается только негазированная вода.
-
Перед прохождением экспресс-теста рекомендуется не есть жирную, сладкую пищу, не курить за 12 часов до теста, избегать чрезмерных физических и эмоциональных нагрузок.
При сдаче анализа потребуется заполнить документы установленного образца. Чтобы минимизировать время на сдачу анализа, пожалуйста, скачайте бланки документов заранее (они доступны по этой ссылке>>>) и заполните их дома.
Как проходит диагностика?
-
Для анализа берётся кровь из вены или из пальца.
-
Пациентам необходимо иметь при себе паспорт.
-
Рекомендуем приходить в масках и одноразовых перчатках.
-
Проводим с соблюдением всех правил санитарно-эпидемиологического режима.
-
Забор осуществляется во всех поликлиниках сети согласно графику их работы.
Если у вас повышена температура, кашель, одышка, боль в мышцах, слабость и ощущение заложенности в грудной клетке, пожалуйста, оставайтесь дома и вызовите врача.
Результаты теста | Gastropanel.co.uk
С помощью анализа GastroPanel измеряются концентрации четырех биомаркеров в пробе крови. Биомаркерами, секретируемыми клетками слизистой желудка, являются пепсиноген I (PGI), пепсиноген II (PGII) и гастрин-17b (G17b). Кроме того, определяются антитела к Helicobacter pylori.
Обобщающая интерпретация результатов определения всех четырех биомаркеров обеспечивает более надежное и полное понимание состояния и функционирования слизистой желудка, чем достигаемое с использованием результатов определения концентраций только одного или двух биомаркеров. По существу, очевидно, что GastroPanel является тест-панелью на четыре биомаркера, так как панель — это больше, чем сумма ее частей. Мы также рекомендуем ознакомиться с блок-схемой GastroPanel (ниже), в которой представлены примеры порядка интерпретации результатов определения биомаркеров. Однако отметьте, что отчет GastroPanel обеспечивает более точную интерпретацию результатов.
Референс-диапазоны биомаркеров основаны на результатах клинических испытаний с участием пациентов с диспепсией. В этих испытаниях результаты пациентов при анализах GastroPanel сравнивались с данными гастроскопии и биопсии слизистой их желудков.
Отчет GastroPanel является инструментом, разработанным в помощь врачам при интерпретации результатов анализов GastroPanel. Отчет содержит результаты определения биомаркеров, в том числе референс-диапазоны и краткую письменную интерпретацию результатов. Интерпретация предоставляет информацию о состоянии слизистой желудка, о любом снижении секреции кислоты и о связанных с этим рисках. Где это уместно, отчет также содержит рекомендации о необходимости проведения лечения для устранения Helicobacter и прохождения гастроскопии.
Пример отчета GastroPanel 1: атрофия тела желудка
Пример отчета GastroPanel 2: желудок в норме
Создайте свой собственный отчет GastroPanel, используя приложение GastroPanel report.
| референс-диапазон* | |
| Пепсиноген I (PGI) | 30 — 160 мкг/л |
| Пепсиноген II (PGII) | 3 — 15 мкг/л |
| PGI/PGII | 3 — 20 |
| Гастрин-17b (G17b) | 1 — 7 пмоль/л |
| Гастрин-17s (G17s) | 3 — 30 пмоль/л |
| IgG к H. pylori (HPAbG) | < 30 EIU |
*Референс-диапазоны для GastroPanel могут быть уточнены данными последующих новых клинических испытаний.
Антитела IgG к Helicobacter (IgG к H. pylori)
Helicobacter pylori обитает в слизистой оболочке желудка зараженного человека. Данная инфекция, как правило, приобретается в детстве и вызывает воспаление (гастрит), которое, если его не лечить, становится хроническим и пожизненным. Данная инфекция в особенности широко распространена среди пожилых людей. У некоторых зараженных людей слизистая оболочка желудка атрофируется через несколько десятилетий. Гастрит и атрофия могут повысить риск различных заболеваний (рак желудка, язва двенадцатиперстной кишки, пептическая язва) и нарушения всасывания некоторых витаминов, минералов и лекарственных веществ (нехватки витамина B12, железа, кальция и магния). Уровень антител выше 30 иммуноферментных единиц (EIU) указывает на вероятное наличие инфекции Helicobacter.
Пепсиноген I (PGI)
Концентрация пепсиногена I в крови — индикатор структуры и функционирования слизистой оболочки тела желудка. При атрофии слизистой оболочки тела желудка концентрация пепсиногена I в крови опускается ниже 30 мкг/л.
Пепсиноген II (PGII)
Концентрация пепсиногена II в крови — индикатор структуры и функционирования слизистой оболочки желудка. Его концентрация в крови часто растет при воспалении слизистой оболочки желудка (пороговое значение — 10 мкг/л). Наиболее распространенная причина — инфекция Helicobacter pylori, но иногда гастрит могут вызвать и другие факторы (обезболивающее, крепкий алкоголь, острые специи, билиарный рефлюкс).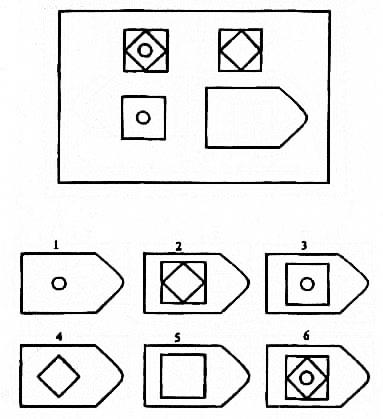
Пепсиноген I / Пепсиноген II (PGI / PGII)
Отношение пепсиноген I / пепсиноген II заметно падает (< 3) при атрофии тела желудка.Б
азальный гастрин-17 (G-17b)
Концентрация гастрина-17 в крови (натощак) — индикатор структуры и функционирования антрального отдела желудка. Моноклональные антитела компании Biohit измеряют только уровень амидированного гастрина-17 — специфического рецептора париетальных клеток. Гастрин-17 секретируется только G-клетками антрального отдела желудка. Он ускоряет секрецию соляной кислоты в париетальных клетках тела желудка. Уровень гастрина-17 выше 10 пмоль/л обычно свидетельствует об анацидном желудке (например, пациент принимает ИПП или страдает атрофией слизистой оболочки, ограниченной телом желудка). По мере повышения кислотности содержимого желудка уровень гастрина-17 в крови падает (pH < 2,5). Уровень гастрина-17 также падает при атрофии слизистой оболочки антрального отдела желудка, поскольку G-клетки исчезают. Низкий уровень гастрина-17, следовательно, свидетельствует либо об атрофии слизистой оболочки антрального отдела желудка, либо о повышенной секреции соляной кислоты.
Стимулированный гастрин-17 (G-17s)
Для дифференциальной диагностики атрофии слизистой оболочки антрального отдела желудка и повышенной секреции соляной кислоты, можно провести гастроскопию или определить уровень гастрина-17 после белковой стимуляции . Низкий уровень стимулированного гастрина-17 (менее 3 пмоль/л) свидетельствует об атрофическом гастрите антрального отдела желудка. Если человек был инфицирован H.pylori, а значение гастрина-17 остается низким после стимуляции белком (менее 3 пмоль / л), это может указывать на атрофический гастрит в антральном отделе желудка. Однако, если уровни антител H.pylori не повышены, результаты указывают на повышенную секрецию соляной кислоты.
Страница не найдена | MIT
Перейти к содержанию ↓- Образование
- Исследовать
- Инновации
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
-
Подробнее ↓
- Прием + помощь
- Студенческая жизнь
- Новости
- Выпускников
- О MIT
Попробуйте поискать что-нибудь еще! Что вы ищете? Увидеть больше результатов
Предложения или отзывы?
t-критерий: двухвыборочное предположение равных вариаций
Инструмент t-критерий парный двухвыборочный для средних значений выполняет парный двухвыборочный t-критерий Стьюдента, чтобы убедиться, что нулевая гипотеза (средние значения двух совокупностей равны) принято или отклонено.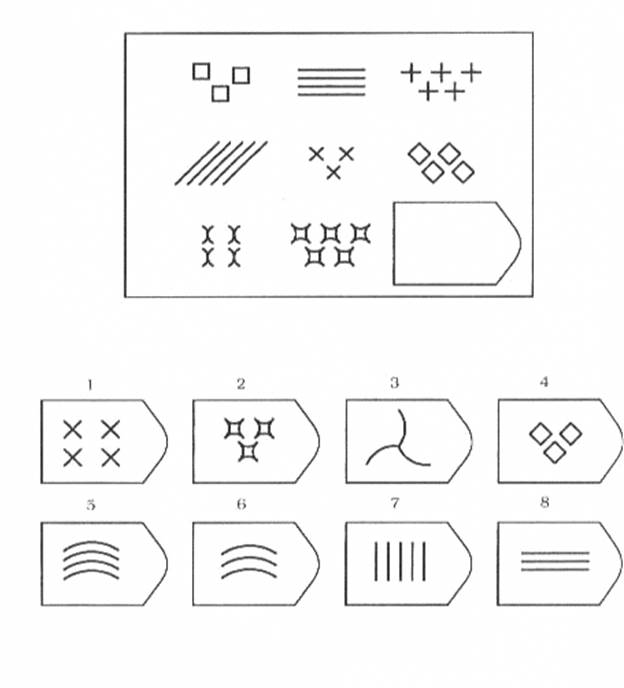 Этот тест не предполагает, что дисперсия обеих популяций одинакова. Парные t-тесты обычно используются для проверки средних значений совокупности до и после некоторого лечения, то есть двух выборок результатов учащихся по математике до и после урока.
Этот тест не предполагает, что дисперсия обеих популяций одинакова. Парные t-тесты обычно используются для проверки средних значений совокупности до и после некоторого лечения, то есть двух выборок результатов учащихся по математике до и после урока.
Результатом этого инструмента является вычисленное значение t. Это значение может быть отрицательным или положительным, в зависимости от данных. Если предположить, что средние по численности населения равны:
- Если t <0, P (T <= t) one-tail - это вероятность того, что значение t-статистики будет более отрицательным, чем t.
- Если t> 0, P (T <= t) один хвост - это вероятность того, что будет наблюдаться значение t-статистики, более положительное, чем t.
- P (T <= t) два хвоста - это вероятность того, что будет наблюдаться значение t-статистики, которое по абсолютной величине больше, чем t.
Примеры наборов данных ниже были взяты из 10 студентов. В начале и в конце учебного года учащимся давали один и тот же тест. Используйте парный t-тест, чтобы определить, улучшился ли средний балл 2-го теста по сравнению со средним баллом 1-го теста.
Для проведения t-теста:
- На панели XLMiner Analysis ToolPak щелкните t-Test Paired Two-Sample for Means.
- Введите A2: A11 для диапазона переменной 1. Это наш первый набор ценностей, значений, записанных в начале учебного года.
- Введите B2: B11 для диапазона переменной 2. Это наш второй набор ценностей, значений, записанных в конце учебного года.
- Введите «0» для предполагаемой средней разницы. Это означает, что мы проверяем, что средние значения двух образцов равны.
- Снимите флажок «Ярлыки», поскольку мы не включили заголовки столбцов в диапазоны переменных 1 и 2.
- Оставьте альфа = 0,05.
- Введите D1 в качестве диапазона вывода.
- Щелкните ОК.
- Ячейки E4 и F4 содержат среднее значение каждой выборки, переменная 1 = начало и переменная 2 = конец.
- Ячейки E5 и F5 содержат дисперсию каждой выборки.
- Ячейки E6 и F6 содержат количество наблюдений в каждой выборке.
- Ячейка E7 содержит корреляцию Пирсона, которая указывает на то, что две переменные довольно тесно коррелированы.
- Ячейка E8 содержит нашу запись для гипотетической средней разности.
- Ячейки E9 содержат степени свободы, 10 — 1.
- Ячейка E10 содержит результат фактического t-критерия. Мы сравним это значение со статистикой t-Critical с двумя хвостами. Примечание: используйте односторонний тест, если у вас есть направление в своей гипотезе, т.е. если вы проверяете, что значение выше или ниже некоторого уровня.
- В этом примере P (T <= t) два хвоста (0,0000321) дает вероятность того, что будет наблюдаться абсолютное значение t-статистики (7,633), которое по абсолютной величине больше, чем критическое значение t (2,26). Поскольку значение p меньше нашего альфа, 0,05, мы отвергаем нулевую гипотезу о том, что нет значительной разницы в средних значениях для каждой выборки.
all.equal function — RDocumentation
Использование
all.equal (target, current,…)# Метод S3 для числовых все.равно (цель, текущий, допуск = sqrt (.Machine $ double.eps), масштаб = NULL, countEQ = FALSE, formatFUN = функция (ошибка, что) формат (ошибка), …, Check.attributes = TRUE)
# Метод S3 для списка all.equal (цель, текущий,…, check.attributes = TRUE, use.names = TRUE)
# Метод S3 для среды all.equal (target, current, all.names = TRUE,…)
# Метод S3 для POSIXt all.equal (цель, ток,…, допуск = 1e-3, масштаб)
attr.all.equal (цель, текущий,…, check.attributes = TRUE, check.names = TRUE)
Подробности
all.equal — это общая функция, отправляющая методы на
цель аргумент. Чтобы увидеть доступные методы, используйте
методы ("all., но обратите внимание, что метод по умолчанию
также выполняет некоторую диспетчеризацию, например, используя необработанный метод для логических
цели.  equal")
equal")
Помните, что аргументы, следующие за … , должны быть указаны
(без сокращений) имя.Не рекомендуется передавать безымянные аргументы в
… , поскольку они будут соответствовать разным аргументам в разных
методы.
Числовые сравнения для шкалы = NULL (по умолчанию)
обычно по шкале относительной разницы , если целевые значения
близки к нулю: во-первых, средняя абсолютная разница двух
числовые векторы. Если это меньше, чем
допуск или не конечный, используются абсолютные разности,
в противном случае относительные различия, масштабируемые по среднему абсолютному
целевое значение .Обратите внимание, что эти сравнения вычисляются только для тех элементов вектора.
где цель не является NA и отличается от текущей .
Если countEQ истинно, равны и NA случаи
насчитали при определении размера «выборки».
Если шкала числовая (и положительная), абсолютные сравнения
Сделано после масштабирования (деления) на масштаб .
Для сложной мишени модуль упругости ( Mod )
разница б / у: всего.equal.numeric называется так аргументы
Допуск и шкала .
Список Метод сравнивает компоненты
target и current рекурсивно, пропуская все остальные
аргументы, если оба они «похожи на список», т. е. выполняют
либо is.vector , либо is.list .
Среда метод работает через метод list ,
и также используется для ссылочных классов (если не указано иное
все.равно метод).
Методы для классов даты и времени по умолчанию допускают допуск
Допуск = 0,001 секунд, и игнорировать шкалу .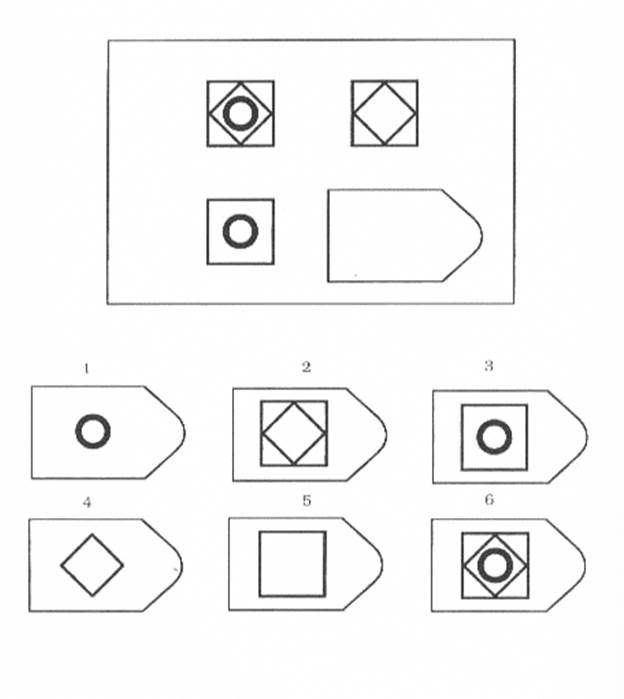
attr.all.equal используется для сравнения
атрибутов , возвращающих NULL или
символов вектор.
Примеры
# NOT RUN {
all.equal (пи, 355/113)
# недостаточно точно (по умолчанию tol)> относительная ошибка
d45 <- пи * (1/4 + 1:10)
стопифнот (
все.equal (tan (d45), rep (1, 10))) # ИСТИНА, но
all (tan (d45) == rep (1, 10)) # ЛОЖЬ, так как не совсем
all.equal (tan (d45), rep (1, 10), толерантность = 0) # чтобы увидеть разницу
## advanced: равенство сред
ae <- all.equal (as.environment ("package: stats"),
asNamespace ("статистика"))
stopifnot (is.character (ae), length (ae)> 10,
## ошибочно считались равными в R <= 3.1.1
all.equal (asNamespace ("статистика"), asNamespace ("статистика")))
## Ситуация, когда countEQ = TRUE имеет смысл:
х1 <- х2 <- (1: 100) / 10; х2 [2] <- 1.1 * x1 [2]
## 99 из 100 пар (x1 [i], x2 [i]) равны:
plot (x1, x2, main = "all.equal.numeric () - не считая равных частей")
all.equal (x1, x2) ## "Средняя относительная разница: 0,1"
mtext (paste ("all.equal (x1, x2):", all.equal (x1, x2)), line = -2)
## 'извлеките' Среднее относительное различие 'как число:
all.eqNum <- функция (...) as.numeric (sub (". *:", '', all.equal (...)))
набор. семян (17)
## Когда x2 дрожит, обычно все пары (x1 [i], x2 [i]) различаются:
сводка (r <- replicate (100, all.eqNum (x1, x2 * (1 + rnorm (x1) * 1e-7))))
mtext (paste ("означает (все.equal (x1, x2 * (1 + eps_k))) {100 x} Среднее значение rel.diff. = ",
signif (mean (r), 3)), line = -4, adj = 0)
## С аргументом countEQ = TRUE получить "то же самое" (без необходимости дрожания):
mtext (paste ("all.equal (x1, x2, countEQ = TRUE):",
signif (all.eqNum (x1, x2, countEQ = TRUE), 3)), line = -6, col = 2)
#}
Как определить равенство двух объектов JavaScript?
На этот вопрос уже более 30 ответов. Я собираюсь обобщить и объяснить их (аналогией с «моим отцом») и добавить свое предлагаемое решение.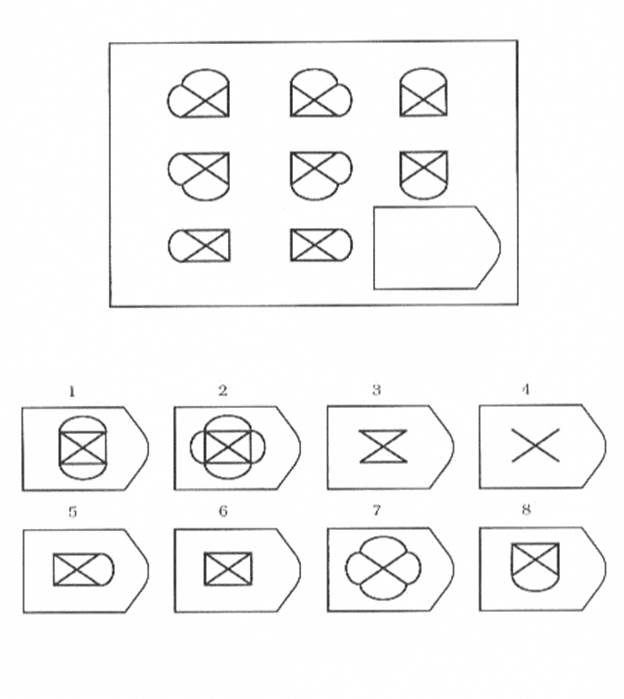
У вас есть 4 + 1 классов решений :
Хорошо, если вы торопитесь и работает 99% корректности.
Примеры этого: JSON.stringify () , предложенный Pratik Bhalodiya, или JSON.encode Джоэлем Анаиром, или .toString () , или другие методы, которые преобразуют ваши объекты в String, а затем сравнивают две строки, в которых используется символ === символ за символом.
Однако недостатком является отсутствие глобально стандартного уникального представления объекта в строке.например {a: 5, b: 8} и {b: 8 и a: 5} равны.
- Плюсы: Быстро, быстро.
- Минусы: Надеюсь работает! Это не будет работать, если среда / браузер / движок запомнит порядок объектов (например, Chrome / V8), а порядок ключей отличается. (Спасибо Eksapsy.) Так что вообще не гарантируется. Производительность тоже была бы невысокой на больших объектах.
Аналогия с моим отцом
Когда я говорю о своем отце, « мой высокий красивый отец » и « мой красивый высокий отец » - это одно и то же лицо! Но эти две струны не одно и то же.
Обратите внимание, что на самом деле существует правильный (стандартный) порядок прилагательных в грамматике английского языка, что говорит о том, что это должен быть «красивый высокий мужчина», но вы рискуете своей компетентностью, если слепо предполагаете, что движок Javascript в iOS 8 Safari является также слепо придерживаться той же грамматики! #WelcomeToJavascriptNonStandards
Хорошо, если учитесь.
Примеры - решение atmin.
Самый большой недостаток - вы обязательно пропустите некоторые крайние случаи.Рассматривали ли вы ссылку на себя в значениях объектов? Вы считали NaN ? Рассматривали ли вы два объекта, которые имеют одинаковые ownProperties , но разные прототипы родителей?
Я бы посоветовал людям делать это только в том случае, если они практикуются, а код не будет запущен в производство.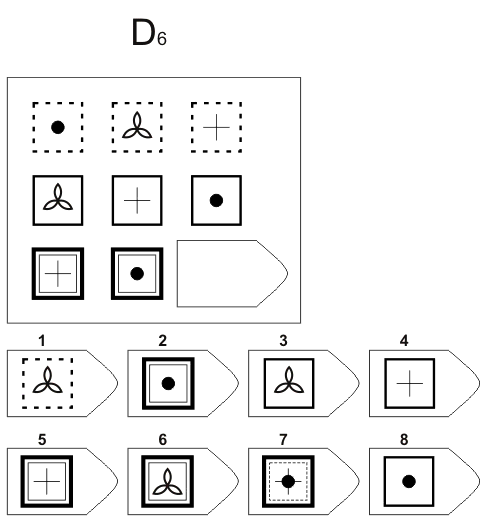 Это единственный случай, когда изобретает колесо заново. имеет оправдание.
Это единственный случай, когда изобретает колесо заново. имеет оправдание.
- Плюсы: Возможность обучения.
- Минусы: Не надежно.Требует времени и забот.
Аналогия с моим отцом
Это как предположить, что если моего отца зовут «Джон Смит», а его день рождения «01.01.1970», то любой, чье имя «Джон Смит» и родился «01.01.1970», является моим отцом.
Обычно так и бывает, но что, если в этот день родятся два Джона Смита? Если вы думаете, что учитываете их рост, то это увеличивает точность, но все же не идеальное сравнение.
2.1 Вы ограниченный объем DIY компаратор
Вместо того, чтобы идти в безумную погоню за рекурсивной проверкой всех свойств, можно рассмотреть возможность проверки только «ограниченного» количества свойств.Например, если объекты - User s, вы можете сравнить их поле emailAddress .
Он все еще не идеален, но его преимущества по сравнению с решением №2 следующие:
- Это предсказуемо, и вероятность сбоя меньше.
- Вы руководствуетесь «определением» равенства, а не полагаетесь на дикую форму и форму объекта, его прототипа и вложенных свойств.
Хорошо, если вам нужно качество на уровне производства, и вы не можете изменить конструкцию системы.
Примеры: _.equal lodash, уже в ответе coolaj86 или Angular или Ember, как указано в ответе Тони Харви или Node от Рафаэля Ксавьера.
- Плюсы: Это то, что делают все остальные.
- Минусы: Внешняя зависимость, которая может стоить вам дополнительной памяти / ЦП / безопасности, даже немного. Кроме того, все еще могут быть пропущены некоторые крайние случаи (например, должны ли два объекта, имеющие одинаковые
ownProperties, но разные прототипные родительские объекты, считаться одинаковыми или нет.) Наконец, вы, , могли бы непреднамеренно воспрепятствовать основной проблеме дизайна с этим; просто говорю!
Аналогия с моим отцом
Это все равно, что заплатить агентству за поиск моего биологического отца по его телефону, имени, адресу и т. Д.
Д.
Это будет стоить дороже и, вероятно, точнее, чем я проверяю биографические данные, но не охватывает крайние случаи, например, когда мой отец является иммигрантом / убежищем и его день рождения неизвестен!
Хорошо, если вы [все еще] можете изменить структуру системы (объекты, с которыми вы имеете дело) и хотите, чтобы ваш код работал долго.
Это применимо не во всех случаях и может быть не очень эффективным. Однако это очень надежное решение, если оно у вас есть.
Решение состоит в том, что каждый объект в системе будет иметь уникальный идентификатор вместе со всеми другими свойствами. Уникальность идентификатора будет гарантирована во время генерации. И вы будете использовать этот идентификатор (также известный как UUID / GUID - глобальный / универсальный уникальный идентификатор), когда дело доходит до сравнения двух объектов.т.е. они равны тогда и только тогда, когда эти идентификаторы равны.
Идентификаторы могут быть простыми числами auto_incremental или строкой, сгенерированной с помощью библиотеки (рекомендуется), или фрагментом кода. Все, что вам нужно сделать, это убедиться, что он всегда уникален, что в случае auto_incremental он может быть встроенным, или в случае UUID можно проверить все существующие значения (например, атрибут столбца MySQL UNIQUE ) или просто (если исходят из библиотеки) следует полагаться на чрезвычайно низкую вероятность столкновения.
Обратите внимание, что вам также необходимо постоянно хранить идентификатор вместе с объектом (чтобы гарантировать его уникальность), и вычисление его в реальном времени может быть не лучшим подходом.
- Плюсы: Надежный, экономичный, не грязный, современный.
- Минусы: Требуется дополнительное место. Возможно, потребуется переработка системы.
Аналогия с моим отцом
Это похоже на то, что номер социального страхования моего отца - 911-345-9283, поэтому любой, у кого есть этот SSN, является моим отцом, и любой, кто утверждает, что является моим отцом, должен иметь этот SSN.
Я лично предпочитаю решение №4 (ID) по точности и надежности. Если это невозможно, я бы выбрал № 2.1 для предсказуемости, а затем № 3. Если ни то, ни другое невозможно, выберите №2 и, наконец, №1.
Как проверить равенство строк в Scala
Это отрывок из Scala Cookbook (частично изменен для Интернета). Это рецепт 1.1, «Проверка равенства строк в Scala».
Проблема
При использовании Scala вы хотите сравнить две строки, чтобы проверить, равны ли они , т.е.е., содержат ли они одну и ту же последовательность символов.
Решение
В Scala вы сравниваете два экземпляра String с оператором == . Учитывая эти строки:
scala> val s1 = "Привет"
s1: java.lang.String = Привет
scala> val s2 = "Привет"
s2: java.lang.String = Привет
scala> val s3 = "H" + "привет"
s3: java.lang.String = Привет
Проверить их равенство можно так:
Scala> s1 == s2
res0: Boolean = true
scala> s1 == s3
res1: Boolean = true
Приятным преимуществом метода == является то, что он не генерирует исключение NullPointerException в базовом тесте, если String равен null :
scala> val s4: строка = ноль
s4: String = null
scala> s3 == s4
res2: Boolean = false
scala> s4 == s3
res3: Boolean = false
Если вы хотите сравнить две строки без учета регистра, вы можете преобразовать обе строки в верхний или нижний регистр и сравнить их с методом == :
scala> val s1 = "Привет"
s1: java.lang.String = Привет
scala> val s2 = "привет"
s2: java.lang.String = привет
scala> s1.toUpperCase == s2.toUpperCase
res0: Boolean = true
Однако имейте в виду, что вызов метода для строки null может вызвать исключение NullPointerException :
scala> val s1: строка = ноль
s1: String = null
scala> val s2: String = null
s2: String = null
scala> s1. toUpperCase == s2.toUpperCase
java.lang.NullPointerException // здесь больше вывода ...
toUpperCase == s2.toUpperCase
java.lang.NullPointerException // здесь больше вывода ...
Чтобы сравнить две строки, игнорируя их регистр, вы также можете вернуться и использовать equalsIgnoreCase класса Java String :
scala> val a = "Marisa"
a: String = Мариса
scala> val b = "мариса"
b: Строка = Мариса
scala> a.equalsIgnoreCase (b)
res0: Boolean = true
Обсуждение
В Scala вы проверяете равенство объектов с помощью метода == .Это отличается от Java, где вы используете метод равно для сравнения двух объектов.
В Scala метод == , определенный в классе AnyRef , сначала проверяет нулевые значения, а затем вызывает метод равно для первого объекта (т. Е. This), чтобы проверить, равны ли два объекта. В результате вам также не нужно проверять нулевые значения при сравнении строк.
В идиоматическом Scala вы никогда не используете нулевые значения. Обсуждение в этом рецепте призвано помочь вам понять, как работает == , если вы встретите значение null , предположительно из-за работы с библиотекой Java или какой-либо другой библиотекой, где использовались значения null .
Если вы переходите с такого языка, как Java, всякий раз, когда вам захочется использовать null , используйте вместо этого Option . (Мне кажется полезным представить, что в Scala даже нет ключевого слова null .) См. Рецепт 20.6, «Как использовать шаблон Scala's Option / Some / None» для получения дополнительной информации и примеров.
Дополнительные сведения об определении методов равенства см. В рецепте 4.17., «Как определить метод равенства (и равенство объектов) в Scala».
... этот пост спонсируется моими книгами ...
Предполагая равные различия в населении - Вводная бизнес-статистика
Проверка гипотез на двух выборках
Обычно мы никогда не можем ожидать, что узнаем какие-либо параметры генеральной совокупности, среднее значение, пропорцию или стандартное отклонение.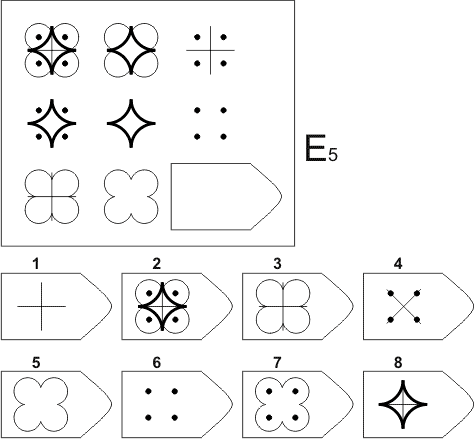 При проверке гипотез о различиях в средних мы сталкиваемся с трудностью двух неизвестных дисперсий, которые играют решающую роль в статистике теста.Мы заменяли выборочные дисперсии так же, как и при проверке гипотез для единственного среднего. И, как мы делали раньше, мы использовали t Стьюдента, чтобы компенсировать недостаток информации о дисперсии генеральной совокупности. Однако могут быть ситуации, когда мы не знаем дисперсию популяций, но можем предположить, что две популяции имеют одинаковую дисперсию. Если это так, то дисперсия объединенной выборки будет меньше дисперсии отдельной выборки. Это даст более точные оценки и снизит вероятность отбрасывания хорошего нуля.Нулевая и альтернативная гипотезы остаются прежними, но статистика теста изменяется на:
При проверке гипотез о различиях в средних мы сталкиваемся с трудностью двух неизвестных дисперсий, которые играют решающую роль в статистике теста.Мы заменяли выборочные дисперсии так же, как и при проверке гипотез для единственного среднего. И, как мы делали раньше, мы использовали t Стьюдента, чтобы компенсировать недостаток информации о дисперсии генеральной совокупности. Однако могут быть ситуации, когда мы не знаем дисперсию популяций, но можем предположить, что две популяции имеют одинаковую дисперсию. Если это так, то дисперсия объединенной выборки будет меньше дисперсии отдельной выборки. Это даст более точные оценки и снизит вероятность отбрасывания хорошего нуля.Нулевая и альтернативная гипотезы остаются прежними, но статистика теста изменяется на:
где - объединенная дисперсия, определяемая по формуле:
Попытка испытания препарата с использованием настоящего лекарства и таблетки, сделанной только из сахара. 18 человек получают настоящий препарат в надежде увеличить выработку эндорфинов. Установлено, что увеличение эндорфинов составляет в среднем 8 микрограммов на человека, а стандартное отклонение образца составляет 5,4 микрограмма. 11 человек получают сахарную пилюлю, и их среднее увеличение эндорфина составляет 4 микрограмма со стандартным отклонением 2.4. Из предыдущих исследований эндорфинов было определено, что можно предположить, что отклонения в двух выборках могут быть одинаковыми. Проведите тест на уровне 5%, чтобы увидеть, оказало ли популяционное среднее для реального препарата значительно большее влияние на эндорфины, чем популяционное среднее для сахарной таблетки.
Сначала мы начнем с обозначения одной из двух групп - группы 1, а другой - группы 2. Это потребуется для отслеживания нулевой и альтернативной гипотез. Давайте обозначим группу 1 как тех, кто получил собственно новое тестируемое лекарство, и, следовательно, группа 2 - это те, кто получил сахарную пилюлю.Теперь мы можем сформулировать нулевую и альтернативную гипотезу как:
H 0 : µ 1 ≤ µ 2
H 1 : µ 1 > µ 2
Это настроено как односторонний тест с утверждением в альтернативной гипотезе, что лекарство будет производить больше эндорфинов, чем сахарная пилюля. Теперь мы вычисляем статистику теста, которая требует, чтобы мы вычислили объединенную дисперсию, используя формулу выше.
Теперь мы вычисляем статистику теста, которая требует, чтобы мы вычислили объединенную дисперсию, используя формулу выше.
t α , позволяет сравнить статистику испытаний и критическое значение.
Статистика теста явно находится в хвосте, 2,31 больше критического значения 1,703, и поэтому мы не можем поддерживать нулевую гипотезу. Таким образом, мы приходим к выводу, что есть существенные доказательства с уровнем уверенности 95%, что новое лекарство дает желаемый эффект.
Обзор главы
В ситуациях, когда мы не знаем дисперсии генеральной совокупности, но предполагаем, что дисперсии одинаковы, дисперсия объединенной выборки будет меньше дисперсии отдельной выборки.
Это даст более точные оценки и снизит вероятность отбрасывания хорошего нуля.
Обзор формулы
где - объединенная дисперсия, определяемая по формуле:
std :: equal - cppreference.com
| (1) | ||
| template bool equal (InputIt1 first1, InputIt1 last1, |
(до C ++ 20) | |
| шаблон <класс InputIt1, класс InputIt2> constexpr bool equal (InputIt1 first1, InputIt1 last1, |
(начиная с C ++ 20) | |
| шаблон <класс ExecutionPolicy, класс ForwardIt1, класс ForwardIt2> bool equal (ExecutionPolicy && policy, ForwardIt1 first1, ForwardIt1 last1, |
(2) | (начиная с C ++ 17) |
| (3) | ||
| template bool equal (InputIt1 first1, InputIt1 last1, |
(до C ++ 20) | |
| template constexpr bool equal (InputIt1 first1, InputIt1 last1, |
(начиная с C ++ 20) | |
| шаблон bool equal (ExecutionPolicy && policy, ForwardIt1 first1, ForwardIt1 last1, ForwardIt2 first2, BinaryPredicate p); |
(4) | (начиная с C ++ 17) |
| (5) | ||
| template bool equal (InputIt1 first1, InputIt1 last1, |
(начиная с C ++ 14) (до C ++ 20) |
|
| шаблон <класс InputIt1, класс InputIt2> constexpr bool equal (InputIt1 first1, InputIt1 last1, |
(начиная с C ++ 20) | |
| шаблон <класс ExecutionPolicy, класс ForwardIt1, класс ForwardIt2> bool equal (ExecutionPolicy && policy, ForwardIt1 first1, ForwardIt1 last1, |
(6) | (начиная с C ++ 17) |
| (7) | ||
| template bool equal (InputIt1 first1, InputIt1 last1, |
(начиная с C ++ 14) (до C ++ 20) |
|
| template constexpr bool equal (InputIt1 first1, InputIt1 last1, |
(начиная с C ++ 20) | |
| шаблон bool equal (ExecutionPolicy && policy, ForwardIt1 first1, ForwardIt1 last1, ForwardIt2 first2, ForwardIt236 last BinaryPredicate p); |
(8) | (начиная с C ++ 17) |
1,3) Возвращает истину, если диапазон [first1, last1) равен диапазону [first2, first2 + (last1 - first1)) , и false в противном случае
5,7) Возвращает true, если диапазон [first1, last1) равен диапазону [first2, last2) , и false - в противном случае.
Два диапазона считаются равными, если они имеют одинаковое количество элементов и для каждого итератора i в диапазоне [first1, last1) , * i равно * (first2 + (i - first1)). Перегрузки (1,2,5,6) используют operator ==, чтобы определить, равны ли два элемента, тогда как перегрузки (3,4,7,8) используют данный двоичный предикат p .
[править] Параметры
| first1, last1 | - | первый диапазон сравниваемых элементов |
| first2, last2 | - | второй диапазон сравниваемых элементов |
| полис | - | используемая политика выполнения.См. Подробности в политике выполнения. |
| п. | - | двоичный предикат, который возвращает истину, если элементы следует рассматривать как равные. Сигнатура функции предиката должна быть эквивалентна следующему: bool pred (const Type1 & a, const Type2 & b); Хотя подпись не обязательно должна иметь const &, функция не должна изменять переданные ей объекты и должна иметь возможность принимать все значения типа (возможно, const) |
| Требования к типу | ||
– InputIt1, InputIt2 должны соответствовать требованиям LegacyInputIterator.
| ||
– ForwardIt1, ForwardIt2 должны соответствовать требованиям LegacyForwardIterator.
| ||
[править] Возвращаемое значение
5-8) Если длина диапазона [first1, last1) не равна длине диапазона [first2, last2) , возвращается false
Если элементы в двух диапазонах равны, возвращает true.
В противном случае возвращает false.
[править] Примечания
std :: equal не следует использовать для сравнения диапазонов, сформированных итераторами из std :: unordered_set, std :: unordered_multiset, std :: unordered_map или std :: unordered_multimap, потому что порядок, в котором элементы хранятся в эти контейнеры могут быть разными, даже если в двух контейнерах хранятся одни и те же элементы.
При сравнении целых контейнеров на предмет равенства обычно предпочтительнее использовать оператор == для соответствующего контейнера.
[править] Сложность
1,3) Не более last1 - first1 применений предиката
last1 - first1 , last2 - first2 ) применений предиката. Однако, если
InputIt1 и InputIt2 соответствуют требованиям LegacyRandomAccessIterator и last1 - first1! = Last2 - first2, то применения предиката не выполняется (несоответствие размера обнаруживается без просмотра каких-либо элементов).2,4,6,8) то же самое, но сложность указывается как O (x), а не «не более x»
[править] Исключения
Перегрузки с параметром шаблона с именем ExecutionPolicy сообщают об ошибках следующим образом:
- Если выполнение функции, вызванной как часть алгоритма, вызывает исключение и
ExecutionPolicyявляется одной из стандартных политик, вызывается std :: terminate. Для любого другогоExecutionPolicyповедение определяется реализацией. - Если алгоритму не удается выделить память, генерируется std :: bad_alloc.
[править] Возможная реализация
| Первая версия |
|---|
шаблон <класс InputIt1, класс InputIt2>
bool equal (InputIt1 first1, InputIt1 last1,
InputIt2 first2)
{
for (; first1! = last1; ++ first1, ++ first2) {
if (! (* first1 == * first2)) {
вернуть ложь;
}
}
вернуть истину;
}
|
| Вторая версия |
шаблон <класс InputIt1, класс InputIt2, класс BinaryPredicate>
bool equal (InputIt1 first1, InputIt1 last1,
InputIt2 first2, BinaryPredicate p)
{
for (; first1! = last1; ++ first1, ++ first2) {
if (! p (* first1, * first2)) {
вернуть ложь;
}
}
вернуть истину;
}
|
[править] Пример
В следующем коде используется std :: equal для проверки того, является ли строка палиндромом.
#include <алгоритм> #include#include constexpr bool is_palindrome (const std :: string_view & s) { return std :: equal (s.begin (), s.begin () + s.size () / 2, s.rbegin ()); } недействительный тест (const std :: string_view & s) { std :: cout << "\" "<< s <<" \ "" << (is_palindrome (s)? "is": "is not") << "палиндром \ n"; } int main () { тестовый («радар»); тест ("привет"); }
Выход:
«радар» - палиндром «привет» - это не палиндром