
Равенна тест: Тест на IQ | Бесплатный современный аналог прогрессивных матриц Равена онлайн
Главная страница
Прогрессивные матрицы Равена (Raven Progressive Matrices) – известный психометрический тест, существующий в нескольких вариантах. Его цветная версия нередко используется для проверки интеллекта в геронтологических исследованиях, в том числе – при когнитивном патологическом снижении.
В 2018 году была опубликована статья португальских ученых, которые выяснили, что успешность выполнения теста (серии AB) людьми пожилого возраста с небольшим снижением памяти позволяет дать долгосрочный прогноз о стабильности состояния пациента.
Если вы отмечаете у себя или пожилого родственника некоторое снижение памяти, которое пока не влияет существенно на выполнение профессиональных обязанностей или работы по дому, и вам хотелось бы понять, стоит ли ожидать ухудшений, попробуйте выполнить этот тест.
Прежде чем приступить к выполнению, подготовьте карандаш и лист бумаги для записи правильных вариантов ответа на 12 вопросов теста.
Выполняющий не должен видеть задания заранее!
Однако мы расскажем, что вас ждет, когда вы откроете тест.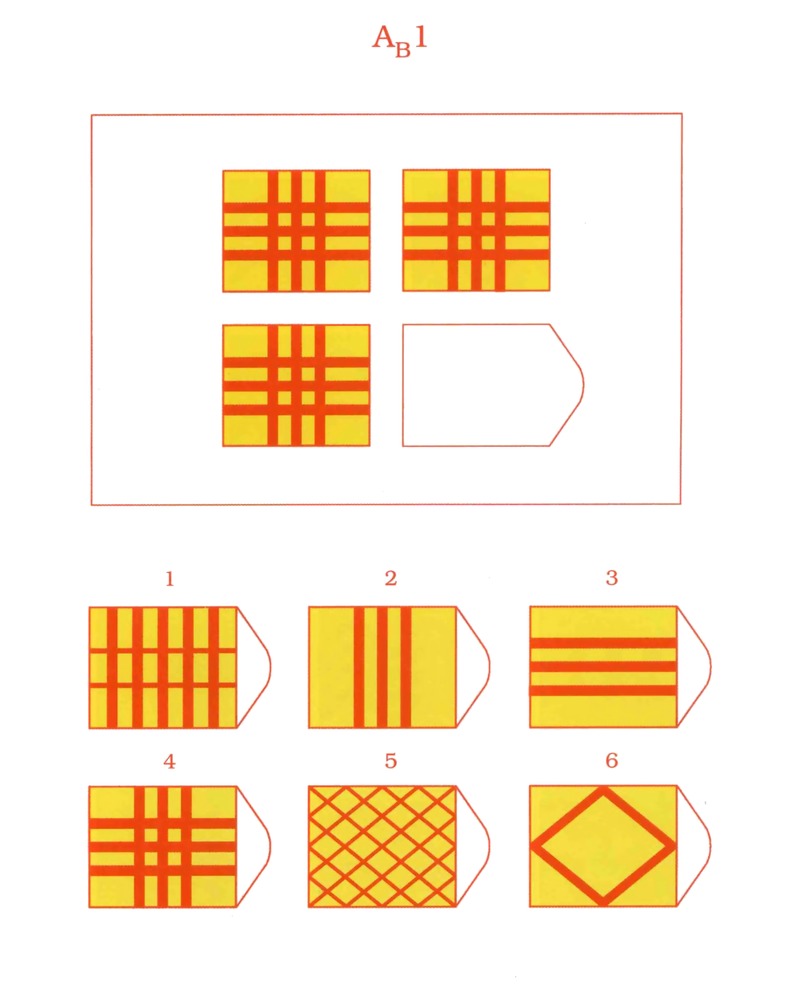 Вы увидите один за другим 12 рисунков, в которых не достает одного фрагмента. Под каждым изображением находятся четыре пронумерованных фрагмента, лишь один из которых подходит для подстановки в рисунок. Ваша задача — определить закономерность, связывающую между собой фрагменты изображения, определить недостающий и указать его номер.
Вы увидите один за другим 12 рисунков, в которых не достает одного фрагмента. Под каждым изображением находятся четыре пронумерованных фрагмента, лишь один из которых подходит для подстановки в рисунок. Ваша задача — определить закономерность, связывающую между собой фрагменты изображения, определить недостающий и указать его номер.
Учтите, что «для чистоты эксперимента» время прохождения теста требуется ограничить пятью минутами.
Готовы? Тогда открывайте файл.
Цветные прогрессивные матрицы Равена.pdf
После выполнения всех заданий ознакомьтесь с ключами и интерпретацией результатов: Подсчет и интерпретация результатов.pdf
Если правильных ответов менее 10 из 12 возможных, это говорит в пользу негативного прогноза, однако не следует воспринимать результат как приговор. Попробуйте обратиться в специализированный кабинет памяти или клинику, в которой есть врачи, специализирующиеся на диагностике и лечении когнитивных расстройств. Возможно, более тщательное тестирование покажет, что всё не так плохо.
ИСТОРИЯ НА РУБЕЖЕ ВЕКОВ – Балканско научно обозрение
Аннотация:Данная статья основана на материалах, опубликованных в Cognitive Psychology (Raven, 2000b), которые ранее вошли в Руководства по прогрессивным матрицам Равена (ПМР, Raven’s Progressive Matrices, RPM). Автор предлагает более развернутый обзор исследований, касающихся стабильности и изменения показателей ПМР с течением времени и развитием культуры (и их причин). Учитывая, что тесты ПМР используются уже 70 лет, выделить доказательства, касающиеся вопроса о том, насколько похожи нормы для разных культурных групп и как они менялись с течением времени не так просто, как можно было бы ожидать. Одна из причин, почему задача настолько трудна, заключается в том, что большинство исследований в этой области не только низкого качества, но и проводятся для других целей. Таким образом, большая часть исследований, в которых использовалась ПМР, была направлена на то, чтобы связать оценки ПМР с некоторыми другими переменными (такими как образовательная или профессиональная успеваемость), а не на сбор базовых нормативных данных.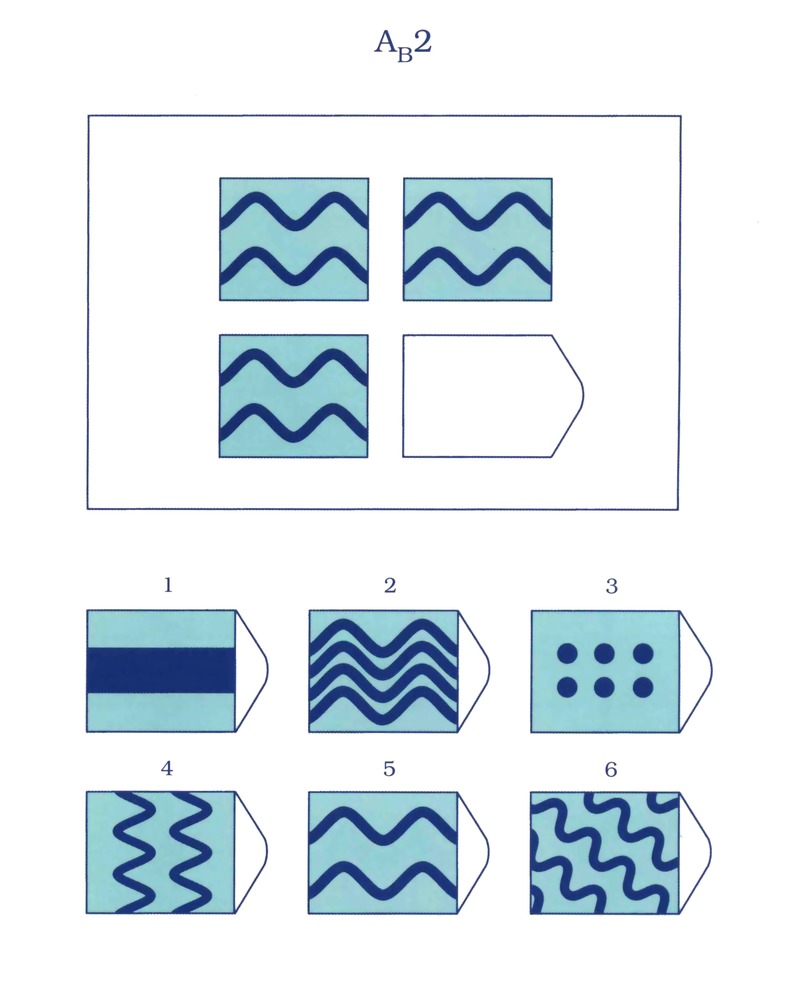
Description:This report is based upon a paper published in Cognitive Psychology (Raven, 2000b), which was itself based on material previously published in the Manuals for the Raven Progressive Matrices (RPM) — see various reference entries for Raven, Raven, and Court. It offers a more extended summary of research relating to the stability and change in RPM scores over culture and time (and their causes) than was included in the General Introduction to this book. Given that the tests have been in use for 70 years, distilling off the evidence bearing on the question of how similar are the norms for different cultural groups and how have they changed over time is not so easy as might be expected. The reasons why the data are not better than they are merit review because of their implications for future work in the area. One reason why the task is so difficult is that, as Dahlstrom (1993) noted in an article appropriately titled “Tests: Small samples, large consequences” that most of the studies in the area are not only of poor quality but also conducted for other purposes. Thus most of the research in which the RPM have been used have sought to relate RPM scores to some other variable (such as educational or occupational performance) rather than to assemble basic normative data.
It offers a more extended summary of research relating to the stability and change in RPM scores over culture and time (and their causes) than was included in the General Introduction to this book. Given that the tests have been in use for 70 years, distilling off the evidence bearing on the question of how similar are the norms for different cultural groups and how have they changed over time is not so easy as might be expected. The reasons why the data are not better than they are merit review because of their implications for future work in the area. One reason why the task is so difficult is that, as Dahlstrom (1993) noted in an article appropriately titled “Tests: Small samples, large consequences” that most of the studies in the area are not only of poor quality but also conducted for other purposes. Thus most of the research in which the RPM have been used have sought to relate RPM scores to some other variable (such as educational or occupational performance) rather than to assemble basic normative data.
Студенты СГЭУ протестировали свои скилы
22 апреля 2021 г.
Вчера студенты Самарского государственного экономического университета получили уникальную возможность познакомится с платформой «Россия – страна возможностей» (РСВ) и протестировать свои логические и интеллектуальные навыки.
Напомним, что между нашим университетом и АНО «Россия — страна возможностей» в начале апреля было подписано соглашение о сотрудничестве и взаимодействии в камках которого на базе СГЭУ будет создан Центр компетенций АНО «Россия — страна возможностей».
Как поясняют в АНО «РСВ» тестирование позволяет оценить потенциал когнитивной логики студентов, необходимой для их будущей профессиональной успешности: «На первом этапе тестирования предлагаются два инструмента оценки: прогрессивные матрицы Равена и тест на определение числовых последовательностей. Проведение тестирования данными инструментами позволяет осуществить оценку уровня развития невербальной логики как одного из компонентов комплекса интеллектуальных способностей, необходимых, в том числе, для будущей профессиональной успешности студентов. Подобные тестовые испытания предлагаются многими работодателями при приеме на работу или продвижении по карьерной лестнице», — говорят в АНО «РСВ».
По итогам тестирования, каждому студенту на электронную почту пришлют индивидуальный отчет. А поскольку в тестировании используется та же методика, что и при отборе на работу ведущими мировыми работодателями, то результаты помогут студентам скорректировать траектории своего развития.
Справка:
«Россия – страна возможностей» — это открытая цифровая площадка для общения талантливых и неравнодушных людей всех возрастов, обмена опытом между предпринимателями, управленцами, молодыми профессионалами, добровольцами и социальными активистами. Платформа создана по инициативе Президента РФ В.В. Путина.
1
Первый слайд презентации: Тест равена
Методика для диагностики интеллекта
Изображение слайда
2
Слайд 2: Джон Равен Родился : 28 июня 1902 г.
 , Лондон, Великобритания Умер: 10 августа 1970 г., Дамфрис, Великобритания Образование: Университет Лондон Известность: Тест Равена
, Лондон, Великобритания Умер: 10 августа 1970 г., Дамфрис, Великобритания Образование: Университет Лондон Известность: Тест Равена
Методика «Шкала прогрессивных матриц» была разработана в 1936 году Джоном Равеном (совместно с Л. Пенроузом). Тест прогрессивные матрицы Равена (ПМР) предназначен для диагностики уровня интеллектуального развития и оценивает способность к систематизированной, планомерной, методичной интеллектуальной деятельности (логичность мышления).
Изображение слайда
3
Слайд 3
Принцип «прогрессивности»
В Стандартных матрицах реализуется двояким образом:
а) внутри каждой серии задания расположены с учётом их возрастающей сложности;
б) все серии отличаются различной трудностью, которая возрастает от серии А к серии Е.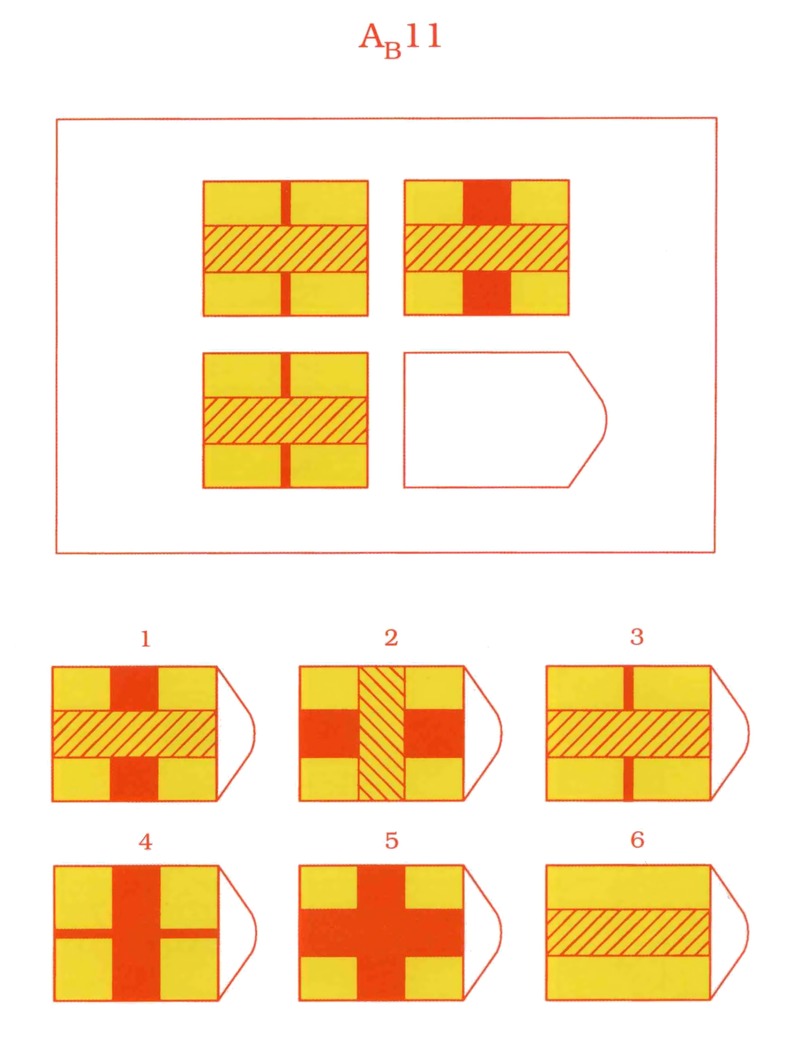
Изображение слайда
5
Слайд 5
В серии А — использован принцип установления взаимосвязи в структуре матриц. Здесь задание заключается в дополнении недостающей части основного изображения одним из приведенных в каждой таблице фрагментов. Выполнение задания требует от обследуемого тщательного анализа структуры основного изображения и обнаружения этих же особенностей в одном из нескольких фрагментов. Затем происходит слияние фрагмента, его сравнение с окружением основной части таблицы.
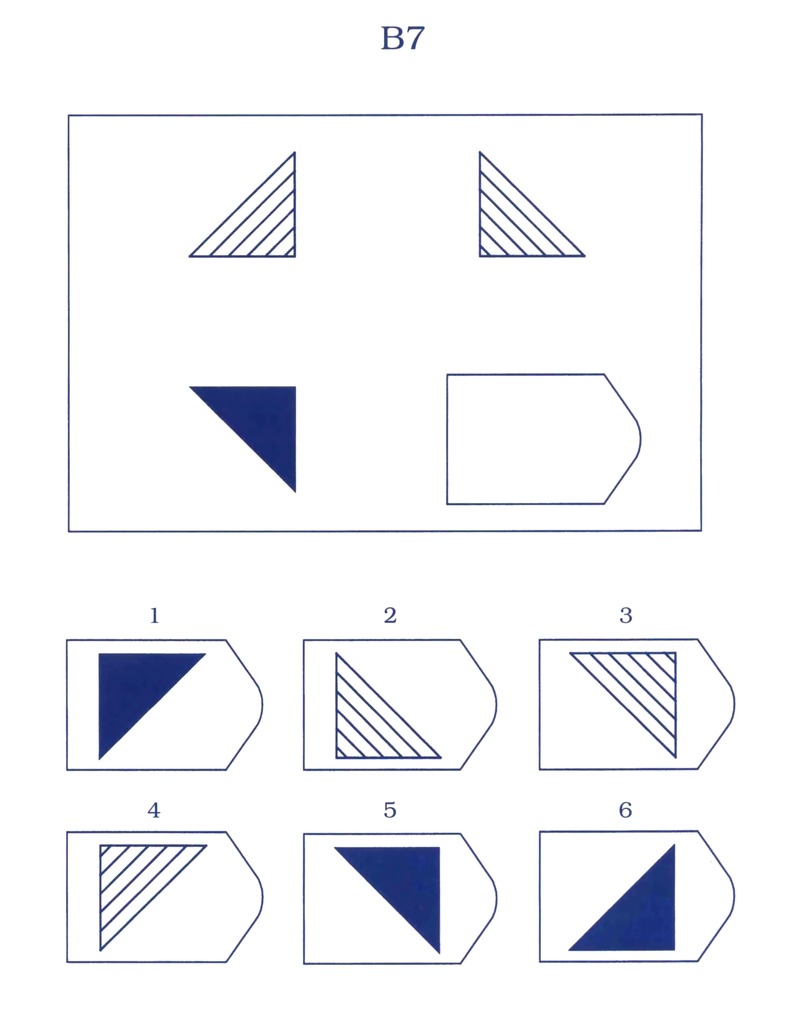
Серия В — построена по принципу аналогии между парами фигур. Обследуемый должен найти принцип, соответствен но которому построена в каждом отдельном случае фигура и, исходя из этого, подобрать недостающий фрагмент. При этом важно определить ось симметрии, соответственно которой расположены фигуры в основном образце.
Серия С — построена по принципу прогрессивных изменений в фигурах матриц. Эти фигуры в пределах одной матрицы все больше усложняются, происходит как бы непрерывное их развитие. Обогащение фигур новыми элементами подчиняется четкому принципу, обнаружив который, можно подобрать недостающую фигуру.
Серия D — построена по принципу перегруппировки фигур в матрице.
Здесь задание заключается в дополнении недостающей части основного изображения одним из приведенных в каждой таблице фрагментов. Выполнение задания требует от обследуемого тщательного анализа структуры основного изображения и обнаружения этих же особенностей в одном из нескольких фрагментов. Затем происходит слияние фрагмента, его сравнение с окружением основной части таблицы.
Серия В — построена по принципу аналогии между парами фигур. Обследуемый должен найти принцип, соответствен но которому построена в каждом отдельном случае фигура и, исходя из этого, подобрать недостающий фрагмент. При этом важно определить ось симметрии, соответственно которой расположены фигуры в основном образце.
Серия С — построена по принципу прогрессивных изменений в фигурах матриц. Эти фигуры в пределах одной матрицы все больше усложняются, происходит как бы непрерывное их развитие. Обогащение фигур новыми элементами подчиняется четкому принципу, обнаружив который, можно подобрать недостающую фигуру.
Серия D — построена по принципу перегруппировки фигур в матрице. Обследуемый должен найти эту перегруппировку, происходящую в горизонтальном и вертикальном положениях.
Серия Е основана на принципе разложения фигур основного изображения на элементы. Недостающие фигуры можно найти, поняв принцип анализа и синтеза фигур.
Обследуемый должен найти эту перегруппировку, происходящую в горизонтальном и вертикальном положениях.
Серия Е основана на принципе разложения фигур основного изображения на элементы. Недостающие фигуры можно найти, поняв принцип анализа и синтеза фигур.
Изображение слайда
6
Слайд 6
Имеется взрослый (с 14 до 65 лет) и детский (с 4,5 до 9 лет) вариант тестов Равена. Возможны два варианта в использовании матриц Равена.
Первый вариант — в качестве теста скорости, с ограничением времени 20 мин. для выполнения заданий. Для группового обследования.
Второй вариант использования матриц Равена в качестве теста интеллекта исключает введение временных ограничений. Задача испытуемого — установить закономерность, связывающую между собой фигуры на рисунке, и на опросном листе указать номер искомой фигуры из предлагаемых вариантов.
С 11
Задача испытуемого — установить закономерность, связывающую между собой фигуры на рисунке, и на опросном листе указать номер искомой фигуры из предлагаемых вариантов.
С 11
Изображение слайда
7
Слайд 7: Инструкция Теста равена
взрослый (с 14 до 65 лет)
Изображение слайда
8
Слайд 8
Инструкция : Тест строго регламентирован во времени, а именно: 20 мин.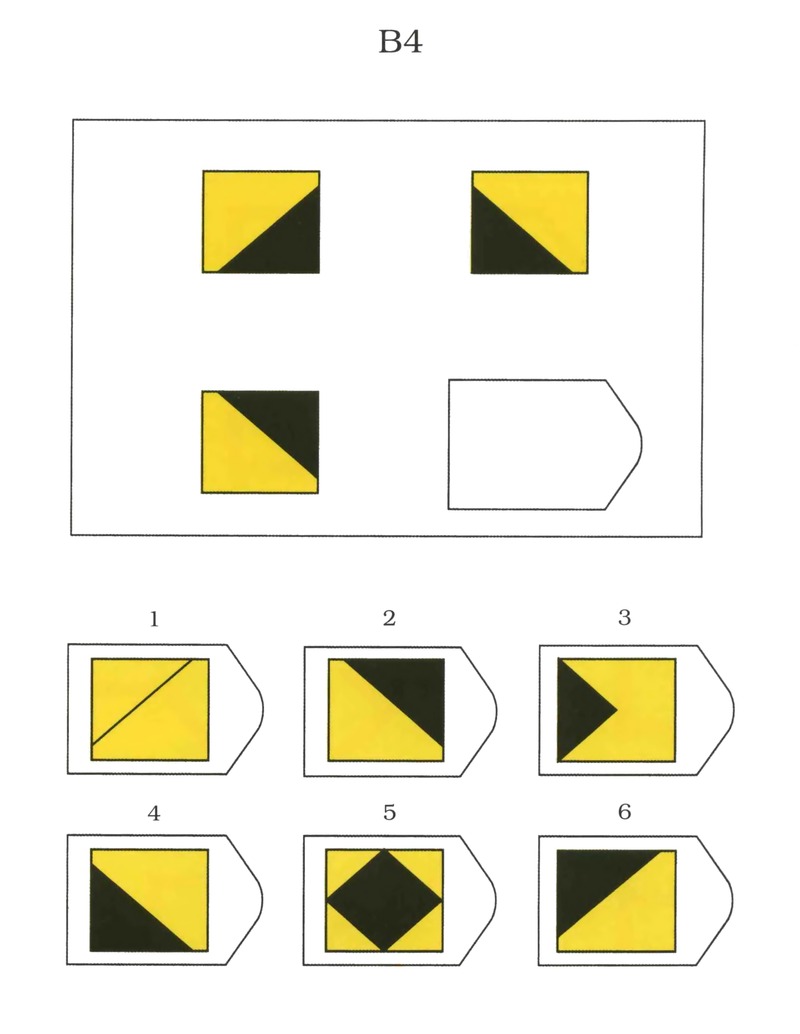 Для того, чтобы соблюсти время, необходимо строго следить за тем, чтобы до общей команды: «Приступить к выполнению теста» — никто не открывал таблицы и не подсматривал. По истечении 20 мин подается команда, например: «Всем закрыть таблицы». О предназначении данного теста можно сказать следующее: «Все наши исследования проводятся исключительно в научных целях, поэтому от вас требуются добросовестность, глубокая обдуманность, искренность и точность в ответах. Данный тест предназначен для уточнения логичности вашего мышления».
После этого взять таблицу и открыть для показа всем 1-ю страницу: «На рисунке одной фигуры недостает. Справа изображено 6-8 пронумерованных фигур, одна из которых является искомой. Надо определить закономерность, связывающую между собой фигуры на рисунке, и указать номер искомой фигуры в листке, который вам выдан» (можно показать на примере одного образца).
Во время выполнения задач теста необходимо контролировать, чтобы респонденты не списывали друг у друга. По истечении 20 мин подать команду: «Закрыть всем таблицы!
Собрать бланки и таблицы к ним.
Для того, чтобы соблюсти время, необходимо строго следить за тем, чтобы до общей команды: «Приступить к выполнению теста» — никто не открывал таблицы и не подсматривал. По истечении 20 мин подается команда, например: «Всем закрыть таблицы». О предназначении данного теста можно сказать следующее: «Все наши исследования проводятся исключительно в научных целях, поэтому от вас требуются добросовестность, глубокая обдуманность, искренность и точность в ответах. Данный тест предназначен для уточнения логичности вашего мышления».
После этого взять таблицу и открыть для показа всем 1-ю страницу: «На рисунке одной фигуры недостает. Справа изображено 6-8 пронумерованных фигур, одна из которых является искомой. Надо определить закономерность, связывающую между собой фигуры на рисунке, и указать номер искомой фигуры в листке, который вам выдан» (можно показать на примере одного образца).
Во время выполнения задач теста необходимо контролировать, чтобы респонденты не списывали друг у друга. По истечении 20 мин подать команду: «Закрыть всем таблицы!
Собрать бланки и таблицы к ним. Проверить, чтобы в правом углу регистрируемого бланка был проставлен карандашом номер обследуемого.
Проверить, чтобы в правом углу регистрируемого бланка был проставлен карандашом номер обследуемого.
Изображение слайда
9
Слайд 9
№ задания Серия A Серия B Серия C Серия D Серия E 1 2 3 4 5 6 7 8 9 10 11 12 Сумма правильных ответов
Изображение слайда
10
Слайд 10
Интерпретация результатов (ключи)
Правильное решение каждого задания оценивается в один балл, затем подсчитывается общее число баллов по всем таблицам и по отдельным сериям. Полученный общий показатель рассматривается как индекс интеллектуальной силы, умственной производительности респондента. Показатели выполнения заданий по отдельным сериям сравнивают со среднестатистическим, учитывают разницу между результатами, полученными в каждой серии, и контрольными, полученными статистической обработкой при исследовании больших групп здоровых обследуемых и, таким образом, расцениваемыми как ожидаемые результату. Такая разница позволяет судить о надежности полученных результатов (это не относится к психической патологии).
№
Серия А
Серия В
Серия С
Серия D
Серия Е
1
4
5
5
3
7
2
5
6
3
4
6
3
1
1
2
3
8
4
2
2
7
8
2
5
6
1
8
7
1
6
3
3
4
6
5
7
6
5
5
5
1
8
2
6
1
4
3
9
1
4
7
1
6
10
3
3
1
2
2
11
4
4
6
5
4
12
2
8
2
6
5
Полученный общий показатель рассматривается как индекс интеллектуальной силы, умственной производительности респондента. Показатели выполнения заданий по отдельным сериям сравнивают со среднестатистическим, учитывают разницу между результатами, полученными в каждой серии, и контрольными, полученными статистической обработкой при исследовании больших групп здоровых обследуемых и, таким образом, расцениваемыми как ожидаемые результату. Такая разница позволяет судить о надежности полученных результатов (это не относится к психической патологии).
№
Серия А
Серия В
Серия С
Серия D
Серия Е
1
4
5
5
3
7
2
5
6
3
4
6
3
1
1
2
3
8
4
2
2
7
8
2
5
6
1
8
7
1
6
3
3
4
6
5
7
6
5
5
5
1
8
2
6
1
4
3
9
1
4
7
1
6
10
3
3
1
2
2
11
4
4
6
5
4
12
2
8
2
6
5
Изображение слайда
11
Слайд 11
Процентная шкала степени развития интеллекта
Полученный суммарный показатель по специальной таблице переводится в проценты.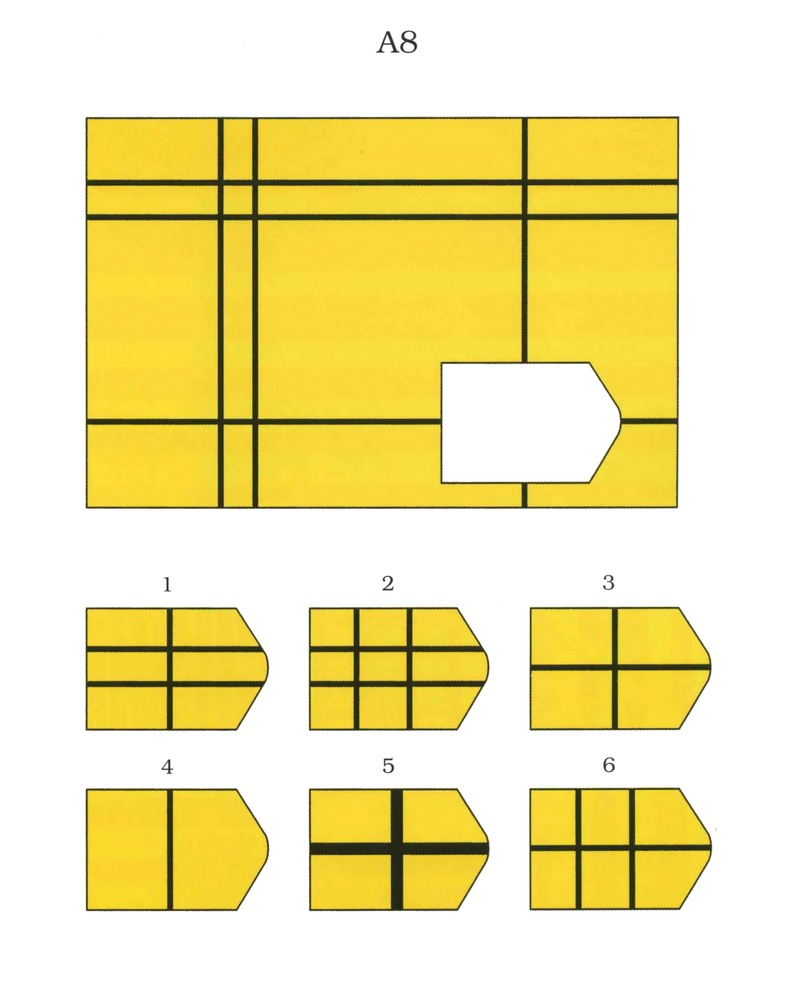 При этом по специальной шкале различают 5 степеней интеллектуального уровня :
Следующий способ оценки общих результатов по Стандартным матрицам Равена заключается в переводе «сырого» балла в стандартизированный — коэффициент IQ.
При этом по специальной шкале различают 5 степеней интеллектуального уровня :
Следующий способ оценки общих результатов по Стандартным матрицам Равена заключается в переводе «сырого» балла в стандартизированный — коэффициент IQ.
Изображение слайда
12
Слайд 12
Возраст 14-30 35 40 45 50 55 65 % 100 97 93 88 82 76 70 Таблица перевода сырых баллов в IQ Далее, ориентируясь на выявленный показатель IQ, можно определить уровень умственных способностей. Градации уровней умственных способностей Показатели IQ Уровень развития интеллекта Свыше 140 незаурядный, выдающийся интеллект 121-140 высокий уровень интеллекта 111-120 интеллект выше среднего 91-110 средний уровень интеллекта 81-90 интеллект ниже среднего 71-80 низкий уровень интеллекта 51-70 лёгкая степень слабоумия 21-50 средняя степень слабоумия 0-20 тяжёлая степень слабоумия
Изображение слайда
13
Слайд 13
A 1 A 2
Изображение слайда
14
Слайд 14
A 3 A 4
Изображение слайда
15
Слайд 15
A 5 A 6
Изображение слайда
16
Слайд 16
A 7 A 8
Изображение слайда
17
Слайд 17
A 9 A 10
Изображение слайда
18
Слайд 18
A 11 A 12
Изображение слайда
19
Слайд 19
B 1 B 2
Изображение слайда
20
Слайд 20
B 3 B 4
Изображение слайда
21
Слайд 21
B 5 B 6
Изображение слайда
22
Слайд 22
B 7 B 8
Изображение слайда
23
Слайд 23
B 9 B 10
Изображение слайда
24
Слайд 24
B 11 B 12
Изображение слайда
25
Слайд 25
C 1 C 2
Изображение слайда
26
Слайд 26
C 3 C 4
Изображение слайда
27
Слайд 27
C 5 C 6
Изображение слайда
28
Слайд 28
C 7 C 8
Изображение слайда
29
Слайд 29
C 9 C 10
Изображение слайда
30
Слайд 30
C 1 1 C 1 2
Изображение слайда
31
Слайд 31
D 1 D 2
Изображение слайда
32
Слайд 32
D 3 D 4
Изображение слайда
33
Слайд 33
D 5 D 6
Изображение слайда
34
Слайд 34
D 7 D 8
Изображение слайда
35
Слайд 35
D 9 D 10
Изображение слайда
36
Слайд 36
D 1 1 D 1 2
Изображение слайда
37
Слайд 37
E 1 E 2
Изображение слайда
38
Слайд 38
E 3 E 4
Изображение слайда
39
Слайд 39
E 5 E 6
Изображение слайда
40
Слайд 40
E 7 E 8
Изображение слайда
41
Слайд 41
E 9 E 10
Изображение слайда
42
Слайд 42
E 11 E 12
Изображение слайда
43
Слайд 43
№ задания Серия A Серия B Серия C Серия D Серия E 1 4 1 (5) 5 3 7 2 5 6 3 4 6 3 1 1 2 3 2 (8) 4 2 2 7 8 2 5 6 1 8 7 1 6 3 3 4 6 8 (5) 7 6 5 5 5 5 (1) 8 2 6 1 4 8 (3) 9 1 4 1 (7) 1 6 10 3 3 6 (1) 1 (2) 7 (2) 11 1 (4) 4 6 2 (5) 5 (4) 12 2 8 3 (2) 7 (6) 6 (5) Сумма правильных ответов 11 11 9 9 5 = 45
Изображение слайда
44
Слайд 44
Полученный суммарный показатель по специальной таблице переводится в проценты. 1 степень — более 95% — высокий интеллект;
2 степень — 75-94% — интеллект выше среднего;
3 степень 25-74% — интеллект средний;
4 степень — 5-24% — интеллект ниже среднего;
степень — ниже 5% — дефект.
Следующий способ оценки общих результатов по Стандартным матрицам Равена заключается в переводе «сырого» балла в стандартизированный — коэффициент IQ.
Возраст
14-30
35
40
45
50
55
65
%
100
97
93
88
82
76
70
1 степень — более 95% — высокий интеллект;
2 степень — 75-94% — интеллект выше среднего;
3 степень 25-74% — интеллект средний;
4 степень — 5-24% — интеллект ниже среднего;
степень — ниже 5% — дефект.
Следующий способ оценки общих результатов по Стандартным матрицам Равена заключается в переводе «сырого» балла в стандартизированный — коэффициент IQ.
Возраст
14-30
35
40
45
50
55
65
%
100
97
93
88
82
76
70
Изображение слайда
45
Слайд 45
Далее, ориентируясь на выявленный показатель IQ, можно определить уровень умственных способностей. Градации уровней умственных способностей Показатели IQ Уровень развития интеллекта Свыше 140 незаурядный, выдающийся интеллект 121-140 высокий уровень интеллекта 111-120 интеллект выше среднего 91-110 средний уровень интеллекта 81-90 интеллект ниже среднего 71-80 низкий уровень интеллекта 51-70 лёгкая степень слабоумия 21-50 средняя степень слабоумия 0-20 тяжёлая степень слабоумия
Изображение слайда
46
Последний слайд презентации: Тест равена: Спасибо за внимание!
Изображение слайда
Тест Равена.
 Шкала прогрессивных матриц
Шкала прогрессивных матриц
1. Тест Равена. Шкала прогрессивных матриц
2. История тесты
Методика «Шкала прогрессивных матриц»была разработана в 1936 году Джоном Равеном
(совместно с Л. Пенроузом).
Автору методики удалось создать тест,
который был бы теоретически обоснован,
однозначно интерпретируем, и оценка которого
минимально зависела бы от различий в
образовании, происхождении и в жизненном опыте
людей.
3. Применение теста
Тест прогрессивные матрицы Равена (ПМР)предназначен для диагностики уровня
интеллектуального развития и оценивает
способность к систематизированной, планомерной,
методичной интеллектуальной деятельности
(логичность мышления).
4. Описание методики
Тест состоит из 60 таблиц (5 серий). В каждойсерии таблиц содержатся задания нарастающей
трудности. В то же время характерно и усложнение
типа заданий от серии к серии. Время прохождения
теста ограничено и составляет 20 мин.

5. Описание серий теста
В серии А — использован принципустановления взаимосвязи в структуре
матриц. Здесь задание заключается в
дополнении недостающей части основного
изображения одним из приведенных в
каждой таблице фрагментов.
Серия В — построена по принципу аналогии
между парами фигур. Обследуемый должен
найти принцип, соответствен но которому
построена в каждом отдельном случае
фигура и, исходя из этого, подобрать
недостающий фрагмент.
Серия С — построена по принципу
прогрессивных изменений в фигурах
матриц. Эти фигуры в пределах одной
матрицы все больше усложняются,
происходит как бы непрерывное их
развитие.
Серия В — построена по принципу
перегруппировки фигур в матрице.
Обследуемый должен найти эту
перегруппировку, происходящую в
горизонтальном и вертикальном
положениях.
Серия Е основана на принципе разложения фигур основного изображения на элементы.
Недостающие фигуры можно найти, поняв принцип анализа и синтеза фигур.
6. Пример тестового вопроса
SNAP-25 gene polymorphism and cognitive resource in patients with stroke sequels | Vilyanov
1. Алфимова МВ, Голимбет ВЕ, Монахов МВ и др. SNAP-25 и DTNBP1 как гены-кандидаты когнитивных резервов при шизофрении. Журнал неврологии и психиатрии им. С.С. Корсакова. 2013;(3):54-60. [Alfimova MV, Golimbet VE, Monakhov MV, et al. SNAP-25 and DTNBP1 as candidate genes for cognitive reserve in schizophrenia. Zhurnal nevrologii i psikhiatrii im. S.S. Korsakova. 2013;(3):54-60. (In Russ.)].
2. Hou QL, Gao X, Lu Q, et al. SNAP-25 in hippocampal CA3 region is required for longterm memory formation. Biochem Biophys Res Commun. 2006 Sep 8;347(4):955-62. Epub 2006 Jul 25.
3. Osen-Sand A, Catsicas M, Staple JK, et al. Inhibition of axonal growth by SNAP-25 antisense oligonucleotides in vitro and in vivo. Nature. 1993 Jul 29;364(6436):445-8.
Osen-Sand A, Catsicas M, Staple JK, et al. Inhibition of axonal growth by SNAP-25 antisense oligonucleotides in vitro and in vivo. Nature. 1993 Jul 29;364(6436):445-8.
4. Gosso MF, de Geus EJ, Polderman TJ, et al. Common variants underlying cognitive ability: further evidence for association between the SNAP-25 gene and cognition using a familybased study in two independent Dutch cohorts. Genes Brain Behav. 2008 Apr;7(3):355-64. Epub 2007 Oct 1.
5. SЪderqvist S, McNab F, Peyrard-Janvid M, et al. The SNAP25 Gene Is Linked to Working Memory Capacity and Maturation of the Posterior ingulate Cortex During Childhood. Biol Psychiatry. 2010 Dec 15;68(12):1120-5. doi: 10.1016/j.biopsych.2010.07.036. Epub 2010 Oct 15.
6. Gosso MF, de Geus EJ, van Belzen MJ, et al. The SNAP-25 gene is associated with cognitive ability: Evidence from a family-based study in two independent Dutch cohorts. Mol Psychiatry. 2006 Sep;11(9):878-86. Epub 2006 Jun 27.
The SNAP-25 gene is associated with cognitive ability: Evidence from a family-based study in two independent Dutch cohorts. Mol Psychiatry. 2006 Sep;11(9):878-86. Epub 2006 Jun 27.
7. Мухордова ОЕ, Шрейбер ТВ, редакторы. Прогрессивные матрицы Равена: методические рекомендации. Ижевск: Удмуртский университет; 2011. 70 с. [Mukhordova OE, Shreyber TV, editors. Progressivnye matritsy Ravena: metodicheskie rekomendatsii [Progressive matrices Raven: methodical recommendations]. Izhevsk: Udmurtskiy universitet; 2011. 70 p.]
8. Шиффер Р. Психология ощущений, глоссарий к книге, 2004 г. [Schiffer R. Psychology of feelings, the glossary to the book, 2004.]
9. Козловский СА, Величковский ББ, Вартанов АВ и др. Роль областей цингулярной коры в функционировании памяти человека. Экспериментальная психология. 2012;(5):12-22. [Kozlovskii SA, Velichkovskii BB, Vartanov AV, et al. The role of singulyarnoi areas of the cortex in the functioning of human memory. Eksperimental’naya psikhologiya. 2012;(5): 12-22. (In Russ.)].
Экспериментальная психология. 2012;(5):12-22. [Kozlovskii SA, Velichkovskii BB, Vartanov AV, et al. The role of singulyarnoi areas of the cortex in the functioning of human memory. Eksperimental’naya psikhologiya. 2012;(5): 12-22. (In Russ.)].
общие сведения о назначении теста и теоретическом конструкте
Прогрессивные матрицы Равена (тест Равена) – методика предназначена для изучения логичности мышления. Предназначен тест для измерения уровня интеллектуального развития. Предложен Л. Пенроузом и Дж. Равеном в 1936 г. Прогрессивные матрицы Равена разрабатывались в соответствии с традициями английской школы изучения интеллекта, согласно которым наилучший способ измерения фактора «g» – задача по выявлению отношений между абстрактными фигурами.
Наиболее
известны два основных варианта:
черно-белый и цветной. Цветной вариант
предназначен для обследования детей
от 6 до 9 лет. Возможно их применение для
детей и более старшего возраста с
аномальным развитием. Иногда рекомендуется
для проведения реабилитационных
исследований и для лиц старше 65 лет.
Цветной вариант
предназначен для обследования детей
от 6 до 9 лет. Возможно их применение для
детей и более старшего возраста с
аномальным развитием. Иногда рекомендуется
для проведения реабилитационных
исследований и для лиц старше 65 лет.
Теор. (методол) основы Тест «Прогрессивные матрицы Равена» относится к числу невербальных тестов интеллекта и основывается на двух теориях, разработанных гештальт-психологией: теорией перцепции форм и так называемой «теорией неогенеза» Ч. Спирмена.
Согласно теории
перцепции форм каждое задание может
быть рассмотрено как определенное
целое, состоящее из ряда взаимосвязанных
друг с другом элементов. Предполагается,
что первоначально происходит глобальная
оценка задания-матрицы, а затем
осуществление аналитической перцепции
с выделением испытуемым принципа,
принятого при разработке серии. На
заключительном этапе выделенные элементы
включаются в целостный образ, что
способствует обнаружению недостающей
детали изображения. Теория Ч. Спирмена
углубляет рассмотренные положения
теории перцепции форм. Как показывает
опыт многолетних исследований, данные,
полученные с помощью теста Равена,
хорошо согласуются с показателями
других распространенных тестов: Векслера,
Стенфорд-Бине, ШТУРа,Выготского-Сахарова.
Прогрессивные матрицы Равена предназначены
для определения уровня умственного
развития у детей ментального возраста
(1-4 класс массовой школы ). Матрицы Равена
могут применяться на испытуемых с любым
языковым составом и социокультурным
фоном, с любым уровнем речевого развития.
Теория Ч. Спирмена
углубляет рассмотренные положения
теории перцепции форм. Как показывает
опыт многолетних исследований, данные,
полученные с помощью теста Равена,
хорошо согласуются с показателями
других распространенных тестов: Векслера,
Стенфорд-Бине, ШТУРа,Выготского-Сахарова.
Прогрессивные матрицы Равена предназначены
для определения уровня умственного
развития у детей ментального возраста
(1-4 класс массовой школы ). Матрицы Равена
могут применяться на испытуемых с любым
языковым составом и социокультурным
фоном, с любым уровнем речевого развития.
Тест состоит из 60 таблиц — 5 серий по 12 задач в каждой.
41. Прогрессивные матрицы Равена: процедура, регистрация данных, интерпритация ПМР, относится к невербальным методикам на интеллект и предназначена для измерения способности мыслить, систематизировать планомерную и методическую д-ть интеллекта. Разработана в 1936 г. в Великобритании Равеном.
Чёрно-белый вариант
состоит из 60 заданий – 5 серий по 12 задач
в каждой.
Инструкция. Каждому испытуемому необходимо выдать 1 экземпляр тетради с заданиями и 1 бланк ответов. До начала тестирования, тест должен быть перевёрнут до тех пор, пока не прозвучит инструкция. Вам будут выданы матрицы, к каждой из которых вам надо будет найти подходящий элемент. На выполнение заданий даётся ограниченное количество времени. До 5 задания включительно, вы имеете право спросить правильность ответа. Старайтесь работать быстро и без ошибок». Первое задание решается совместно с экспериментатором. Время засекается после решения 5 задания. Время прохождения методики = 35 минут.
Данные регистрируются в бланке ответов.
Характеристика
ПМР по отдельным сериям. 1
серия:
характеризуется по непрерывности и
целостности структуры. 2
серия:
характеризуется аналогия между парами
фигур. 3 серия:
характеризуются прогрессивные изменения
в структурах. 4
серия:
характеризуется перестановка структур. 5 серия:
характеризуется разложение структур
на составляющие части. 4.
5 серия:
характеризуется разложение структур
на составляющие части. 4.
Оценка результатов.
|
Степень |
Оценка результатов. |
Результаты. |
|
1. |
Очень хороший, весьма высокий интеллект. |
результат 95% и выше. |
|
2. |
Хороший, высокий интеллект. |
результаты 75 % и выше. |
|
3. |
Средний интеллект. |
Результат в границах выше 25 и ниже 75%. |
|
4. |
Слабый, сниженный интеллект. |
результаты 25% и ниже. |
|
5. |
Очень слабый интеллект или интелл дефект. |
результаты 5% и ниже. |

Количественная обработка производится следующим образом: каждое правильное решения = 1 баллу, в сумме может быть 60 баллов. Подсчитывается общая сумма полученных баллов, общий процент правильных решений, число правильных решений в каждой из 5 серий.
|
|

Независимые образцы t-тест — Учебники SPSS
Постановка проблемы
В нашем выборочном наборе данных учащиеся указали свое обычное время пробежать милю и были ли они спортсменами. Предположим, мы хотим знать, отличается ли среднее время пробега мили для спортсменов и не спортсменов. Это включает в себя проверку того, различаются ли выборочные средние значения времени на милю среди спортсменов и не спортсменов в вашей выборке (и, в более широком смысле, вывод о том, существенно ли различаются средние значения времени на милю в популяции между этими двумя группами).Вы можете использовать тест Independent Samples t , чтобы сравнить среднее время пробега для спортсменов и спортсменов, не занимающихся спортом.
Гипотезы для этого примера могут быть выражены как:
H 0 : µ не спортсмен — µ спортсмен = 0 («разница средних равна нулю»)
H 1 : µ не спортсмен — µ спортсмен ≠ 0 («разница средних не равна нулю»)
, где µ спортсмен и µ не спортсмен — средние значения для спортсменов и не спортсменов, соответственно.
В данных выборки мы будем использовать две переменные: Athlete и MileMinDur . Переменная Атлет имеет значения либо «0» (не спортсмен), либо «1» (спортсмен). Он будет функционировать как независимая переменная в этом T-тесте. Переменная MileMinDur — это числовая переменная продолжительности (ч: мм: сс), и она будет работать как зависимая переменная. В SPSS первые несколько строк данных выглядят так:
Перед испытанием
Перед запуском теста независимых выборок t рекомендуется взглянуть на описательную статистику и графики, чтобы понять, чего ожидать.Запуск «Средств сравнения» (Анализ > Средние сравнения> Средние ) для получения описательной статистики по группам говорит нам, что стандартное отклонение времени на милю для не спортсменов составляет около 2 минут; для спортсменов это около 49 секунд. Это соответствует отклонению в 14803 секунды для не спортсменов и отклонению в 2447 секунд для спортсменов 1 . Выполнение процедуры исследования ( Analyze> Descriptives> Explore ) для получения сравнительной коробчатой диаграммы дает следующий график:
Выполнение процедуры исследования ( Analyze> Descriptives> Explore ) для получения сравнительной коробчатой диаграммы дает следующий график:
Если бы дисперсии действительно были равны, можно было бы ожидать, что общая длина коробчатых диаграмм будет примерно одинаковой для обеих групп.Однако из этой диаграммы ясно, что разброс наблюдений для не спортсменов намного больше, чем разброс наблюдений для спортсменов. Уже сейчас мы можем оценить, что дисперсия для этих двух групп сильно различается. Не будет сюрпризом, если мы запустим тест Independent Samples t и увидим, что тест Левена имеет важное значение.
Кроме того, мы также должны выбрать уровень значимости (обычно обозначаемый греческой буквой альфа, α ), прежде чем проводить наши проверки гипотез.Уровень значимости — это порог, который мы используем для определения значимости результата теста. В этом примере возьмем α = 0,05.
1 При вычислении дисперсии переменной продолжительности (форматированной как чч: мм: сс или мм: сс или мм: сс. с), SPSS преобразует значение стандартного отклонения в секунды перед возведением в квадрат.
с), SPSS преобразует значение стандартного отклонения в секунды перед возведением в квадрат.
Запуск теста
Для запуска независимых образцов t Test:
- Щелкните Анализировать> Сравнить средние> T-тест для независимых выборок .
- Переместите переменную Athlete в поле Grouping Variable и переместите переменную MileMinDur в область Test Variable (s) . Теперь Athlete определен как независимая переменная, а MileMinDur определен как зависимая переменная.
- Щелкните Определить группы , чтобы открыть новое окно. Использовать указанные значения выбрано по умолчанию. Поскольку наша группирующая переменная имеет числовой код (0 = «Не спортсмен», 1 = «Спортсмен»), введите «0» в первое текстовое поле и «1» во втором текстовом поле.Это означает, что мы будем сравнивать группы 0 и 1, которые соответствуют не спортсменам и спортсменам соответственно.
 По завершении щелкните Продолжить .
По завершении щелкните Продолжить . - Щелкните ОК , чтобы запустить тест независимых образцов t . Выходные данные для анализа отобразятся в окне просмотра выходных данных.
Синтаксис
T-ТЕСТОВЫЕ ГРУППЫ = Спортсмен (0 1)
/ MISSING = АНАЛИЗ
/ ПЕРЕМЕННЫЕ = MileMinDur
/CRITERIA=CI(.95).
Выход
Столы
В выходных данных появляются два раздела (прямоугольника): Групповая статистика и Тест независимых выборок .Первый раздел, Group Statistics , предоставляет основную информацию о групповых сравнениях, включая размер выборки ( n ), среднее значение, стандартное отклонение и стандартную ошибку для времени пробега по группе. В этом примере 166 спортсменов и 226 не спортсменов. Среднее время на милю для спортсменов составляет 6 минут 51 секунду, а среднее время на милю для спортсменов — 9 минут 6 секунд.
Второй раздел, Тест независимых образцов , отображает результаты, наиболее подходящие для теста независимых образцов t . Есть две части, которые предоставляют различную информацию: (A) тест Левена на равенство вариантов и (B) t-тест на равенство средних значений.
Есть две части, которые предоставляют различную информацию: (A) тест Левена на равенство вариантов и (B) t-тест на равенство средних значений.
A Тест Левена на равенство вариантов : В этом разделе представлены результаты теста Левена. Слева направо:
- F — статистика теста Левена
- Sig. — p-значение, соответствующее этой статистике теста.
Значение p теста Левена печатается как «.000 «(но следует читать как p <0,001 - то есть p очень мало), поэтому мы отвергаем нулевое значение теста Левена и заключаем, что дисперсия времени на милю у спортсменов значительно отличается от дисперсии не -athletes. Это говорит нам о том, что мы должны посмотреть на строку «Не предполагаемые равные отклонения» для результатов теста t (и соответствующий доверительный интервал) (если этот результат теста не был значимым, то есть если мы наблюдали p > α — тогда мы использовали бы результат «Предполагаемые равные дисперсии». )
)
B t-тест на равенство средних предоставляет результаты для фактического теста независимых выборок t . Слева направо:
Обратите внимание, что средняя разница вычисляется путем вычитания среднего значения второй группы из среднего значения первой группы. В этом примере среднее время на милю для спортсменов было вычтено из среднего времени на милю для не спортсменов (9:06 минус 6:51 = 02:14). Знак средней разности соответствует знаку значения t .Положительное значение t в этом примере указывает на то, что среднее время в миле для первой группы, не спортсменов, значительно больше, чем среднее значение для второй группы, спортсменов.
Соответствующее значение p печатается как «.000»; двойной щелчок по значению p покажет не округленное число. SPSS округляет p-значения до трех десятичных знаков, поэтому любое p-значение, слишком маленькое для округления до 0,001, будет напечатано как 0,000. (В этом конкретном примере значения p имеют порядок 10 -40 . )
)
C Доверительный интервал разницы : Эта часть выходных данных теста t дополняет результаты теста значимости. Как правило, если CI для средней разницы содержит 0 в пределах интервала, т. Е. Если нижняя граница CI является отрицательным числом, а верхняя граница CI является положительным числом, результаты не имеют значения для выбранного уровень значимости. В этом примере 95% доверительный интервал — [01:57, 02:32], который не содержит нуля; это согласуется с небольшим значением критерия значимости p .
Решение и выводы
Поскольку p <0,001 меньше, чем выбранный нами уровень значимости α = 0,05, мы можем отклонить нулевую гипотезу и заключить, что среднее время пробега на милю для спортсменов и не спортсменов значительно различается.
По результатам можно констатировать следующее:
- Наблюдалась значительная разница в средней длине мили между спортсменами и не спортсменами ( t 315.
 846 = 15,047, p <0,001).
846 = 15,047, p <0,001). - Среднее время на милю для спортсменов было на 2 минуты и 14 секунд быстрее, чем среднее время на милю для не спортсменов.
unittest — Среда модульного тестирования — документация Python 3.9.7
Исходный код: Lib / unittest / __ init__.py
(Если вы уже знакомы с основными концепциями тестирования, вы можете чтобы перейти к списку методов assert.)
Фреймворк для юнит-тестирования Фреймворк для юнит-тестирования изначально был вдохновлен JUnit.
и имеет тот же вкус, что и основные фреймворки модульного тестирования в других
языков.Он поддерживает автоматизацию тестирования, совместное использование кода настройки и выключения.
для тестов, объединение тестов в коллекции и независимость
тесты из структуры отчетности.
Для этого unittest поддерживает некоторые важные концепции в
объектно-ориентированный способ:
- Испытательное приспособление
-
Испытательное приспособление представляет собой подготовку, необходимую для выполнения одного или нескольких тесты и любые связанные с ними действия по очистке.
 Это может включать, например,
создание временных или прокси-баз данных, каталогов или запуск сервера
процесс.
Тестовый пример
Это может включать, например,
создание временных или прокси-баз данных, каталогов или запуск сервера
процесс.
Тестовый пример -
Тестовый пример — это отдельная единица тестирования. Он проверяет наличие определенного ответ на конкретный набор входных данных.
unittestпредоставляет базовый класс,TestCase, который можно использовать для создания новых тестовых случаев. - набор тестов
-
Набор тестов — это набор тестовых примеров, наборов тестов или и того, и другого. это используется для агрегирования тестов, которые должны выполняться вместе.
Средство выполнения тестов -
Средство выполнения тестов — это компонент, который организует выполнение тестов и предоставляет результат пользователю.Бегун может использовать графический интерфейс, текстовый интерфейс или вернуть специальное значение, чтобы указать результаты выполнение тестов.
См. Также
Также
- Модуль
doctest -
Еще один модуль поддержки тестирования с совершенно другим вкусом.
- Simple Smalltalk Testing: With Patterns
-
Оригинальная статья Кента Бека о тестовых фреймворках с использованием общего шаблона пользователем
unittest. - pytest
-
Сторонняя среда unittest с облегченным синтаксисом для записи тесты.Например,
assert func (10) == 42. - Таксономия инструментов тестирования Python
-
Обширный список инструментов тестирования Python, включая функциональное тестирование фреймворки и библиотеки имитирующих объектов.
- Тестирование в списке рассылки Python
-
Группа с особыми интересами для обсуждения тестирования и инструментов тестирования, в Python.
Сценарий Tools / unittestgui / unittestgui.py в дистрибутиве исходного кода Python
инструмент с графическим интерфейсом для обнаружения и выполнения тестов.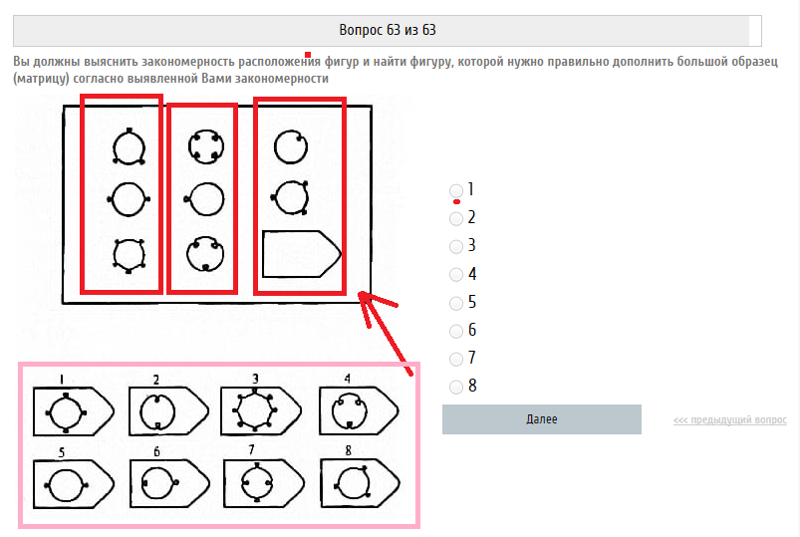 Это сделано в основном для простоты использования.
для новичков в модульном тестировании. Для производственных сред это
рекомендуется, чтобы тесты проводились с помощью системы непрерывной интеграции, такой как
Buildbot, Дженкинс
или Travis-CI, или AppVeyor.
Это сделано в основном для простоты использования.
для новичков в модульном тестировании. Для производственных сред это
рекомендуется, чтобы тесты проводились с помощью системы непрерывной интеграции, такой как
Buildbot, Дженкинс
или Travis-CI, или AppVeyor.
Базовый пример
Модуль unittest предоставляет богатый набор инструментов для построения и
запущенные тесты. В этом разделе показано, что небольшая часть инструментов
достаточно для удовлетворения потребностей большинства пользователей.
Вот короткий сценарий для проверки трех строковых методов:
import unittest
класс TestStringMethods (unittest.Прецедент):
def test_upper (сам):
self.assertEqual ('foo'.upper (),' FOO ')
def test_isupper (сам):
self.assertTrue ('FOO'.isupper ())
self.assertFalse ('Фу'.isupper ())
def test_split (сам):
s = 'привет, мир'
self.assertEqual (s.split (), ['привет', 'мир'])
# проверяем, что s. split не работает, если разделитель не является строкой
с self.assertRaises (TypeError):
с.сплит (2)
если __name__ == '__main__':
unittest.main ()
split не работает, если разделитель не является строкой
с self.assertRaises (TypeError):
с.сплит (2)
если __name__ == '__main__':
unittest.main ()
Тестовый набор создается путем создания подкласса unittest.Тест-кейс . Три
индивидуальные тесты определяются методами, имена которых начинаются с букв
тест . Это соглашение об именах информирует участника тестирования о том, какие методы
представляют собой тесты.
Суть каждого теста — это вызов assertEqual () для проверки наличия
ожидаемый результат; assertTrue () или assertFalse ()
для проверки состояния; или assertRaises () , чтобы убедиться, что
возникает конкретное исключение. Эти методы используются вместо
assert , чтобы исполнитель тестов мог накапливать все результаты тестов.
и составим отчет.
Методы setUp () и tearDown () позволяют
для определения инструкций, которые будут выполняться до и после каждого метода тестирования. Более подробно они описаны в разделе «Организация тестового кода».
Более подробно они описаны в разделе «Организация тестового кода».
Последний блок показывает простой способ запуска тестов. unittest.main ()
предоставляет интерфейс командной строки для тестового сценария. При запуске из команды
строка, приведенный выше сценарий дает результат, который выглядит следующим образом:
... -------------------------------------------------- -------------------- Выполнить 3 теста в 0.000 с Ok
Передавая параметр -v вашему сценарию тестирования, вы получите команду unittest.main ()
для включения более высокого уровня детализации и получения следующего вывода:
test_isupper (__main __. TestStringMethods) ... хорошо test_split (__main __. TestStringMethods) ... хорошо test_upper (__main __. TestStringMethods) ... хорошо -------------------------------------------------- -------------------- Выполнить 3 теста за 0,001 с Ok
В приведенных выше примерах показаны наиболее часто используемые функции unittest , которые
достаточны для удовлетворения многих повседневных потребностей тестирования. Остальная часть
документация исследует полный набор функций с первых принципов.
Остальная часть
документация исследует полный набор функций с первых принципов.
Интерфейс командной строки
Модуль unittest можно использовать из командной строки для запуска тестов из модули, классы или даже отдельные методы испытаний:
python -m unittest test_module1 test_module2 python -m unittest test_module.TestClass python -m unittest test_module.TestClass.test_method
Вы можете передать список с любой комбинацией имен модулей и полностью квалифицированные имена классов или методов.
Тестовые модули также можно указать по пути к файлу:
python -m unittest тесты / test_something.py
Это позволяет использовать завершение имени файла оболочки для указания тестового модуля.
Указанный файл по-прежнему должен быть импортирован как модуль. Путь преобразован
в имя модуля, удалив «.py» и преобразовав разделители путей в «.».
Если вы хотите запустить тестовый файл, который нельзя импортировать как модуль, вам следует
вместо этого выполнить файл напрямую.
Вы можете запускать тесты с более подробной информацией (более высокая степень детализации), передав флаг -v:
python -m unittest -v тестовый_модуль
При выполнении без аргументов запускается тестовое обнаружение:
Список всех параметров командной строки:
Изменено в версии 3.2: В более ранних версиях можно было запускать только отдельные методы тестирования и не модули или классы.
Параметры командной строки
unittest поддерживает следующие параметры командной строки:
-
-b,- буфер -
Стандартный поток вывода и стандартные потоки ошибок буферизируются во время теста бег. Вывод при прохождении теста отбрасывается. Вывод отображается нормально при провале теста или ошибке и добавляется к сообщениям об ошибках.
-
-c,-catch -
Control-C во время тестового запуска ожидает завершения текущего теста, а затем сообщает все результаты на данный момент.
 Второй Control-C поднимает нормальный
Второй Control-C поднимает нормальный
KeyboardInterruptисключение.См. Раздел Обработка сигналов для получения информации о функциях, обеспечивающих эту функциональность.
-
-f,-failfast -
Остановить тестовый прогон при первой ошибке или сбое.
-
-к -
Запускайте только тестовые методы и классы, соответствующие шаблону или подстроке. Этот параметр можно использовать несколько раз, и в этом случае все тестовые примеры, включены совпадения заданных шаблонов.
Шаблоны, содержащие подстановочный знак (
*), сопоставляются с имя теста с использованиемfnmatch.fnmatchcase (); в противном случае просто с учетом регистра Используется сопоставление подстроки.Шаблоны сопоставляются с полным именем метода тестирования как импортировано тестовым загрузчиком.

Например,
-k fooсоответствуетfoo_tests.SomeTest.test_something,bar_tests.SomeTest.test_foo, но неbar_tests.FooTest.test_something.
-
- местные жители -
Показать локальные переменные в трассировке.
Новое в версии 3.2: добавлены параметры командной строки -b , -c и -f .
Новое в версии 3.5: Параметр командной строки --locals .
Новое в версии 3.7: параметр командной строки -k .
Командную строку также можно использовать для обнаружения тестов, для запуска всех тесты в проекте или только в подмножестве.
Тестовое открытие
Unittest поддерживает простое обнаружение тестов. Чтобы быть совместимым с тестом
обнаружение, все тестовые файлы должны быть модулями или
пакеты (включая пакеты пространства имен), импортируемые из каталога верхнего уровня
проект (это означает, что их имена файлов должны быть действительными идентификаторами).
Обнаружение тестов реализовано в TestLoader.discover () , но также может быть
используется из командной строки. Базовое использование командной строки:
cd каталог_проекта python -m unittest обнаружить
Примечание
В качестве ярлыка python -m unittest эквивалентен
python -m unittest обнаружить . Если вы хотите передать аргументы для проверки
обнаружение подкоманда обнаружение должна использоваться явно.
Подкоманда discover имеет следующие параметры:
-
-v,-verbose -
Подробный вывод
-
-s,--start-directorydirectory -
Каталог для начала обнаружения (
.по умолчанию)
-
-p,- шаблоншаблон -
Шаблон для соответствия тестовым файлам (
test * .по умолчанию) py
py
-
-t,--top-level-directorydirectory -
Каталог верхнего уровня проекта (по умолчанию — начальный каталог)
Параметры -s , -p и -t могут быть переданы в
как позиционные аргументы в этом порядке.Следующие две командные строки
эквивалентны:
python -m unittest discover -s каталог_проекта -p "* _test.py" python -m unittest обнаружить каталог_проекта "* _test.py"
Помимо пути, можно передать имя пакета, например
myproject.subpackage.test в качестве начального каталога. Пакет называет вас
Затем поставка будет импортирована, и будет использовано ее местоположение в файловой системе.
в качестве начального каталога.
Осторожно
Обнаружение тестов загружает тесты, импортируя их.Как только тестовое обнаружение обнаружит
все тестовые файлы из начального каталога, который вы укажете, он поворачивает пути
в имена пакетов для импорта. Например,
Например, foo / bar / baz.py будет
импортировано как foo.bar.baz .
Если у вас есть пакет, установленный глобально, и попробуйте выполнить тестовое обнаружение на другая копия пакета, тогда импорт может происходить из неправильное место. Если это произойдет, тестовое обнаружение предупредит вас и выйдет.
Если вы укажете начальный каталог как имя пакета, а не как путь к каталогу, а затем обнаружение предполагает, что в любом месте он импорт из того места, которое вы планировали, поэтому вы не получите предупреждение.
Тестовые модули и пакеты могут настраивать тестовую загрузку и обнаружение с помощью протокол load_tests.
Изменено в версии 3.4: Тестовое обнаружение поддерживает пакеты пространства имен.
для начального каталога. Обратите внимание, что вам нужно указать верхний уровень
каталог тоже (например,
python -m unittest discover -s root / namespace -t root ).
Код организации тестирования
Основными строительными блоками модульного тестирования являются тестовых случаев — одиночный
сценарии, которые необходимо настроить и проверить на правильность. В
В unittest ,
тестовые примеры представлены экземплярами unittest.TestCase .
Чтобы создать свои собственные тестовые примеры, вы должны написать подклассы
TestCase или используйте FunctionTestCase .
Тестовый код экземпляра TestCase должен быть полностью самостоятельным
содержится, так что его можно запускать как изолированно, так и произвольно.
комбинация с любым количеством других тестовых случаев.
Простейший подкласс TestCase просто реализует метод тестирования
(я.е. метод, имя которого начинается с test ) для выполнения определенных
код тестирования:
import unittest
класс DefaultWidgetSizeTestCase (unittest.TestCase):
def test_default_widget_size (self):
widget = Виджет ('Виджет')
self.assertEqual (размер виджета (), (50, 50))
Обратите внимание, чтобы что-то протестировать, мы используем одно из утверждений * ()
методы, предоставляемые базовым классом TestCase . Если тест не пройден,
исключение будет вызвано с пояснительным сообщением, и
Если тест не пройден,
исключение будет вызвано с пояснительным сообщением, и unittest
идентифицирует тестовый пример как ошибку .Любые другие исключения будут
обрабатывается как ошибок .
Тесты могут быть многочисленными, и их настройка может повторяться. К счастью, мы
может исключить установочный код, реализовав метод, называемый
setUp () , который среда тестирования автоматически
звоните для каждого отдельного теста, который мы запускаем:
import unittest
класс WidgetTestCase (unittest.TestCase):
def setUp (сам):
self.widget = Виджет ('Виджет')
def test_default_widget_size (self):
себя.assertEqual (self.widget.size (), (50,50),
'неправильный размер по умолчанию')
def test_widget_resize (сам):
self.widget.resize (100,150)
self.assertEqual (self.widget.size (), (100,150),
'неправильный размер после изменения размера')
Примечание
Порядок, в котором будут выполняться различные тесты, определяется
путем сортировки имен тестовых методов по встроенным
заказ струн.
Если метод setUp () вызывает исключение во время выполнения теста
запущен, фреймворк будет считать, что в тесте произошла ошибка, и
метод тестирования не будет выполняться.
Точно так же мы можем предоставить метод tearDown () , который убирает
после запуска метода тестирования:
import unittest
класс WidgetTestCase (unittest.TestCase):
def setUp (сам):
self.widget = Виджет ('Виджет')
def tearDown (сам):
self.widget.dispose ()
Если setUp () успешно, tearDown () будет
запустить независимо от того, прошел ли тестовый метод успешно.
Такая рабочая среда для кода тестирования называется
Приспособление для испытаний .Новый экземпляр TestCase создается как уникальный
тестовое приспособление, используемое для выполнения каждого отдельного метода тестирования. Таким образом
setUp () , tearDown () и __init __ ()
будет вызываться один раз за тест.
Рекомендуется использовать реализации TestCase для группировки тестов вместе
согласно тестируемым характеристикам. unittest обеспечивает механизм для
это: набор тестов , представленный unittest ’s
TestSuite класс.В большинстве случаев вызов unittest.main () подойдет.
то, что нужно, соберите для вас все тестовые примеры модуля и выполните
их.
Однако, если вы хотите настроить сборку своего набора тестов, можно сделать самому:
def Suite ():
suite = unittest.TestSuite ()
suite.addTest (WidgetTestCase ('test_default_widget_size'))
suite.addTest (WidgetTestCase ('test_widget_resize'))
возвращение люкс
если __name__ == '__main__':
runner = unittest.TextTestRunner ()
бегун.запустить (набор ())
Вы можете разместить определения тестовых случаев и наборов тестов в одних и тех же модулях.
в качестве кода, который они должны тестировать (например, widget.py ), но есть несколько
преимущества размещения тестового кода в отдельном модуле, например
test_widget.py :
-
Тестовый модуль можно запустить автономно из командной строки.
-
Контрольный код легче отделить от кода поставки.
-
Меньше соблазна изменить тестовый код в соответствии с кодом, который он тестирует без веская причина.
-
Тестовый код следует изменять гораздо реже, чем код, который он тестирует.
-
Протестированный код легче подвергнуть рефакторингу.
-
Тесты для модулей, написанных на C, в любом случае должны быть в отдельных модулях, так почему бы и нет быть последовательным?
-
При изменении стратегии тестирования нет необходимости изменять исходный код.
Повторное использование старого кода теста
Некоторые пользователи обнаружат, что у них есть тестовый код, который они хотели бы
запускать из unittest , не конвертируя все старые тестовые функции в
TestCase подкласс.
По этой причине unittest предоставляет класс FunctionTestCase .
Этот подкласс TestCase можно использовать для обертывания существующего теста.
функция. Также могут быть предусмотрены функции настройки и демонтажа.
Дана следующая тестовая функция:
def testSomething ():
что-то = makeSomething ()
assert something.name не None
# ...
можно создать эквивалентный экземпляр тестового примера следующим образом, с необязательным методы установки и демонтажа:
testcase = unittest.FunctionTestCase (testSomething,
setUp = makeSomethingDB,
tearDown = deleteSomethingDB)
Примечание
Хотя FunctionTestCase можно использовать для быстрого преобразования
от существующей тестовой базы к системе на основе unittest , этот подход
не рекомендуется. Потратьте время на настройку правильного TestCase
подклассы значительно упростят рефакторинг тестов в будущем.
В некоторых случаях существующие тесты могли быть написаны с использованием doctest
модуль.Если это так, doctest предоставляет класс DocTestSuite , который может
автоматически создавать экземпляры unittest.TestSuite из существующих
doctest — тесты.
Пропуск тестов и ожидаемые отказы
Unittest поддерживает пропуск отдельных методов тестирования и даже целых классов
тесты. Кроме того, он поддерживает пометку теста как «ожидаемого отказа», теста
который сломан и выйдет из строя, но не должен считаться отказом на
TestResult .
Пропуск теста — это просто вопрос использования декоратора skip ()
или один из его условных вариантов, вызывая TestCase.skipTest () в
setUp () или метод тестирования, или вызов SkipTest напрямую.
Базовый пропуск выглядит так:
класс MyTestCase (unittest.TestCase):
@ unittest.skip («демонстрация пропусков»)
def test_nothing (сам):
self.fail («не должно происходить»)
@ unittest.skipIf (mylib .__ version__ <(1, 3),
"не поддерживается в этой версии библиотеки")
def test_format (сам):
# Тесты, работающие только для определенной версии библиотеки.проходить
@ unittest.skipUnless (sys.platform.startswith ("win"), "требуется Windows")
def test_windows_support (самостоятельно):
# код тестирования для Windows
проходить
def test_maybe_skipped (сам):
если не external_resource_available ():
self.skipTest («внешний ресурс недоступен»)
# тестовый код, зависящий от внешнего ресурса
проходить
Это результат выполнения приведенного выше примера в подробном режиме:
test_format (__main__.MyTestCase) ... пропущено 'не поддерживается в этой версии библиотеки' test_nothing (__main __. MyTestCase) ... пропущено 'демонстрация пропуска' test_maybe_skipped (__main __. MyTestCase) ... пропущено 'внешний ресурс недоступен' test_windows_support (__main __. MyTestCase) ... пропущено 'требует Windows' -------------------------------------------------- -------------------- Выполнить 4 теста за 0,005 с. ОК (пропущено = 4)
Классы можно пропускать так же, как и методы:
@ unittest.skip ("показывает пропуск занятий")
класс MySkippedTestCase (unittest.Прецедент):
def test_not_run (сам):
проходить
TestCase.setUp () также может пропустить тест. Это полезно, когда ресурс
который необходимо настроить, недоступен.
Ожидаемые сбои используют декоратор expectedFailure () .
класс ExpectedFailureTestCase (unittest.TestCase):
@ unittest.expectedFailure
def test_fail (сам):
self.assertEqual (1, 0, «сломанный»)
Легко создать собственные пропускающие декораторы, создав декоратор, который вызывает
skip () на тесте, когда он хочет, чтобы его пропустили.Этот декоратор пропускает
тест, если переданный объект не имеет определенного атрибута:
def skipUnlessHasattr (obj, attr):
если hasattr (obj, attr):
вернуть лямбда-функцию: func
return unittest.skip ("{! r} не имеет {! r}". format (obj, attr))
Следующие декораторы и исключения реализуют пропуск тестов и ожидаемые сбои:
-
@unittest.пропустить( причина ) -
Безоговорочно пропустить оформленный тест. причина должна описывать, почему тест пропускается.
-
@unittest.skipIf( условие , причина ) -
Пропустить декорированный тест, если условие истинно.
-
@unittest.пропустить Если( условие , причина ) -
Пропустить декорированный тест, если не выполняется условие .
-
@unittest.ожидается Отказ -
Отметить тест как ожидаемый сбой или ошибку. Если тест не прошел или возникли ошибки в самой тестовой функции (а не в одном из тестовых приспособлений методы), то это будет считаться успешным. Если тест пройден, он считаться неудачей.
-
исключение
unittest.SkipTest( причина ) -
Это исключение возникает для пропуска теста.
Обычно вы можете использовать
TestCase.skipTest ()или одну из пропущенных декораторы вместо того, чтобы поднимать это напрямую.
В пропущенных тестах не будет выполняться setUp () или tearDown () .
Для пропущенных классов не будет выполняться setUpClass () или tearDownClass () .
Пропущенные модули не будут выполнять setUpModule () или tearDownModule () .
Различение итераций теста с помощью подтестов
Когда между вашими тестами есть очень маленькие различия, для
Например, некоторые параметры, unittest позволяет различать их внутри
тело метода тестирования с использованием диспетчера контекста subTest () .
Например, следующий тест:
класс NumbersTest (unittest.TestCase):
def test_even (сам):
"" "
Проверьте, все ли числа от 0 до 5 четны.
"" "
для i в диапазоне (0, 6):
с self.subTest (i = i):
self.assertEqual (я% 2, 0)
выдаст следующий результат:
================================================= =====================
ОТКАЗ: test_even (__main __. NumbersTest) (i = 1)
-------------------------------------------------- --------------------
Отслеживание (последний вызов последний):
Файл "субтесты.py ", строка 32, в test_even
self.assertEqual (я% 2, 0)
AssertionError: 1! = 0
================================================== ====================
ОТКАЗ: test_even (__main __. NumbersTest) (i = 3)
-------------------------------------------------- --------------------
Отслеживание (последний вызов последний):
Файл "subtests.py", строка 32, в test_even
self.assertEqual (я% 2, 0)
AssertionError: 1! = 0
================================================== ====================
ОТКАЗ: test_even (__main __. NumbersTest) (i = 5)
-------------------------------------------------- --------------------
Отслеживание (последний вызов последний):
Файл "субтесты.py ", строка 32, в test_even
self.assertEqual (я% 2, 0)
AssertionError: 1! = 0
Без использования подтеста выполнение остановится после первого сбоя,
и ошибку будет труднее диагностировать, потому что значение i
не будет отображаться:
================================================= =====================
ОТКАЗ: test_even (__main __. NumbersTest)
-------------------------------------------------- --------------------
Отслеживание (последний вызов последний):
Файл "субтесты.py ", строка 32, в test_even
self.assertEqual (я% 2, 0)
AssertionError: 1! = 0
Классы и функции
В этом разделе подробно описывается API unittest .
Тестовые наборы
-
класс
unittest.TestCase( methodName = 'runTest' ) -
Экземпляры класса
TestCaseпредставляют собой логические тестовые единицы во вселеннойunittest. Этот класс предназначен для использования в качестве базового класс, при этом конкретные тесты реализуются конкретными подклассами.Этот класс реализует интерфейс, необходимый для запуска тестов, чтобы позволить ему управлять тесты и методы, которые тестовый код может использовать для проверки и сообщения о различных виды неудач.Каждый экземпляр
TestCaseбудет запускать единственный базовый метод: метод с именем methodName . В большинстве случаев использованияTestCaseвы не будете менять methodName и не переопределить методrunTest ()по умолчанию.Изменено в версии 3.2:
TestCaseможет быть успешно создан без предоставления Имя метода . Это упрощает эксперименты сTestCase. из интерактивного переводчика.Экземпляры TestCaseпредоставляют три группы методов: одна использованная группа для запуска теста, другой используется реализацией теста для проверки условий и сообщать о сбоях, а также о некоторых методах запроса, позволяющих получить информацию о сам тестируй собраться.Методы первой группы (выполняющей тест):
-
Комплект
-
Метод, вызываемый для подготовки испытательного приспособления.Это называется немедленно перед вызовом тестового метода; кроме
AssertionErrorилиSkipTest, любое исключение, вызванное этим методом, будет считаться ошибкой, а не провал теста. Реализация по умолчанию ничего не делает.
-
tearDown() -
Метод, вызываемый сразу после вызова метода тестирования и результат записан. Это вызывается, даже если тестовый метод вызвал исключение, поэтому реализация в подклассах может потребоваться особенно осторожно проверяйте внутреннее состояние.Любое исключение, кроме
AssertionErrorилиSkipTest, вызванные этим методом, будут считается дополнительной ошибкой, а не провалом теста (таким образом, увеличивая общее количество сообщенных ошибок). Этот метод будет вызываться только в том случае, еслиsetUp ()завершается успешно, независимо от результата метода тестирования. Реализация по умолчанию ничего не делает.
-
setUpClass() -
Метод класса, вызываемый перед запуском тестов в отдельном классе.
setUpClassвызывается с классом в качестве единственного аргумента и должен быть оформлен как метод класса():@classmethod def setUpClass (cls): ...Дополнительные сведения см. В разделе «Приспособления для классов и модулей».
-
tearDownClass() -
Метод класса, вызываемый после выполнения тестов в отдельном классе.
tearDownClassвызывается с классом в качестве единственного аргумента и должен быть оформлен как метод класса():@classmethod def tearDownClass (cls): ...Дополнительные сведения см. В разделе «Приспособления для классов и модулей».
-
запустить(результат = нет ) -
Запустите тест, собрав результат в объект
TestResultпередано как результат . Если результат опущен илиНет, временный создается объект результата (вызовомdefaultTestResult ()метод) и используется. Объект результата возвращается вrun ()’s звонящий.Тот же эффект можно получить, просто позвонив в
TestCaseпример.Изменено в версии 3.3: Предыдущие версии
выполнялине возвращали результат. Тоже не сделал вызов экземпляра.
-
skipTest( причина ) -
Вызов этого метода во время теста или
setUp ()пропускает текущий тестовое задание. См. Пропуск тестов и ожидаемые сбои для получения дополнительной информации.
-
подтест(сообщение = нет , ** параметры ) -
Вернуть диспетчер контекста, который выполняет вложенный блок кода как субтест. msg и params являются необязательными, произвольные значения, которые отображается всякий раз, когда подтест не проходит, что позволяет идентифицировать их четко.
Тестовый пример может содержать любое количество объявлений подтестов, и они могут быть вложены произвольно.
См. Раздел «Различение итераций теста с помощью подтестов» для получения дополнительной информации.
-
отладка() -
Запустить тест без сбора результатов. Это позволяет создавать исключения тестом, который будет передан вызывающему, и может использоваться для поддержки запуск тестов под отладчиком.
Класс
TestCaseпредоставляет несколько методов утверждения для проверки и сообщать о сбоях. В следующей таблице перечислены наиболее часто используемые методы. (дополнительные методы assert см. в таблицах ниже):Метод
Проверяет, что
Новое в
assertEqual (a, b)a == bassertNotEqual (a, b)a! = BassertTrue (x)bool (x) истинноassertFalse (x)bool (x) неверноassertIs (a, b)a is b3.1
assertIsNot (a, b)a не b3,1
assertIsNone (x)x Нет3,1
assertIsNotNone (x)x не равно Нет3,1
assertIn (а, б)a дюйм b3.1
assertNotIn (a, b)a не в b3,1
assertIsInstance (a, b)isinstance (a, b)3,2
assertNotIsInstance (a, b)не является экземпляром (а, б)3.2
Все методы assert принимают аргумент msg , который, если указан, используется как сообщение об ошибке при сбое (см. также
longMessage). Обратите внимание, что аргумент ключевого слова msg может быть передан вassertRaises (),assertRaisesRegex (),assertWarns (),assertWarnsRegex ()только когда они используются в качестве диспетчера контекста.-
assertEqual( первый , второй , msg = Нет ) -
Проверить, что первый и второй равны.Если значения не сравните равные, тест не пройдёт.
Кроме того, если первые и вторые являются одним и тем же типом и одним из list, tuple, dict, set, frozenset или str или любой тип, являющийся подклассом регистрируется с помощью
addTypeEqualityFunc ()равенство, зависящее от типа функция будет вызываться, чтобы сгенерировать более полезное значение по умолчанию сообщение об ошибке (см. также список методов для конкретных типов).Изменено в версии 3.1: Добавлен автоматический вызов функции равенства типов.
Изменено в версии 3.2:
assertMultiLineEqual ()добавлено как равенство типов по умолчанию функция сравнения строк.
-
assertNotEqual( первый , второй , msg = Нет ) -
Проверить, что первый и второй не равны. Если значения сравните равные, тест не пройдёт.
-
assertTrue( expr , msg = None ) -
assertFalse( expr , msg = None ) -
Проверить, что expr истинно (или ложно).
Обратите внимание, что это эквивалентно
bool (expr), True, а неexpr равно True(для последнего используйтеassertIs (expr, True)). Этот способ также следует избегать, когда доступны более конкретные методы (например,assertEqual (a, b)вместоassertTrue (a == b)), потому что они предоставить лучшее сообщение об ошибке в случае сбоя.
-
assertIs( первый , второй , msg = Нет ) -
assertIsNot( первый , второй , msg = Нет ) -
Проверьте, что первый и второй являются (или не являются) одним и тем же объектом.
-
assertIsNone( expr , msg = None ) -
assertIsNotNone( expr , msg = None ) -
Проверьте, что expr является (или не является)
None.
-
assertIn(элемент , контейнер , msg = Нет ) -
assertNotIn(элемент , контейнер , сообщение = Нет ) -
Проверьте, находится ли элемент (или нет) в контейнере .
-
assertIsInstance( obj , cls , msg = None ) -
assertNotIsInstance( obj , cls , msg = None ) -
Проверьте, что obj является (или не является) экземпляром cls (который может быть class или кортеж классов, поддерживаемый
isinstance ()). Чтобы проверить точный тип, используйтеassertIs (type (obj), cls).
Также можно проверить создание исключений, предупреждений и регистрировать сообщения, используя следующие методы:
Метод
Проверяет, что
Новое в
assertRaises (exc, fun, * args, ** kwds)fun (* args, ** kwds)рейзит excassertRaisesRegex (exc, r, fun, * args, ** kwds)fun (* args, ** kwds)рейзит exc и сообщение соответствует регулярному выражению r3.1
assertWarns (предупреждение, забава, * аргументы, ** kwds)fun (* args, ** kwds)поднимает warn3,2
assertWarnsRegex (warn, r, fun, * args, ** kwds)fun (* args, ** kwds)поднимает предупреждает и сообщение соответствует регулярному выражению r3,2
assertLogs (регистратор, уровень)сблокировкой журналов на регистраторе с минимальным уровнем3.4
-
assertRaises( исключение , вызываемый , * args , ** kwds ) -
assertRaises( исключение , * , msg = Нет ) -
Проверить, возникает ли исключение, когда вызываемый вызывается с любым позиционные или ключевые аргументы, которые также передаются в
assertRaises (). Тест проходит, если возникает исключение , это ошибка, если возникает другое исключение, или сбой, если исключение не возникает.Чтобы перехватить любую группу исключений, кортеж, содержащий исключение классы могут передаваться как , исключение .Если указаны только исключение и, возможно, аргументы msg , вернуть диспетчер контекста, чтобы можно было написать тестируемый код встроенный, а не как функция:
с self.assertRaises (SomeException): сделай что-нибудь()При использовании в качестве диспетчера контекста
assertRaises ()принимает дополнительный аргумент ключевого слова msg .Диспетчер контекста сохранит перехваченный объект исключения в своем
исключениеатрибут. Это может быть полезно, если намерение заключается в выполнении дополнительных проверок возникшего исключения:с self.assertRaises (SomeException) как cm: сделай что-нибудь() the_exception = cm.exception self.assertEqual (the_exception.error_code, 3)Изменено в версии 3.1: Добавлена возможность использовать
assertRaises ()в качестве диспетчера контекста.Изменено в версии 3.2: Добавлен атрибут исключения
.Изменено в версии 3.3: Добавлен аргумент ключевого слова msg при использовании в качестве диспетчера контекста.
-
assertRaisesRegex( исключение , regex , вызываемый , * args , ** kwds ) -
assertRaisesRegex( исключение , регулярное выражение , * , msg = Нет ) -
Как
assertRaises (), но также проверяет соответствие регулярному выражению в строковом представлении возникшего исключения. регулярное выражение может быть объект регулярного выражения или строка, содержащая регулярное выражение подходит для использованияre.search (). Примеры:self.assertRaisesRegex (ValueError, "недопустимый литерал для. * XYZ '$", int, 'XYZ')или:
с self.assertRaisesRegex (ValueError, 'literal'): интервал ('XYZ')Новое в версии 3.1: добавлено под именем
assertRaisesRegexp.Изменено в версии 3.3: Добавлен аргумент ключевого слова msg при использовании в качестве диспетчера контекста.
-
assertWarns( предупреждение , вызываемый , * args , ** kwds ) -
assertWarns( предупреждение , * , msg = Нет ) -
Проверить, что предупреждение срабатывает, когда вызываемый вызывается с любым позиционные или ключевые аргументы, которые также передаются в
assertWarns ().Тест считается пройденным, если срабатывает предупреждение и терпит неудачу, если это не так. Любое исключение - ошибка. Чтобы поймать любое из группы предупреждений, кортеж, содержащий предупреждение классы могут передаваться как предупреждений .Если даны только предупреждение и, возможно, аргументы msg , вернуть диспетчер контекста, чтобы можно было написать тестируемый код встроенный, а не как функция:
с self.assertWarns (SomeWarning): сделай что-нибудь()При использовании в качестве диспетчера контекста
assertWarns ()принимает дополнительный аргумент ключевого слова msg .Диспетчер контекста сохранит обнаруженный объект предупреждения в своем
предупреждениеатрибут и исходная строка, которая вызвала предупреждения в атрибутахfilenameиcabin. Это может быть полезно, если вы собираетесь выполнить дополнительные проверки. на предупреждении поймано:с self.assertWarns (SomeWarning) как cm: сделай что-нибудь() self.assertIn ('myfile.py', cm.filename) self.assertEqual (320, см. lineno)Этот метод работает независимо от установленных фильтров предупреждений, когда он называется.
Изменено в версии 3.3: Добавлен аргумент ключевого слова msg при использовании в качестве диспетчера контекста.
-
assertWarnsRegex( предупреждение , regex , вызываемый , * args , ** kwds ) -
assertWarnsRegex( предупреждение , регулярное выражение , * , msg = Нет ) -
Подобно
assertWarns (), но также проверяет соответствие регулярному выражению на сообщение о сработавшем предупреждении. regex может быть регулярным выражением объект или строка, содержащая регулярное выражение, подходящее для использования пользователяre.search (). Пример:self.assertWarnsRegex (DeprecationWarning, r'legacy_function \ (\) устарела ', legacy_function, 'XYZ')или:
с self.assertWarnsRegex (RuntimeWarning, 'небезопасный запуск'): заморозить ('/ etc / passwd')Изменено в версии 3.3: Добавлен аргумент ключевого слова msg при использовании в качестве диспетчера контекста.
-
assertLogs(регистратор = Нет , level = Нет ) -
Диспетчер контекста для проверки наличия хотя бы одного сообщения в системе регистратор или один из его дочерних, по крайней мере, с заданным уровень .
Если задано, регистратор должен быть объектом регистрации
. Объект регистратораилиstrс названием регистратора. По умолчанию это корень регистратор, который перехватит все сообщения, которые не были заблокированы нераспространяющийся потомок регистратора.Если задан, уровень должен быть либо числовым уровнем ведения журнала, либо его строковый эквивалент (например,
"ERROR"илижурнал.ОШИБКА). По умолчанию ведется журнал.INFO.Тест считается пройденным, если внутри
было отправлено хотя бы одно сообщение с кодом. блок соответствует условиям регистратора и уровня , в противном случае он не работает.Объект, возвращаемый диспетчером контекста, является помощником записи. который отслеживает соответствующие сообщения журнала.Имеет два атрибуты:
-
записей -
Список объектов журнала
.LogRecordсоответствия сообщения журнала.
-
выход -
Список объектов
strс форматированным выводом соответствующие сообщения.
Пример:
с self.assertLogs ('foo', level = 'INFO') как cm: logging.getLogger ('foo'). info ('первое сообщение') logging.getLogger ('foo.bar '). error (' второе сообщение ') self.assertEqual (cm.output, ['ИНФОРМАЦИЯ: foo: первое сообщение', 'ОШИБКА: foo.bar: второе сообщение']) -
Существуют также другие методы, используемые для выполнения более конкретных проверок, например:
Метод
Проверяет, что
Новое в
assertAlmostEqual (a, b)круглый (a-b, 7) == 0assertNotAlmostEqual (a, b)круглый (a-b, 7)! = 0assertGreater (a, b)a> b3.1
assertGreaterEqual (a, b)a> = b3,1
assertLess (a, b)a3,1
assertLessEqual (a, b)a <= b3,1
assertRegex (s, r)р.поиск (ы)3,1
assertNotRegex (s, r)без повторного поиска3,2
assertCountEqual (a, b)a и b имеют одинаковые элементы в том же количестве, независимо от их порядка.
3,2
-
assertAlmostEqual( первый , второй , мест = 7 , msg = None , delta = None ) -
assertNotAlmostEqual( первый , второй , мест = 7 , msg = None , delta = None ) -
Проверьте, что первый и второй приблизительно (или не приблизительно) равны, вычисляя разницу, округляя до заданного количества десятичная дробь разрядов (по умолчанию 7) и сравнение с нулем.Обратите внимание, что эти методы округляют значения до заданного числа из десятичных знаков (т.е. как функция
round ()), а не значащих цифр .Если дельта вместо ставит , то разница между первым и вторым должно быть меньше или равно (или больше) дельта .
Подача дельта и позиций вызывает
TypeError.Изменено в версии 3.2:
assertAlmostEqual ()автоматически считает почти равные объекты которые сравнивают равными.assertNotAlmostEqual ()автоматически завершается ошибкой если сравнивать объекты одинаково. Добавлен аргумент ключевого слова delta .
-
assertGreater( первый , второй , msg = Нет ) -
assertGreaterEqual( первый , второй , msg = Нет ) -
assertLess( первый , второй , msg = Нет ) -
assertLessEqual( первый , второй , msg = Нет ) -
Проверить, что первый соответственно>,> =, <или <= второй в зависимости по имени метода.В противном случае тест не пройден:
>>> self.assertGreaterEqual (3, 4) AssertionError: «3» неожиданно не больше или равно «4»
-
assertRegex( текст , регулярное выражение , msg = Нет ) -
assertNotRegex( текст , регулярное выражение , msg = Нет ) -
Проверить, что поиск по регулярному выражению соответствует (или не совпадает) с текстом . В случае ошибки, сообщение об ошибке будет включать шаблон и текст (или шаблон и часть текста , которая неожиданно совпала). регулярное выражение может быть объектом регулярного выражения или строкой, содержащей регулярный выражение, подходящее для использования
re.search ().Новое в версии 3.1: добавлено под именем
assertRegexpMatches.Изменено в версии 3.2: Метод
assertRegexpMatches ()был переименован вassertRegex ().Новое в версии 3.5: имя
assertNotRegexpMatchesявляется устаревшим псевдонимом дляassertNotRegex ().
-
assertCountEqual( первый , второй , msg = Нет ) -
Проверить, что последовательность первый содержит те же элементы, что и второй , независимо от их порядка. В противном случае появляется сообщение об ошибке со списком будут сгенерированы различия между последовательностями.
Дублирующиеся элементы не игнорируются при сравнении первых и второй . Он проверяет, имеет ли каждый элемент одинаковое количество в обоих последовательности.Эквивалентен:
assertEqual (Счетчик (список (первый)), Счетчик (список (второй)))но работает и с последовательностями нехэшируемых объектов.
Метод
assertEqual ()отправляет проверку равенства для объектов один и тот же тип для разных методов, зависящих от типа. Эти методы уже есть реализовано для большинства встроенных типов, но также возможно зарегистрируйте новые методы с помощьюaddTypeEqualityFunc ():-
addTypeEqualityFunc( typeobj , функция ) -
Регистрирует зависящий от типа метод, вызываемый
assertEqual ()для проверки если два объекта точно такого же типа obj (не подклассы) сравнивают равный. функция должна принимать два позиционных аргумента и третий msg = None аргумент ключевого слова точно так же, какassertEqual (). Он должен поднятьself.failureException (msg)при неравенстве между первыми двумя параметрами обнаруживается - возможно, обеспечивая полезный информация и подробное объяснение неравенств в ошибке сообщение.
Список методов, зависящих от типа, автоматически используемых
assertEqual ()приведены в следующей таблице.Примечание что обычно нет необходимости вызывать эти методы напрямую.-
assertMultiLineEqual( первый , второй , msg = Нет ) -
Проверить, что многострочная строка первый равна строке второй . Когда не равно разница двух строк, подчеркивающая различия будет включено в сообщение об ошибке. Этот метод используется по умолчанию при сравнении строк с
assertEqual ().
-
assertSequenceEqual( первый , второй , msg = None , seq_type = None ) -
Проверяет, что две последовательности равны. Если указан seq_type , оба первый и второй должны быть экземплярами seq_type , иначе произойдет сбой. быть поднятым. Если последовательности отличаются, появляется сообщение об ошибке. построенный, который показывает разницу между ними.
Этот метод не вызывается напрямую
assertEqual (), но он используется для реализацииassertListEqual ()иassertTupleEqual ().
-
assertListEqual( первый , второй , msg = Нет ) -
assertTupleEqual( первый , второй , msg = Нет ) -
Проверяет равенство двух списков или кортежей. В противном случае появляется сообщение об ошибке. построенный, который показывает только различия между ними. Ошибка также возникает, если какой-либо из параметров имеет неправильный тип. Эти методы используются по умолчанию при сравнении списков или кортежей с
assertEqual ().
-
assertSetEqual( первый , второй , msg = Нет ) -
Проверяет, что два набора равны. В противном случае создается сообщение об ошибке. в котором перечислены различия между наборами. Этот метод используется по умолчанию при сравнении наборов или замороженных наборов с
assertEqual ().Сбой, если один из первый или второй не имеет
set.difference ()метод.
-
assertDictEqual( первый , второй , msg = Нет ) -
Проверка равенства двух словарей. В противном случае появляется сообщение об ошибке. построено, что показывает различия в словарях. Этот будет использоваться по умолчанию для сравнения словарей в вызывает
assertEqual ().
Наконец,
TestCaseпредоставляет следующие методы и атрибуты:-
сбой(сообщение = нет ) -
Безоговорочно сигнализирует об отказе теста, с сообщением или
Нетдля сообщение об ошибке.
-
failureException -
Этот атрибут класса выдает исключение, вызванное тестовым методом. Если инфраструктура тестирования должна использовать специализированное исключение, возможно, для переноса дополнительная информация, он должен создать подкласс этого исключения, чтобы «играть ярмарка »с рамкой. Начальное значение этого атрибута
Ошибка утверждения.
-
длинное Сообщение -
Этот атрибут класса определяет, что происходит, когда пользовательское сообщение об ошибке передается в качестве аргумента msg при неудачном вызове assertXYY.
Истинно- значение по умолчанию. В этом случае добавляется собственное сообщение до конца стандартного сообщения об ошибке. Если установлено значениеЛожь, настраиваемое сообщение заменяет стандартное сообщение.Настройку класса можно переопределить в отдельных методах тестирования, назначив атрибут экземпляра self.longMessage до
TrueилиFalseперед вызов методов assert.Настройка класса сбрасывается перед каждым тестовым вызовом.
-
maxDiff -
Этот атрибут управляет максимальной длиной выводимых различий с помощью assert методы, которые сообщают о различиях в случае сбоя.По умолчанию это 80 * 8 символов. Методы утверждения, на которые влияет этот атрибут:
assertSequenceEqual ()(включая все сравнения последовательностей методы, которые делегируют ему),assertDictEqual ()иassertMultiLineEqual ().Настройка
maxDiff отдоНетозначает, что нет максимальной длины разн.
Среды тестирования могут использовать следующие методы для сбора информации о тест:
-
countTestCases() -
Вернуть количество тестов, представленных этим тестовым объектом.Для
TestCase, это всегда будет1.
-
defaultTestResult() -
Вернуть экземпляр класса результата теста, который должен использоваться для этого класс тестового примера (если в
run ()метод).Для экземпляров
TestCaseэто всегда будет экземплярTestResult; подклассыTestCaseдолжны переопределить это как необходимо.
-
id() -
Вернуть строку, идентифицирующую конкретный тестовый пример. Обычно это полное имя тестового метода, включая имя модуля и класса.
-
краткое Описание() -
Возвращает описание теста или
Нет, если нет описания был предоставлен. Реализация этого метода по умолчанию возвращает первую строку строки документации тестового метода, если она доступна, илиНет.Изменено в версии 3.1: В версии 3.1 это было изменено, чтобы добавить имя теста в краткое описание даже при наличии строки документации. Это вызвало проблемы с совместимостью с расширениями unittest и добавление имени теста было перемещено в
TextTestResultв Python 3.2.
-
addCleanup( функция , /, * args , ** kwargs ) -
Добавить функцию, которая будет вызываться после
tearDown ()для очистки ресурсов использовался во время теста.Функции будут вызываться в обратном порядке к порядок их добавления ( LIFO ). Они вызываются с любыми аргументами и аргументами ключевого слова, переданными вaddCleanup ()при их добавлении.Если
setUp ()завершается неудачно, что означает, чтоtearDown ()не вызывается, тогда все добавленные функции очистки будут вызываться.
-
doCleanups() -
Этот метод вызывается безоговорочно после
tearDown ()или послеsetUp (), еслиsetUp ()вызывает исключение.Он отвечает за вызов всех функций очистки, добавленных
addCleanup (). Если вам нужно вызвать функции очистки до доtearDown (), затем вы можете позвонить по телефонуdoCleanups ()сам.doCleanups ()извлекает методы из стека очистки функционирует по одному, поэтому его можно вызывать в любое время.
-
classmethod
addClassCleanup( функция , /, * args , ** kwargs ) -
Добавить функцию, которая будет вызываться после
tearDownClass ()для очистки ресурсы, используемые во время тестового класса.Функции будут вызываться в обратном порядке порядок их добавления ( LIFO ). Они вызываются с любыми аргументами и аргументами ключевого слова, переданными вaddClassCleanup ()при их добавлении.Если
setUpClass ()завершается с ошибкой, это означает, чтоtearDownClass ()не выполняется. вызывается, то все добавленные функции очистки будут по-прежнему вызываться.
-
classmethod
doClassCleanups() -
Этот метод вызывается безоговорочно после
tearDownClass ()или послеsetUpClass (), еслиsetUpClass ()вызывает исключение.Он отвечает за вызов всех функций очистки, добавленных
addClassCleanup (). Если вам нужно вызвать функции очистки до доtearDownClass (), тогда вы можете позвонитьdoClassCleanups ()самостоятельно.doClassCleanups ()извлекает методы из стека очистки функционирует по одному, поэтому его можно вызывать в любое время.
-
Комплект
-
класс
unittest.IsolatedAsyncioTestCase( methodName = 'runTest' ) -
Этот класс предоставляет API, аналогичный
TestCase, а также принимает сопрограммы как тестовые функции.-
сопрограмма
asyncSetUp() -
Метод, вызываемый для подготовки испытательного приспособления. Это вызывается после
setUp (). Это вызывается непосредственно перед вызовом тестового метода; Кроме какAssertionErrorилиSkipTest, любое исключение, вызванное этим методом будет считаться ошибкой, а не провалом теста. Реализация по умолчанию ничего не делает.
-
сопрограмма
asyncTearDown() -
Метод, вызываемый сразу после вызова метода тестирования и результат записан.Это вызывается до
tearDown (). Это называется, даже если метод тестирования вызвал исключение, поэтому для реализации в подклассах может потребоваться быть особенно внимательным при проверке внутреннего состояния. Любое исключение, кромеAssertionErrorилиSkipTest, вызванные этим методом, будут считается дополнительной ошибкой, а не провалом теста (таким образом, увеличивая общее количество сообщенных ошибок). Этот метод будет вызываться только в том случае, еслиasyncSetUp ()завершается успешно, независимо от результата метода тестирования.Реализация по умолчанию ничего не делает.
-
addAsyncCleanup(функция , /, * args , ** kwargs ) -
Этот метод принимает сопрограмму, которая может использоваться как функция очистки.
-
запустить(результат = нет ) -
Устанавливает новый цикл событий для запуска теста, собирая результат в объект
TestResultпередан как результат .Если результат будет опущено илиНет, создается временный объект результата (путем вызова методdefaultTestResult ()) и использовал. Объект результата вернулся вrun () вызывающий абонент. По окончании теста все задания в цикле событий отменяются.
Пример, иллюстрирующий заказ:
из unittest import IsolatedAsyncioTestCase события = [] класс Test (IsolatedAsyncioTestCase): def setUp (сам): События.append ("setUp") async def asyncSetUp (сам): self._async_connection = ждать AsyncConnection () events.append ("asyncSetUp") async def test_response (сам): events.append ("test_response") response = await self._async_connection.get ("https://example.com") self.assertEqual (response.status_code, 200) self.addAsyncCleanup (self.on_cleanup) def tearDown (сам): events.append ("tearDown") async def asyncTearDown (сам): ждать себя._async_connection.close () events.append ("asyncTearDown") async def on_cleanup (сам): events.append («очистка») если __name__ == "__main__": unittest.main ()После запуска теста
событиябудут содержать["setUp", "asyncSetUp", "test_response", "asyncTearDown", "tearDown", "cleanup"]. -
сопрограмма
-
класс
unittest.FunctionTestCase( testFunc , setUp = None , tearDown = None , description = None ) -
Этот класс реализует часть интерфейса
TestCase, которая позволяет исполнителю теста провести тест, но не предоставляет методы какой тестовый код можно использовать для проверки и сообщения об ошибках.Это используется для создания тестовые примеры с использованием устаревшего тестового кода, что позволяет интегрировать его вunittest Тестовая среда на основе.
Устаревшие псевдонимы
По историческим причинам некоторые методы TestCase имели один или несколько
псевдонимы, которые теперь устарели. В следующей таблице перечислены правильные имена.
вместе с их устаревшими псевдонимами:
Не рекомендуется, начиная с версии 3.1: псевдонимы fail *, перечисленные во втором столбце, устарели.
Не рекомендуется, начиная с версии 3.2: псевдонимы assert *, перечисленные в третьем столбце, устарели.
Не рекомендуется, начиная с версии 3.5: имя
assertNotRegexpMatchesустарело в пользуassertNotRegex ().
Групповые испытания
-
класс
unittest.TestSuite( тестов = () ) -
Этот класс представляет собой совокупность отдельных тестовых примеров и наборов тестов.Класс представляет интерфейс, необходимый для запуска тестов. как и любой другой тестовый пример. Запуск экземпляра
TestSuiteаналогичен итерация по набору, запуск каждого теста индивидуально.Если дан тестов , он должен быть повторением отдельных тестовых примеров или других наборы тестов, которые будут использоваться для первоначальной сборки набора. Дополнительные методы предоставляются для добавления тестовых примеров и наборов в коллекцию позже.
Объекты TestSuiteведут себя так же, как объектыTestCase, за исключением они фактически не проводят тест.Вместо этого они используются для агрегирования тесты на группы тестов, которые должны выполняться вместе. Некоторые дополнительные доступны методы для добавления тестов в экземплярыTestSuite:-
addTest( тест ) -
Добавьте в набор
TestCaseилиTestSuite.
-
addTests( тестов ) -
Добавьте все тесты из итерации
TestCaseиTestSuiteэкземпляры к этому набору тестов.Это эквивалентно повторению тестов , вызову
addTest ()для каждый элемент.
TestSuiteиспользует следующие методы сTestCase:-
пробег( результат ) -
Запустите тесты, связанные с этим набором, собрав результат в объект результата теста передан как результат результат . Обратите внимание, что в отличие от
TestCase.run (),TestSuite.run ()требует, чтобы объект результата пройти.
-
отладка() -
Запустить тесты, связанные с этим набором, без сбора результат. Это позволяет распространять исключения, вызванные тестом, на вызывающий и может использоваться для поддержки выполнения тестов в отладчике.
-
countTestCases() -
Вернуть количество тестов, представленных этим тестовым объектом, включая все индивидуальные тесты и подкомплексы.
-
__iter__() -
Доступ к тестам, сгруппированным по
TestSuite, всегда осуществляется итерацией. Подклассы могут лениво предоставлять тесты, переопределяя__iter __ (). Примечание что этот метод может вызываться несколько раз в одном пакете (для пример при подсчете тестов или сравнении на равенство), поэтому тесты возвращенный повторными итерациями доTestSuite.run ()должен быть то же самое для каждой итерации вызова. ПослеTestSuite.run (), вызывающие должны не полагаться на тесты, возвращаемые этим методом, если вызывающий не использует подкласс, который переопределяетTestSuite._removeTestAtIndex ()для сохранения тестовые ссылки.Изменено в версии 3.2: в более ранних версиях
TestSuiteобращался к тестам напрямую, а не чем через итерацию, поэтому переопределения__iter __ ()было недостаточно для предоставления тестов.Изменено в версии 3.4: в более ранних версиях
TestSuiteсодержал ссылки на каждыйTestCaseпослеTestSuite.запустить (). Подклассы могут восстанавливать это поведение путем переопределенияTestSuite._removeTestAtIndex ().
При типичном использовании объекта
TestSuiteметодrun ()вызывается программойTestRunner, а не тестовой системой конечного пользователя. -
Нагрузочные и ходовые испытания
-
класс
unittest.Загрузчик тестов -
Класс
TestLoaderиспользуется для создания наборов тестов из классов и модули.Обычно нет необходимости создавать экземпляр этого класса; в Модульunittestпредоставляет экземпляр, который можно использовать какunittest.defaultTestLoader. Однако при использовании подкласса или экземпляра позволяет настраивать некоторые настраиваемые свойства.Объекты TestLoaderимеют следующие атрибуты:-
ошибок -
Список нефатальных ошибок, обнаруженных при загрузочных тестах. Не сбрасывать загрузчиком в любой момент.Неустранимые ошибки сигнализируются соответствующими метод, вызывающий исключение для вызывающей стороны. Нефатальные ошибки также указывается синтетическим тестом, который вызывает исходную ошибку, когда бег.
Объекты TestLoaderимеют следующие методы:-
loadTestsFromTestCase( testCaseClass ) -
Возвращает набор всех тестовых случаев, содержащихся в
TestCase, производном отtestCaseClass.Экземпляр тестового набора создается для каждого метода, названного
getTestCaseNames ().По умолчанию это имена методов начиная стест. ЕслиgetTestCaseNames ()возвращает no методов, но реализован методrunTest (), единственный тест case создается вместо этого для этого метода.
-
loadTestsFromModule( модуль , шаблон = Нет ) -
Вернуть набор всех тестовых случаев, содержащихся в данном модуле. Этот метод ищет в модуле классы, производные от
TestCaseи создает экземпляр класса для каждого метода тестирования, определенного для класс.Примечание
При использовании иерархии классов
, производных от TestCase, можно удобно в совместном использовании фикстур и вспомогательных функций, определяя тест методы на базовых классах, которые не предназначены для создания экземпляров напрямую не работает с этим методом. Однако это может быть полезным, когда приборы разные и определены в подклассах.Если модуль предоставляет функцию
load_tests, он будет вызван для загрузить тесты. Это позволяет модулям настраивать тестовую загрузку.Это протокол load_tests. Аргумент шаблона передается как третий аргументload_tests.Изменено в версии 3.2: добавлена поддержка
load_tests.Изменено в версии 3.5: Недокументированный и неофициальный аргумент use_load_tests по умолчанию устарел и игнорируется, хотя все еще принимается для обратного совместимость. Метод также теперь принимает аргумент, состоящий только из ключевых слов. Шаблон , который передается в
load_testsв качестве третьего аргумента.
-
loadTestsFromName( имя , module = None ) -
Вернуть набор всех тестовых примеров с учетом спецификатора строки.
Спецификатор имя - это «имя, разделенное точками», которое может разрешаться либо в модуль, класс тестового примера, метод тестирования в классе тестового примера,
TestSuiteили вызываемый объект, который возвращает ЭкземплярTestCaseилиTestSuite. Эти проверки применяется в указанном здесь порядке; то есть метод возможного теста case-класс будет выбран как «тестовый метод в тестовом классе», а не «вызываемый объект».Например, если у вас есть модуль
SampleTests, содержащийTestCase- производный классSampleTestCaseс тремя тестами методы (test_one (),test_two ()иtest_three ()), спецификатор'SampleTests.SampleTestCase'приведет к тому, что этот метод вернуть набор, который будет запускать все три метода тестирования. Использование спецификатора'SampleTests.SampleTestCase.test_two'заставит его вернуть тест набор, который будет запускать только тестовый методtest_two ().Спецификатор может относиться к модулям и пакетам, которые не были импортированы; они будут быть импортированным как побочный эффект.Метод необязательно разрешает имя относительно данного модуля .
Изменено в версии 3.5: если при перемещении возникает ошибка
ImportErrorилиAttributeErrorname , то синтетический тест, который вызывает эту ошибку при запуске, будет вернулся. Эти ошибки включены в ошибки, накопленные себя.ошибки.
-
loadTestsFromNames( имен , module = None ) -
Похож на
loadTestsFromName (), но принимает последовательность имен, а не чем одно имя. Возвращаемое значение - это набор тестов, который поддерживает все тесты, определенные для каждого имени.
-
getTestCaseNames( testCaseClass ) -
Возвращает отсортированную последовательность имен методов, найденных в testCaseClass ; это должен быть подкласс
TestCase.
-
discover( start_dir , pattern = 'test * .py' , top_level_dir = None ) -
Найдите все тестовые модули, рекурсивно переходя в подкаталоги из указанный начальный каталог и вернуть объект TestSuite, содержащий их. Будут загружены только тестовые файлы, соответствующие шаблону . (Использование стиля оболочки сопоставление с шаблоном.) Только имена модулей, которые можно импортировать (т.е. Идентификаторы Python) будут загружены.
Все тестовые модули должны быть импортированы с верхнего уровня проекта. Если начальный каталог не является каталогом верхнего уровня, тогда верхний уровень каталог необходимо указывать отдельно.
Если при импорте модуля произошел сбой, например, из-за синтаксической ошибки, то это будет записано как отдельная ошибка, и обнаружение будет продолжено. Если сбой импорта из-за того, что был поднят
SkipTest, он будет записывается как пропуск вместо ошибки.Если пакет (каталог, содержащий файл с именем
__init__.py) это найден, пакет будет проверен на наличие функцииload_tests. Если это существует, то он будет называтьсяpackage.load_tests (загрузчик, тесты, паттерн). Test Discovery заботится чтобы гарантировать, что пакет проверяется на тесты только один раз во время вызов, даже если функция load_tests сама вызывает Загрузчик. Открытие.Если существует
load_tests, то обнаружение , а не , рекурсивно переходит в пакет,load_testsотвечает за загрузку всех тестов в упаковка.Шаблон намеренно не сохраняется в качестве атрибута загрузчика, чтобы пакеты могут продолжить обнаружение самостоятельно. top_level_dir хранится так
load_testsне нужно передавать этот аргумент вloader.discover ().start_dir может быть именем модуля, разделенным точками, а также каталогом.
Изменено в версии 3.4: модули, которые вызывают
SkipTestпри импорте, записываются как пропуски, не ошибки.Изменено в версии 3.4: Пути сортируются перед импортом, так что порядок выполнения является то же самое, даже если порядок базовой файловой системы не зависит по имени файла.
Изменено в версии 3.5: найденные пакеты теперь проверяются на предмет
load_testsнезависимо от соответствует ли их путь шаблону , потому что это невозможно для имя пакета, соответствующее шаблону по умолчанию.
Следующие атрибуты
TestLoaderмогут быть настроены либо с помощью подкласс или присвоение экземпляру:-
testMethodPrefix -
Строка с префиксом имени метода, который будет интерпретироваться как тест методы.Значение по умолчанию -
«тест».Это влияет на
getTestCaseNames ()и на все loadTestsFrom * ()
-
sortTestMethodsUsing -
Функция, которая будет использоваться для сравнения имен методов при их сортировке в
getTestCaseNames ()и все методыloadTestsFrom * ().
-
люксКласс -
Вызываемый объект, который создает набор тестов из списка тестов.Нет методы на результирующем объекте необходимы. Значение по умолчанию -
TestSuiteкласс.Это влияет на все методы
loadTestsFrom * ().
-
testNamePatterns -
Список шаблонов имен тестов с подстановочными знаками в стиле оболочки Unix, которые тестируют методы должны соответствовать, чтобы быть включенными в наборы тестов (см. опцию
-v).Если этот атрибут не
Нет(по умолчанию), все методы тестирования должны быть входящие в комплекты тестов должны соответствовать одному из шаблонов в этом списке.Обратите внимание, что совпадения всегда выполняются с использованиемfnmatch.fnmatchcase (), поэтому в отличие от шаблонов, переданных в опцию-v, простые шаблоны подстроки необходимо будет преобразовать с использованием подстановочных знаков*.Это влияет на все методы
loadTestsFrom * ().
-
-
класс
unittest.Результат теста -
Этот класс используется для сбора информации о том, какие тесты были успешными. и которые потерпели неудачу.
Объект
TestResultхранит результаты набора тестов. В КлассыTestCaseиTestSuiteгарантируют, что результаты правильно записаны; авторам тестов не нужно беспокоиться о записи результат испытаний.Среды тестирования, построенные на основе
unittest, могут нуждаться в доступе кTestResult Объект, созданный путем запуска набора тестов для создания отчетов цели; экземплярTestResultвозвращаетсяTestRunner.run ()для этой цели.TestResult Экземплярыимеют следующие атрибуты, которые будут Интерес при просмотре результатов запуска набора тестов:-
ошибок -
Список, содержащий 2 кортежа экземпляров
TestCaseи строк хранение отформатированных трассировок. Каждый кортеж представляет собой тест, который поднял неожиданное исключение.
-
отказов -
Список, содержащий 2 кортежа экземпляров
TestCaseи строк хранение отформатированных трассировок.Каждый кортеж представляет собой тест, в котором произошел сбой. был явно сигнализирован с использованием методовTestCase.assert * ().
-
пропущено -
Список, содержащий 2 кортежа экземпляров
TestCaseи строк удерживая причину пропуска теста.
-
Ожидается
Неисправности -
Список, содержащий 2 кортежа экземпляров
TestCaseи строк хранение отформатированных трассировок.Каждый кортеж представляет собой ожидаемый сбой или ошибка тестового примера.
-
неожиданные успехи -
Список, содержащий
экземпляров TestCase, которые были отмечены как ожидалось неудачи, но удалось.
-
следует остановить -
Устанавливается на
Истинно, когда выполнение тестов должно останавливаться наstop ().
-
тестов Выполнить -
Общее количество выполненных тестов.
-
буфер -
Если установлено значение true,
sys.stdoutиsys.stderrбудут буферизованы между ВызываютсяstartTest ()иstopTest (). Собранный результат будет будет отображаться только на реальныхsys.stdoutиsys.stderr, если тест сбои или ошибки. Любой вывод также прилагается к сообщению об ошибке / сбое.
-
отказоустойчивый -
Если установлено значение true
stop ()будет вызываться при первом сбое или ошибке, остановка пробного запуска.
-
tb_locals -
Если установлено значение true, то в трассировке будут отображаться локальные переменные.
-
был успешным() -
Вернуть
Истина, если все тесты пройдены до сих пор, в противном случае возвращаетЛожь.
-
упор() -
Этот метод может быть вызван, чтобы сообщить, что набор выполняемых тестов должен быть прервано установкой для атрибута
shouldStopзначенияTrue.TestRunner Объектыдолжны учитывать этот флаг и возвращаться без выполнение любых дополнительных тестов.Например, эта функция используется классом
TextTestRunnerдля остановить тестовую среду, когда пользователь сигнализирует о прерывании от клавиатура. Интерактивные инструменты, обеспечивающиеTestRunnerреализации могут использовать это аналогичным образом.
Следующие методы класса
TestResultиспользуются для поддержки внутренние структуры данных и могут быть расширены в подклассы для поддержки дополнительные требования к отчетности.Это особенно полезно при создании инструменты, которые поддерживают интерактивную отчетность во время выполнения тестов.-
startTest( test ) -
Вызывается, когда будет запущен тестовый пример test .
-
stopTest( test ) -
Вызывается после выполнения тестового примера test , независимо от исход.
-
startTestRun() -
Вызывается один раз перед выполнением любых тестов.
-
stopTestRun() -
Вызывается один раз после выполнения всех тестов.
-
addError( test , err ) -
Вызывается, когда тестовый пример Тест вызывает непредвиденное исключение. err - это кортеж формы, возвращаемый
sys.exc_info ():(тип, значение, трассировка).Реализация по умолчанию добавляет кортеж
(test, formatted_err)в атрибутошибок экземпляра, где formatted_err - это отформатированная трассировка, полученная из , ошибка .
-
addFailure( test , err ) -
Вызывается, когда тестовый пример test сигнализирует об ошибке. err - это кортеж форма, возвращаемая
sys.exc_info ():(тип, значение, трассировка).Реализация по умолчанию добавляет кортеж
(test, formatted_err)в атрибутотказов экземпляра, где ошибка_форматирования - это отформатированная трассировка, полученная из , ошибка .
-
addSuccess( тест ) -
Вызывается, когда тестовый пример успешно проходит тест .
Реализация по умолчанию ничего не делает.
-
addSkip( тест , причина ) -
Вызывается, когда пропущен тестовый пример test . причина причина тест дали на пропуск.
Реализация по умолчанию добавляет кортеж
(тест, причина)в экземплярпропустил атрибут.
-
addExpectedFailure( test , err ) -
Вызывается, когда тестовый пример Тест дает сбой или ошибки, но был отмечен значком декоратор
expectedFailure ().Реализация по умолчанию добавляет кортеж
(test, formatted_err)в атрибутexpectedFailuresэкземпляра, где ошибка_форматирования это отформатированная трассировка, полученная из err .
-
addUnexpectedSuccess( тест ) -
Вызывается, когда тестовый пример Тест был отмечен знаком
expectedFailure ()декоратор, но успешно.Реализация по умолчанию добавляет тест к экземпляру Атрибут
unknownSuccesses.
-
addSubTest( тест , субтест , результат ) -
Вызывается по завершении подтеста. тест - тестовый пример соответствующий методу испытаний. субтест - кастомный
TestCaseЭкземпляр, описывающий подтест.Если результат -
Нет, подтест завершился успешно. Иначе, это не удалось, за исключением случая, когда результат является кортежем в форме возвращаетсяsys.exc_info ():(тип, значение, трассировка).Реализация по умолчанию ничего не делает, когда результатом является успех, и записывает сбои подтестов как обычные сбои.
-
-
класс
unittest.TextTestResult( поток , описания , подробность ) -
Конкретная реализация
TestResult, используемаяTextTestRunner.Новое в версии 3.2: этот класс ранее назывался
_TextTestResult. Старое имя все еще существует как псевдоним, но устарел.
-
unittest.defaultTestLoader -
Экземпляр класса
TestLoader, предназначенный для совместного использования. Если нет требуется настройкаTestLoader, этот экземпляр можно использовать вместо того, чтобы многократно создавать новые экземпляры.
-
класс
unittest.TextTestRunner( stream = None , descriptions = True , verbosity = 1 , failfast = False , buffer = False , resultclass = None , warnings = None * , tb_locals = Ложь ) -
Базовая реализация средства выполнения тестов, которая выводит результаты в поток.Если поток равно
Нет, по умолчаниюsys.stderrиспользуется в качестве выходного потока. Этот класс имеет несколько настраиваемых параметров, но по сути очень прост. Графический приложения, которые запускают наборы тестов, должны предоставлять альтернативные реализации. Такой реализации должны принимать** kwargsв качестве интерфейса для создания бегунов изменяется при добавлении функций в unittest.По умолчанию этот бегун показывает
DeprecationWarning,PendingDeprecationWarning,ResourceWarningиImportWarning, даже если они по умолчанию игнорируются.Предупреждения об устаревании, вызванные устаревшим модулем unittest методы также имеют специальный регистр и, когда предупреждение фильтры:'по умолчанию'или'всегда', они будут отображаться только один раз на модуль, чтобы избежать слишком большого количества предупреждающих сообщений. Такое поведение может можно переопределить с помощью параметров Python-Wdили-Wa(см. Предупреждение) и оставив предупреждений с поНет.Изменено в версии 3.2: Добавлен аргумент
warnings.Изменено в версии 3.2: поток по умолчанию установлен на
sys.stderrво время создания экземпляра, а не чем время импорта.Изменено в версии 3.5: Добавлен параметр tb_locals.
-
_makeResult() -
Этот метод возвращает экземпляр
TestResult, используемыйrun (). Он не предназначен для прямого вызова, но может быть переопределен в подклассы для предоставления настраиваемогоTestResult._makeResult ()создает экземпляр класса или вызываемого объекта, переданного вTextTestRunnerв качестве аргументаresultclass.Это по умолчаниюTextTestResult, если не указан класс результатовпоток, описания, многословие
-
пробег( пробег ) -
Этот метод является основным общедоступным интерфейсом для
TextTestRunner. Этот Метод принимает экземплярTestSuiteилиTestCase. АTestResultсоздается путем вызова_makeResult ()и тесты выполняются, а результаты выводятся на стандартный вывод.
-
-
unittest.основной( module = '__ main__' , defaultTest = None , argv = None , testRunner = None , testLoader = unittest.defaultTestLoader , exit = 1 True os , failfast = Нет , catchbreak = Нет , buffer = Нет , предупреждений = Нет ) -
Программа командной строки, которая загружает набор тестов из модуля и запускает их; это в первую очередь для того, чтобы сделать тестовые модули удобными для исполнения.Самым простым способом использования этой функции является включение следующей строки в конец тестового скрипта:
, если __name__ == '__main__': unittest.main ()Вы можете запустить тесты с более подробной информацией, передав многословие аргумент:
, если __name__ == '__main__': unittest.main (многословие = 2)Аргумент defaultTest - это либо имя отдельного теста, либо итерация имен тестов для запуска, если имена тестов не указаны через argv .Если не указано или
Нети имена тестов не указаны через argv , все выполняются тесты, найденные в модуле .Аргумент argv может быть списком параметров, переданных программе, с первым элементом является имя программы. Если не указано или
Нет, используются значенияsys.argv.Аргумент testRunner может быть либо классом тестового исполнителя, либо уже создал его экземпляр. По умолчанию
mainвызываетsys.exit ()с код выхода, указывающий на успешное или неудачное выполнение тестов.Аргумент testLoader должен быть экземпляром
TestLoader, и по умолчаниюdefaultTestLoader.mainподдерживает использование из интерактивного интерпретатора путем передачи аргументвыход = Ложь. Результат отобразится на стандартном выходе без вызовsys.exit ():>>> из unittest import main >>> main (module = 'test_module', exit = False)
Параметры failfast , catchbreak и buffer имеют одинаковые эффект как одноименные параметры командной строки.
Аргумент предупреждений указывает фильтр предупреждений это следует использовать при запуске тестов. Если не указано иное, будет остается
Нет, если параметр-Wпередается в python (см. Предупреждение), в противном случае будет установлено значение«по умолчанию».Вызов
mainфактически возвращает экземпляр классаTestProgram. Это сохраняет результат выполненных тестов как атрибутresult.Изменено в версии 3.1: добавлен параметр exit .
Изменено в версии 3.2: подробность , failfast , catchbreak , buffer и предупреждений добавлено параметров.
Изменено в версии 3.4: параметр defaultTest был изменен, чтобы также принимать итерацию имена тестов.
load_tests Протокол
Модули или пакеты могут настраивать способ загрузки тестов из них во время нормального
запуски тестов или обнаружение тестов путем реализации функции load_tests .
Если тестовый модуль определяет load_tests , он будет вызываться
TestLoader.loadTestsFromModule () со следующими аргументами:
load_tests (загрузчик, стандартные_тесты, шаблон)
, где шаблон передается напрямую из loadTestsFromModule . Это
по умолчанию Нет .
Он должен вернуть TestSuite .
Загрузчик - это экземпляр TestLoader , выполняющий загрузку. standard_tests - это тесты, которые по умолчанию загружаются из
модуль. Обычно тестовые модули хотят только добавлять или удалять тесты.
из стандартного набора тестов.
Третий аргумент используется при загрузке пакетов в рамках обнаружения тестов.
Типичная функция load_tests , которая загружает тесты из определенного набора
TestCase классы могут выглядеть так:
test_cases = (TestCase1, TestCase2, TestCase3)
def load_tests (загрузчик, тесты, шаблон):
suite = TestSuite ()
для test_class в test_cases:
тесты = загрузчик.loadTestsFromTestCase (тестовый_класс)
suite.addTests (тесты)
возвращение люкс
Если обнаружение запущено в каталоге, содержащем пакет, либо из
в командной строке или вызвав TestLoader.discover () , затем пакет
__init__.py будет проверяться на load_tests . Если эта функция
не существует, обнаружение будет рекурсивно в пакет, как если бы это было просто
другой каталог. В противном случае обнаружение тестов пакета будет отложено.
в load_tests , который вызывается со следующими аргументами:
load_tests (загрузчик, стандартные_тесты, шаблон)
Это должно вернуть TestSuite , представляющий все тесты
из упаковки.( standard_tests будет содержать только тесты
собрано с __init__.py .)
Поскольку шаблон передается в load_tests , пакет можно бесплатно
продолжить (и потенциально изменить) обнаружение теста. "Ничего не делать"
Функция load_tests для тестового пакета будет выглядеть так:
def load_tests (загрузчик, стандартные_тесты, шаблон):
# каталог верхнего уровня, кэшируемый на экземпляре загрузчика
this_dir = os.path.dirname (__ file__)
package_tests = загрузчик.обнаружить (start_dir = this_dir, pattern = pattern)
standard_tests.addTests (package_tests)
вернуть стандартные_тесты
Изменено в версии 3.5: Discovery больше не проверяет имена пакетов на соответствие шаблону из-за невозможность совпадения имен пакетов с шаблоном по умолчанию.
Приспособления для классов и модулей
Приспособления на уровне классов и модулей реализованы в TestSuite . Когда
набор тестов встречает тест из нового класса, затем tearDownClass ()
из предыдущего класса (если он есть) вызывается, за которым следует
setUpClass () из нового класса.
Аналогично, если тест взят из модуля, отличного от предыдущего теста, тогда
tearDownModule из предыдущего модуля, за которым следует
setUpModule из нового модуля.
После завершения всех тестов последний класс tearDownClass и
tearDownModule запущены.
Обратите внимание, что общие приборы плохо работают с [потенциальными] функциями, такими как test распараллеливание, и они нарушают тестовую изоляцию. Их следует использовать с осторожностью.
По умолчанию тесты, созданные загрузчиками модульных тестов, группируются.
все тесты из одних и тех же модулей и классов вместе. Это приведет к
setUpClass / setUpModule (и т. Д.) Вызывается ровно один раз для каждого класса и
модуль. Если вы рандомизируете порядок, чтобы тесты из разных модулей и
классы смежны друг с другом, тогда эти общие функции фикстуры могут быть
вызывается несколько раз за один тестовый прогон.
Общие светильники не предназначены для работы с апартаментами с нестандартными
заказ. BaseTestSuite все еще существует для фреймворков, которые не хотят
поддержка общих светильников.
Если возникают какие-либо исключения во время одной из общих функций прибора
тест регистрируется как ошибка. Потому что нет соответствующего теста
экземпляр объекта _ErrorHolder (который имеет тот же интерфейс, что и
TestCase ) создается для представления ошибки. Если вы просто используете
стандартного средства запуска unittest test, то эта деталь не имеет значения, но если вы
автор фреймворка, это может быть актуально.
setUpClass и tearDownClass
Они должны быть реализованы как методы класса:
import unittest
класс Test (unittest.TestCase):
@classmethod
def setUpClass (cls):
cls._connection = createExuredConnectionObject ()
@classmethod
def tearDownClass (cls):
cls._connection.destroy ()
Если вы хотите, чтобы setUpClass и tearDownClass в базовых классах вызывали
тогда вы должны сами позвонить им. Реализации в
TestCase пустые.
Если исключение возникает во время setUpClass , тогда тесты в классе
не запускаются, и tearDownClass не запускается. Пропущенные занятия не будут
выполнить setUpClass или tearDownClass . Если исключение составляет
SkipTest исключения, тогда класс будет пропущен
вместо ошибки.
setUpModule и tearDownModule
Они должны быть реализованы как функции:
по умолчанию setUpModule ():
createConnection ()
def tearDownModule ():
closeConnection ()
Если исключение возникает в setUpModule , то ни один из тестов в
модуль будет запущен, а tearDownModule не будет запущен.Если исключение составляет
SkipTest исключение, тогда модуль будет пропущен
вместо ошибки.
Чтобы добавить код очистки, который должен запускаться даже в случае исключения, используйте
addModuleCleanup :
-
unittest.addModuleCleanup( функция , /, * args , ** kwargs ) -
Добавить функцию, которая будет вызываться после
tearDownModule ()для очистки ресурсы, используемые во время тестового класса.Функции будут вызываться в обратном порядке порядок их добавления ( LIFO ). Они вызываются с любыми аргументами и аргументами ключевого слова, переданными вaddModuleCleanup ()при их добавлении.Если
setUpModule ()завершается ошибкой, это означает, чтоtearDownModule ()не выполняется. вызывается, то все добавленные функции очистки будут по-прежнему вызываться.
-
unittest.doModuleCleanups() -
Эта функция вызывается безоговорочно после
tearDownModule ()или послеsetUpModule (), еслиsetUpModule ()вызывает исключение.Он отвечает за вызов всех функций очистки, добавленных
addCleanupModule (). Если вам нужно вызвать функции очистки до наtearDownModule (), затем вы можете позвонитьdoModuleCleanups ()самостоятельно.doModuleCleanups ()извлекает методы из стека очистки функционирует по одному, поэтому его можно вызывать в любое время.
Обработка сигналов
Параметр командной строки -c / - catch для unittest,
вместе с параметром catchbreak до unittest.main () , укажите
более удобное обращение с control-C во время пробного запуска. С перерывом
с включенным поведением control-C позволит завершить текущий тест,
Затем тестовый прогон завершится, и будут представлены все результаты на текущий момент. Второй
control-c вызовет KeyboardInterrupt обычным способом.
Обработчик сигнала обработки control-c пытается оставаться совместимым с кодом или
тесты, которые устанавливают собственный обработчик сигнала signal.SIGINT . Если unittest
вызывается обработчик, но не является установленным сигналом .Обработчик SIGINT ,
то есть он был заменен тестируемой системой и делегирован, затем он
вызывает обработчик по умолчанию. Обычно это ожидаемое поведение по коду.
который заменяет установленный обработчик и делегирует ему полномочия. Для индивидуальных тестов
что нужно unittest control-c обработка отключила removeHandler ()
декоратор можно использовать.
Есть несколько служебных функций для авторов фреймворка, чтобы включить control-c функциональность обработки в рамках тестовой среды.
-
unittest.installHandler() -
Установите обработчик control-c. При получении сигнала
.SIGINT(обычно в ответ на нажатие пользователем Ctrl-c) все зарегистрированные результаты вызовитеstop ().
-
unittest.регистрацияРезультат( результат ) -
Зарегистрируйте объект
TestResultдля обработки control-c. Регистрация result сохраняет слабую ссылку на него, поэтому он не препятствует сборщик мусора.Регистрация объекта
TestResultне имеет побочных эффектов, если Ctrl-c обработка не включена, поэтому тестовые фреймворки могут безоговорочно регистрировать все результаты, которые они создают, независимо от того, включена ли обработка.
-
unittest.removeResult( результат ) -
Удалить зарегистрированный результат. Как только результат был удален, тогда
stop ()больше не будет вызываться для этого объекта результата в ответ на Control-c.
-
unittest.removeHandler(функция = Нет ) -
При вызове без аргументов эта функция удаляет обработчик control-c если он был установлен. Эту функцию также можно использовать как декоратор тестов. для временного удаления обработчика во время выполнения теста:
@ unittest.removeHandler def test_signal_handling (сам): ...
Равная защита | Wex | Закон США
Обзор
Равная защита относится к идее о том, что правительственный орган не может отказывать людям в равной защите своих регулирующих законов.Государство руководящего органа должно относиться к человеку так же, как и к другим в аналогичных условиях и обстоятельствах.
Допустимая дискриминация
Прежде чем продолжить, важно помнить, что правительству разрешено дискриминировать отдельных лиц при условии, что дискриминация удовлетворяет анализу равной защиты, изложенному ниже и подробно описанному в этой статье обзора законодательства Санта-Клары.
Конституция США
Пункт о надлежащей правовой процедуре Пятой поправки требует, чтобы правительство Соединенных Штатов практиковало равную защиту.Положение о равной защите Четырнадцатой поправки требует, чтобы государства практиковали равную защиту.
Равная защита вынуждает государство действовать беспристрастно, а не проводить различия между людьми исключительно на основании различий, не имеющих отношения к законной цели правительства. Таким образом, положение о равной защите имеет решающее значение для защиты гражданских прав.
Анализ равной защиты
Когда человек считает, что федеральное правительство или правительство штата нарушило гарантированные ему равные права, он может подать иск против этого государственного органа с просьбой о возмещении ущерба.
В зависимости от типа предполагаемой дискриминации, человеку сначала необходимо доказать, что руководящий орган действительно дискриминировал человека. Человеку необходимо будет доказать, что действия руководящего органа привели к фактическому ущербу для человека. Доказав это, суд, как правило, исследует действия правительства одним из трех способов, чтобы определить, допустимо ли действие государственного органа: эти три метода называются строгим контролем, промежуточным контролем и исследованием рациональной основы.Суд определит, какой проверке будет подвергнуто лицо, опираясь на правовой прецедент, чтобы определить, какой уровень проверки использовать. Важно отметить, что суды объединили элементы двух из трех тестов для создания специального теста.
Дополнительная литература
Дополнительную информацию о равной защите см. В этой статье Harvard Law Review, этой статье University of Pennsylvania Law Review и этой статье Columbia University Law Review.
11.2 - Когда различия в популяциях не равны
Психолог интересовался исследованием того, имеют ли студенты колледжа мужское и женское поведение вождения по-разному.Было несколько способов, которыми она могла количественно оценить поведение за рулем. Она решила сосредоточиться на максимальной скорости, которую когда-либо водил человек. Таким образом, конкретный статистический вопрос, который она сформулировала, был следующим:
Отличается ли средняя максимальная скорость студентов мужского пола от средней максимальной скорости студенток колледжа?
Она провела опрос случайных \ (n = 34 \) студентов мужского пола и случайных \ (m = 29 \) студенток колледжа. Вот краткое описание результатов ее опроса:
Достаточно ли доказательств на \ (\ alpha = 0.05 \), чтобы сделать вывод о том, что средняя максимальная скорость студентов мужского пола отличается от средней максимальной скорости студенток колледжа?
Ответ
На этот раз давайте не будем предполагать, что дисперсии населения равны. Затем посмотрим, придем ли мы к другому выводу. Тем не менее, давайте все же предположим, что две популяции с самой быстрой скоростью - мужчины и женщины - распределены нормально. И мы снова допустим случайность двух выборок, чтобы также предположить независимость измерений.2} = 55,5 \)
Ой ... это не целое число, поэтому нам нужно взять наибольшую целую часть этого \ (r \). То есть мы принимаем степени свободы равными \ (\ lfloor r \ rfloor = \ lfloor 55,5 \ rfloor = 55 \).
Затем подход критического значения говорит нам отклонить нулевую гипотезу в пользу альтернативной гипотезы, если:
\ (t> t_ {0,025,55} = 2,004 \)
Мы отклоняем нулевую гипотезу, потому что тестовая статистика (\ (t = 3,54 \)) попадает в область отклонения:
Имеется (снова!) Достаточное свидетельство в \ (\ alpha = 0.05 \), чтобы сделать вывод о том, что средняя максимальная скорость, на которой движется популяция студентов мужского пола, отличается от средней максимальной скорости, установленной популяцией студенток колледжа.
И снова решение то же самое с использованием подхода \ (p \) - значения. \ (P \) - значение 0,0008:
\ (P = 2 \ times P (T_ {55}> 3,54) = 2 (0,0004) = 0,0008 \)
Следовательно, поскольку \ (p = 0,008 \ le \ alpha = 0,05 \), мы отвергаем нулевую гипотезу в пользу альтернативной гипотезы.Опять же, мы заключаем, что на уровне \ (\ alpha = 0,05 \) имеется достаточно доказательств, чтобы сделать вывод о том, что средняя максимальная скорость, установленная популяцией студентов мужского пола, отличается от средней максимальной скорости, установленной популяцией студенток колледжа.
Во всяком случае, мы видим, что в этом случае наш вывод один и тот же независимо от того, предполагаем мы равенство дисперсий совокупности или нет.
И, на всякий случай, если вам интересно ... мы очень скоро увидим, как сообщить Minitab о проведении \ (t \) - теста Велча, а пока вот как будет выглядеть результат для этого Например:
Предполагая равные различия в населении - вводная бизнес-статистика
Проверка гипотез на двух выборках
Обычно мы никогда не можем ожидать, что узнаем какие-либо параметры генеральной совокупности, среднее значение, пропорцию или стандартное отклонение.При проверке гипотез о различиях в средних мы сталкиваемся с трудностью двух неизвестных дисперсий, которые играют решающую роль в статистике теста. Мы заменяли выборочные дисперсии так же, как и при проверке гипотез для единственного среднего. Как и раньше, мы использовали t Стьюдента, чтобы компенсировать недостаток информации о дисперсии генеральной совокупности. Однако могут быть ситуации, когда мы не знаем дисперсию популяций, но можем предположить, что две популяции имеют одинаковую дисперсию.Если это так, то дисперсия объединенной выборки будет меньше дисперсии отдельной выборки. Это даст более точные оценки и снизит вероятность отбрасывания хорошего нуля. Нулевая и альтернативная гипотезы остаются прежними, но статистика теста меняется на:
, где - объединенная дисперсия, вычисляемая по формуле:
Попытка испытания препарата с использованием настоящего наркотика и таблетки, сделанной только из сахара. 18 человек получают настоящий препарат в надежде увеличить выработку эндорфинов.Установлено, что увеличение эндорфинов составляет в среднем 8 микрограммов на человека, а стандартное отклонение образца составляет 5,4 микрограмма. 11 человек получают сахарную пилюлю, и их средний прирост эндорфина составляет 4 мкг со стандартным отклонением 2,4. Из предыдущих исследований эндорфинов было определено, что можно предположить, что отклонения в двух выборках могут быть одинаковыми. Проведите тест на уровне 5%, чтобы увидеть, оказало ли популяционное среднее для реального препарата значительно большее влияние на эндорфины, чем популяционное среднее для сахарной таблетки.
Сначала мы начнем с обозначения одной из двух групп - группы 1, а другой - группы 2. Это потребуется для отслеживания нулевой и альтернативной гипотез. Давайте обозначим группу 1 как тех, кто получил собственно новое тестируемое лекарство, и, следовательно, группа 2 - это те, кто получил сахарную пилюлю. Теперь мы можем сформулировать нулевую и альтернативную гипотезу как:
H 0 : µ 1 ≤ µ 2
H 1 : µ 1 > µ 2
Это настроено как односторонний тест с утверждением в альтернативной гипотезе, что лекарство будет производить больше эндорфинов, чем сахарная пилюля.Теперь мы вычисляем статистику теста, которая требует, чтобы мы вычислили объединенную дисперсию, используя формулу выше.
t α , позволяет сравнить статистику теста и критическое значение.
Статистика теста явно находится в хвосте, 2,31 больше критического значения 1,703, и поэтому мы не можем поддерживать нулевую гипотезу. Таким образом, мы приходим к выводу, что есть существенные доказательства с уровнем уверенности 95%, что новое лекарство дает желаемый эффект.
Обзор главы
В ситуациях, когда мы не знаем дисперсии генеральной совокупности, но предполагаем, что дисперсии одинаковы, дисперсия объединенной выборки будет меньше дисперсии отдельной выборки.
Это даст более точные оценки и снизит вероятность отбрасывания хорошего нуля.
Формула Обзор
, где - объединенная дисперсия, вычисляемая по формуле:
t-критерий: двухвыборочный критерий, предполагающий равные отклонения
Инструмент t-критерий парный двухвыборочный для средних значений выполняет парный двухвыборочный t-критерий Стьюдента, чтобы убедиться, что нулевая гипотеза (средние значения двух совокупностей равны) принято или отклонено.Этот тест не предполагает, что дисперсия обеих популяций одинакова. Парные t-тесты обычно используются для проверки средних значений совокупности до и после некоторого лечения, то есть двух выборок результатов учащихся по математике до и после урока.
Результатом этого инструмента является вычисленное значение t. Это значение может быть отрицательным или положительным, в зависимости от данных. Если предположить, что средние по численности населения равны:
- Если t <0, P (T <= t) one-tail - это вероятность того, что значение t-статистики будет более отрицательным, чем t.
- Если t> 0, P (T <= t) один хвост - это вероятность того, что будет наблюдаться значение t-статистики, более положительное, чем t.
- P (T <= t) два хвоста - это вероятность того, что будет наблюдаться значение t-статистики, которое по абсолютной величине больше, чем t.
Примеры наборов данных ниже были взяты из 10 студентов. В начале и в конце учебного года учащимся давали один и тот же тест. Используйте парный t-тест, чтобы определить, улучшился ли средний балл 2-го теста по сравнению со средним баллом 1-го теста.
Для проведения t-теста:
- На панели XLMiner Analysis ToolPak щелкните t-Test Paired Two-Sample for Means.
- Введите A2: A11 для диапазона переменной 1. Это наш первый набор ценностей, значений, записанных в начале учебного года.
- Введите B2: B11 для диапазона переменной 2. Это наш второй набор ценностей, значений, записанных в конце учебного года.
- Введите «0» для предполагаемой средней разницы. Это означает, что мы проверяем, что средние значения двух образцов равны.
- Снимите флажок «Ярлыки», поскольку мы не включили заголовки столбцов в диапазоны переменных 1 и 2.
- Оставьте альфа = 0,05.
- Введите D1 в качестве диапазона вывода.
- Нажмите ОК.
- Ячейки E4 и F4 содержат среднее значение каждой выборки, переменная 1 = начало и переменная 2 = конец.
- Ячейки E5 и F5 содержат дисперсию каждой выборки.
- Ячейки E6 и F6 содержат количество наблюдений в каждой выборке.
- Ячейка E7 содержит корреляцию Пирсона, которая указывает на то, что две переменные довольно тесно коррелированы.
- Ячейка E8 содержит нашу запись для гипотетической средней разности.
- Ячейки E9 содержат степени свободы, 10 - 1.
- Ячейка E10 содержит результат фактического t-критерия. Мы сравним это значение со статистикой t-Critical с двумя хвостами. Примечание: используйте односторонний тест, если у вас есть направление в своей гипотезе, т.е. если вы проверяете, что значение выше или ниже некоторого уровня.
- В этом примере P (T <= t) два хвоста (0,0000321) дает вероятность того, что будет наблюдаться абсолютное значение t-статистики (7,633), которое по абсолютной величине больше, чем критическое значение t (2,26). Поскольку значение p меньше нашего альфа, 0,05, мы отвергаем нулевую гипотезу о том, что нет значительной разницы в средних значениях для каждой выборки.